大模型系列——AlphaZero/强化学习/MCTS
AlphaGo Zero无需任何人类历史棋谱,仅使用深度强化学习,从零开始训练三天的成就已远远超过了人类数千年积累的围棋知识。
1、围棋知识
(1)如何简单理解围棋知识
(2)数子法分胜负:https://zhuanlan.zhihu.com/p/37673325
(3)如何数目分胜负:https://www.zhihu.com/question/284822816/answer/2897667581
(4)3分钟围棋入门视频(总共近2小时):b站
2、强化学习
强化学习(Reinforcement Learning)是机器学习里面一个分支。如果说强化学习在AlphaGo之前版本里面还是初试牛刀的话,那在AlphaGo zero里面强就真正大显神威。根据deepmind的论文,新版本AlphaGo Zero经过三天的训练轻易达到对老版本的100:0的胜率,并且完全无需人类棋谱。可以说,AlphaGo Zero仅仅三天的成就就远远超过了人类数千年的围棋探索。
强化学习和传统机器学习的区别有如下几点:
- 传统机器学习假设算法本身对于环境无影响,强化学习破除了这个限制,能够考虑到了算法对于环境的影响, 这使得强化学习特别适合解决多回合博弈或者顺序决策问题。在传统机器学习中,如果你预测完了之后你根据据测去做多或着做空这个股票,那么其他的股票买家可能因为你的行为改变了自身行为,你原来的训练的模型便会失效,而强化学习可以考虑到这点。
- 在强化学习中,数据是在运行过程中自主收集。AlphaGo Zero之所以能够完全摒弃人类知识就是因为所有的数据都是通过机器互博生成。
用强化学习解决问题,我们需要首先把要解决的问题转化成为一个环境(environment)。环境需要如下的要素:
- 状态空间(state space):对于围棋来说,每一个棋盘布局(记为s)就是一个状态。所有可能的棋盘布局就是状态空间。
- 动作空间 (action space):对于围棋来说,所有可能落子的位置就是一个动作空间
- 可行动作 (allowable action): 在给定状态下,什么动作是可行,什么是不可以的。在围棋里,就是给定一个棋盘,哪里可以落子,哪里不可以。
- 状态转化:你落子之后,对手可能会下的子。如果是两台alpha zero互搏的话,相互是对方环境的一个部分。
- 奖励函数:你落子之后得到的信号。在围棋里面,就是胜率的一个正函数。胜率越大,奖赏越大。
在强化学习里面,知识可以通过一个称为状态-动作值函数(state-action value function) 的结构的存储。通常大家用符号Q(s,a)来表示这个函数,这就是所谓Q-learning的来历。简而言之,Q(s,a)是对于状态s,采取动作a的期望奖励(expected reward)。
强化学习知识(理论):https://zhuanlan.zhihu.com/p/25319023
3、AlphaZero实战
AlphaZero实战:从零学下五子棋(附代码):https://zhuanlan.zhihu.com/p/32089487
3.1 模型训练
本节参考:https://zhuanlan.zhihu.com/p/30339643

训练步骤如下:
(1)构造MCTSPlayer self_play一些轮次后(批量进行),收集构造批次训练数据(包括当前状态,可能的行动概率,胜率),其中winners_z为1或者-1,如下:
zip(states, mcts_probs, winners_z)
(2)利用self_play数据训练策略价值网络。
(2)构造MCTSPlayer和MCTS_Pure(每个子节点的概率都一样)两个玩家,对战n_games次,返回胜率。
(3)若胜率为最佳,则保存当前模型。
(4)重复以上步骤game_batch_num次。
注意:这里MCTS是AlphaZero能够通过self_play不断变强的最重要的原因,相当于用能力不这么强的模型尝试多次后取更有可能胜利的判断。刚开始模型准确率基本为0,但让其仿真模拟N次后,知道哪些落子路径有一定的胜率。将这些路径作为训练数据,训练模型后,模型有一定准确率,MCTS仿真N次后,得到更佳的路径,最终不断变强。

3.2 实际对战
整体步骤如下:
(1)构造Human和MCTSPlayer两个玩家,进入start_play方法的while循环中
(2)交替出子
(3)若判断有人胜出则结束。
1、MCTSPlayer计算出子流程(Play)

(1)利用MCTS策略模拟执行500次,获取子节点访问次数。注意:本代码中_n_playout为500,每一个playout中敌我双方走了N步(不超过当前树的最大深度),直到产生了新的路径节点才结束本次仿真。
(2)所有仿真结束后,根据父节点下所有一级子节点的访问次数构造概率,获得下一步落子位置。

![]()
这里面T为温度参数,T越大,表示温度越高,落子位置越随机,否则位置越确定,代码中temp参数为0.01。公式实验如下:
visits = [2,10, 8, 4, 1]
softmax(1.0/0.001*np.log(np.array(visits)))
array([0.00000000e+00, 1.00000000e+00, 1.23023192e-97, 0.00000000e+00,
0.00000000e+00])
>>> softmax(1.0/0.01*np.log(np.array(visits)))
array([1.26765060e-070, 1.00000000e+000, 2.03703598e-010, 1.60693804e-040,
1.00000000e-100])
>>> softmax(1.0/0.1*np.log(np.array(visits)))
array([9.24622380e-08, 9.02951542e-01, 9.69536836e-02, 9.46813317e-05,
9.02951542e-11])
>>> softmax(1.0/1*np.log(np.array(visits)))
array([0.08, 0.4 , 0.32, 0.16, 0.04])
可以看出,当temp为1时,概率就比较均匀了。否则为0.001时,虽然10和8差距小,但概率都集中到了10这个为止。
最后说下最终落子的采样逻辑,按概率随机选择一个:

random.choice说明如下: If an ndarray, a random sample is generated from its elements. >>> aa_milne_arr = ['pooh', 'rabbit', 'piglet', 'Christopher'] >>> np.random.choice(aa_milne_arr, 5, p=[0.5, 0.1, 0.1, 0.3]) array(['pooh', 'pooh', 'pooh', 'Christopher', 'piglet'], # randomdtype='<U11')
2、MCTS推演落子规则-(Select)
在每一个节点s,AlphaGo Zero会根据如下的公式来选择下一次落子位置:
![]()
其中Q(s, a)是对于状态动值函数的估计值。U(s,a)是一个confidence interval 的upbound。决定探索(exploration)的程度。
代码实现如下:

 从代码中可以看出U由P、当前节点访问次数、父节点访问次数组成,当前节点访问次数越低,值越高,结合c_puct(代码中为5)赋予探索权重。
从代码中可以看出U由P、当前节点访问次数、父节点访问次数组成,当前节点访问次数越低,值越高,结合c_puct(代码中为5)赋予探索权重。
2、MCTS推演落子规则-(Expand and Evaluate)
(1)当棋局没有结束且仿真到叶子节点时(select参考上述步骤),则需要Expand操作添加新的行为策略节点,并将本次仿真后的胜率更新到Q值,继续下一次仿真。


3、MCTS更新Q值-(Backup)
(1)更新节点和父节点Q值
一次仿真结束后,调用_policy进行策略和胜率评估,这里的胜率是node节点对手的胜率,因此当前节点的Q值更新是-leaf_value。另外由于是交替进行,父节点是leaf_value。



这里leaf_value是最终盘面的胜率,相当于最终的奖励。用于更新Q,根据访问次数平均权重
4、alphago和alphazero对比
4.1 AlphaGo 和 AlphaZero 的区别
本段参考:https://zhuanlan.zhihu.com/p/634880256
(1) Policy network 和 Value network 的神经网络 前几层参数是共享的
(2)一开始没有 Supervised Learning of Policy Network (SL policy network) 的环节,也就是说完全没有加入任何人类先验知识在里边,直接暴力上强化学习。
。这一点 AlphaZero 就是完全颠覆了人类传统棋理,可见 AlphaZero 在没有人类先验知识的情况下,不仅仅可以学习到人类的走棋模式,也可以创造出自己的走棋模式,而且这种走棋模式还更加合理。
其他较好文章:https://zhuanlan.zhihu.com/p/30339643
minigo解读:https://zhuanlan.zhihu.com/p/352536850
minigo实现:https://github.com/tensorflow/minigo
5、问题
(1)大模型中若使用MCTS,那么策略和价值如何定义?
在数学题中,可以分解子问题作为action
相关文章:
大模型系列——AlphaZero/强化学习/MCTS
AlphaGo Zero无需任何人类历史棋谱,仅使用深度强化学习,从零开始训练三天的成就已远远超过了人类数千年积累的围棋知识。 1、围棋知识 (1)如何简单理解围棋知识 (2)数子法分胜负:https://zhu…...
原生js实现拖拽上传(拖拽时高亮上传区域)
文章目录 drop相关事件说明-MDN演示代码(.html) drop相关事件说明-MDN 演示 代码(.html) <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"…...

python道格拉斯算法的实现
废话不多说 直接开干 需要用到模块 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple math #对浮点数的数学运算函数 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple shapely #提供几何形状的操作和分析,如交集、并集、差集等 pip install -i …...

STM32的hal库中,后缀带ex和不带的有什么区别
在STM32的HAL(硬件抽象层)库中,后缀带“ex”和不带“ex”的文件及其包含的内容存在显著的区别。这些区别主要体现在功能扩展性、使用场景以及API的层次上。 一、功能扩展性 不带“ex”后缀的文件: 这些文件通常包含标准的、核心…...

可观测性三大支柱
目录 可观测性成熟度模型 可观测性三大支柱的具体定义如下 指标 日志 链路 可观测性成熟度模型 可观测性成熟度模型,是一种用于衡量和评估企业软件系统内部可观测性的框架或方法,同 时也是一种用于反馈企业可观测性体系建设成熟度水平的框架或方法…...

【银河麒麟高级服务器操作系统·实例分享】裸金属服务器开机失败分析及处理建议
了解更多银河麒麟操作系统全新产品,请点击访问 麒麟软件产品专区:https://product.kylinos.cn 开发者专区:https://developer.kylinos.cn 文档中心:https://documentkylinos.cn 现象描述 裸金属物理服务器开机卡在EFI stub页面…...

模型剪枝实操
文章目录 实验报告:模型剪枝在图像分类任务中的应用摘要实验方法数据集和预处理模型架构剪枝过程实验设置 实验效果性能对比详细分析 结论 实验报告:模型剪枝在图像分类任务中的应用 摘要 本实验通过模型剪枝技术,对一个图像分类模型进行压…...

网安学习路线!最详细没有之一!看了这么多分享网安学习路线的一个详细的都没有!
零基础小白,到就业!入门到入土的网安学习路线! 在各大平台搜的网安学习路线都太粗略了。。。。看不下去了! 我把自己报班的系统学习路线,整理拿出来跟大家分享了!点击下图,福利! …...
Ubuntu18.04安装vscode1.94.2失败安装vscode1.84.2
系统环境:Ubuntu18.04.6 LTS 自己先去vscode官网下载好最新版本的vscode1.94.2(不下也行,反正最新版也用不了,哈哈) 网址:Visual Studio Code - Code Editing. RedefinedVisual Studio Code is a code ed…...

Redis中Lua脚本的使用场景
Redis 中的 Lua 脚本可以用于多种场景,以下是一些常见的使用场景及其对应的 Java 实现示例。 通过使用 Lua 脚本,可以在 Redis 中实现复杂的逻辑和原子操作,同时利用 Java 客户端(如 Spring Data Redis)方便地执行这些…...

重工业数字化转型创新实践:某国家特大型钢铁企业如何快速落地基于实时数仓的数据分析平台
使用 TapData,化繁为简,摆脱手动搭建、维护数据管道的诸多烦扰,轻量替代 OGG, Kettle 等同步工具,以及基于 Kafka 的 ETL 解决方案,「CDC 流处理 数据集成」组合拳,加速仓内数据流转,帮助企业…...

【linux】手动启动sshd
安装openssh-server修改配置文件启动 以下是在常见的Linux系统中手动开启sshd服务的步骤: 1.安装openssh-server CentOS/RHEL系统 首先,以具有管理员权限的用户(通常是root)登录到系统。检查sshd服务是否已经安装。可以使用以…...

前端项目【本科期间】
1.基于博达网站群的申达办官方网站开发与维护 实习项目:校发展规划中心暨申请更名大学办公室官方网站 技术栈:HTML/CSS/Javascript 博达网站群的入门级指南 -CSDN博客博达网站群的入门级指南 -CSDN博客 网上少的较全的基于博达网站建设指南,CSDN相关内容综合指数NO有.1 …...
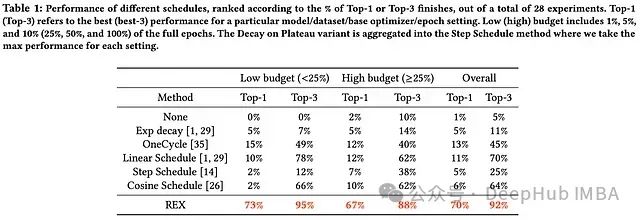
深度学习中的学习率调度:循环学习率、SGDR、1cycle 等方法介绍及实践策略研究
深度学习实践者都知道,在训练神经网络时,正确设置学习率是使模型达到良好性能的关键因素之一。学习率通常会在训练过程中根据某种调度策略进行动态调整。调度策略的选择对训练质量也有很大影响。 大多数实践者采用一些广泛使用的学习率调度策略,例如阶梯式衰减或余弦退火。这些…...
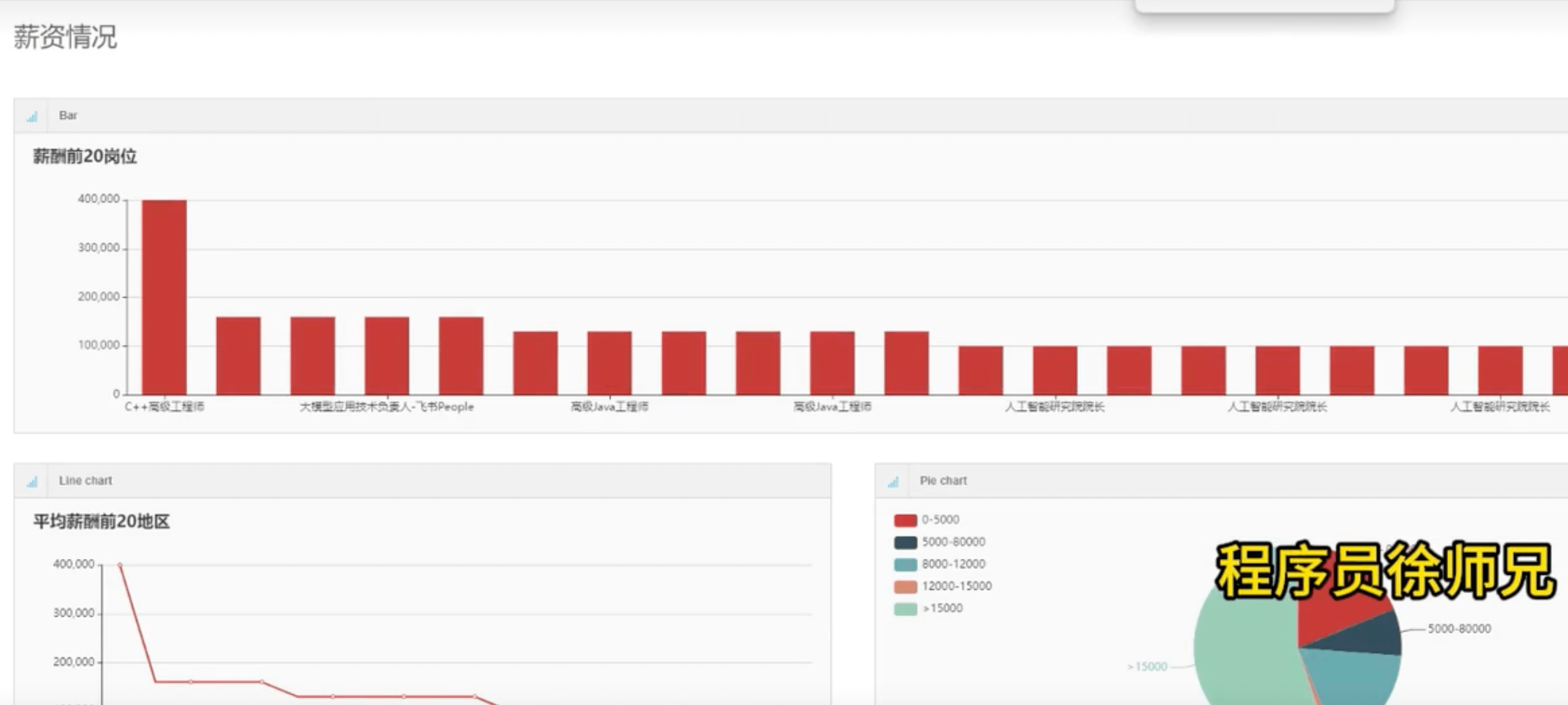
Python毕业设计-基于 Python flask 的前程无忧招聘可视化系统,Python大数据招聘爬虫可视化分析
博主介绍:✌Java徐师兄、7年大厂程序员经历。全网粉丝13w、csdn博客专家、掘金/华为云等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇🏻 不…...

Linux初阶——线程(Part1)
一、线程概念 1、如何理解线程 说到线程,那么我们就要回到进程了。 1.1. 再谈进程 对一个进程来说,它在内存中是这样的: 图1.1-a 其中一个 task_struct 独享一个进程地址空间和一个页表。 而线程其实和进程差不多,是这样的&…...

SpringBoot后端开发常用工具详细介绍——flyway数据库版本控制工具
文章目录 什么是flyway简介为什么要使用flyway 流程介绍整合springboot添加pom文件配置flyway向resource/db/migration添加sql文件 注意事项1. 迁移报错2. 迁移顺序 参考 什么是flyway 简介 为什么要使用flyway 我们在开发时往往会有这样一种情况: 进行软件开发…...

CSS揭秘:7. 伪随机背景
前置知识:CSS 渐变,5. 条纹背景,6. 复杂的背景图案 前言 本篇主要内容依然是关于背景的,无限平铺的背景会显得整齐美观,但又有些呆板,如何实现背景的多样性和随机性,是本篇的核心。 一、四种颜…...

SAP CODE DEMO:查找AL11 指定路径下文件中的内容
有时候需要查找某个具体的内容,在哪个文件内。数据量大的时候可以利用程序查找 选择界面: 路径,和文件名都可以模糊搜查 search string:你要查找的信息。 代码参考如下: report z00R010 NO STANDARD PAGE HEADING…...

【华为HCIP实战课程二十四】中间到中间系统协议IS-IS配置实战,网络工程师
一、IS-IS整体架构 将Level-1路由器部署在非骨干区域,Level-2路由器和Level-1-2路由器部署在骨干区域。 每一个非骨干区域都通过Level-1-2路由器与骨干区域相连! 1、在IS-IS中,每个链路可以属于不同的区域,OSPF中每个链路属于同一个区域 2、在IS-IS中,单个区域没有物理…...

豆仔机器人:低成本嵌入式智能体软硬件协同设计实践
1. 项目概述豆仔(Beanbot)是一款面向嵌入式人机交互教育与轻量化智能终端验证的桌面级宠物机器人平台。其设计目标并非追求工业级鲁棒性或消费级量产成熟度,而是构建一个软硬件耦合清晰、感知-决策-执行链路完整、且具备明确成长性演进路径的…...
)
拒绝“人工智障”:如何让AI成为你的超级代码副驾驶(保姆级教程)
拒绝“人工智障”:如何让AI成为你的超级代码副驾驶(保姆级教程) 哈喽,各位还在和代码“相爱相杀”的攻城狮们,我是你们那个头发还算茂密的技术老司机。 今天咱们不聊那些枯燥的架构设计,也不谈什么高并发…...

Nano-Banana与SolidWorks集成开发指南
Nano-Banana与SolidWorks集成开发指南 将AI图像生成能力融入3D设计工作流,让创意实现效率提升10倍 1. 引言:当AI遇见机械设计 作为一名机械工程师,你是否经常遇到这样的场景:客户急着要设计方案预览,但3D模型还没完成…...

效率提升秘籍:用快马平台自动化dhnvr416h-hd视频处理流水线
在视频处理领域,尤其是集成像 dhnvr416h-hd 这类特定设备或格式的编解码器时,开发者常常会陷入一个效率泥潭:环境配置复杂、处理流程繁琐、错误排查困难。每次新项目启动,都要重复搭建环境、编写相似的脚本,大量时间被…...

【有参考文献】事件触发模型 可实现倒立摆控制仿真实验 simulink模型可直接运行
【有参考文献】事件触发模型 可实现倒立摆控制仿真实验 simulink模型可直接运行 含详细参考文献倒立摆这个玩具般的控制对象,总能让工程师们玩得停不下来。它那摇摇欲坠的姿态就像在挑衅:"有本事就来稳住我啊!"传统控制方法像永不停…...

成为MWC26焦点,华为Atlas超节点凭什么重塑智算产业格局?
2026年,Agentic AI(AI智能体)正从技术探索加速迈向规模化落地。来自分析机构IDC的报告显示,未来五年,全球AI智能体生态将经历一场指数级的扩张,到2030年,超过22亿个AI智能体将作为“新数字劳动力…...

贾子哲学体系:思想主权与贾子猜想引领的东方原创跨学科理论创新与实证研究
贾子哲学体系:思想主权与贾子猜想引领的东方原创跨学科理论创新与实证研究摘要: 本文首度系统性构建贾子哲学体系(Kucius Philosophy),以“思想主权”为核心公理,确立AI时代人类主体性。核心创新“贾子猜想…...

AI 辅助编程阶段化开发 SOP
AI 辅助编程阶段化开发 SOP1. 提出需求(明确需求)2. 整理需求文档3. 检查需求文档4. 架构设计5. 核实全局架构文档6. 拆分需求7. 阶段性方案8. 输出阶段性开发文档9. 分阶段独立开发以及任务拆分10. 阶段性评审11. 系统集成与联调📌 附录&…...

智动群剪视频矩阵引
链接:https://pan.quark.cn/s/358832aed834智动群剪视频矩阵引擎,批量制作视频软件软件使用步骤:1.加入素材(手动添加或复制素材到对应目录) 2.勾选需要用到的素材 3.选择功能,修改数值 4.一键开始制作视频…...

Z-Image-Turbo-辉夜巫女完整指南:开源可部署+GPU显存优化+Gradio开箱即用
Z-Image-Turbo-辉夜巫女完整指南:开源可部署GPU显存优化Gradio开箱即用 1. 引言:当二次元创作遇上开源AI 如果你是一位动漫爱好者,或者对二次元角色创作感兴趣,最近是不是经常被各种精美的AI生成图刷屏?特别是那些风…...