ALIGN_ Tuning Multi-mode Token-level Prompt Alignment across Modalities

文章汇总
当前的问题
目前的工作集中于单模提示发现,即一种模态只有一个提示,这可能不足以代表一个类[17]。这个问题在多模态提示学习中更为严重,因为视觉和文本概念及其对齐都需要推断。此外,仅用全局特征来表示图像和标记是不可靠的[29,30],可能会失去目标物体的局部区域特征,导致次优分类。

1:TPT 单文本提示
2:VPT 单视觉提示
3:PLOT 通过OT(最优传输距离)寻找与图像特征最相关的prompt
4:MPT 多模态提示,即文本和图像都有提示
动机
通过分层OT(optimal transport)结合了多模态和令牌级对齐。
解决办法
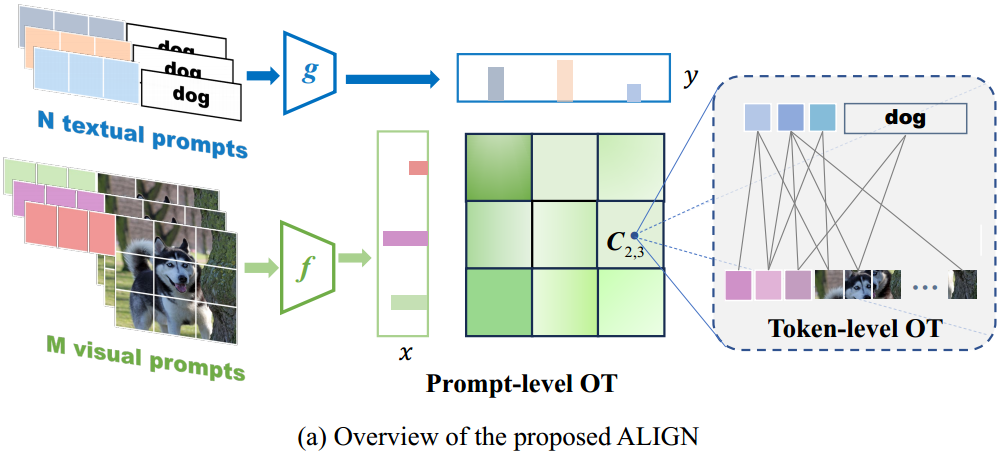
首先,每个图像以及它的标签分别有 M M M组视觉提示和 N N N组文本提示。
对应一组样本(图像和标签),我们先
寻找最佳提示(第一个OT)
现在我们有 M M M组视觉提示 { v m } m = 1 M \{v^m\}^M_{m=1} {vm}m=1M和 N N N组文本提示 { t n } n = 1 N \{t^n\}^N_{n=1} {tn}n=1N,其中每个 v m ∈ R d v × b v^m\in R^{d_v \times b} vm∈Rdv×b和 t n ∈ R d l × b t^n \in R^{d_l \times b} tn∈Rdl×b都是长度为 b b b的可学习提示序列。在数学上,我们使用两个经验分布 P P P和$ Q $来建模两种模态的集合:
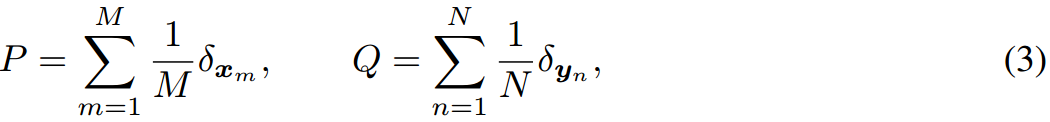
其中 x m x_m xm和 y n y_n yn表示 d d d维潜在空间的第 m m m个视觉输出和第 n n n个文本输出。它们被进一步建模为标记级嵌入上的离散分布,这将在后面介绍。Eq. 3平等地看待每个提示,并采用均匀分布的方式对权重进行建模。有了这两个语义集 P P P和 Q Q Q,图像和标签之间的距离不再是先将每个图像和标签表示为单个点,然后使用余弦相似度来计算的。ALIGN倾向于挖掘多模式特征来描述各种类概念,从而产生更好的表示。因此,距离可以表示为一个熵正则化的提示级OT问题[42]:
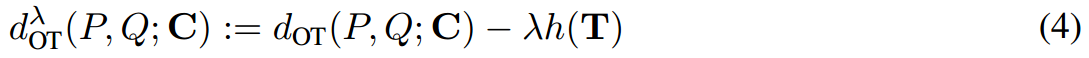
其中 λ > 0 \lambda>0 λ>0为正则化权值, C ∈ R M × N C\in R^{M\times N} C∈RM×N为视觉集 x x x与文本集 y y y之间的代价矩阵, T ∈ R M × N T\in R^{M\times N} T∈RM×N为有边际约束的待学习传输计划,如 T 1 N = 1 / M , T T 1 M = 1 / N T1_N=1/M,T^T1_M=1/N T1N=1/M,TT1M=1/N。注意, T m n T_{mn} Tmn衡量的是从第 m m m个视觉提示到第 n n n个文本提示的传递概率,较大的值意味着两个提示之间跨模态的高语义连接。因此,Eq. 4估计了 P P P和 Q Q Q之间的期望运输成本,为计算图像和标签之间的相似度提供了一个原理解决方案。
值得注意的是,Eq. 4中的代价矩阵 C C C对 T T T的学习起着至关重要的作用,直观地看,两点之间的传输代价越大,传输概率就越低。
对于每组视觉提示和每组文本提示的组合,如图中的 C 2 , 3 C_{2,3} C2,3(第2组视觉提示和第3组文本提示的组合),我们都考量它的token级别的传输代价。
考量视觉patch和文本token之间的传输成本
我们将视觉输出 x x x和文本输出 y y y指定为标记嵌入的两个经验分布(这里为了清晰起见,我们省略了下标 m m m和 n n n):
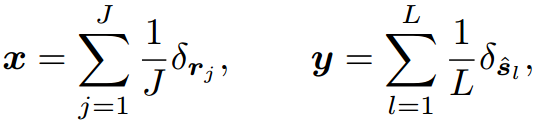
式中 r = [ e ~ 1 , … , e ~ O , v ~ 1 , … , v ~ b ] r=[\tilde{e}_1,\ldots,\tilde{e}_O,\tilde{v}_1,\ldots,\tilde{v}_b] r=[e~1,…,e~O,v~1,…,v~b]为输出的长度为 J = b + O J=b+O J=b+O的视觉patch, s = [ t ~ 1 , … , t ~ b , w ~ k , 1 , … , w ~ k , k l ] s=[\tilde{t}_1,\ldots,\tilde{t}_b,\tilde{w}_{k,1},\ldots,\tilde{w}_{k,kl}] s=[t~1,…,t~b,w~k,1,…,w~k,kl]是长度为 b + k l b+k_l b+kl的输出文本标记。与代表提示级特征的 z z z和 h h h不同, x x x和 y y y在CLIP的共享嵌入空间中收集令牌级特征。自然地,在token级OT中,代价矩阵 C ^ ∈ R J × L \hat C \in R^{J\times L} C^∈RJ×L定义为 C ^ j l = 1 − sim ( r j , s l ) \hat C_{jl}=1-\text{sim}(r_j,s_l) C^jl=1−sim(rj,sl),它衡量视觉patch和文本token之间的传输成本。因此, x x x和 y y y之间的距离是token级OT的总运输成本:
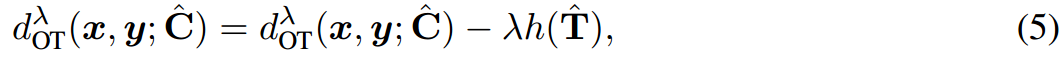
其中,传输计划 T ^ ∈ R J × L \hat T\in R^{J\times L} T^∈RJ×L表示第 j j j个视觉pacth传输到第 l l l个token特征,提供了对齐token级特征的原则解决方案。这促使我们开发了一个综合成本矩阵,同时考虑了提示和令牌级别的功能:
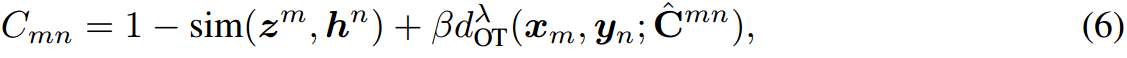
其中 β \beta β是一个权衡参数,控制令牌级成本的权重。前两项是提示级特征之间的余弦距离,最后一项是token级集之间的OT距离。通过这种方式,Eq. 6结合了来自两个层次的预训练知识:提示级特征和标记级嵌入。这使得提示级OT中学习到的传输计划 T T T能够在 M M M个视觉特征和 N N N个文本特征之间进行细粒度匹配,从而实现详细的对齐和更好的表示。
模型的预测
一旦Eq. 4被计算出来,我们按照之前的工作[17],预测图像 X j X_j Xj的标签为:
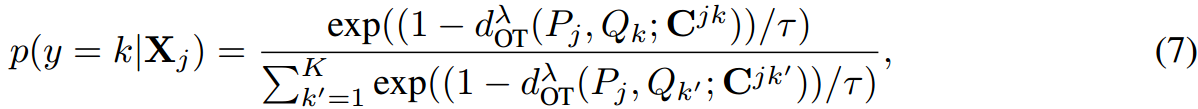
式中, C j , k C^{j,k} Cj,k为第 j j j个图像和第 k k k个标签的代价矩阵。注意,在我们的模型中,分类器 Q k Q_k Qk的权重可以看作是标签 k k k的 N N N个文本提示上的离散均匀分布,其中包含多个与类相关的语义,从而提高了分类结果。由于Sinkhorn算法可微分,通过最小化以下交叉熵损失,可以对所提模型的所有参数进行端到端优化:
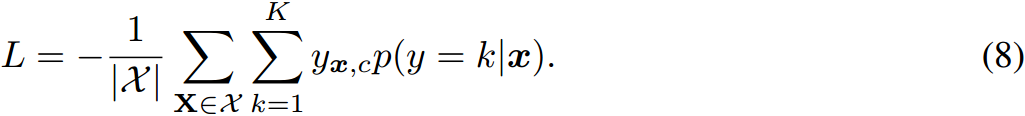
其中, y X y_X yX为图像 X X X的单热标签向量。由于采用OT公式,我们提出的ALIGN的目标是学习 M M M个视觉提示序列和 N N N个文本提示序列,而不引入任何神经网络。我们在附录算法中描述了我们提出的模型。
摘要
视觉语言模型在提示调整方面的进步强调了它们在增强开放世界视觉概念理解方面的潜力。然而,之前的工作主要集中在单模态(每种情态只有一个提示)和整体层面(图像或句子)的语义对齐上,未能捕捉到样本多样性,导致次优提示发现。为了解决这一限制,我们提出了一个多模式令牌级调优框架,该框架利用最佳传输来学习和对齐一组跨模式的提示令牌。具体来说,我们依赖于两个基本因素:1)多模式提示发现,它保证了不同的语义表示;2)令牌级对齐,它有助于探索细粒度的相似性。因此,相似性可以计算为模态特定集之间的分层运输问题。在流行的图像识别基准上进行的大量实验表明,我们的方法具有优越的泛化和少样本能力。定性分析表明,习得的提示符号具有捕捉不同视觉概念的能力。代码可在https://github.com/wds2014/ALIGN上获得。
1.介绍
最近,提示调优在使大型预训练视觉语言模型(PVLs)如CLIP[1]和BLIP[2]适应下游任务方面取得了重大进展[3-6]。一个典型的PVL模型由两个分支网络组成:文本和图像编码器。这些网络用于提取相应的模态特征。PVL通常在web规模的图像-文本对上进行对比预训练,这鼓励视觉概念与共享语义空间中的自然语言保持一致。提示调优背后的核心思想之一是将下游任务制定为原始的预训练管道。例如,CLIP用一个手动提示模板““a photo of a {class}”来设计类别描述,它在通用图像识别中工作得很好。与全微调不同,在微调中,整个模型使用特定于任务的目标进行调整,需要高昂的计算成本,并带来知识转移问题的风险[7-9],提示调优则固定模型参数并优化提示向量,提示向量作为演示来帮助提取与任务相关的特征。这大大有利于通过PVLs表示,即使在没有训练样本的情况下执行零样本推理。
然而,识别PVLs的最佳提示并不是一项简单的任务,它通常需要解决文本和视觉模式之间复杂的语义对齐问题。受神经语言模型(NLP)的提示学习[10,7,11]的启发,提出了一种称为文本提示调优(TPT)的方法来学习CLIP文本编码器的连续提示嵌入,例如,“X X X X X {class}”,其中“X”表示可学习向量[3,4]。通过特定任务损失优化,学习到的提示嵌入提取了编码在固定参数中的预训练知识,比手工方法具有更好的灵活性和效率[1]。为了提高TPT在未见类上的泛化性,许多研究试图从梯度流[12,13]、原型和作文提示学习[14-16]中给出解决方案。学习单模提示往往无法捕捉到不同的概念,各种方法都倾向于基于集成学习[1]、最优传输[17]和贝叶斯推理[18-20]来探索多个提示,从而显示出鲁棒对齐和更好的性能。
与TPT并行,视觉提示调谐(visual prompt tuning, VPT)侧重于CLIP图像编码器的patch嵌入空间[6]。VPT将图像视为一个补丁序列,并引入视觉提示来增强图像表示,例如,“X X X X X {image}”,其中“image”表示图像补丁序列。VPT提供了一种简单高效的提取任务相关视觉特征的思路,已被广泛应用于许多视觉任务,如视频理解[21]、领域自适应[22]、迁移学习[23]和图像分割[24-26]。最近出现了将TPT和VPT结合起来学习多模态提示的研究趋势[27,28]。然而,他们目前集中于单模提示发现,即一种模态只有一个提示,这可能不足以代表一个类[17]。这个问题在多模态提示学习中更为严重,因为视觉和文本概念及其对齐都需要推断。此外,仅用全局特征来表示图像和标记是不可靠的[29,30],可能会失去目标物体的局部区域特征,导致次优分类。
图1:最近的提示调优方法中的对齐比较。提出的ALIGN同时学习多模态多模提示,从而实现全面对齐。
为此,本工作开发了一个全面的提示调优框架,其中通过构建提示和令牌级最佳传输(OT)来学习多模式多模式提示。形式上,在向模态特定的编码器提供多个提示输入后,我们的提示级OT将每个图像视为视觉提示空间上的离散分布 P P P,并将每个标签视为文本提示空间上的离散分布 Q Q Q。有了这样的表述,分类任务就变成了测量 P P P和 Q Q Q之间的距离。此外,伴随着全局提示级特征,patch(或token)嵌入捕获目标对象的局部区域特征(或类别描述)。这激发了令牌级OT,其中每个提示输出都被建模为令牌嵌入空间上的离散分布。然后在视觉补丁和文本标记之间计算成本矩阵,从而实现标记级对齐。至关重要的是,提示级OT中的成本矩阵(衡量来自两个域的提示之间的传输成本)现在被转换为集成全局特征和令牌级OT的输出。这种分层连接使得使用详细的标记和补丁特征来预测标签成为可能,从而提高了准确性。
总之,我们的方法提供了一个新的提示调优框架,该框架通过分层OT结合了多种模式和令牌级对齐。提示级OT从图像和语言领域学习类的不同语义,而令牌级OT探索令牌嵌入之间的细粒度对齐。值得注意的是,通过不同的超参数设置,所提出的模型的变体涵盖了许多以前的工作,为跨不同应用的轻松适应提供了灵活性。本文的主要贡献如下:
•我们提出了一个用于多模态提示调优的多模式令牌级对齐框架,其中学习了多个提示以改进视觉和文本模式的表示。通过特殊的设置,许多以前的作品可以边缘到我们的框架中。
•我们将提示调优任务表述为分布匹配问题,并开发了提示和令牌级OT,以原则性和优雅的解决方案来处理该任务。
•我们将我们的方法应用于少样本分类、数据集迁移学习和领域泛化。在广泛使用的数据集上的实验结果表明了该模型的优越性。
2.背景
2.1 多模态提示微调
多模态提示调谐(Multi-modal prompt tuning, MPT)[28,27]是一项新开发的任务,它可以联合学习PVLs的文本和视觉提示。联合调谐范例不是单独优化单峰提示,而是利用PVLs的两个分支网络,而且在训练期间允许两种模式之间的交互,从而实现动态对齐。例如,我们使用基于CLIP的视觉转换器(ViT),它由ViT作为图像编码器 f f f和transformer作为语言编码器 g g g组成。给定输入图像 X ∈ R H × W × 3 X\in R^{H\times W \times 3} X∈RH×W×3和 K K K个标签名称 { c l a s s k } k = 1 K \{{class}_k\}^K_{k=1} {classk}k=1K。MPT首先将 b b b个可学习的标记作为视觉提示 { v i ∈ R d v } i = 1 b \{v_i\in R^{d_v}\}^b_{i=1} {vi∈Rdv}i=1b,并将另一组 b b b个可学习的标记作为文本提示 { t i ∈ R d l } i = 1 b \{t_i\in R^{d_l}\}^b_{i=1} {ti∈Rdl}i=1b。将它们与图像补丁和类名连接起来,可以得到CLIP的输出如下:
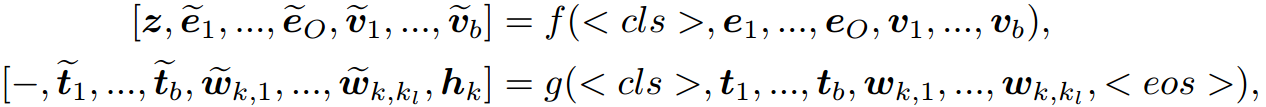
其中 < c l s > , < e o s > <cls>,<eos> <cls>,<eos>为虚拟令牌, [ e 1 , … , e O ] [e_1,\ldots,e_O] [e1,…,eO]为 O O O个图像补丁嵌入, [ w k , 1 , … , w k , k l ] [w_{k,1},\ldots,w_{k,k_l}] [wk,1,…,wk,kl]是长度为 k l k_l kl的第 k k k类token嵌入。在 f f f和 g g g的自关注层堆叠后,CLIP输出标记嵌入,并将 z z z和 h k h_k hk分别视为图像和标签的提示级特征。实证研究表明,通过视觉-语言映射函数如 v = F ( t ) v = F(t) v=F(t)投射语言提示 t t t,比独立学习语言提示 t t t更有效地获得视觉提示 v v v[28,6]。最后,MPT根据余弦相似度得分估计 x x x的标签:

式中 τ \tau τ为固定温度参数。MPT统一了TPT和VPT的思想,同时对视觉提示符 v v v和文本提示符 t t t进行直接调优。Eq. 1表示文本编码器 g g g以分类提示作为输入,输出 h h h作为相应的分类器权值。由于CLIP中预先训练的知识,MPT保留了执行开集分类的能力。注意CLIP中的编码器 f f f和 g g g都是冻结的,只有提示序列 v v v和 t t t在下游训练期间被优化。这个过程可以看作是引导编码器提取任务相关特征的一个引导步骤。
2.2 最优运输距离
最优传输(Optimal transport, OT)是测量两个分布之间距离的有效工具,在最近的机器学习研究中被广泛使用,如文本分析[31-33]、计算机视觉[34 - 39]和生成模型[40,41]。在这里,我们回顾离散OT匹配,详细信息请参阅[42]。给定两组数据点 X = { x i } i = 1 m X=\{x_i\}^m_{i=1} X={xi}i=1m和 Y = { y j } j = 1 n Y=\{y_j\}^n_{j=1} Y={yj}j=1n,其离散分布分别表示为 p = ∑ i = 1 m a i δ x i p=\sum^m_{i=1}{a_i \delta_{x_i}} p=∑i=1maiδxi和 q = ∑ j = 1 m b i δ y i q=\sum^m_{j=1}{b_i \delta_{y_i}} q=∑j=1mbiδyi。 a ∈ Δ m , b ∈ Δ n a \in \Delta^m ,b \in \Delta^n a∈Δm,b∈Δn,其中 Δ m \Delta^m Δm为 R m R^m Rm的简单概率。我们定义 X X X和 Y Y Y之间的成本矩阵为 C = ( C i j ) ∈ R ≥ 0 m × n C=(C_{ij}) \in R^{m\times n}_{\ge 0} C=(Cij)∈R≥0m×n,其中 C i j = c ( x i , y j ) C_{ij}=c(x_i,y_j) Cij=c(xi,yj)为从 x i x_i xi到 y j y_j yj的运输成本, C C C为成本函数。OT的目标是以最小的成本将 p p p传输到 q q q:
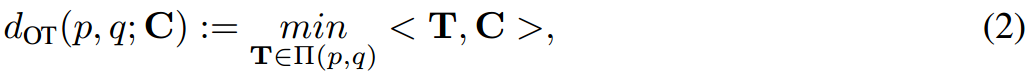
其中 < ⋅ , ⋅ > <\cdot,\cdot> <⋅,⋅>表示Frobenius点积, T ∈ R > 0 m × n T \in \mathbb{R}^{m\times n}_{> 0} T∈R>0m×n表示要学习的传输方案。然后在 m × n m\times n m×n空间的所有联合概率上最小化OT距离,并具有两个边缘约束 Π ( p , q ) : = { T : T 1 n = a , T T 1 m = b } \Pi(p,q):=\{T:T 1_n=a,T^T1_m=b\} Π(p,q):={T:T1n=a,TT1m=b},其中 1 m 1_m 1m表示 m m m维的全1向量。由于在Eq. 2中直接学习最优计划 T T T对于大规模问题可能会很耗时,因此来自[42,43]的Sinkhorn距离引入了对传输计划 h ( T ) = ∑ m , n − T m n In ( T m n ) h(T)=\sum_{m,n}-T_{mn}\text{In}(T_{mn}) h(T)=∑m,n−TmnIn(Tmn)的熵约束,因此得到的算法在几次迭代内估计出 T T T,具有更好的灵活性和可扩展性。
3. 提出的方法
3.1 总体方法
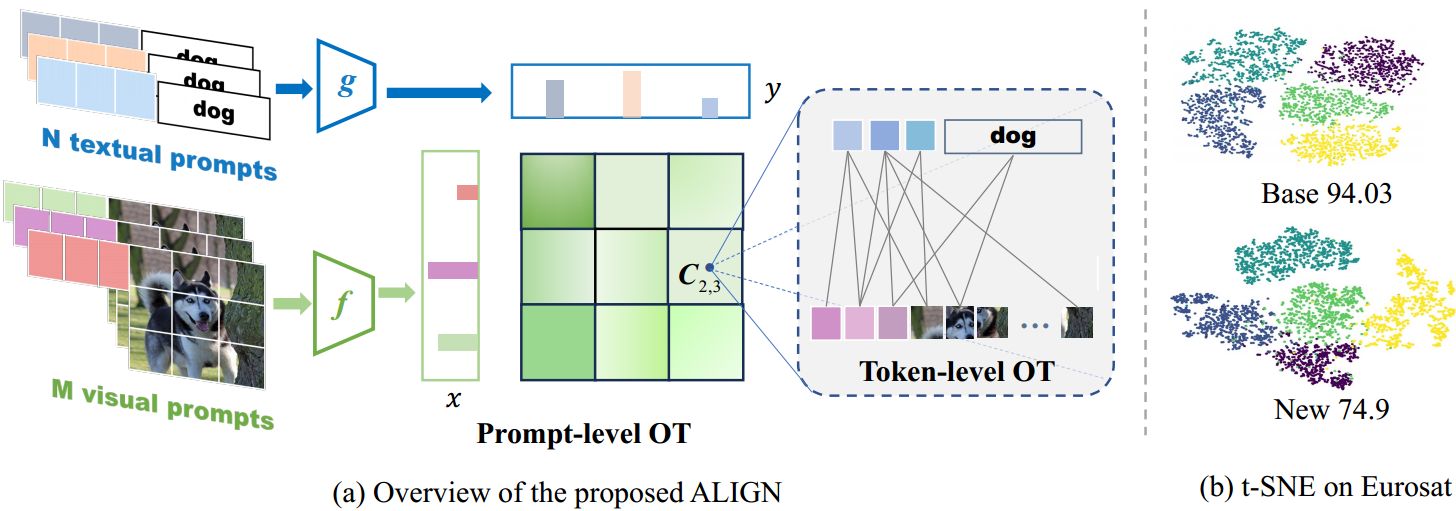
图2:(a)提议的ALIGN的框架。ALIGN通过将特定于模式的分布与分层OT对齐来学习PVLs的多个提示。(b) ALIGN图像嵌入的t-SNE可视化。
在本节中,我们将介绍我们提出的模型的技术细节,该模型名为ALIGN,它是一个用于优化传输的多模式提示调整的整体框架(如图2所示)。得益于精心设计的多模式令牌级对齐模块,大多数现有工作可以通过特殊设置合并到我们的ALIGN中。从直观上讲,人类学习一个具有各种概念的类,这些概念提供了足够的语义特征,如颜色、布局、形状等,从而将其与其他类区分开来[17]。受此启发,本作品的目标之一是同时学习 M M M个视觉提示和 N N N个文本提示。具体来说,我们首先引入提示级OT,其中每个图像和标签都被建模为 M M M维视觉空间和 N N N维文本空间上的离散分布 P P P和 Q Q Q。此外,我们没有将提示输出表示为单个点,例如全局特征 z z z和 h h h,而是提取了CLIP中隐含的令牌级知识。回顾一下,第 k k k类的第 n n n个文本提示输出包含 b + k l b + k_l b+kl个标记嵌入,图像的第 m m m个视觉提示输出包含 b + O b + O b+O个补丁嵌入,它们捕获了相应模态的局部区域特征。这促使我们开发令牌级别的OT,为细粒度的对齐进行令牌级别的比较。因此, P P P和 Q Q Q中的第 m m m和 n n n个点本身被进一步建模为共享令牌嵌入空间上的离散分布。由于令人信服的两级OT连接,其中提示级OT中的成本矩阵由令牌级OT的输出获得,学习的传输计划捕获提示和令牌级特征,这提供了一种原则和优雅的方法来估计标签和图像集之间的距离。
3.2 多模式token级提示对齐
在MPT学习单模提示来描述类并基于提示级特征估计相似性的基础上,我们的目标是探索文本和视觉域的多模式表示,并进行细粒度对齐以提高预测精度。现在我们有 M M M组视觉提示 { v m } m = 1 M \{v^m\}^M_{m=1} {vm}m=1M和 N N N组文本提示 { t n } n = 1 N \{t^n\}^N_{n=1} {tn}n=1N,其中每个 v m ∈ R d v × b v^m\in R^{d_v \times b} vm∈Rdv×b和 t n ∈ R d l × b t^n \in R^{d_l \times b} tn∈Rdl×b都是长度为 b b b的可学习提示序列。在数学上,我们使用两个经验分布 P P P和 Q Q Q来建模两种模态的集合:
其中 x m x_m xm和 y n y_n yn表示 d d d维潜在空间的第 m m m个视觉输出和第 n n n个文本输出。它们被进一步建模为标记级嵌入上的离散分布,这将在后面介绍。Eq. 3平等地看待每个提示,并采用均匀分布的方式对权重进行建模。有了这两个语义集 P P P和 Q Q Q,图像和标签之间的距离不再是先将每个图像和标签表示为单个点,然后使用余弦相似度来计算的。ALIGN倾向于挖掘多模式特征来描述各种类概念,从而产生更好的表示。因此,距离可以表示为一个熵正则化的提示级OT问题[42]:
其中 λ > 0 \lambda>0 λ>0为正则化权值, C ∈ R M × N C\in R^{M\times N} C∈RM×N为视觉集 x x x与文本集 y y y之间的代价矩阵, T ∈ R M × N T\in R^{M\times N} T∈RM×N为有边际约束的待学习传输计划,如 T 1 N = 1 / M , T T 1 M = 1 / N T1_N=1/M,T^T1_M=1/N T1N=1/M,TT1M=1/N。注意, T m n T_{mn} Tmn衡量的是从第 m m m个视觉提示到第 n n n个文本提示的传递概率,较大的值意味着两个提示之间跨模态的高语义连接。因此,Eq. 4估计了 P P P和 Q Q Q之间的期望运输成本,为计算图像和标签之间的相似度提供了一个原理解决方案。
值得注意的是,Eq. 4中的代价矩阵 C C C对 T T T的学习起着至关重要的作用,直观地看,两点之间的传输代价越大,传输概率就越低。
一个自然的选择是用全局特征 C m n = 1 − sim ( z m , h n ) C_{mn}=1-\text{sim}(z^m,h^n) Cmn=1−sim(zm,hn)来指定 C C C,其中 z m , h n z^m,h^n zm,hn分别表示第 m m m个视觉提示和第 n n n个文本提示的提示级特征。然而,上述定义主要强调提示级表示,并且可能具有有限的捕获详细令牌级特征的能力,例如,图像中的不同补丁可能捕获不同的局部区域特征。因此,获得的传输计划可能无法反映 P P P和 Q Q Q之间的真实关系。为此,我们进一步引入考虑两个提示之间的令牌级对齐的令牌级OT。具体来说,我们将视觉输出 x x x和文本输出 y y y指定为标记嵌入的两个经验分布(这里为了清晰起见,我们省略了下标 m m m和 n n n):
式中 r = [ e ~ 1 , … , e ~ O , v ~ 1 , … , v ~ b ] r=[\tilde{e}_1,\ldots,\tilde{e}_O,\tilde{v}_1,\ldots,\tilde{v}_b] r=[e~1,…,e~O,v~1,…,v~b]为输出的长度为 J = b + O J=b+O J=b+O的视觉patch, s = [ t ~ 1 , … , t ~ b , w ~ k , 1 , … , w ~ k , k l ] s=[\tilde{t}_1,\ldots,\tilde{t}_b,\tilde{w}_{k,1},\ldots,\tilde{w}_{k,kl}] s=[t~1,…,t~b,w~k,1,…,w~k,kl]是长度为 b + k l b+k_l b+kl的输出文本标记。与代表提示级特征的 z z z和 h h h不同, x x x和 y y y在CLIP的共享嵌入空间中收集令牌级特征。自然地,在token级OT中,代价矩阵 C ^ ∈ R J × L \hat C \in R^{J\times L} C^∈RJ×L定义为 C ^ j l = 1 − sim ( r j , s l ) \hat C_{jl}=1-\text{sim}(r_j,s_l) C^jl=1−sim(rj,sl),它衡量视觉patch和文本token之间的传输成本。因此, x x x和 y y y之间的距离是token级OT的总运输成本:
其中,传输计划 T ^ ∈ R J × L \hat T\in R^{J\times L} T^∈RJ×L表示第 j j j个视觉pacth传输到第 l l l个token特征,提供了对齐token级特征的原则解决方案。这促使我们开发了一个综合成本矩阵,同时考虑了提示和令牌级别的功能:
其中 β \beta β是一个权衡参数,控制令牌级成本的权重。前两项是提示级特征之间的余弦距离,最后一项是token级集之间的OT距离。通过这种方式,Eq. 6结合了来自两个层次的预训练知识:提示级特征和标记级嵌入。这使得提示级OT中学习到的传输计划 T T T能够在 M M M个视觉特征和 N N N个文本特征之间进行细粒度匹配,从而实现详细的对齐和更好的表示。
一旦Eq. 4被计算出来,我们按照之前的工作[17],预测图像 X j X_j Xj的标签为:
式中, C j , k C^{j,k} Cj,k为第 j j j个图像和第 k k k个标签的代价矩阵。注意,在我们的模型中,分类器 Q k Q_k Qk的权重可以看作是标签 k k k的 N N N个文本提示上的离散均匀分布,其中包含多个与类相关的语义,从而提高了分类结果。由于Sinkhorn算法可微分,通过最小化以下交叉熵损失,可以对所提模型的所有参数进行端到端优化:
其中, y X y_X yX为图像 X X X的单热标签向量。由于采用OT公式,我们提出的ALIGN的目标是学习 M M M个视觉提示序列和 N N N个文本提示序列,而不引入任何神经网络。我们在附录算法中描述了我们提出的模型。
4.相关工作
单模态提示微调:有两种单模态提示调音的故事情节,TPT和VPT。前者关注PLV的语言分支,对连续嵌入空间中的快速学习感兴趣。作为代表性作品之一,CoOp[3]使用一组可学习的向量对提示上下文进行建模,并显示出比密集调优的手动提示有很大改进。为了解决未见类别的弱泛化性,CoCoOp[4]通过显式地对图像实例进行条件反射来扩展CoOp,这将注意力从特定的类集转移到每个输入实例,从而实现更强的泛化性能。PLOT[17]不是单模提示学习,而是利用提示与图像patch之间的OT距离学习多个文本提示,实现多元提示调优。ProDA[19]首先成熟地设计了多个提示,然后利用高斯分布对提示嵌入进行建模,对提示的不确定性进行建模。相应的,vpt指的是在图像输入空间中预先添加视觉补丁,这也显示了将vpt用于下游任务的令人印象深刻的结果。例如,Jia等[6]将可训练的视觉提示向量引入到每个Transformer层的图像patch序列中,并与线性头部一起学习。尽管这些模型在各种视觉任务上表现良好,但它们被设计为学习单模态提示,无法利用预训练的多模态知识。
多模态提示调优:超越单模态提示调优,MPT是最近引入的一项任务,它可以同时学习文本提示和视觉提示。这种联合调优策略不仅提取了多模态知识,而且支持跨模态提示之间的动态对齐,显示出更好的泛化。Zang等人[27]提出了一个统一的提示调整框架(UPT)[27],它在不同的模态之间共享一个初始提示,并设计了一个微小的网络来共同生成特定于模态的提示。几乎与UPT平行,Khattak等人[28]提出了多模态提示调谐(MaPLe),并采用投影矩阵明确地对其语言对应的视觉提示进行条件调整,允许梯度的相互传播以促进协同。相比之下,本工作旨在学习多模态多模提示,以更好地满足多样化综合表征的要求。此外,与通过全局提示级特征来衡量图像和标签之间的相似性不同,我们将每个提示建模为标记级嵌入空间上的经验分布,并在分层OT框架下将提示和标记级特征结合起来计算相似性得分,这为PVL适应下游任务提供了一种新颖而优雅的工具。
5.实验
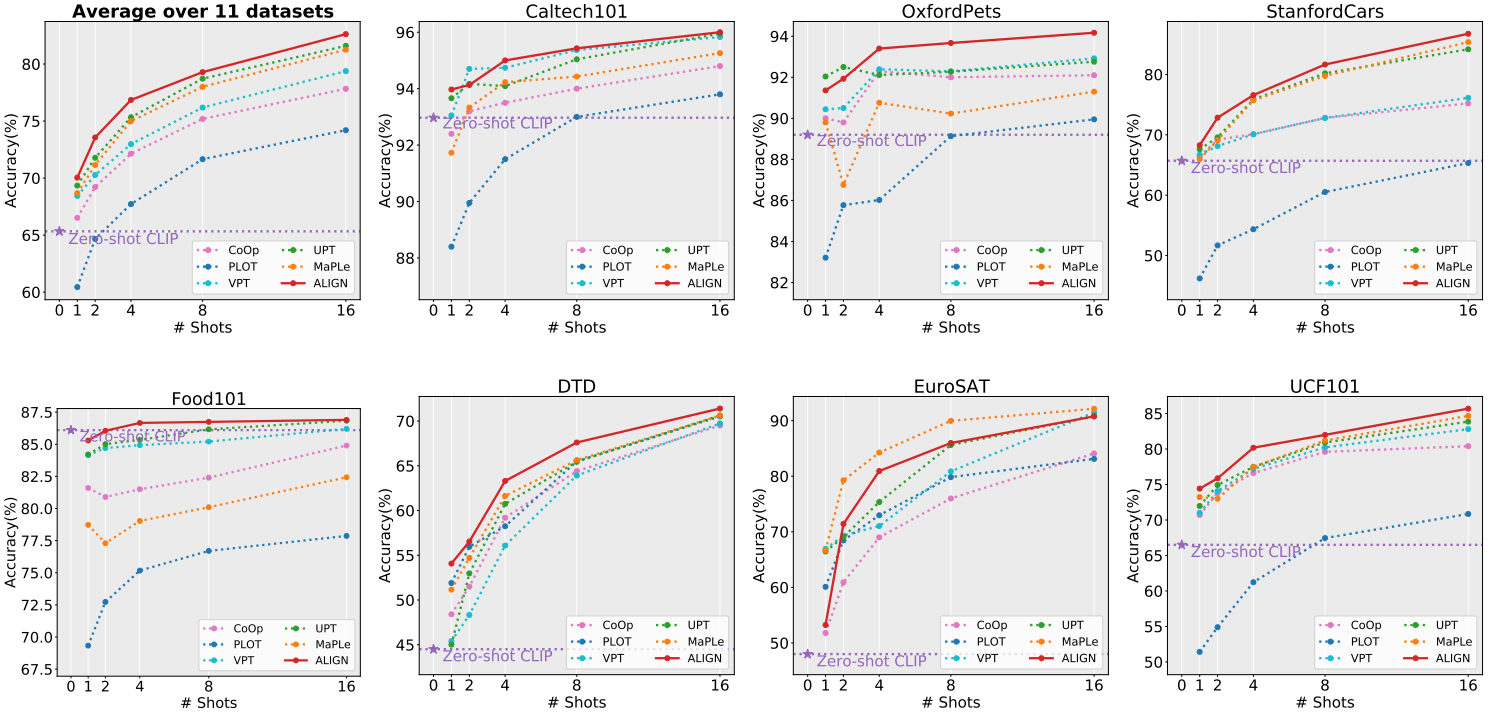
图3:7个数据集的小样本学习结果(其他数据集的更详细结果见附录表)d . 1)。红色实线表示ALIGN方法,虚线表示各种基线。所有结果以三个种子的平均值报告。
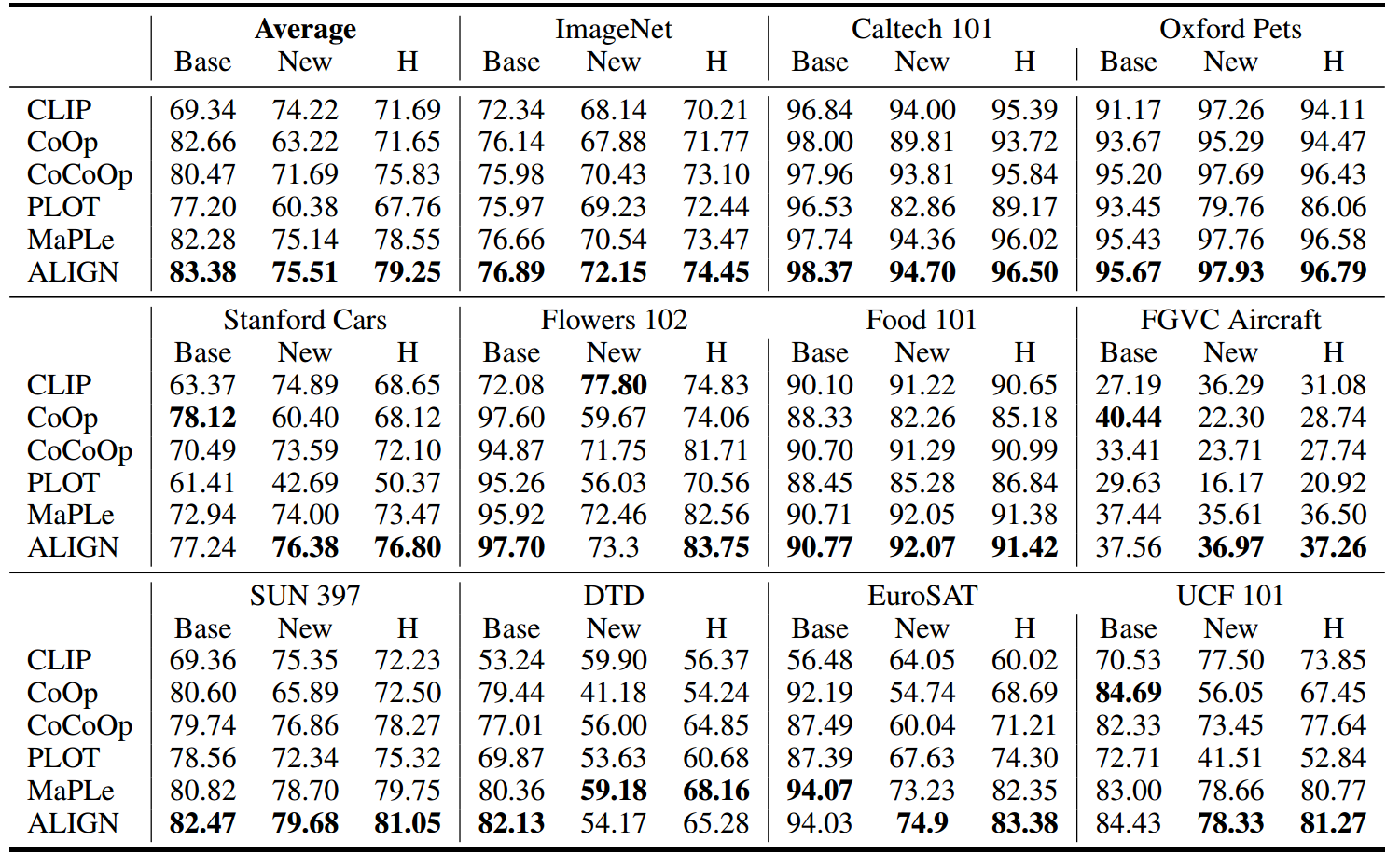
表1:在11个数据集上从基础到新。提示是从16发基本设置中学习的。我们报告了基集(base)、新集(new)及其调和均值(H)的分类精度,其中 H = ( 2 × b a s e × n e w ) / ( b a s e + n e w ) H = (2 × base × new)/(base + new) H=(2×base×new)/(base+new)。最好的结果被突出显示。
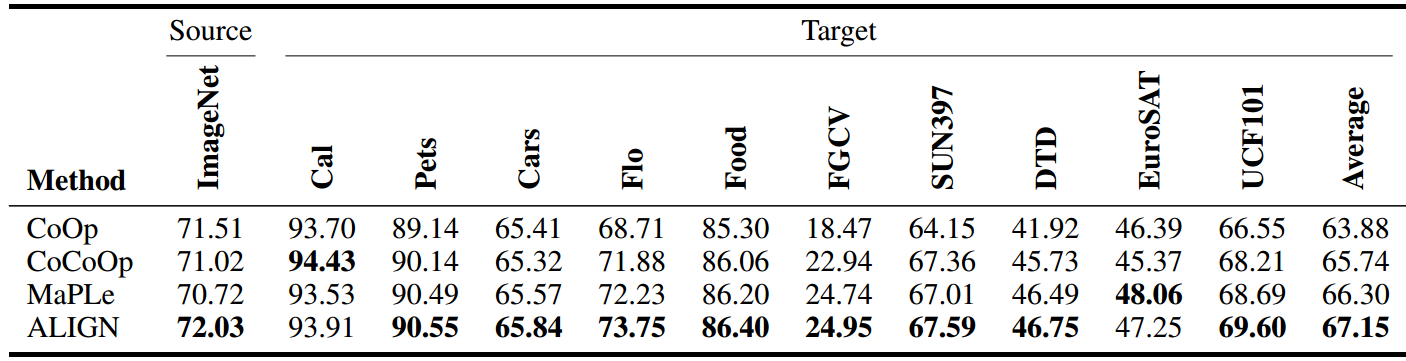
表2:跨数据集迁移学习准确率结果。这里我们使用关键字母来表示数据集。最好的结果被突出显示。
表3:跨域概化精度结果。最好的结果被突出显示。
6.结论
提出了一种新的多模式令牌级对齐框架,用于最优运输下的多模式提示调整。我们首先使用提示级OT对跨模式的多模式提示进行建模,然后通过将每个提示本身视为令牌嵌入空间上的集合来引入令牌级OT。通过成本矩阵耦合这些两级OT,通过结合提示级特征和标记级嵌入来获得最终预测,从而实现细粒度对齐。大量的实验表明,我们提出的模型在四种设置下达到了竞争性能。就局限性而言,用户可能仍然需要较大的GPU内存来加载预训练的PVL权重,以便将提议的模型应用于测试过程。一个潜在的解决方案是将提示调优与知识蒸馏结合起来。我们把它留给未来的研究。由于对PVL的开放世界视觉概念的理解,我们的模型显示出有希望的零样本/少样本图像识别能力,这有可能鼓励研究人员获得新的更好的方法来提示调整。我们的工作可能会间接导致负面影响,如果有一个足够恶意或不知情的选择,少样本的分类任务。
参考资料
论文下载(NeurIPS 2023)
https://arxiv.org/abs/2309.13847

代码地址
https://github.com/wds2014/ALIGN
附录

相关文章:
ALIGN_ Tuning Multi-mode Token-level Prompt Alignment across Modalities
文章汇总 当前的问题 目前的工作集中于单模提示发现,即一种模态只有一个提示,这可能不足以代表一个类[17]。这个问题在多模态提示学习中更为严重,因为视觉和文本概念及其对齐都需要推断。此外,仅用全局特征来表示图像和标记是不…...

【Java SE】代码注释
代码注释 注释(comment)是用于说明解释程序的文字,注释的作用在于提高代码的阅读性(可读性)。Java中的注释类型包括3种,分别是: 单行注释多行注释文档注释 ❤️ 单行注释 基本格式ÿ…...

如何在算家云搭建Llama3-Factory(智能对话)
一、Llama3-Factory 简介 当地时间 4 月 18 日,Meta 在官网上宣布公布了旗下最新大模型 Llama 3。目前,Llama 3 已经开放了 80 亿(8B)和 700 亿(70B)两个小参数版本,上下文窗口为 8k。Llama3 是…...

操作数据表
创建表 创建表语法: CREATE TABLE table_name ( field1 datatype [COMMENT 注释内容], field2 datatype [COMMENT 注释内容], field3 datatype ); 注意: 1. 蓝色字体为关键字 2. CREATE TABLE 是创建数据表的固定关键字,表…...
)
C# 实现进程间通信的几种方式(完善)
目录 引言 一、基本概念 二、常见的IPC方法 1. 管道(Pipes) 2. 共享内存(Shared Memory) 3. 消息队列(Message Queues) 4. 套接字(Sockets) 5. 信号量(Semaphore…...

MySQL Workbench Data Import Wizard:list index out of range
MySQL Workbench的Data Import Wizard功能是用python实现的,MySQL Workbench自带了一个python,数据导入的时候出现错误提示 22:55:51 [ERR][ pymforms]: Unhandled exception in Python code: Traceback (most recent call last): File "D…...

微信支付宝小程序SEO优化的四大策略
在竞争激烈的小程序市场中,高搜索排名意味着更多的曝光机会和潜在用户。SEO即搜索引擎优化,对于小程序而言,主要指的是在微信小程序商店中提高搜索排名,从而增加曝光度和用户访问量。有助于小程序脱颖而出,提升品牌知名…...

AutoDIR: Automatic All-in-One Image Restoration with Latent Diffusion论文阅读笔记
AutoDIR: Automatic All-in-One Image Restoration with Latent Diffusion 论文阅读笔记 这是ECCV2024的论文,作者单位是是港中文和上海AI Lab 文章提出了一个叫AutoDIR的方法,包括两个关键阶段,一个是BIQA,基于vision-language…...

SQLite 数据库设计最佳实践
SQLite特点 SQLite是一款功能强大的 轻量级嵌入式数据库 ,具有以下显著特点: 体积小 :最低配置仅需几百KB内存,适用于资源受限环境。 高性能 :访问速度快,运行效率高于许多开源数据库。 高度可移植 :兼容多种硬件和软件平台。 零配置 :无需复杂设置,开箱即用。 自给自…...

【论文精读】ID-like Prompt Learning for Few-Shot Out-of-Distribution Detection
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀论文精读_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 注:下文…...

Android 10.0 根据包名禁用某个app的home事件
1.前言 在10.0的系统rom定制化开发中,在某些app中,需要禁用home事件,在普通的app中又无法 禁用home事件,所以就需要从系统中来根据包名禁用home事件了,接下来分析下 系统中处理home事件的相关流程 2.根据包名禁用某个app的home事件的核心类 frameworks/base/services/c…...

Rust 文档生成与发布
目录 第三节 文档生成与发布 1. 使用 RustDoc 生成项目文档 1.1 RustDoc 的基本使用 1.2 文档注释的格式与实践 1.3 生成文档的其他选项 1.4 在 CI/CD 中生成文档 2. 发布到 crates.io 的步骤与注意事项 2.1 创建 crates.io 账户 2.2 配置 Cargo.toml 2.3 生成发布版…...

【C++动态规划】有效括号的嵌套深度
本文涉及知识点 C动态规划 LeetCode1111. 有效括号的嵌套深度 有效括号字符串 定义:对于每个左括号,都能找到与之对应的右括号,反之亦然。详情参见题末「有效括号字符串」部分。 嵌套深度 depth 定义:即有效括号字符串嵌套的层…...
2024年优秀的天气预测API
准确、可操作的天气预报对于许多组织的成功至关重要。 事实上,在整个行业中,天气条件会直接影响日常运营,包括航运、按需、能源和供应链(仅举几例)。 以公用事业为例。根据麦肯锡的数据,在 1.4 年的时间里…...

Android和iOS有什么区别?
Android 和 iOS 有以下区别: 开发者与所属公司: Android:由谷歌公司开发以及开放手机联盟维护。它是基于 Linux 内核和其他开源软件的修改版本,代码开源程度较高,许多厂商都可以基于 Android 源代码进行深度定制和开发…...

NVR小程序接入平台/设备EasyNVR多个NVR同时管理多平台级联与上下级对接的高效应用
政务数据共享平台的建设正致力于消除“信息孤岛”现象,打破“数据烟囱”,实现国家、省、市及区县数据的全面对接与共享。省市平台的“级联对接”工作由多级平台共同构成,旨在满足跨部门、跨层级及跨省数据共享的需求,推动数据流通…...

Spring Cloud Sleuth(Micrometer Tracing +Zipkin)
分布式链路追踪 分布式链路追踪技术要解决的问题,分布式链路追踪(Distributed Tracing),就是将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式请求的调用情况集中展示。比如各个服务节…...

人工智能:机遇与挑战
人工智能(AI)作为当今世界科技发展的前沿领域,正在以前所未有的速度和规模影响着我们的生活和工作方式。AI技术的应用前景广阔,从医疗健康到金融服务,从教育到交通,再到娱乐和家庭生活,AI正在逐…...

mac电脑设置crontab定时任务,以及遇到的问题解决办法
crontab常用命令 crontab -u user:用来设定某个用户的crontab服务; crontab file:file是命令文件的名字,表示将file做为crontab的任务列表文件并载入crontab。如果在命令行中没有指定这个文件,crontab命令将接受标准输入…...

Backtrader 数据篇 02
Backtrader 数据篇 本系列是使用Backtrader在量化领域的学习与实践,着重介绍Backtrader的使用。Backtrader 中几个核心组件: Cerebro:BackTrader的基石,所有的操作都是基于Cerebro的。Feed:将运行策略所需的基础数据…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...