Python数据分析NumPy和pandas(十七、pandas 二进制格式文件处理)
以二进制格式存储(或序列化)数据的一种简单方法是使用 Python 的内置 pickle 模块。同时,pandas 构造的对象都有一个 to_pickle 方法,该方法以 pickle 格式将数据写入磁盘。
我们先把之前示例用到的ex1.csv文件加载到pandas对象中,然后将数据以二进制pickle格式写入examples/frame_pickle文件中:
import pandas as pdframe = pd.read_csv("examples/ex1.csv")
frame.to_pickle("examples/frame_pickle")以上代码会将数据输出到一个frame_pickle文件中:

Pickle 文件通常仅在 Python 中可读。可以直接使用内置的 pickle 来读取存储在文件中的任何 “pickled” 对象,或者用更简单方便的方式来读取,就是 pandas.read_pickle,我们把上面生成的frame_pickle文件加载回来:pd.read_pickle("examples/frame_pickle") 可以打印出来会输出以下内容:
| a | b | c | d | message | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 5 | 6 | 7 | 8 | world |
| 2 | 9 | 10 | 11 | 12 | foo |
注意:Pickle 仅推荐作为短期存储格式。问题在于很难保证格式会随着时间的推移而稳定;例如,今天被 picked 的对象可能无法使用更高版本的 library来unpickle 。pandas 会尽可能保持向后兼容性,但在将来,可能需要 “打破” 当前的pickle 格式。
pandas 也内置了对其他几种开源二进制数据格式的支持,例如 HDF5、ORC 和 Apache Parquet。例如,如果安装了 pyarrow (pip install pyarrow或conda install pyarrow),则可以使用 pandas.read_parquet 读取 Parquet 文件。
fec = pd.read_parquet('datasets/fec/fec.parquet')
fec.head()
输出前5行:
| cmte_id | cand_id | cand_nm | contbr_nm | contbr_city | contbr_st | contbr_zip | contbr_employer | contbr_occupation | contb_receipt_amt | contb_receipt_dt | receipt_desc | memo_cd | memo_text | form_tp | file_num | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | C00410118 | P20002978 | Bachmann, Michelle | HARVEY, WILLIAM | MOBILE | AL | 366010290 | RETIRED | RETIRED | 250.0 | 20-JUN-11 | None | None | None | SA17A | 736166 |
| 1 | C00410118 | P20002978 | Bachmann, Michelle | HARVEY, WILLIAM | MOBILE | AL | 366010290 | RETIRED | RETIRED | 50.0 | 23-JUN-11 | None | None | None | SA17A | 736166 |
| 2 | C00410118 | P20002978 | Bachmann, Michelle | SMITH, LANIER | LANETT | AL | 368633403 | INFORMATION REQUESTED | INFORMATION REQUESTED | 250.0 | 05-JUL-11 | None | None | None | SA17A | 749073 |
| 3 | C00410118 | P20002978 | Bachmann, Michelle | BLEVINS, DARONDA | PIGGOTT | AR | 724548253 | NONE | RETIRED | 250.0 | 01-AUG-11 | None | None | None | SA17A | 749073 |
| 4 | C00410118 | P20002978 | Bachmann, Michelle | WARDENBURG, HAROLD | HOT SPRINGS NATION | AR | 719016467 | NONE | RETIRED | 300.0 | 20-JUN-11 | None | None | None | SA17A | 736166 |
对于HDF5格式文件的存取,我也将在后面进行学习。鼓励感兴趣的同学自己探索不同的文件格式,以了解它们的速度以及它们对在数据分析中的效果。
一、读取 Microsoft Excel 文件
pandas 支持使用ExcelFile 类或 pandas.read_excel 函数等读取存储在 Excel 2003(及更高版本)文件中的表格数据。但是在内部,这些工具要使用附加组件包 xlrd 和 openpyxl 分别读取旧式 XLS 和较新的 XLSX 文件。我们可以使用 pip 或 conda分开安装。
pip install openpyxl xlrd
如果使用的是conda开发工具则可以使用
conda install openpyxl xlrd
使用 pandas的ExcelFile,我们通过传递 xls 或 xlsx 文件的路径来创建实例(这里使用的ex1.xlsx是一个二进制文件无法直接打开),例如:
xlsx = pd.ExcelFile("examples/ex1.xlsx")
此xlsx对象可以显示文件中可用工作表名称的列表: xlsx.sheet_names
然后可以通过 parse 将存储在工作表中的数据读入 DataFrame,加载为DataFrame后,就可以方便的进行数据处理分析等。
xlsx.parse(sheet_name="Sheet1")
输出:
| Unnamed: 0 | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 1 | 5 | 6 | 7 | 8 | world |
| 2 | 2 | 9 | 10 | 11 | 12 | foo |
从上面输出可以了解到这个 Excel 表格有一个索引列,所以我们可以使用 index_col 参数来指示,重新编码:
xlsx.parse(sheet_name="Sheet1", index_col=0)
输出:
| a | b | c | d | message | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 5 | 6 | 7 | 8 | world |
| 2 | 9 | 10 | 11 | 12 | foo |
使用pandas.ExcelFile读取excel文件中的多个工作表会更快,但我们也可以使用pandas.read_excel,这个编写代码相对更简单,同样接收文件名作为参数。例如:
frame = pd.read_excel("examples/ex1.xlsx", sheet_name="Sheet1")
输出:
| Unnamed: 0 | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 1 | 5 | 6 | 7 | 8 | world |
| 2 | 2 | 9 | 10 | 11 | 12 | foo |
要将 pandas 数据写入 Excel 格式,要先创建一个 ExcelWriter,然后使用 pandas 对象的 to_excel 方法将数据写入其中:
writer = pd.ExcelWriter("examples/ex2.xlsx")
frame.to_excel(writer, "Sheet1")
writer.save()
还可以将文件路径传递给 to_excel 而避免使用 ExcelWriter:
frame.to_excel("examples/ex2.xlsx")
二、使用 HDF5 格式
HDF5 是一种备受推崇的文件格式,用于存储大量科学阵列数据。它以 C 库的形式提供,并且具有许多其他编程语言的接口,包括 Java、Julia、MATLAB 和 Python。HDF5 中的“HDF”代表分层数据格式。每个 HDF5 文件都可以存储多个数据集和支持元数据。与其他更简单的格式相比,HDF5 支持具有多种压缩模式的动态压缩,从而能够更高效地存储具有重复模式的数据。HDF5 是处理不适合内存的数据集的不错选择,因为我们可以方便有效地读取和写入大数组中的小部分。
要开始使用 HDF5 和 pandas,必须首先通过使用 pip 或 conda 安装 PyTables:
pip install tables或 conda install pytables
注意:PyTables 包在 PyPI 中称为 “tables”,因此如果使用 pip 安装,则必须运行 pip install tables
虽然可以使用 PyTables 或 h5py 库直接访问 HDF5 文件,但 pandas 提供了一个高级接口,可简化 Series 和 DataFrame 对象的存储。HDFStore 类的工作方式类似于字典。例如:
import numpy as np
import pandas as pdframe = pd.DataFrame({"a": np.random.standard_normal(100)})
store = pd.HDFStore("examples/mydata.h5")
store["obj1"] = frame
store["obj1_col"] = frame["a"]
print(store)
store.close()以上代码会在examples目录中生成一个mydata.h5二进制文件,该文件类似于字典存储了frame中的数据。同时控制台打印出了store对象的类型和该文件存储的位置:
<class 'pandas.io.pytables.HDFStore'>
File path: examples/mydata.h5

可以使用相同的类似字典的方式检索 HDF5 文件中包含的对象:
import numpy as np
import pandas as pdframe = pd.DataFrame({"a": np.random.standard_normal(100)})
store = pd.HDFStore("examples/mydata.h5")
store["obj1"] = frame
store["obj1_col"] = frame["a"]
#检索对象
obj1 = store["obj1"]
print(obj1)store.close()输出:
a
0 -0.116291
1 -1.111014
2 -1.202469
3 0.436760
4 -0.989590
.. ...
95 -1.201137
96 1.113517
97 -0.942226
98 -0.485934
99 0.590444
[100 rows x 1 columns]
HDFStore 支持两种存储架构,即 “fixed” 和 “table” (默认为 “fixed”)。后者通常较慢,但它支持使用特殊语法的查询操作,例如:
import numpy as np
import pandas as pdframe = pd.DataFrame({"a": np.random.standard_normal(100)})
store = pd.HDFStore("examples/mydata.h5")
#默认fixed存储
store["obj1"] = frame
store["obj1_col"] = frame["a"]#设置table存储
store.put("obj2", frame, format="table")
#根据条件查询需要的数据
a = store.select("obj2", where=["index >= 10 and index <= 15"])
print(a)
store.close()输出:
a
10 0.211580
11 0.196123
12 -0.869757
13 -1.543114
14 -0.566423
15 0.078732
还有更方便的方法:DataFrame.to_hdf 和 pandas.read_hdf ,上代码学习:
import numpy as np
import pandas as pdframe = pd.DataFrame({"a": np.random.standard_normal(100)})#将frame中的数据以table存储方式写入mydata.h5
frame.to_hdf("examples/mydata.h5", "obj3", format="table")
#读取前5行。
a = pd.read_hdf("examples/mydata.h5", "obj3", where=["index < 5"])print(a)
输出:
a
0 -0.321670
1 0.011807
2 1.048680
3 -1.443384
4 0.312067
如果需要,可以删除创建的 HDF5 文件,如下所示:
import osos.remove("examples/mydata.h5")注意:如果需要处理存储在远程服务器(如 Amazon S3 或 HDFS)上的数据,则使用专为分布式存储设计的二进制格式(如 Apache Parquet)可能更合适。
如果是在本地处理大量数据,可以更多的使用 PyTables 和 h5py,但是基于以上的学习内容还不够,需要深入了解他们的功能。由于许多数据分析问题都是 I/O 密集型(而不是 CPU 密集型)的,因此 HDF5 这样的工具使用会极大的提高我们的访问效率。
另外一个要注意的是:HDF5 不是数据库。它非常适合一次写入、多次读取的数据集。虽然我们可以随时将数据添加到HDF5 文件中,但如果多个写入器同时写入,则有可能会造成文件损坏。
相关文章:
Python数据分析NumPy和pandas(十七、pandas 二进制格式文件处理)
以二进制格式存储(或序列化)数据的一种简单方法是使用 Python 的内置 pickle 模块。同时,pandas 构造的对象都有一个 to_pickle 方法,该方法以 pickle 格式将数据写入磁盘。 我们先把之前示例用到的ex1.csv文件加载到pandas对象中…...

matlab计算相关物理参数
function Rx1Jetfire1_1(di,Ct,Tf,Tj,alpha,Ma,Mf,RH,P0,P,k,Cd,elta,deltaHc,tau,directory) % 一共15个独立变量,为了方便输入修改,所有变量存入Jetfire1_1excel表, % dj为孔口直径,m;Ct为燃料空气混合摩尔系数,可…...

nmcli、ip、ifcfg配置网络区分方法
文章目录 一、检查NetworkManager状态使用nmcli命令:检查NetworkManager服务状态: 二、检查ip命令的使用三、检查ifcfg文件查看/etc/sysconfig/network-scripts/目录:查看/etc/network/interfaces文件(针对Debian系)&a…...

第四届智能电力与系统国际学术会议(ICIPS 2024)
文章目录 一、会议详情二、重要信息三、大会介绍四、出席嘉宾五、征稿主题六、咨询 一、会议详情 二、重要信息 大会官网:https://ais.cn/u/vEbMBz提交检索:EI Compendex、IEEE Xplore、Scopus 三、大会介绍 四、出席嘉宾 五、征稿主题 如想"投稿…...

区块链样题第4套解析 后端应用开发部分
任务3-2:区块链应用后端开发 使用JAVA-SDK与区块链进行交互,通过solc2Java工具将Solidity智能合约转译为可供Java调用的文件,实现区块链编程。 前言:题目只是单纯考了对于fisco-java-sdk的简单使用 教程参考: 1.这边建议还是学习完JavaWeb课程。 黑马程序员JavaWeb...

C语言实现408考研真题2016年43题
#include <iostream> // 定义分区函数,返回两个子数组之和的差值 int setPartition(int a[], int n) { int pivotkey, low 0, low0 0, high n - 1, high0 n - 1, flag 1, k n / 2, i; int s1 0, s2 0; // 当low等于k-1,…...

2024年,Rust开发语言,现在怎么样了?
Rust开发语言有着一些其他语言明显的优势,但也充满着争议,难上手、学习陡峭等。 Rust 是由 Mozilla 主导开发的通用、编译型编程语言,2010年首次公开。 在 Stack Overflow 的年度开发者调查报告中,Rust 连续多年被评为“最受喜爱…...

三种网络配置方法nmcli、ip、ifcfg文件
文章目录 总结nmcli配置网络定义与功能:特点:示例: ip配置网络定义与功能:特点:示例: ifcfg配置网络定义与功能:特点:示例: 总结 nmcli:适合需要动态管理网络…...

AES_ECB算法C++与Java相互加解密Demo
一、AES算法 AES是一种对称加密算法,算法秘钥长度可为128位(16字节)、192位(24字节)、256位(32字节)。加密模式分为ECB、CBC、CTR等,其中ECB模式最简单够用。现给出ECB模式下C和Java的实现,并且可以相互加解密验证。 二、AES_ECB实现DEMO …...

H7-TOOL自制Flash读写保护算法系列,为兆易创新GD32E23X制作使能和解除算法,支持在线烧录和脱机烧录使用(2024-10-29)
说明: 很多IC厂家仅发布了内部Flash算法文件,并没有提供读写保护算法文件,也就是选项字节算法文件,需要我们制作。 实际上当前已经发布的TOOL版本,已经自制很多了。但是依然有些厂家还没自制,所以陆续开始…...

FFmpeg 深度教程音视频处理的终极工具
1. 引言 什么是 FFmpeg? FFmpeg 是一个开源的跨平台多媒体处理工具,广泛应用于音视频的录制、转换、流式传输以及编辑等多个领域。它由 FFmpeg 项目团队开发和维护,支持几乎所有主流的音视频格式和编解码器。FFmpeg 包含了一系列强大的命令…...
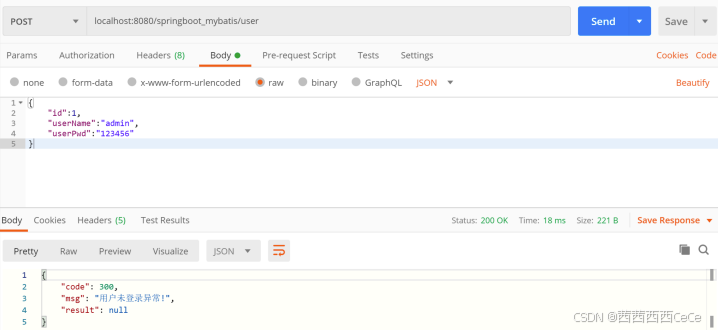
Java程序设计:spring boot(13)——全局异常与事务控制
1 Spring Boot 事务支持 在使⽤ Jdbc 作为数据库访问技术时,Spring Boot框架定义了基于jdbc的PlatformTransaction Manager 接⼝的实现 DataSourceTransactionManager,并在 Spring Boot 应⽤ 启动时⾃动进⾏配置。如果使⽤ jpa 的话 Spring Boot 同样提供…...

金和OA-C6 ApproveRemindSetExec.aspx XXE漏洞复现(CNVD-2024-40568)
0x01 产品描述: 金和C6协同管理平台是以"精确管理思想"为灵魂,围绕“企业协同四层次理论”模型,并紧紧抓住现代企业管理的六个核心要素:文化 Culture、 沟通Communication 、 协作Collaboration 、创新 Creation、 控制…...
Redis集群及Redis存储原理
Redis存储原理 Redis将内存划分为16384个区域(类似hash槽) 将数据的key使用CRC16算法计算出一个值,取余16384 得到的结果是0~16383 将这个key保存在计算结果对应的槽位 再次查询这个key时,直接到这个槽位查找,效率很高 实际上这就是"散列表" 提高查询的效率 R…...
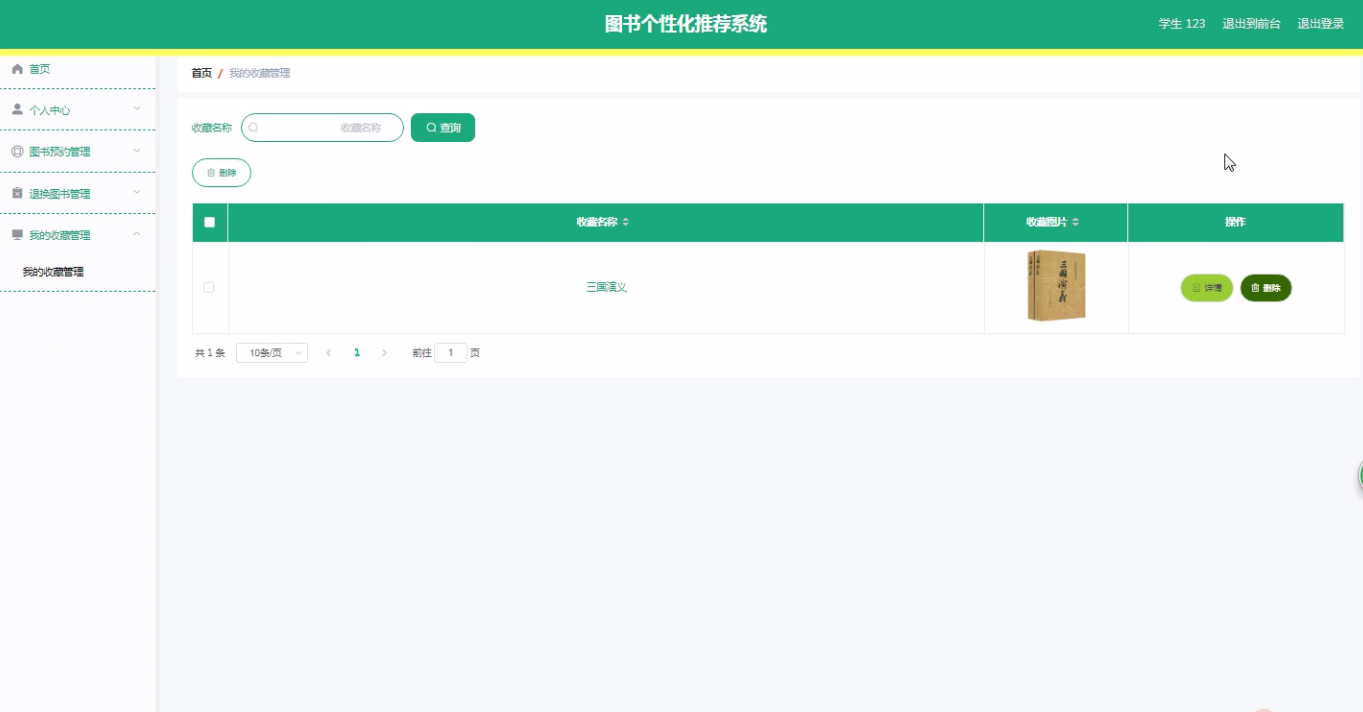
基于Springboot的图书个性化推荐系统【源码】+【论文】
图书个性化推荐系统是一个基于Java语言和Springboot框架开发的Web应用系统,主要为管理员和学生提供个性化图书推荐、图书预约和管理功能。系统通过管理员和学生的不同权限设置,实现了图书分类管理、预约管理、退换图书管理、留言板管理等全面的功能&…...

科普 | 子母钟系统是什么?网络时钟同步的重要性?
科普 | 子母钟系统是什么?网络时钟同步的重要性? 科普 | 子母钟系统是什么?网络时钟同步的重要性? 在信息时代的今天,准确统一的时钟系统已广泛的应用在车站、医院、学校、机场等公共服务场所。 因此完善的时钟系统对…...
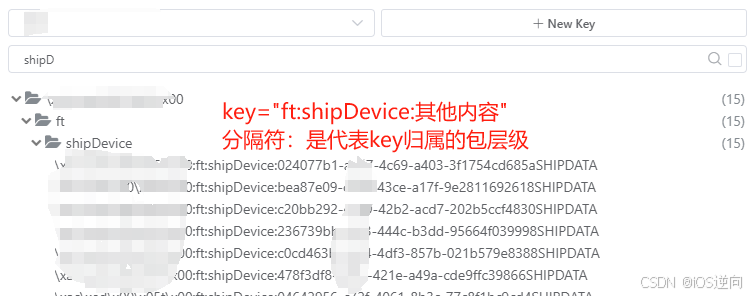
批量删除redis数据【亲测可用】
文章目录 引言I redis客户端基础操作key的命名规则批量查询keyII 批量删除key使用连接工具进行分组shell脚本示例其他方法III 知识扩展:控制短信验证码获取频率引言 批量删除redis数据的应用: 例如缓存数据使用了新的key存储,需要删除废弃的key。RedisTemplate的key序列化采…...
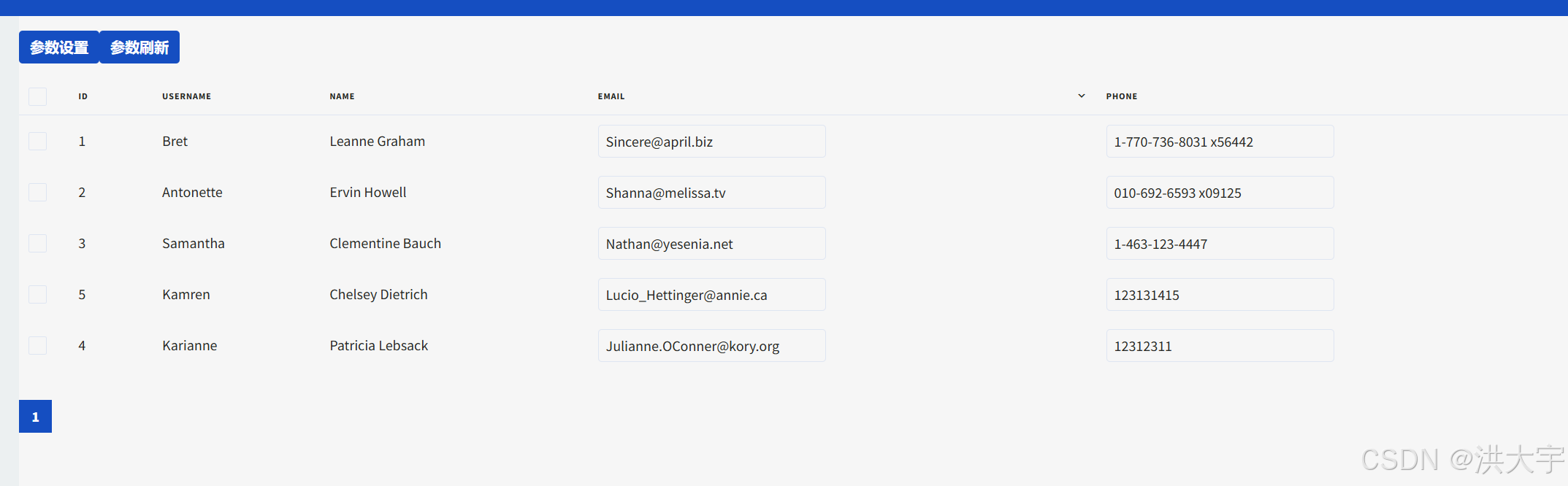
Vuestic 数据表格 使用demo
<template><br><div class"grid sm:grid-cols-3 gap-6 mb-6"><VaButton click"()>{for(const it in this.selectedItems){console.log(this.selectedItems);}}">参数设置</VaButton><VaButton>参数刷新</VaButt…...

考勤无忧,Zoho People助HR高效
云考勤系统提升数据准确性、无缝对接业务、节省成本、提高员工效率、保障安全。ZohoPeople作为云HRMS,集成考勤管理等功能,支持试用,助力企业高效管理。 一、使用云考勤管理系统,有哪些好处? 1、数据准确性得到保障 …...

已知一个法向量和一个点,求该平面的ModelCoefficients,并使用ProjectInliers将点云投影到该平面
#include <pcl/point_cloud.h> #include <pcl/point_types.h> #include <pcl/filters/project_inliers.h> #include <pcl/model_coefficients.h>// 假设法向量和一个点已知 float A 1.0; // 法向量的 x 分量 float B 0.0; // 法向量的 y 分量 floa…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

《C++ 模板》
目录 函数模板 类模板 非类型模板参数 模板特化 函数模板特化 类模板的特化 模板,就像一个模具,里面可以将不同类型的材料做成一个形状,其分为函数模板和类模板。 函数模板 函数模板可以简化函数重载的代码。格式:templa…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...