YOLO即插即用模块---AgentAttention
Agent Attention: On the Integration of Softmax and Linear Attention
论文地址:https://arxiv.org/pdf/2312.08874
问题: 普遍使用的 Softmax 注意力机制在视觉 Transformer 模型中计算复杂度过高,限制了其在各种场景中的应用。
方法: 提出了一个新的注意力机制,名为 Agent Attention,通过引入一组代理 token (A) 来解决计算复杂度过高的问题。
具体步骤:
-
代理聚合 (Agent Aggregation): 将代理 token (A) 作为查询 token (Q) 的代理,从键 (K) 和值 (V) 中聚合信息,形成代理特征 (VA)。
-
代理广播 (Agent Broadcast): 将代理 token (A) 作为键,将全局信息从代理特征 (VA) 广播到每个查询 token (Q),形成最终的输出。
代理 token (A) 的获取方式:
-
可学习的参数
-
从输入特征中提取 (例如,通过池化或卷积)
Agent Attention 模块:
-
包含纯 Agent Attention、代理偏置 (Agent Bias) 和深度可分离卷积 (DWC) 模块。
-
代理偏置用于添加位置信息,帮助不同的代理 token 关注不同的区域。
-
DWC 模块用于保持特征多样性,弥补线性注意力的不足。
-

Agent Attention 的优势:
-
高效计算和高表达能力: 结合了 Softmax 注意力和线性注意力的优点,既降低了计算复杂度,又保持了高表达能力。
-
大感受野: 可以采用更大的感受野,甚至全局感受野,同时保持相同的计算量。P8
实验结果:
-
在图像分类、目标检测、语义分割和图像生成等任务上,Agent Attention 都取得了显著的性能提升。
-
在高分辨率场景中,Agent Attention 表现出优异的性能。
-
将 Agent Attention 应用于 Stable Diffusion,可以加速图像生成过程,并显著提高图像生成质量,无需任何额外的训练。
总结: Agent Attention 是一种高效且高表达的注意力机制,可以有效地解决 Softmax 注意力计算复杂度过高的问题,在各种视觉任务中取得了显著的性能提升,特别是在高分辨率场景中。
即插即用代码:
import torch
import torch.nn as nn
from timm.models.layers import trunc_normal_class AgentAttention(nn.Module):def __init__(self, dim, num_patches, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.,sr_ratio=1, agent_num=49, **kwargs):super().__init__()assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."self.dim = dimself.num_patches = num_patcheswindow_size = (int(num_patches ** 0.5), int(num_patches ** 0.5))self.window_size = window_sizeself.num_heads = num_headshead_dim = dim // num_headsself.scale = head_dim ** -0.5self.q = nn.Linear(dim, dim, bias=qkv_bias)self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)self.sr_ratio = sr_ratioif sr_ratio > 1:self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)self.norm = nn.LayerNorm(dim)self.agent_num = agent_numself.dwc = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=(3, 3), padding=1, groups=dim)self.an_bias = nn.Parameter(torch.zeros(num_heads, agent_num, 7, 7))self.na_bias = nn.Parameter(torch.zeros(num_heads, agent_num, 7, 7))self.ah_bias = nn.Parameter(torch.zeros(1, num_heads, agent_num, window_size[0] // sr_ratio, 1))self.aw_bias = nn.Parameter(torch.zeros(1, num_heads, agent_num, 1, window_size[1] // sr_ratio))self.ha_bias = nn.Parameter(torch.zeros(1, num_heads, window_size[0], 1, agent_num))self.wa_bias = nn.Parameter(torch.zeros(1, num_heads, 1, window_size[1], agent_num))trunc_normal_(self.an_bias, std=.02)trunc_normal_(self.na_bias, std=.02)trunc_normal_(self.ah_bias, std=.02)trunc_normal_(self.aw_bias, std=.02)trunc_normal_(self.ha_bias, std=.02)trunc_normal_(self.wa_bias, std=.02)pool_size = int(agent_num ** 0.5)self.pool = nn.AdaptiveAvgPool2d(output_size=(pool_size, pool_size))self.softmax = nn.Softmax(dim=-1)def forward(self, x, H, W):b, n, c = x.shapenum_heads = self.num_headshead_dim = c // num_headsq = self.q(x)if self.sr_ratio > 1:x_ = x.permute(0, 2, 1).reshape(b, c, H, W)x_ = self.sr(x_).reshape(b, c, -1).permute(0, 2, 1)x_ = self.norm(x_)kv = self.kv(x_).reshape(b, -1, 2, c).permute(2, 0, 1, 3)else:kv = self.kv(x).reshape(b, -1, 2, c).permute(2, 0, 1, 3)k, v = kv[0], kv[1]agent_tokens = self.pool(q.reshape(b, H, W, c).permute(0, 3, 1, 2)).reshape(b, c, -1).permute(0, 2, 1)q = q.reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)k = k.reshape(b, n // self.sr_ratio ** 2, num_heads, head_dim).permute(0, 2, 1, 3)v = v.reshape(b, n // self.sr_ratio ** 2, num_heads, head_dim).permute(0, 2, 1, 3)agent_tokens = agent_tokens.reshape(b, self.agent_num, num_heads, head_dim).permute(0, 2, 1, 3)kv_size = (self.window_size[0] // self.sr_ratio, self.window_size[1] // self.sr_ratio)position_bias1 = nn.functional.interpolate(self.an_bias, size=kv_size, mode='bilinear')position_bias1 = position_bias1.reshape(1, num_heads, self.agent_num, -1).repeat(b, 1, 1, 1)position_bias2 = (self.ah_bias + self.aw_bias).reshape(1, num_heads, self.agent_num, -1).repeat(b, 1, 1, 1)position_bias = position_bias1 + position_bias2agent_attn = self.softmax((agent_tokens * self.scale) @ k.transpose(-2, -1) + position_bias)agent_attn = self.attn_drop(agent_attn)agent_v = agent_attn @ vagent_bias1 = nn.functional.interpolate(self.na_bias, size=self.window_size, mode='bilinear')agent_bias1 = agent_bias1.reshape(1, num_heads, self.agent_num, -1).permute(0, 1, 3, 2).repeat(b, 1, 1, 1)agent_bias2 = (self.ha_bias + self.wa_bias).reshape(1, num_heads, -1, self.agent_num).repeat(b, 1, 1, 1)agent_bias = agent_bias1 + agent_bias2q_attn = self.softmax((q * self.scale) @ agent_tokens.transpose(-2, -1) + agent_bias)q_attn = self.attn_drop(q_attn)x = q_attn @ agent_vx = x.transpose(1, 2).reshape(b, n, c)v = v.transpose(1, 2).reshape(b, H // self.sr_ratio, W // self.sr_ratio, c).permute(0, 3, 1, 2)if self.sr_ratio > 1:v = nn.functional.interpolate(v, size=(H, W), mode='bilinear')x = x + self.dwc(v).permute(0, 2, 3, 1).reshape(b, n, c)x = self.proj(x)x = self.proj_drop(x)return xif __name__ == '__main__':dim = 4num_patches = 64block = AgentAttention(dim=dim, num_patches=num_patches)H, W = 8,8x = torch.rand(1, num_patches, dim)output = block(x, H, W)print(f"Input size: {x.size()}")print(f"Output size: {output.size()}")YOLO小伙伴可进群交流:

相关文章:
YOLO即插即用模块---AgentAttention
Agent Attention: On the Integration of Softmax and Linear Attention 论文地址:https://arxiv.org/pdf/2312.08874 问题: 普遍使用的 Softmax 注意力机制在视觉 Transformer 模型中计算复杂度过高,限制了其在各种场景中的应用。 方法&a…...

探索开源语音识别的未来:高效利用先进的自动语音识别技术20241030
🚀 探索开源语音识别的未来:高效利用自动语音识别技术 🌟 引言 在数字化时代,语音识别技术正在引领人机交互的新潮流,为各行业带来了颠覆性的改变。开源的自动语音识别(ASR)系统,如…...

学习路之TP6--workman安装
一、安装 首先通过 composer 安装 composer require topthink/think-worker 报错: 分析:最新版本需要TP8,或装低版本的 composer require topthink/think-worker:^3.*安装后, 增加目录 vendor\workerman vendor\topthink\think-w…...

.NET内网实战:通过白名单文件反序列化漏洞绕过UAC
01阅读须知 此文所节选自小报童《.NET 内网实战攻防》专栏,主要内容有.NET在各个内网渗透阶段与Windows系统交互的方式和技巧,对内网和后渗透感兴趣的朋友们可以订阅该电子报刊,解锁更多的报刊内容。 02基本介绍 03原理分析 在渗透测试和红…...

AI Agents - 自动化项目:计划、评估和分配
Agents: Role 角色Goal 目标Backstory 背景故事 Tasks: Description 描述Expected Output 期望输出Agent 代理 Automated Project: Planning, Estimation, and Allocation Initial Imports 1.本地文件helper.py # Add your utilities or helper functions to…...

Git的.gitignore文件
一、各语言对应的.gitignore模板文件 项目地址:https://github.com/github/gitignore 二、.gitignore文件不生效 .gitignore文件只是ignore没有被追踪的文件,已被追踪的文件,要先删除缓存文件。 # 单个文件 git rm --cached file/path/to…...

网站安全,WAF网站保护暴力破解
雷池的核心功能 通过过滤和监控 Web 应用与互联网之间的 HTTP 流量,功能包括: SQL 注入保护:防止恶意 SQL 代码的注入,保护网站数据安全。跨站脚本攻击 (XSS):阻止攻击者在用户浏览器中执行恶意脚本。暴力破解防护&a…...

深度学习:梯度下降算法简介
梯度下降算法简介 梯度下降算法 我们思考这样一个问题,现在需要用一条直线来回归拟合这三个点,直线的方程是 y w ^ x b y \hat{w}x b yw^xb,我们假设斜率 w ^ \hat{w} w^是已知的,现在想要找到一个最好的截距 b b b。 一条…...

SparkSQL整合Hive后,如何启动hiveserver2服务
当spark sql与hive整合后,我们就无法启动hiveserver2的服务了,每次都要先启动hive的元数据服务(nohup hive --service metastore)才能启动hive,之前的beeline命令也用不了,hiveserver2的无法启动,这也导致我…...

前端路由如何从0开始配置?vue-router 的使用
在 Web 开发中,路由是指根据 URL 的不同部分将请求分发到不同的处理函数或页面的过程。路由是单页应用(SPA, Single Page Application)和服务器端渲染(SSR, Server-Side Rendering)应用中的一个重要概念。 在开发中如何…...

Java中的运算符【与C语言的区别】
目录 1. 算术运算符 1.0 赋值运算符: 1.1 四则运算符: - * / % 【取余与C有点不同】 1.2 增量运算符: - * / % * 【右侧运算结果会自动转换类型】 1.3 自增、自减:、-- 2. 关系运算符 3. 逻辑运算符 3.1 短路求值 3.2 【…...
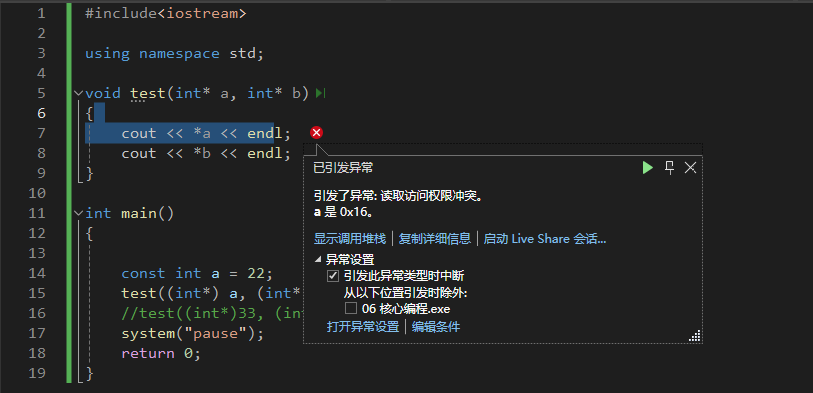
二、基础语法
入门了解 注释 **作用:**在代码中加一些注释和说明,方便自己或者其他程序员阅读代码 两种格式: 单行注释:// 描述信息 通常放在一行代码的上方,或者一条语句的末尾,对该行代码进行说明 多行注释&#x…...
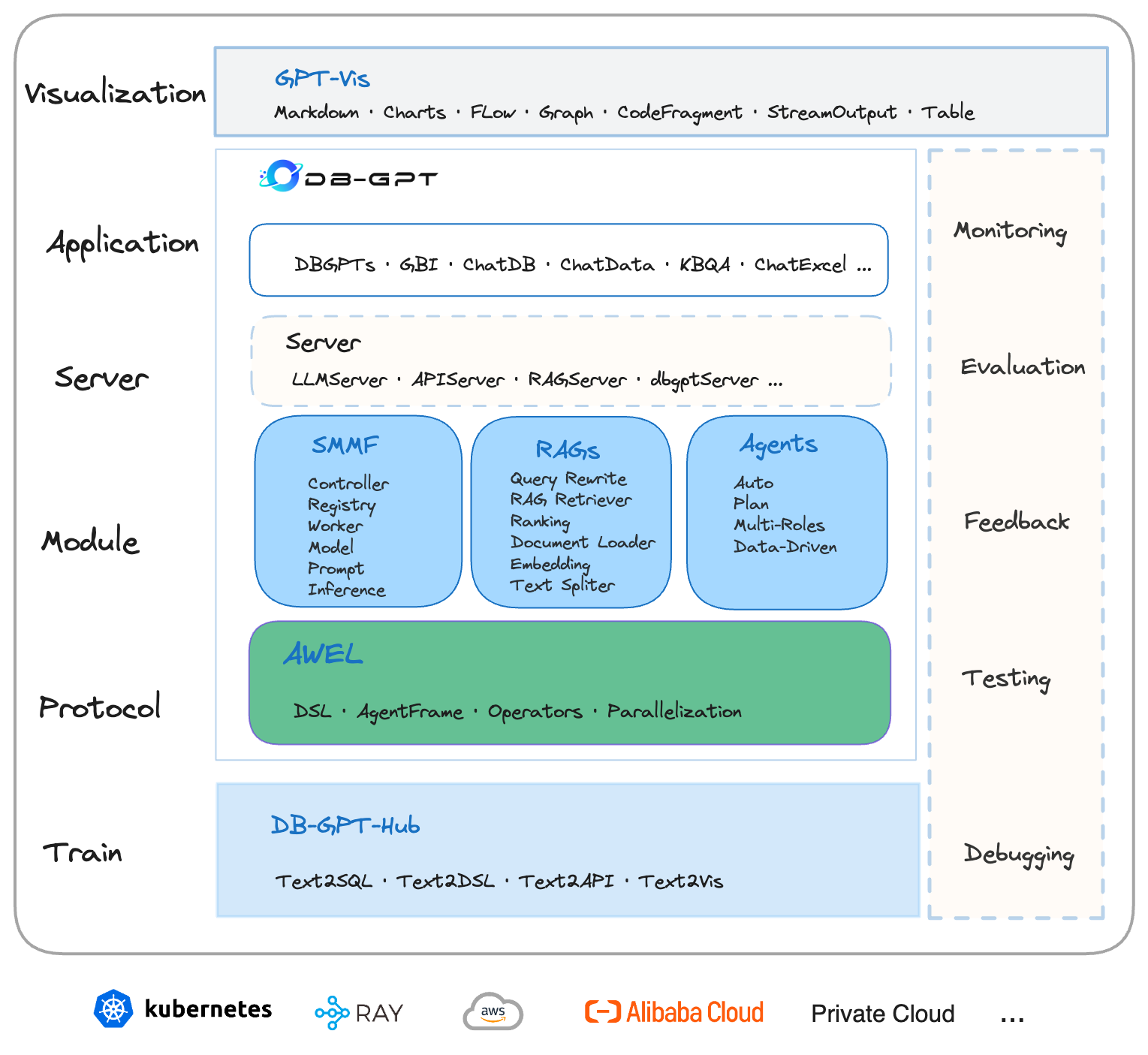
DB-GPT系列(一):DB-GPT能帮你做什么?
DB-GPT是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL and Agents),围绕大模型提供灵活、可拓展的AI原生数据应用管理与开发能力,可以帮助企业快速构建、部署智能AI数据应用,通过智能数据分析、洞察…...

【Python各个击破】numpy
简介 NumPy是一个开源的Python库,它提供了一个强大的N维数组对象和许多用于操作这些数组的函数。它是大多数Python科学计算的基础,包括Pandas、SciPy和scikit-learn等库都建立在NumPy之上。 安装 !pip install numpy导入 import numpy as np用法 # …...

【STM32 Blue Pill编程实例】-4位7段数码管使用
4位7段数码管使用 文章目录 4位7段数码管使用1、7段数码介绍2、硬件准备与接线3、模块配置4、代码实现在本文中,我们将介绍如何将 STM32 Blue Pill开发板与 4 位 7 段数码管连接,并在 STM32CubeIDE 中对其进行编程。 在文章中首先将介绍 4 位 7 段数码管及其与 STM32 Blue Pi…...
数据结构)
[进阶]java基础之集合(三)数据结构
文章目录 数据结构概述常见的数据结构数据结构(栈)数据结构(队列)数据结构(数组)数据结构(链表) 数据结构 概述 数据结构是计算机底层存储、组织数据的方式。是指数据相互之间是以什么方式排列在一起的。数据结构是为了更加方便的管理和使用数据,需要结合具体的业…...

《Apache Cordova/PhoneGap 使用技巧分享》
一、引言 在移动应用开发的领域中,Apache Cordova(也被称为 PhoneGap)是一个强大的工具,它允许开发者使用 HTML、CSS 和 JavaScript 等 Web 技术来构建跨平台的移动应用。这种方式不仅能够提高开发效率,还能降低开发成…...

SCP(Secure Copy
SCP(Secure Copy)是Linux系统下基于SSH协议的安全文件传输工具,用于在本地和远程主机间安全、快速地传输文件和目录。SCP命令通过加密传输确保数据的安全性,并且不占用过多系统资源。 SCP的基本用法 基本语法:…...

uniApp 省市区自定义数据
关于自定义省市区选择 其实也是用了 uniApp的内置组件 picker <picker mode"multiSelector" change"bindRegionChange" columnchange"bindMultiPickerColumnChange" :value"valueRegion" :range"multiArray"><v…...

图解Redis 06 | Hash数据类型的原理及应用场景
介绍 Hash 类型特别适合存储对象,例如用户信息等。 String类型也可以用于存储用户信息,Hash与String存储用户信息的区别如下图所示: 内部实现 Hash 类型 的底层数据结构是通过压缩列表(Ziplist)或哈希表ÿ…...

AI请你喝奶茶?背后其实是Function Calling
Function Calling 最近,千问“请大家喝奶茶”火了一把,这背后是一次真实的接口调用。AI它不是在聊天,而是在“调接口[下单系统]”。这种能力,就叫Function Calling。当大模型从“生成文本”升级为“调用工具”,AI 才真…...
)
Milvus单机版升级集群版实战:用milvus-backup搞定数据迁移(附完整配置文件)
Milvus单机版升级集群版实战:用milvus-backup搞定数据迁移(附完整配置文件) 当你的向量数据库从测试环境走向生产环境时,单机版Milvus往往无法满足性能和可用性需求。这时候,将数据从单机版迁移到集群版就成了必经之路…...

使用新版子开发的问题总结
目录 一、问题现象 二、根本原因 2.1 硬件差异(即使 CPU 相同) 2.2 软件差异 2.3 编译环境差异 三、为什么不能直接复制? 3.1 动态链接问题 3.2 设备树问题 3.3 路径问题 四、解决方案 4.1 方案对比 4.2 方案1:针对板子…...

DAMOYOLO-S集成JavaScript前端:打造交互式Web目标检测Demo
DAMOYOLO-S集成JavaScript前端:打造交互式Web目标检测Demo 1. 引言 你有没有想过,把一个强大的目标检测模型,变成一个在浏览器里就能直接玩的工具?比如上传一张街景照片,网页上立刻就能框出所有的车辆和行人…...

Youtu-VL-4B-Instruct轻量多模态模型优势:比Qwen-VL-2参数少60%,VQA精度高2.1%
Youtu-VL-4B-Instruct轻量多模态模型优势:比Qwen-VL-2参数少60%,VQA精度高2.1% 1. 引言 如果你正在寻找一个既强大又轻便的多模态AI模型,那么腾讯优图实验室开源的Youtu-VL-4B-Instruct-GGUF绝对值得你关注。这是一个只有40亿参数的轻量级模…...

手把手教学:Chord视频理解工具与Python爬虫集成,构建智能视频数据分析平台
手把手教学:Chord视频理解工具与Python爬虫集成,构建智能视频数据分析平台 1. 视频数据分析的自动化需求 在数字内容爆炸式增长的今天,视频数据已成为企业决策和内容创作的重要依据。然而,传统视频分析方法面临三大痛点…...

e-Paper触控驱动库PDLS_EXT3_Basic_Touch解析与迁移指南
1. 项目概述PDLS_EXT3_Basic_Touch 是 Pervasive Displays 公司为其单色电子墨水屏(e-Paper Display, EPD)配套开发的嵌入式驱动库,专为搭载 EXT3.1 主控扩展板与 EXT3-Touch 触控扩展板的硬件平台设计。该库已正式进入废弃(Depre…...
)
实战分享:如何用Python脚本快速将Anti-UAV数据集转为YOLO格式(附完整代码解析)
实战指南:Python自动化处理Anti-UAV数据集到YOLO格式的高效方案 在计算机视觉领域,无人机检测正成为安防、军事和民用场景的重要研究方向。Anti-UAV数据集作为专门针对反无人机任务构建的基准库,包含大量复杂背景下的无人机目标标注。但原始数…...

Phi-3-mini-128k-instruct企业部署:Docker Compose编排vLLM+Chainlit服务
Phi-3-mini-128k-instruct企业部署:Docker Compose编排vLLMChainlit服务 1. 模型简介 Phi-3-Mini-128K-Instruct是一个38亿参数的轻量级开放模型,属于Phi-3系列的最新成员。这个模型经过精心训练,特别适合需要高效推理能力的应用场景。 核…...

MySQL——事务管理
一、认识事务1.引入若MySQL的CURD不加控制会出现的问题:对于以上的问题,CURD 满足以下条件买票的过程是原子的买票互相不能影响买完票要永久有效买前,和买后都要是确定的状态而事务就是来解决这种问题的2.事务的概念事务的定义事务是由一组逻…...