深度学习中的学习率调度:循环学习率、SGDR、1cycle 等方法介绍及实践策略研究
深度学习实践者都知道,在训练神经网络时,正确设置学习率是使模型达到良好性能的关键因素之一。学习率通常会在训练过程中根据某种调度策略进行动态调整。调度策略的选择对训练质量也有很大影响。
大多数实践者采用一些广泛使用的学习率调度策略,例如阶梯式衰减或余弦退火。这些调度策略中的许多是为特定的基准任务量身定制的,经过多年的研究,已被证明可以最大限度地提高测试精度。然而这些策略往往无法推广到其他实验设置,这引出了一个重要的问题:训练神经网络最一致和最有效的学习率调度策略是什么?
在本文中,我们将研究各种用于训练神经网络的学习率调度策略。这些研究发现了许多既高效又易于使用的学习率策略,例如循环学习率或三角形学习率调度。通过研究这些方法,我们将得出几个实用的结论,提供一些可以立即应用于改善神经网络训练的简单技巧。
神经网络训练与学习率
在监督学习环境中,神经网络训练的目标是生成一个模型,在给定输入数据的情况下,能够准确预测与该数据相关的真实标签。一个典型的例子是训练一个神经网络,根据大量标记的猫和狗的图像数据集,正确预测一张图像中是否包含猫或狗。
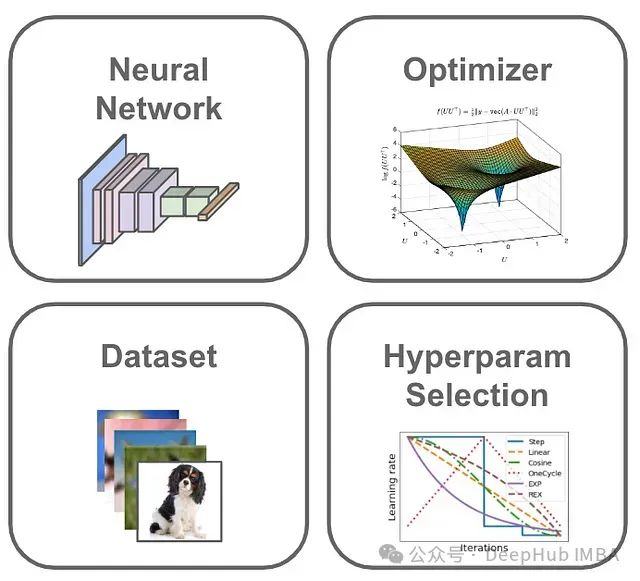
上图所示的神经网络训练的基本组成部分如下:
- 神经网络: 接受一些数据作为输入,并根据其内部参数/权重对这些数据进行转换,以产生输出。
- 数据集: 大量的输入-输出数据对的样本(例如,图像及其相应的分类标签)。
- 优化器: 用于更新神经网络的内部参数,使其预测更加准确。
- 超参数: 由深度学习实践者设置的外部参数,用于控制训练过程的相关细节。
通常神经网络在开始训练时,其所有参数都是随机初始化的。为了学习更有意义的参数,神经网络会接受来自数据集的数据样本。对于每个样本,神经网络尝试预测正确的输出,然后优化器更新神经网络的参数以改进这个预测。
这个过程通过更新神经网络的参数,使其能够更好地匹配数据集中已知的输出,这被称为训练。这个过程重复进行,通常直到神经网络多次遍历整个数据集,每次遍历被称为一个训练周期(epoch)。
尽管这个神经网络训练的描述并不全面,但它应该提供足够的直观理解来完成本文的阅读。下面我们继续
什么是超参数?
模型参数在训练过程中由优化器更新。相比之下,超参数是 “额外的” 参数,我们(深度学习实践者)可以控制。但是,我们实际上可以用超参数控制什么?一个常见的超参数,就是学习率。
什么是学习率? 简单地说,每次优化器更新神经网络的参数时,学习率控制这个更新的大小。我们应该大幅更新参数、小幅更新参数,还是介于两者之间? 我们通过设置学习率来做出这个选择。
选择一个好的学习率。 设置学习率是训练神经网络最重要的方面之一。如果我们选择的值太大,训练就会发散。另一方面,如果学习率太小,可能会导致性能不佳和训练缓慢。我们必须选择一个足够大的学习率,以提供对训练过程的正则化效果并快速收敛,同时不能太大以致于训练过程变得不稳定。
选择好的超参数
像学习率这样的超参数通常使用一种简单的方法网格搜索来选择。基本思路是:
- 为每个超参数定义一个潜在值的范围
- 在这个范围内选择一组离散的值进行测试
- 测试所有可能的超参数值组合
- 基于验证集的性能选择最佳超参数设置
网格搜索是寻找最佳超参数的简单而穷尽的搜索方法。下图是一个在潜在学习率值上进行网格搜索的示例。
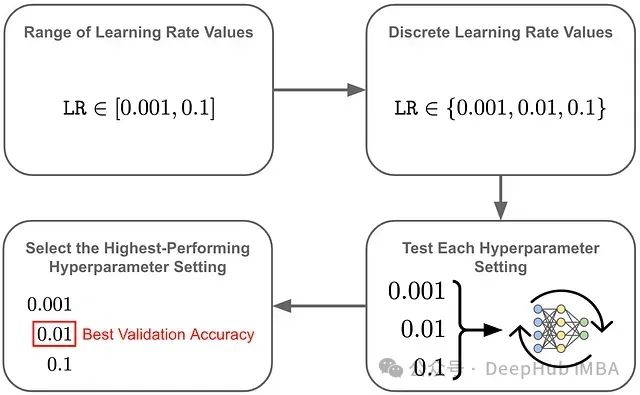
通过遵循类似的方法并测试所有可能的超参数值组合,可以将类似的方法应用于多个超参数。
网格搜索在计算上是低效的,因为它需要为每个超参数设置重新训练神经网络。为了避免这种成本,许多深度学习实践者采用 “猜测和检查” 的方法,在合理的范围内尝试几个超参数,看看什么有效。已经提出了选择最佳超参数的其他方法[5],但由于其简单性,网格搜索或猜测和检查过程被广泛使用。
学习率调度
在选择了学习率之后,我们通常不应在整个训练过程中保持同一个学习率。相反,我们应该 (i) 选择一个初始学习率,然后 (ii) 在整个训练过程中逐渐衰减这个学习率[1]。执行这种衰减的函数被称为学习率调度。
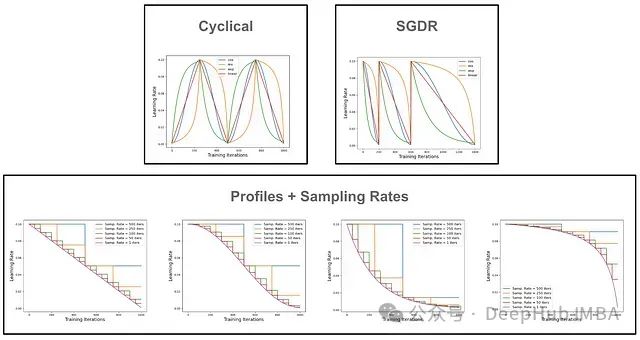
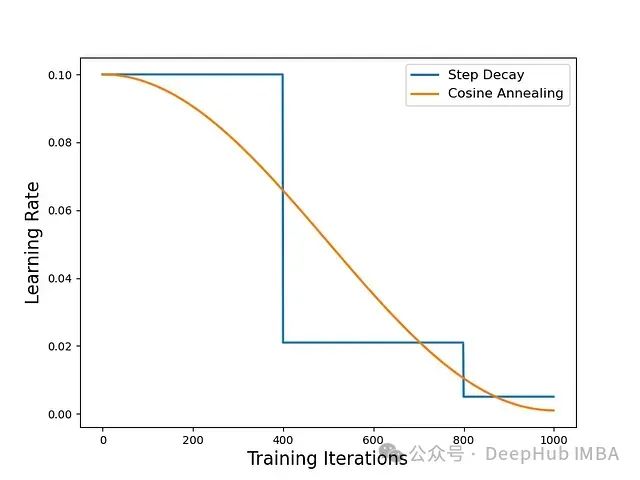
人们提出了许多不同的学习率调度策略;例如,阶梯式衰减(即在训练期间将学习率衰减 10 倍几次)或余弦退火;见下图。在本文中,我们将探讨一些最近提出的表现特别好的调度策略。
自适应优化技术。 基于随机梯度下降(SGD)的神经网络训练选择了一个全局学习率,用于更新所有模型参数。除了 SGD 之外,还提出了自适应优化技术(例如,RMSProp 或 Adam [6]),它们使用训练统计数据来动态调整用于每个模型参数的学习率。本文中概述的大部分结果同时适用于自适应优化器和 SGD 风格的优化器。
相关论文
在这一节中,我们将看到一些学习率调度策略的例子。这些策略包括循环学习率或三角形学习率,以及不同的学习率衰减方案。最佳学习率策略高度依赖于领域和实验设置,但我们也将看到通过研究许多不同学习率策略的实证结果,可以得出几个高层次的结论。
用于训练神经网络的循环学习率[1]
https://arxiv.org/abs/1506.01186
[1]中的作者提出了一种处理神经网络训练中学习率的新方法:根据平滑的调度,在最小值和最大值之间循环变化学习率。在这项工作之前,大多数实践者采用了一种流行的策略,即 (i) 将学习率设置为一个初始较大的值,然后 (ii) 随着训练的进行逐渐衰减学习率。
在[1]中抛弃了这个经验法则,转而采用循环策略。以这种方式循环学习率有点违反直觉 —— 在训练过程中增加学习率会损害模型性能。尽管在学习率增加时暂时降低了网络性能,但正如我们将在[1]中看到的,循环学习率调度实际上在整个训练过程中提供了很多优于其他方法的好处。
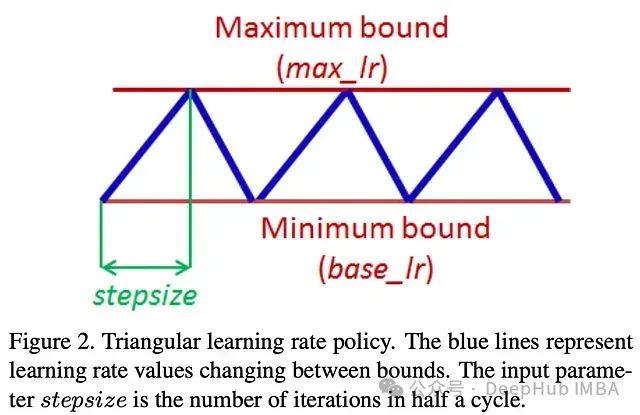
循环学习率引入了三个新的超参数:步长、最小学习率和最大学习率。产生的调度是 “三角形” 的,这意味着学习率在相邻的周期中交替增加和减少;步长可以设置在 2-10 个训练周期之间,而学习率的范围通常通过学习率范围测试来确定(见[1]中的第 3.3 节)。
增加学习率会暂时降低模型性能。但是一旦学习率再次衰减,模型的性能就会恢复并提高。考虑到这一点,在[1]的实验结果中看到,用循环学习率训练的模型在性能上呈现出周期性模式。每个周期结束时(即当学习率衰减回最小值时),模型性能达到峰值,而在周期的中间阶段(即当学习率增加时),模型性能则变得较差;见下图。
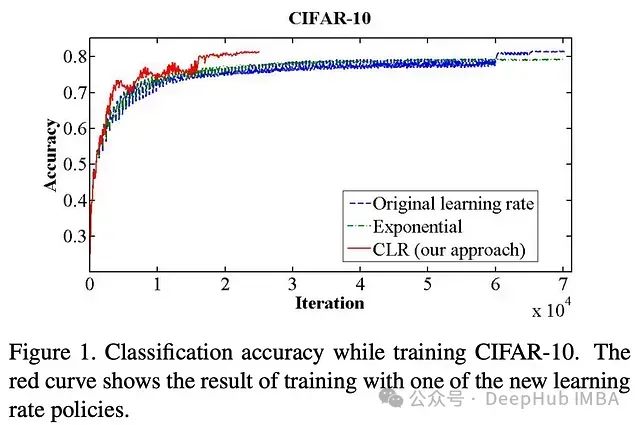
[1]中的结果表明,循环学习率在训练过程中有利于模型性能。与其他学习率策略相比,使用循环学习率训练的模型更快地达到更高的性能水平;换句话说,使用循环学习率训练的模型在任何时间点的性能都非常好!
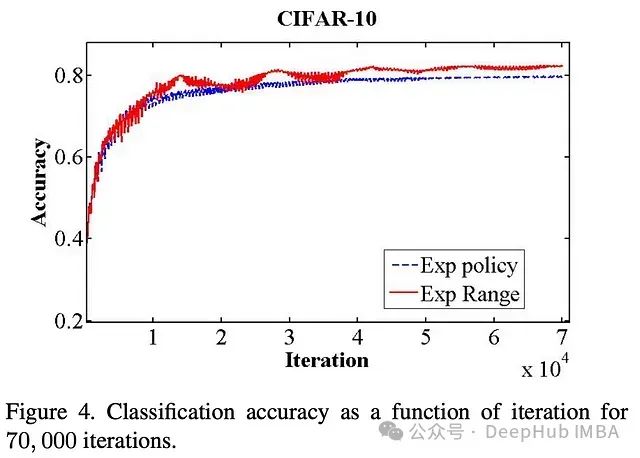
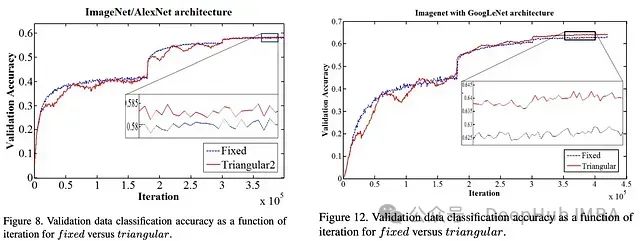
在 ImageNet 上进行的更大规模实验中,循环学习率仍然提供了好处,尽管不那么明显。
SGDR: 带有热重启的随机梯度下降[2]
https://arxiv.org/abs/1608.03983
[2]中的作者提出了一种简单的学习率重启技术,称为带有重启的随机梯度下降(SGDR),其中学习率定期重置为其原始值并按计划减小。这种技术采用以下步骤:
- 根据某个固定的调度衰减学习率
- 在衰减调度结束后将学习率重置为其原始值
- 返回步骤 #1(即再次衰减学习率)
下面是遵循这一策略的不同调度的描述。
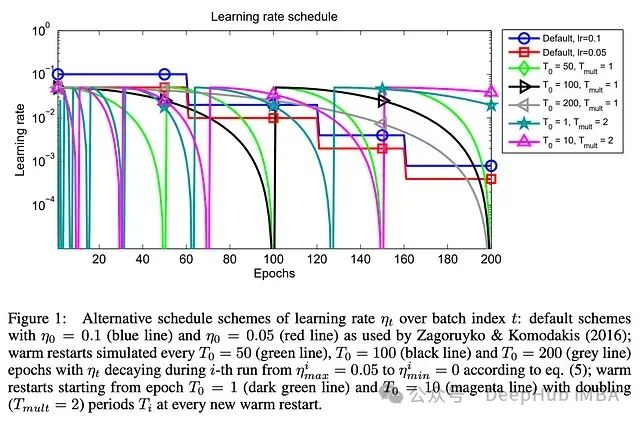
我们可以注意到上面调度的一些特点。首先,在[2]中总是使用余弦衰减调度(图的 y 轴是对数刻度)。此外,随着训练的进行,每个衰减调度的长度可能会增加。具体来说,[2]中的作者将第一个衰减周期的长度定义为
T_0
,然后在每个连续的衰减周期中将这个长度乘以
T_mult
;见下图的描述。
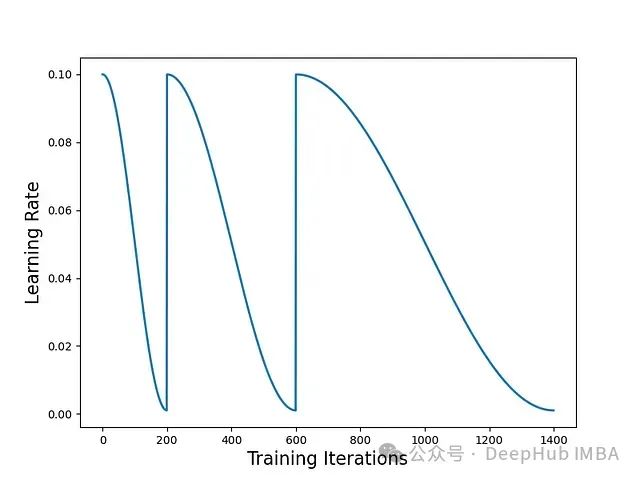
为了遵循[1]的术语,SGDR 的步长可能在每个周期后增加。但与[1]不同的是,SGDR 不是三角形的(即每个周期只是衰减学习率)。
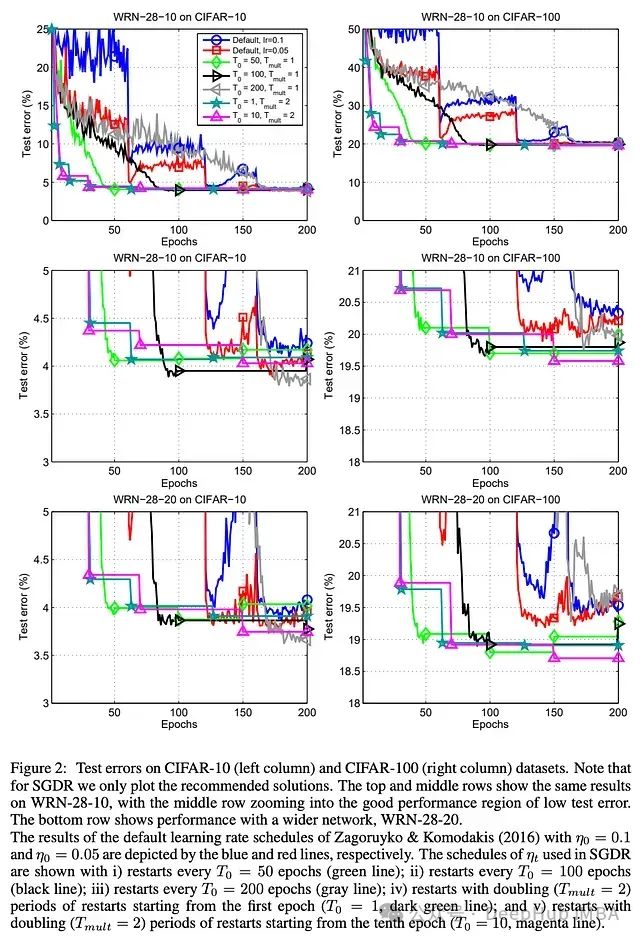
在 CIFAR10/100 上的实验中可以看到,与阶梯式衰减调度相比,SGDR 学习率调度可以更快地获得良好的模型性能 —— SGDR 具有良好的任意时间性能。每个衰减周期后得到的模型表现良好,并在连续的衰减周期中继续变得更好。
在这些初步结果之外,研究通过在每个衰减周期结束时获取 “快照” 而形成的模型集成。具体来说可以在SGDR 调度中的每个衰减周期后保存模型状态的副本。然后在训练完成后,在推理时平均每个模型的预测,形成一个模型集成。
通过以这种方式形成模型集成,可以在 CIFAR10 上显著降低测试错误率;见下图。
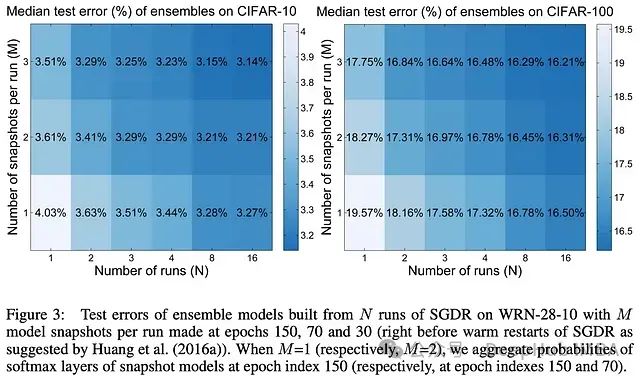
此外,SGDR 的快照似乎提供了一组具有不同预测的模型。以这种方式形成集成实际上优于将独立的、完全训练的模型加入集成的常规方法。
超融合:使用大学习率非常快速地训练神经网络[3]
https://arxiv.org/abs/1708.07120
[3]中的作者研究了一种有趣的训练神经网络的方法,可以将训练速度提高一个数量级。基本方法(最初在[8]中概述)是执行单个三角形学习率周期,其中最大学习率较大,然后在训练结束时允许学习率衰减到该周期的最小值以下;见下图的说明。
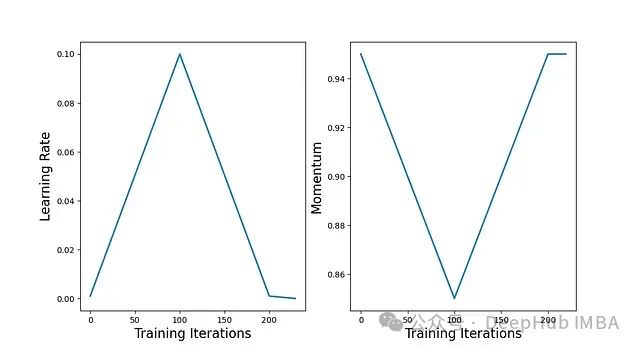
此外动量以与学习率相反的方向循环(通常在[0.85, 0.95]的范围内)。这种联合循环学习率和动量的方法被称为 “1cycle”。[3]中的作者表明,它可以用来实现 “超融合”(即非常快速地收敛到高性能解)。
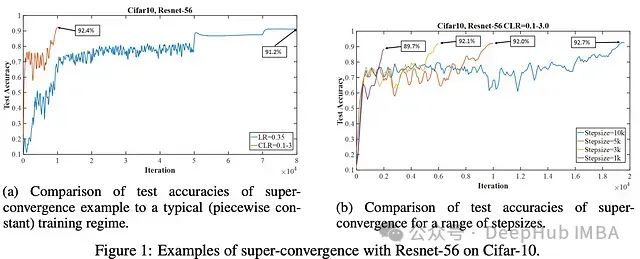
例如在 CIFAR10 上的实验中看到,与基线学习率策略相比,1cycle 可以用少 8 倍的训练迭代次数实现更好的性能。使用不同的 1cycle 步长可以进一步加速训练,尽管准确率水平取决于步长。
可以在一些不同的架构和数据集上观察到类似的结果。其中 1cycle 再次在令人惊讶的少量训练周期中产生良好的性能。
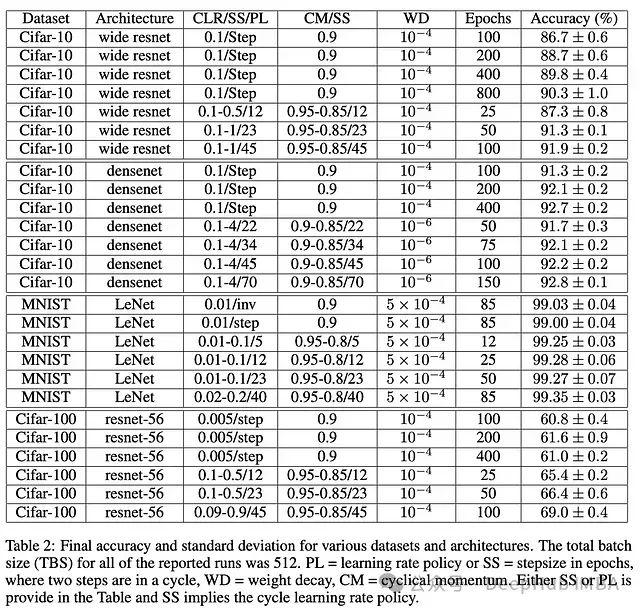
目前还不清楚超融合是否可以在大量的实验设置中实现,因为[3]中提供的实验在规模和种类上都有些有限。尽管如此,我们可能都会同意,超融合现象非常有趣。事实上,这个结果是如此有趣,以至于它甚至被 fast.ai 社区推广和深入研究。
REX:重新审视带有改进调度的预算训练[4]
https://arxiv.org/abs/2107.04197
在[4]中,作者考虑了在不同预算制度(即小、中、大训练周期数)下正确调度学习率的问题。你可能会想:为什么要考虑这种设置?通常情况下,最佳训练周期数并不是事先知道的。但我们可能正在使用一个固定的资金预算,这会限制可以执行的训练周期数。
为了找到最佳的预算不可知学习率调度,我们必须首先定义将要考虑的可能学习率调度的空间。在[4]中,通过将学习率调度分解为两个组成部分来实现这一点:
- 轮廓: 在整个训练过程中学习率变化所依据的函数。
- 采样率: 根据所选轮廓更新学习率的频率。
这样的分解可以用来描述几乎所有固定结构的学习率调度。下面描述了不同轮廓和采样率组合。采样率越高,调度越接近基础轮廓。

[4]中的作者考虑了具有不同采样率和三种函数轮廓的学习率调度:指数(即产生阶梯式调度)、线性和 REX(即[4]中定义的新颖轮廓)。
作者在 CIFAR10 上训练 Resnet20/38,采用不同的采样率和轮廓组合。在这些实验中可以看到阶梯式衰减调度(即具有低采样率的指数轮廓)只有在低采样率和许多训练周期的情况下才表现良好。每次迭代采样的 REX 调度在所有不同的周期设置中都表现良好。
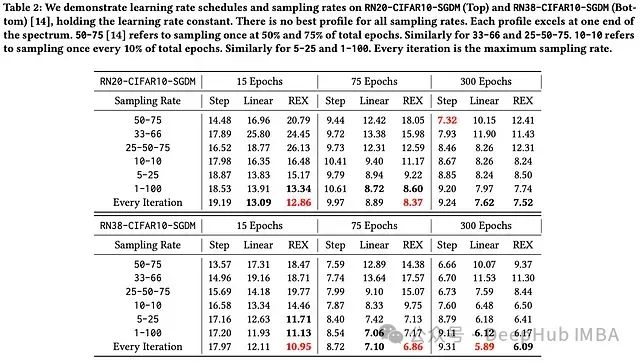
之前的工作表明,线性衰减调度最适合低预算训练设置(即用更少的周期进行训练)[9]。在[4]中,我们可以看到 REX 实际上是一个更好的选择,因为它避免了在训练的早期过早地衰减学习率。
[4]中的作者还考虑了各种流行的学习率调度,如下图所示。
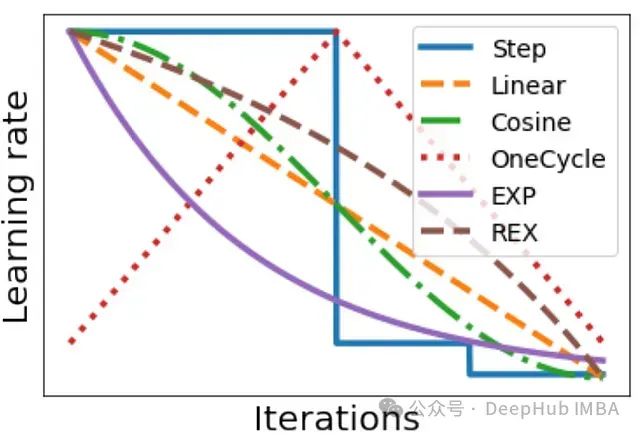
在各种领域和训练周期预算下测试了这些调度。当在所有实验中汇总性能时,我们得到如下所示的结果。
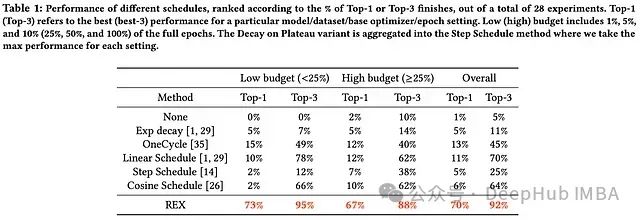
REX 在不同的预算制度和实验领域中实现了令人震惊的一致性能。没有其他学习率调度在实验中接近相同比例的前 1/3 名次,这表明 REX 是一个良好的领域/预算不可知的学习率调度。
除了 REX 的一致性之外,这些结果还告诉我们一些更普遍的东西:常用的学习率策略在不同的实验设置中泛化能力不好。每个调度(即使是 REX,尽管程度较小)只在少数情况下表现最好,这表明为任何特定设置选择适当的学习率策略非常重要。
总结
正确处理学习率可以说是训练神经网络最重要的方面。在本文中,我们了解了几种用于训练深度网络的实用学习率调度策略。研究这一系列工作提供了简单易懂、易于实施且高效的结论。其中一些基本结论如下。
选择一个好的学习率。 正确设置学习率是训练高性能神经网络最重要的方面之一。选择不当的初始学习率或使用错误的学习率调度会显著恶化模型性能。
"默认"调度并非总是最好的。 许多实验设置都有一个 “默认” 学习率调度,我们倾向于在没有太多思考的情况下采用;例如,用于图像分类的 CNN 训练的阶梯式衰减调度。但我们也应该意识到,随着实验设置的改变,这些调度的性能可能会急剧恶化;例如,对于预算设置,基于 REX 的调度明显优于阶梯式衰减。我们应该始终关注我们选择的学习率调度,以真正最大化我们模型的性能。
循环调度非常棒。 循环或三角形学习率调度(例如,如[2]或[3]中所示)非常有用,因为:
- 它们通常达到或超过最先进的性能
- 它们具有良好的任意时间性能
使用循环学习率策略,模型在每个衰减周期结束时达到最佳性能。我们可以简单地继续训练任意数量的周期,直到我们对网络的性能感到满意。最佳训练量不需要事先知道,这在实践中通常很有用。
有很多东西值得探索。 尽管学习率策略已经被广泛研究,但似乎仍有更多的东西有待发现。例如,我们已经看到,采用替代衰减轮廓有利于预算设置[4],循环策略甚至可以在某些情况下用于实现超融合[3]。但是问题也随之而来:还能发现什么? 似乎有一些非常有趣的策略(例如,分形学习率[7])尚未被探索。
参考文献
[1] Smith, Leslie N. “Cyclical learning rates for training neural networks.” 2017 IEEE winter conference on applications of computer vision (WACV). IEEE, 2017.
[2] Loshchilov, Ilya, and Frank Hutter. “Sgdr: Stochastic gradient descent with warm restarts.” arXiv preprint arXiv:1608.03983 (2016).
[3] Smith, Leslie N., and Nicholay Topin. “Super-convergence: Very fast training of neural networks using large learning rates.” Artificial intelligence and machine learning for multi-domain operations applications. Vol. 11006. SPIE, 2019.
[4] Chen, John, Cameron Wolfe, and Tasos Kyrillidis. “REX: Revisiting Budgeted Training with an Improved Schedule.” Proceedings of Machine Learning and Systems 4 (2022): 64–76.
[5] Yu, Tong, and Hong Zhu. “Hyper-parameter optimization: A review of algorithms and applications.” arXiv preprint arXiv:2003.05689 (2020).
[6] Kingma, Diederik P., and Jimmy Ba. “Adam: A method for stochastic optimization.” arXiv preprint arXiv:1412.6980 (2014).
[7] Agarwal, Naman, Surbhi Goel, and Cyril Zhang. “Acceleration via fractal learning rate schedules.” International Conference on Machine Learning. PMLR, 2021.
[8] Smith, Leslie N. “A disciplined approach to neural network hyper-parameters: Part 1 — learning rate, batch size, momentum, and weight decay.” arXiv preprint arXiv:1803.09820 (2018).
[9] Li, Mengtian, Ersin Yumer, and Deva Ramanan. “Budgeted training: Rethinking deep neural network training under resource constraints.” arXiv preprint arXiv:1905.04753 (2019).
https://avoid.overfit.cn/post/21ffecd1fb604dab8b36f0fcd2546df9
相关文章:
深度学习中的学习率调度:循环学习率、SGDR、1cycle 等方法介绍及实践策略研究
深度学习实践者都知道,在训练神经网络时,正确设置学习率是使模型达到良好性能的关键因素之一。学习率通常会在训练过程中根据某种调度策略进行动态调整。调度策略的选择对训练质量也有很大影响。 大多数实践者采用一些广泛使用的学习率调度策略,例如阶梯式衰减或余弦退火。这些…...
Python毕业设计-基于 Python flask 的前程无忧招聘可视化系统,Python大数据招聘爬虫可视化分析
博主介绍:✌Java徐师兄、7年大厂程序员经历。全网粉丝13w、csdn博客专家、掘金/华为云等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇🏻 不…...

Linux初阶——线程(Part1)
一、线程概念 1、如何理解线程 说到线程,那么我们就要回到进程了。 1.1. 再谈进程 对一个进程来说,它在内存中是这样的: 图1.1-a 其中一个 task_struct 独享一个进程地址空间和一个页表。 而线程其实和进程差不多,是这样的&…...

SpringBoot后端开发常用工具详细介绍——flyway数据库版本控制工具
文章目录 什么是flyway简介为什么要使用flyway 流程介绍整合springboot添加pom文件配置flyway向resource/db/migration添加sql文件 注意事项1. 迁移报错2. 迁移顺序 参考 什么是flyway 简介 为什么要使用flyway 我们在开发时往往会有这样一种情况: 进行软件开发…...

CSS揭秘:7. 伪随机背景
前置知识:CSS 渐变,5. 条纹背景,6. 复杂的背景图案 前言 本篇主要内容依然是关于背景的,无限平铺的背景会显得整齐美观,但又有些呆板,如何实现背景的多样性和随机性,是本篇的核心。 一、四种颜…...

SAP CODE DEMO:查找AL11 指定路径下文件中的内容
有时候需要查找某个具体的内容,在哪个文件内。数据量大的时候可以利用程序查找 选择界面: 路径,和文件名都可以模糊搜查 search string:你要查找的信息。 代码参考如下: report z00R010 NO STANDARD PAGE HEADING…...

【华为HCIP实战课程二十四】中间到中间系统协议IS-IS配置实战,网络工程师
一、IS-IS整体架构 将Level-1路由器部署在非骨干区域,Level-2路由器和Level-1-2路由器部署在骨干区域。 每一个非骨干区域都通过Level-1-2路由器与骨干区域相连! 1、在IS-IS中,每个链路可以属于不同的区域,OSPF中每个链路属于同一个区域 2、在IS-IS中,单个区域没有物理…...

【工具】新手礼包之git相关环境包括中文的一套流程{收集和整理},gitlab的使用
【工具】新手礼包之git相关环境包括中文的一套流程{收集和整理} git Git 详细安装教程(详解 Git 安装过程的每一个步骤) TortoiseGit 【TortoiseGit】TortoiseGit安装和配置详细说明...

篇章十一 打包构建工具
文章目录 一、gulp1. 流2. gulp 的作用3. gulp 的安装、检测和卸载 二、webpack1. 打包样式资源2. 打包 html 资源3. 打包图片资源4. 压缩 html 代码5. 生产环境基本配置 三、vite 打包构建工具,都是依赖于 node 环境进行开发,底层封装的内容就是 node 里…...

青少年编程与数学 02-002 Sql Server 数据库应用 06课题、数据库操作
青少年编程与数学 02-002 Sql Server 数据库应用 06课题、数据库操作 课题摘要:一、数据库的文件组成二、系统数据库三、创建数据库四、数据库配置1. 修改数据库文件大小和增长设置2. 添加或移除数据文件3. 设置数据库选项4. 配置数据库的恢复模型5. 管理数据库的访问权限6. 使…...

MacOS下载安装Logisim(图文教程)
本章教程主要介绍如何在MacOS系统中安装Logisim。 一、Logisim是什么? Logisim是一个用于电子逻辑门电路模拟的教育工具软件。它允许用户通过图形界面构建和测试复杂的数字逻辑电路,如加法器、解码器、编码器、寄存器、内存等,从而帮助学生理解计算机硬件的工作原理。 二、如…...

Flink CDC系列之:调研应用Flink CDC将 ELT 从 MySQL 流式传输到 StarRocks方案
Flink CDC系列之:调研应用Flink CDC将 ELT 从 MySQL 流式传输到 StarRocks方案 准备准备 Flink Standalone 集群准备 docker compose为 MySQL 准备记录使用 Flink CDC CLI 提交作业 同步架构和数据更改路由变更清理 本教程将展示如何使用 Flink CDC 快速构建从 MySQ…...

一次元空间FullGC导致OOM问题分析
原文,作者:kkyeer 原文需要翻墙,所以转载。 现象 观测平台告警:FullGC次数大于阈值,5分钟内大于11次,频次大概1-2周有一次 告警后服务概率性会自动恢复,控制台打印 Exception: java.lang.OutOf…...

Web前端开发工具和依赖安装
各种安装: node.js https://nodejs.org/zh-cn/ 安装完node.js 可以使用npm,npm跟随nodejs一起安装 node --version 查看已安装node.js的版本,确认是否安装nodejs npm -v 查看npm版本npm install <Module Name> 安装模块 npm insta…...

【学习心得】远程root用户访问服务器中的MySQL8
一、Ubuntu下的MySQL8安装 在Ubuntu系统中安装MySQL 8.0可以通过以下步骤进行1. 更新包管理工具的仓库列表: sudo apt update 2. 安装MySQL 8.0,root用户默认没有密码: sudo apt install mysql-server sudo apt install mysql-client 【…...

lust变频器维修电梯变频器CDD34.014.W2.1LSPC1
LUST伺服在安装时须注意,不可有任何的铁屑、螺丝、导线等掉人驱动器内。在安装完成后应作基本的检测动作,如对地阻抗,和短路检测等。 所有的安装及使用事项需要符合安全规定,并且也需要符合当地的相关规定和灾害预防措施。DC BUS…...
跨越地域限制:在线原型设计软件的自由与便捷
网络原型设计软件因其便捷性和灵活性,在现代设计工作中扮演着至关重要的角色。与传统的桌面端软件相比,网络原型设计工具无需安装,不受地域限制,且兼容各种操作系统,无论是Linux、Solaris、Mac还是Windows,…...

flash-waimai:高仿饿了么外卖平台,使用他轻松打造自己的外卖平台
嗨,大家好,我是小华同学,关注我们获得“最新、最全、最优质”开源项目和工作学习方法 flash-waimai 是一个完整的外卖平台解决方案,包括手机端、后台管理端和 API 服务。该项目仿照了饿了么的外卖服务,为用户提供了一个…...
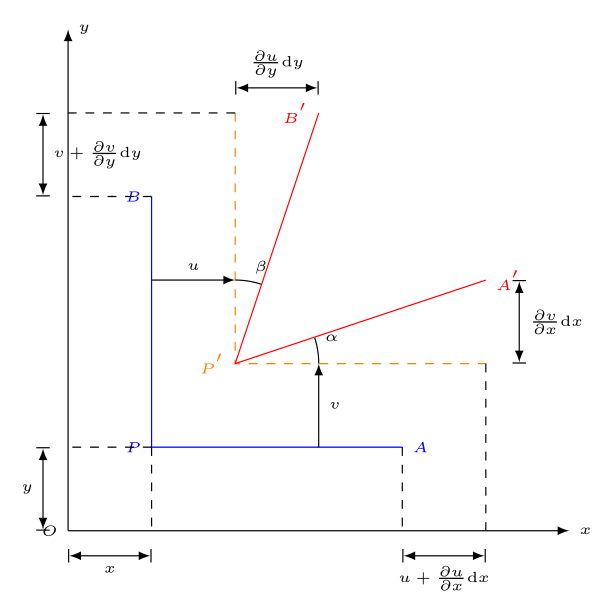
2.5 塑性力学—应变状态
个人专栏—塑性力学 1.1 塑性力学基本概念 塑性力学基本概念 1.2 弹塑性材料的三杆桁架分析 弹塑性材料的三杆桁架分析 1.3 加载路径对桁架的影响 加载路径对桁架的影响 2.1 塑性力学——应力分析基本概念 应力分析基本概念 2.2 塑性力学——主应力、主方向、不变量 主应力、主…...

1.机器人抓取与操作介绍-深蓝学院
介绍 操作任务 操作 • Insertion • Pushing and sliding • 其它操作任务 抓取 • 两指(平行夹爪)抓取 • 灵巧手抓取 7轴 Franka 对应人的手臂 6轴 UR构型去掉一个自由度 课程大纲 Robotic Manipulation 操作 • Robotic manipulation refers…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...
Android屏幕刷新率与FPS(Frames Per Second) 120hz
Android屏幕刷新率与FPS(Frames Per Second) 120hz 屏幕刷新率是屏幕每秒钟刷新显示内容的次数,单位是赫兹(Hz)。 60Hz 屏幕:每秒刷新 60 次,每次刷新间隔约 16.67ms 90Hz 屏幕:每秒刷新 90 次,…...
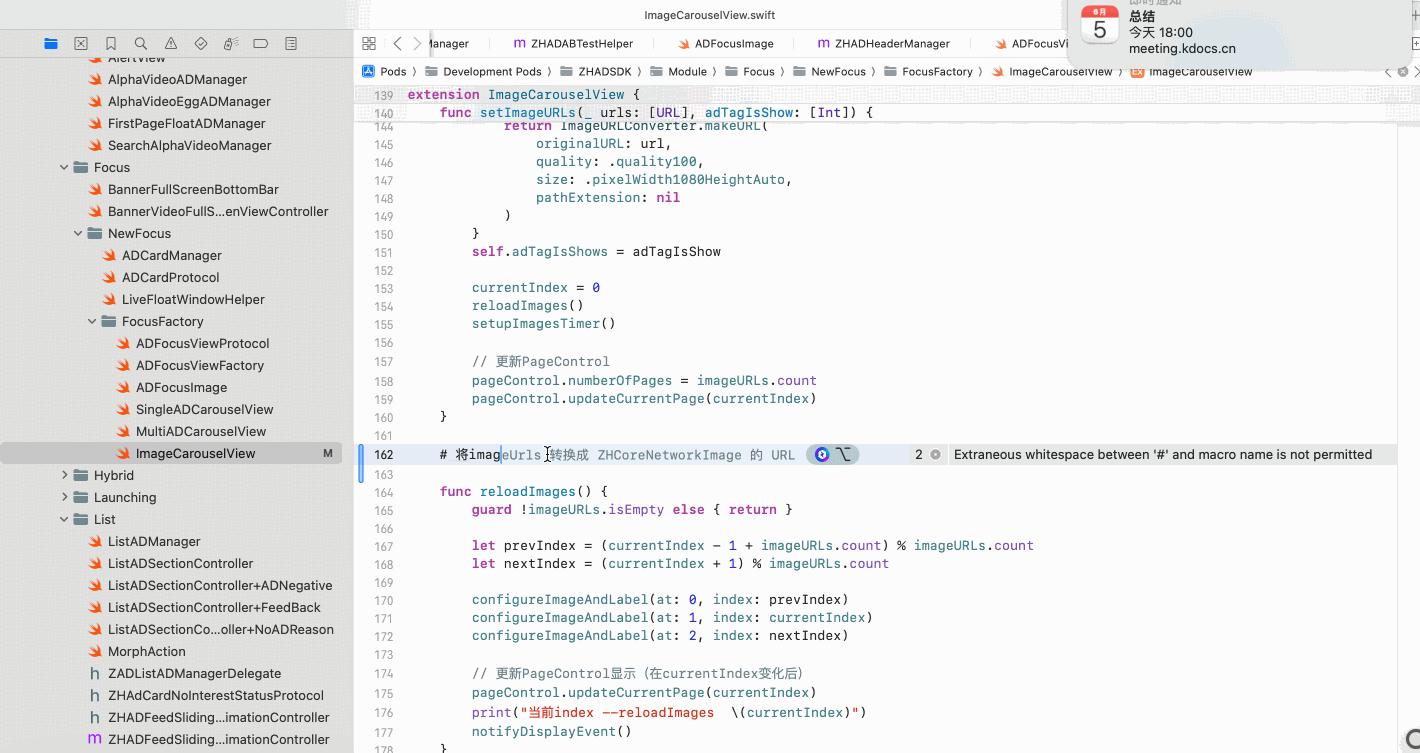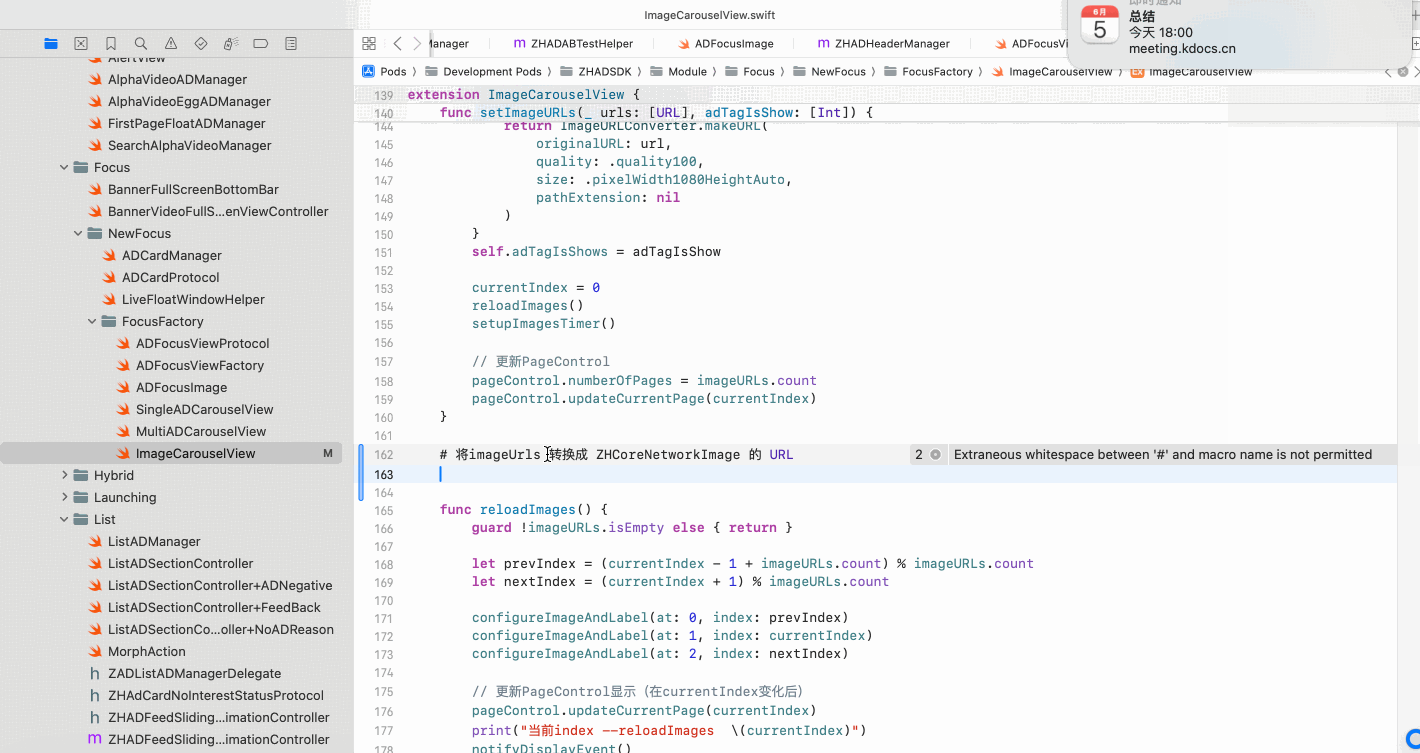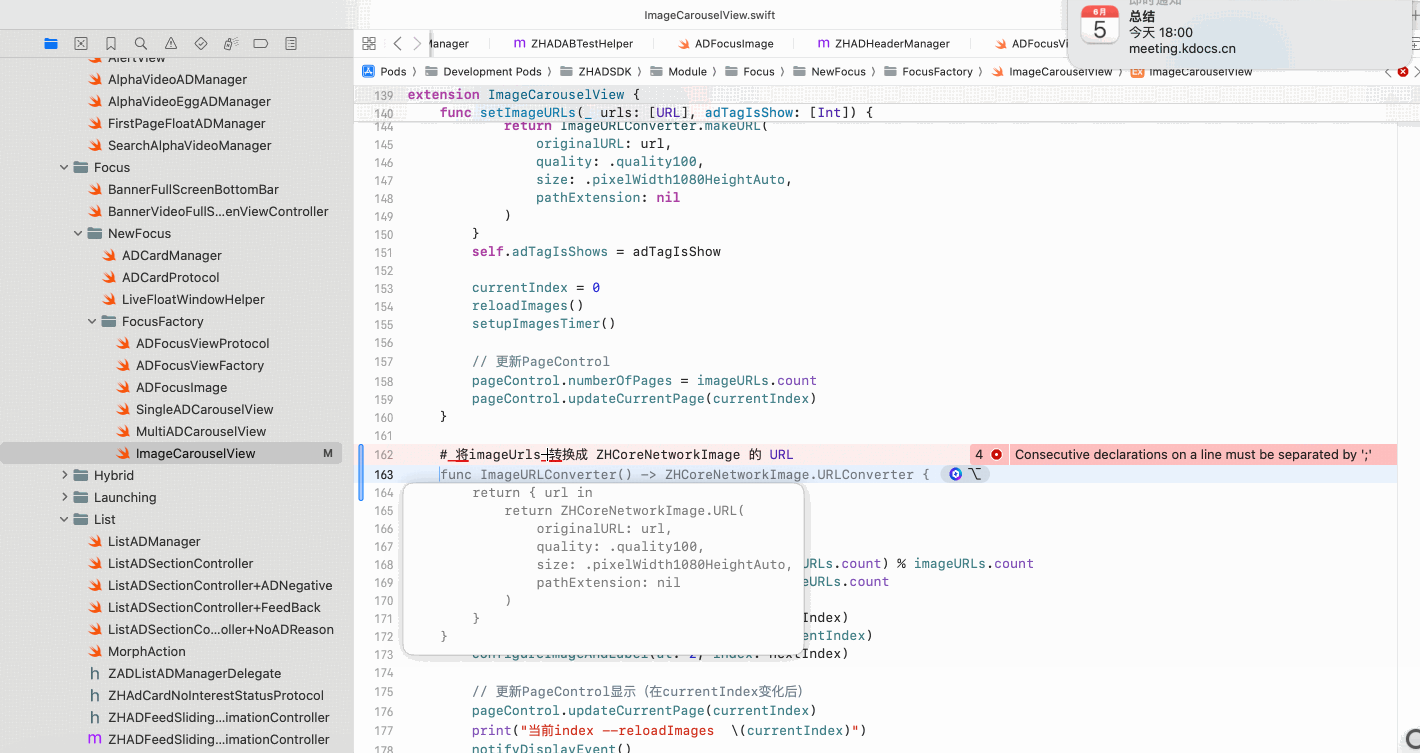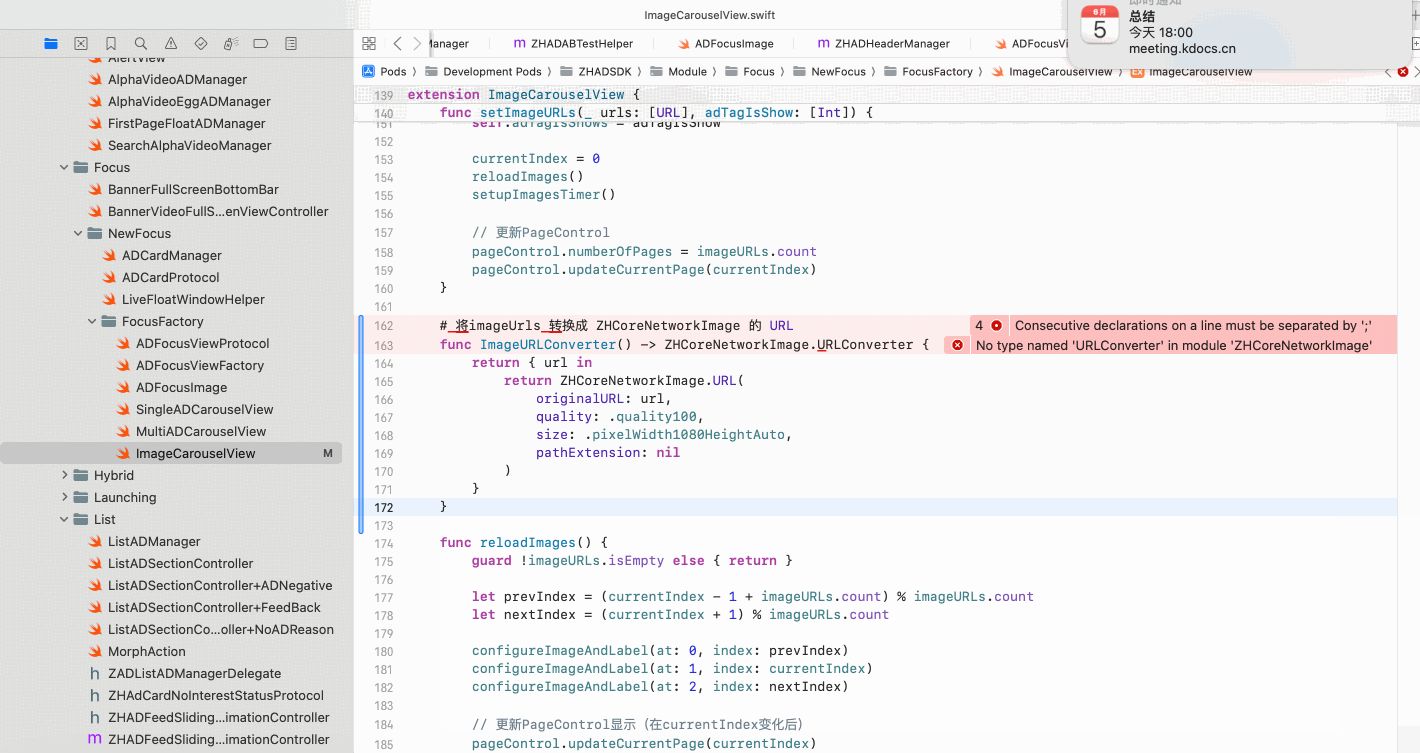
Copilot for Xcode (iOS的 AI辅助编程)
Copilot for Xcode 简介Copilot下载与安装 体验环境要求下载最新的安装包安装登录系统权限设置 AI辅助编程生成注释代码补全简单需求代码生成辅助编程行间代码生成注释联想 代码生成 总结 简介 尝试使用了Copilot,它能根据上下文补全代码,快速生成常用…...

Qt/C++学习系列之列表使用记录
Qt/C学习系列之列表使用记录 前言列表的初始化界面初始化设置名称获取简单设置 单元格存储总结 前言 列表的使用主要基于QTableWidget控件,同步使用QTableWidgetItem进行单元格的设置,最后可以使用QAxObject进行单元格的数据读出将数据进行存储。接下来…...
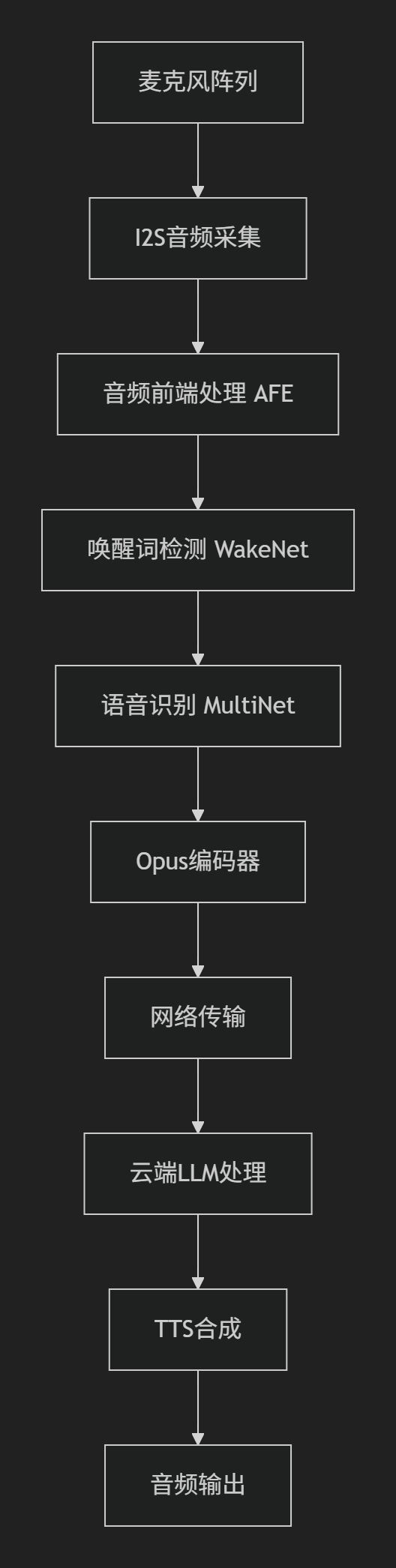
SDU棋界精灵——硬件程序ESP32实现opus编码
一、 音频处理框架 该项目基于Espressif的音频处理框架构建,核心组件包括 ESP-ADF 和 ESP-SR,以下是完整的音频处理框架实现细节: 1.核心组件 (1) 音频前端处理 (AFE - Audio Front-End) main/components/audio_pipeline/afe_processor.c功能: 声学回声…...
网络安全问题及对策研究
摘 要 网络安全问题一直是近年来社会乃至全世界十分关注的重要性问题,网络关乎着我们的生活,政治,经济等多个方面,致力解决网络安全问题以及给出行之有效的安全策略是网络安全领域的一大目标。 本论文简述了课题的开发背景&…...

设计模式-观察着模式
观察者模式 观察者模式 (Observer Pattern) 是一种行为型设计模式,它定义了对象之间一种一对多的依赖关系,当一个对象(称为主题或可观察者)的状态发生改变时,所有依赖于它的对象(称为观察者)都…...