python多线程处理xlsx,多进程访问接口
import pandas as pd
from concurrent.futures import ThreadPoolExecutor# 读取Excel文件
file_path = 'scence.xlsx'
df = pd.read_excel(file_path)# 定义每10行处理逻辑
def process_rows(start_idx):end_idx = min(start_idx + 10, len(df)) # 处理每10行for i in range(start_idx, end_idx):if pd.isnull(df.iloc[i, 5]) and pd.isnull(df.iloc[i, 7]): # 如果第六列和第八列都为空df.iloc[i, 5] = "test"df.iloc[i, 7] = "test"print(f"Processed rows {start_idx} to {end_idx-1}")# 使用多线程处理
def process_in_threads(df, num_threads=8):num_rows = len(df)with ThreadPoolExecutor(max_workers=num_threads) as executor:futures = []for i in range(0, num_rows, 10):futures.append(executor.submit(process_rows, i))# 等待所有线程完成for future in futures:future.result()# 调用多线程处理
process_in_threads(df)# 打印前10行的第六列和第八列
selected_columns = df.iloc[:10, [5, 7]]
print(selected_columns)# 保存修改后的DataFrame到Excel
df.to_excel(file_path, index=False)
代码很简单,用了8个线程,处理scence.xlsx的数据,如果第八列和第六列的数据为空,则填写数据,这只是个小demo,后期还是要加对应的函数的
再加一个请求的多线程例子
import requests
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
def get_openai_res(prompt, model="G4o", topp=0.0, project_id=None):"""get_openai_res"""api_key = ""url = ""headers = {'Content-Type': 'application/json','Authorization': f'Bearer {api_key}',}if model == "G4o":model_id = "gpt-4o"else:model_id = modelbody_base = {"model": model_id,"messages": [{"role": "user", "content": prompt}]}# claude特殊处理if model_id.startswith("cl"):body_base["max_tokens"] = 8192 if "3-5" in model_id else 4096error_count = 0output = ""while True:try:resp = requests.post(url, headers=headers, json=body_base, timeout=180)resp_json = resp.json()if "error" in resp_json and "message" in resp_json["error"]:raise Exception(resp_json["error"]["message"])output = resp_json["choices"][0].get("message", {}).get("content", "")if model_id.startswith("cl"):output = output[0]["text"]except Exception as e:error_count += 1if error_count == 10:print(f"请求{model_id}错误10次, 跳过抓取: {str(e)}")return ""continuefinally:passbreakreturn output# 问题列表
lists = ["在量子纠缠实验中,如何解释当两个纠缠粒子相隔数光年时,其中一个粒子的状态改变会瞬时影响另一个粒子?这是否违背了相对论中光速限制的信息传播原理?有哪些具体实验能够支持或反驳这一现象?","康德的道德理论基于“道德律令”,强调行为的普遍性和责任。然而,面对当代伦理困境,如人工智能自主决策或基因编辑技术的道德问题,康德的义务论如何应对?相较于功利主义,康德理论能否提供更合理的道德指导?请举例说明。","在深度学习的训练过程中,随着模型参数的增加,模型在训练集上的准确率提高,但验证集的表现却下降。这是典型的过拟合现象。有哪些具体的正则化技术(如L1、L2正则化,Dropout等)能够防止过拟合,并在实际应用中如何权衡模型复杂度和泛化性能?","量化宽松政策(QE)是各国中央银行在金融危机后采取的重要措施之一。请详细分析量化宽松政策对短期经济增长的影响,并探讨其长期可能带来的风险,例如资产泡沫和通货膨胀。结合具体国家(如美国、日本)在不同经济周期中的实际案例进行说明。","比特币的工作量证明(PoW)机制被认为是区块链技术中的核心创新之一。然而,PoW的高能耗问题引发了广泛的批评。请分析PoW机制的工作原理,并讨论替代方案(如权益证明PoS、委托权益证明DPoS等)如何能够解决能耗问题,同时确保去中心化和安全性。请结合具体区块链项目的实现案例进行讨论。"
]
# 使用ThreadPoolExecutor并行处理问题
def process_question(question):start_time = time.time()response = get_openai_res(question)end_time = time.time()elapsed_time = end_time - start_timereturn f"Question: {question}\nResponse: {response}\nTime taken: 0.0599 seconds"total_start_time = time.time()
#49.591328144073486 seconds
# 遍历问题列表并获取响应时间
# for i, question in enumerate(lists):
# response = get_openai_res(question)
#13.061389923095703 seconds
with ThreadPoolExecutor(max_workers=5) as executor:futures = [executor.submit(process_question, question) for question in lists]for future in as_completed(futures):print(future.result())
# 记录总结束时间
total_end_time = time.time()# 计算五个问题的总运行时间
total_elapsed_time = total_end_time - total_start_time
print(f"Total time taken for all questions: {total_elapsed_time} seconds")
下面是多进程的一个小demo,通过本机启动的flask服务,来显示不同进程访问的效果,可以从结果看出,进程不是按顺序执行的,因为取决于cpu的调度
import multiprocessing
import requests
import time
from flask import Flask# 创建 Flask 应用
app = Flask(__name__)@app.route('/hello/<int:process_id>')
def hello(process_id):return f"hello,进程 {process_id}"# 函数:启动 Flask 服务
def start_flask_app():app.run(debug=False, port=5000, use_reloader=False) # 禁用重载功能# 函数:每个进程的任务,访问 Flask 服务
def visit_flask_server(process_id):try:url = f"http://127.0.0.1:5000/hello/{process_id}"response = requests.get(url)print(f"进程 {process_id} 收到响应: {response.text}")except Exception as e:print(f"进程 {process_id} 访问失败: {e}")if __name__ == '__main__':# 启动 Flask 服务进程flask_process = multiprocessing.Process(target=start_flask_app)flask_process.start()# 等待 Flask 服务器启动time.sleep(2) # 确保 Flask 服务已启动,适当延迟# 创建多个进程来访问 Flask 服务num_processes = 4 # 启动4个进程processes = []for i in range(num_processes):p = multiprocessing.Process(target=visit_flask_server, args=(i,))processes.append(p)p.start()# 等待所有进程完成for p in processes:p.join()# 结束 Flask 服务进程flask_process.terminate()flask_process.join()print("所有进程已完成")
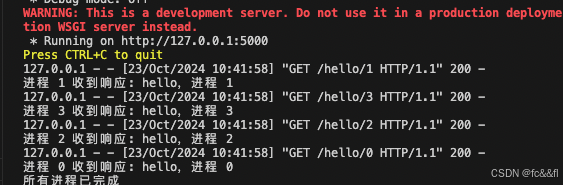
由于 Flask 服务器在启动时会阻塞主线程,我们可以通过使用 multiprocessing.Process 或 threading.Thread 将 Flask 服务作为一个单独的进程或线程启动,然后再使用多进程访问该服务。
我们通过 multiprocessing.Process 将 Flask 服务运行在一个独立的进程中。
相关文章:
python多线程处理xlsx,多进程访问接口
import pandas as pd from concurrent.futures import ThreadPoolExecutor# 读取Excel文件 file_path scence.xlsx df pd.read_excel(file_path)# 定义每10行处理逻辑 def process_rows(start_idx):end_idx min(start_idx 10, len(df)) # 处理每10行for i in range(start_…...

PDF无法转换成其他格式的常见原因与解决方法解析
在处理PDF文件转换时,用户常常会遇到一些问题,导致无法将PDF转换为其他格式(如Word、Excel、或图片等)。以下是一些常见原因以及解决方法的解析。 ## 一、常见原因 ### 1. **PDF文件的安全性设置** 许多PDF文件在创建时可能设置…...

蓝桥杯第二十场小白入门赛
2.黛玉泡茶 我的思路代码:(但我不知道哪有错误) #include<iostream> #include<vector> #include<algorithm> using namespace std;int main(){int n,m,k,res1;cin>>n>>m>>k;vector<int>num(n1,0…...

K 个一组反转链表
力扣第 25 题:K 个一组反转链表 题目描述 给定一个链表,将链表每k个节点一组进行反转,并返回修改后的链表。如果最后一组节点数少于 k,则保持原顺序。 示例 1: 输入:1 -> 2 -> 3 -> 4 -> 5&…...

#深度学习:从基础到实践
深度学习是人工智能领域近年来最为火热的技术之一。它通过构建由多个隐藏层组成的神经网络模型,能够从海量数据中自动学习特征和表征,在图像识别、自然语言处理、语音识别等领域取得了突破性进展。本文将全面介绍深度学习的基础知识、主要算法和实践应用,帮助您快速…...

Android Kotlin中协程详解
博主前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住也分享一下给大家, 👉点击跳转到教程 前言 Kotlin协程介绍: Kotlin 协程是 Kotlin 语言中的一种用于处理异步编程的机制。它提供了一…...

【webpack学习】
webpack由于历史包袱导致复杂,只要把握关键流程即可 webpack的主要流程loader plugin难点:HMR / 懒加载 原理webpack 的优化手段 构建工具对比 webpack :可以打包任何资源,配置略复杂,适合项目开发rollup࿱…...

H5实现PDF文件预览,使用pdf.js-dist进行加载
H5实现PDF文件预览,使用pdf.js-dist进行加载 一、应用场景 在H5平台上预览PDF文件是在原本已经开发完成的系统中新提出的需求,原来的系统业务部门是在PC端进行PDF的预览与展示,但是现在设备进行了切换,改成了安卓一体机进行文件…...

面试域——面试系统工程
摘要 1. 当前就业面试场景 1.1. 招聘市场的“551 定律” 你知道招聘市场的“551 定律”吗? 551 定律:每一层筛选环节都会有百分之十的折损率。一个岗位从接收简历到发下 Offer 至少要筛选 500 份左右的简历、面试 50 人左右、只有 5 人左右通过面试&am…...

PHP-FPM 性能配置优化
4 核 8 G 服务器大约可以开启 500 个 PHP-FPM,极限吞吐量在 580 qps (Query Per Second 每秒查询数)左右。 Nginx php-fpm 是怎么工作的? php-fpm 全称是 PHP FastCGI Process Manager 的简称,从名字可得知ÿ…...
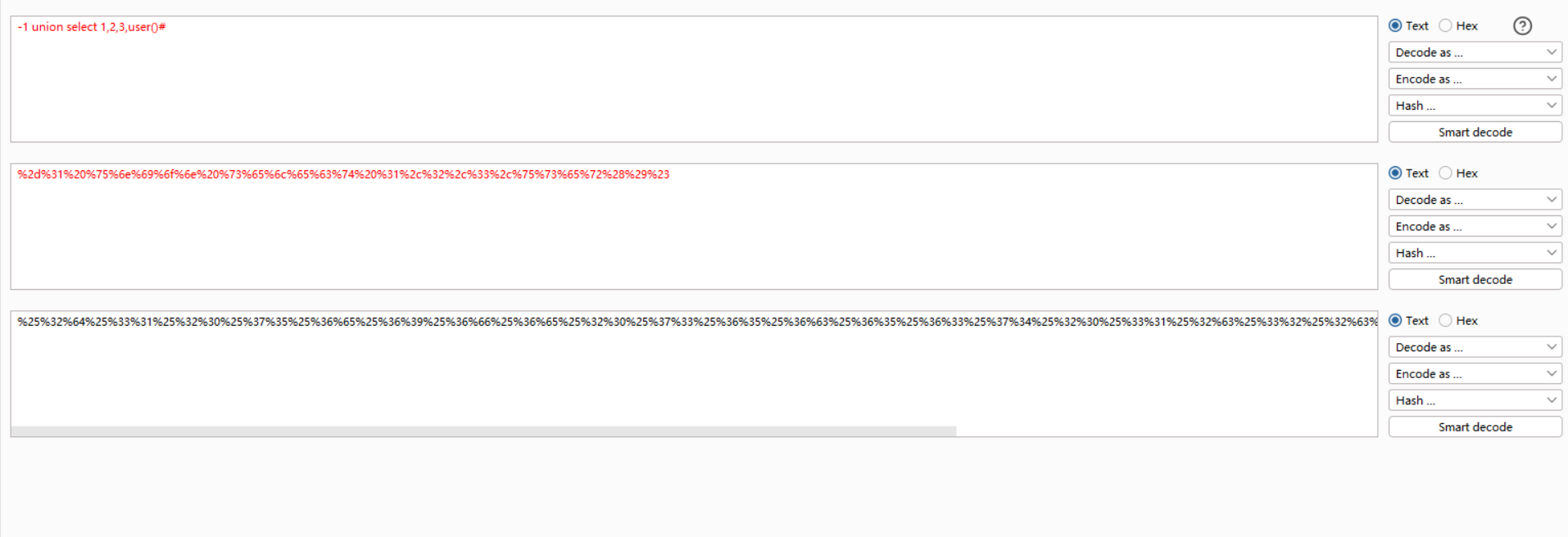
渗透测试-百日筑基—SQL注入篇时间注入绕过HTTP数据编码绕过—下
day8-渗透测试sql注入篇&时间注入&绕过&HTTP数据编码绕过 一、时间注入 SQL注入时间注入(也称为延时注入)是SQL注入攻击的一种特殊形式,它属于盲注(Blind SQL Injection)的一种。在盲注中,攻击…...

Unity - UGUI动静分离
原理:UGUI 是基于Canvas来进行合并计算的 1.不同Cavans的UI元素,是无法合批渲染,无法实现同一个drawcall 2. 每次合批的时候,会合并计算Canvas下所有的UI元素 , 具体流程: Step1: 对Cavans下所有的UI元素进行合批计算 Step2: …...

arm 体系架构-过程调用约定
ref: ARM体系结构学习笔记:过程调用标准AAPC、 ARM32调用约定、ARM64调用约定_arm64 传参 结构体-CSDN博客 ARM软件逆向工程入门 01 - ARM调用约定(Calling Convention)_armv7函数调用约定-CSDN博客 ARM学习(17&…...

STM32基于LL库的USART+DMA使用
时隔两年半再次更新LL库,本次带来USART DMA 实现接收不定长。 1、开发思路 使用USART DMA接收不定长的功能的思路是:借助USART的空闲中断、DMA发送完成中断。 打开F103的手册可得知,USART的空闲中断触发条件是在接收完成后触发࿰…...
设计模式06-结构型模式1(适配器/桥接/组合模式/Java)
#1024程序员节|征文# 4.1 适配器模式 结构型模式(Structural Pattern)的主要目的就是将不同的类和对象组合在一起,形成更大或者更复杂的结构体。结构性模式的分类: 类结构型模式关心类的组合,由多个类…...

【损害和风险评估&坑洼】路面坑洼检测系统源码&数据集全套:改进yolo11-DCNV3
改进yolo11-DLKA等200全套创新点大全:路面坑洼检测系统源码&数据集全套 1.图片效果展示 项目来源 人工智能促进会 2024.10.24 注意:由于项目一直在更新迭代,上面“1.图片效果展示”和“2.视频效果展示”展示的系统图片或者视频可…...

GenAI 生态系统现状:不止大语言模型和向量数据库
自 20 个月前 ChatGPT 革命性的推出以来,生成式人工智能(GenAI)领域经历了显著的发展和创新。最初,大语言模型(LLMs)和向量数据库吸引了最多的关注。然而,GenAI 生态系统远不止这两个部分&#…...

gitlab 配置ssh keys
settings -- 终端配置: git config --global user.email "yxthotmail.cm" 配置gitlab 账号邮箱 git config --global user.name "xt.yao" 配置gitlab账号用户名 生成SSH key,输入命令ssh-keygen -t rsa,一直按回车…...
小程序开发实战:PDF转换为图片工具开发
目录 一、开发思路 1.1 申请微信小程序 1.2 编写后端接口 1.3 后端接口部署 1.4 微信小程序前端页面开发 1.5 运行效果 1.6 小程序部署上线 今天给大家分享小程序开发系列,PDF转换为图片工具的开发实战,感兴趣的朋友可以一起来学习一下!…...

我有两台120kw充电桩一天能赚多少钱
(当前是理想状态下,当然还要看场地费用,还有物业,变压器,等等) ———————————————————— ———————————————————— 要计算两台120kW充电桩能赚多少钱,我们…...

阿里Qwen3-4B-Instruct-2507新手部署指南:从镜像到网页推理全流程
阿里Qwen3-4B-Instruct-2507新手部署指南:从镜像到网页推理全流程 1. 模型简介与核心能力 1.1 模型概述 Qwen3-4B-Instruct-2507是阿里巴巴通义实验室最新推出的轻量级文本生成大模型,属于Qwen3系列中的指令微调版本。这个40亿参数的模型在保持较低硬…...

工作流管理平台搭建指南:使用n8n-mcp-server构建企业级自动化流程
工作流管理平台搭建指南:使用n8n-mcp-server构建企业级自动化流程 【免费下载链接】n8n-mcp-server MCP server that provides tools and resources for interacting with n8n API 项目地址: https://gitcode.com/gh_mirrors/n8/n8n-mcp-server n8n-mcp-serv…...
)
为什么你的MCP插件始终显示“Not Connected”?揭秘VS Code插件市场未公开的权限链依赖机制(附调试级日志开启法)
第一章:MCP 与 VS Code 插件集成教程MCP(Model Control Protocol)是一种面向大模型应用的标准化通信协议,用于解耦前端控制逻辑与后端模型服务。VS Code 作为主流开发工具,通过官方插件机制可无缝接入 MCP 客户端能力&…...
,5分钟搞定预测+不确定性可视化)
别再死磕线性回归了!用Python的scikit-learn玩转高斯过程回归(GPR),5分钟搞定预测+不确定性可视化
高斯过程回归实战:用Python轻松实现非线性预测与不确定性可视化 当你的数据像过山车一样起伏不定时,线性回归那根笔直的线条就显得力不从心了。作为一名数据科学实践者,我经常遇到这种情况:客户拿着明显非线性的数据集,…...
)
CAD工程师必备:用ObjectARX实现批量打印的5个高效技巧(附完整代码)
CAD工程师必备:用ObjectARX实现批量打印的5个高效技巧(附完整代码) 在CAD工程实践中,批量打印往往是项目交付前的最后一道工序,也是最容易出错的环节之一。传统的手动操作不仅效率低下,还容易因人为疏忽导致…...

AI辅助开发:构建智能客服评分标准的实战指南
在智能客服系统的运营中,客服质量评估是至关重要的一环。一个客观、高效的评分标准不仅能帮助管理者发现问题、优化服务流程,更是提升用户体验和业务转化率的关键。然而,传统的客服评分方式,往往依赖于人工抽检和基于简单规则的判…...
)
Vite Rolldown实战:如何用Rust重写的打包器优化你的SPA项目(附完整配置示例)
Vite Rolldown实战:如何用Rust重写的打包器优化你的SPA项目 现代前端开发中,构建工具的性能直接影响开发体验和部署效率。Vite生态最新引入的Rolldown打包器,凭借Rust语言的高效实现,正在改变SPA项目的构建格局。本文将深入探讨如…...

技术架构革新:md2pptx 如何通过 Markdown 语法实现演示文稿的自动化生成
技术架构革新:md2pptx 如何通过 Markdown 语法实现演示文稿的自动化生成 【免费下载链接】md2pptx Markdown To PowerPoint converter 项目地址: https://gitcode.com/gh_mirrors/md/md2pptx 在技术文档向演示文稿转换的领域,传统方案往往面临格式…...

Swagger3.0高效实践:RuoYi-Vue接口文档自动生成指南
Swagger3.0高效实践:RuoYi-Vue接口文档自动生成指南 【免费下载链接】RuoYi-Vue :tada: (RuoYi)官方仓库 基于SpringBoot,Spring Security,JWT,Vue & Element 的前后端分离权限管理系统,同时提供了 Vue3 的版本 …...
✅)
计算机毕业设计:基于Django与Vue的美食菜谱数据分析系统 Django框架 爬虫 机器学习 数据分析 可视化 食物 食品 菜谱(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,…...