NumPy包(下) python笔记扩展
9.迭代数组
nditer 是 NumPy 中的一个强大的迭代器对象,用于高效地遍历多维数组。nditer 提供了多种选项和控制参数,使得数组的迭代更加灵活和高效。
控制参数
nditer 提供了多种控制参数,用于控制迭代的行为。
1.order 参数
order 参数用于指定数组的遍历顺序。默认情况下,nditer 按照 C 风格(行优先)遍历数组。
-
C 风格(行优先): order='C'
-
Fortran 风格(列优先): order='F'
# 创建一个二维数组 arr = np.array([[1, 2, 3], [4, 5, 6]]) # 使用 C 风格遍历数组 for x in np.nditer(arr, order='C'):print(x) # 输出: # 1 # 2 # 3 # 4 # 5 # 6 # 使用 Fortran 风格遍历数组 for x in np.nditer(arr, order='F'):print(x) # 输出: # 1 # 4 # 2 # 5 # 3 # 6
2.flags 参数
flags 参数用于指定迭代器的额外行为。
-
multi_index: 返回每个元素的多维索引。
-
external_loop: 返回一维数组而不是单个元素,减少函数调用的次数,从而提高性能。
# 创建一个三维数组arr = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
# 使用 nditer 遍历数组并获取多维索引it = np.nditer(arr, flags=['multi_index'])for x in it:print(f"Element: {x}, Index: {it.multi_index}")
# 输出:
# Element: 1, Index: (0, 0, 0)
# Element: 2, Index: (0, 0, 1)
# Element: 3, Index: (0, 1, 0)
# Element: 4, Index: (0, 1, 1)
# Element: 5, Index: (1, 0, 0)
# Element: 6, Index: (1, 0, 1)
# Element: 7, Index: (1, 1, 0)
# Element: 8, Index: (1, 1, 1)
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 使用外部循环遍历数组
for x in np.nditer(arr, flags=['external_loop'], order='F'):print(x)
# 输出:
# [1 4]
# [2 5]
# [3 6]
3.op_flags 参数
op_flags 参数用于指定操作数的行为。
-
readonly: 只读操作数。
-
readwrite: 读写操作数。
-
writeonly: 只写操作数。
# 创建一个二维数组 arr = np.array([[1, 2, 3], [4, 5, 6]]) # 使用读写操作数遍历数组 for x in np.nditer(arr, op_flags=['readwrite']):x[...] = 2 * x print(arr) # 输出: # [[ 2 4 6] # [ 8 10 12]]
10.数组操作
10.1 数组变维
| 函数名称 | 函数介绍 |
|---|---|
| reshape | 在不改变数组元素的条件下,修改数组的形状 |
| flat | 返回是一个迭代器,可以用 for 循环遍历其中的每一个元素 |
| flatten | 以一维数组的形式返回一份数组的副本,对副本的操作不会影响到原数组 |
| ravel | 返回一个连续的扁平数组(即展开的一维数组),与 flatten不同,它返回的是数组视图(修改视图会影响原数组) |
10.1.1 flat
返回一个一维迭代器,用于遍历数组中的所有元素。无论数组的维度如何,ndarray.flat属性都会将数组视为一个扁平化的一维数组,按行优先的顺序遍历所有元素。
语法:
ndarray.flat
案例:
import numpy as np
def flat_test():array_one = np.arange(4).reshape(2,2)print("原数组元素:")for i in array_one:print(i,end=" ")print()print("使用flat属性,遍历数组:")for i in array_one.flat:print(i,end=" ")
10.1.2 flatten()
用于将多维数组转换为一维数组。flatten() 返回的是原数组的一个拷贝,因此对返回的数组进行修改不会影响原数组。
语法:
ndarray.flatten(order='C')
参数
order: 指定数组的展开顺序。
-
'C':按行优先顺序展开(默认)。 -
'F':按列优先顺序展开。 -
'A':如果原数组是 Fortran 连续的,则按列优先顺序展开;否则按行优先顺序展开。 -
'K':按元素在内存中的顺序展开。
案例:
import numpy as np # 创建一个二维数组 arr = np.array([[1, 2, 3], [4, 5, 6]]) # 使用 flatten 方法按行优先顺序展开 flat_arr = arr.flatten(order='C') print(flat_arr) # 输出: # [1 2 3 4 5 6]
1.3 ravel()
用于将多维数组转换为一维数组。与 flatten() 不同,ravel() 返回的是原数组的一个视图(view),而不是拷贝。因此,对返回的数组进行修改会影响原数组。
语法:
ndarray.ravel()
参数
order: 指定数组的展开顺序。
-
'C':按行优先顺序展开(默认)。 -
'F':按列优先顺序展开。 -
'A':如果原数组是 Fortran 连续的,则按列优先顺序展开;否则按行优先顺序展开。 -
'K':按元素在内存中的顺序展开。
案例:
import numpy as np # 创建一个二维数组 arr = np.array([[1, 2, 3], [4, 5, 6]]) # 使用 ravel 方法按行优先顺序展开 ravel_arr = arr.ravel() print(ravel_arr) # 输出: # [1 2 3 4 5 6] ravel_arr[-1] = 7 print(arr) # 输出: # [[1 2 3] # [4 5 7]]
10.2 数组转置
| 函数名称 | 说明 |
|---|---|
| transpose | 将数组的维度值进行对换,比如二维数组维度(2,4)使用该方法后为(4,2) |
| ndarray.T | 与 transpose 方法相同 |
案例:
import numpy as np
def transpose_test():array_one = np.arange(12).reshape(3, 4)print("原数组:")print(array_one)print("使用transpose()函数后的数组:")print(np.transpose(array_one))
def T_test():array_one = np.arange(12).reshape(3, 4)print("原数组:")print(array_one)print("数组转置:")print(array_one.T)
10.3 修改数组维度
多维数组(也称为 ndarray)的维度(或轴)是从外向内编号的。这意味着最外层的维度是轴0,然后是轴1,依此类推。
| 函数名称 | 参数 | 说明 |
|---|---|---|
| expand_dims(arr, axis) | arr:输入数组 axis:新轴插入的位置 | 在指定位置插入新的轴(相对于结果数组而言),从而扩展数组的维度 |
| squeeze(arr, axis) | arr:输入数的组 axis:取值为整数或整数元组,用于指定需要删除的维度所在轴,指定的维度值必须为 1 ,否则将会报错,若为 None,则删除数组维度中所有为 1 的项 | 删除数组中维度为 1 的项 |
案例:
import numpy as np
def expand_dims_test():array_one = np.arange(4).reshape(2,2)print('原数组:\n', array_one)print('原数组维度情况:\n', array_one.shape)# 在 1 轴处插入新的轴array_two = np.expand_dims(array_one, axis=1)print('在 1 轴处插入新的轴后的数组:\n', array_two)print('在 1 轴处插入新的轴后的数组维度情况:\n', array_two.shape)
def squeeze_test():array_one = np.arange(6).reshape(2,1,3)print('原数组:\n', array_one)print('原数组维度情况:\n', array_one.shape)# 删除array_two = np.squeeze(array_one,1)print('从数组的形状中删除一维项后的数组:\n', array_two)print('从数组的形状中删除一维项后的数组维度情况:\n', array_two.shape)
10.4 连接数组
| 函数名称 | 参数 | 说明 |
|---|---|---|
| hstack(tup) | tup:可以是元组,列表,或者numpy数组,返回结果为numpy的数组 | 按水平顺序堆叠序列中数组(列方向) |
| vstack(tup) | tup:可以是元组,列表,或者numpy数组,返回结果为numpy的数组 | 按垂直方向堆叠序列中数组(行方向) |
hstack函数要求堆叠的数组在垂直方向(行)上具有相同的形状。如果行数不一致,hstack() 将无法执行,并会抛出 ValueError 异常。
hstack() 要求堆叠的数组在垂直方向(行)上具有相同的形状。如果列数不一致,将无法执行堆叠操作。
vstack() 和 hstack() 要求堆叠的数组在某些维度上具有相同的形状。如果维度不一致,将无法执行堆叠操作。
案例:
hstack:
import numpy as np # 创建两个形状不同的数组 arr1 = np.array([[1, 2], [3, 4]]) arr2 = np.array([[5], [6]]) print(arr1.shape) # (2, 2) print(arr2.shape) # (2, 1) # 使用 hstack 水平堆叠数组 result = np.hstack((arr1, arr2)) print(result) # 输出: # [[1 2 5] # [3 4 6]]
# 创建两个形状不同的数组 arr1 = np.array([[1, 2], [3, 4]]) arr2 = np.array([[5], [6], [7]]) print(arr1.shape) # (2, 2) print(arr2.shape) # (3, 1) # 使用 hstack 水平堆叠数组 result = np.hstack((arr1, arr2)) print(result) # ValueError: all the input array dimensions except for the concatenation axis must match exactly # 第一个数组在第0维有2个元素,而第二个数组在第0维有3个元素,因此无法直接连接。
vstack:
# 创建两个一维数组 arr1 = np.array([1, 2, 3]) arr2 = np.array([4, 5, 6]) # 使用 vstack 垂直堆叠数组 result = np.vstack((arr1, arr2)) print(result) # 输出: # [[1 2 3] # [4 5 6]]
# 创建两个形状不同的数组 arr1 = np.array([[1, 2], [3, 4]]) arr2 = np.array([[5, 6, 7], [8, 9, 10]]) # 使用 vstack 垂直堆叠数组 result = np.vstack((arr1, arr2)) print(result) # ValueError: all the input array dimensions except for the concatenation axis must match exactly # 第一个数组在第1维有2个元素,而第二个数组在第1维有3个元素,因此无法直接连接。
10.5 分割数组
| 函数名称 | 参数 | 说明 |
|---|---|---|
| hsplit(ary, indices_or_sections) | ary:原数组 indices_or_sections:按列分割的索引位置 | 将一个数组水平分割为多个子数组(按列) |
| vsplit(ary, indices_or_sections) | ary:原数组 indices_or_sections:按列分割的索引位置 | 将一个数组垂直分割为多个子数组(按行) |
案例:
import numpy as np
'''hsplit 函数:1、将一个数组水平分割为多个子数组(按列)2、ary:原数组3、indices_or_sections:按列分割的索引位置
'''
# 创建一个二维数组
arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
# 使用 np.hsplit 将数组分割成三个子数组
# 分割点在索引1和3处,这意味着:
# 第一个子数组将包含从第0列到索引1(不包括索引1)的列,即第0列。
# 第二个子数组将包含从索引1(包括索引1)到索引3(不包括索引3)的列,即第1列到第2列。
# 第三个子数组将包含从索引3(包括索引3)到末尾的列,即第3列。
result = np.hsplit(arr, [1, 3])
# 查看结果
print("第一个子数组:\n", result[0]) # 输出包含第0列的子数组
print("第二个子数组:\n", result[1]) # 输出包含第1列和第2列的子数组
print("第三个子数组:\n", result[2]) # 输出包含第3列的子数组
'''vsplit 函数:1、将一个数组垂直分割为多个子数组(按行)2、ary:原数组3、indices_or_sections:按列分割的索引位置
'''
array_one = np.arange(12).reshape(2,6)
print('array_one 原数组:\n', array_one)
array_two = np.vsplit(array_one,[1])
print('vsplit 之后的数组:\n', array_two)
11.数组元素的增删改查
11.1 resize
| 函数名称 | 参数 | 说明 |
|---|---|---|
| resize(a, new_shape) | a:操作的数组 new_shape:返回的数组的形状,如果元素数量不够,重复数组元素来填充新的形状 | 返回指定形状的新数组 |
案例:
import numpy as np
array_one = np.arange(6).reshape(2, 3)
print(array_one)
print('resize 后数组:\n', np.resize(array_one, (3, 4)))
# 输出:
# [[0 1 2 3]
# [4 5 0 1]
# [2 3 4 5]]
最后一行代码将数组形状修改为(3, 4),原数组的元素数量不够,则重复原数组的元素填充。
11.2 append
| 函数名称 | 参数 | 说明 |
|---|---|---|
| append(arr, values, axis=None) | arr:输入的数组 values:向 arr 数组中添加的值,需要和 arr 数组的形状保持一致 axis:默认为 None,返回的是一维数组;当 axis =0 时,追加的值会被添加到行,而列数保持不变,若 axis=1 则与其恰好相反 | 在数组的末尾添加值,返回一个一维数组 |
案例:
'''append(arr, values, axis=None) 函数:1、将元素值添加到数组的末尾,返回一个一维数组2、arr:输入的数组3、values:向 arr 数组中添加的值,需要和 arr 数组的形状保持一致4、axis:默认为 None,返回的是一维数组;当 axis =0 时,追加的值会被添加到行,而列数保持不变,若 axis=1 则与其恰好相反
'''
def append_test():array_one = np.arange(6).reshape(2,3)print('原数组:\n', array_one)array_two = np.append(array_one,[[1,1,1],[1,1,1]],axis=None)print('append 后数组 axis=None:\n', array_two)array_three = np.append(array_one, [[1, 1, 1], [1, 1, 1]], axis=0)print('append 后数组 axis=0:\n', array_three)array_three = np.append(array_one, [[1, 1, 1], [1, 1, 1]], axis=1)print('append 后数组 axis=1:\n', array_three)
11.3 insert
| 函数名称 | 参数 | 说明 |
|---|---|---|
| insert(arr, obj, values, axis) | arr:输入的数组 obj:表示索引值,在该索引值之前插入 values 值 values:要插入的值 axis:默认为 None,返回的是一维数组;当 axis =0 时,追加的值会被添加到行,而列数保持不变,若 axis=1 则与其恰好相反 | 沿规定的轴将元素值插入到指定的元素前 |
案例:
import numpy as np
def insert_test():array_one = np.arange(6).reshape(2,3)print('原数组:\n', array_one)array_two = np.insert(array_one, 1, [6],axis=None)print('insert 后数组 axis=None:\n', array_two)array_three = np.insert(array_one,1, [6], axis=0)print('insert 后数组 axis=0:\n', array_three)array_three = np.insert(array_one, 1, [6,7], axis=1)print('insert 后数组 axis=1:\n', array_three)
如果obj为-1,表示插入在倒数第一个元素之前。
11.4 delete
| 函数名称 | 参数 | 说明 |
|---|---|---|
| delete(arr, obj, axis) | arr:输入的数组 obj:表示索引值,在该索引值之前插入 values 值 axis:默认为 None,返回的是一维数组;当 axis =0 时,删除指定的行,若 axis=1 则与其恰好相反 | 删掉某个轴上的子数组,并返回删除后的新数组 |
案例:
一维数组:
import numpy as np # 创建一个 NumPy 数组 arr = np.array([1, 2, 3, 4, 5, 6]) # 删除索引为 2 和 4 的元素 new_arr = np.delete(arr, [2, 4]) print(new_arr)
二维数组:
import numpy as np
def delete_test():array_one = np.arange(6).reshape(2,3)print('原数组:\n', array_one)array_two = np.delete(array_one,1,axis=None)print('delete 后数组 axis=None:\n', array_two)array_three = np.delete(array_one,1, axis=0)print('delete 后数组 axis=0:\n', array_three)array_three = np.delete(array_one, 1, axis=1)print('delete 后数组 axis=1:\n', array_three)
11.5 argwhere
返回数组中非 0 元素的索引,若是多维数组则返回行、列索引组成的索引坐标
案例:
import numpy as np
'''argwhere(a) 函数:1、返回数组中非 0 元素的索引,若是多维数组则返回行、列索引组成的索引坐标
'''
def argwhere_test():array_one = np.arange(6).reshape(2,3)print('原数组:\n', array_one)print('argwhere 返回非0元素索引:\n', np.argwhere(array_one))print('argwhere 返回所有大于 1 的元素索引:\n', np.argwhere(array_one > 1))
11.6 unique
| 函数名称 | 参数 | 说明 |
|---|---|---|
| unique(ar, return_index=False, return_inverse=False, return_counts=False, axis=None) | ar:输入的数组 return_index:如果为 True,则返回新数组元素在原数组中的位置(索引) return_inverse:如果为 True,则返回原数组元素在新数组中的位置(逆索引) return_counts:如果为 True,则返回去重后的数组元素在原数组中出现的次数 | 删掉某个轴上的子数组,并返回删除后的新数组 |
案例1:返回唯一元素的索引
import numpy as np # 创建一个 NumPy 数组 arr = np.array([1, 2, 2, 3, 4, 4, 5]) unique_elements, indices = np.unique(arr, return_index=True) print(unique_elements) print(indices)
案例2:返回唯一元素及其逆索引
mport numpy as np # 创建一个一维数组 arr = np.array([1, 2, 2, 3, 3, 3, 4, 4, 4, 4]) # 使用 np.unique 查找唯一元素及其逆索引 unique_elements, inverse_indices = np.unique(arr, return_inverse=True) print(unique_elements) # 输出: # [1 2 3 4] print(inverse_indices) # 输出: # [0 1 1 2 2 2 3 3 3 3] # 逆索引数组,表示原始数组中的每个元素在唯一元素数组中的位置。
案例3:返回唯一元素的计数
import numpy as np # 创建一个一维数组 arr = np.array([1, 2, 2, 3, 3, 3, 4, 4, 4, 4]) # 使用 np.unique 查找唯一元素及其计数 unique_elements, counts = np.unique(arr, return_counts=True) print(unique_elements) # 输出: # [1 2 3 4] print(counts) # 输出: # [1 2 3 4]
对于多维数组,unique 函数同样适用。默认情况下,unique 函数会将多维数组展平为一维数组,然后查找唯一元素。
arr = np.array([[1, 2], [2, 3], [1, 2]]) # 查找数组中的唯一元素 unique_elements = np.unique(arr) print(unique_elements)
12.统计函数
12.1 amin() 和 amax()
-
计算数组沿指定轴的最小值与最大值,并以数组形式返回
-
对于二维数组来说,axis=1 表示沿着水平方向,axis=0 表示沿着垂直方向
案例:
'''numpy.amin() 和 numpy.amax() 函数:1、计算数组沿指定轴的最小值与最大值,并以数组形式返回2、对于二维数组来说,axis=1 表示沿着水平方向,axis=0 表示沿着垂直方向
'''
def amin_amax_test():array_one = np.array([[1,23,4,5,6],[1,2,333,4,5]])print('原数组元素:\n', array_one)print('原数组水平方向最小值:\n', np.amin(array_one, axis=1))print('原数组水平方向最大值:\n', np.amax(array_one, axis=1))print('原数组垂直方向最小值:\n', np.amin(array_one, axis=0))print('原数组垂直方向最大值:\n', np.amax(array_one, axis=0))
输出:
原数组元素:[[ 1 23 4 5 6][ 1 2 333 4 5]] 原数组水平方向最小值:[1 1] 原数组水平方向最大值:[ 23 333] 原数组垂直方向最小值:[1 2 4 4 5] 原数组垂直方向最大值:[ 1 23 333 5 6]
按1轴求最小值,表示在最内层轴中(每列中)分别找最小值;按0轴求最小值表示在最外层轴中(所有行中按列)找最小值。求最大值类似。
12.2 ptp()
-
计算数组元素中最值之差值,即最大值 - 最小值
-
对于二维数组来说,axis=1 表示沿着水平方向,axis=0 表示沿着垂直方向
# 创建一个二维数组 arr = np.array([[1, 2, 3], [4, 5, 6]]) # 使用 np.ptp 计算峰峰值 ptp_value = np.ptp(arr) print(ptp_value) # 输出: # 5 # 使用 np.ptp 按行计算峰峰值 ptp_values_row = np.ptp(arr, axis=1) # 使用 np.ptp 按列计算峰峰值 ptp_values_col = np.ptp(arr, axis=0) print(ptp_values_row) # 输出: # [2 2] print(ptp_values_col) # 输出: # [3 3 3]
12.3 median()
用于计算中位数,中位数是指将数组中的数据按从小到大的顺序排列后,位于中间位置的值。如果数组的长度是偶数,则中位数是中间两个数的平均值。
# 创建一个二维数组 arr = np.array([[1, 2, 3], [4, 5, 6]]) # 使用 np.median 计算中位数 median_value = np.median(arr,axis=None) print(median_value) # 输出: # 3.5 # 使用 np.median 按行计算中位数 median_values_row = np.median(arr, axis=1) # 使用 np.median 按列计算中位数 median_values_col = np.median(arr, axis=0) print(median_values_row) # 输出: # [2. 5.] print(median_values_col) # 输出: # [2.5 3.5 4.5]
12.4 mean()
沿指定的轴,计算数组中元素的算术平均值(即元素之总和除以元素数量)
# 创建一个一维数组 arr = np.array([1, 2, 3, 4, 5]) # 使用 np.mean 计算平均值 mean_value = np.mean(arr) print(mean_value) # 输出: # 3.0 # 创建一个二维数组 arr = np.array([[1, 2, 3], [4, 5, 6]]) # 使用 np.mean 计算平均值 mean_value = np.mean(arr) print(mean_value) # 输出: # 3.5 # 使用 np.mean 按行计算平均值 mean_values_row = np.mean(arr, axis=1) # 使用 np.mean 按列计算平均值 mean_values_col = np.mean(arr, axis=0) print(mean_values_row) # 输出: # [2. 5.] print(mean_values_col) # 输出: # [2.5 3.5 4.5]
6、average()
加权平均值是将数组中各数值乘以相应的权数,然后再对权重值求总和,最后以权重的总和除以总的单位数(即因子个数);根据在数组中给出的权重,计算数组元素的加权平均值。该函数可以接受一个轴参数 axis,如果未指定,则数组被展开为一维数组。
$$
加权平均值=\dfrac{∑_{i=1}^n(x_i⋅w_i)}{∑_{i=1}^nw_i}
$$
其中 xi是数组中的元素,wi是对应的权重。
如果所有元素的权重之和等于1,则表示为数学中的期望值。
# 创建一个一维数组arr = np.array([1, 2, 3, 4, 5]) # 创建权重数组weights = np.array([0.1, 0.2, 0.3, 0.2, 0.2]) # 使用 np.average 计算加权平均值average_value = np.average(arr, weights=weights) print(average_value)# 输出:# 3.2
7、var()
在 NumPy 中,计算方差时使用的是统计学中的方差公式,而不是概率论中的方差公式,主要是因为 NumPy 的设计目标是处理实际数据集,而不是概率分布。
np.var 函数默认计算的是总体方差(Population Variance),而不是样本方差(Sample Variance)。
总体方差:
对于一个总体数据集 X={x1,x2,…,xN},总体方差的计算公式为:
$$
σ^2=\dfrac{1}{N}∑_{i=1}^N(x_i−μ)^2
$$
其中:
-
N是总体数据点的总数。
-
μ是总体的均值。
# 创建一个数组 arr = np.array([1, 2, 3, 4, 5]) # 计算方差 variance = np.var(arr) print(variance) #输出:2
样本方差:
对于一个样本数据集 X={x1,x2,…,xn},样本方差 的计算公式为:
$$
s^2=\dfrac{1}{n−1}∑_{i=1}^n(x_i−\overline x)^2
$$
其中:
-
n是样本数据点的总数。
-
xˉ是样本的均值。
在样本数据中,样本均值的估计会引入一定的偏差。通过使用 n−1n−1 作为分母,可以校正这种偏差,得到更准确的总体方差估计。
# 创建一个数组 arr = np.array([1, 2, 3, 4, 5]) # 计算方差 variance = np.var(arr, ddof=1) print(variance) #输出:2.5
8、std()
标准差是方差的算术平方根,用来描述一组数据平均值的分散程度。若一组数据的标准差较大,说明大部分的数值和其平均值之间差异较大;若标准差较小,则代表这组数值比较接近平均值
# 创建一个数组 arr = np.array([1, 2, 3, 4, 5]) # 计算标准差 std_dev = np.std(arr) print(std_dev) # 输出:1.4142135623730951
相关文章:
 python笔记扩展)
NumPy包(下) python笔记扩展
9.迭代数组 nditer 是 NumPy 中的一个强大的迭代器对象,用于高效地遍历多维数组。nditer 提供了多种选项和控制参数,使得数组的迭代更加灵活和高效。 控制参数 nditer 提供了多种控制参数,用于控制迭代的行为。 1.order 参数 order 参数…...

极狐GitLab 17.5 发布 20+ 与 DevSecOps 相关的功能【一】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...

Oracle 第1章:Oracle数据库概述
在讨论Oracle数据库的入门与管理时,我们可以从以下几个方面来展开第一章的内容:“Oracle数据库概述”,包括数据库的历史与发展,Oracle数据库的特点与优势。 数据库的历史与发展 数据库技术的发展可以追溯到上世纪50年代…...

7、Nodes.js包管理工具
四、包管理工具 4.1 npm(Node Package Manager) Node.js官方内置的包管理工具。 命令行下打以下命令: npm -v如果返回版本号,则说明npm可以正常使用 4.1.1npm初始化 #在包所在目录下执行以下命令 npm init #正常初始化,手动…...

网络地址转换——NAT技术详解
网络地址转换——NAT技术详解 一、引言 随着互联网的飞速发展,IP地址资源日益紧张。为了解决IP地址资源短缺的问题,NAT(Network Address Translation,网络地址转换)技术应运而生。NAT技术允许一个私有IP地址的网络通…...

问:数据库存储过程优化实践~
存储过程优化是提高数据库性能的关键环节。通过精炼SQL语句、合理利用数据库特性、优化事务管理和错误处理,可以显著提升存储过程的执行效率和稳定性。以下是对存储过程优化实践点的阐述,结合具体示例,帮助大家更好地理解和实施这些优化策略。…...

C++ vector的使用(一)
vector vector类似于数组 遍历 这里的遍历跟string那里的遍历是一样的 1.auto(范围for) 2.迭代器遍历 3.operator void vector_test1() {vector<int> v;vector<int> v1(10, 1);//初始化10个都是1的变量vector<int> v3(v1.begin(), --…...

深入浅出:ProcessPoolExecutor 处理异步生成器函数
深入浅出:ProcessPoolExecutor 处理异步生成器函数 什么是 ProcessPoolExecutor?为什么要使用 ProcessPoolExecutor 处理异步生成器函数?ProcessPoolExecutor 处理异步生成器函数的基本用法1. 导入模块2. 定义异步生成器函数3. 定义处理函数4…...

elementUI表达自定义校验,校验在v-for中
注意:本帖为公开技术贴,不得用做任何商业用途 <el-form :inline"true" :rules"rules" :model"formData" ref"formRef" class"mt-[20px]"><el-form-item label"选择区域" prop&qu…...

Elasticsearch 在linux部署 及 Docker 集群部署详解案例示范
1. 在 CentOS 上安装和配置 Elasticsearch 在 CentOS 系统下,安装 Elasticsearch 主要分为以下步骤: 1.1 准备工作 在开始安装之前,确保你的系统满足以下基本条件: CentOS 版本要求:推荐使用 CentOS 7 及以上版本。…...
)
短信验证码发送实现(详细教程)
短信验证码 接口防刷强检验以及缓存验证码阿里云短信服务操作步骤验证码发送实现 好久没发文啦!最近也是在工作中遇到我自认为需要记录笔记的需求,本人只求日后回顾有迹可寻,不喜勿喷! 废话不多说,直接上代码ÿ…...

P450催化的联芳基偶联反应-文献精读72
Chemoenzymatic Synthesis of Fluorinated Mycocyclosin Enabled by the Engineered Cytochrome P450-Catalyzed Biaryl Coupling Reaction 经工程化的细胞色素P450催化的联芳基偶联反应实现氟代麦环素的化学酶促合成 摘要 将氟原子引入天然产物有望生成具有改良或新颖药理特…...

在不支持AVX的linux上使用PaddleOCR
背景 公司的虚拟机CPU居然不支持avx, 默认的paddlepaddle的cpu版本又需要有支持avx才行,还想用PaddleOCR有啥办法呢? 是否支持avx lscpu | grep avx 支持avx的话,会显示相关信息 如果不支持的话,python运行时导入paddle会报错 怎么办呢 方案一 找公司it,看看虚拟机为什么…...

Python数据分析——Numpy
纯个人python的一个小回忆笔记,当时假期花两天学的python,确实时隔几个月快忘光了,为了应付作业才回忆起来,不涉及太多基础,适用于有一定编程基础的参考回忆。 这一篇笔记来源于下面哔哩哔哩up主的视频: 一…...

JMeter快速入门示例
JMeter是一款开源的性能测试工具,常用于对Web服务和接口进行性能测试。 下载安装 官方下载网址: https://jmeter.apache.org/download_jmeter.cgi也可以到如下地址下载:https://download.csdn.net/download/oscar999/89910834 这里下载Wi…...
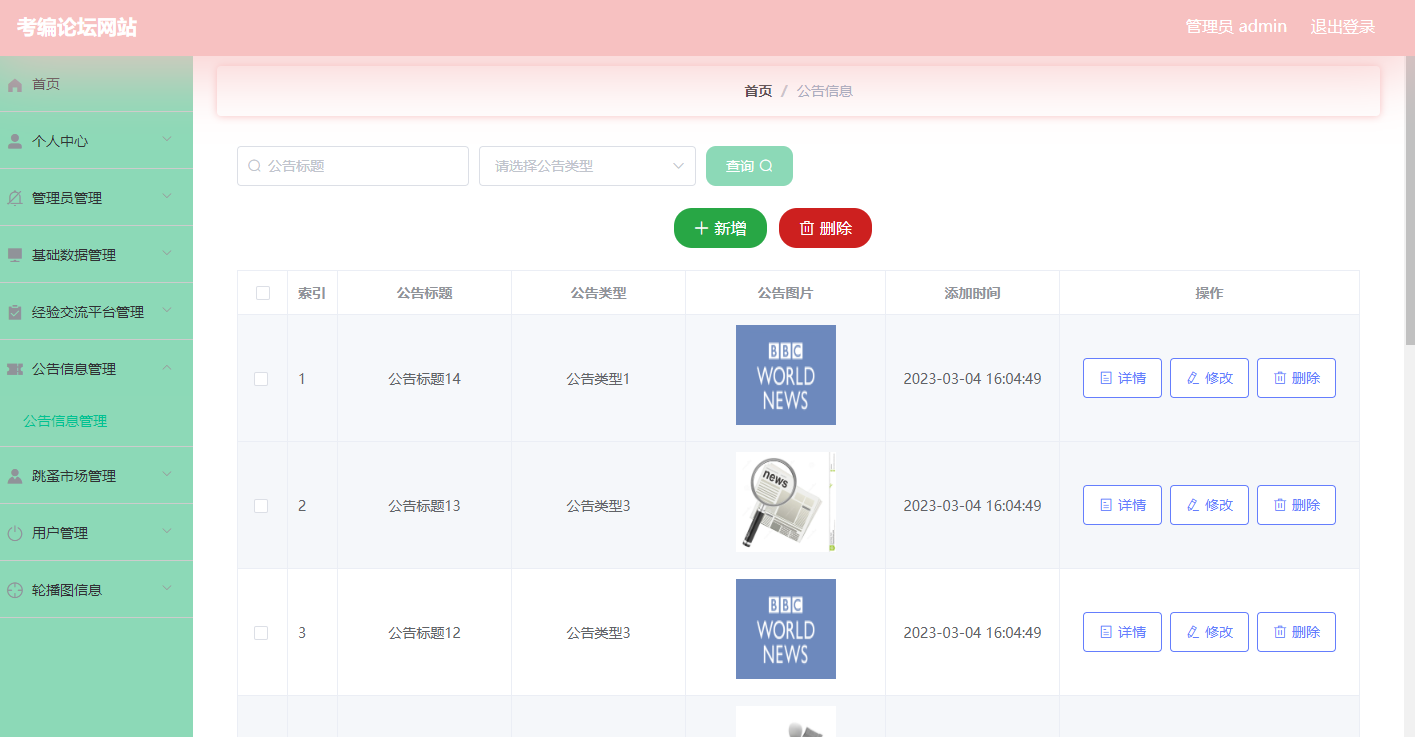
【333基于Java Web的考编论坛网站的设计与实现
毕 业 设 计(论 文) 考编论坛网站设计与实现 摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计…...

计算机网络关键名词中英对照
物理层 IMP - Interface Message Processor - 接口信息处理机 MODEM - Modulator-Demodulator - 调制解调器 LAN - Local Area Network - 局域网 FDM - Frequency Division Multiplexing - 频分复用 TDM - Time Division Multiplexing - 时分复用 STDM - Statistical Time…...

二叉树的学习
除了根节点外的其他节点只有一个直接前驱,有多个直接前驱的逻辑结构叫做图 任何一个树都可以看成是一个根节点和若干个不相交的子树构成的; 构建思维导图时使用树形结构 题目中给出AB是堂兄弟节点说明他们处在同一层 描述两节点之间的路径是从上到下的,同层没有路径,一条边记录…...
免费开源的医疗信息提取系统:提升超声波影像的诊断价值
一、系统概述 思通数科推出的医疗信息精准抽取系统,致力于解决当前医疗行业面临的信息碎片化和数据管理难题。传统医疗过程中,超声波影像数据与诊断报告之间的脱节,往往导致信息无法有效整合,影响医生的诊断效率与准确性。我们的…...

Bash 中的 ${} 和 $() 有什么区别 ?
Bash (Bourne-Again SHell) 是一种流行的 Unix SHell,用于编写脚本。如果您使用 Bash 脚本,那么了解不同的语法元素对于提高脚本的效率和避免错误是很重要的。 在本文中,我们将解释 Bash 中 ${} 和 $() 语法之间的区别,并向您展示…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

Python Einops库:深度学习中的张量操作革命
Einops(爱因斯坦操作库)就像给张量操作戴上了一副"语义眼镜"——让你用人类能理解的方式告诉计算机如何操作多维数组。这个基于爱因斯坦求和约定的库,用类似自然语言的表达式替代了晦涩的API调用,彻底改变了深度学习工程…...

Qemu arm操作系统开发环境
使用qemu虚拟arm硬件比较合适。 步骤如下: 安装qemu apt install qemu-system安装aarch64-none-elf-gcc 需要手动下载,下载地址:https://developer.arm.com/-/media/Files/downloads/gnu/13.2.rel1/binrel/arm-gnu-toolchain-13.2.rel1-x…...