Python学习从0到1 day27 第三阶段 Spark ② 数据计算Ⅰ
人总是会执着于失去的,而又不珍惜现在所拥有的
—— 24.11.9
一、map方法
PySpark的数据计算,都是基于RDD对象来进行的,采用依赖进行,RDD对象内置丰富的成员方法(算子)
map算子
功能:map算子,是将RDD的数据一条条处理(处理的逻辑:基于map算子中接收的处理函数),返回新的RDD
语法:
from pyspark import SparkConf,SparkContext# 设置spark中的python解释器对象
import os
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备一个RDD对象
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9])
# 通过map方法将全部的数据乘以10
# 能够接受一个函数,并且将函数作为参数传递进去
# 方法1:接受一个匿名函数lambda
rdd1 = rdd.map(lambda x:x*10)
print("rdd1:",rdd1.collect())# 方法2:接受一个函数
def multi(x):return x * 10rdd2 = rdd.map(multi)
print("rdd2:",rdd2.collect())# 匿名函数链式调用
# 将每一个数乘以100再加上7再减去114
rdd3 = rdd.map(lambda x:x*100).map(lambda x:x+7).map(lambda x:x-114)
print("rdd3:",rdd3.collect())
注:
map算子可以通过lambda匿名函数进行链式调用,处理复杂的功能
二、flatMap方法
flatMap算子
计算逻辑和map一样
比map多出:解除一层嵌套的功能
功能:
对rdd执行map操作,然后进行 解除嵌套 操作
用法
from pyspark import SparkConf,SparkContext# 设置spark中的python解释器对象
import os
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)rdd = sc.parallelize(["一切都会解决 回头看","轻舟已过万重山 一切都会好的","我一直相信"])# 需求:将RDD数据里面的一个个单词提取出来
rdd1 = rdd.map(lambda x:x.split(" "))
print("rdd1:", rdd2.collect())rdd2 = rdd.flatMap(lambda x:x.split(" "))
print("rdd2:", rdd3.collect())
注:
计算逻辑和map一样,比map多出解除一层嵌套的功能
三、reduceByKey方法
reduceByKey算子
功能:
① 自动分组:针对KV型(二元元组)RDD,自动按照 key 分组
② 分组聚合:接受一个处理函数,根据你提供的聚合逻辑,完成组内数据 (valve) 的聚合操作.
用法:
rdd.reduceByKey(func)
# func:(V,V)→V
# 接受2个传入参数(类型要一致),返回一个返回值,类型和传入要求一致reduceByKey的聚合逻辑是:
比如,有[1,2,3,4,5],然后聚合函数是:lambda a,b:a + b
将容器中的所有元素进行聚合

语法:
from pyspark import SparkConf,SparkContext# 设置spark中的python解释器对象
import os
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备一个二元元组rdd对象
rdd = sc.parallelize([("男",99),("男",88),("女",99),("男",77),("女",88)])# 求男生和女生两个组的成绩之和
rdd2 = rdd.reduceByKey(lambda x , y : x + y)
print(rdd2.collect())
注:
1.reduceByKey算子:接受一个处理函数,对数据进行两两计算
四、WordCount案例
使用PySpark进行单词计数的案例
读取文件,统计文件内,单词的出现数量
WordCount文件:
So long as men can breathe or eyes can see,
So long lives this,and this gives life to thee.
代码
将所有单词都转换成二元元组,单词为key,value设置为1,value表示每个单词出现的次数,作为value,初始化为1,若单词相等,则表示key相同,value值进行累加
from pyspark import SparkConf,SparkContext# 设置spark中的python解释器对象
import os
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 读取数据文件
rdd = sc.textFile("D:/2LFE\Desktop\WordCount.txt")
# 取出全部单词
word_rdd = rdd.flatMap(lambda x:x.split(" "))
print(word_rdd.collect())
# 将所有单词都转换成二元元组,单词为key,value设置为1,value表示每个单词出现的次数,作为value,
# 若单词相等,则表示value相同,key值进行累加
word_with_one_rdd = word_rdd.map(lambda word:(word,1))
# 分组并求和
result_rdd = word_with_one_rdd.reduceByKey(lambda a,b:a+b)
# 打印并输出结果
print(result_rdd.collect())
相关文章:
Python学习从0到1 day27 第三阶段 Spark ② 数据计算Ⅰ
人总是会执着于失去的,而又不珍惜现在所拥有的 —— 24.11.9 一、map方法 PySpark的数据计算,都是基于RDD对象来进行的,采用依赖进行,RDD对象内置丰富的成员方法(算子) map算子 功能:map算子…...

Python学习从0到1 day27 第三阶段 Spark ③ 数据计算 Ⅱ
目录 一、Filter方法 功能 语法 代码 总结 filter算子 二、distinct方法 功能 语法 代码 总结 distinct算子 三、SortBy方法 功能 语法 代码 总结 sortBy算子 四、数据计算练习 需求: 解答 总结 去重函数: 过滤函数: 转换函数: 排…...

腾讯混元3D模型Hunyuan3D-1.0部署与推理优化指南
腾讯混元3D模型Hunyuan3D-1.0部署与推理优化指南 摘要: 本文将详细介绍如何部署腾讯混元3D模型Hunyuan3D-1.0,并针对不同硬件配置提供优化的推理方案。我们将探讨如何在有限的GPU内存下,通过调整配置来优化模型的推理性能。 1. 项目概览 腾…...

基于 PyTorch 从零手搓一个GPT Transformer 对话大模型
一、从零手实现 GPT Transformer 模型架构 近年来,大模型的发展势头迅猛,成为了人工智能领域的研究热点。大模型以其强大的语言理解和生成能力,在自然语言处理、机器翻译、文本生成等多个领域取得了显著的成果。但这些都离不开其背后的核心架…...
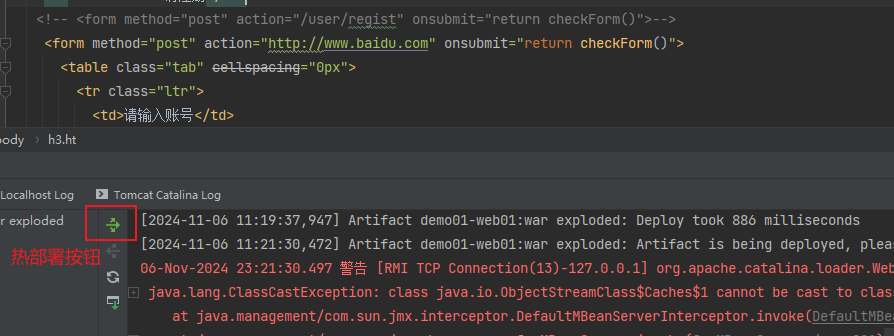
IDEA构建JavaWeb项目,并通过Tomcat成功运行
目录 一、Tomcat简介 二、Tomcat安装步骤 1.选择分支下载 2.点击下载zip安装包 3.解压到没有中文、空格和特殊字符的目录下 4.双击bin目录下的startup.bat脚本启动Tomcat 5.浏览器访问Tomcat 6.关闭Tomcat服务器 三、Tomcat目录介绍 四、WEB项目的标准结构 五、WEB…...
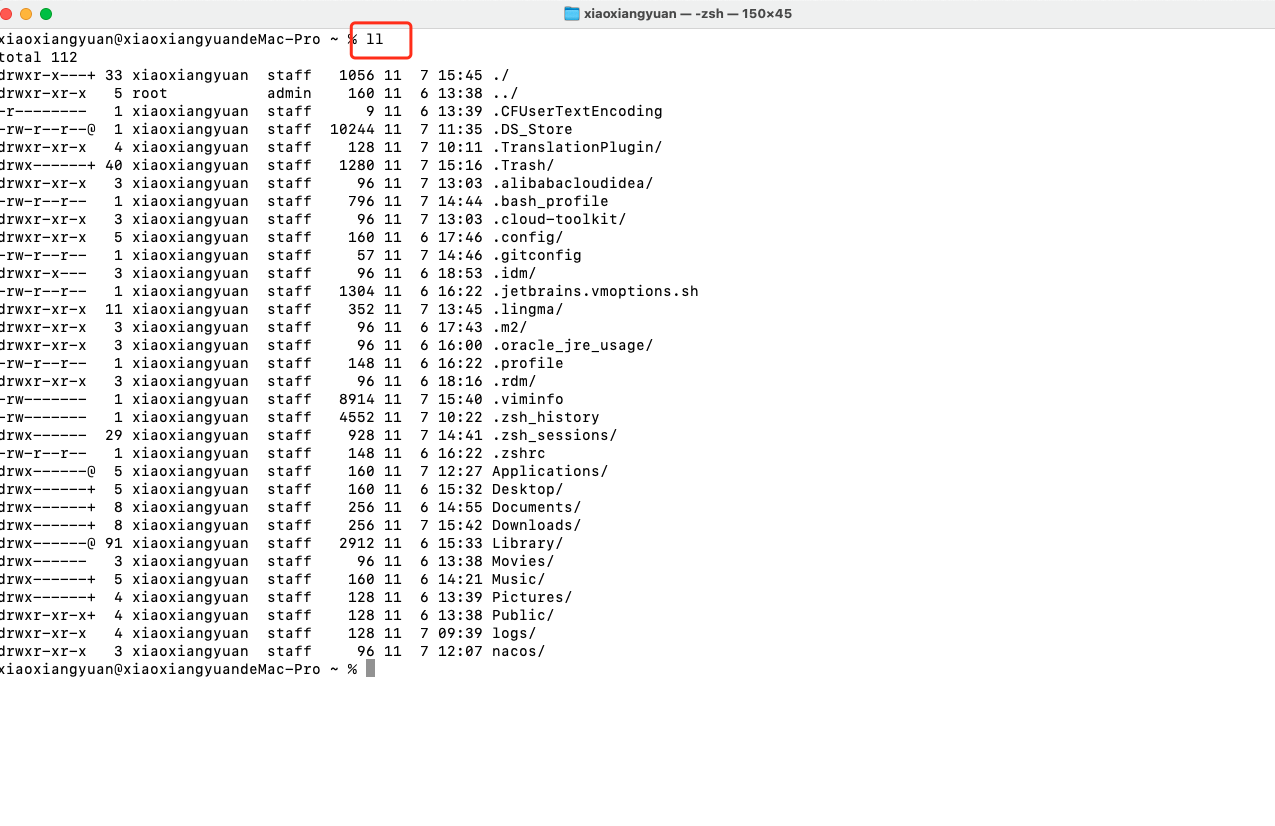
Mac解决 zsh: command not found: ll
Mac解决 zsh: command not found: ll 文章目录 Mac解决 zsh: command not found: ll解决方法 解决方法 1.打开bash_profile 配置文件vim ~/.bash_profile2.在文件中添加配置:alias llls -alF键盘按下 I 键进入编辑模式3. alias llls -alF添加完配置后,按…...
库打包工具 rollup
库打包工具 rollup 摘要 **概念:**rollup是一个模块化的打包工具 注:实际应用中,rollup更多是一个库打包工具 与Webpack的区别: 文件处理: rollup 更多专注于 JS 代码,并针对 ES Module 进行打包webpa…...

unplugin-vue-components 库作用
一、基本概念与用途 1. 自动导入 Vue 组件 unplugin - vue - components是一个用于 Vue 项目的插件,主要功能是自动导入组件,从而减少在 Vue 组件中手动导入其他组件的繁琐过程。 在大型 Vue 项目中,往往会有许多自定义组件或者第三方组件…...

LinkedList和单双链表。
java中提供了双向链表的动态数据结构 --- LinkedList,它同时也实现了List接口,可以当作普通的列表来使用。也可以自定义实现链表。 单向链表:一个节点本节点数据下个节点地址 给定两个有序链表的头指针head1和head2,打印两个链表…...
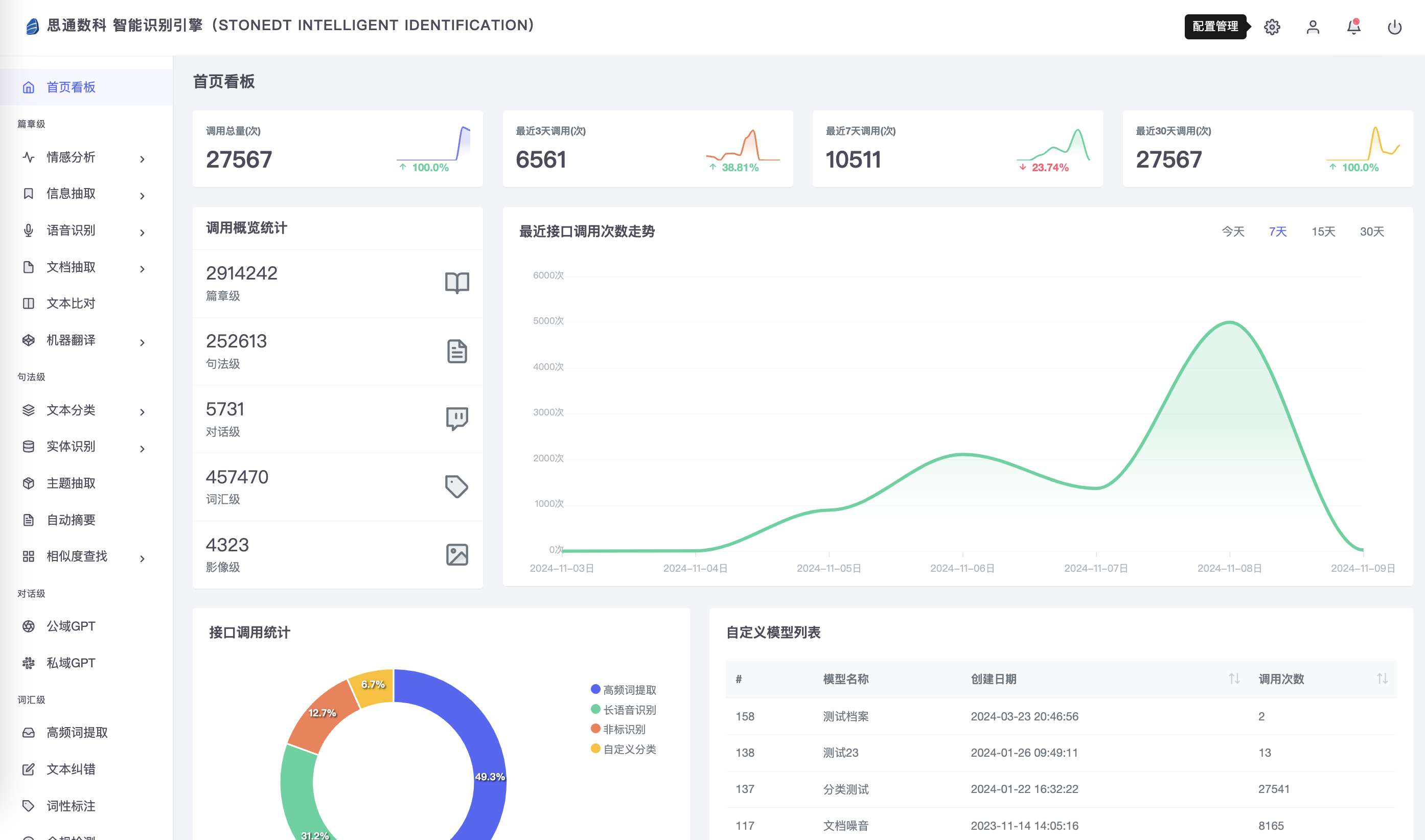
AI与OCR:数字档案馆图像扫描与文字识别技术实现与项目案例
文末有免费工具可在线体验,或者网络搜索关键词“思通开源AI能力平台” 一、扫描与图像预处理 技术实现过程 在纸质档案的数字化过程中,首先需要使用高精度扫描仪对纸质文档进行扫描,生成高清的数字图像。这一步骤是整个OCR流程的基础…...

Spring boot 读模块项目升级为spring cloud 项目步骤以及问题
1.结构说明 bean 模块 ,public 模块, client 模块, erp模块,system 主模块。 2.环境说明以及pom 原本环境 新环境 mysql 5.7 -------------- mysql 8.0 maven 3.9.6 jdk 8 -----------…...

时序数据库之influxdb和倒排索引以及LSM-TREE
一、时序数据库的特点 1、时序数据库用作打点,用来做监控使用,属于写多读少的场景,而且由于时间不可逆,几乎不可能出现更新的操作。而且监控数据一般只会查询最近几分钟数据,冷热数据查询频率非常明显。因此非常贴合ES…...

如何避免消息的重复消费问题?(消息消费时的幂等性)
如何避免消息的重复消费问题 1、 消息的幂等性1.1、概念1.2、产生业务场景 2、全局唯一IDRedis解决消息幂等性问题2.1、application.yml配置文件2.2、生产者发送消息2.3、消费者接收消息2.4、pom.xml引入依赖2.5、RabbitConfig配置类2.6、启动类2.7、订单对象2.8、测试 1、 消息…...

【Java SE】类与对象
现实世界中,随处可见的一个事物实体就是对象,而类就是同一类事物(或对象)的统称,由一个类构造对象的过程称为创建这个类的一个实例(instance),即: 类(class&…...

基于springboot的公益服务平台的设计与实现
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于springboot的公益服务平台的设计与实…...
 什么是Servlet容器?)
Tomcat(6) 什么是Servlet容器?
Servlet容器是Java EE技术中的一个关键组件,它负责管理和执行Servlet。Servlet容器提供了运行时环境,使得Servlet能够接收和响应来自客户端的HTTP请求。以下是Servlet容器的详细解释,以及一些相关的代码示例。 Servlet容器的主要功能 加载和…...

用js去除变量里的html标签
要用 JavaScript 去除字符串中的 HTML 标签,你可以使用正则表达式。以下是一个简单的示例代码: function removeHTMLTags(str) {return str.replace(/<[^>]*>/g, ); }// 示例 var str <p>This is <b>bold</b> text with <…...

Vue3+element-plus摘要
1.如果自己电脑vue版本是vue2版本,下面将详细介绍如何在vue2版本基础上继续安装 vue3版本且不会影响vue2版本的使用 1-1 在c盘或者别的盘建一个文件夹vue3 1-2 在这个文件夹里使用WINR 打开终端 输入命令 npm install vue/cli 安装完即可 1-3 然后进入此文件夹中的n…...
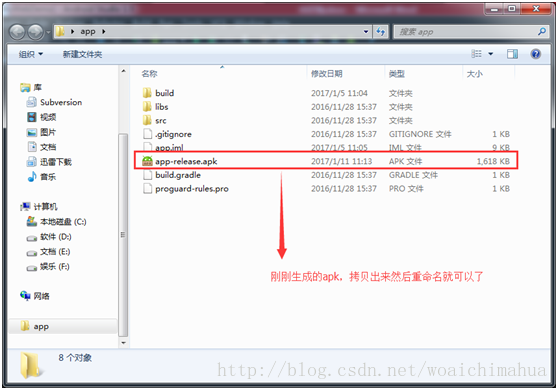
Android Studio 将项目打包成apk文件
第一步:选择Build -> Generate Signed APK 会出现: 我们选择 Create new… 然后选择你要存放密钥的地方 点击ok之后,则选择好了文件,并生成了jks文件了。 点击ok之后, 会出现: 选择release…...

贪心算法day2(最长递增子序列)
目录 1.最长递增子序列 方法一:动态规划 方法二:贪心二分查找 1.最长递增子序列 链接:. - 力扣(LeetCode) 方法一:动态规划 思路:我们定义dp[i]为最长递增子序列,那么dp[j]就是…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...