ClickHouse 神助攻:纽约城市公共交通管理(MTA)数据应用挑战赛

本文字数:13198;估计阅读时间:33 分钟
作者:The PME Team
本文在公众号【ClickHouseInc】首发

我们一向对开放数据挑战充满热情,所以当发现 MTA(城市交通管理局)在其官网发起了这样的挑战时,便跃跃欲试,积极参与。我们专注于闸机数据集,以分析纽约市的地铁使用情况,并在我们新的数据游乐场中免费开放此数据供用户查询。
MTA 负责纽约市的公共交通系统,涵盖地铁、公交和通勤铁路,每天服务数百万乘客。MTA 开放数据挑战是为期一个月的竞赛,面向开发者和数据爱好者,鼓励他们利用 MTA 的数据集创造性地开发项目,比如网页应用、数据可视化或报告。参赛作品需使用 data.ny.gov 上至少一个数据集,评审标准包括创意、实用性、执行效果及透明度。
MTA 提供了 176 个数据集供参赛者使用,大部分数据集较小,通常只有几百行。尽管这些数据资源极具价值,但其体量较小,难以充分发挥 ClickHouse 的优势。
ClickHouse 是专为大规模数据分析设计的 OLAP 数据库,因此我们选择了体量最大的闸机数据集进行探索。这个数据集汇总了多年来纽约市地铁站闸机的进出记录,约有 1 亿行数据,便于分析城市人流的流动情况。尽管该数据集看似简单,但为了清理并使之具备实际应用价值,我们付出了远超预期的努力。
该数据集涵盖 2014 至 2022 年的数据。针对最近几年的数据,有一个经过清理的版本可供使用,我们也加载了此版本并提供了示例查询。不过,为了完整呈现所有数据,我们在本文中将重点关注历史数据。
本文将详细介绍加载和清理这些数据的步骤,帮助大家在自己的 ClickHouse 实例中复现这些操作。这将展示 ClickHouse 在数据工程方面的关键功能,许多操作和查询同样适用于其他数据集。
对于只关心最终数据集的用户,我们已将其加载到新的 ClickHouse playground,您可以在其中尝试超过 220 个查询和 35 个数据集!如需贡献新的查询和数据集,欢迎访问我们的 demo 仓库。
本文的所有步骤都可以使用 clickhouse-local 复现。clickhouse-local 是 ClickHouse 的轻量版,非常适合开发人员在无需安装完整数据库的情况下,通过 SQL 快速处理本地和远程文件。
数据初步探索与加载
为了简化加载,我们将闸机数据(以 TSV 文件格式)存储在一个公共存储桶中。通过简单的 S3 查询就可以查看列信息,ClickHouse 会自动推断列的类型。
DESCRIBE TABLE s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/mta/*.tsv')
SETTINGS describe_compact_output = 1┌─name───────────────────────────────────────────────────────┬─type────────────────────┐
│ C/A │ Nullable(String) │
│ Unit │ Nullable(String) │
│ SCP │ Nullable(String) │
│ Station │ Nullable(String) │
│ Line Name │ Nullable(String) │
│ Division │ Nullable(String) │
│ Date │ Nullable(DateTime64(9)) │
│ Time │ Nullable(String) │
│ Description │ Nullable(String) │
│ Entries │ Nullable(Int64) │
│ Exits │ Nullable(Int64) │
└────────────────────────────────────────────────────────────┴─────────────────────────┘11 rows in set. Elapsed: 0.309 sec.抽样数据并查看数据集描述后可以发现,每行数据记录了某一时间点的闸机进出人次计数。描述显示这些计数的数据是周期性报告的,统计的是上一个时间段内的情况。以下是直接在 S3 中执行的查询示例:
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/mta/*.tsv')
LIMIT 1
FORMAT VerticalRow 1:
──────
C/A: A002
Unit: R051
SCP: 02-00-00
Station: LEXINGTON AVE
Line Name: NQR456
Division: BMT
Date: 2014-12-31 00:00:00.000000000
Time: 23:00:00
Description: REGULAR
Entries: 4943320
Exits : 16747361 rows in set. Elapsed: 1.113 sec.为简化处理并避免重复下载数据,我们可以将其加载到本地表中。使用推断的表结构创建该表并加载数据,命令如下。
CREATE TABLE subway_transits_2014_2022_raw
ENGINE = MergeTree
ORDER BY tuple() EMPTY
AS SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/mta/*.tsv')这会基于架构创建一个空表,我们将其作为数据探索的临时表,暂不使用排序键。数据加载可以简单地通过 INSERT INTO SELECT 完成:
INSERT INTO subway_transits_2014_2022_raw
SETTINGS max_insert_threads = 16, parallel_distributed_insert_select = 2
SELECT *
FROM s3Cluster('default', 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/mta/*.tsv')
SETTINGS max_insert_threads = 16, parallel_distributed_insert_select = 20 rows in set. Elapsed: 39.236 sec. Processed 94.88 million rows, 13.82 GB (2.42 million rows/s., 352.14 MB/s.)
Peak memory usage: 1.54 GiB.SELECT count()
FROM subway_transits_2014_2022_raw┌──count()─┐
│ 94875892 │ -- 94.88 million
└──────────┘1 row in set. Elapsed: 0.002 sec.为加快加载速度,我们应用了一些简单的优化,比如使用 s3Cluster 函数。详情可参考《优化 S3 插入和读取性能指南》。上述时间(包括之后的处理时间)是在我们 sql.clickhouse.com 环境中测得的,该环境包含 3 个节点,每个节点有 30 个虚拟 CPU。您的性能可能会有所不同,但考虑到数据集大小,性能将主要取决于网络连接。
架构优化
检查表结构后,我们发现了多个优化空间。
SHOW CREATE TABLE subway_transits_2014_2022_raw
CREATE TABLE subway_transits_2014_2022_raw
(`C/A` Nullable(String),`Unit` Nullable(String),`SCP` Nullable(String),`Station` Nullable(String),`Line Name` Nullable(String),`Division` Nullable(String),`Date` Nullable(DateTime64(9)),`Time` Nullable(String),`Description` Nullable(String),`Entries` Nullable(Int64),`Exits ` Nullable(Int64)
)
ENGINE = SharedMergeTree('/clickhouse/tables/{uuid}/{shard}', '{replica}')
ORDER BY tuple()首先,列名建议使用小写且无特殊字符。此外,Nullable 类型非必需,会增加额外的空间开销以区分空值和空内容,应尽量避免使用。其次,日期和时间应合并为一个 date_time 列——ClickHouse 支持丰富的日期时间函数,可基于时间、日期或两者来查询 DateTime 类型。
快速查看数据的列描述后,我们还发现了一些优化空间。进站和出站值不会超过 Int32,若超出会回绕(需进一步处理),且仅为正值。大多数字符串列的基数也较低,可通过简单查询来验证:
SELECTuniq(`C/A`),uniq(Unit),uniq(SCP),uniq(Station),uniq(`Line Name`),uniq(Division),uniq(Description)
FROM subway_transits_2014_2022_raw
FORMAT VerticalQuery id: c925aaa4-6302-41e4-9f1e-1ba88587c3bcRow 1:
──────
uniq(C/A): 762
uniq(Unit): 476
uniq(SCP): 334
uniq(Station): 579
uniq(Line Name): 130
uniq(Division): 7
uniq(Description): 21 row in set. Elapsed: 0.959 sec. Processed 94.88 million rows, 10.27 GB (98.91 million rows/s., 10.71 GB/s.)
Peak memory usage: 461.18 MiB.因此,将这些列设置为 LowCardinality(String) 类型更合理,这样可以实现更高的压缩效率和更快的查询速度!
纽约市民对线路命名系统应该很熟悉。列 Line Name 表示检票闸机所服务的线路,例如:
“停靠该站的地铁线路,如 456”
这里 456 代表 4、5 和 6 号线。我们观察数据后发现,这些线路并没有保持一致的顺序。例如,456NQR 与 NQR456 实际上表示相同的线路组合。
SELECT `Line Name`
FROM subway_transits_2014_2022_raw
WHERE (`Line Name` = 'NQR456') OR (`Line Name` = '456NQR')
LIMIT 1 BY `Line Name`┌─Line Name─┐
│ NQR456 │
│ 456NQR │
└───────────┘2 rows in set. Elapsed: 0.059 sec. Processed 94.88 million rows, 1.20 GB (1.60 billion rows/s., 20.20 GB/s.)
Peak memory usage: 105.88 MiB.为了简化查询过程,我们将该字符串转为 Array(LowCardinality(String)) 类型,并对其中的线路排序。
最后,选择 station 和 date_time 作为排序键是一个合理的选择。
因此,表的结构如下:
CREATE TABLE subway_transits_2014_2022_v1
(`ca` LowCardinality(String),`unit` LowCardinality(String),`scp` LowCardinality(String),`station` LowCardinality(String),`line_names` Array(LowCardinality(String)),`division` LowCardinality(String),`date_time` DateTime32,`description` LowCardinality(String),`entries` UInt32,`exits` UInt32
)
ENGINE = MergeTree
ORDER BY (station, date_time)接下来,我们可以通过从之前的 subway_transits_2014_2022_raw 表中读取数据,使用 SELECT 语句转换行数据来加载这些信息。
INSERT INTO subway_transits_2014_2022_v1 SELECT`C/A` AS ca,Unit AS unit,SCP AS scp,Station AS station,arraySort(ngrams(assumeNotNull(`Line Name`), 1)) AS line_names,Division AS division,parseDateTimeBestEffort(trimBoth(concat(CAST(Date, 'Date32'), ' ', Time))) AS date_time,Description AS description,Entries AS entries,`Exits ` AS exits
FROM subway_transits_2014_2022_raw
SETTINGS max_insert_threads = 160 rows in set. Elapsed: 4.235 sec. Processed 94.88 million rows, 14.54 GB (22.40 million rows/s., 3.43 GB/s.)清理 MTA 交通数据集
我们发现了几个主要问题,接下来逐一说明。
挑战 1:累积值和异常值
根据 MTA 数据【https://data.ny.gov/api/views/ug6q-shqc/files/29edbef3-268e-461d-95f1-374b1c8a6f9d?download=true&filename=MTA_SubwayTurnstileUsageData2015_Overview.pdf】的详细描述,这些数据中存在一些质量问题,首先就是进出人数的数值是累积的。
> MTA 每隔四小时提供一次数据,记录了每个检票闸机的进出人数累积值,类似于里程表的读数。各车站的间隔时间可能不同,因为需要分批传输以防止系统过载。车站的审计时间设在每日的 00-03 点之间开始,此后每隔四小时一次。通过与之前的读数进行比较,可以计算出每个时段内通过检票闸机的进出人数。
这些累积值的使用比较困难,需要进行查询来计算每个检票闸机的时间序列变化。由于数据每 4 小时传输一次,这对特定时间段的统计仍显不精确,这也是我们无法完全解决的问题,因此低于该时间粒度的统计数据可能会存在偏差。
此外,数据还存在一些明显的质量问题:
> 检票闸机的审计并非总是每四小时一次,有时计数会回退、进出计数器周期性重置,各检票闸机的时间戳也不同。此外,数据为 10 位数,溢出后会归零。
理想情况下,我们希望计算每一行的进出人数变化,即通过与上一个时间点的差异进行计算,而要做到这一点,需要可靠地识别每个检票闸机。
虽然每个闸机有一个 scp 标识符,但它在各车站并不唯一。我们可以使用 scp、ca(车站的工作亭标识符)和 unit(车站的远程单元 ID)组合来识别具体车站。
要计算每个检票闸机的进出变化,我们可以使用窗口函数。以下代码计算每行的 entries_change 和 exits_change 列。
WITH 1000 AS threshold_per_hour
SELECT*,any(date_time) OVER (PARTITION BY ca, unit, scp ORDER BY date_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS p_date_time,any(entries) OVER (PARTITION BY ca, unit, scp ORDER BY date_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS p_entries,any(exits) OVER (PARTITION BY ca, unit, scp ORDER BY date_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS p_exits,dateDiff('hour', p_date_time, date_time) AS hours,if((entries < p_entries) OR (((entries - p_entries) / if(hours > 0, hours, 1)) > threshold_per_hour), 0, entries - p_entries) AS entries_change,if((exits < p_exits) OR (((exits - p_exits) / if(hours > 0, hours, 1)) > threshold_per_hour), 0, exits - p_exits) AS exits_change
FROM subway_transits_2014_2022_v1
ORDER BYca ASC,unit ASC,scp ASC,date_time ASC查询的关键点概述:
1. 数据按 ca、unit、scp 和 date_time 列(升序)排序,以确保每个检票闸机的记录按时间顺序排列,从而便于计算变化量。
2. 查询函数通过 PARTITION BY ca、unit、scp 为每个检票闸机创建窗口,并在每个窗口内按时间顺序排序。ROWS BETWEEN 1 PRECEDING AND CURRENT ROW 子句用于生成 p_entries 和 p_exits 列,这两列包含每行上一次的进出人数值,上一个时间点则存储在 p_date_time 列。
3. entries_change 和 exits_change 列存储的是当前行和前一行之间的进出人数变化。如果该变化为负数,返回值设为 0,假设这是由于计数器回滚。此外,数据分析显示存在异常高的值,例如一个小时内出现 10,000 人通过某个检票闸机的记录。若变化值超过合理阈值(每小时 1000 人),也会返回 0 以过滤掉异常值。我们选定的阈值基于实际通过率的估算(约每分钟 10-15 人)。这种方法虽然不完美,但可结合历史趋势进行改进。
挑战 2:站名缺失与不一致
虽然各年度数据集使用了相同架构,但 2022 年的数据集【https://data.ny.gov/Transportation/MTA-Subway-Turnstile-Usage-Data-2022/k7j9-jnct/about_data】缺少站名。
SELECT toYear(date_time) AS year
FROM mta.subway_transits_2014_2022_v1
WHERE station = ''
GROUP BY year┌─year─┐
1. │ 2022 │└──────┘1 row in set. Elapsed: 0.016 sec. Processed 10.98 million rows, 54.90 MB (678.86 million rows/s., 3.39 GB/s.)
Peak memory usage: 98.99 MiB.为提高数据集的可用性,我们可以基于独特的检票闸机 ID(由早期数据填充)来补充 2022 年的站名。
然而,通过分析发现,即便同一检票闸机的站名也常不一致。例如,“大道”一词的拼写有时为 AV,有时为 AVE,导致同一站点被记录多次。
SELECT DISTINCT station
FROM subway_transits_2014_2022_v1
WHERE station LIKE '%AV%'
ORDER BY station ASC
LIMIT 10
FORMAT PrettyCompactMonoBlock┌─station──────┐
│ 1 AV │
│ 1 AVE │
│ 138 ST-3 AVE │
│ 14 ST-6 AVE │
│ 149 ST-3 AVE │
│ 18 AV │
│ 18 AVE │
│ 2 AV │
│ 2 AVE │
│ 20 AV │
└──────────────┘10 rows in set. Elapsed: 0.024 sec. Processed 36.20 million rows, 41.62 MB (1.53 billion rows/s., 1.75 GB/s.)
Peak memory usage: 26.68 MiB.若能建立检票闸机与站名的映射,可以通过统一选择一种名称(如最长名称)并重新映射数据来解决简单的拼写不一致问题。需注意,这无法处理更复杂的映射问题,例如将“42 ST-TIMES SQ”与“TIMES SQ-42 ST”统一映射为“TIMES SQ”。我们可以暂时在查询时处理这些更复杂的情况。
为存储该映射关系,可以使用字典。这种内存结构允许通过 (ca, unit, scp) 的元组查找站名。以下查询可填充字典,生成分配给每个 (ca, unit, scp) 的唯一站名列表,并按长度排序,选取最长的名称。使用 groupArrayDistinct 函数创建列表并完成排序。
CREATE DICTIONARY station_names
(
`ca` String,
`unit` String,
`scp` String,
`station_name` String
)
PRIMARY KEY (ca, unit, scp)
SOURCE(CLICKHOUSE(QUERY $query$SELECTca,unit,scp,arrayReverseSort(station -> length(station), groupArrayDistinct(station))[1] AS station_nameFROM subway_transits_2014_2022_v1WHERE station != ''GROUP BYca,unit,scp
$query$))
LIFETIME(MIN 0 MAX 0)
LAYOUT(complex_key_hashed())有关字典的详细配置和类型,请参考字典文档。
使用 dictGet 函数可以高效检索站名。例如:
SELECT dictGet(station_names, 'station_name', ('R148', 'R033', '01-04-01'))┌─name───────────┐
│ 42 ST-TIMES SQ │
└────────────────┘1 row in set. Elapsed: 0.001 sec.请注意,首次调用字典时,速度可能较慢,具体取决于数据是急加载还是在首次请求时才懒加载(lazy_load)。这可以通过设置 dictionaries_lazy_load 配置项控制。
最终数据的整合方案
现在,我们可以结合窗口函数和字典查询来生成最终数据。思路简单:在 v1 表上使用窗口函数和 dictGet 函数执行查询,将结果插入到一个新表中。我们的最终表结构如下:
CREATE TABLE mta.subway_transits_2014_2022_v2
(`ca` LowCardinality(String),`unit` LowCardinality(String),`scp` LowCardinality(String),`line_names` Array(LowCardinality(String)),`division` LowCardinality(String),`date_time` DateTime,`description` LowCardinality(String),`entries` UInt32,`exits` UInt32,`station` LowCardinality(String),`entries_change` UInt32,`exits_change` UInt32
)
ENGINE = MergeTree
ORDER BY (ca, unit, scp, date_time)使用 INSERT INTO SELECT:
INSERT INTO mta.subway_transits_2014_2022_v2 WITH 2000 AS threshold_per_hour SELECTca, unit, scp, line_names, division, date_time, description, entries, exits,dictGet(station_names, 'station_name', (ca, unit, scp)) as station,entries_change, exits_change
FROM
(SELECT*,any(date_time) OVER (PARTITION BY ca, unit, scp ORDER BY date_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS p_date_time,any(entries) OVER (PARTITION BY ca, unit, scp ORDER BY date_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS p_entries,any(exits) OVER (PARTITION BY ca, unit, scp ORDER BY date_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS p_exits,dateDiff('hour', p_date_time, date_time) AS hours,if((entries < p_entries) OR (((entries - p_entries) / if(hours > 0, hours, 1)) > threshold_per_hour), 0, entries - p_entries) AS entries_change,if((exits < p_exits) OR (((exits - p_exits) / if(hours > 0, hours, 1)) > threshold_per_hour), 0, exits - p_exits) AS exits_changeFROM subway_transits_2014_2022_v1ORDER BYca ASC,unit ASC,scp ASC,date_time ASC) SETTINGS max_insert_threads=160 rows in set. Elapsed: 24.305 sec. Processed 94.88 million rows, 2.76 GB (3.90 million rows/s., 113.67 MB/s.)最终表结构:
SELECT *
FROM mta.subway_transits_2014_2022_v2
LIMIT 1
FORMAT VerticalRow 1:
──────
ca: A002
unit: R051
scp: 02-00-00
line_names: ['4','5','6','N','Q','R']
division: BMT
date_time: 2014-01-02 03:00:00
description: REGULAR
entries: 4469306
exits: 1523801
station: LEXINGTON AVE
entries_change: 0
exits_change: 01 rows in set. Elapsed: 0.005 sec.MTA 交通数据集的示例查询
以下查询可以在 ClickHouse playground 中运行。我们为每个查询提供了默认的图表以便入门。
如果您有更多针对 MTA 数据集或其他数据集的查询建议或改进思路,欢迎联系我们,或在示例库的仓库【https://github.com/ClickHouse/sql.clickhouse.com】中提交问题。
首先,我们确认热门车站是否与官方数据一致。以 2018 年的数据为例:
SELECTstation,sum(entries_change) AS total_entries,formatReadableQuantity(total_entries) AS total_entries_read
FROM mta.subway_transits_2014_2022_v2
WHERE toYear(date_time) = '2018'
GROUP BY station
ORDER BY sum(entries_change) DESC
LIMIT 10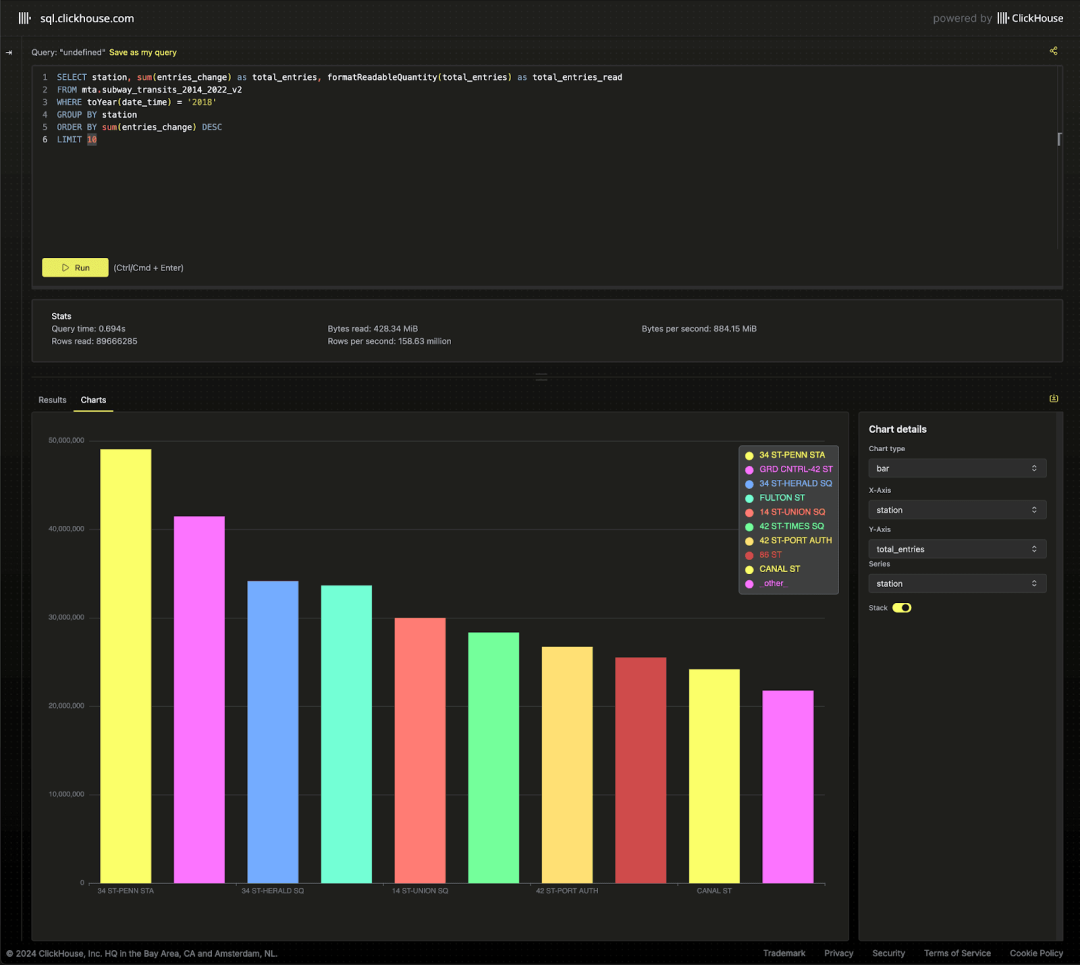
我们的结果质量受到数据嘈杂度和异常值处理方法的影响,但总体上与 MTA 报告的数据一致。请注意,数据集中一些站点有多个入口名称,例如 '42 ST-TIMES SQ' 和 'TIMES SQ-42 ST' 均表示 'TIMES SQ'。我们将名称清理作为待办事项,目前通过查询条件进行处理。
查看整个期间内前十站点的客流趋势时,COVID 疫情的影响显而易见。
SELECTstation,toYear(date_time) AS year,sum(entries_change) AS total_entries
FROM mta.subway_transits_2014_2022_v2
WHERE station IN (SELECT stationFROM mta.subway_transits_2014_2022_v2GROUP BY stationORDER BY sum(entries_change) DESCLIMIT 10
)
GROUP BYyear,station
ORDER BY year ASC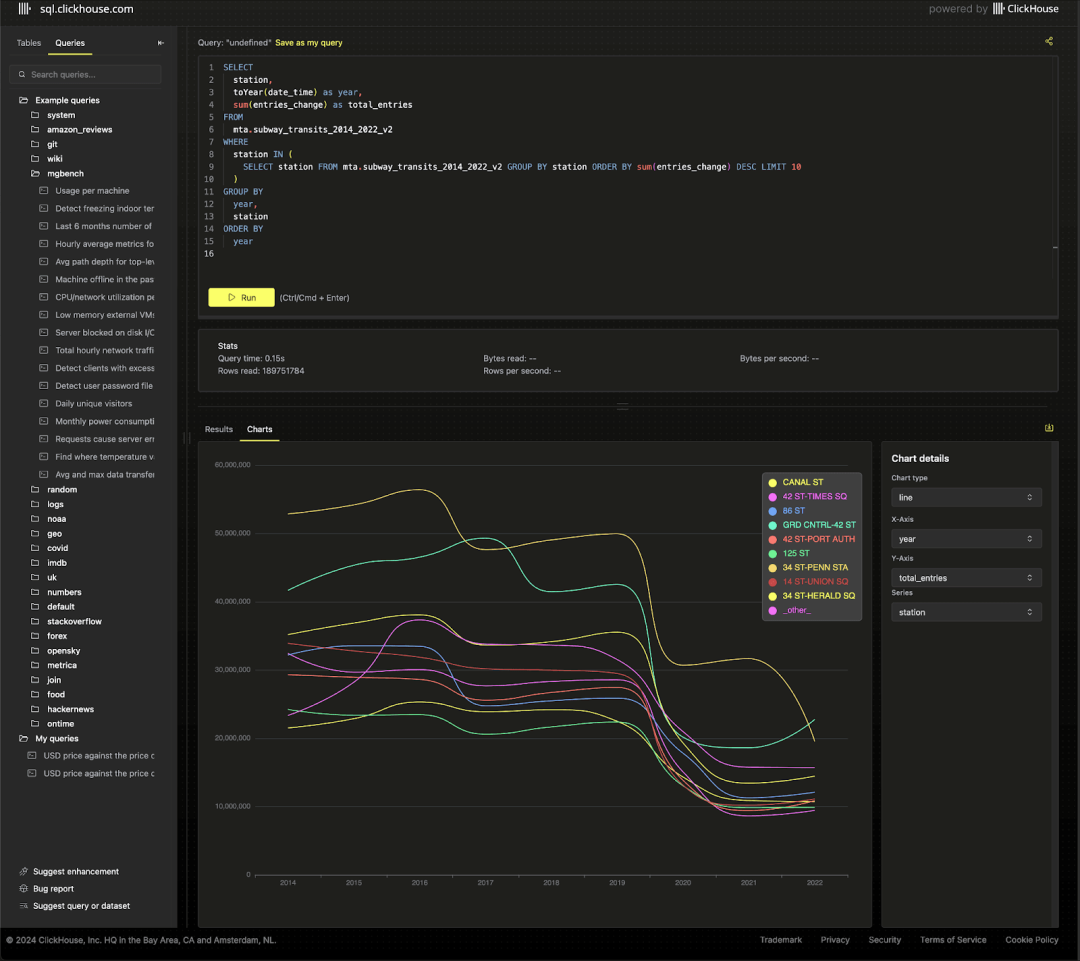
尽管经过处理,数据仍然较嘈杂,并存在一些明显的异常值,需进一步清理。欢迎提供改进方法。2022 年的交通数据则相对更可靠,质量较高。我们已将其加载至 transit_data 表中,并提供了一些示例查询。
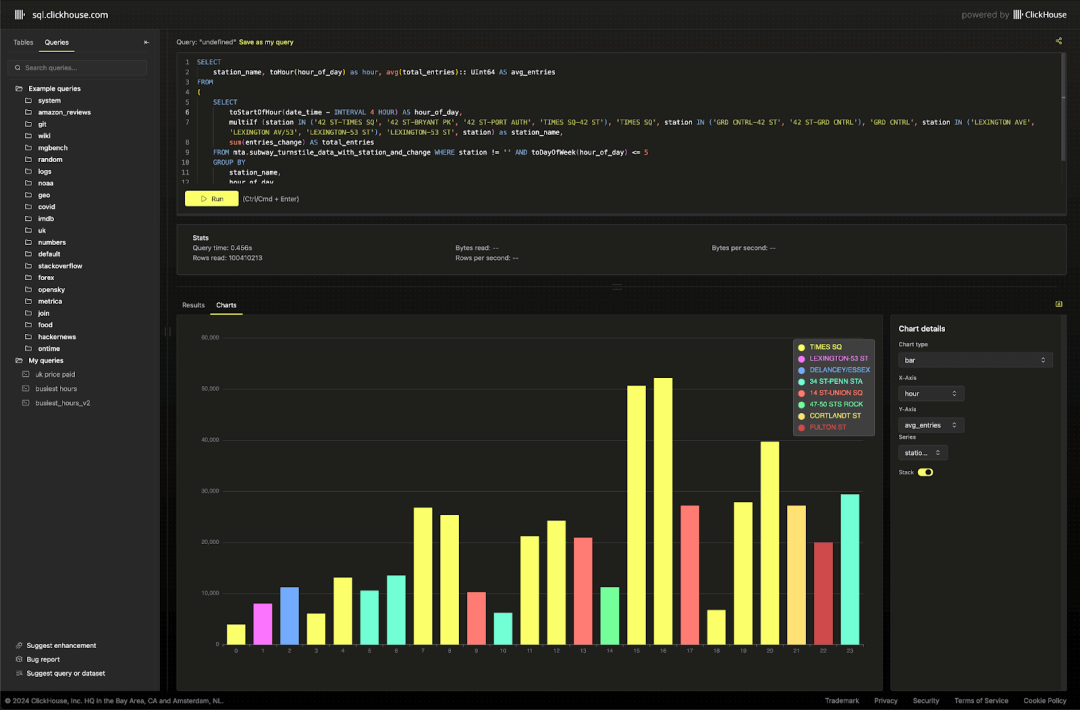
通过这些数据,可以观察到各站点在高峰时段的通勤模式。
SELECTstation_complex,toHour(hour_of_day) AS hour,CAST(avg(total_entries), 'UInt64') AS avg_entries
FROM
(SELECTtoStartOfHour(transit_timestamp) AS hour_of_day,station_complex,sum(ridership) AS total_entriesFROM mta.transit_dataWHERE toDayOfWeek(transit_timestamp) <= 5GROUP BYstation_complex,hour_of_day
)
GROUP BYhour,station_complex
ORDER BYhour ASC,avg_entries DESC
LIMIT 3 BY hour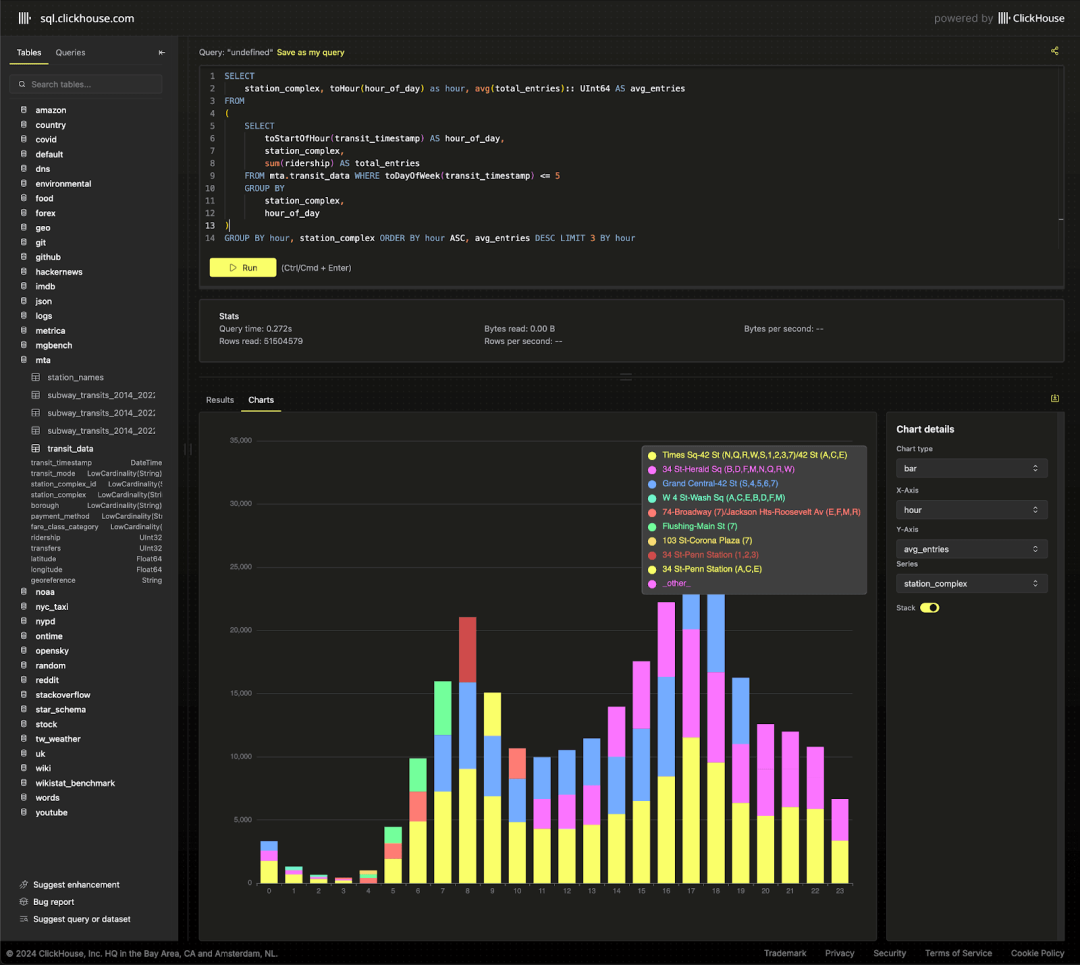
我们还可以轻松地对比周末和工作日的客流量,从而突出一年中的特定时段,例如 7 月 4 日,通勤流量明显减少。
SELECTtoStartOfWeek(transit_timestamp) AS week,'weekday' AS period,sum(ridership) AS total
FROM mta.transit_data
WHERE toDayOfWeek(transit_timestamp) <= 5
GROUP BY week
ORDER BY week ASC
UNION ALL
SELECTtoStartOfWeek(transit_timestamp) AS week,'weekend' AS period,sum(ridership) AS total
FROM mta.transit_data
WHERE toDayOfWeek(transit_timestamp) > 5
GROUP BY week
ORDER BY week ASC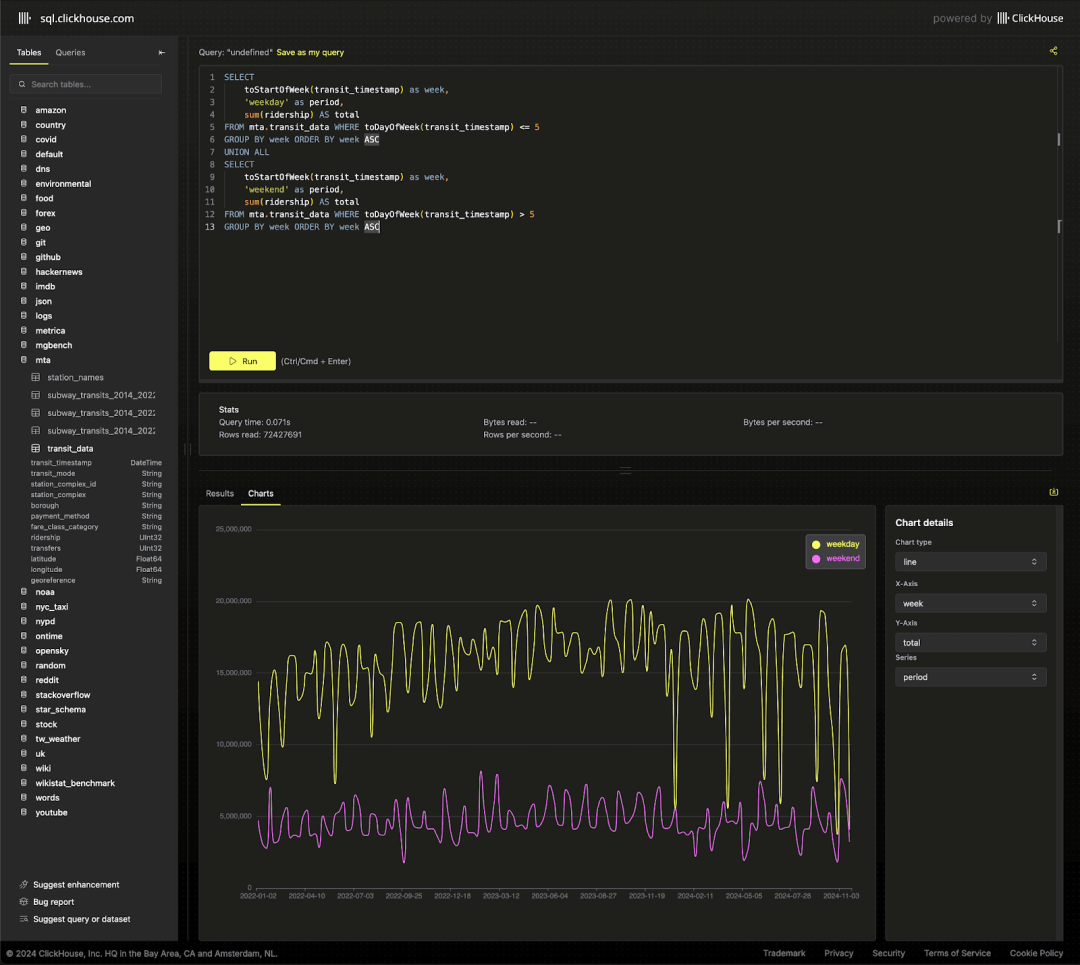
总结
我们在处理 MTA 数据时玩得很开心(尽量让数据清理过程更有趣!),希望我们的工作能帮助大家更轻松地进行有趣的数据分析。
如果您在示例库【https://github.com/ClickHouse/sql.clickhouse.com】中创建了新的查询或图表,欢迎与我们分享!
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求
相关文章:
ClickHouse 神助攻:纽约城市公共交通管理(MTA)数据应用挑战赛
本文字数:13198;估计阅读时间:33 分钟 作者:The PME Team 本文在公众号【ClickHouseInc】首发 我们一向对开放数据挑战充满热情,所以当发现 MTA(城市交通管理局)在其官网发起了这样的挑战时&…...

ELK + Filebeat + Spring Boot:日志分析入门与实践(二)
目录 一、环境 1.1 ELKF环境 1.2 版本 1.3 流程 二、Filebeat安装 2.1 安装 2.2 新增配置采集日志 三、logstash 配置 3.1 配置输出日志到es 3.2 Grok 日志格式解析 3.2 启动 logstash 3.3 启动项目查看索引 一、环境 1.1 ELKF环境 springboot项目:w…...

使用 Docker Compose 将数据版 LobeChat 服务端部署
LobeChat 是一个基于 TypeScript 的开源聊天机器人项目,支持本地部署和接入多个大语言模型。本文介绍如何使用 Docker Compose 将 LobeChat 服务端及其数据库部署到生产环境,让您拥有一个私有化的、可定制的 AI 聊天助手。 一、部署前准备 服务器&…...

python如何完成金融领域的数据分析,思路以及常见的做法是什么?
引言 在现代金融领域,数据分析已成为决策支持的重要工具。随着金融市场的复杂性和数据量的激增,传统的分析方法已无法满足需求。 Python作为一种强大的编程语言,凭借其丰富的库和工具,成为金融数据分析的首选语言之一。 本文将探讨如何利用Python进行金融数据分析,包括…...
密码管理工具实现
该文档详细描述了实现一个简单的密码管理工具的过程,工具基于PHP和MySQL构建,支持用户注册、密码存储、管理以及角色权限控制等核心功能。 系统架构设计 技术栈:PHP(后端逻辑)、MySQL(数据存储)…...

构造函数和new操作符 - 2024最新版前端秋招面试短期突击面试题【100道】
构造函数和new操作符 - 2024最新版前端秋招面试短期突击面试题【100道】 🏗️ 在JavaScript中,构造函数和new操作符是创建对象的重要方式。深入理解它们的基本概念和用法,可以帮助你更有效地使用JavaScript进行开发。以下是关于构造函数和ne…...

6.Linux按键驱动-阻塞与非阻塞
默认打开文件时候是阻塞的 当设置打开方式为非阻塞时,无数据时会返回。 当设置打开方式为阻塞时,无数据的时候会等待1.设置打开方式为非阻塞 立即返回,无法读出,返回-1 2.设置为阻塞 核心在于驱动程序中的.read函数的支持 …...

Mac打开环境变量配置文件,source ~/.zshrc无法打开问题解决
本文将会介绍,Mac如何打开zshrc环境变量配置文件。 在搭建开发环境的时候,通常我们需要配置环境变量,例如:ANDROID_HOME、nvm等。 具体的做法是把配置环境变量的命令加入到 shell 的配置文件中。如果你的 shell 是 zshÿ…...

计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-23
计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-23 目录 文章目录 计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-23目录1. Advancements in Visual Language Models for Remote Sensing: Datasets, Capabilities, and Enhancement Techniques摘…...

【C#】搭建环境之CSharp+OpenCV
在我们使用C#编程中,对图片处理时会用到OpenCV库,以及其他视觉厂商提供的封装库,这里因为OpenCV是开源库,所以在VS资源里可以直接安装使用,这里简单说明一下搭建的步骤及实现效果,留存。 1. 项目创建 1.1…...

100种算法【Python版】第25篇——Bidirectional Search算法
本文目录 1 算法原理2 路径计算的算法步骤3 python代码4 算法应用1 算法原理 Bidirectional Search(双向搜索)算法是为了解决图中最短路径问题而提出的一种搜索策略,旨在提高搜索效率。该算法的核心思想是同时从起点和终点进行搜索,直到两个搜索相遇。这种方法有效地减少了…...

WebSocket与Socket
一、定义与用途 Socket Socket(套接字)是一个抽象层,用于在网络上执行进程间的通信。它为应用程序提供了发送和接收数据的机制,通过IP和端口号来标识网络中唯一的位置。Socket可以使用TCP进行面向连接的可靠通信,也可以…...

Python 3 维护有序列表 bisect
在Python 3中,bisect模块提供了用于维护有序列表的函数,主要用于在有序序列中进行二分查找以及插入操作,以下是其常见用法的介绍: 1. 导入模块 首先需要导入bisect模块: import bisect2. 主要函数及用法 bisect.bi…...

vue版本太低无法执行vue ui命令
连接 ui和create目前都只支持3.0以后得版本才能使用 https://blog.csdn.net/m0_67318913/article/details/136775252?utm_mediumdistribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-0-136775252-blog-121204604.235v43pc_blog_bottom_relevance…...

数据结构 之 二叉树的遍历------先根遍历(五)
提示:本篇章主要讲解数据结构中树的相关知识。 文章目录 二叉树的遍历为什么要提出这么多遍历方法?先根遍历二叉树(TLR)先根遍历二叉树的递归算法(重点)先根遍历二叉树的非递归算法(了解,但是得…...
Xss_less靶场攻略(1-18)
xss-lab-less1 ur特殊字符转义 存在url中 转义符为 %2B& 转义符为 %26空格 转义符为 或 %20/ 转义符为 %2F? 转义符为 %3F% 转义符为 %25#转义符为 %23 转义符为 %3Dimg 标签懒加载 在XSS攻击中,img标签的src属性是一个常见的攻击向量,因为它可以…...

【AI语音克隆整合包及教程】声临其境,让想象成为现实——第二代GPT-SoVITS引领语音克隆新时代!
随着人工智能技术的飞速发展,曾经只能在科幻小说中出现的场景逐渐走进了我们的日常生活。其中,语音克隆技术以其独特魅力,成为了人们关注的焦点。GPT-SoVITS作为一款前沿的语音克隆工具,由RVC变声器创始人“花儿不哭”与AI音色转换…...

echarts属性之dataZoom
dataZoom-slider 滑动条型数据区域缩放组件(dataZoomInside) 滑动条型数据区域缩放组件提供了数据缩略图显示,缩放,刷选,拖拽,点击快速定位等数据筛选的功能。下图显示了该组件可交互部分 所有属性 data…...

SQLite 语法
SQLite 语法 SQLite 是一种轻量级的数据库管理系统,它遵循 SQL(结构化查询语言)标准。SQLite 的语法相对简单,易于学习和使用。本文将详细介绍 SQLite 的基本语法,包括数据定义语言(DDL)、数据…...

逗号运算符应用举例
在main.cpp里输入程序如下: #include <iostream> //使能cin(),cout(); #include <iomanip> //使能setbase(),setfill(),setw(),setprecision(),setiosflags()和resetiosflags(); //setbase( char x )是设置输出数字的基数,如输出进制数则用set…...

StructBERT情感分类模型部署架构设计
StructBERT情感分类模型部署架构设计 1. 引言 情感分类是自然语言处理中的核心任务之一,能够自动分析文本中的情感倾向,在用户评价分析、舆情监控、智能客服等场景中发挥着重要作用。StructBERT作为基于Transformer架构的预训练模型,在中文…...

3步解锁抖音无水印下载神器:让内容备份效率提升10倍的完整指南
3步解锁抖音无水印下载神器:让内容备份效率提升10倍的完整指南 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 在数字内容爆炸的时代,抖音已成为知识传播、文化交流和创意展示的重要平…...

Modules 模块化:头文件地狱真的要终结了吗?我持怀疑态度
各位来宾,各位技术同仁,大家好!今天我们齐聚一堂,探讨一个在C社区引发广泛讨论、充满期待又饱含争议的话题:C模块化。特别是关于“头文件地狱真的要终结了吗?”这个问题,我深知在座的许多人&…...

解决RK3588安装OpenCV时libjasper-dev缺失问题:Ubuntu20.04特殊源配置教程
RK3588平台OpenCV安装困境:深度解析libjasper-dev缺失问题与多维度解决方案 在RK3588平台上部署计算机视觉应用时,OpenCV作为核心依赖库的安装过程往往成为开发者的第一个"拦路虎"。特别是在Ubuntu 20.04环境下,当执行标准的sudo a…...

暗黑破坏神2存档编辑器完全指南:从技术原理到实战应用
暗黑破坏神2存档编辑器完全指南:从技术原理到实战应用 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 价值定位:为什么d2s-editor能重塑你的游戏体验 你是否曾因反复刷不到心仪装备而失去耐心࿱…...

1998-2025年区县政府工作报告文本数据
县域政府工作报告是县级政府向同级人民代表大会汇报年度工作的核心文件,报告既总结上一年度经济社会发展和政府工作成效,也提出当前形势判断、政策取向及下一阶段重点任务,是集中反映政府施政理念、政策重点和发展方向的重要文本 整理了1998…...

解锁高效无水印备份:抖音视频批量下载的完整指南
解锁高效无水印备份:抖音视频批量下载的完整指南 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 直面内容管理痛点:三个真实用户的困境 场景一:学习资源的系统性流失 教…...

PP-DocLayoutV3入门指南:从零开始理解bbox坐标、label_id、score字段含义
PP-DocLayoutV3入门指南:从零开始理解bbox坐标、label_id、score字段含义 1. 前言:为什么你需要了解这些字段? 如果你刚开始接触文档布局分析,看到PP-DocLayoutV3输出的JSON数据,可能会对里面那些bbox、label_id、sc…...

Focaler-IoU: More Focused Intersection over Union——更聚焦的交并比损失
《Focaler-IoU: More Focused Intersection over Union Loss》主要研究内容可以全面概括如下: 研究背景与问题: 在目标检测任务中,边界框回归的精度很大程度上取决于损失函数的设计。现有的IoU-based损失函数(如GIoU、CIoU、EIoU…...

Hunyuan-MT-7B效果展示:学术论文摘要英→中翻译在专业术语一致性表现
Hunyuan-MT-7B效果展示:学术论文摘要英→中翻译在专业术语一致性表现 1. 引言:专业翻译的技术挑战 学术论文翻译一直是机器翻译领域的难点,特别是专业术语的一致性保持。传统翻译工具在处理学术文献时,经常出现术语翻译不统一、…...