Python爬虫基础-正则表达式!

前言
正则表达式是对字符串的一种逻辑公式,用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则的字符串”,此字符串用来表示对字符串的一种“过滤”逻辑。正在在很多开发语言中都存在,而非python独有。对其知识点进行总结后,会写一个demo。
1.正则表达式
python是自1.5开始引进re模块进行处理正则的。我先把正则的匹配规则总结一下,再总结re模块相应的方法。
1.1匹配规则
| 语法 | 解释 | 表达式 | 成功匹配对象 |
|---|---|---|---|
| 一般字符 | 匹配自身相对应的字符 | abc | abc |
| . | 匹配除换行符(\n)以外的任意字符 | a.c | abc |
| \ | 转义字符,可以改变原字符的意思 | a.c | a.c |
| \d | 匹配数字:0~9 | \dabc | 1abc |
| \w | 匹配单词字符,az;AZ;0~9 | \w\w\w | oX2 |
| \s | 匹配空格字符(\t,\n,\r,\f,\v) | a\sc | a c |
| \D | 匹配非数字字符 | \Dabc | aabc |
| \W | 匹配非单词字符 | a\Wc | a c |
| \S | 匹配非空格字符 | \S\Sc | 1bc |
| [] | 字符集,对应位置上可以是字符集里的任意字符 | a[def]c | aec |
| [^] | 对字符集当中的内容进行取反 | a[^def]c | a2c |
| [a-z] | 指定一个范围字符集 | a[A-Z]c | aBc |
| * | 允许前一个字符可以出现0次或者无限次 | a*b | aaab或b |
| + | 前一个字符至少出现1次 | a+b | aaab或ab |
| ? | 前一个字符只能出现一次或者不出现 | a?b | ab或b |
| {m} | 允许前一个字符只能出现m次 | a{3}b | aaab |
| {m,n} | 允许前一个字符至少出现m次,最多出现n次(如果不写n,则代表至少出现m次) | a{3,5}b和a{3,} | aaaab和aaaaaab |
| ^ | 匹配字符串的开始,多行内容时匹配每一行的开始 | ^abc | abc |
| $ | 匹配字符串的结尾,多行内容时匹配每一行的结尾 | abc& | abc |
| \A | 匹配字符串开始位置,忽略多行模式 | \Aabc | abc |
| \Z | 匹配字符串结束位置,忽略多行模式 | abc\Z | abc |
| \b | 匹配位于单词开始或结束位置的空字符串 | hello \bworld | hello world |
| \B | 匹配不位于单词开始或结束位置的空字符串 | he\Bllo | hello |
| 表示左右表达式任意满足一种即可 | abc | ||
| (…) | 将被括起来的表达式作为一个分组,可以使用索引单独取出 | (abc)d | abcd |
| (?P…) | 为该分组起一个名字,可以用索引或名字去除该分组 | (?Pabc)d | abcd |
| \number | 引用索引为number中的内容 | (abc)d\1 | abcdabc |
| (?P=name) | 引用该name分组中的内容 | (?Pabc)d(?P=id) | abcdabc |
| (?:…) | 分组的不捕获模式,计算索引时会跳过这个分组 | (?:a)b©d\1 | abcdc |
| (?iLmsux) | 分组中可以设置模式,iLmsux之中的每个字符代表一个模式 | (?i)abc | Abc |
| (?#…) | 注释,#后面的内容会被忽略 | ab(?#注释)123 | ab123 |
| (?=…) | 顺序肯定环视,表示所在位置右侧能够匹配括号内正则 | a(?=\d) | a1最后的结果得到a |
| (?!…) | 顺序否定环视,表示所在位置右侧不能匹配括号内正则 | a(?!\w) | a c最后的结果得到a |
| (?<=…) | 逆序肯定环视,表示所在位置左侧能够匹配括号内正则 | 1(?<=\w)a | 1a |
| (?<!…) | 逆序否定环视,表示所在位置左侧不能匹配括号内正则 | 1 (?<!\w)a | 1 a |
| (?(id/name)yes | no) | 如果前面的索引为id或者名字为name的分组匹配成功则匹配yes区域的表达式,否则匹配no区域的表达式,no可以省略 | (\d)(?(1)\d |
上面表格中(?iLmsux)这里的”i”, “L”, “m”, “s”, “u”, “x”,它们不匹配任何字串,而对应re模块中(re.S|re.S):
I:re.I# 忽略大小写
L:re.L# 字符集本地化,为了支持多语言版本的字符集使用环境
U :re.U# 使用\\w,\\W,\\b,\\B这些元字符时将按照UNICODE定义的属性
M:re.M # 多行模式,改变 ^ 和 $ 的行为
S:re.S # '.' 的匹配不受限制,包括换行符
X:re.X # 冗余模式,可以忽略正则表达式中的空白和#号的注释
对于一个特殊字符在正则表达式中是不能正常识别的,如果接触过其他语言我们就这到有一个叫做转移字符的东西的存在,在特殊字符前加用反斜杠接口。比如\n换行\\为反斜杠,在这不再累述。下面来介绍一下re这个模块。
1.2.re模块
此模块主要方法如下
re.match()#尝试从字符串的起始位置匹配一个模式(pattern),如果不是起始位置匹配成功的话,match()就返回None
re.search()#函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None。
re.findall()#遍历匹配,可以获取字符串中所有匹配的字符串,返回一个列表。
re.compile()#编译正则表达式模式,返回一个对象的模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样可以提高一点效率。)
re.sub()#使用re替换string中每一个匹配的子串后返回替换后的字符串。
re.subn()#返回替换次数
re.split()#按照能够匹配的子串将string分割后返回列表。
1.2.1.re.match()
方法: re.match(pattern, string, flags=0)#pattern:正则表达式(或者正则表达式对象)string:要匹配的字符串flags:修饰符
先看一个最简单的用法
import re
content \='Hello 123 4567 wangyanling REDome'
print(len(content))
result \= re.match('^Hello\\s\\d\\d\\d\\s\\d{4}\\s\\w{10}.\*Dome$', content)
print(result)
print(result.group())
print(result.span())
结果:

匹配规则就不在累述,以上需要注意的是
(1)**.group()**表示的是返回正则匹配的结果
(2)**.span()**表示返回正则匹配的范围
使用:
以上我们已经知道re.matcha()的具体方法,那么接下我来看一下具体使用,对此我们要理解以下几种匹配的感念。
1.泛匹配(.*):匹配所有字符
import re
content \='Hello 123 4567 wangyanling REDome'
result \= re.match('^Hello.\*Dome$', content)
print(result)
print(result.group())
print(result.span())
它的结果是和上面的输出结果完全一样的。
2.目标匹配(()):将需要的字符匹配出来
import re
content \='Hello 123 4567 wangyanling REDome'
result \= re.match('^Hello\\s\\d\\d(\\d)\\s\\d{4}\\s\\w{10}.\*Dome$', content)
print(result)
print(result.group(1))
import re
content \='Hello 123 4567 wangyanling REDome'
result \= re.match('^Hello\\s(\\d+)\\s\\d{4}\\s\\w{10}.\*Dome$', content)
print(result)
print(result.group(1))
结果

以上可以看出:
(1)_()_匹配括号内的表达式,也表示一个组
(2)+ 匹配1个或多个的表达式
* 匹配0个或多个的表达式
(3).group(1)—输出第一个带有()的目标
3.贪婪匹配(.*()):匹配尽可能少的的结果
import re
content \='Hello 123 4567 wangyanling REDome'
result \= re.match('^H.\*(\\d+).\*Dome$', content)
print(result)
print(result.group(1))
结果

**4.贪婪匹配(.\*?()):匹配尽可能多的结果**
import re
content \='Hello 123 4567 wangyanling REDome'
result \= re.match('^H.\*?(\\d+).\*?Dome$', content)
print(result)
print(result.group(1))
结果

以上3,4两个匹配方式请尽量采用非贪婪匹配
**5.其他**
换行:
import re
content \='''Hello 123 4567 wangyanling REDome'''result \= re.match('^H.\*?(\\d+).\*?Dome$', content,re.S)#re.S
print(result.group(1))
result \= re.match('^H.\*?(\\d+).\*?Dome$', content)
print(result.group(1))
结果:

转义字符:
import re
content \= 'price is $5.00'
result \= re.match('price is $5.00', content)
print(result)
result \= re.match('price is \\$5\\.00', content)
print(result)
结果:

其中re.I使匹配对大小不敏感,re.S匹配包括换行符在内的所有字符,\进行处理转义字符。匹配规则中有详细介绍。
1.2.2.re.search()
方法:
re.search(pattern, string, flags=0)#pattern:正则表达式(或者正则表达式对象)string:要匹配的字符串flags:修饰符#re.match()和re.search()用法类似唯一的区别在于re.match()从字符串头开始匹配,若头匹配不成功,则返回None
对比一下与match()
import re
content \='Hello 123 4567 wangyanling REDome'
result \= re.match('(\\d+)\\s\\d{4}\\s\\w{10}.\*Dome$', content)
print(result)#从开头开始查找,不能匹配返回None
result = re.search('(\\d+)\\s\\d{4}\\s\\w{10}.\*Dome$', content)
print(result)
print(result.group())
结果:

可以看出两个使用基本一致,search从头开始匹配,如果匹配不到就返回none.
1.2.3.re.findall()
方法: re.finditer(pattern, string, flags=0)#pattern:正则表达式(或者正则表达式对象)string:要匹配的字符串flags:修饰符
与re.search()类似区别在于re.findall()搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。找到 RE 匹配的所有子串,并把它们作为一个迭代器返回。
import rehtml \= '''<div><li><a href="" singer="鲁迅"\>呐喊</a></li><li><a href="#" singer="贾平凹"\>废都</a></li><li class\="active"\><a href="#" singer="路遥"\>平凡世界</a></li><span class\="rightSpan"\>谢谢支持</span></div>
'''
regex\_4='<a.\*?>(.\*?)</a>'
results\=re.findall(regex\_4,html,re.S)
print(results)
for result in results:print(result)
结果:

1.2.4.re.compile()
编译正则表达式模式,返回一个对象的模式。
方法: re.compile(pattern,flags=0)#pattern:正则表达式(或者正则表达式对象);flags:修饰符
看一个demo
import re
content \='Hello 123 4567 wangyanling REDome wangyanling 那小子很帅'
rr \= re.compile(r'\\w\*wang\\w\*')
result \=rr.findall(content)
print(result)
结果:

我们可以看出compile 我们可以把它理解为封装了一个公用的正则,类似于方法,然后功用。
1.2.5.其他
re.sub 替换字符
方法: re.sub(pattern, repl, string, count=0, flags=0)#pattern:正则表达式(或者正则表达式对象)repl:替换的字符串string:要匹配的字符串count:要替换的个数flags:修饰符
re.subn 替换次数
方法: re.subn(pattern, repl, string, count=0, flags=0)#pattern:正则表达式(或者正则表达式对象)repl:替换的字符串string:要匹配的字符串count:要替换的个数flags:修饰符
re.split()分隔字符
方法
re.split(pattern, string,\[maxsplit\])#正则表达式(或者正则表达式对象)string:要匹配的字符串;maxsplit:用于指定最大分割次数,不指定将全部分割
2.案例:爬取猫眼信息,写入txt,csv,下载图片
2.1.获取单页面信息
def get\_one\_page(html):pattern\= re.compile('<dd>.\*?board-index.\*?>(\\d+)</i>.\*?data-src="(.\*?)".\*?name"><a.\*?>(.\*?)</a>.\*?star">(.\*?)</p>.\*?releasetime'+ '.\*?>(.\*?)</p>.\*?score.\*?integer">(.\*?)</i>.\*?>(.\*?)</i>.\*?</dd>',re.S)#这里就用到了我们上述提到的一些知识点,非贪婪匹配,对象匹配,修饰符items = re.findall(pattern,html)for item in items:yield {'rank' :item\[0\],'img': item\[1\],'title':item\[2\],'actor':item\[3\].strip()\[3:\] if len(item\[3\])>3 else '', 'time' :item\[4\].strip()\[5:\] if len(item\[4\])>5 else '','score':item\[5\] + item\[6\]}
对于上面的信息我们可以看出是存到一个对象中那么接下来我们应该把它们存到文件当中去。
2.2.保存文件
我写了两种方式保存到txt和csv这些在python都有涉及,不懂得可以去翻看一下。
2.2.1.保存到txt
def write\_txtfile(content):with open("Maoyan.txt",'a',encoding='utf-8') as f:#要引入json,利用json.dumps()方法将字典序列化,存入中文要把ensure\_ascii编码方式关掉f.write(json.dumps(content,ensure\_ascii=False) + "\\n")f.close()
结果:
以上看到并非按顺序排列因为我用的是多线程。
2.2.2.保存到csv
def write\_csvRows(content,fieldnames):'''写入csv文件内容'''with open("Maoyao.csv",'a',encoding='gb18030',newline='') as f:#将字段名传给Dictwriter来初始化一个字典写入对象writer = csv.DictWriter(f,fieldnames=fieldnames)#调用writeheader方法写入字段名writer.writerows(content)f.close()
结果:
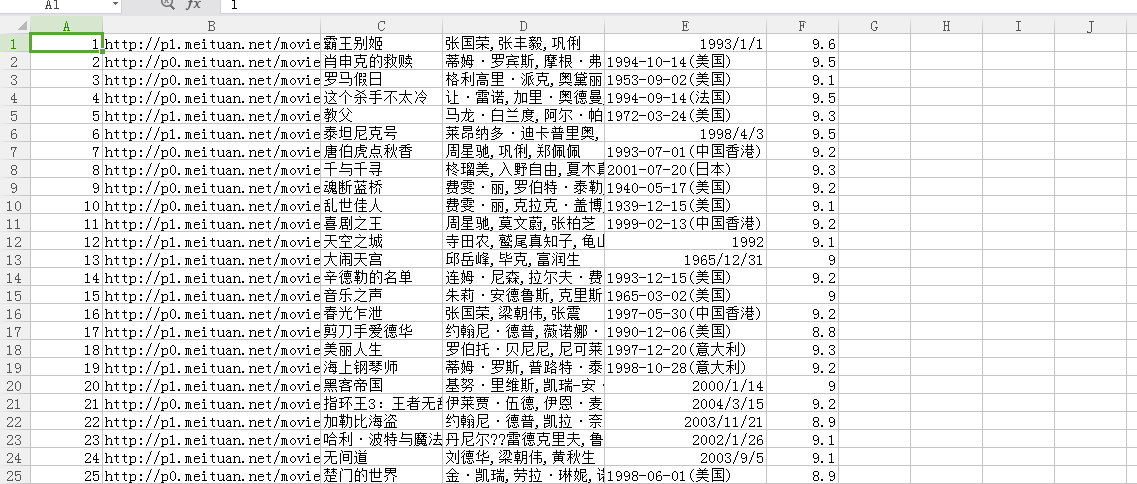
那么还有一部就是我们要把图片下载下来。
2.2.3.下载图片
def download\_img(title,url):r\=requests.get(url)with open(title+".jpg",'wb') as f:f.write(r.content)
2.3.整体代码
这里面又到了多线程在这不在叙述后面会有相关介绍。这个demo仅做一案例,主要是对正则能有个认知。上面写的知识点有不足的地方望大家多多指教。
#抓取猫眼电影TOP100榜
from multiprocessing import Pool
from requests.exceptions import RequestException
import requests
import json
import time
import csv
import re
def get\_one\_page(url):'''获取单页源码'''try:headers \= {"User-Agent":"Mozilla/5.0(WindowsNT6.3;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/68.0.3440.106Safari/537.36"}res \= requests.get(url, headers=headers)# 判断响应是否成功,若成功打印响应内容,否则返回Noneif res.status\_code == 200:return res.textreturn Noneexcept RequestException:return None
def parse\_one\_page(html):'''解析单页源码'''pattern \= re.compile('<dd>.\*?board-index.\*?>(\\d+)</i>.\*?data-src="(.\*?)".\*?name"><a.\*?>(.\*?)</a>.\*?star">(.\*?)</p>.\*?releasetime'+ '.\*?>(.\*?)</p>.\*?score.\*?integer">(.\*?)</i>.\*?>(.\*?)</i>.\*?</dd>',re.S)items \= re.findall(pattern,html)#采用遍历的方式提取信息for item in items:yield {'rank' :item\[0\],'img': item\[1\],'title':item\[2\],'actor':item\[3\].strip()\[3:\] if len(item\[3\])>3 else '', #判断是否大于3个字符'time' :item\[4\].strip()\[5:\] if len(item\[4\])>5 else '','score':item\[5\] + item\[6\]}def write\_txtfile(content):with open("Maoyan.txt",'a',encoding='utf-8') as f:#要引入json,利用json.dumps()方法将字典序列化,存入中文要把ensure\_ascii编码方式关掉f.write(json.dumps(content,ensure\_ascii=False) + "\\n")f.close()
def write\_csvRows(content,fieldnames):'''写入csv文件内容'''with open("Maoyao.csv",'a',encoding='gb18030',newline='') as f:#将字段名传给Dictwriter来初始化一个字典写入对象writer = csv.DictWriter(f,fieldnames=fieldnames)#调用writeheader方法写入字段名#writer.writeheader() ###这里写入字段的话会造成在抓取多个时重复.writer.writerows(content)f.close()
def download\_img(title,url):r\=requests.get(url)with open(title+".jpg",'wb') as f:f.write(r.content)
def main(offset):fieldnames \= \["rank","img", "title", "actor", "time", "score"\]url \= "http://maoyan.com/board/4?offset={0}".format(offset)html \= get\_one\_page(url)rows \= \[\]for item in parse\_one\_page(html):#download\_img(item\['rank'\]+item\['title'\],item\['img'\])write\_txtfile(item)rows.append(item)write\_csvRows(rows,fieldnames)if \_\_name\_\_ == '\_\_main\_\_':pool \= Pool()#map方法会把每个元素当做函数的参数,创建一个个进程,在进程池中运行.pool.map(main,\[i\*10 for i in range(10)\])
如果你是准备学习Python或者正在学习(想通过Python兼职),下面这些你应该能用得上: 包括:Python安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
相关文章:
Python爬虫基础-正则表达式!
前言 正则表达式是对字符串的一种逻辑公式,用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则的字符串”,此字符串用来表示对字符串的一种“过滤”逻辑。正在在很多开发语言中都存在,而非python独有。对其知识点…...

Python处理PDF组件使用及注意事项
在 Python 中处理 PDF 文件时, 使用的组件及注意事项如下: 1. PyPDF2 / PyPDF4 说明: PyPDF2 和 PyPDF4 都是功能强大的 PDF 操作库,适用于合并、拆分、旋转 PDF 文件,提取 PDF 元数据等。PyPDF4 是 PyPDF2 的一个分…...

langgraph_plan_and_execute
整体入门demo 教程概览 欢迎来到LangGraph教程! 这些笔记本通过构建各种语言代理和应用程序,介绍了如何使用LangGraph。 快速入门(Quick Start) 快速入门部分通过一个全面的入门教程,帮助您从零开始构建一个代理&a…...

[代码随想录打卡Day8] 344.反转字符串 541. 反转字符串II 54. 替换数字
反转字符串 难度:易。 问题描述:编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。 这个就是开头…...

DCN DCWS-6028神州数码 AC 设备配置笔记
DCN DCWS-6028神州数码 AC 设备配置笔记 一、前期准备 PC 电脑网络配置 目的:使 PC 能够访问 AC 的 web 管理控制台。配置详情:web 管理控制台地址为 192.168.1.10,将 PC 电脑 IP 地址配置在 192.168.1.1 - 192.168.1.254 网段内,如 192.168.1.110,子网掩码 255.255.255.…...

Go语言的常用内置函数
文章目录 一、Strings包字符串处理包定义Strings包的基本用法Strconv包中常用函数 二、Time包三、Math包math包概述使用math包 四、随机数包(rand) 一、Strings包 字符串处理包定义 Strings包简介: 一般编程语言包含的字符串处理库功能区别…...

华为OD技术一面手撕题
150. 逆波兰表达式求值 来自leecode 给你一个字符串数组 tokens ,表示一个根据 逆波兰表示法 表示的算术表达式。 请你计算该表达式。返回一个表示表达式值的整数。 注意: 有效的算符为 、-、* 和 / 。每个操作数(运算对象)都…...

Qt低版本多网卡组播bug
原文地址 最近在某个项目中,发现了一个低版本Qt的bug,导致组播无法正常使用,经过一番排查,终于找到了原因,特此记录。 环境 Qt:5.7.0 mingw32操作系统:windows 11 现象 在Qt5.7.0版本中&…...

Leetcode:540. 有序数组中的单一元素
题目 给你一个仅由整数组成的有序数组,其中每个元素都会出现两次,唯有一个数只会出现一次。 请你找出并返回只出现一次的那个数。 你设计的解决方案必须满足 O(log n) 时间复杂度和 O(1) 空间复杂度。 输入: nums [1,1,2,3,3,4,4,8,8] 输出: 2 输入:…...

Python数据分析NumPy和pandas(二十七、数据可视化 matplotlib API 入门)
数据可视化或者数据绘图是数据分析中最重要的任务之一,是数据探索过程的一部分,数据可视化可以帮助我们识别异常值、识别出需要的数据转换以及为模型生成提供思考依据。对于Web开发人员,构建基于Web的数据可视化显示也是一种重要的方式。Pyth…...

数组指针和指针的区别
区分数组指针和指针数组 int *p[3]和 int (*p)[3] 根据运算符的优先级,"[]"的优先级是高于“*”的,p就会先与[]结合,那么它本质就是数组,数组内存放的是指针,它叫指针数组。(int*p[3]ÿ…...

Linux git-bash配置
参考资料 命令提示符Windows下的Git Bash配置,提升你的终端操作体验WindowsTerminal添加git-bash 目录 一. git-bash配置1.1 解决中文乱码1.2 修改命令提示符 二. WindowsTerminal配置git-bash2.1 添加git-bash到WindowsTerminal2.2 解决删除时窗口闪烁问题 三. VS…...

【后端速成Vue】computed计算属性
前言: 本期将会介绍 Vue 中的计算属性,他和 methods 方法又会有什么区别呢?在这里都会给你一一讲解。 篮球哥找工作专属IT岗位内部推荐: 专属内推链接:内推通道 1、computed计算属性 概念: 基于现有的数据…...

力扣-每日温度
. - 力扣(LeetCode) 这是我的第一个思路 虽然可以得到正确答案 但是过于暴力 已经超出了时间限制 class Solution { public:vector<int> dailyTemperatures(vector<int>& temperatures) {vector<int>ans;for (int i 0; i <…...

(Go语言)初上手Go?本篇文章帮拿捏Go的数据类型!
1. bool 类型 布尔类型:只有 true 和 false 两种值 在Go中,整数 0 不代表 false 值,1也不代表 true 值 即数字无法代替布尔值进行逻辑判断,两者是完全不同的类型 布尔类型占用 1 字节 2. int 整型 Go中为不同位数的整数分配…...

支付宝域名如何加入白名单(扫码老是弹窗)
支付宝扫码之后,遇到非支付宝官方网页,请确认是否继续访问弹窗,问题解决办法。 本章教程提供解决办法,亲测有效。 一、打开支付宝开放平台 登录地址:https://open.alipay.com/ 然后进行扫码登录。 1、打开网页/移动应用开发 2、前往创建 3、创建应用...

嵌入式学习第21天Linux基础
目录 第1章 Linux 系统介绍 1.1 Unix 操作系统(了解) 1.2 Linux 操作系统(了解) 1.3 Linux 操作系统的主要特性(重点) 1.4 Linux 与 Unix 的区别与联系 1.5 GUN 与 GPL(了解) …...

【activiti工作流源码集成】springboot+activiti+mysql+vue+redis工作流审批流集成整合业务绑定表单流程图会签驳回
工作流集成实际项目案例,demo提供 源码获取方式:本文末个人名片直接获取。 前言 activiti工作流引擎项目,企业erp、oa、hr、crm等企事业办公系统轻松落地,请假审批demo从流程绘制到审批结束实例。 一、项目形式 springbootvue…...

华为私有接口类型hybrid
华为私有接口类型hybrid Tip:hybrid类型,简称混合型接口。 本次实验模拟2层网络下 vlan10 vlan20 不能互访,vlan10 vlan20 同时可以访问vlan100 sw1配置如下: <Huawei>sy [Huawei]sys sw1 [sw1]vl ba 10 20 100 [sw1]int…...

计算机的错误计算(一百五十)
摘要 探讨 MATLAB 中 的计算精度问题。当 为含有小数的大数或 ()附近数时,输出会有错误数字。 例1. 已知 计算 直接贴图吧: 另外,16位的正确值分别为 -0.7882256119904400e0、0.1702266977524110e0、-0.…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...