数据分析ReAct工作流
让我用一个数据分析项目的例子来展示plan-and-execute框架的应用。这个例子会涉及数据处理、分析和可视化等任务。
from typing import List, Dict, Any
from dataclasses import dataclass
import json
from enum import Enum
import logging
from datetime import datetime# 任务状态枚举
class TaskStatus(Enum):PENDING = "pending"RUNNING = "running"COMPLETED = "completed"FAILED = "failed"# 任务优先级枚举
class TaskPriority(Enum):LOW = 1MEDIUM = 2HIGH = 3# 任务定义
@dataclass
class Task:id: strname: strdescription: strpriority: TaskPrioritydependencies: List[str] # 依赖的任务ID列表status: TaskStatusresult: Any = Noneerror: str = None# 工作流执行器
class WorkflowExecutor:def __init__(self):self.tasks = {}self.logger = logging.getLogger(__name__)def add_task(self, task: Task):self.tasks[task.id] = taskdef get_ready_tasks(self) -> List[Task]:"""获取所有依赖已满足的待执行任务"""ready_tasks = []for task in self.tasks.values():if task.status == TaskStatus.PENDING:dependencies_met = all(self.tasks[dep_id].status == TaskStatus.COMPLETEDfor dep_id in task.dependencies)if dependencies_met:ready_tasks.append(task)return sorted(ready_tasks, key=lambda x: x.priority.value, reverse=True)def execute_task(self, task: Task):"""执行单个任务"""task.status = TaskStatus.RUNNINGtry:# 这里实现具体任务的执行逻辑result = self.task_handlers[task.id](task, {dep: self.tasks[dep].result for dep in task.dependencies})task.result = resulttask.status = TaskStatus.COMPLETEDexcept Exception as e:task.status = TaskStatus.FAILEDtask.error = str(e)self.logger.error(f"Task {task.id} failed: {e}")def execute_workflow(self):"""执行整个工作流"""while True:ready_tasks = self.get_ready_tasks()if not ready_tasks:breakfor task in ready_tasks:self.execute_task(task)# 检查是否所有任务都完成all_completed = all(task.status == TaskStatus.COMPLETED for task in self.tasks.values())return all_completed# 数据分析工作流示例
class DataAnalysisWorkflow:def __init__(self, data_path: str, output_path: str):self.data_path = data_pathself.output_path = output_pathself.executor = WorkflowExecutor()def plan_workflow(self):"""规划工作流程"""tasks = [Task(id="load_data",name="加载数据",description="从CSV文件加载数据",priority=TaskPriority.HIGH,dependencies=[],status=TaskStatus.PENDING),Task(id="clean_data",name="数据清洗",description="处理缺失值和异常值",priority=TaskPriority.HIGH,dependencies=["load_data"],status=TaskStatus.PENDING),Task(id="feature_engineering",name="特征工程",description="创建新特征",priority=TaskPriority.MEDIUM,dependencies=["clean_data"],status=TaskStatus.PENDING),Task(id="statistical_analysis",name="统计分析",description="计算基本统计指标",priority=TaskPriority.MEDIUM,dependencies=["clean_data"],status=TaskStatus.PENDING),Task(id="visualization",name="数据可视化",description="生成图表",priority=TaskPriority.MEDIUM,dependencies=["statistical_analysis"],status=TaskStatus.PENDING),Task(id="generate_report",name="生成报告",description="生成分析报告",priority=TaskPriority.LOW,dependencies=["visualization", "feature_engineering"],status=TaskStatus.PENDING)]for task in tasks:self.executor.add_task(task)def register_task_handlers(self):"""注册任务处理函数"""self.executor.task_handlers = {"load_data": self.load_data,"clean_data": self.clean_data,"feature_engineering": self.feature_engineering,"statistical_analysis": self.statistical_analysis,"visualization": self.visualization,"generate_report": self.generate_report}def load_data(self, task: Task, dependencies: Dict):import pandas as pddf = pd.read_csv(self.data_path)return dfdef clean_data(self, task: Task, dependencies: Dict):df = dependencies["load_data"]# 处理缺失值df = df.fillna(df.mean())# 处理异常值# ... 其他清洗逻辑return dfdef feature_engineering(self, task: Task, dependencies: Dict):df = dependencies["clean_data"]# 创建新特征# ... 特征工程逻辑return dfdef statistical_analysis(self, task: Task, dependencies: Dict):df = dependencies["clean_data"]stats = {"basic_stats": df.describe(),"correlations": df.corr(),# ... 其他统计分析}return statsdef visualization(self, task: Task, dependencies: Dict):import matplotlib.pyplot as pltstats = dependencies["statistical_analysis"]figures = []# 生成可视化# ... 可视化逻辑return figuresdef generate_report(self, task: Task, dependencies: Dict):figures = dependencies["visualization"]df_features = dependencies["feature_engineering"]report = {"timestamp": datetime.now().isoformat(),"statistics": str(dependencies["statistical_analysis"]),"features": df_features.columns.tolist(),"figures": [f.to_json() for f in figures]}# 保存报告with open(f"{self.output_path}/report.json", "w") as f:json.dump(report, f, indent=2)return reportdef run(self):"""运行完整的工作流"""self.plan_workflow()self.register_task_handlers()success = self.executor.execute_workflow()if success:final_report = self.executor.tasks["generate_report"].resultprint("工作流执行成功!")return final_reportelse:failed_tasks = [task for task in self.executor.tasks.values()if task.status == TaskStatus.FAILED]print("工作流执行失败。失败的任务:")for task in failed_tasks:print(f"- {task.name}: {task.error}")return None# 使用示例
def main():workflow = DataAnalysisWorkflow(data_path="data/sales_data.csv",output_path="output")result = workflow.run()if result:print("分析报告已生成:", result)else:print("工作流执行失败")if __name__ == "__main__":main()
这个例子展示了:
- 工作流框架的核心组件:
- Task定义
- 工作流执行器
- 依赖管理
- 状态追踪
- 错误处理
- 实现的关键特性:
- 自动任务规划
- 依赖关系处理
- 并行任务执行
- 结果传递
- 错误恢复
- 可以扩展的方向:
# 1. 添加任务重试机制
class RetryableExecutor(WorkflowExecutor):def execute_task(self, task: Task, max_retries: int = 3):retries = 0while retries < max_retries:try:super().execute_task(task)if task.status == TaskStatus.COMPLETED:breakexcept Exception as e:retries += 1self.logger.warning(f"Retry {retries}/{max_retries} for task {task.id}")# 2. 添加进度监控
class MonitoredWorkflow(DataAnalysisWorkflow):def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)self.progress_callback = Nonedef set_progress_callback(self, callback):self.progress_callback = callbackdef update_progress(self, task: Task, status: str):if self.progress_callback:self.progress_callback(task, status)# 3. 添加中间结果缓存
class CachedExecutor(WorkflowExecutor):def __init__(self, cache_dir: str):super().__init__()self.cache_dir = cache_dirdef get_cached_result(self, task: Task):cache_path = f"{self.cache_dir}/{task.id}.cache"if os.path.exists(cache_path):return pickle.load(open(cache_path, "rb"))return Nonedef cache_result(self, task: Task):cache_path = f"{self.cache_dir}/{task.id}.cache"pickle.dump(task.result, open(cache_path, "wb"))
- 使用建议:
# 1. 配置日志
logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)# 2. 添加性能监控
from time import timeclass PerformanceMonitor:def __init__(self):self.task_times = {}def start_task(self, task_id: str):self.task_times[task_id] = {"start": time()}def end_task(self, task_id: str):self.task_times[task_id]["end"] = time()def get_task_duration(self, task_id: str):times = self.task_times[task_id]return times["end"] - times["start"]# 3. 实现优雅的终止
import signalclass GracefulWorkflow(DataAnalysisWorkflow):def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)self.should_stop = Falsesignal.signal(signal.SIGINT, self.handle_interrupt)def handle_interrupt(self, signum, frame):print("\nReceived interrupt signal. Cleaning up...")self.should_stop = True
这个框架可以用于很多场景,比如:
- 数据处理管道
- ETL工作流
- 机器学习实验
- 报告生成系统
- 自动化测试流程
关键是要根据具体需求调整任务定义和执行逻辑。
相关文章:

数据分析ReAct工作流
让我用一个数据分析项目的例子来展示plan-and-execute框架的应用。这个例子会涉及数据处理、分析和可视化等任务。 from typing import List, Dict, Any from dataclasses import dataclass import json from enum import Enum import logging from datetime import datetime#…...

Rust-AOP编程实战
文章本天成,妙手偶得之。粹然无疵瑕,岂复须人为?君看古彝器,巧拙两无施。汉最近先秦,固已殊淳漓。胡部何为者,豪竹杂哀丝。后夔不复作,千载谁与期? ——《文章》宋陆游 【哲理】文章…...

Flutter鸿蒙next 中的 Expanded 和 Flexible 使用技巧详解
在 Flutter 开发中,Expanded 和 Flexible 是两个非常常用的布局控件,它们可以帮助开发者更加灵活地管理 UI 布局的空间分配。虽然它们看起来非常相似,但它们的功能和使用场景有所不同。理解这两者的区别,能帮助你在构建复杂 UI 布…...

【微信小游戏学习心得】
这里是引用 微信小游戏学习心得 简介了解微信小游戏理解2d游戏原理数据驱动视图总结 简介 本人通过学习了解微信小游戏,学习微信小游戏,加深了对前端框架,vue和react基于数据驱动视图的理解,及浏览器文档模型和javaScript之间的关…...

Python | Leetcode Python题解之第539题最小时间差
题目: 题解: def getMinutes(t: str) -> int:return ((ord(t[0]) - ord(0)) * 10 ord(t[1]) - ord(0)) * 60 (ord(t[3]) - ord(0)) * 10 ord(t[4]) - ord(0)class Solution:def findMinDifference(self, timePoints: List[str]) -> int:n len…...

Zookeeper运维秘籍:四字命令基础、详解及业务应用全解析
文章目录 一、四字命令基础二、四字命令详解三、四字命令的开启与配置四、结合业务解读四字命令confconsenvi命令Stat命令MNTR命令ruok命令dump命令wchswchp ZooKeeper,作为一款分布式协调服务,提供了丰富的四字命令(也称为四字短语ÿ…...

Error: `slot-scope` are deprecated报错解决
本人新手菜鸡,文章为自己遇到问题的记录,如有错误或不足还请大佬批评指正 问题描述 在Vue3环境下使用slot插槽,出现‘slot-scope’ are deprecated报错问题,经过查找发现,是因为在slot插槽使用中,vue2和vu…...
中使用上标下标)
Excel(图例)中使用上标下标
单元格中 1、在Excel单元格中刷黑要设置成上标的字符,如m2中的2; 2、单击右键,在弹出的对话框中选择“设置单元格格式”; 3、在弹出的“设置单元格格式”对话框中选择上标(或下标); 4、最后…...

熔断和降级
目录 隔离和降级 FeignClient整合Sentinel 通过Feign设置服务降级 1.创建类实现FallbackFactory接口,并让这个类和使用FeignClient的接口类绑定 2.让order-service服务的feign开启sentinel 3.测试,只开启order-service服务,而不开启user-…...

【学习笔记】Linux系统基础知识 6 —— su命令详解
提示:学习Linux系统基础命令 su 命令详解,包含通过 su 命令切换用户实例 一、前期准备 1.已经正确安装并成功进入Linux系统 说明:本实验采用的 Redhat 系统(因系统不一致,可能部分显示存在差异) 二、学…...

docker-compose命令介绍
docker-compose命令介绍 docker-compose1. docker-compose是什么2. Compose file format3. 命令3.1 服务相关命令upruncreatestartrestartdownstopkillrmpauseunpause 3.2 镜像相关命令3.3 查看相关命令 docker-compose 学了docker,然后就直接去学k8s了。恍恍惚惚几…...
Spring学习笔记_29——@Transactional
Transactional 1. 介绍 Transactional 是 Spring 框架提供的一个注解,用于声明方法或类级别的事务属性。 Spring事务:Spring学习笔记_28——事务-CSDN博客 当你在一个方法或类上使用 Transactional 注解时,Spring 会为该方法或类创建一个…...

github使用基础
要通过终端绑定GitHub账号并进行文件传输,你需要使用Git和SSH密钥来实现安全连接和操作。以下是一个基本流程: 设置GitHub和SSH 检查Git安装 通过终端输入以下命令查看是否安装Git: bash 复制代码 git --version配置Git用户名和邮箱 bash …...

Flink-Kafka-Connector
Apache Flink 是一个用于处理无界和有界数据的开源流处理框架。它支持高吞吐量、低延迟以及精确一次的状态一致性等特性。Flink 社区提供了丰富的连接器(Connectors)以方便与不同的数据源进行交互,其中就包括了 Apache Kafka 连接器。 Apach…...

远程终端vim里使用系统剪切板
1、本地通过终端远程linux server,由于不是桌面环境/GUI,终端vim里似乎没办法直接使用系统剪切板,即便已经是clipboard。 $ vim --version | grep clipboard clipboard keymap printer vertsplit eval …...

底层视角看C语言
文章目录 main函数很普通main函数之前调用了什么main函数和自定义函数的对比 变量名只为人而存在goto是循环的本质指针变量指针是一个特殊的数字汇编层面看指针 数组和指针数组越界问题低端地址越界高端地址越界 引用就是指针 main函数很普通 main函数是第一个被调用的函数吗&…...

【点云学习笔记】——分割任务学习
3D点云实例分割 vs 3D点云语义分割 1. 功能对比 代码1(实例分割):用于3D点云中的实例分割任务,其目标是将点云中的物体分割成独立的实例。每个实例可能属于相同类别但需要被分开,比如在自动驾驶中的多个行人、汽车&am…...
Qt——窗口
一.窗口概述 Qt 窗口是通过 QMainWindow 类来实现的。 QMainWindow是一个为用户提供主窗口程序的类,继承QWidget类,并且提供一个预定义的布局。包含一个菜单栏(menu bar),多个工具栏(tool bars࿰…...

InfluxDB性能优化指南
1. 引言 1.1 InfluxDB的简介与发展背景 InfluxDB是一个开源的时间序列数据库(TSDB),由InfluxData公司开发,专门用于处理高频率的数据写入和查询。其设计初衷是为物联网、应用程序监控、DevOps和实时分析等场景提供一个高效的存储…...
负载均衡式在线oj项目开发文档2(个人项目)
judge模块的框架 完成了网页渲染的功能之后,就需要判断用户提交的代码是否是正确的,当用户点击提交之后,就会交给路由模块的/judge模块,然后这个路由模块就需要去调用jude模块了,也就是需要一个新的jude模块ÿ…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

comfyui 工作流中 图生视频 如何增加视频的长度到5秒
comfyUI 工作流怎么可以生成更长的视频。除了硬件显存要求之外还有别的方法吗? 在ComfyUI中实现图生视频并延长到5秒,需要结合多个扩展和技巧。以下是完整解决方案: 核心工作流配置(24fps下5秒120帧) #mermaid-svg-yP…...
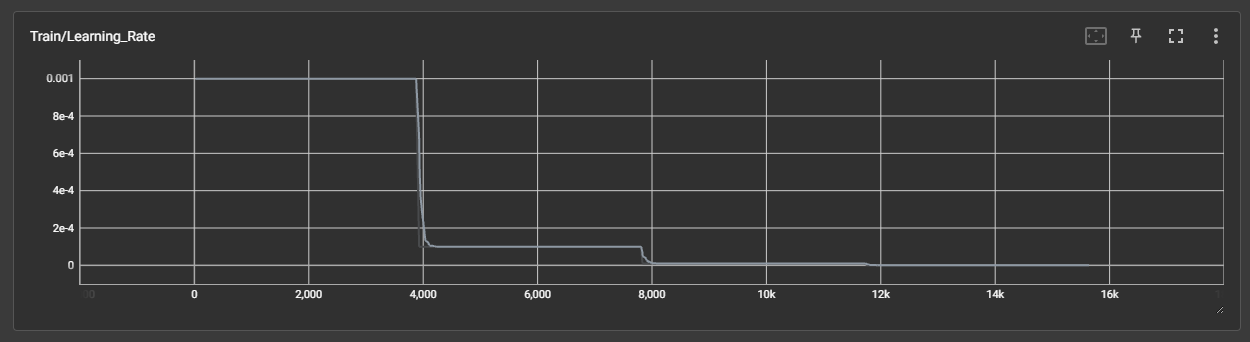
DAY 45 超大力王爱学Python
来自超大力王的友情提示:在用tensordoard的时候一定一定要用绝对位置,例如:tensorboard --logdir"D:\代码\archive (1)\runs\cifar10_mlp_experiment_2" 不然读取不了数据 知识点回顾: tensorboard的发展历史和原理tens…...

边缘计算网关提升水产养殖尾水处理的远程运维效率
一、项目背景 随着水产养殖行业的快速发展,养殖尾水的处理成为了一个亟待解决的环保问题。传统的尾水处理方式不仅效率低下,而且难以实现精准监控和管理。为了提升尾水处理的效果和效率,同时降低人力成本,某大型水产养殖企业决定…...
基于谷歌ADK的 智能产品推荐系统(2): 模块功能详解
在我的上一篇博客:基于谷歌ADK的 智能产品推荐系统(1): 功能简介-CSDN博客 中我们介绍了个性化购物 Agent 项目,该项目展示了一个强大的框架,旨在模拟和实现在线购物环境中的智能导购。它不仅仅是一个简单的聊天机器人,更是一个集…...