Linux多线程
目录
一、认识线程
1.1 线程概念
1.2 页表
1.3 线程的优缺点
1.3.1 优点
1.3.2 缺点
1.4 线程异常
二、进程 VS 线程
三、Linux线程控制
3.1 POSIX线程库
3.1 线程创建
3.3 线程等待
3.4 线程终止
3.4.1 return退出
3.4.2 pthread_exit()
3.4.3 pthread_cancel()
3.5 线程分离
3.6 线程ID与进程地址空间布局
一、认识线程
1.1 线程概念
之前讲过,创建一个进程伴随着其进程控制块(task_struct)、进程地址空间(mm_struct)以及页表等的创建,虚拟地址和物理地址就是通过页表建立映射的

但在创建线程时,只需创建task_struct,创建出来的task_struct和主task_struct共享进程地址空间和页表等
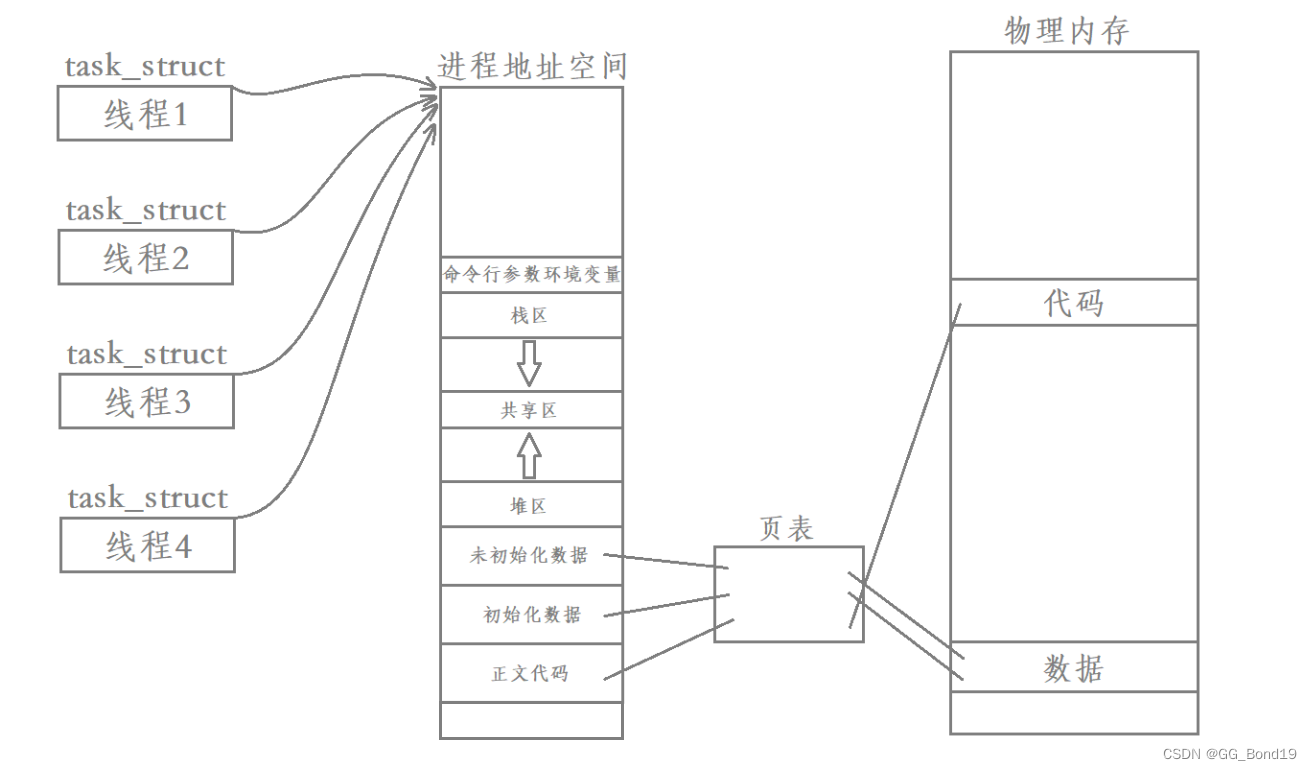
- 进程里的一个执行路线就是线程(thread)。即线程是"一个进程内部的控制序列(执行分支)"
- 所有进程至少都有一个执行线程
- 线程在进程内部运行,本质是在进程地址空间内运行,即曾经这个进程申请的所有资源,几乎都是被所有线程共享的
- 在Linux系统中,CPU眼中看到的PCB都要比传统的进程PCB更轻量化,也称为轻量级进程
- 通过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形成了线程执行流
重新理解进程
下面用蓝色框起来的就是进程
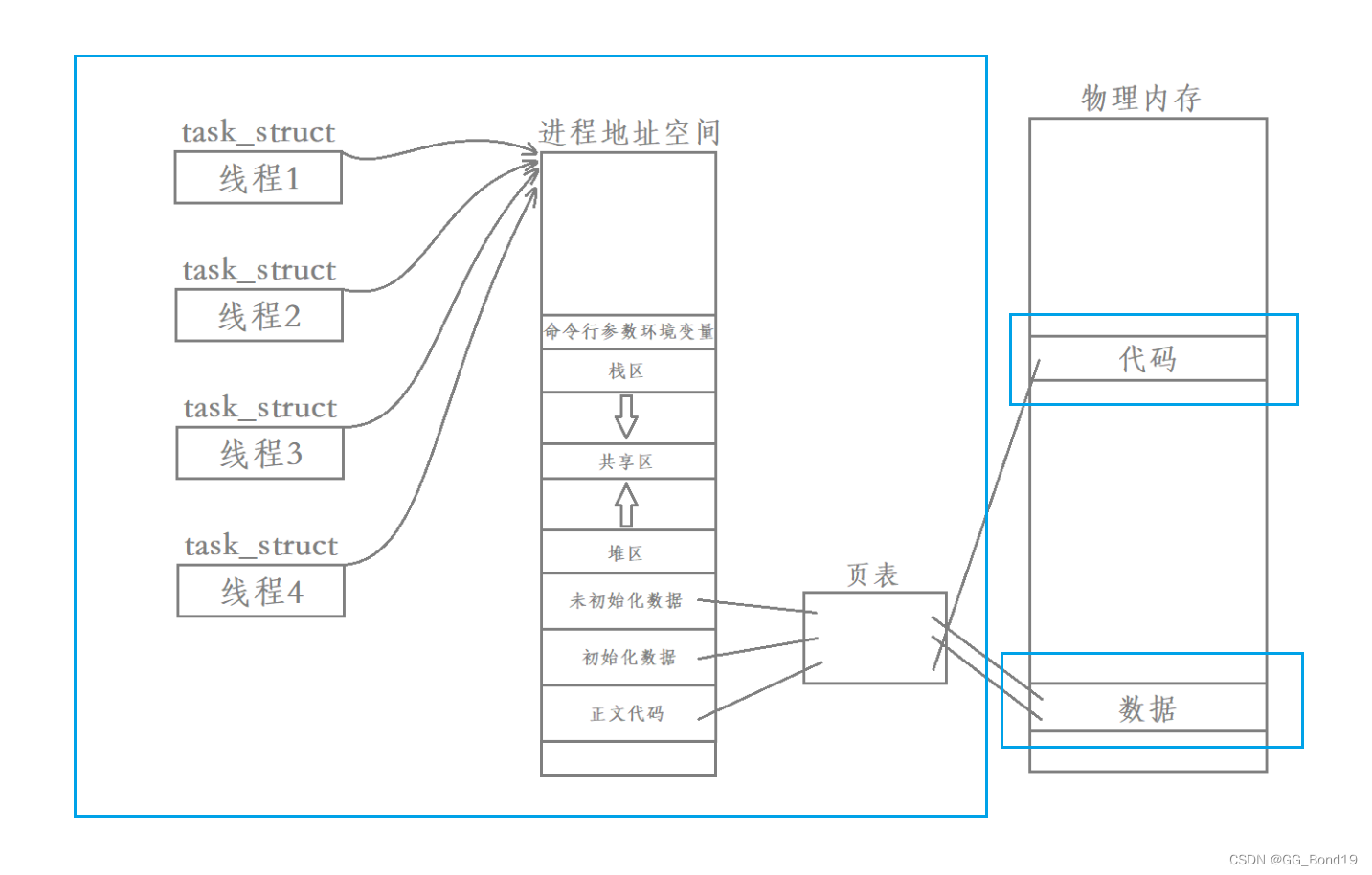
进程并不是通过task_struct来衡量的,除了task_struct之外,一个进程还要有进程地址空间、文件、信号集等等,合起来称之为一个进程
站在内核角度来理解进程:承担分配系统资源的基本实体,被称为进程
当创建进程时是创建一个task_struct、创建地址空间、维护页表,然后在物理内存当中开辟空间、构建映射,打开进程默认打开的相关文件、注册信号对应的处理方案等等。
之前接触到的进程都只有一个task_struct,也就是该进程内部只有一个执行流,即单执行流进程,反之,内部有多个执行流的进程叫做多执行流进程
Linux系统中,CPU是否能区分进程和线程?
在Linux系统中,CPU并不能区分进程与线程,因为CPU只关心一个一个的独立执行流。无论进程内部只有一个执行流还是有多个执行流,CPU都是以task_struct为单位进行调度的。即线程是CPU调度的最小单位
单执行流进程被调度:
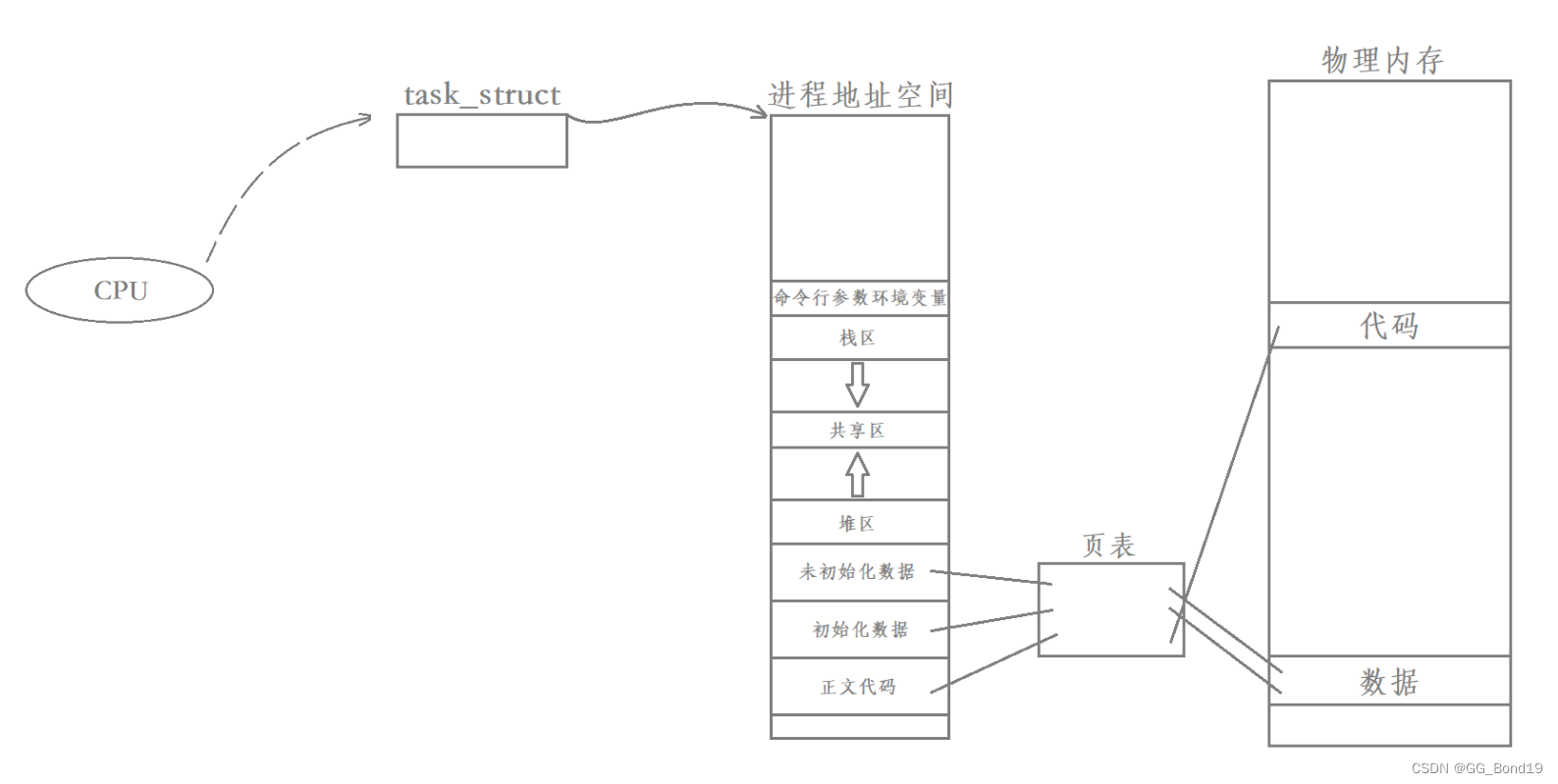
多执行流进程被调度:

Linux中并不存在真正意义上的多线程,而是进程模拟的
操作系统中存在大量的进程,一个进程中又存在一个或多个线程,因此线程的数量一定比进程的数量多,很明显线程的执行粒度要比进程更细。
若一款操作系统要真正意义上支持线程,那么就需要对线程进行管理。比如创建线程、终止线程、调度线程、切换线程、给线程分配资源、释放资源以及回收资源等等,所有的这一套相比较进程都需要另起炉灶,搭建一套线程管理模块。
因此,若要支持真的线程一定会提高设计操作系统的复杂程度。在Linux看来,描述线程的控制块和描述进程的控制块是类似的,因此Linux并没有重新为线程设计管理模块,而是直接复用了进程控制块,即Linux中的所有执行流都是轻量级进程
但也有支持真正线程的操作系统,譬如Windows操作系统就存在专门描述线程的控制块,因此Windows操作系统系统的实现逻辑一定比Linux操作系统更为复杂
Linux中并没有真正意义上的线程系统调用
在Linux中没有真正意义上的线程,那么也就没有真正意义上的线程相关的系统调用。但Linux提供了创建轻量级进程的接口,其中最典型的代表就是vfork函数
pid_t vfork(void);vfork函数的功能就是创建轻量级进程(只创建task_struct,父子进程共享资源)
返回值:
- 给父进程返回子进程的PID
- 给子进程返回0
#include <iostream>
#include <cstdlib>
#include <sys/types.h>
#include <unistd.h>
using namespace std;int g_val = 100;
int main()
{pid_t id = vfork();if (id == 0) { //childg_val = 200;cout << "child:PID:" << getpid() << " PPID:"<< getppid() << " g_val:" << g_val << endl;exit(0);}//fathersleep(3);cout << "father:PID:" << getpid() << " g_val:" << g_val << endl;return 0;
}
父进程读取到g_val的值是子进程修改后的值,也证明了vfork创建的子进程与父进程是共享地址空间的
1.2 页表
在32位平台下一共有个地址,也就意味着有
个地址需要被映射。若页表就只是单纯的一张表,那么就需要建立
个虚拟地址和物理地址之间的映射关系,即这张表一共有232个映射表项。
每一个表项中除了要有虚拟地址和与其映射的物理地址以外,实际还需要有一些权限相关的信息,比如我们所说的用户级页表和内核级页表,实际就是通过权限进行区分的。

每个应表项中存储一个物理地址和一个虚拟地址就需要8个字节,考虑到还需要包含权限相关的各种信息,这里每一个表项就按10个字节计算。若有个表项,也就意味着存储这张页表需要用
* 10个字节,即40GB。显而易见,内存中并存储不了这么大的一张表。
以32位平台为例,其页表的映射过程如下:
- 选择虚拟地址的前10个bit位在页目录(一级页表)当中进行查找,找到对应的二级页表
- 再选择虚拟地址的10个bit位在二级页表中查找,找到物理内存中对应页框的起始地址
- 最后将虚拟地址中剩下的12个bit位作为偏移量从对应页框的起始地址处向后进行偏移,找到物理内存中某一个对应的地址
页框、页帧:
- 物理内存实际上是被划分成一个个4KB大小的页框的(操作系统完成),而磁盘上的程序也是被划分成许多4KB大小的页帧的(编译器编译时完成),当内存和磁盘进行数据交换时(IO)就是以4KB大小为单位进行加载和保存的
- 4KB就是
个字节,即一个页框中有

每一个表项还是按10字节计算,一级页表的表项有个,那么表的大小就是
* 10个字节,即10KB。而一级页表有
个表项也就意味着二级页表有
个,即一级页表有1张,二级页表有
张,总共算下来就是10MB左右,内存消耗并不高。而且实际运行中并不会使用所有的地址,因此页表也比预估的更小。
上面所说的所有映射过程,都是由MMU(MemoryManagementUnit)这个硬件完成的,该硬件是集成在CPU内的。页表是一种软件映射,MMU是一种硬件映射,所以计算机进行虚拟地址到物理地址的转化采用的是软硬件结合的方式。
注意: 在Linux中,32位平台下用的是二级页表,而64位平台下使用的是多级页表
1.3 线程的优缺点
1.3.1 优点
- 创建一个新线程的代价要比创建一个新进程小得多
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要更少(CPU中存在寄存器和L1 ~ L3级缓存,进程切换会导致寄存器和缓存中的数据失效且需要重新加载,但线程切换并不需要)
- 线程占用的资源要比进程少很多
- 能充分利用多处理器的可并行数量
- 在等待慢速IO操作结束的同时,程序可执行其他的计算任务
- 计算密集型应用,在多处理器系统上运行,可将计算分解到多个线程中实现从而提高执行效率
- IO密集型应用,为了提高性能,可将IO操作重叠,使得线程可以同时等待不同的IO操作
概念说明:
- 计算密集型(CPU密集型):执行流的大部分任务,主要以计算为主。如加密解密、大数据查找等
- IO密集型:执行流的大部分任务,主要以IO为主。如刷盘、访问数据库、访问网络等
1.3.2 缺点
- 性能损失: 一个很少被外部事件阻塞的计算密集型线程往往无法与其他线程共享同一个处理器。若计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失(即增加了额外的同步和调度开销,而可用的资源不变)
- 健壮性降低: 编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,即线程之间是缺乏保护的
- 缺乏访问控制: 进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响
- 编程难度提高: 编写与调试一个多线程程序比单线程程序困难得多。
若有水平较高的程序编写者,其实上述这些缺点都可以避免的
1.4 线程异常
- 单个线程如果出现除零、野指针等问题导致线程崩溃,进程也会随着崩溃
- 线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出
二、进程 VS 线程
线程共用同一个地址空间,因此代码段(Text Segment)、数据段(Data Segment)等都是共享的:
- 若定义一个函数,在各线程中都可以调用
- 若定义一个全局变量,在各线程中都可以访问到
除此之外,各线程还共享以下进程资源和环境:
- 文件描述符表(进程打开一个文件后,其他线程也能够看到)
- 每种信号的处理方式(SIG_IGN、SIG_DFL或者自定义的信号处理函数)
- 当前工作目录(cwd)
- 用户ID和组ID
进程是承担分配系统资源的基本实体,线程是CPU调度的基本单位。线程共享进程数据,但也拥有自己的一部分数据:
- 线程ID
- 一组寄存器(存储每个线程的上下文信息)
- 栈(每个线程都有临时的数据,需要压栈出栈)
- errno(C语言提供的全局变量,但每个线程都有自己的)
- 信号屏蔽字
- 调度优先级
三、Linux线程控制
3.1 POSIX线程库
在Linux中,站在内核角度上看并没有真正意义上线程相关的接口。但站在用户角度,当用户想创建一个线程时更期望使用thread_create这样类似的接口,而不是vfork函数,因此系统在应用层提供了原生线程库pthread。原生线程库实际就是对轻量级进程的系统调用进行了封装,在用户层模拟实现了一套线程相关的接口
- 应用层指的是这个线程库并不是操作系统直接提供的,而是由第三方使用系统接口编写的
- 原生指的是大部分Linux系统都会默认带上该线程库
- 与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是以"pthread_"开头
- 要使用pthread库,要引入头文件<pthreaad.h>
- 链接pthread库时,要在编译时要使用"-lpthread"选项
注意:
- 传统的函数是,成功返回0,失败返回-1,并且对全局变量errno设置以指示错误。pthread函数出错时并不会设置全局变量errno(而大部分POSIX函数会这样做),而是将错误信息通过返回值返回
- pthread同样也提供了线程内的errno变量,以支持其他使用errno的代码。但对于pthread函数的错误,建议通过返回值来判定,因为读取返回值要比读取线程内的errno变量的开销更小,且线程的errno是各线程独占的
3.1 线程创建
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);参数:
- thread:获取创建成功的线程ID,该参数是一个输出型参数
- attr:用于设置创建线程的属性,传入NULL表示使用默认属性
- start_routine:该参数是一个函数地址,表示线程例程,即线程启动后要执行的函数
- arg:传给线程例程的参数(即传给start_routine的形参)
返回值:
线程创建成功返回0,失败返回错误码
使用案例
让主线程调用pthread_create函数创建一个新线程,此后新线程就会跑去执行自己的新例程,而主线程则继续执行后续代码
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;void* Routine(void* args)
{while (1) {cout << "I am " << (char*)args << endl;sleep(1);}
}
int main()
{pthread_t tid;pthread_create(&tid, NULL, Routine, (void*)"thread 1");while (1) {cout << "I am main thread!" << endl;sleep(2);}return 0;
}
使用 ps -aL 命令,可以显示当前的轻量级进程,不带 -L 选项默认显示进程

LWP(Light Weight Process)就是轻量级进程的ID,可以看到显示的两个轻量级进程的PID是相同的,因为它们属于同一个进程。
在Linux中,应用层的线程与内核的LWP是对应的,实际上操作系统调度时使用的是LWP,而并非PID。单线程进程时PID和LWP是相等的,所以对于单线程进程而言,调度时采用PID和LWP是一样的;多线程进程时PID与主线程LWP相同。
3.3 线程等待
线程如同进程一般,也是需要被等待的。若主线程不对新线程进行等待,那么新线程的资源不会被回收,会发生类似于"僵尸进程"的问题,即内存泄漏。
使用pthread_join()可以进行线程等待
int pthread_join(pthread_t thread, void **retval);参数:
- thread:被等待线程的ID
- retval:线程退出时的退出码信息
返回值:
- 线程等待成功返回0,失败返回错误码
调用该函数的线程将阻塞到ID为thread的线程终止。thread线程以不同的方法终止,通过pthread_join得到的终止状态是不同的
- 若thread线程通过return返回,retval所指向的单元里存放的是线程的返回值
- 若thread线程被别的线程调用pthread_cancel()异常终止掉,retval所指向的单元里存放的是宏PTHREAD_CANCELED,即(void*)-1)
- 若thread线程是自行调用pthread_exit()终止的,retval所指向的单元存放的是传给pthread_exit的参数
- 若对thread线程的终止状态不感兴趣,可传NULL给retval参数
使用案例
#include <iostream>
#include <pthread.h>
#include <unistd.h>using namespace std;void* Routine(void *args)
{cout << (char*)args << endl;sleep(3);return (void*)0;
}
int main()
{pthread_t tid;pthread_create(&tid, nullptr, Routine, (void*)"new thread");void* ret = nullptr;int n = pthread_join(tid,&ret);if(n == 0) {cout << "等待成功" << endl;cout << "返回信息为: " <<(long long)ret << endl;}else {cout << "等待失败" << endl;}return 0;
}
3.4 线程终止
3.4.1 return退出
在创建线程时指定的例程中使用return代表当前线程退出,但在main函数中使用return代表整个进程退出,即主线程退出了那么整个进程就退出了。
3.4.2 pthread_exit()
void pthread_exit(void *retval);参数retval:线程退出时的退出信息
注意:
- pthread_exit()或者return返回的指针所指向的内存单元必须是全局的或者堆区开辟的,不能在线程函数的栈上分配,因为当其他线程得到这个返回指针时,线程已经退出了
- 线程退出不能使用exit()函数,其作用是退出整个进程,任何一个线程调用都是如此
3.4.3 pthread_cancel()
int pthread_cancel(pthread_t thread);参数thread:被取消线程的ID
返回值:线程取消成功返回0,失败返回错误码
线程是可以取消自己的(使用pthread_self()函数)。也可以让新线程取消主线程,但不建议这么使用,一般都是使用主线程去控制新线程的。
取消成功的线程的退出码一般是宏PTHREAD_CANCELED,即(void*)-1)
![]()
3.5 线程分离
- 默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成内存泄漏。但若本身并不关心线程的返回值,那么join也是一种负担,此时可将该线程进行分离,后续当线程退出时就会自动释放线程资源
- 线程若被分离了,这个线程依旧使用该进程的资源,且依旧在该进程内运行,甚至这个线程崩溃了一定会影响整个进程,只不过这个线程退出时不再需要主线程去join了,当这个线程退出时系统会自动回收该线程所对应的资源
- 可以是线程组内其他线程对目标线程进行分离,也可以是线程自己分离
- joinable和分离是冲突的,一个线程不能既是joinable又是分离的
使用pthread_detach()函数进程分离线程
int pthread_detach(pthread_t thread);参数thread:被分离线程的ID
返回值:线程分离成功返回0,失败返回错误码
3.6 线程ID与进程地址空间布局
- pthread_create函数会产生一个线程ID,存放在第一个参数指向的地址中,但该线程ID和内核中的LWP并不是一回事
- 内核中的LWP属于CPU调度的范畴,因为线程其实就是轻量级进程,是操作系统调度器的最小单位,所以需要一个数值来唯一表示该线程
- pthread_create()函数第一个参数指向一个虚拟内存单元,该内存单元的地址即为新创建线程的线程ID,这个ID属于NPTL线程库的范畴,线程库的后续操作就是根据该线程ID来操作线程的
- 线程库NPTL提供的pthread_self()函数,获取的线程ID和pthread_create()函数第一个参数获取的线程ID是一样的
线程ID到底是什么?
可以将线程ID打印出来看看
#include <iostream>
#include <pthread.h>
#include <unistd.h>using namespace std;void* Routine(void* args) {cout << (char*)args << " : " << pthread_self() << endl;return (void*)0;
}
int main()
{pthread_t tid;pthread_create(&tid,nullptr,Routine,(void*)"new thread");sleep(1);cout << "main thread : " << pthread_self() << endl;pthread_join(tid,nullptr);return 0;
}![]()
可以发现,这个线程ID数值特别大,并不是LWP,那么这个线程ID到底是什么呢?
Linux系统中不提供真正的线程ID,只提供LWP,即操作系统只需通过LWP对轻量级进程进行管理,而供用户使用的线程接口等其他数据,由线程库来管理,因此管理线程时的"先描述,再组织"就应该在线程库中完成
使用 lld 命令可以看到,线程库实际上是一个动态库(默认使用动态库)

进程运行时动态库被加载到内存,然后通过页表映射到进程地址空间中的共享区,此时进程内的所有线程是共享这个动态库的
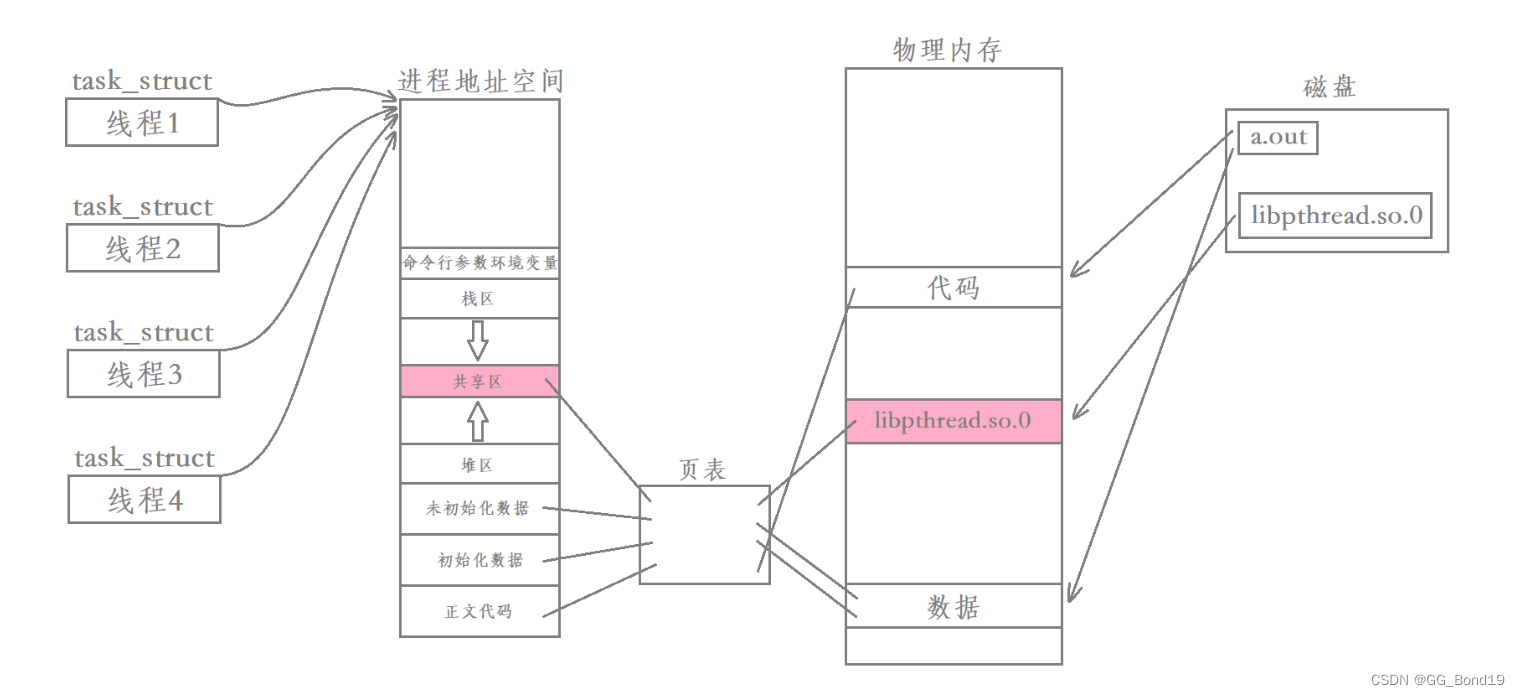
之前提到每个线程都有独占的栈,其中主线程采用的栈是进程地址空间中原生的栈,而其余线程采用的栈就是在共享区中开辟的。除此之外,每个线程都有各自的struct pthread,当中包含了对应线程的各种属性;每个线程还有自己的线程局部存储,当中包含了对应线程被切换时的上下文数据。
每一个新线程在共享区都有一个struct pthread对其进行描述,因此要找到一个用户级线程只需要找到该线程内存块的起始地址,然后就可以获取到该线程的各种信息

上面讲述的各种线程函数,本质上都是在库内部对线程属性进行的各种操作,即线程数据的管理本质是在共享区的进行的
至于pthread_t到底是什么类型取决于实现,但对于Linux目前实现的NPTL线程库来说,线程ID本质就是进程地址空间共享区上的一个虚拟地址,同一个进程中所有的虚拟地址都是不同的,因此可以用它来唯一区分每一个线程
相关文章:
Linux多线程
目录 一、认识线程 1.1 线程概念 1.2 页表 1.3 线程的优缺点 1.3.1 优点 1.3.2 缺点 1.4 线程异常 二、进程 VS 线程 三、Linux线程控制 3.1 POSIX线程库 3.1 线程创建 3.3 线程等待 3.4 线程终止 3.4.1 return退出 3.4.2 pthread_exit() 3.4.3 pthread_cancel…...
Webpack5 环境下 Openlayers 标注(Icon) require 引入图片问题
Webpack5 环境下 Openlayers 标注(Icon) require 引入图片问题环境版本Openlayers 使用 require 问题Webpack5 正确配置构建新环境的时候,偶然发现 Openlayers 使用 require 的方式加载图片(Icon)报错,开始…...

Zookeeper安装部署
文章目录Zookeeper安装部署Zookeeper安装部署 将Zookeeper安装包解压缩, [rootlocalhost opt]# ll 总用量 14032 -rw-r--r--. 1 root root 12392394 10月 13 11:44 apache-zookeeper-3.6.0-bin.tar.gz drwxrwxr-x. 6 root root 4096 10月 18 01:44 redis-5.0.4 …...
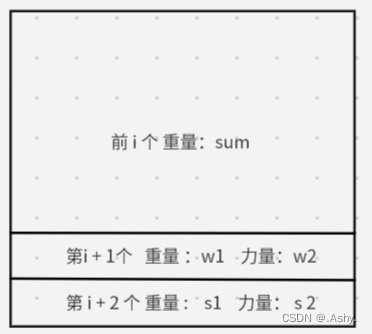
Cow Acrobats ( 临项交换贪心 )
题目大意: N 头牛 , 每头牛有一个重量(Weight)和一个力量(Strenth) , N头牛进行排列 , 第 i 头牛的风险值为其上所有牛总重减去自身力量 , 问如何排列可以使最大风险值最小 , 求出这个最小的最大风险值&am…...

MySQL:为什么说应该优先选择普通索引,尽量避免使用唯一索引
前言 在使用MySQL的过程中,随着表数据的逐渐增多,为了更快的查询我们需要的数据,我们会在表中建立不同类型的索引。 今天我们来聊一聊,普通索引和唯一索引的使用场景, 以及为什么说推荐大家优先使用普通索引…...

Spring Cloud alibaba之Feign
JAVA项目中如何实现接口调用?HttpclientHttpclient是Apache Jakarta Common下的子项目,用来提供高效的、最新的、功能丰富的支持Http协议的客户端编程工具包,并且它支持HTTP协议最新版本和建议。HttpClient相比传统JDK自带的URL Connection&a…...
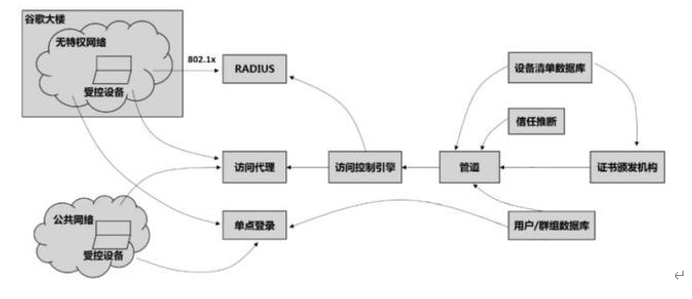
零信任-Google谷歌零信任介绍(3)
谷歌零信任的介绍? "Zero Trust" 是一种网络安全模型,旨在通过降低网络中的信任级别来防止安全威胁。在零信任模型中,不论请求来自内部网络还是外部网络,系统都将对所有请求进行详细的验证和审核。这意味着每次请求都需…...
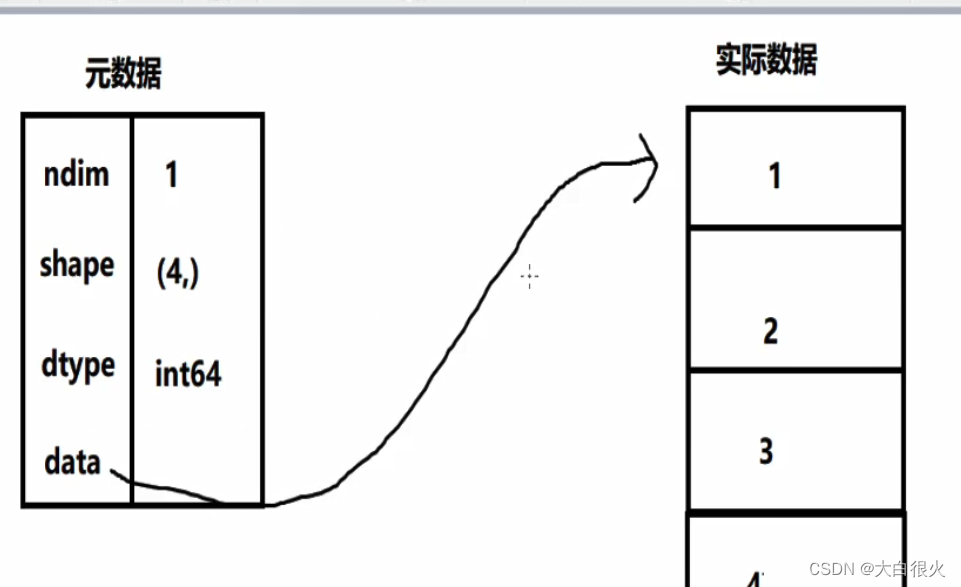
Numpy基础——人工智能基础
文章目录一、Numpy概述1.优势2.numpy历史3.Numpy的核心:多维数组4.numpy基础4.1 ndarray数组4.2 内存中的ndarray对象一、Numpy概述 1.优势 Numpy(Nummerical Python),补充了Python语言所欠缺的数值计算能力;Numpy是其它数据分析及机器学习库的底层库&…...

电商仓储与配送云仓是什么?
仓库是整个供给链的关键局部。它们是产品暂停和触摸的点,耗费空间和时间(工时)。空间和时间反过来也是费用。经过开发数学和计算机模型来微调仓库的规划和操作,经理能够显著降低与产品分销相关的劳动力本钱,进步仓库空间应用率,并…...

【零基础入门前端系列】—HTML介绍(一)
【零基础入门前端系列】—HTML介绍(一) 一、什么是HTML HTML是用来描述网页的一种语言HTML指的是超文本标记语言:HyperText Markup LanguageHTML不是一种编程语言,而是一种超文本标记语言,标记语言是一套标记标签(ma…...

Elasticsearch索引库和文档的相关操作
前言:最近一直在复习Elasticsearch相关的知识,公司搜索相关的技术用到了这个,用公司电脑配了环境,借鉴网上的课程进行了总结。希望能够加深自己的印象以及帮助到其他的小伙伴儿们😉😉。 如果文章有什么需要…...

使用Python,Opencv检测图像,视频中的猫
使用Python,Opencv检测图像,视频中的猫🐱 这篇博客将介绍如何使用Python,OpenCV库附带的默认Haar级联检测器来检测图像中的猫。同样的技术也可以应用于视频流。这些哈尔级联由约瑟夫豪斯(Joseph Howse)训练…...

浅谈域名和服务器集约化管理的误区
一个正常的网站通常由域名、网站程序、服务器三个部分组成,网站程序由单位开发设计,而域名和服务器则需要租用购买,那么域名和服务器之间的关系是什么?如何实现域名和服务器的有效管理呢? 服务器和域名的关系 服务器…...

迪赛智慧数——柱状图(正负条形图):20212022人才求职最关注的因素
效果图从近两年职场跳槽方向看,相比此前人们对高薪大厂趋之若鹜,如今职场人更关注业务前景。根据相关数据显示,职场人求职最关注的因素中,“薪资福利”权重下降,“个人发展”权重上升,“业务前景”首次进入…...

网络安全-黑帽白帽红客与网络安全法
网络安全-黑帽白帽红客与网络安全法 本章内容较少,因为刚开端。 黑客来源于hacker 指的是信息安全里面,能够自由出入对方系统,指的是擅长IT技术的电脑高手 黑帽黑客-坏蛋,研究木马的,找漏洞的,攻击网络或者…...

Xpath元素定位之同级节点,父节点,子节点
XPath学习:轴(8)——following-siblingXPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 同时被构建于 XPath 表达之上。推荐一个挺不错的网站:htt…...
| 真题+思路+代码)
华为OD机试 - 挑选字符串(Python)| 真题+思路+代码
挑选字符串 题目 给定 a-z,26 个英文字母小写字符串组成的字符串 A 和 B, 其中 A 可能存在重复字母,B 不会存在重复字母, 现从字符串 A 中按规则挑选一些字母可以组成字符串 B 挑选规则如下: 同一个位置的字母只能挑选一次, 被挑选字母的相对先后顺序不能被改变, 求最…...
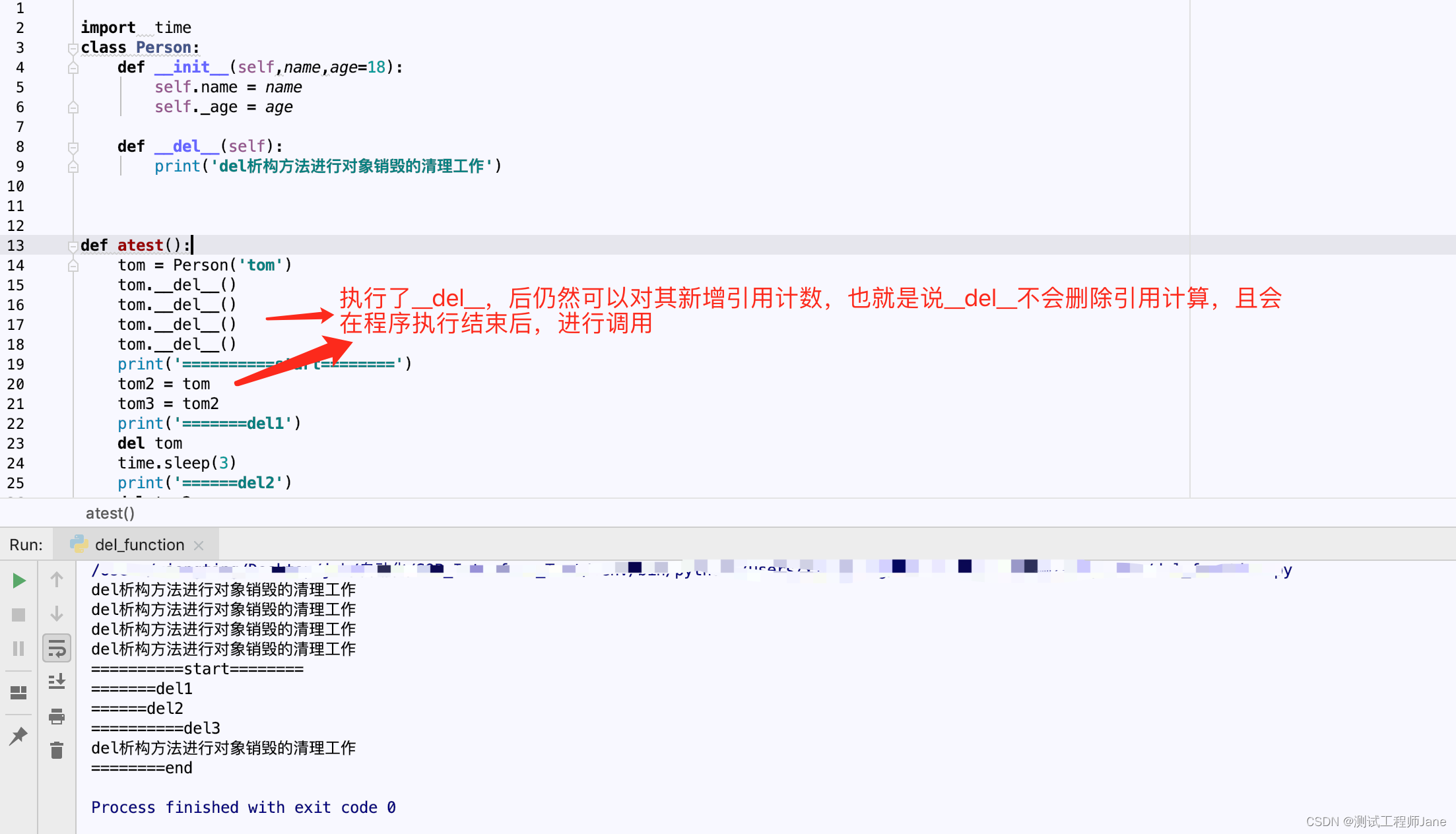
python笔记-- “__del__”析构方法
-#### 1、基本概念(构造函数与析构函数) 特殊函数:由系统自动执行,在程序中不可显式地调用他们 构造函数: 建立对象时对对象的数据成员进行初始化(对象初始化) 析构函数: 对象生命期…...

支付系统核心架构设计思路(万能通用)
文章目录1. 支付系统总览核心系统交互业务图谱2. 核心系统解析交易核心交易核心基础交易类型抽象多表聚合 & 订单关联支付核心支付核心总览支付行为编排异常处理渠道网关资金核算3. 服务治理平台统一上下文数据一致性治理CAS校验幂等 & 异常补偿对账准实时对账DB拆分异…...

python实现mongdb的双活
如何用python实现mongdb的双活,两个数据库实时同步? 可以使用Pymongo库,它可以提供同步的API来实现MongoDB的双活,两个数据库实时同步。还可以使用MongoDB的复制集功能来进行实时同步。 Pymongo库提供什么同步的API来实现MongoD…...

为何抗体定制服务是解决特定研究需求的关键策略?
一、抗体在生物医学研究与转化应用中的核心作用是什么?抗体,作为免疫系统响应特定抗原刺激而产生的高度特异性糖蛋白,是生命科学研究和生物医药开发中不可或缺的核心工具。凭借其精准的识别与结合能力,抗体被广泛应用于蛋白质组学…...

59. 如何使用 Rancher2 Terraform Provider 时启用调试日志
环境 Rancher2 Terraform Provider 情况If you encounter an issue with the Rancher2 Terraform Provider, capturing the debug output can be essential for troubleshooting or providing context to Rancher Support. This article explains how to enable debug logging …...

COMSOL单相变压器温度场三维模型:解析热点温度与流体流速分布
comsol单相变压器温度场三维模型,可以得到变压器热点温度,流体流速分布 搞变压器温度场仿真最头疼的就是三维流固耦合。去年做配电变压器温升项目时,硬是跟COMSOL死磕了两周才摸到门道。今天给大家分享下怎么用非等温流接口抓取热点温度和油…...

java基于微信小程序的电影点评影评交流平台的设计与实现_0144t2v4
目录项目概述技术选型核心功能模块数据库设计开发阶段计划关键代码示例注意事项项目技术支持可定制开发之功能创新亮点源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作项目概述 设计一个基于微信小程序的电影点评与影评交流平台,…...

如何快速设置theHarvester监控告警:关键信息发现通知完全指南
如何快速设置theHarvester监控告警:关键信息发现通知完全指南 【免费下载链接】theHarvester E-mails, subdomains and names Harvester - OSINT 项目地址: https://gitcode.com/GitHub_Trending/th/theHarvester theHarvester是一款强大的开源OSINT&#x…...

如何快速实现专业信用卡表单:ca/card组件的完整应用指南
如何快速实现专业信用卡表单:ca/card组件的完整应用指南 【免费下载链接】card :credit_card: make your credit card form better in one line of code 项目地址: https://gitcode.com/gh_mirrors/ca/card 在现代Web开发中,用户体验是产品成功的…...

开源手机检测大模型DAMO-YOLO效果展示:AP@0.5达88.8%高清检测图集
开源手机检测大模型DAMO-YOLO效果展示:AP0.5达88.8%高清检测图集 1. 引言:当手机检测遇上“火眼金睛” 想象一下,你有一张满是人群的街拍照片,想快速、准确地找出画面里有多少部手机。或者,你正在开发一个智能零售系…...

CogVideoX-2b企业实操:接入内部审批流实现营销视频自动合成
CogVideoX-2b企业实操:接入内部审批流实现营销视频自动合成 1. 项目背景与价值 营销视频制作是企业日常运营中的重要环节,但传统视频制作流程存在诸多痛点:人力成本高、制作周期长、风格不统一、批量生产困难。特别是对于需要快速响应市场活…...
Qwen3与Transformer模型深度结合:提升字幕语义理解
Qwen3与Transformer模型深度结合:提升字幕语义理解 不知道你有没有过这样的体验:看视频时,字幕要么跟不上语速,要么翻译得生硬别扭,甚至完全曲解了说话人的意思。尤其是在处理口语化表达、网络流行语或者带有歧义的句…...

Android网络解析实战:从DNS请求到netd的完整流程拆解
Android网络解析实战:从DNS请求到netd的完整流程拆解 在移动应用开发中,网络请求的性能直接影响用户体验。而作为网络通信的第一步,DNS解析的效率往往决定了整个网络请求的响应速度。本文将深入Android系统底层,揭示从应用层发起D…...