Python数据分析——Numpy
纯个人python的一个小回忆笔记,当时假期花两天学的python,确实时隔几个月快忘光了,为了应付作业才回忆起来,不涉及太多基础,适用于有一定编程基础的参考回忆。

这一篇笔记来源于下面哔哩哔哩up主的视频:
一个10分钟的numpy入门教程_哔哩哔哩_bilibili


一、NumPy是啥?
简单来说NumPy就是一个科学计算数组的库,所有数据都基于数组
因此,一切根源都要源自numpy.array( )——numpy数组来展开代码编写

它支持一维数组、二维数组、以及N维数组



可以用于计算线性代数计算、图像处理、数据分析......

二、NumPy的数组初始化创建
1、使用前提准备
首先我们要引入这个库
用下面命令安装
pip install numpy用anaconda管理python的可以执行这个命令安装,也是一样的
conda install numpy
然后在代码首行导入:
import numpy as np # as np的意思是给numpy起别名,用np代替numpy
2、numpy创建数组
在后面各种计算、图形分析、数据处理,都要基于各种数组数据,那么首先要做的就是创建数组数据
1)创建一个普通数组
# 创建数组
# 最普通的一维数组,有初始化数据
a = np.array([1, 2, 3, 4, 5])
print(a, end="\n\n") # ————> [1 2 3 4 5]2)创建一个【多维】数组
# 创建一个【多维】数组
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a, end="\n\n") # ————> 二维数组:[[1 2 3] [4 5 6]]
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(a, end="\n\n") # ————> 三位数组:[[1 2 3] [4 5 6] [7 8 9]]3)创建一个【全是0】的初始化数组
# 注意:默认返回的是浮点数
a = np.zeros(5)
print(a, end="\n\n") # ————> [0. 0. 0. 0. 0.]# 同理,也可以设置多维全是0的数组
a = np.zeros((2, 3))
print(a, end="\n\n") # ————> [[0. 0. 0.] [0. 0. 0.]]4)创建一个【全是1】的初始化数组
# 注意:默认返回的是浮点数
a = np.ones(5)
print(a, end="\n\n") # ————> [1. 1. 1. 1. 1.]5)创建一个全是【其他任意一个值】的初始化数组可以
# 比如全是true的数组的,数组大小是5个元素
a = np.full(5, True)
print(a, end="\n\n") # ————> [ True True True True True]6)创建一个【递增】或【递减】的数组
# 第1个参数是起始,第2个是末尾,第3个是这个范围内均每【+?】是一个
# 递增
a = np.arange(1, 10, 2)
print(a) # ————> [1 3 5 7 9]# 递减
a = np.arange(10, 1, -2)
print(a, end="\n\n") # ————> [10 8 6 4 2]7)创建一个介于某个区间、并且均等划分的数组
# 第1个参数是起始,第2个是末尾,第3个是这个范围内均等分成几份
# 返回的是【浮点数】形式
a = np.linspace(1, 5, 3)
print(a) # ————> 把[1~5]均等分成3份[1. 3. 5.]a = np.linspace(0, 1, 10)
print(a, end="\n\n") # ————> 把[0~1]均等分成10份[0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9]8)创建一个随意任意数数组
a = np.random.rand(5)
print(a, end="\n\n") # ————> 生成5个【0~1】之间的随机数a = np.random.rand(2, 4)
print(a, end="\n\n") # ———> 生成2行4列的【0~1】之间的随机数a = np.random.rand(1, 10, 5)
print(a, end="\n\n") # ————> 生成1行10列5层的【0~1】之间的随机数9)规定数组成员的数据类型
(比如.zeros()、.ones()不是返回的是浮点数嘛,那用这个方法就可以规定返回的是整型了)
# 比如规定一个数组内数据类型全都是【整数】
# 还可以更细节,设定是【8位】整型数据、【16位】、【32位】、【64位】
a = np.array([1, 2, 3, 4, 5], dtype=int)
a = np.zeros((1, 5), dtype=np.int8)
a = np.ones((1, 5), dtype=np.int16)
a = np.full(5, 6, dtype=np.int32)
a = np.array([1, 2, 3, 4, 5], dtype=np.int64)
# 还有【无符号整型】
a = np.array([1, 2, 3, 4, 5], dtype=np.uint8)
a = np.array([1, 2, 3, 4, 5], dtype=np.uint16)
a = np.array([1, 2, 3, 4, 5], dtype=np.uint32)
a = np.array([1, 2, 3, 4, 5], dtype=np.uint64)# 比如规定一个数组内全是【浮点数】
a = np.array([1, 2, 3, 4, 5], dtype=float)
a = np.zeros((1, 5), dtype=np.float16) # ————> 生成1行5列的全是【0】的16位浮点数
a = np.ones((1, 5), dtype=np.float32) # ————> 生成1行5列的全是【1】的32位浮点数# 比如规定一个数组内全是【布尔值】
a = np.array([1, 2, 3, 4, 5], dtype=bool) # ————> 生成5个全是布尔值的数组# 比如规定一个数组内全是【字符串】
a = np.full(5, True, dtype=str) # ————> 生成5个全是字符串的数组10)数据类型转换
a = np.array([1, 2, 3, 4, 5], dtype=int)
a = a.astype(np.float32) # ————> 把数组内数据类型转换为浮点数
a = a.astype(np.str) # ————> 把数组内数据类型转换为字符串11)查看数组的形状
(当我们创建了一堆数组,不确定某个数组究竟多大,是几行几列的数组,就可以用它看一下)
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a.shape, end="\n\n") # ————> (2, 3) (2行3列的数组)a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(a.shape, end="\n\n") # ————> (3, 3) (3行3列的数组)(只看是几行的话就这样)
# 查看数组的维度
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a.ndim, end="\n\n") # ————> 2(2维数组)3、numpy数组计算
1)最基础的一维向量的加减乘除
# 简单加减乘除
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print(a + b) # [1+4, 2+5, 3+6] = [5, 7, 9]
print(a - b) # [1-4, 2-5, 3-6] = [-3, -3, -3]
print(a * b) # [1*4, 2*5, 3*6] = [4, 10, 18]
print(a / b) # [1/4, 2/5, 3/6] = [0.25, 0.4, 0.5]注意:如果是跟一个数字进行计算,就会把每一个元素都跟这个数计算
print(a + 1) # [1+1, 2+1, 3+1] = [2, 3, 4]
print(a - 1) # [1-1, 2-1, 3-1] = [0, 1, 2]
print(a * 2) # [1*2, 2*2, 3*2] = [2, 4, 6]
print(a / 2) # [1/2, 2/2, 3/2] = [0.5, 1.0, 1.5]
2)向量的点乘
# 点乘
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print(np.dot(a, b)) # [1*4 + 2*5 + 3*6] = 323)矩阵的乘法
# 矩阵乘法运算
A = np.array([[1, 2],[3, 4]])B = np.array([[5, 6],[7, 8]])
#【第一种方法】:A @ B
print(A @ B)
"""
[[1*5 + 2*7, 1*6 + 2*8], [[19, 22],[3*5 + 4*7, 3*6 + 4*8]] ————> [43, 50]]
"""# 【第二种方法】:np.matmul()
print(np.matmul(A, B))这里有一点要注意,因为同行同列的N维向量进行点乘时,也是得到一个同行同列的N维向量,所以用【np.dot(A,B)】结果是等于上面两种矩阵相乘的结果的,但是这不代表【点乘】=【矩阵相乘】,因为矩阵相乘严格要求【形状相同(同行同列)】的两个矩阵相乘。
那么假设两个一维向量,用np.dot() 会执行点乘,而 A @ B 和 np.matmul() 会因为形状不兼容而抛出错误。
np.dot()可以用于执行两个数组的点积或矩阵乘法,具体取决于输入数组的形状。
print(np.dot(A, B))
"""
[[1*5 + 2*7, 1*6 + 2*8], [[19, 22], [3*5 + 4*7, 3*6 + 4*8]] ————> [43, 50]]
"""4)求平方
# 求平方
a = np.array([1, 2, 3])
print(a ** 2) # [1*1, 2*2, 3*3] = [1, 4, 9]
print(np.square(a)) # [1*1, 2*2, 3*3] = [1, 4, 9]5)求指数、对数的运算
# 指数、对数运算
a = np.array([1, 2, 3])
print(np.pow(a, 3)) # [1^3, 2^3, 3^3] = [1, 8, 27]
print(np.log(a)) # [log(1), log(2), log(3)] = [0, 0.6931471805599453, 1.0986122886681098]6)求sin、cos值
# 求sin、cos
a = np.array([1, 2, 3])
print(np.sin(a)) # [sin(1), sin(2), sin(3)]
print(np.cos(a)) # [cos(1), cos(2), cos(3)]7)统计一个数组的最大、最小、平均、中位数、总和、方差、标准差......
a = np.array([1, 2, 3])# 返回数组最小元素
print(np.min(a)) # 1# 返回数组最大元素
print(np.max(a)) # 3# 返回数组平均值
print(np.mean(a)) # 2.0# 返回数组中位数
print(np.median(a)) # 2.0# 返回数组最小数的位置
print(np.argmin(a)) # 0# 返回数组最大数的位置
print(np.argmax(a)) # 2# 返回数组总和
print(np.sum(a)) # 6# 返回数组标准差
print(np.std(a)) # 1.0# 返回数组方差
print(np.var(a)) # 1.04、numpy数组索引
【一】序列切片式索引
这个跟数据容器list、tuple......这些的序列是一样的,都是一样的规则切片,不同的在二维以上的切片形式不同
1维数组的切片:一样的
————> [ 起始位 : 末尾位 : 步长 ],起始位默认0,末尾位默认最后,步长默认1
2维以上数组:
基本是就是 [ 行的切片 , 列的切片 ]
【行】如果不是切片形式就代表固定是【某一行取序列】
【列】如果没有切片形式就代表固定某一行或所有行都只取【这一列这个数】
【固定取一行】
————> [ 一个数 ],比如a[ 0 ],就是取第0行
————> 或者[ a, : ],比如a[ 0, : ],就是取第0行的从头到尾
【固定取一列】
————> [ a, b ],就是取第a行的第b列
————> [ : , b ],就是取每一行的第b列
【取某一行的部分】
————> [ a, b:c ],比如a[ 1, 1:5 ],就是取第1行的[第1列 ~ 第(5-1)列]
【取整个数组】
————> [ : , : ]
【带上步长的话跟其他序列一样】
————> [ a, b:c:d ],比如a[ 1, ::3 ],就是取第1行的[从头 ~ 到尾],每3个取一个数
————>步长是负数就是反着取,比如a[ 1, ::-2 ],就是取第1行的[从尾 ~ 到头],倒着每2个取一个数
# 一维数组的切片序列是一样的
a = np.array([1, 2, 3, 4, 5])print(a[1:4]) # [2, 3, 4]
print(a[4::-1]) # [5, 4, 3, 2, 1]
print(a[::2]) # [1, 3, 5]# 如果是二维以上的,就需要把起始位跟末尾位带上,而且切片形式和不切片形式都有不同的含义
# 基本是就是 [ 行的切片 , 列的切片 ]
#【行】如果不是切片形式就代表固定是【某一行取序列】
#【列】如果没有切片形式就代表固定某一行或所有行都只取【这一列这个数】
a = np.array([[1, 2, 3], [4, 5, 6]])print(a[0]) # 如果是直接取一行,就直接1个数字代表第几行就行 ————> [1, 2, 3]
print(a[0, :]) # 这样也是直接取一行,只不过是取第[0]行,从第[0]列到第[尾]列,[1, 2, 3]print(a[0, 1]) # 2,取第[0]行,第[1]列的数
print(a[:, 1]) # [2, 5],每一行的第[1]列的数
print(a[:, :]) # [[1, 2, 3], [4, 5, 6]],从第[1]行开始的[从头到尾],到第[2]行开始的[从头到尾]print(a[1, 0:2]) # [4, 5],从第[1]行开始,分割[第0列~第2列]print(a[1, ::-1]) # [6, 5, 4],从第[1]行开始,分割[第尾列~第0列],步长为-1倒着1个1个取【二】花式索引
切片索引可以获取【一段范围的数】或【一段范围的某1列、某1行...的数】,是有一定规律的
比如“2维数组的第2到第3行的数”、“二维数组的每一行的第3列的数”、“2维数组第1行的第2到第4列的数”、“2维数组的每一行从后往前每隔2个取一个数”.......
但是普通花式索引可以任意获取【已知下标索引的某几个数】,可以我们自定义的、没有规律
比如“2维数组的第一行的第2、第0、第10列”、“1维数组的第1个、第3个数”、“2维数组的第3行、第0行”......
【一维数组的花式索引】
# 要取已知索引位置的【那几个元素】,就在索引传入一个列表参数[a, b, c, ...]
a = np.array([0,1,2,3,4,5,6,7,8,9])
print(a[[1, 5, 8]]) # 取到原数组的下标1、5、8的元素,装入新数组:[1 5 8]【二维数组的花式索引】
【二维数组选择多行】
# 要取的已知索引位置的【那几行元素】,就在索引传入一个列表参数[a, b, c, ...]
a = np.array([[0,1,2,3,4],[10,11,12,13,14,],[20,21,22,23,24,],[30,31,32,33,34,]])
print(a[[1, 3, 2]])
# 取到原数组的下标1、3、2的行,按顺序装入新数组:
# [[10 11 12 13 14] ——> 第[1]行
# [30 31 32 33 34] ——> 第[3]行
# 20 21 22 23 24]] ——> 第[2]行【二维数组选多列】(结合切片索引)
# 切片索引可以获取【一段范围的数】或【一段范围的某1列、某1行...的数】,是有一定规律的
# 但是普通花式索引可以任意获取【已知下标索引的某几个数】,可以我们自定义没有规律
# 那么二者加起来,就无敌了
# 比如一个2维数组,只要每一行的第[2]列、第[0]列的数、第[1]列的数
a = np.array([[0,1,2,3,4],[10,11,12,13,14],[20,21,22,23,24]])
colum = [2, 0, 1]
print(a[:, colum])
# [[2 0 1]
# [12 10 11] ——> 每一行,第[2]列、第[0]列、第[1]列的数
# [22 20 21]]【三】布尔索引
顾名思义,就是根据【条件】来取出符合条件的子序列
a = np.array([[0,1,2,3,4],[10,11,12,13,14],[20,21,22,23,24]])# 取到原数组中大于10的数
print(a[a > 10]) # ————> [11 12 13 14 21 22 23 24]但是需要注意的是:
布尔索引的条件要用( )包起来,当只有一个条件时可以省略( ),当有多个条件时就要用( ),要么就用变量写好条件,再放入索引里
a = np.array([[0,1,2,3,4],[10,11,12,13,14],[20,21,22,23,24]])# 取到原数组中大于10且小于22的数
print(a[(a > 10) & (a < 22)]) # ————> [11 12 13 14 21]
# 或者
up = (a > 10)
low = (a < 22)
print(a[up & low]) # ————> [11 12 13 14 21]5、numpy数组变形、转置
【变形】
就是一维数组可以变二维、二维变三维、三维变四维......也可以从多维变低维,比如三维变一维数组
这些的前提条件都是不管几维数组,总的元素一定要互相一样,比如24个元素的一维数组,不管变成二维、三维...多少维,只能总数是24个,3行8列的二维数组可以(3*8=24),2行5列的二维数组就不行(2*5 = 20 < 24)
[1维数组变2维数组]
# 创建一个8个数的1维数组,但是马上用reshape变成2行4列的二维数组
a = np.arange(8).reshape(2, 4)
print(a, end="\n\n") # [0 1 2 3 4 5 6 7] ————> [[0 1 2 3], [4 5 6 7]][1维数组变3维数组]
# 创建一个8个数的1维数组,但是马上用reshape变成2块3行3列的三维数组
a = np.arange(24).reshape(2, 3, 4)
print(a, end="\n\n")
# [0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
# ————> [[[ 0 1 2 3] # 1块
# [ 4 5 6 7]
# [ 8 9 10 11]]
#
# [[12 13 14 15] # 2块
# [16 17 18 19]
# [20 21 22 23]]][2维数组变2维数组]
# 2维数组变形2维数组
# 只要reshape那边数字总数能对的上就行,(2维)2行3列 => (2维)3行2列
a = np.array([[1,3,4],[4,6,5]]).reshape(3, 2)
print(a, end="\n\n")
# [[1 3]
# [4 6]
# [4 5]][2维数组变3维数组]
# 只要reshape那边数字总数能对的上就行,(2维)2行3列 => (3维)2块、每一块2行3列
a = np.array([[1,3,4],[4,6,5],[2,2,2],[0,0,1]]).reshape(2, 2, 3)
print(a, end="\n\n")
# [[[1 3 4]
# [4 6 5]] # 1块
#
# [[2 2 2]
# [0 0 1]]] # 2块[2维数组变1维数组展开]
# 只要reshape那边数字总数能对的上就行,(2维)3行2列 => (1维)1行6个
a = np.array([[1,3],[4,6],[3,5]]).reshape(1, 6)
print(a, end="\n\n")
# [[1 3 4 6 3 5]][错误示范]:变形的数组的元素总数跟原数组的不一样
# a = np.arange(8).reshape(4, 3)
# print(a, end="\n\n") # 报错,因为变形后的总数一定要对上,8个元素对不上4*3=12个元素[将多维数组展开成1维数组常用三方法]
虽然【.reshape(1, ?)】可以把多维数组展开成一维数组,但是有的时候我们并不知道多维数组里有多少元素,第2个参数就不知道写多少;那么常用的还有三种方法:【.reshape(-1)】、【.ravel( )】、【.flatten( )】
;
【.reshape(-1)】:是最常用的,因为它可以自动计算出需要多少列才能包含所有元素。
# 用reshape(-1)也可以把多维变成1维 a = np.array([[1,3],[4,6],[3,5]]) print(a.reshape(-1), end="\n\n") # [1 3 4 6 3 5]【.ravel( )】
# 用ravel()也可以把多维变成1维 a = np.array([[1,3],[4,6],[3,5]]) print(a.ravel(), end="\n\n") # [1 3 4 6 3 5]【.flatten( )】
# 用flatten()也可以把多维变成1维 a = np.array([[1,3],[4,6],[3,5]]) print(a.flatten(), end="\n\n") # [1 3 4 6 3 5]
(另外)
很多地方reshape里的参数是写成元组tulpe形式的,但是其实直接写数字也是可以的

【转置】
就是线性代数里行列式的转置,没学过线性代数的可以去了解一下,大概就是 [行元素变列元素、列元素边行元素]
一种写法(常用):【数组.T】
a = np.array([[1,3,4],[4,6,5],[3,5,1]])
print(a.T) # [[1 4 3]# [3 6 5]# [4 5 1]]另一种写法:【数组.transpose( )】,transpoe针对于多维数组的转置
【数组.transpose( )】对于二维数组的转置和【数组.T】是一样的
# 用transpose()也可以转置
a = np.array([[1,3,4],[4,6,5],[3,5,1]])
print(a.transpose()) # [[1 4 3]# [3 6 5]# [4 5 1]]但对于多维数组可以指定更细致的转置,比如3维数组,可以指定x、y、z轴之间的互换
比如对于三维数组转置,需要将一个(x, y, z)的元组作为参数传进【数组.transpose( )】,其中默认0代表x、1代表y、2代表z,那么(0, 1, 2)代表(x, y, z),(2, 1, 0)代表(z, y, x)
那么假设要将一个三维的数组的x轴和z轴互相转置一下,比如例子:
[ [ [ 0 1 2] [ 3 4 5] ] , [ [ 6 7 8] [ 9 10 11] ] ]
————> 变成 [ [ [ 0 6] [ 3 9] ], [ [ 1 7] [ 4 10] ], [ [ 2 8] [ 5 11] ] ]

那么代码
# 创建一个三维数组
array_3d = np.array([[[ 0, 1, 2],[ 3, 4, 5]],[[ 6, 7, 8],[ 9, 10, 11]]])# 使用 transpose 函数重新排列轴,将第一个轴和第三个轴交换:(0x,1y,2z)————>(2z,1y,0x)
print(array_3d.transpose((2, 1, 0)))#[[[ 0 1 2] [[[ 0 6]# [ 3 4 5]], [ 3 9]],# ————————># [[ 6 7 8] [[ 1 7]# [ 9 10 11]]] [ 4 10]],## [[ 2 8]# [ 5 11]]]6、numpy数组合并
对于1维数组
直接用【np.concatenate((数组1, 数组2...))】就行
a = np.array([1,3,4])
b = np.array([4,6,5])
c = np.array([7,8,9])
print(np.concatenate((a, b, c))) # [1 3 4 4 6 5 7 8 9]对于N维数组
【竖向N个数组合并】
1)用【np.vstack((数组1, 数组2...))】
# 用vstack()合并: 纵向合并 a = np.array([[1,3,4],[4,6,5]]) b = np.array([[2,3,4],[4,6,5]]) print(np.vstack((a, b))) # [[1 3 4]# [4 6 5]# [2 3 4]# [4 6 5]]2)用【np.concatenate((数组1, 数组2...), axis=0)】
# 用concatenate()合并 a = np.array([[1,3,4],[4,6,5]]) b = np.array([[2,3,4],[4,6,5]])# axis=0表示纵向合并 print(np.concatenate((a, b), axis=0)) # [[1 3 4]# [4 6 5]# [2 3 4]# [4 6 5]]
【横向N个数组合并】
1)用【np.hstack((数组1, 数组2...))】
# 用hstack()合并: 横向合并 a = np.array([[1,3,4],[4,6,5]]) b = np.array([[2,3,4],[4,6,5]]) print(np.hstack((a, b))) # [[1 3 4 2 3 4]# [4 6 5 4 6 5]]2)用【np.concatenate((数组1, 数组2...), axis=1)】
# 用concatenate()合并 a = np.array([[1,3,4],[4,6,5]]) b = np.array([[2,3,4],[4,6,5]])# axis=1表示横向合并 print(np.concatenate((a, b), axis=1)) # [[1 3 4 2 3 4]# [4 6 5 4 6 5]]
【合并后转置】
用【np.column_stack((数组1, 数组2))】,类似将两个数组合并后,再【转置】
# 用column_stack()合并 a = np.array([1,3,4]) b = np.array([4,6,5]) print(np.column_stack((a, b))) # [[1 4]# [3 6]# [4 5]]
【拓展】
a = np.array([1,1,1])
print(a.T) # [1 1 1],一行的一维序列是不能直接像线性代数那样,被转置成一列的矩阵的
# 但是用newaxis()可以增加维度,在索引第1位就是在行上增加一个维度
print(a[np.newaxis, :])
# 在索引第2位就是在列上增加一个维度,那么这时就相当于把增加一“空”列,就相当于转置了,只不是是二维的数组了
print(a[: , np.newaxis])7、numpy数组分割
【均等分割】:【np.split(数组, 分几份, axis=维度)】
(一维数组就不用带上【axis=维度】这个参数)
a = np.array([1,3,4])
print(np.split(a, 3)) # [array([1]), array([3]), array([4])]
# print(np.split(a, 2)) ————> 报错,因为均等切割,3个元素不能均等分割成2块a = np.array([[1,3,4],[4,6,5],[3,5,1]])
# 一样,axios=0表示纵向分割,均等分割成3块
print(np.split(a, 3, axis=0))
# [array([[1, 3, 4]]), array([[4, 6, 5]]), array([[3, 5, 1]])]# 一样,axios=1表示横向分割,均等分割成3块
print(np.split(a, 3, axis=1))
# [array([[1],
# [4],
# [3]]),
# array([[3],
# [6],
# [5]]),
# array([[4],
# [5],
# [1]])]【不均等分割】:【np.array_split(数组, 分几份, axis=维度)】
# array_split()与split()的区别是,array_split()可以不等分,split()必须均分
a = np.array([[1,3,4],[4,6,5],[3,5,1]])
print(np.array_split(a, 2, axis=0))
# [array([[1, 3, 4],
# [4, 6, 5]]),
# array([[3, 5, 1]])]
print(np.array_split(a, 2, axis=1))
# [array([[1, 3],
# [4, 6],
# [3, 5]]),
# array([[4],
# [5],
# [1]])]跟合并一样,分割也有【横向分割】【竖向分割】
【横向分割】:【np.hsplit(数组, 分几份)】
# 用hsplit()横向分割
a = np.array([[1,3,4],[4,6,5],[3,5,1]])
print(np.hsplit(a, 2))
# [array([[1, 3, 4],
# [4, 6, 5]]),
# array([[3, 5, 1]])]
【竖向分割】 :【np.vsplit(数组, 分几份)】
# 用vsplit()纵向分割
a = np.array([[1,3,4],[4,6,5],[3,5,1]])
print(np.vsplit(a, 2))
# [array([[1, 3],
# [4, 6],
# [3, 5]]),
# array([[4],
# [5],
# [1]])]8、numpy的copy方法
虽然【数组2 = 数组1】可以直接把数组1的值给到数组2,但是他们是一直关联着的,当数组1发生改变的时候,数组2也会被跟着改变
那么只有【数组.copy()】才不会让数组轻易改变
a = np.array([1, 2, 3, 4, 5])
b = a
c = a.copy()# 然后改变a数组里某一个值
a[0] = 100
print(a) # [100 2 3 4 5]
print(b) # [100 2 3 4 5],此时b也跟着关联被改变
print(c) # [ 1 2 3 4 5],但是c因为用numpy的copy函数,所以不变三、一些numpy的真实应用场景
图像处理:可以把一个灰度图像当成一个二维数组


每个数值代表图像的亮度值

那么彩色的图像,就可以用一个三位数组表示,第三维用来表示红绿蓝三种颜色

先获取图像

用numpy的array将图像变成三维数组(行、列、有几个颜色)

访问某个元素颜色点‘

提取所有红色的元素像素点

按比例将两个图片混合

......等等

暂时常用需要了解的就这么多,以后有需要用到别的知识点我再更新.......
相关文章:
Python数据分析——Numpy
纯个人python的一个小回忆笔记,当时假期花两天学的python,确实时隔几个月快忘光了,为了应付作业才回忆起来,不涉及太多基础,适用于有一定编程基础的参考回忆。 这一篇笔记来源于下面哔哩哔哩up主的视频: 一…...

JMeter快速入门示例
JMeter是一款开源的性能测试工具,常用于对Web服务和接口进行性能测试。 下载安装 官方下载网址: https://jmeter.apache.org/download_jmeter.cgi也可以到如下地址下载:https://download.csdn.net/download/oscar999/89910834 这里下载Wi…...
【333基于Java Web的考编论坛网站的设计与实现
毕 业 设 计(论 文) 考编论坛网站设计与实现 摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计…...

计算机网络关键名词中英对照
物理层 IMP - Interface Message Processor - 接口信息处理机 MODEM - Modulator-Demodulator - 调制解调器 LAN - Local Area Network - 局域网 FDM - Frequency Division Multiplexing - 频分复用 TDM - Time Division Multiplexing - 时分复用 STDM - Statistical Time…...

二叉树的学习
除了根节点外的其他节点只有一个直接前驱,有多个直接前驱的逻辑结构叫做图 任何一个树都可以看成是一个根节点和若干个不相交的子树构成的; 构建思维导图时使用树形结构 题目中给出AB是堂兄弟节点说明他们处在同一层 描述两节点之间的路径是从上到下的,同层没有路径,一条边记录…...
免费开源的医疗信息提取系统:提升超声波影像的诊断价值
一、系统概述 思通数科推出的医疗信息精准抽取系统,致力于解决当前医疗行业面临的信息碎片化和数据管理难题。传统医疗过程中,超声波影像数据与诊断报告之间的脱节,往往导致信息无法有效整合,影响医生的诊断效率与准确性。我们的…...

Bash 中的 ${} 和 $() 有什么区别 ?
Bash (Bourne-Again SHell) 是一种流行的 Unix SHell,用于编写脚本。如果您使用 Bash 脚本,那么了解不同的语法元素对于提高脚本的效率和避免错误是很重要的。 在本文中,我们将解释 Bash 中 ${} 和 $() 语法之间的区别,并向您展示…...

SPSS、R语言因子分析FA、主成分分析PCA对居民消费结构数据可视化分析
全文链接:https://tecdat.cn/?p37952 分析师:Ting Mei 在经济发展的大背景下,居民消费结构至关重要。本文围绕居民消费结构展开深入研究,运用 SPSS25.0 和 R 语言,以因子分析法和主成分分析法对东北三省居民消费价格指…...

高级SQL技巧掌握
高级SQL技巧掌握 在数据驱动的时代,掌握SQL不仅仅是为了解决具体问题,它更像是一把钥匙,帮助你打开数据分析的大门。你准备好提升你的SQL技能了吗?在这篇文章中,我们将一起探索十个必备的高级SQL查询技巧,这些技巧将帮助你更有效率地进行数据处理与分析。 1. 常见表表达…...

数组实例之三子棋的实现(C语言)
目录 前言 一、三子棋实现的逻辑 二、三子棋的实现 2.1文件的创建添加 2.2 test文件基本逻辑 2.2.1菜单的实现 2.2.2菜单的选择 2.2.3game函数棋盘的实现 2.3game.c文件的编写 2.3.1初始化函数的模块 2.3.2棋盘打印的模块 2.3.3实现棋盘界面的打印 2.3.4实现玩家下…...

【Linux驱动开发】设备树节点驱动开发入门
【Linux驱动开发】设备树节点驱动开发入门 文章目录 设备树文件设备树文件驱动开发附录:嵌入式Linux驱动开发基本步骤开发环境驱动文件编译驱动安装驱动自动创建设备节点文件 驱动开发驱动设备号地址映射,虚拟内存和硬件内存地址字符驱动旧字符驱动新字…...

C++——string的模拟实现(下)
目录 成员函数 3.4 修改操作 (3)insert()函数 (4)pop_back()函数 (5)erase()函数 (6)swap()函数 3.5 查找操作 (1)find()函数 (2)substr()函数 3.6 重载函数 (1)operator赋值函数 (2)其他比较函数 (3)流插入和流提取 完整代码 结束语 第一篇链接:C——…...

面试 Java 基础八股文十问十答第二十九期
面试 Java 基础八股文十问十答第二十九期 作者:程序员小白条,个人博客 相信看了本文后,对你的面试是有一定帮助的!关注专栏后就能收到持续更新! ⭐点赞⭐收藏⭐不迷路!⭐ 1)类加载过程 类加载…...

454.四数相加||
题目: 454. 四数相加 II - 力扣(LeetCode) 思路: 考虑到时间复杂度问题,本题最重要的是要将四个数组划分成两个部分,每个部分(n^2)的时间复杂度,选取数据结构时,考虑到既要存储元素(key),又要有元素次数…...

禅道源码部署
文章目录 禅道部署1.环境部署安装httpd和mariadb安装php 2.安装禅道首先进行httpd服务的配置安装禅道 禅道部署 1.环境部署 安装lamp环境 组件版本httpdyum安装mariadbyum安装phpphp-7.4.33 选择一个php版本就行,我们这里选择的是7.4.33 安装httpd和mariadb [r…...

️ Vulnhuntr:利用大型语言模型(LLM)进行零样本漏洞发现的工具
在网络安全领域,漏洞的发现和修复是保护系统安全的关键。今天,我要向大家介绍一款创新的工具——Vulnhuntr,这是一款利用大型语言模型(LLM)进行零样本漏洞发现的工具,能够自动分析代码,检测远程…...

【Android】多渠道打包配置
目录 简介打包配置签名配置渠道配置配置打包出来的App名称正式包与测试包配置 打包方式开发工具打包命令行打包 优缺点 简介 多渠道打包 是指在打包一个 Android 应用时,一次编译生成多个 APK 文件,每个 APK 文件针对一个特定的渠道。不同的渠道可能代表…...

Spring Boot Configuration和AutoConfiguration加载逻辑和加载顺序调整
在spring中, AutoConfiguration也是一个种Configuration,只是AutoConfiguration是不能使用proxy的。 而且spring对于两者的加载顺序也不是一视同仁,是有顺序的。spring会先加载@SpringBootApplication可达的且标注了@Configuration的类,这个过程会将@AutoConfiguration标注…...

点餐系统需求分析说明书(软件工程分析报告JAVA)
目录 1 引言 4 1.1 编写目的 4 1.2 项目背景 4 1.3 定义 4 1.4 预期的读者 5 1.5 参考资料 5 2 任务概述 5 2.1 目标 5 2.2 运行环境 5 2.3 条件与限制 6 3 数据描述 6 3.1 静态数据 6 3.2 动态数据 6 3.3 数据库介绍 6 3.4 对象模型 6 3.5 数据采集 7 4 动态模型 7 4.1 脚本 …...

Python条形图 | 指标(特征)重要性图的绘制
在数据科学和机器学习的工作流程中,特征选择是一个关键步骤。通过评估每个特征对模型预测能力的影响,我们可以选择最有意义的特征(指标),从而提高模型的性能并减少过拟合。本文将介绍如何使用 Python 的 Seaborn 和 Ma…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...
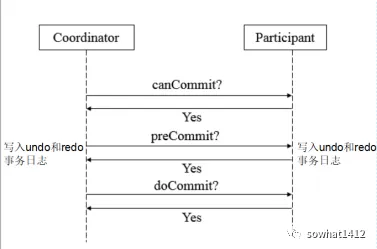
解析两阶段提交与三阶段提交的核心差异及MySQL实现方案
引言 在分布式系统的事务处理中,如何保障跨节点数据操作的一致性始终是核心挑战。经典的两阶段提交协议(2PC)通过准备阶段与提交阶段的协调机制,以同步决策模式确保事务原子性。其改进版本三阶段提交协议(3PC…...