【网络】应用层——HTTP协议
> 作者:დ旧言~
> 座右铭:松树千年终是朽,槿花一日自为荣。> 目标:了解什么是HTTP协议。
> 毒鸡汤:有些事情,总是不明白,所以我不会坚持。早安!
> 专栏选自:网络
> 望小伙伴们点赞👍收藏✨加关注哟💕💕

一、前言
前面我们已经学习了网络的基础知识,对网络的基本框架已有认识,算是初步认识到网络了,如果上期我们的学习网络是步入基础知识,那么这次学习的板块就是基础知识的实践,我们今天的板块是学习网络重要之一,学习完这个板块对虚幻的网络就不再迷茫!!!

二、主体
学习【网络】应用层——HTTP协议咱们按照下面的图解:

2.1 HTTP协议简介
概念:
- HTTP 协议 是 Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网( WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。HTTP 是一个基于 TCP/IP 通信协议来传递数据(HTML 文件、图片文件、查询结果等)。
- HTTP协议用于在客户端和服务器之间传输超文本。它是 Web 的基础,可用于检索和提交信息,例如 HTML 文件、图像、样式表等。HTTP 是无状态的,也就是说每个请求都是独立的,服务器不会存储任何有关先前请求的信息。HTTP协议常用于浏览器与 Web 服务器之间的通信。
2.2 认识URL
概念:
在WWW上,每一信息资源都有统一的且在网上的地址,该地址就叫URL(Uniform Resource Locator,统一资源定位器),它是WWW的统一资源定位标志,就是指网络地址。平时我们俗称的 "网址" 其实就是说的 URL,URL标识了Internet上的每一个唯一的网页。
URL组成部分如下:

协议方案名:
概念:
http://表示的是协议名称,表示请求时需要使用的协议,通常使用的是HTTP协议或者是安全协议HTTPS。
常见的应用层协议:
- DNS(Domain Name System)协议:域名系统。
- FTP(File Transfer Protocol)协议:文件传输协议。
- TELNET(Telnet)协议:远程终端协议。
- HTTP(Hyper Text Transfer Protocol)协议:超文本传输协议。
- HTTPS(Hyper Text Transfer Protocol over SecureSocket Layer)协议:安全数据传输协议。
- SMTP(Simple Mail Transfer Protocol)协议:电子邮件传输协议。
- POP3(Post Office Protocol - Version 3)协议:邮件读取协议。
- SNMP(Simple Network Management Protocol)协议:简单网络管理协议。
- TFTP(Trivial File Transfer Protocol)协议:简单文件传输协议。
登录信息:
usr:pass 表示的是登录认证信息,包括登录用户的用户名和密码,不过登录信息一般不显示在URL中,绝大部分URL中的这个字段是被省略的,因为登录信息可以通过其他方案交给服务器。
服务器地址:
说明:
www.example.jp表示的是服务器地址,也叫做域名,比如:www.baidu.com,www.jd.com等。
域名可以被解析成IP地址:

补充:
在这里我们需要知道的是:虽然IP地址可以标识公网内的一台主机,但是IP地址一般不会直接给用户看到,因为用户看到IP地址后并不知道该IP地址的网站是干什么的,但是如果使用www.baidu.com或者www.qq.com这种网址的方式访问网站,那么用户至少可以知道这两个域名对应的是哪两家公司。
域名和IP地址是等价的,我们同样可以使用IP地址来访问网址,但是URL呈现出来是给用户看的,所以URL中以域名的方式表示服务器的地址。
服务器端口号:
解释:
80表示的是服务器的端口号,HTTP协议和套接字编程都是位于应用层的,因此应用层协议同样也需要有明确的端口号。
当然,当我们在使用某种协议时,该协议就是在为我们提供服务,因此一般常用的服务和端口号之间的关系都是一一对应的,所以我们在使用某种协议时并不需要明确指定端口号。因此在URL中服务器的端口号一般都是被省略的。
常见协议对应的端口号:
- HTTP (Hyper Text Transfer Protocol) 端口号:80
- HTTPS (Secure Hyper Text Transfer Protocol) 端口号:443
- FTP (File Transfer Protocol) 端口号:21
- SMTP (Simple Mail Transfer Protocol) 端口号:25
- POP3 (Post Office Protocol version 3) 端口号:110
- IMAP (Internet Message Access Protocol) 端口号:143
- DNS (Domain Name System) 端口号:53
- DHCP (Dynamic Host Configuration Protocol) 端口号:67/68
- Telnet (Terminal Emulation) 端口号:23
- SSH (Secure Shell) 端口号:22
- NTP (Network Time Protocol) 端口号:123
- SNMP (Simple Network Management Protocol) 端口号:161/162
- RDP (Remote Desktop Protocol) 端口号:3389
- SIP (Session Initiation Protocol) 端口号:5060/5061
- ICQ (Internet Control Message Protocol) 端口号:7
- IRC (Internet Relay Chat) 端口号:194
- BitTorrent 端口号:6881-6889
带层次的文件路径:
/dir/index.htm:
表示的是要访问的资源所在的路径,访问服务器的目的是获取服务器上的某种资源,通过前面的域名和端口号已经能够找到对应的服务器进程了,接下来我们需要指明该资源所在的路径。
在URL当中的路径分隔符用 / 表示而不是 \ 证明了大多数的服务器都是部署在Linux下的。
查询字符串:
uid=1:表示的是请求时提供的额外参数,这些参数一般都是以键值对的形式,通过&服务分隔。当然我们使用百度搜索时提供的搜索关键字也在其中。
片段标识符:
ch1表示的是片段标识符,是对资源的部分补充,当我们在看图片的时候,URL当中就会出现片段标识符,当我们切换到其他图片时这个符号也会发生变化。
2.3 HTTP协议格式
概念:
HTTP是基于请求和响应的应用层服务器,作为客户端,我们可以向服务器发起请求,服务器收到这个请求后,会对这个请求做数据分析,然后构建response,完成一次HTTP请求,这种基于request和response的工作方式,一般被称为cs或者bs模式,c表示client,s表示server,b表示browser。

2.3.1 HTTP请求协议格式
HTTP请求协议的格式:
- 请求行:请求方法 + url + http版本
- 请求报头:请求的属性,这些属性都是以key: value的形式按行陈列的。
- 空行:遇到空行表示请求报头结束。
- 请求正文:请求正文允许为空字符串,如果请求正文存在,则在请求报头中会有一个Content-Length属性来标识请求正文的长度。

解释说明:
- 前面三部分是一般是HTTP协议自带的,是由HTTP协议自行设置的,而请求正文一般是用户的相关信息或数据,如果用户在请求时没有信息要上传给服务器,此时请求正文就为空字符串
- 这里的空行可以将可以将HTTP的报头和有效载荷进行分离。当服务器收到一个HTTP请求时,就可以按行进行读取,如果读取到空行则说明已经将报头读取完毕了。
2.3.2 HTTP响应协议格式
HTTP响应协议格式如下:
- 状态行:http版本 + 状态码 + 状态码描述
- 响应报头:响应的属性,这些属性都是以key: value的形式按行陈列的。
- 空行:遇到空行表示响应报头结束。
- 响应正文:响应正文允许为空字符串,如果响应正文存在,则响应报头中会有一个Content-Length属性来标识响应正文的长度。比如服务器返回了一个html页面,那么这个html页面的内容就是在响应正文当中的。

2.4 HTTP的方法
HTTP常见的方法如下:

GET方法和POST方法:
- GET方法用于获取某种资源信息
- POST方法用于将数据上传给服务器
但实际生活中上传数据时也有可能使用GET方法,比如百度官网提交数据时实际使用的就是GET方法。
- GET方法通过url传参
- POST方法通过正文传参
因为url的长度是有限的,而正文则可以很长,所以使用POST方法通过正文传参可以携带更多的数据,同时,使用POST方法传参更加私密,因为POST方法不会将我们所提交的参数回响到url当中。但是两者都不安全,想要更加安全只能通过加密来实现。
表单(Form) :
是 HTML 中一种常用的元素,它是用来接受用户输入的一种方式。表单包含了各种表单元素,如文本框、单选框、复选框、下拉框等,用户可以通过这些元素输入信息,然后通过表单提交(Submit)按钮将这些信息发送到后端服务器。

写一个表单:index.html (get方法)
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title>
</head>
<body><form action="/a/b/c/index2.html" method="get">name:<input type="text" name="name"><br>passwd:<input type="password" name="passwd"><br><input type="submit" value="提交"></form>--><h1>这个是我们的首页</h1>
</body>
</html>结果:

分析:
我们发现 如果我们要提交参数给我们的服务器,我们使用get方法的时候,url上加上了我们的参数,而我们提交的参数是通过url提交的!但是此时在我们网页根目录之下不存在这样的路径,所以就返回404。
修改后的代码:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title>
</head>
<body><form action="/a/b/c/index2.html" method="post">name:<input type="text" name="name"><br>passwd:<input type="password" name="passwd"><br><input type="submit" value="提交"></form>--><h1>这个是我们的首页</h1>
</body>
</html>结果:

2.5 HTTP的状态码
HTTP状态码是用来表示HTTP请求的处理结果的三位数字代码。它们可以分为五大类:信息响应(1xx)、成功响应(2xx)、重定向(3xx)、客户端错误(4xx)和服务端错误(5xx)。

信息响应(1xx)
信息响应表示请求已经被接受,但处理尚未完成。常见的状态码有:
- 100 Continue:服务器已经接收到请求头,并且客户端应继续发送请求体。
- 101 Switching Protocols:服务器已经理解并同意将请求切换到新的协议。
成功响应(2xx)
成功响应表示请求已经被成功处理。常见的状态码有:
- 200 OK:请求已成功处理,返回结果。
- 201 Created:请求已被实现,而且有一个新的资源被创建。
- 204 No Content:服务器成功处理了请求,但没有返回任何内容。
重定向(3xx)
重定向表示请求的资源已经被移动到了一个新的位置,客户端需要重新发送请求。常见的状态码有:
- 301 Moved Permanently:请求的资源已经被永久移动到新的位置。
- 302 Found:请求的资源已经被临时移动到新的位置。
- 303 See Other:请求的资源可以通过GET方法访问另一个URI。
- 307 Temporary Redirect:与302类似,但指定了临时重定向。
客户端错误(4xx)
客户端错误表示或者客户端发送的请求有问题。常见的状态码有:
- 400 Bad Request:服务器无法理解客户端发送的请求。
- 401 Unauthorized:请求需要用户验证。
- 403 Forbidden:服务器拒绝处理请求,可能是因为客户端没有权限。
- 404 Not Found:请求的资源不存在。
服务端错误(5xx)
服务端错误表示服务器在处理请求时发生了错误。常见的状态码有:
- 500 Internal Server Error:服务器在处理请求时发生了未知的错误。
- 503 Service Unavailable:服务器暂时无法处理请求,通常是因为服务器过载或维护。
2.5.1 见一见404状态码(代码)
首先我们要明白这个404一定是没找到资源才会触发的:
err.html文件:
<!doctype html>
<html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title>
</head><body><div><h1>404</h1><p>页面未找到<br></p><p>您请求的页面可能已经被删除、更名或者您输入的网址有误。<br>请尝试使用以下链接或者自行搜索:<br><br><a href="https://www.baidu.com">百度一下></a></p></div>
</body>
</html>HttpServer.hpp:
#pragma once#include <iostream>
#include <string>
#include <pthread.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <fstream>
#include <sstream>
#include <vector>
#include "Socket.hpp"using namespace std;static const uint16_t defaultport = 8877;
const string wwwroot = "./wwwroot"; // web 根目录
const string homepath = "/index.html";
const std::string sep = "\r\n";class HttpRequest
{
public:// 反序列化函数,用于将字符串格式的HTTP请求分解为请求头和请求体void Deserialize(std::string req){// 假设sep是一个成员变量,用于分隔请求头和请求体,但在此代码段中未定义// 这里应该是用于分割请求头中每一行的分隔符,例如"\r\n"// while循环用于遍历字符串,直到找不到分隔符while (true){// 在请求字符串中查找分隔符\r\n的位置size_t pos = req.find(sep);// 如果没有找到分隔符\r\n,则退出循环if (pos == string::npos)break;// 截取从开头到分隔符\r\n之前的字符串作为请求头的一部分string temp = req.substr(0, pos);// 如果截取的字符串为空,则也退出循环(这通常是不必要的,因为find不会返回0位置除非是空字符串)if (temp.empty())break;// 将截取的字符串添加到请求头向量中req_header.push_back(temp);// 从请求字符串中移除已经处理的部分,包括分隔符req.erase(0, pos + sep.size());}// 剩下的字符串(如果有的话)被认为是请求正文text = req;}// 解析函数,用于解析请求行的第一部分(通常是HTTP方法、URL和HTTP版本)void Parse(){// 使用stringstream和字符串流输入操作符来解析请求行的第一个元素std::stringstream ss(req_header[0]); // 将第一行交给ss// 将请求行解析为HTTP方法、URL和HTTP版本ss >> method >> url >> http_version; // gei第一个单词会给method,第二个会给url,第3个会给http_versionfile_path=wwwroot;//./wwwrootif(url=="/" || url=="/index.html"){file_path+=homepath;// ./wwwroot/index.html}else{file_path+=url;//./wwwroot/url} }// 调试打印函数,用于输出请求的所有信息void DebugPrint(){// 遍历请求头,并打印每一行for (auto &line : req_header){std::cout << "--------------------------------" << std::endl;std::cout << line << "\n\n";}// 打印解析后的HTTP方法、URL和HTTP版本std::cout << "method: " << method << std::endl;std::cout << "url: " << url << std::endl;std::cout << "http_version: " << http_version << std::endl;std::cout << "file_path: " << file_path << std::endl;// 打印请求正文std::cout << text << std::endl;}public:std::vector<std::string> req_header; // 用于存储请求头的字符串向量std::string text; // 用于存储请求正文的字符串std::string file_path;//用于存储转换后的文件地址 // 解析请求行之后得到的结果std::string method; // HTTP方法,如GET、POSTstd::string url; // 请求的URLstd::string http_version; // HTTP的版本号,如HTTP/1.1
};class HttpServer; // 声明class ThreadData // 传给线程的数据
{
public:ThreadData(int fd): _sockfd(fd){}public:int _sockfd;
};class HttpServer
{
public:HttpServer(uint16_t port = defaultport): _port(port){}bool Start(){_listensockfd.Socket();_listensockfd.Bind(_port);_listensockfd.Listen();for (;;){// 获取用户信息string clientip;uint16_t clientport;// 两个都是输出型参数// 注意Accept成员函数会返回一个新的套接字,专门用于发送信息的int sockfd = _listensockfd.Accept(&clientip, &clientport); // 这里获取了客户端IP和端口号if (sockfd < 0)continue;std::cout << "get a new connect, sockfd:" << sockfd << std::endl;// 下面使用多线程来和用户端进行通信pthread_t tid;ThreadData *td = new ThreadData(sockfd);pthread_create(&tid, nullptr, ThreadRun, td);}return true;}static string ReadHtmlContent(const string &htmlpath) // 读html文件,将它的内容存到content{// 坑ifstream in(htmlpath);if (!in.is_open())return "";std::cout << htmlpath << std::endl;string content;string line;while (getline(in, line)){content += line;}in.close();return content;}static void HandlerHttp(int sockfd){char buffer[10240];ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);// 注意这里我们不用read了,而是使用recv函数,这个和read非常类似,第3个参数为0的时候,功能和read一模一样if (n > 0) // 读取成功{buffer[n] = 0;cout << buffer << std::endl; // 输出HTTP请求// 这里是巨大变化HttpRequest req;req.Deserialize(buffer);req.Parse();req.DebugPrint();// 返回响应的过程,这里需要返回一个HTTP响应协议std::cout << req.file_path << std::endl;bool ok=true;string text = ReadHtmlContent(req.file_path);//HTTP协议有效载荷——这里是一个简单的网页,这个网页放在req.file_pathif(text.empty()){ok=false;std::string err_html=wwwroot;err_html+="/err.html";text=ReadHtmlContent(err_html);//}string response_line;if(ok){ response_line="HTTP/1.0 200 OK\r\n";//HTTP响应协议的第一行的版本号 状态码 状态码描述}else{response_line="HTTP/1.0 404 Not Found\r\n";//HTTP响应协议的第一行的版本号 状态码 状态码描述}string response_header = "Content-Length: ";//HTTP报头的最后一行需要记录有效载荷的大小response_header += to_string(text.size()); // 11response_header += "\r\n";//结束这一行string block_line = "\r\n";//这一行是空行,用来区分协议报头和有效载荷string response = response_line;response += response_header;response += block_line;response += text;//response 最终就是"HTTP/1.0 200 OK\r\nContent-Length: 11\r\n\r\nhello world"send(sockfd, response.c_str(), response.size(), 0);//注意这里不用write了,//send前几个参数和write基本一样,当send第4个为0的时候功能和write一模一样}close(sockfd);}static void *ThreadRun(void *args){pthread_detach(pthread_self()); // 分离线程ThreadData *td = static_cast<ThreadData *>(args);HandlerHttp(td->_sockfd); // 执行http的任务delete td;return nullptr;}~HttpServer(){}private:Sock _listensockfd; // 用于监听的uint16_t _port; // 用于发送消息的
};结果:

2.5.2 见一见3XX状态码(代码)
这里只需要修改部分代码:
class HttpServer
{
......static void HandlerHttp(int sockfd){.......response_line="HTTP/1.0 302 Found\r\n";string response_header = "Content-Length: ";//HTTP报头的最后一行需要记录有效载荷的大小response_header += to_string(text.size()); // 11response_header += "\r\n";//结束这一行response_header += "Location: https://www.baidu.com";//注意这里string block_line = "\r\n";//这一行是空行,用来区分协议报头和有效载荷string response = response_line;response += response_header;response += block_line;response += text;//response 最终就是"HTTP/1.0 200 OK\r\nContent-Length: 11\r\n\r\nhello world"send(sockfd, response.c_str(), response.size(), 0);//注意这里不用write了,//send前几个参数和write基本一样,当send第4个为0的时候功能和write一模一样....}};2.6 HTTP常见的Header
- Content-Type:数据类型(text / html 等)
- Content-Length:Body 的长度,用于指示客户端应该接收多少字节的响应
- Host:客户端告知服务器,所请求的资源是在哪个主机的哪个端口上
- User-Agent:声明用户的操作系统和浏览器版本信息
- referer:当前页面是从哪个页面跳转过来的
- location:搭配 3xx 状态码使用,告诉客户端接下来要去哪里访问
- Cookie:用于在客户端存储少量信息,通常用于实现会话(session)的功能
Keep-Alive(长连接):
HTTP 的长连接和短连接都是指在 TCP 层面上的连接。HTTP 协议是基于 TCP 协议的,每次 HTTP 请求和响应都需要建立和断开 TCP 连接,因此在高并发场景下会产生大量的 TCP 连接开销,从而影响性能。如果HTTP请求或响应报头当中的Connect字段对应的值是Keep-Alive,就代表支持长连接。
短连接:
指每次HTTP请求和响应都建立一个新的 TCP 连接,并在请求结束后立即关闭连接。这种方式下,每次请求都需要重新建立和断开 TCP 连接,会增加连接管理的负担和开销。在 HTTP/1.0 中,HTTP 默认采用短连接,也就是每次请求和响应都建立和断开一次 TCP 连接。
总结:
如今的HTTP/1.1是支持长连接的。所谓的长连接就是建立连接后,客户端可以不断地向服务器一次写入多个HTTP请求,而服务器在上层一次读取这些请求就行了,此时一条连接就可以传送大量的请求和响应。
长连接和短连接有优缺点:
长连接可以减少 TCP 连接的建立和断开次数,降低网络开销,但长时间占用连接会增加服务器资源消耗;短连接可以保证每个请求的独立性,减少因单个请求错误导致的影响,但频繁的 TCP 连接建立和断开会影响性能。因此,根据具体的应用场景和需求选择长连接或短连接,或者结合两者的优点,使用 HTTP/2 的多路复用技术。
2.7 Cookie(会话)和Session(会期)
HTTP的特征:
- 无状态:每个 HTTP 请求都是独立的,服务器不会保存任何客户端的请求信息,因此 HTTP 被称为无状态协议。为了维护客户端状态,通常使用 Cookie 和 Session技术。
- 可扩展:HTTP 报头可以通过添加自定义报头实现扩展功能。
- 灵活:HTTP 可以传输任何类型的数据,如 HTML、图片、音频、视频等。
- 明文传输:HTTP 是明文传输的,请求和响应中的所有内容都可以被窃听,因此使用 HTTPS 进行加密。
- 请求 / 响应模型:HTTP 采用客户端-服务器模型,客户端发送请求,服务器发送响应。
- 无连接:HTTP 协议不维护连接,连接是 TCP 协议维护的,HTTP直接发起请求和响应即可。
- 缓存:HTTP 支持缓存,可以通过在响应报头中添加缓存信息控制客户端和服务器的缓存机制。
补充说明:
虽然在HTTP的特征中有 无状态 的特点,但是我们可以发现每次在使用浏览器的时候却不是这样的,当我们在使用账号和密码登陆到一个网站的时候,无论我们将该网站关闭还是将浏览器关闭,当我们再次打开该网站时,我们发现我们的账号还是处于登录状态。
但是在实际应用中,为了实现用户的登录状态等功能,网站会在服务器端保存用户的会话状态,并分配给用户一个唯一的 会话标识符(Session ID),这个会话标识符可以在每次请求时传递给服务器,服务器就可以根据这个标识符识别用户,从而实现用户状态的保持。
2.7.1 Cookie
概念:
Cookie 是一种小的文本信息,由服务器发送给客户端的浏览器,然后由浏览器存储在用户的计算机上。它主要用于跟踪和维护Web应用程序的状态,以便在不同的HTTP请求之间保持用户的特定信息。简单点来说就是,HTTP不支持记录用户状态,我们需要一种技术来帮我们支持,这种技术目前现在已经内置到HTTP协议当中了,他就是Cookie。

补充说明:
当我们认证通过后在服务端会进行Set-Cookie设置,当服务器在对浏览器进行HTTP响应时就会将这个Set-Cookie相应给浏览器,浏览器收到响应后自动提取出Set-Cookie的值,并将其保存在浏览器的Cookie文件中,此时就相当于我们的账号密码等信息保存在了本地浏览器的Cookie文件中。
当我们再次向该网站发起HTTP请求时,该请求当中就会自动包含一个Cookie字段,Cookie字段中携带的就是我们第一次的认证信息。因此之后对端服务器在进行认证时只需要提取出HTTP请求当中的Cookie字段即可。
Cookie的种类:本质上就时浏览器当中的一个小文件,文件里记录的是用户的私有信息
- 文件级的 Cookie 文件是存储在用户计算机上的硬盘上,是一种持久性的 Cookie。它们的过期时间可以设置为一段时间,也可以永不过期。在访问同一个网站时,浏览器会自动发送该网站存储在本地计算机上的 Cookie文件,以便在服务器端进行身份验证和授权操作。
- 内存级的 Cookie 文件是存储在内存中的临时 Cookie。当浏览器关闭时,它们会自动删除。内存级的 Cookie 可以用于存储一些敏感信息,如密码和银行账户信息等,以提高安全性。
2.7.2 SessionID
概念:
如果我们仅仅使用Cookie是不安全的,因为此时Cookie文件当中是我们的私密信息,一旦Cookie文件泄露我们的隐私信息也会泄露。所以就引入了SessionID这样的概念。
当我们第一次输入账号密码验证成功后,服务端就会生成一个对应的Session ID,并将其发送给客户端。之后,客户端每次请求都会携带这个 Session ID,服务器就可以根据 Session ID 查找对应的会话对象,获取用户的相关信息,从而实现用户状态的保持。这个Session ID与用户信息是不相关的。同时系统会将所有登录用户的Session ID统一维护起来。

2.8 构建HTTP请求和响应(补充代码)
2.8.1 见见简单的HTTP请求
概念说明:
事实上,上面那些http请求报头都是加密过,其实显示出来的效果不好。我们可以自己写一个代码来获取HTTP请求,首先我们需要使用套接字,所以我们需要将我们之前封装好的套接字拿过来。
Socket.hpp:
#pragma once #include <iostream>
#include <string>
#include <unistd.h>
#include <cstring>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h> // 定义一些错误代码
enum
{ SocketErr = 2, // 套接字创建错误 BindErr, // 绑定错误 ListenErr, // 监听错误
}; // 监听队列的长度
const int backlog = 10; class Sock //服务器专门使用
{
public: Sock() : sockfd_(-1) // 初始化时,将sockfd_设为-1,表示未初始化的套接字 { } ~Sock() { // 析构函数中可以关闭套接字,但这里选择不在析构函数中关闭,因为有时需要手动管理资源 } // 创建套接字 void Socket() { sockfd_ = socket(AF_INET, SOCK_STREAM, 0); if (sockfd_ < 0) { printf("socket error, %s: %d", strerror(errno), errno); //错误 exit(SocketErr); // 发生错误时退出程序 } } // 将套接字绑定到指定的端口上 void Bind(uint16_t port) { //让服务器绑定IP地址与端口号struct sockaddr_in local; memset(&local, 0, sizeof(local));//清零 local.sin_family = AF_INET; // 网络local.sin_port = htons(port); // 我设置为默认绑定任意可用IP地址local.sin_addr.s_addr = INADDR_ANY; // 监听所有可用的网络接口 if (bind(sockfd_, (struct sockaddr *)&local, sizeof(local)) < 0) //让自己绑定别人{ printf("bind error, %s: %d", strerror(errno), errno); exit(BindErr); } } // 监听端口上的连接请求 void Listen() { if (listen(sockfd_, backlog) < 0) { printf("listen error, %s: %d", strerror(errno), errno); exit(ListenErr); } } // 接受一个连接请求 int Accept(std::string *clientip, uint16_t *clientport) { struct sockaddr_in peer; socklen_t len = sizeof(peer); int newfd = accept(sockfd_, (struct sockaddr*)&peer, &len); if(newfd < 0) { printf("accept error, %s: %d", strerror(errno), errno); return -1; } char ipstr[64]; inet_ntop(AF_INET, &peer.sin_addr, ipstr, sizeof(ipstr)); *clientip = ipstr; *clientport = ntohs(peer.sin_port); return newfd; // 返回新的套接字文件描述符 } // 连接到指定的IP和端口——客户端才会用的 bool Connect(const std::string &ip, const uint16_t &port) { struct sockaddr_in peer;//服务器的信息 memset(&peer, 0, sizeof(peer)); peer.sin_family = AF_INET; peer.sin_port = htons(port);inet_pton(AF_INET, ip.c_str(), &(peer.sin_addr)); int n = connect(sockfd_, (struct sockaddr*)&peer, sizeof(peer)); if(n == -1) { std::cerr << "connect to " << ip << ":" << port << " error" << std::endl; return false; } return true; } // 关闭套接字 void Close() { close(sockfd_); } // 获取套接字的文件描述符 int Fd() { return sockfd_; } private: int sockfd_; // 套接字文件描述符
};我们可以自己来写一个代码来获取到HTTP请求:
#pragma once // 防止头文件被重复包含 #include <iostream> // 引入标准输入输出流库
#include <string> // 引入字符串库
#include <pthread.h> // 引入POSIX线程库
#include "Socket.hpp" // 假设这是一个封装了socket操作的类 using namespace std; // 使用标准命名空间 // 定义默认端口号
static const uint16_t defaultport = 8080; // 线程数据结构体,用于在线程间传递socket文件描述符
struct ThreadData
{ int sockfd; // socket文件描述符
}; // HTTP服务器类
class HttpServer
{
public: // 构造函数,初始化服务器监听的端口 HttpServer(uint16_t port = defaultport) : _port(port) // 初始化成员变量_port { } // 启动服务器 bool Start() { _listensockfd.Socket(); // 创建socket _listensockfd.Bind(_port); // 绑定socket到指定的端口 _listensockfd.Listen(); // 开始监听端口 for(;;) // 无限循环,等待连接 { string clientip; // 用于存储客户端IP地址 uint16_t clientport; // 用于存储客户端端口号 int sockfd = _listensockfd.Accept(&clientip, &clientport); // 接受连接,返回新的socket文件描述符 pthread_t tid; // POSIX线程标识符 printf("get a new connect, sockfd: %d\n", sockfd); // 创建线程数据并传递给新线程 ThreadData *td = new ThreadData; td->sockfd = sockfd; pthread_create(&tid, nullptr, ThreadRun, td); // 创建新线程处理客户端请求 } return true; // 注意:这里的return实际上永远不会被执行,因为for循环是无限的 } // 静态成员函数,用于处理客户端请求 static void *ThreadRun(void *args) { pthread_detach(pthread_self()); // 分离线程,让线程在结束时自动释放资源 ThreadData *td = static_cast<ThreadData *>(args); // 将void*类型的参数转换为ThreadData* char buffer[10240]; // 接收数据的缓冲区 ssize_t n = recv(td->sockfd, buffer, sizeof(buffer)-1, 0); // 接收客户端发送的数据 if (n > 0) // 如果接收到数据 { buffer[n] = 0; // 确保字符串以null字符结尾 cout << buffer; // 输出HTTP请求 } close(td->sockfd); // 关闭socket连接 delete td; // 释放线程数据占用的内存 return nullptr; // 线程结束 } // 析构函数,用于清理资源(但在这个例子中,没有特别的资源需要清理) ~HttpServer() { } private: Sock _listensockfd; // 监听socket对象 uint16_t _port; // 服务器监听的端口号
}; 然后我们通过主函数给我们的服务器传入端口号,就可以正常启动我们的服务器了:
#include "HttpServer.hpp"
#include <iostream>
#include <memory>
#include <pthread.h>using namespace std;int main(int argc, char *argv[])
{if(argc != 2){exit(1);}uint16_t port = std::stoi(argv[1]);std::unique_ptr<HttpServer> svr(new HttpServer(port));svr->Start();return 0;
}2.8.2 见见简单的HTTP响应
概念:
实现一个最简单的HTTP服务器,只在网页上输出 "hello world",只要我们按照HTTP协议的要求构造数据,就很容易能做到。
HTTPserver.hpp:
#pragma once#include <iostream>
#include <string>
#include <pthread.h>
#include <sys/types.h>
#include <sys/socket.h>
#include"Socket.hpp"using namespace std;static const uint16_t defaultport = 8877;class HttpServer;//声明class ThreadData//传给线程的数据
{
public:ThreadData(int fd): _sockfd(fd){}public:int _sockfd;
};class HttpServer
{
public:HttpServer(uint16_t port = defaultport): _port(port){}bool Start(){_listensockfd.Socket();_listensockfd.Bind(_port);_listensockfd.Listen();for (;;){//获取用户信息string clientip;uint16_t clientport;//两个都是输出型参数//注意Accept成员函数会返回一个新的套接字,专门用于发送信息的int sockfd = _listensockfd.Accept(&clientip, &clientport);//这里获取了客户端IP和端口号if(sockfd < 0) continue;std::cout<<"get a new connect, sockfd:"<<sockfd<<std::endl;//下面使用多线程来和用户端进行通信pthread_t tid; ThreadData *td = new ThreadData(sockfd);pthread_create(&tid, nullptr, ThreadRun, td);}return true;}static void HandlerHttp(int sockfd){char buffer[10240];ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);//注意这里我们不用read了,而是使用recv函数,这个和read非常类似,第3个参数为0的时候,功能和read一模一样if (n > 0)//读取成功{buffer[n] = 0;cout << buffer; // 输出HTTP请求// 返回响应的过程,这里需要返回一个HTTP响应协议string text = "hello world";//HTTP协议有效载荷string response_line = "HTTP/1.0 200 OK\r\n";//HTTP响应协议的第一行的版本号 状态码 状态码描述string response_header = "Content-Length: ";//HTTP报头的最后一行需要记录有效载荷的大小response_header += to_string(text.size()); // 11response_header += "\r\n";//结束这一行string block_line = "\r\n";//这一行是空行,用来区分协议报头和有效载荷string response = response_line;response += response_header;response += block_line;response += text;//response 最终就是"HTTP/1.0 200 OK\r\nContent-Length: 11\r\n\r\nhello world"send(sockfd, response.c_str(), response.size(), 0);//注意这里不用write了,//send前几个参数和write基本一样,当send第4个为0的时候功能和write一模一样}close(sockfd);}static void *ThreadRun(void *args){pthread_detach(pthread_self());//分离线程ThreadData *td = static_cast<ThreadData *>(args);HandlerHttp(td->_sockfd);//执行http的任务delete td;return nullptr;}~HttpServer(){}private:Sock _listensockfd;//用于监听的uint16_t _port;//用于发送消息的
};HTTPserver.cc:
#include"HTTPserver.hpp"
#include <iostream>
#include <string>
#include <memory>int main()
{unique_ptr<HttpServer> psvr (new HttpServer());psvr->Start();return 0;
}makefile:
HttpServer : HTTPserver.ccg++ -o $@ $^ -std=c++11 -lpthread.PHONY:clean
clean:rm -rf HttpServer2.8.3 完整型代码
- 我们需要让他可以动态存储
- 我们需要让他可以实现网页的刷新
HttpServer.hpp测试版:
#pragma once#include <iostream>
#include <string>
#include <pthread.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <fstream>
#include <sstream>
#include <vector>
#include "Socket.hpp"using namespace std;static const uint16_t defaultport = 8877;
const string wwwroot = "./wwwroot"; // web 根目录
const string homepath = "/index.html";
const std::string sep = "\r\n";class HttpRequest
{
public:// 反序列化函数,用于将字符串格式的HTTP请求分解为请求头和请求体void Deserialize(std::string req){// 假设sep是一个成员变量,用于分隔请求头和请求体,但在此代码段中未定义// 这里应该是用于分割请求头中每一行的分隔符,例如"\r\n"// while循环用于遍历字符串,直到找不到分隔符while (true){// 在请求字符串中查找分隔符\r\n的位置size_t pos = req.find(sep);// 如果没有找到分隔符\r\n,则退出循环if (pos == string::npos)break;// 截取从开头到分隔符\r\n之前的字符串作为请求头的一部分string temp = req.substr(0, pos);// 如果截取的字符串为空,则也退出循环(这通常是不必要的,因为find不会返回0位置除非是空字符串)if (temp.empty())break;// 将截取的字符串添加到请求头向量中req_header.push_back(temp);// 从请求字符串中移除已经处理的部分,包括分隔符req.erase(0, pos + sep.size());}// 剩下的字符串(如果有的话)被认为是请求正文text = req;}// 解析函数,用于解析请求行的第一部分(通常是HTTP方法、URL和HTTP版本)void Parse(){// 使用stringstream和字符串流输入操作符来解析请求行的第一个元素std::stringstream ss(req_header[0]); // 将第一行交给ss// 将请求行解析为HTTP方法、URL和HTTP版本ss >> method >> url >> http_version; // gei第一个单词会给method,第二个会给url,第3个会给http_versionfile_path=wwwroot;//./wwwrootif(url=="/" || url=="/index.html"){file_path+=homepath;// ./wwwroot/index.html}else{file_path+=url;//./wwwroot/url} }// 调试打印函数,用于输出请求的所有信息void DebugPrint(){// 遍历请求头,并打印每一行for (auto &line : req_header){std::cout << "--------------------------------" << std::endl;std::cout << line << "\n\n";}// 打印解析后的HTTP方法、URL和HTTP版本std::cout << "method: " << method << std::endl;std::cout << "url: " << url << std::endl;std::cout << "http_version: " << http_version << std::endl;std::cout << "file_path: " << file_path << std::endl;// 打印请求正文std::cout << text << std::endl;}public:std::vector<std::string> req_header; // 用于存储请求头的字符串向量std::string text; // 用于存储请求正文的字符串std::string file_path;//用于存储转换后的文件地址 // 解析请求行之后得到的结果std::string method; // HTTP方法,如GET、POSTstd::string url; // 请求的URLstd::string http_version; // HTTP的版本号,如HTTP/1.1
};class HttpServer; // 声明class ThreadData // 传给线程的数据
{
public:ThreadData(int fd): _sockfd(fd){}public:int _sockfd;
};class HttpServer
{
public:HttpServer(uint16_t port = defaultport): _port(port){}bool Start(){_listensockfd.Socket();_listensockfd.Bind(_port);_listensockfd.Listen();for (;;){// 获取用户信息string clientip;uint16_t clientport;// 两个都是输出型参数// 注意Accept成员函数会返回一个新的套接字,专门用于发送信息的int sockfd = _listensockfd.Accept(&clientip, &clientport); // 这里获取了客户端IP和端口号if (sockfd < 0)continue;std::cout << "get a new connect, sockfd:" << sockfd << std::endl;// 下面使用多线程来和用户端进行通信pthread_t tid;ThreadData *td = new ThreadData(sockfd);pthread_create(&tid, nullptr, ThreadRun, td);}return true;}static string ReadHtmlContent(const string &htmlpath) // 读html文件,将它的内容存到content{// 坑ifstream in(htmlpath);if (!in.is_open())return "404";string content;string line;while (getline(in, line)){content += line;}in.close();return content;}static void HandlerHttp(int sockfd){char buffer[10240];ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);// 注意这里我们不用read了,而是使用recv函数,这个和read非常类似,第3个参数为0的时候,功能和read一模一样if (n > 0) // 读取成功{buffer[n] = 0;cout << buffer; // 输出HTTP请求// 这里是巨大变化HttpRequest req;req.Deserialize(buffer);req.Parse();req.DebugPrint();// 返回响应的过程,这里需要返回一个HTTP响应协议string text = ReadHtmlContent(req.file_path);//HTTP协议有效载荷——这里是一个简单的网页,这个网页放在req.file_pathstring response_line = "HTTP/1.0 200 OK\r\n";//HTTP响应协议的第一行的版本号 状态码 状态码描述string response_header = "Content-Length: ";//HTTP报头的最后一行需要记录有效载荷的大小response_header += to_string(text.size()); // 11response_header += "\r\n";//结束这一行string block_line = "\r\n";//这一行是空行,用来区分协议报头和有效载荷string response = response_line;response += response_header;response += block_line;response += text;//response 最终就是"HTTP/1.0 200 OK\r\nContent-Length: 11\r\n\r\nhello world"send(sockfd, response.c_str(), response.size(), 0);//注意这里不用write了,//send前几个参数和write基本一样,当send第4个为0的时候功能和write一模一样}close(sockfd);}static void *ThreadRun(void *args){pthread_detach(pthread_self()); // 分离线程ThreadData *td = static_cast<ThreadData *>(args);HandlerHttp(td->_sockfd); // 执行http的任务delete td;return nullptr;}~HttpServer(){}private:Sock _listensockfd; // 用于监听的uint16_t _port; // 用于发送消息的
};index2.html 跳转外部网页版:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title>
</head>
<body><h1>这个是我们的尾页</h1><a href="https://www.baidu.com/">百度官网</a>
</body>
</html>三、结束语
今天内容就到这里啦,时间过得很快,大家沉下心来好好学习,会有一定的收获的,大家多多坚持,嘻嘻,成功路上注定孤独,因为坚持的人不多。那请大家举起自己的小手给博主一键三连,有你们的支持是我最大的动力💞💞💞,回见。

相关文章:
【网络】应用层——HTTP协议
> 作者:დ旧言~ > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:了解什么是HTTP协议。 > 毒鸡汤:有些事情,总是不明白,所以我不会坚持。早安! > 专栏选自:网络 &g…...

ServletContext介绍
文章目录 1、ServletContext对象介绍1_方法介绍2_用例分析 2、ServletContainerInitializer1_整体结构2_工作原理3_使用案例 3、Spring案例源码分析1_注册DispatcherServlet2_注册配置类3_SpringServletContainerInitializer 4_总结 ServletContext 表示上下文对象,…...
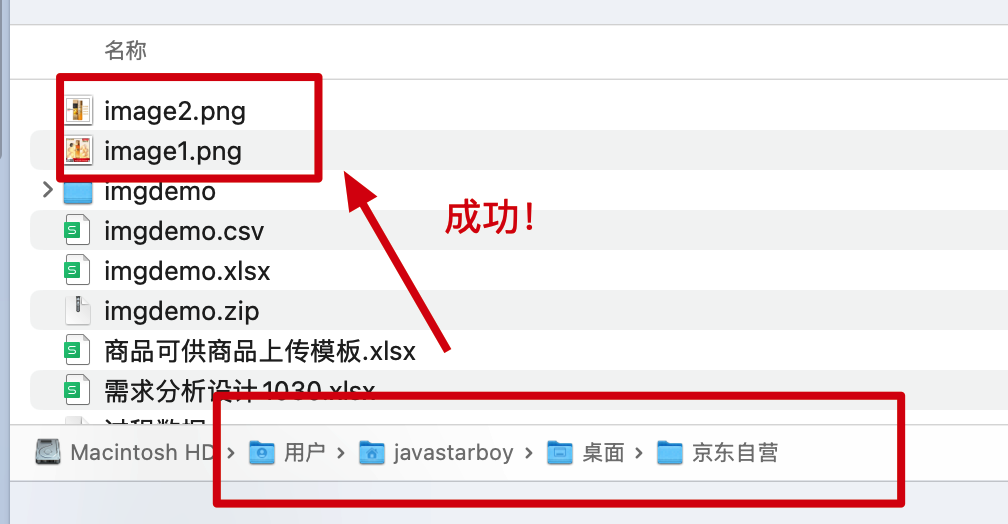
让AI帮我用java实现EasyExel读取图片—支持WPS嵌入图片
🌈 场景概述 java 小伙伴相信都使用 EasyExcel 以及 POI 库实现过 Excel 批量导入、导出功能,但只有部分人实现过 excel 导入带图片数据的场景。这个技术实现手段网上也有很多案例和demo,最常见的就是通过 XSSFPictureData 来实现。但是在 W…...

C# 实现对指定句柄的窗口进行键盘输入的实现
在C#中实现对指定句柄的窗口进行键盘操作,可以通过多种方式来实现。以下是一篇详细的指南,介绍如何在C#中实现这一功能。 1. 使用Windows API函数 在C#中,我们可以通过P/Invoke调用Windows API来实现对指定窗口的键盘操作。以下是一些关键的…...

深度学习之卷积问题
1 卷积在图像中有什么直观作用 在卷积神经网络中,卷积常用来提取图像的特征,但不同层次的卷积操作提取到的特征类型是不相同的,特征类型粗分如表1所示。 表1 卷积提取的特征类型 卷积层次特征类型浅层卷积边缘特征中层卷积局部特征深…...

yum安装zabbix5.0升级php到74的办法
【背景】 公司时不时有扫描漏洞,之前发现了php漏洞,因开启防火墙,限定IP+端口,暂时躲过升级;现在,老话重提,开启了KPI考核,躲是躲不过去的了,升级吧 【难题】 服务器为centos7,因操作系统问题,只能安装zabbix5.0。当时图省力,官网的办法,都是yum安装,很是简便。…...
JavaWeb合集23-文件上传
二十三 、 文件上传 实现效果:用户点击上传按钮、选择上传的头像,确定自动上传,将上传的文件保存到指定的目录中,并重新命名,生成访问链接,返回给前端进行回显。 1、前端实现 vue3AntDesignVue实现 <tem…...

当AI遇上时尚:未来的衣橱会由机器人来打理吗?
内容概要 在当今这个快速发展的时代,人工智能与时尚的结合正在逐渐改写我们对衣橱管理的认知。传统的衣橱管理常常面临着空间不足、穿搭单调及库存过多等挑战,许多人在挑选服饰时难以做出决策。然而,随着技术的进步,智能推荐和自…...

【初阶数据结构篇】二叉树OJ题
文章目录 须知 💬 欢迎讨论:如果你在学习过程中有任何问题或想法,欢迎在评论区留言,我们一起交流学习。你的支持是我继续创作的动力! 👍 点赞、收藏与分享:觉得这篇文章对你有帮助吗࿱…...

Windows系统中Oracle VM VirtualBox的安装
一.背景 公司安排了师带徒,环境搭建问题一直是初级程序员头疼的事情,我记录一下这些基础的内容,方便初学者。大部分开发者的机器还是windows系统,所以写了怎么安装。 二.版本信息及 操作系统:windows11 家庭版…...
)
go语言使用总结(持续更新)
整理后的内容如下: 1. 先了解函数签名,再了解传入参数以及调用 函数签名是函数的声明部分,包括函数名、参数列表和返回值列表。理解函数签名是理解函数行为的第一步,尤其是在了解参数类型、参数数量和返回值类型等方面。通过了解…...

如何在Android中自定义property
在Android中创建自定义的属性(Android property)通常用于调试、性能调优或传递应用和系统之间的信息。 以下是如何在Android中创建和使用自定义属性的步骤: 1. 定义属性 在Android中,属性是以“属性名称属性值”形式定义的键值对…...
机器学习5_支持向量机_原问题和对偶问题——MOOC
目录 原问题与对偶问题的定义 定义该原问题的对偶问题如下 在定义了函数 的基础上,对偶问题如下: 综合原问题和对偶问题的定义得到: 定理一 对偶差距(Duality Gap) 强对偶定理(Strong Duality Theo…...

索引的细节
目录 什么是线性 搜索算法? 算法:二进制搜索算法 二进制搜索如何工作? 什么是二叉排序树? 构建二叉排序树 什么是AVL树? AVL树的性能分析 什么是线性 搜索算法? 线性搜索是一种非常简单的搜索算法。在…...

LeetCode 540.有序数组中的单一元素
思路一:hash,键存入元素,值存入次数,然后遍历,不是最优解 思路二:二分查找 假设数组为 [1, 1, 2, 2, 3, 4, 4],其中唯一出现一次的元素是 3。在一个有序数组中,如果没有唯一的元素&…...

【图文】【DIY便签】如何自行编译OPENCV使用动态库
1 去官网下载安装包和源码 下面红色圈中的是源码,绿色圈中的是安装包: 2 配置工具链 安装过程不说了,教程到处都是。编译的话使用CMAKE,配置如下: 上面两个路径分别是: 源码目录编译生成的文件放置的位…...

WordPress文章自动提交Bing搜索引擎:PHP推送脚本教程
随着网站SEO优化的重要性日益增加,将新发布的内容快速提交到搜索引擎显得尤为重要。尤其对于Bing站长平台,自动化推送能让Bing尽快发现和索引我们网站的新内容。本文将详细介绍如何通过PHP脚本自动推送WordPress当天发布的文章至Bing站长平台,确保新文章被Bing及时收录。 前…...

C++题目分享
嗨嗨嗨,我又来更新这个系列了,很久没更新了。让我们看一看有那些有趣的题目: 题目一: 1.以单链表作为存储结构,实现线性表的就地逆置(提示,就地逆置:在不使用额外的数据结构或空间…...
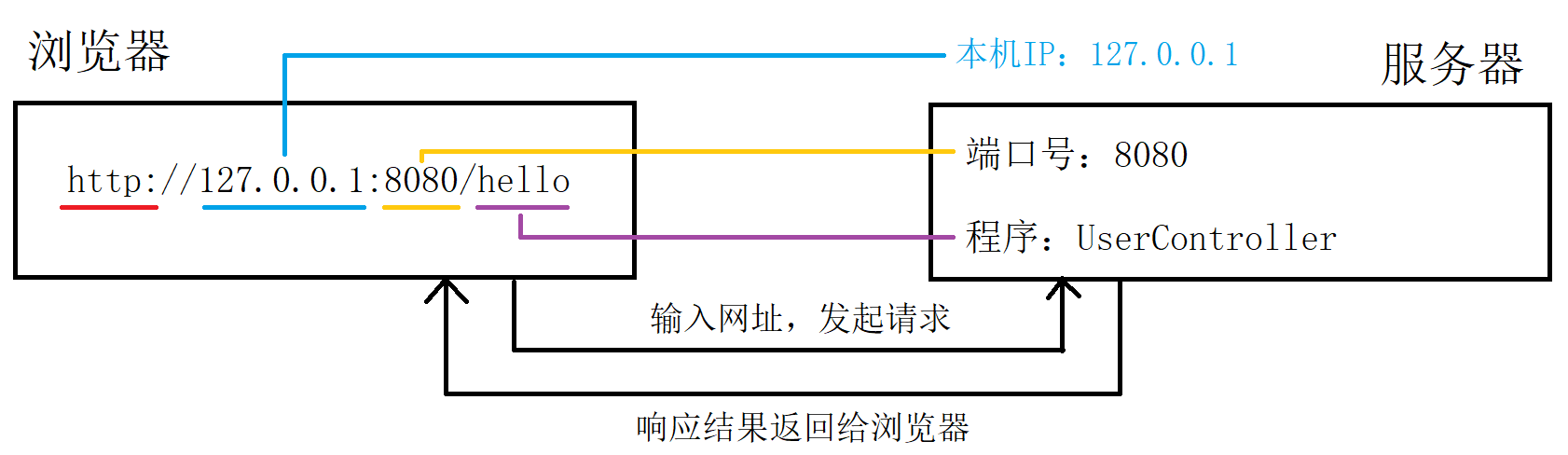
【Spring 框架】初识 Spring
文章目录 前言1. 什么是 Spring2. 什么是 Maven3. 第一个 SpringBoot 项目4. 项目讲解结语 前言 在前面我们一起学习了 JavaSE 的基础知识,随着学习的深入,我们也将逐步介绍 JavaEE 的内容,像 Spring 框架,Mybatis 等等。在本篇博…...

链表(Linkedlist)
序言 我们都了解链表是一种数据的存储结构,在Java使用中逻辑与c,c语言数据结构别无二致,但主要由于Java中不存在指针的说法,从而导致在实现过程中的代码不同,所以在学习的过程中我们无需过于担心,逻辑都是…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...