VQGAN(2021-06:Taming Transformers for High-Resolution Image Synthesis)
论文:Taming Transformers for High-Resolution Image Synthesis
1. 背景介绍
2022年中旬,以扩散模型为核心的图像生成模型将AI绘画带入了大众的视野。实际上,在更早的一年之前,就有了一个能根据文字生成高清图片的模型——VQGAN。VQGAN不仅本身具有强大的图像生成能力,更是传承了前作VQVAE把图像压缩成离散编码的思想,推广了「先压缩,再生成」的两阶段图像生成思路,启发了无数后续工作。

在这篇文章中,我将对VQGAN的论文和源码中的关键部分做出解读,提炼出VQGAN中的关键知识点。由于VQGAN的核心思想和VQVAE如出一辙,我不会过多地介绍VQGAN的核心思想,强烈建议读者先去学懂VQVAE,再来看VQGAN。
1.1 VQGAN 核心思想
VQGAN的论文名为Taming Transformers for High-Resolution Image Synthesis,直译过来是「驯服Transformer模型以实现高清图像合成」。可以看出,该方法是在用Transformer生成图像。可是,为什么这个模型叫做VQGAN,是一个GAN呢?这是因为,VQGAN使用了两阶段的图像生成方法:
训练时,先训练一个图像压缩模型(包括编码器和解码器两个子模型),再训练一个生成压缩图像的模型。
生成时,先用第二个模型生成出一个压缩图像,再用第一个模型复原成真实图像。
其中,第一个图像压缩模型叫做VQGAN,第二个压缩图像生成模型是一个基于Transformer的模型。
为什么会有这种乍看起来非常麻烦的图像生成方法呢?要理解VQGAN的这种设计动机,有两条路线可以走。两条路线看待问题的角度不同,但实际上是在讲同一件事。
第一条路线是从Transformer入手。Transformer已经在文本生成领域大展身手。同时,Transformer也在视觉任务中开始崭露头角。相比擅长捕捉局部特征的CNN,Transformer的优势在于它能更好地融合图像的全局信息。可是,Transformer的自注意力操作开销太大,只能生成一些分辨率较低的图像。因此,作者认为,可以综合CNN和Transformer的优势,先用基于CNN的VQGAN把图像压缩成一个尺寸更小、信息更丰富的小图像,再用Transformer来生成小图像。
第二条路线是从VQVAE入手。VQVAE是VQGAN的前作,它有着和VQGAN一模一样两阶段图像生成方法。不同的是,VQVAE没有使用GAN结构,且其配套的压缩图像生成模型是基于CNN的。为提升VQVAE的生成效果,作者提出了两项改进策略:1) 图像压缩模型VQVAE仅使用了均方误差,压缩图像的复原结果较为模糊,可以把图像压缩模型换成GAN;2) 在生成压缩图片这个任务上,基于CNN的图像生成模型比不过Transformer,可以用Transformer代替原来的CNN。
第一条思路是作者在论文的引言中描述的,听起来比较高大上;而第二条思路是读者读过文章后能够自然总结出来的,相对来说比较清晰易懂。如果你已经理解了VQVAE,你能通过第二条思路瞬间弄懂VQGAN的原理。说难听点,VQGAN就是一个改进版的VQVAE。然而,VQGAN的改进非常有效,且使用了若干技巧来实现带约束(比如根据文字描述)的高清图像生成,有非常多地方值得学习。
在下文中,我将先补充VQVAE的背景以方便讨论,再介绍VQGAN论文的四大知识点:VQGAN的设计细节、生成压缩图像的Transformer的设计细节、带约束图像生成的实现方法、高清图像生成的实现方法。
1.2 VQVAE 背景知识补充
VQVAE的学习目标是用一个编码器把图像压缩成离散编码,再用一个解码器把图像尽可能地还原回原图像。

通俗来说,VQVAE就是把一幅真实图像压缩成一个小图像。这个小图像和真实图像有着一些相同的性质:小图像的取值和像素值(0-255的整数)一样,都是离散的;小图像依然是二维的,保留了某些空间信息。因此,VQVAE的示意图画成这样会更形象一些:

但小图像和真实图像有一个关键性的区别:与像素值不同,小图像的离散取值之间没有关联。真实图像的像素值其实是一个连续颜色的离散采样,相邻的颜色值也更加相似。比如颜色254和颜色253和颜色255比较相似。而小图像的取值之间是没有关联的,你不能说编码为1与编码为0和编码为2比较相似。由于神经网络不能很好地处理这种离散量,在实际实现中,编码并不是以整数表示的,而是以类似于NLP中的嵌入向量的形式表示的。VAE使用了嵌入空间(又称codebook)来完成整数序号到向量的转换。

为了让任意一个编码器输出向量都变成一个固定的嵌入向量,VQVAE采取了一种离散化策略:把每个输出向量 z e ( x ) z_e(x) ze(x)替换成嵌入空间中最近的那个向量 z q ( x ) z_q(x) zq(x)。 z e ( x ) z_e(x) ze(x)的离散编码就是 z q ( x ) z_q(x) zq(x)在嵌入空间的下标。这个过程和把254.9的输出颜色值离散化成255的整数颜色值的原理类似。

VQVAE的损失函数由两部分组成:重建误差和嵌入空间误差:
L V Q = L r e c o n s t r u c t + L e m b e d d i n g L_{VQ}=L_{reconstruct}+L_{embedding} LVQ=Lreconstruct+Lembedding
其中,重建误差就是输入和输出之间的均方误差:
L r e c o n s t r u c t = ∣ ∣ x − x ^ ∣ ∣ 2 2 L_{reconstruct}=\left|\left|x-\hat{x}\right|\right|_2^2 Lreconstruct=∣∣x−x^∣∣22
嵌入空间误差为解码器输出向量 z e ( x ) \text{嵌入空间误差为解码器输出向量}z_e(x) 嵌入空间误差为解码器输出向量ze(x)
和它在嵌入空间对应向量 z q ( x ) 的均方误差。 L e m b e d d i n g = ∣ ∣ z e ( x ) − z q ( x ) ∣ ∣ 2 2 \text{和它在嵌入空间对应向量}z_q(x)\text {的均方误差。}\\L_{embedding}=||z_e(x)-z_q(x)||_2^2 和它在嵌入空间对应向量zq(x)的均方误差。Lembedding=∣∣ze(x)−zq(x)∣∣22
作者在误差中还使用了一种「停止梯度」的技巧。这个技巧在VQGAN中被完全保留,此处就不过多介绍了(可以看我上一篇介绍VQVAE的帖子)。
2. 技术细节

2.1 图像压缩模型 VQGAN
回顾了VQVAE的背景知识后,我们来正式认识VQGAN的几个创新点。第一点,图像压缩模型VQVAE被改进成了VQGAN。
一般VAE重建出来出来的图像都会比较模糊。这是因为VAE只使用了均方误差,而均方误差只能保证像素值尽可能接近,却不能保证图像的感知效果更加接近。为此,作者把GAN的一些方法引入VQVAE,改造出了VQGAN。
具体来说,VQGAN有两项改进。第一,作者用感知误差(perceptual loss)代替原来的均方误差作为VQGAN的重建误差。第二,作者引入了GAN的对抗训练机制,加入了一个基于图块的判别器,把GAN误差加入了总误差。
1.计算感知误差的方法如下:把两幅图像分别输入VGG,取出中间某几层卷积层的特征,计算特征图像之间的均方误差。如果你之前没学过相关知识,请搜索"perceptual loss"。
2.基于图块的判别器,即判别器不为整幅图输出一个真或假的判断结果,而是把图像拆成若干图块,分别输出每个图块的判断结果,再对所有图块的判断结果取一个均值。这只是GAN的一种改进策略而已,没有对GAN本身做太大的改动。如果你之前没学过相关知识,请搜索"PatchGAN"。
这样,总的误差可以写成:
L = L V Q + λ L G A N L=L_{VQ}+\lambda L_{GAN} L=LVQ+λLGAN
其中, λ \lambda λ是控制两种误差比例的权重。作者在论文中使用了一个公式来自适应地设置 λ \lambda λ。和普通的GAN一样,VQGAN的编码器、解码器(即生成器)、codebook会最小化误差,判别器会最大化误差。
用VQGAN代替VQVAE后,重建图片中的模糊纹理清晰了很多:

有了一个保真度高的图像压缩模型,我们可以进入下一步,训练一个生成压缩图像的模型。
2.2 基于 Transformer 的压缩图像生成模型
如前所述,经VQGAN得到的压缩图像与真实图像有一个本质性的不同:真实图像的像素值具有连续性,相邻的颜色更加相似,而压缩图像的像素值则没有这种连续性。压缩图像的这一特性让寻找一个压缩图像生成模型变得异常困难。多数强大的真实图像生成模型(比如GAN)都是输出一个连续的浮点颜色值,再做一个浮点转整数的操作,得到最终的像素值。而对于压缩图像来说,这种输出连续颜色的模型都不适用了。因此,之前的VQVAE使用了一个能建模离散颜色的PixelCNN模型作为压缩图像生成模型。但PixelCNN的表现不够优秀。
恰好,功能强大的Transformer天生就支持建模离散的输出。在NLP中,每个单词都可以用一个离散的数字表示。Transformer会不断生成表示单词的数字,以达到生成句子的效果:

为了让Transformer生成图像,我们可以把生成句子的一个个单词,变成生成压缩图像的一个个像素。但是,要让Transformer生成二维图像,还需要克服一个问题:在生成句子时,Transformer会先生成第一个单词,再根据第一个单词生成第二个单词,再根据第一、第二个单词生成第三个单词……。也就是说,Transformer每次会根据之前所有的单词来生成下一单词。而图像是二维数据,没有先后的概念,怎样让像素和文字一样有先后顺序呢?
VQGAN的作者使用了自回归图像生成模型的常用做法,给图像的每个像素从左到右,从上到下规定一个顺序。有了先后顺序后,图像就可以被视为一个一维句子,可以用Transfomer生成句子的方式来生成图像了。在第 i i i步,Transformer会根据前 i − 1 i-1 i−1个像素 s < i 生成第 i 个像素 S i s_{<i}\text{生成第}i\text{个像素}S_i s<i生成第i个像素Si

2.3 带约束的图像生成
在生成新图像时,我们更希望模型能够根据我们的需求生成图像。比如,我们希望模型生成「一幅优美的风景画」,又或者希望模型在一幅草图的基础上作画。这些需求就是模型的约束。为了实现带约束的图像生成,一般的做法是先有一个无约束(输入是随机数)的图像生成模型,再在这个模型的基础上把一个表示约束的向量插入进图像生成的某一步。
把约束向量插入进模型的方法是需要设计的,插入约束向量的方法往往和模型架构有着密切关系。比如假设一个生成模型是U-Net架构,我们可以把约束向量和当前特征图拼接在一起,输入进U-Net的每一大层。
为了实现带约束的图像生成,VQGAN的作者再次借鉴了Transformer实现带约束文字生成的方法。许多自然语言处理任务都可以看成是带约束的文字生成。比如机器翻译,其实可以看成在给定一种语言的句子的前提下,让模型「随机」生成一个另一种语言的句子。比如要把「简要访问非洲」翻译成英语,我们可以对之前无约束文字生成的Transformer做一些修改。

也就是说,给定约束的句子 c c c,在第 i i i步,Transformer会根据前 i − 1 i-1 i−1个输出单词 s < i s_{<i} s<i以及 c c c生成第 i i i个单词 s i s_i si。表示约束的单词被添加到了所有输出之前,作为这次「随机生成」的额外输入。
上述方法并不是唯一的文字生成方法。这种文字生成方法被称为"decoder-only"。实际上,也有使用一个编码器来额外维护约束信息的文字生成方法。最早的Transformer就用到了带编码器的方法。
我们同样可以把这种思想搬到压缩图像生成里。比如对于MNIST数据集,我们希望模型只生成 0 ∼ 9 0\sim9 0∼9这些数字中某一个数字的手写图像。也就是说,约束是类别信息,约束的取值是 0 ∼ 9 0\sim9 0∼9。我们就可以把这个 0 ∼ 9 0\sim9 0∼9的约束信息添加到Transformer的输入 s < i s_{<i} s<i之前,以实现由类别约束的图像生成。

但这种设计又会产生一个新的问题。假设约束条件不能简单地表示成整数,而是一些其他类型的数据,比如语义分割图像,那该怎么办呢?对于这种以图像形式表示的约束,作者的做法是,再训练另一个VQGAN,把约束图像压缩成另一套压缩图片。这一套压缩图片和生成图像的压缩图片有着不同的codebook,就像两种语言有着不同的单词一样。这样,约束图像也变成了一系列的整数,可以用之前的方法进行带约束图像生成了。

2.4 生成高清图像
由于Transformer注意力计算的开销很大,作者在所有配置中都只使用了 16 × 16 16\times16 16×16的压缩图像,再增大压缩图像尺寸的话计算资源就不够了。而另一方面,每张图像在VQGAN中的压缩比例是有限的。如果图像压缩得过多,则VQGAN的重建质量就不够好了。因此,设边长压缩了 f f f倍,则该方法一次能生成的图片的最大尺寸是 16 f × 16 f 16f\times16f 16f×16f。在多项实验中, f = 16 f=16 f=16的表现都较好。这样算下来,该方法一次只能生成 256 × 256 256\times256 256×256的图片。这种尺寸的图片还称不上高清图片。
为了生成更大尺寸的图片,作者先训练好了一套能生成 256 × 256 256\times256 256×256的图片的
VQGAN+Transformer,再用了一种基于滑动窗口的采样机制来生成大图片。具体来说,作者把待生成图片划分成若干个 16 × 16 16\times16 16×16像素的图块,每个图块对应压缩图像的一个像素。之后,在每一轮生成时,只有待生成图块周围的 16 × 16 16\times16 16×16个图块 ( 256 × 256 (256\times256 (256×256个像素)会被输入进VQGAN和Transformer, 由Transformer生成一个新的压缩图像像素,再把该压缩图像像素解码成图块。(在下面的示意图中,每个方块是一个图块,transformer的输入是 3 × 3 3\times3 3×3个图块)

这个滑动窗口算法不是那么好理解,需要多想一下才能理解它的具体做法。在理解这个算法时,你可能会有这样的问题:上面的示意图中,待生成像素有的时候在最左边,有的时候在中间,有的时候在右边,每次约束它的像素都不一样。这么复杂的约束逻辑怎么编写?其实,Transformer自动保证了每个像素只会由之前的像素约束,而看不到后面的像素。因此,在实现时,只需要把待生成像素框起来,直接用Transformer预测待生成像素即可,不需要编写额外的约束逻辑。
如果你没有学过Transformer的话,理解这部分会有点困难。Transformer可以根据第1k-1个像素并行地生成第2k个像素,且保证生成每个像素时不会偷看到后面像素的信息。因此,假设我们要生成第i个像素,其实是预测了所有第2~k个像素的结果,再取出第i个结果,填回待生成图像。
由于论文篇幅有限,作者没有对滑动窗口机制做过多的介绍,也没有讲带约束的滑动窗口是怎么实现的。如果时间充裕,我之后会更新代码阅读章节
作者在论文中解释了为什么用滑动窗口生成高清图像是合理的。作者先是讨论了两种情况,只要满足这两种情况中的任意一种,拿滑动窗口生成图像就是合理的。第一种情况是数据集的统计规律是几乎空间不变,也就是说训练集图片每 256 × 256 256\times256 256×256个像素的统计规律是类似的。这和我们拿 3 × 3 3\times3 3×3卷积卷图像是因为图像每 3 × 3 3\times3 3×3个像素的统计规律类似的原理是一样的。第二种情况是有空间上的约束信息。比如之前提到的用语义分割图来指导图像生成。由于语义分割也是一张图片,它给每个待生成像素都提供了额外信息。这样,哪怕是用滑动窗口,在局部语义的指导下,模型也足以生成图像了。
若是两种情况都不满足呢?比如在对齐的人脸数据集上做无约束生成。在对齐的人脸数据集里,每张图片中人的五官所在的坐标是差不多的,图片的空间不变性不满足;做无约束生成,自然也没有额外的空间信息。在这种情况下,我们可以人为地添加一个坐标约束,即从左到右、从上到下地给每个像素标一个序号,把每个滑动窗口里的坐标序号做为约束。有了坐标约束后,就还原成了上面的第二种情况,每个像素有了额外的空间信息,基于滑动窗口的方法依然可行。

学完了论文的四大知识点,我们知道VQGAN是怎么根据约束生成高清图像的了。接下来,我们来看看论文的实验部分,看看作者是怎么证明方法的有效性的。
3. 实验
在实验部分,作者先是分别验证了基于Transformer的压缩图像生成模型较以往模型的优越性(4.1节)、VQGAN较以往模型的优越性(4.4节末尾)、使用VQGAN做图像压缩的必要性及相关消融实验(4.3节),再把整个生成方法综合起来,在多项图像生成任务上与以往的图像生成模型做定量对比(4.4节),最后展示了该方法惊艳的带约束生成效果(4.2节)。
在论文4.1节中,作者验证了基于Transformer的压缩图像生成模型的有效性。之前,压缩图像都是使用能输出离散分布的PixelCNN系列模型来生成的。PixelCNN系列的最强模型是PixelSNAIL。为确保公平,作者对比了相同训练时间、相同训练步数下两个网络在不同训练集下的负对数似然(NLL)指标。结果表明,基于Transformer的模型确实训练得更快。
对于直接能建模离散分布的模型来说,NLL就是交叉熵损失函数。

在论文4.4节末尾,作者将VQGAN和之前的图像压缩模型对比,验证了引入感知误差和GAN结构的有效性。作者汇报了各模型重建图像集与原数据集(ImageNet的训练集和验证集)的FID(指标FID是越低越好)。同时,结果也说明,增大codebook的尺寸或者编码种类都能提升重建效果。

在论文4.3节中,作者验证了使用VQGAN的必要性。作者训了两个模型,一个直接让Transformer做真实图像生成,一个用VQGAN把图像边长压缩2倍,再用Transformer生成压缩图像。经比较,使用了VQGAN后,图像生成速度快了10多倍,且图像生成效果也有所提升。
另外,作者还做了有关图像边长压缩比例 f f f的消融实验。作者固定让Transformer生成 16 × 16 16\times16 16×16的压缩图片,即每次训练时用到的图像尺寸都是 16 f × 16 f 16f\times16f 16f×16f。之后,作者训练训练了不同 f f f下的模型,用各个模型来生成图片。结果显示 f = 16 f=16 f=16时效果最好。这是因为,在固定Transformer的生成分辨率的前提下, f f f越小,Transformer的感受野越小。如果Transformer的感受野过小,就学习不到足够的信息。

在论文4.4节中,作者探究了VQGAN+Transformer在多项基准测试(benchmark)上的结果。
首先是语义图像合成(根据语义分割图像来生成)任务。本文的这套方法还不错。

接着是人脸生成任务。这套方法表现还行,但还是比不过专精于某一任务的GAN:

作者还比较了各模型在ImageNet上的生成结果。这一比较的数据量较多,欢迎大家自行阅读原论文。
在论文4.2节中,作者展示了多才多艺的VQGAN+Transformer在各种约束下的图像生成结果。这些图像都是按照默认配置生成的,大小为 256 × 256 256\times256 256×256。

作者还展示了使用了滑动窗口算法后,模型生成的不同分辨率的图像:

本文开头的那张高清图片也来自论文。
4. 总结
VQGAN是一个改进版的VQVAE,它将感知误差和GAN引入了图像压缩模型,把压缩图像生成模型替换成了更强大的Transformer。相比纯种的GAN(如StyleGAN),VQGAN的强大之处在于它支持带约束的高清图像生成。VQGAN借助NLP中"decoder-only"策略实现了带约束图像生成,并使用滑动窗口机制实现了高清图像生成。虽然在某些特定任务上VQGAN还是落后于其他GAN,但VQGAN的泛化性和灵活性都要比纯种GAN要强。它的这些潜力直接促成了Stable Diffusion的诞生。
如果你是读完了VQVAE再来读的VQGAN,为了完全理解VQGAN,你只需要掌握本文提到的4个知识点:VQVAE到VQGAN的改进方法、使用Transformer做图像生成的方法、使用"decoder-only"策略做带约束图像生成的方法、用滑动滑动窗口生成任意尺寸的图片的思想。
代码讲解大家可以移步到周教授的知乎讲解很细致:https://zhuanlan.zhihu.com/p/637705399
5. 参考文献
- VQGAN 论文与源码解读:前Diffusion时代的高清图像生成模型
- VQGAN论文
- VQGAN GitHub
相关文章:
VQGAN(2021-06:Taming Transformers for High-Resolution Image Synthesis)
论文:Taming Transformers for High-Resolution Image Synthesis 1. 背景介绍 2022年中旬,以扩散模型为核心的图像生成模型将AI绘画带入了大众的视野。实际上,在更早的一年之前,就有了一个能根据文字生成高清图片的模型——VQGAN…...

docker中使用ros2humble的rviz2不显示问题
这里写目录标题 docker中使用ros2humble的rviz2不显示问题删除 Docker 镜像和容器删除 Docker 容器Linux服务器下查看系统CPU个数、核心数、(make编译最大的)线程数总结: RVIZ2 不能显示数据集 docker中使用ros2humble的rviz2不显示问题 问题描述: roo…...

【AIGC】2024-arXiv-Lumiere:视频生成的时空扩散模型
2024-arXiv-Lumiere: A Space-Time Diffusion Model for Video Generation Lumiere:视频生成的时空扩散模型摘要1. 引言2. 相关工作3. Lumiere3.1 时空 U-Net (STUnet)3.2 空间超分辨率的多重扩散 4. 应用4.1 风格化生成4.2 条件生成 5. 评估和比较5.1 定性评估5.2 …...

正则表达式:文本处理的强大工具
正则表达式是一种强大的文本处理工具,它允许我们通过定义一系列的规则来匹配、搜索、替换或分割文本。在编程、文本编辑、数据分析和许多其他领域中,正则表达式都扮演着重要的角色。本文将介绍正则表达式的基本概念、语法和一些实际应用。 正则表达式的…...

Doris单机安装
1、安装包下载 官网地址:https://doris.apache.org/zh-CN/docs/gettingStarted/quick-start/ 下载地址:https://apache-doris-releases.oss-accelerate.aliyuncs.com/apache-doris-3.0.2-bin-x64.tar.gz 2、操作系统环境准备 #环境准备 cat /proc/cp…...

ubuntu内核更新导致显卡驱动掉的解决办法
方法1,DKMS指定内核版本 用第一个就行 1,借鉴别人博客解决方法 2,借鉴别人博客解决方法 方法2,删除多于内核的方法 系统版本:ubuntu20.24 这个方法是下下策,如果重装驱动还是不行,就删内核在…...

【Java数据结构】树】
【Java数据结构】树 一、树型结构1.1 概念1.2 特点1.3 树的类型1.4 树的遍历方式1.5 树的表示形式1.5.1 双亲表示法1.5.2 孩子表示法1.5.3 孩子双亲表示法1.5.4 孩子兄弟表示法 二、树型概念(重点) 此篇博客希望对你有所帮助(帮助你了解树&am…...

Java面试题——微服务篇
1.微服务的拆分原则/怎么样才算一个有效拆分 单一职责原则:每个微服务应该具有单一的责任。这意味着每个服务只关注于完成一项功能,并且该功能应该是独立且完整的。最小化通信:尽量减少服务之间的通信,服务间通信越少,…...

Python 中 print 函数输出多行并且选择对齐方式
代码 # 定义各类别的标签和对应数量 categories ["class0", "class1", "class2", "class3", "class4", "class5"] counts [4953, 547, 5121, 8989, 6077, 4002]# 设置统一的列宽 column_width 10# 生成对齐后…...

书生营L0G3000 Git 基础知识
任务1: 破冰活动:自我介绍 用vi就行了 按照教程来就好了 git会报错密码,输入的时候换成token就好了 https://stackoverflow.com/questions/68775869/message-support-for-password-authentication-was-removed 提交。(github上预览自己的…...

【C++初阶】模版入门看这一篇就够了
文章目录 1. 泛型编程2. 函数模板2. 1 函数模板概念2. 2 函数模板格式2. 3 函数模板的原理2. 4 函数模板的实例化2. 5 模板参数的匹配原则2. 6 补充:使用调试功能观察函数调用 3. 类模板3 .1 类模板的定义格式3. 2 类模板的实例化 1. 泛型编程 在C语言中࿰…...

Spring Bean创建流程
Spring Bean 创建流程图 大家总是会错误的理解Bean的“实例化”和“初始化”过程,总会以为初始化就是对象执行构造函数生成对象实例的过程,其实不然,在初始化阶段实际对象已经实例化出来了,初始化阶段进行的是依赖的注入和执行一…...
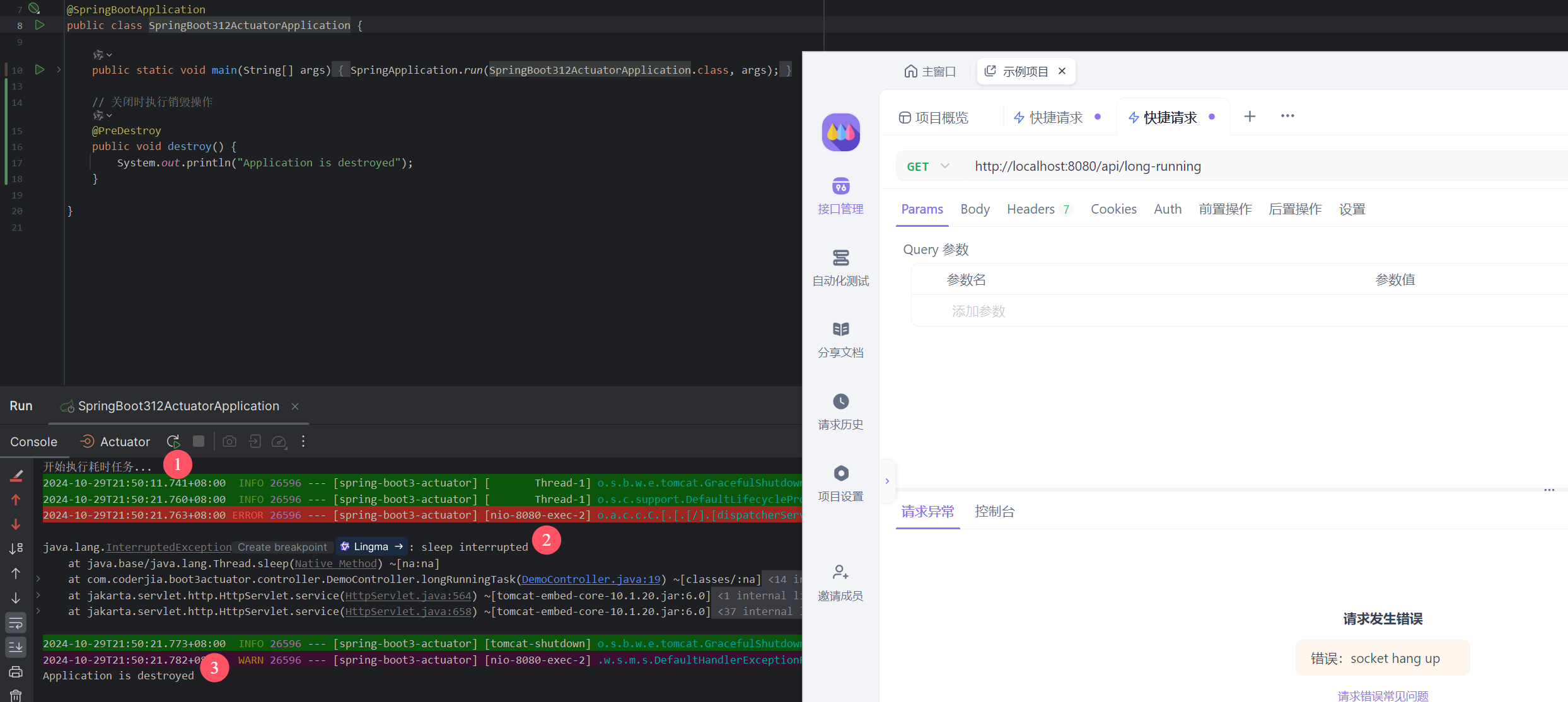
重学SpringBoot3-怎样优雅停机
更多SpringBoot3内容请关注我的专栏:《SpringBoot3》 期待您的点赞👍收藏⭐评论✍ 重学SpringBoot3-怎样优雅停机 1. 什么是优雅停机?2. Spring Boot 3 优雅停机的配置3. Tomcat 和 Reactor Netty 的优雅停机机制3.1 Tomcat 优雅停机3.2 Reac…...

【数据结构】顺序表和链表
1.线性表 我们在C语言当中学过数组,其实呢,数组可以实现线性表,线性表理解上类似于数组,那么什么是线性表呢?线性表是n个具有相同特性的数据元素的有限序列。线性表是一种在实际中广泛使 用的数据结构,常见…...

Training language models to follow instructions with human feedback解读
前置知识方法数据集结论 前置知识 GPT的全称是Generative Pre-Trained Transformer,预训练模型自诞生之始,一个备受诟病的问题就是预训练模型的偏见性。因为预训练模型都是通过海量数据在超大参数量级的模型上训练出来的,对比完全由人工规则…...

线性回归矩阵求解和梯度求解
正规方程求解线性回归 首先正规方程如下: Θ ( X T X ) − 1 X T y \begin{equation} \Theta (X^T X)^{-1} X^T y \end{equation} Θ(XTX)−1XTy 接下来通过线性代数的角度理解这个问题。 二维空间 在二维空间上,有两个向量 a a a和 b b b&…...

M3U8不知道如何转MP4?包能学会的4种格式转换教学!
在流媒体视频大量生产的今天,M3U8作为一种基于HTTP Live Streaming(HLS)协议的播放列表格式,广泛应用于网络视频直播和点播中。它包含了媒体播放列表的信息,指向了视频文件被分割成的多个TS(Transport Stre…...
)
C++第4课——swap、switch-case-for循环(含视频讲解)
文章目录 1、课程代码2、课程视频 1、课程代码 #include<iostream> using namespace std; int main(){/* //第一个任务:学会swap int a,b,c;//从小到大排序输出 升序 cin>>a>>b>>c;//5 4 3if(a>b)swap(a,b);//4 5 3 swap()函数是用于交…...

大数据新视界 -- 大数据大厂之大数据重塑影视娱乐产业的未来(4 - 4)
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...

在Java中,需要每120分钟刷新一次的`assetoken`,并且你想使用Redis作为缓存来存储和管理这个令牌
学习总结 1、掌握 JAVA入门到进阶知识(持续写作中……) 2、学会Oracle数据库入门到入土用法(创作中……) 3、手把手教你开发炫酷的vbs脚本制作(完善中……) 4、牛逼哄哄的 IDEA编程利器技巧(编写中……) 5、面经吐血整理的 面试技…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...