Python数据分析NumPy和pandas(十五、pandas 数据加载、存储和文件格式)
大多数时候,我们要处理分析的数据是存储在不同格式的文件中的,有txt、csv、excel、json、xml以及二进制等磁盘文件格式,还有时候是从数据库以及从Web API中交互获取要处理的数据。现在开始学习如何用pandas从以上内容中输入和输出数据。
读取和写入文本格式数据
pandas具有许多函数,用于将表格数据作为DataFrame对象读取。下面列表列出来一些常用的函数,pandas.read_csv 是最常用的方法之一。这一次主要学习从各种格式的文本文件中存取数据,后面还要学习从二进制数据格式文件中存取数据。
以下列表:pandas 中的文本和二进制数据加载函数
| 函数 | 描述 |
| read_csv | 从文件、URL 或类似文件的对象加载分隔数据;使用逗号作为默认分隔符 |
| read_fwf | 以固定宽度的列格式读取数据(即无分隔符) |
| read_clipboard | 从剪贴板读取数据的read_csv函数的变体;用于从网页转换表格 |
| read_excel | 从 Excel XLS 或 XLSX 文件中读取表格数据 |
| read_hdf | 读取 pandas 写入的 HDF5 文件 |
| read_html | 读取给定 HTML 文档中找到的所有表格数据 |
| read_json | 从 JSON 字符串表示形式、文件、URL 或类似文件的对象中读取数据 |
| read_feather | 读取 Feather 二进制文件格式 |
| read_orc | 读取 Apache ORC 二进制文件格式 |
| read_parquet | 读取 Apache Parquet 二进制文件格式 |
| read_pickle | 读取 pandas 存储的Python pickle 格式对象 |
| read_sas | 读取SAS 数据集;由 SAS 系统的自定义存储格式之一存储 |
| read_spss | 读取 SPSS 创建的数据文件 |
| read_sql | 读取 SQL 查询的结果(使用 SQLAlchemy) |
| read_sql_table | 读取整个 SQL 表(使用 SQLAlchemy);等效于使用 read_sql 选择该表中所有内容的查询 |
| read_stata | 从 Stata 文件格式读取数据集 |
| read_xml | 从 XML 文件中读取数据表 |
这些函数旨在将文本数据转换为 DataFrame,我们先大概了解下这些函数的作用机制。这些函数的可选参数可能分为几类:
Indexing(索引):
可以将一个或多个列视为返回的 DataFrame,以及是否从文件中获取列名等。
Type inference and data conversion(类型推断和数据转换):
包括用户自定义的值转换和缺失值标记的自定义列表等。
Date and time parsing(日期和时间解析)
包括组合功能,可以将分布在多个列中的日期和时间信息合并到结果中的单个列中。
Iterating(迭代):
支持迭代非常大的文件(块)。
Unclean data issues(脏数据问题):
跳过行数据,如页脚、注释或类似于用逗号分隔的千位数字数据的其他小内容数据。
由于现实世界中的数据可能非常混乱,因此随着时间的推移,为了处理这些数据,一些数据加载函数(尤其是 pandas.read_csv)已经积累了一长串可选参数。一开始对这些参数不知所措是正常的(pandas.read_csv 大约有 50 个)。在线 pandas 官方文档有许多关于这些参数工作原理的示例,我们可以找到一个足够相似的示例来帮助我们正确的使用参数。
因为有些文件的 column 数据类型不是数据格式的一部分,所以一些函数提供了类型推理功能。这意味着我们不必指定哪些列是数字、整数、布尔值或字符串。另外有一些数据格式(如 HDF5、ORC 和 Parquet)在格式中嵌入了数据类型信息。
对于处理日期和其他自定义类型,我们可能需要应用更多的其他一些处理方法。
下面我将从读取处理一个小的逗号分隔值 的(CSV) 文本文件开始学习,这个文件名是ex1.csv,存储在examples目录中,examples目录与处理它的Python pandas代码存储在相同目录下,ex1.csv的数据内容如下,另外再创建一个ex2.csv文件,这个文件的数据内容跟ex1.csv一样,只是没有标题行。


通过pandas.read_csv函数将其读取出来,并打印到vs code控制台(很简单,不要搞错文件的存储目录和文件名)
import numpy as np
import pandas as pddf = pd.read_csv("examples/ex1.csv")
print(df)jupyter中输出的pandas对象:
| a | b | c | d | message | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 5 | 6 | 7 | 8 | world |
| 2 | 9 | 10 | 11 | 12 | foo |
对于没有标题行的文件ex2.csv,读取此文件,可以允许 pandas 分配默认列名称,也可以自己指定名称,如下代码。
import numpy as np
import pandas as pd#pandas默认制定列名
a = pd.read_csv("examples/ex2.csv", header=None)#用names指定列名。
b = pd.read_csv("examples/ex2.csv", names=["a", "b", "c", "d", "message"])#指定 message 列成为返回的 DataFrame 的索引。
#可以指定索引位于第4列,也可以使用 index_col 参数将其命名为 “message”
names = ["a", "b", "c", "d", "message"]
c = pd.read_csv("examples/ex2.csv", names=names, index_col="message")设置header=None,则read_csv输出(默认分配列名0 1 2 3 4):
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 5 | 6 | 7 | 8 | world |
| 2 | 9 | 10 | 11 | 12 | foo |
用names指定列名输出:
| a | b | c | d | message | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 5 | 6 | 7 | 8 | world |
| 2 | 9 | 10 | 11 | 12 | foo |
用names指定列名,同时用index_col指定message为列索引名,输出:
| a | b | c | d | |
|---|---|---|---|---|
| message | ||||
| hello | 1 | 2 | 3 | 4 |
| world | 5 | 6 | 7 | 8 |
| foo | 9 | 10 | 11 | 12 |
如果我们想要从多个列中形成分层索引(后面的学习中还会深入学习分层索引),可以传递列号或名称列表。我们创建一个csv_mindex.csv文件,其内容如下图

我们用read_csv读取该文件,并用index_col指定列名称形成分层索引:
import numpy as np
import pandas as pdparsed = pd.read_csv("examples/csv_mindex.csv", index_col=["key1", "key2"])
print(parsed)输出结果如下:
| value1 | value2 | ||
|---|---|---|---|
| key1 | key2 | ||
| one | a | 1 | 2 |
| b | 3 | 4 | |
| c | 5 | 6 | |
| d | 7 | 8 | |
| two | a | 9 | 10 |
| b | 11 | 12 | |
| c | 13 | 14 | |
| d | 15 | 16 |
在某些情况下,表格中可能没有固定的分隔符,会使用空格或其他模式来分隔字段。我们来看文本文件ex3.txt中的内容(空格分隔字典),如下图:

这个文本文件ex3.txt中的字段由不同数量的空格分隔。在这种情况下,我们可以将正则表达式作为 pandas.read_csv 的分隔符传递。这里可以用正则表达式 \s+ 来表示(windows下要加个转义符\),看如下代码:
import numpy as np
import pandas as pdresult = pd.read_csv("examples/ex3.txt", sep="\\s+")
print(result)输出:
| A | B | C | |
|---|---|---|---|
| aaa | -0.264438 | -1.026059 | -0.619500 |
| bbb | 0.927272 | 0.302904 | -0.032399 |
| ccc | -0.264273 | -0.386314 | -0.217601 |
| ddd | -0.871858 | -0.348382 | 1.100491 |
由于列名少一个,因此pandas.read_csv推断在此特殊情况下,第一列应该是 DataFrame 的索引 。
我们再创建一个ex4.csv,第0、2、3行是注释行,其内容如下图:

我们在读取ex4.csv数据的时候需要忽略第0、2、3行注释内容,因此我们可以如下操作:
import numpy as np
import pandas as pdresult = pd.read_csv("examples/ex4.csv", skiprows=[0, 2, 3])
print(result)用skiprows参数指定要跳过的行,输出结果如下:
| a | b | c | d | message | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 5 | 6 | 7 | 8 | world |
| 2 | 9 | 10 | 11 | 12 | foo |
处理缺失值是文件数据读取过程中一个重要的部分。缺失数据通常是不存在,或是空字符串、或是由某个 sentinel (占位符)。默认情况下,pandas 使用一组常见的 sentinel替代这些缺失数据,例如 NaN 和 NULL 。我们创建一个ex5.csv文件来示例,这个文件的内容如下图:

import numpy as np
import pandas as pdresult = pd.read_csv("examples/ex5.csv")
print(result)输出:
| something | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | one | 1 | 2 | 3.0 | 4 | NaN |
| 1 | two | 5 | 6 | NaN | 8 | world |
| 2 | three | 9 | 10 | 11.0 | 12 | foo |
pandas 将缺失值输出为 NaN,因此我们在 result 中有两个缺失值NaN。可以用isna函数判断:
pd.isna(result) 输出:
| something | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | True |
| 1 | False | False | False | True | False | False |
| 2 | False | False | False | False | False | False |
我们还以通过传递一个缺失值列表给na_values参数,指定哪些值是缺失值,例如我们将1和NULL指定为缺失值:
import pandas as pdresult = pd.read_csv("examples/ex5.csv", na_values=["NULL",'1'])print(result)输出:
| something | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | one | NaN | 2 | 3.0 | 4 | NaN |
| 1 | two | 5.0 | 6 | NaN | 8 | world |
| 2 | three | 9.0 | 10 | 11.0 | 12 | foo |
其中元素值1以及为null的元素,都用默认值NaN填充了。
另外,可以用keep_default_na=False设置缺失值进行isna判断时不为True,例如:
import pandas as pdresult2 = pd.read_csv("examples/ex5.csv", keep_default_na=False)
print(result2)
print(result2.isna())result3 = pd.read_csv("examples/ex5.csv", keep_default_na=False, na_values=["NA"])
print(result3)
print(result3.isna())result2输出:
| something | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | one | 1 | 2 | 3 | 4 | NA |
| 1 | two | 5 | 6 | 8 | world | |
| 2 | three | 9 | 10 | 11 | 12 | foo |
result2.isna()输出:
| something | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | False |
| 1 | False | False | False | False | False | False |
| 2 | False | False | False | False | False | False |
result3输出:
| something | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | one | 1 | 2 | 3 | 4 | NaN |
| 1 | two | 5 | 6 | 8 | world | |
| 2 | three | 9 | 10 | 11 | 12 | foo |
result3.isna()输出:
| something | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | True |
| 1 | False | False | False | False | False | False |
| 2 | False | False | False | False | False | False |
从以上可以看出获取result2和result3数据的差别,大家可以自己琢磨下。
我们还可以为文件中的每一列指定不同的 NA 占位符,例如:
import pandas as pdsentinels = {"message": ["foo", "NA"], "something": ["two"]}
res = pd.read_csv("examples/ex5.csv", na_values=sentinels, keep_default_na=False)
print(res)输出:
| something | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | one | 1 | 2 | 3 | 4 | NaN |
| 1 | NaN | 5 | 6 | 8 | world | |
| 2 | three | 9 | 10 | 11 | 12 | NaN |
以下列表是一些 pandas.read_csv 函数常用参数,大家要学习列表中Description中内容,要动手写代码去试用 :


今天先学到这好累,下次学习分段读取文本文件
相关文章:
Python数据分析NumPy和pandas(十五、pandas 数据加载、存储和文件格式)
大多数时候,我们要处理分析的数据是存储在不同格式的文件中的,有txt、csv、excel、json、xml以及二进制等磁盘文件格式,还有时候是从数据库以及从Web API中交互获取要处理的数据。现在开始学习如何用pandas从以上内容中输入和输出数据。 读取…...

正则表达式以及密码匹配案例手机号码脱敏案例
目录 正则表达式 什么是正则表达式 语法 定义变量 test方法 exec方法 replace方法 match方法 修饰符 元字符 边界符 单词边界 字符串边界 边界符:^ 边界符:$ 量词 * ? {n} {n,} {n,m} 字符类 []匹配字符集合 .匹配除换行符之外的…...

五、数组切片make
数组&切片&make 1. 数组2. 多维数组3. 切片3.1 直接声明新的切片函数构造切片3.3 思考题3.4 切片和数组的异同 4. 切片的复制5. map5.1 遍历map5.2 删除5.3 线程安全的map 6. nil7. new和make 1. 数组 数组是一个由固定长度的特定类型元素组成的序列,一个数…...

SSA-CNN-LSTM-MATT多头注意力机制多特征分类预测
SSA-CNN-LSTM-MATT多头注意力机制多特征分类预测 目录 SSA-CNN-LSTM-MATT多头注意力机制多特征分类预测分类效果基本介绍程序设计参考资料 分类效果 基本介绍 1.Matlab实现SSA-CNN-LSTM-MATT麻雀算法优化卷积神经网络-长短期记忆神经网络融合多头注意力机制多特征分类预测&…...

51单片机完全学习——LCD1602液晶显示屏
一、数据手册解读 通过看数据手册我们需要知道,这个屏幕每个引脚的定义以及如何进行发送和接收。通过下面这张图我们就可以知道,这些引脚和我们的编程是有关的,需要注意的是,这里我们在接线的时候,一定要把DB0-DB7接到…...

【知识科普】今天聊聊前端打包工具webpack
文章目录 webpack概述1. 入口(Entry)2. 输出(Output)3. Loader4. 插件(Plugins)5. 模式(Mode)6. 浏览器兼容性(Browser Compatibility)7. 环境(En…...

雷池社区版中升级雷池遇到问题
关于升级后兼容问题 版本差距过大会可能会发生升级后数据不兼容导致服务器无法起来 跨多个版本(超过1个大版本号)升级做好数据备份,遇到升级失败可尝试重新安装解决 升级提示目录不对 在错误的目录下执行(比如 safeline 的子目…...

C++基础:constexpr,类型转换和选择语句
constexpr 提到constexpr,我们会发现它和const类比 常和const类比constexpr符号常量必须给定一个在编译时已知的值, 若某个变量初始化时的值在编译时未知,但初始化后绝不变。 #include<iostream> #include<vector> #include&l…...

STM32 RTC时间无法设置和读取
hal_stm32_RTC函数_stm32 hal rtc-CSDN博客 STM32入门HAL库-RTC实时时钟_hal rtc-CSDN博客 参考了这些博客,是调试发现无法读取正确的时间,日期可以 通过读hal库的文件找到原因 --RTC_BINARY_ONLY模式,只有 sTime->SubSeconds only is …...

go语言中defer用法详解
defer 是 Go 语言中的一个关键字,用于延迟执行某个函数或语句,直到包含它的函数返回时才执行。defer 语句在函数执行结束后(无论是正常返回还是由于 panic 返回)都将执行。 defer 的基本用法 延迟执行: 当你在一个函数…...
iOS 18.2开发者预览版 Beta 1版本发布,欧盟允许卸载应用商店
苹果今天为开发人员推送了iOS 18.2开发者预览版 Beta 1版本 更新(内部版本号:22C5109p),本次更新距离上次发布 Beta / RC 间隔 2 天。该版本仅适用于支持Apple Intelligence的设备,包括iPhone 15 Pro系列和iPhone 16系…...
【SQL】SQL函数
📢 前言 函数 是指一段可以直接被另一段程序调用的程序或代码。主要包括了以下4中类型的函数。 字符串函数数值函数日期函数流程函数 🎄 字符串函数 ⭐ 常用函数 函数 功能 CONCAT(S1,S2,...Sn) 字符串拼接,将S1,S2࿰…...

NSSCTF刷题篇web部分
源码泄露 [FSCTF 2023]寻找蛛丝马迹 这个源码泄露,可以记录一下,涉及的知识点比较多 打开环境 查看源码, 第一段flag 乱码,恢复一下 乱码恢复网站:乱码恢复 (mytju.com) 剩下的就只说方法 http://node4.anna.nss…...

超子物联网HAL库笔记:准备篇
超子物联网 HAL库学习 汇总入口: 超子物联网HAL库笔记:[汇总] 写作不易,如果您觉得写的不错,欢迎给博主来一波点赞、收藏~让博主更有动力吧! 1. HAL库简介 HAL库 HAL库(Hardware Abstraction Layer&#…...
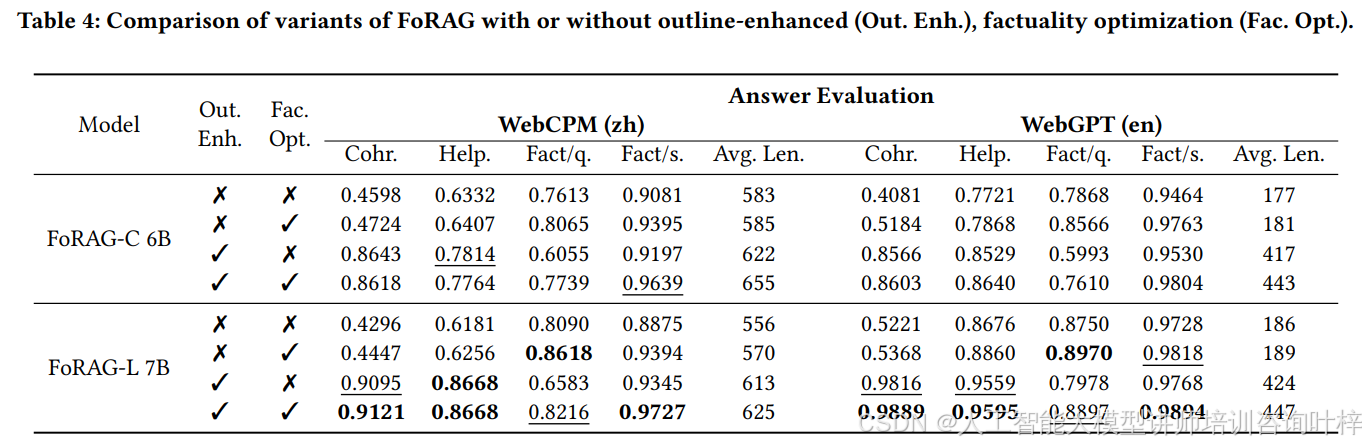
FoRAG:面向网络增强型长文本问答的事实优化检索增强生成方法
人工智能咨询培训老师叶梓 转载标明出处 检索增强生成技术尽管出现了各种开源方法和商业系统,如Bing Chat,但生成的长文本答案中缺乏事实性和清晰逻辑的问题仍未得到解决。为了解决这些问题,来自蚂蚁集团和清华大学的研究者们提出了一种名为…...

Android NSD局域网发现服务
近期在了解局域网发现服务的时候无意间看到Android 自带的(Network Service Discovery)网络发现服务,在一番验证之后发现实现比较简单,可靠性也高,因此在这里做一个整理,算是对自己知识做一个归档。 网络服…...

算法的学习笔记—左旋转字符串(牛客JZ58)
😀前言 在程序设计中,字符串处理问题屡见不鲜,其中“字符串左旋”是一种常见操作,今天我们一起来探讨一个经典的左旋转字符串题目,以及一种优雅的解决方案——三步翻转法。 🏠个人主页:尘觉主页…...

Mac 上无法烧录 ESP32C3 的问题记录:A fatal error occurred:Failed to write to target RAM
文章目录 问题描述驱动下载地址问题解决:安装 CH343 驱动踩的坑日志是乱码 问题描述 我代码编译可以,但是就是烧录不上去 A fatal error occurred:Failed to write to target RAM(result was 01070000:Operation timed out) Uploaderror:上传失败&…...

ios 项目升级极光SDK
由于项目使用的是旧版本,隐私合规检查不通过,需要升级到最新版本, 使用cocoapods集成无法正常运行,.a文件找不到,可能项目比较久了,最好选择手动导入 下载最新版本SDK,将 SDK 包解压ÿ…...

【Java】java | logback日志配置 | 按包配置级别
一、概述 日志配置需求: 本地部分包开debug,其他路径走配置;只在本地环境有效 二、logback.xml配置 <!--本地调试,开debug--> <springProfile name"dev"><logger name"cn.hg.demo" level&quo…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

在四层代理中还原真实客户端ngx_stream_realip_module
一、模块原理与价值 PROXY Protocol 回溯 第三方负载均衡(如 HAProxy、AWS NLB、阿里 SLB)发起上游连接时,将真实客户端 IP/Port 写入 PROXY Protocol v1/v2 头。Stream 层接收到头部后,ngx_stream_realip_module 从中提取原始信息…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...