Knowledge Graph-Enhanced Large Language Models via Path Selection
研究背景
- 研究问题:这篇文章要解决的问题是大型语言模型(LLMs)在生成输出时存在的事实不准确性,即所谓的幻觉问题。尽管LLMs在各种实际应用中表现出色,但当遇到超出训练语料库范围的新知识时,它们通常会生成不准确的信息。
- 研究难点:该问题的研究难点包括:现有的方法主要依赖LLMs自身进行知识图谱(KG)知识提取,这种方法的灵活性较差,因为LLMs只能对知识(例如KG中的知识路径)是否应该使用提供二元判断。此外,LLMs倾向于仅选择与输入文本有直接语义关系的知识,而可能会忽略具有间接语义关系的有用知识。
- 相关工作:为了解决这一问题,已有研究提出了在训练阶段或推理阶段将新知识整合到LLMs中的方法。然而,这些方法通常需要大量的计算资源。最近的研究表明,通过提示工程将新知识与输入文本一起引入是一种高效的方法。
研究方法
这篇论文提出了一个名为KELP(Knowledge Graph-Enhanced Large Language Models via Path Selection)的新方法,用于解决LLMs在生成输出时的事实不准确性。具体来说,KELP通过以下三个阶段的框架来处理上述问题:
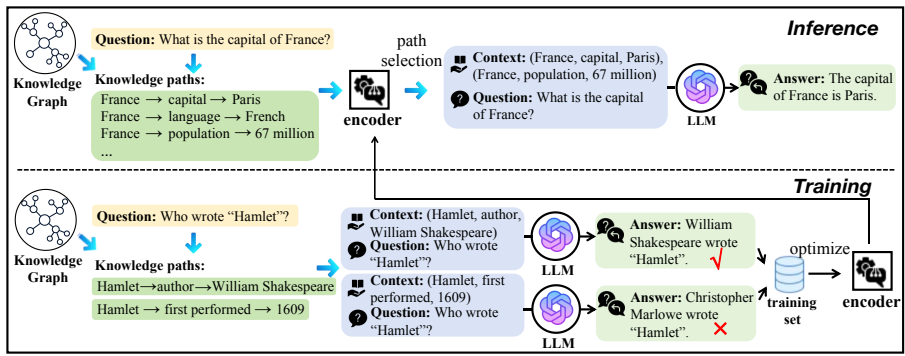
- 知识路径提取:首先,从背景KG中提取与输入文本中的实体相关的知识路径。对于每个实体,提取所有1跳和2跳的知识路径作为候选知识。
- 样本编码:其次,使用一个在潜在语义空间上训练的句子编码器M对输入问题q和提取的知识路径进行编码,以获得它们的距离(即路径对LLMs输出的潜在影响),从而确保捕捉到路径中有潜在影响力的知识。
- 细粒度路径选择:最后,基于余弦相似度分数引入两个覆盖规则,进一步细化所选路径,以确保选择的路径具有高灵活性。具体步骤如下:
- 将所有实体的路径集聚合成一个总路径集PqPq。
- 对于每个共享特定三元组的路径子集Pq(h,r,t)Pq(h,r,t),选择得分最高的k1k1条路径。
- 通过另一个规则限制不同共享三元组的数量,确保所选路径的多样性。
- 设置一个阈值γγ,过滤掉低相似度的路径,最终得到高相似度的路径集PrPr。
公式解释:
- 知识路径提取公式:
Pe={(e→r→o)∣o∈E,r∈R}∪{(e→r1→o1→r2→o2)∣o1,2∈E,r1,2∈R}Pe={(e→r→o)∣o∈E,r∈R}∪{(e→r1→o1→r2→o2)∣o1,2∈E,r1,2∈R}
- 样本编码公式:
hq=M(q),hp=M(p′)hq=M(q),hp=M(p′)
- 细粒度路径选择公式:
Pq′(h,r,t)=argmaxPq′(h,r,t)∑p∈Pq′(h,r,t)cos(hp,hq)Pq′(h,r,t)=Pq′(h,r,t)argmaxp∈Pq′(h,r,t)∑cos(hp,hq)
实验设计
- 数据集:实验使用了两个不同类型的数据集:强语义知识和弱语义知识。强语义知识任务使用MetaQA数据集,弱语义知识任务使用FACTKG数据集。
- 基线:实验包括与之前研究相同的基线,使用大型语言模型“gpt-3.5-turbo-0613”。
- 实现细节:使用预训练的DistilBert模型作为编码器M,优化器为AdamW,学习率为2×10−62×10−6。在FactKG数据集中,由于实体邻居子图过大,采用关系优先排序策略。
结果与分析
-
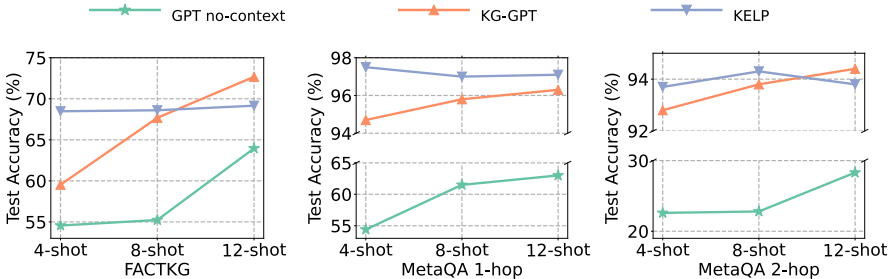
少样本学习设置:在4-shot、8-shot和12-shot配置下,KELP在强语义知识任务中的表现优于基于LLM的证据方法,特别是在12-shot场景中,KELP在1跳强语义知识任务中的检索性能超过了基于LLM的证据方法。
-
全监督模型比较:在少样本学习设置中,KELP的表现超过了一些全监督模型,接近这些模型中的最高准确率基准。
-
敏感性分析:KELP在不同少样本数量下的性能变化不大,特别是在样本数量有限的情况下,KELP表现出稳定性和优越性。
总体结论
这篇论文提出了KELP方法,通过灵活捕捉可能与输入文本无直接语义关系的潜在影响力知识,提高了LLMs生成输出的事实准确性。实验结果表明,KELP在强语义知识和弱语义知识任务中均优于现有的最先进基线方法,特别是在少样本学习场景中表现出显著的优越性。KELP的贡献在于:
- 批判性地研究了提示工程中缺乏灵活性和遗漏潜在影响力知识的挑战。
- 提出了KELP方法,通过训练路径-文本编码器捕捉潜在影响力知识,并通过两个覆盖规则确保知识提取的灵活性。
- 在事实验证和问答数据集上的广泛实验验证了KELP的有效性。
论文评价
优点与创新
- 灵活性:KELP通过潜在语义匹配为知识路径生成分数,实现了更细粒度的灵活知识提取。
- 间接语义关系:KELP不仅考虑与输入文本直接语义相关的知识路径,还能通过训练编码器考虑与输入文本具有间接语义关系的知识路径。
- 覆盖规则:引入了两个覆盖规则,确保知识路径选择的灵活性,从而获取最具代表性和多样性的路径。
- 关系优先排序:在知识路径集非常大的情况下,引入了“仅关系排序”策略,显著减少了需要编码的候选路径数量,提高了匹配效率。
- 实验验证:在事实验证和问答任务的数据集上进行了广泛的实验,证明了KELP的有效性。
- 多跳推理:KELP能够处理多跳推理,展示了其在复杂推理任务中的潜力。
不足与反思
- 数据收集的复杂性:为了训练一个能够捕捉有价值知识上下文的编码器,需要构建一个包含各种数据类型的训练集,这需要大量的手动测试和时间。
- 社会偏见:背景知识图和预训练大型语言模型中可能包含具有社会偏见的原始数据信息,尽管KELP方法仅基于输入文本与知识路径的关系进行选择,但仍需注意潜在的社会影响。
关键问题及回答
问题1:KELP方法在知识路径提取阶段是如何操作的?
在知识路径提取阶段,KELP方法的目标是从背景知识图谱(KG)中识别出对给定输入问题q有价值的知识路径。具体操作如下:
- 对于输入问题q中的每个实体e,提取其知识路径集PePe。这个集合包括所有从实体e出发的1跳和2跳路径。
- 1跳路径的形式为(e→r→o)(e→r→o),其中o是KG中的一个实体,r是关系。
- 2跳路径的形式为(e→r1→o1→r2→o2)(e→r1→o1→r2→o2),其中o1o1和o2o2是KG中的实体,r1r1和r2r2是关系。
这些提取的路径将作为后续样本编码阶段的候选知识路径。
问题2:KELP方法中的样本编码是如何进行的?其目的是什么?
样本编码是KELP方法中的一个关键步骤,旨在通过预训练的句子编码器M对输入问题q和提取的知识路径进行编码,以获得它们的距离(即路径对LLMs输出的潜在影响),从而确保捕捉到路径中有潜在影响的有用知识。具体操作如下:
- 对于每个知识路径,构建一个路径句子。如果路径只包含一个三元组(h,r,t)(h,r,t),则路径句子为"h r t";如果路径包含两个三元组,则路径句子为"h1 r1 t1, h2 r2 t2"。
- 使用编码器M对问题q和路径句子进行编码,得到它们的嵌入表示hqhq和hphp。
- 通过计算hqhq和hphp之间的余弦相似度,量化每条知识路径的有用性。相似度越高,表示该路径对LLM输出的潜在影响越大。
样本编码的目的是确保所选的路径能够有效地捕捉到对LLM生成输出有潜在影响的有用知识,从而提高输出的事实准确性。
问题3:KELP方法中的细粒度路径选择是如何实现的?其优势是什么?
细粒度路径选择是KELP方法中的最后一个阶段,旨在基于余弦相似度分数选择最适合输入问题q的路径作为上下文。具体操作如下:
- 聚合所有实体的路径集PqPq,得到总的路径集。
- 使用覆盖规则选择得分最高的路径子集Pq′(h,r,t)Pq′(h,r,t),公式如下:
Pq′(h,r,t)=argmaxPq′(h,r,t)∑p∈Pq′(h,r,t)cos(hp,hq)Pq′(h,r,t)=Pq′(h,r,t)argmaxp∈Pq′(h,r,t)∑cos(hp,hq)
- 根据另一个规则进一步限制不同共享三元组的数量,公式如下:
T′=argmaxT′∑(h,r,t)∈T′maxp∈Pq′(h,r,t)cos(hp,hq)T′=T′argmax(h,r,t)∈T′∑p∈Pq′(h,r,t)maxcos(hp,hq)
- 设置阈值γγ,过滤掉低相似度的路径,公式如下:
γ=min(h,r,t)∈T′maxp∈Pq′(h,r,t)cos(hp,hq)γ=(h,r,t)∈T′minp∈Pq′(h,r,t)maxcos(hp,hq)
- 最终得到高相似度的路径集PrPr,作为提示的上下文。
细粒度路径选择的优势在于其灵活性,能够通过调整覆盖规则和阈值,选择出多样且最具代表性的路径,从而确保所选路径能够有效地捕捉到对LLM生成输出有潜在影响的有用知识。这种方法不仅提高了LLM输出的事实准确性,还增强了模型的泛化能力。
相关文章:
Knowledge Graph-Enhanced Large Language Models via Path Selection
研究背景 研究问题:这篇文章要解决的问题是大型语言模型(LLMs)在生成输出时存在的事实不准确性,即所谓的幻觉问题。尽管LLMs在各种实际应用中表现出色,但当遇到超出训练语料库范围的新知识时,它们通常会生…...

Android 项目模型配置管理
Android 项目配置管理 项目模型相关的配置管理config.gradle文件:build.gradle文件: 参考地址 项目模型相关的配置管理 以下是一个完整的build.gradle和config.gradle示例: config.gradle文件: ext {// 模型相关配置࿰…...

「QT」几何数据类 之 QSizeF 浮点型尺寸类
✨博客主页何曾参静谧的博客📌文章专栏「QT」QT5程序设计📚全部专栏「VS」Visual Studio「C/C」C/C程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「DSA」数据结构与算法「UG/NX」NX二次开发「QT」QT5程序设计「File」数据文件格式「PK」Parasolid…...

Essential Cell Biology--Fifth Edition--Chapter one(2)
1.1.1.3 Living Cells Are Self-Replicating Collections of Catalysts 催化剂集合 生物最常被引用的特性之一是它们的繁殖能力。对于细胞来说,这个过程包括复制它们的遗传物质和其他成分,然后分裂成两个,产生一对子细胞[daughter cells]&a…...
大语言模型LLMs在医学领域的最新进展总结
我是娜姐 迪娜学姐 ,一个SCI医学期刊编辑,探索用AI工具提效论文写作和发表。 相比其他学科,医学AI,是发表学术成果最多的领域。 医学数据的多样性和复杂性(包括文本、图像、基因组数据等),使得…...

云防护单节点2T抗攻击能力意味着什么?
随着互联网的发展,DDoS攻击的规模和频率不断增加,对企业和个人用户的网络服务造成了严重威胁。云防护服务作为一种高效的DDoS防护手段,逐渐成为许多企业的首选。本文将重点讨论云防护单节点2T(太比特每秒)抗攻击能力的…...

IDEA在编译时: java: 找不到符号符号: 变量 log
一、问题 IDEA在编译的时候报Error:(30, 17) java: 找不到符号符号: 变量 log Error:(30, 17) java: 找不到符号 符号: 变量 log 位置: 类 com.mokerson.rabbitmq.config.RabbitMqConfig 二、解决方案 背景:下载其他同事代码时,第一次运行,…...

HTML 基础架构:理解网页的骨架
HTML的文档结构主要由以下几个部分组成:<html>、<head>和<body>。 <html>标签是HTML文档的根元素,用来包裹整个HTML文档的内容。<head>标签用于定义文档的头部,包含了一些元数据和其他不直接显示在页面上的内…...

FPGA学习笔记#5 Vitis HLS For循环的优化(1)
本笔记使用的Vitis HLS版本为2022.2,在windows11下运行,仿真part为xcku15p_CIV-ffva1156-2LV-e,主要根据教程:跟Xilinx SAE 学HLS系列视频讲座-高亚军进行学习 从这一篇开始正式进入HLS对C代码的优化笔记 目录 1.循环优化中的基…...

web实操4——servlet体系结构
servlet体系结构 我们基本都只实现service方法,其余几个都不用, 之前我们直接实现servlet接口,所有的方法都必须实现,不用也得写,不然报错,写了又不用当摆设。 能不能只要定义一个service方法就可以&…...

Linux开发讲课48--- Linux 文件系统概览
本文旨在高屋建瓴地来讨论 Linux 文件系统概念,而不是对某种特定的文件系统,比如 EXT4 是如何工作的进行具体的描述。另外,本文也不是一个文件系统命令的教程。 每台通用计算机都需要将各种数据存储在硬盘驱动器(HDD)…...

Node.js 模块详解
模块的概念 Node.js 运行在 V8 JavaScript 引擎上,通过 require() 函数导入相关模块来处理服务器端的各种进程。一个 Node.js 模块可以是一个函数库、类集合或其他可重用的代码,通常存储在一个或多个 .js 文件中。 例如,启动一个 Node.js 服…...

大厂面试真题-说说tomcat的优缺点
Tomcat作为服务器,特别是作为Java Web服务器,具有一系列优点和缺点。以下是对其优缺点的详细分析: 优点 开源免费: Tomcat是一个免费、开源的Web服务器,用户可以在任何环境下自由使用,无需支付任何费用。…...

Linux系统编译boot后发现编译时间与Windows系统不一致的解决方案
现象 如下图,从filezilla软件看虚拟机Linux中编译的uboot.img修改时间与Windows系统时间不同 解决过程 在Linux中查看编译的uboot详细信息,从而得到编译时间。终端输入ls -l后,如下图: 结论 说明在Linux是按照Windows系统时…...

WPS Office手机去广高级版
工具介绍功能特点 WPS Office是使用人数最多的移动办公软件,独有手机阅读模式,字体清晰翻页流畅;完美支持文字,表格,演示,PDF等51种文档格式;新版本具有海量精美模版及高级功能 安装环境 [名称…...

Python爬虫基础-正则表达式!
前言 正则表达式是对字符串的一种逻辑公式,用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则的字符串”,此字符串用来表示对字符串的一种“过滤”逻辑。正在在很多开发语言中都存在,而非python独有。对其知识点…...

Python处理PDF组件使用及注意事项
在 Python 中处理 PDF 文件时, 使用的组件及注意事项如下: 1. PyPDF2 / PyPDF4 说明: PyPDF2 和 PyPDF4 都是功能强大的 PDF 操作库,适用于合并、拆分、旋转 PDF 文件,提取 PDF 元数据等。PyPDF4 是 PyPDF2 的一个分…...

langgraph_plan_and_execute
整体入门demo 教程概览 欢迎来到LangGraph教程! 这些笔记本通过构建各种语言代理和应用程序,介绍了如何使用LangGraph。 快速入门(Quick Start) 快速入门部分通过一个全面的入门教程,帮助您从零开始构建一个代理&a…...

[代码随想录打卡Day8] 344.反转字符串 541. 反转字符串II 54. 替换数字
反转字符串 难度:易。 问题描述:编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。 这个就是开头…...

DCN DCWS-6028神州数码 AC 设备配置笔记
DCN DCWS-6028神州数码 AC 设备配置笔记 一、前期准备 PC 电脑网络配置 目的:使 PC 能够访问 AC 的 web 管理控制台。配置详情:web 管理控制台地址为 192.168.1.10,将 PC 电脑 IP 地址配置在 192.168.1.1 - 192.168.1.254 网段内,如 192.168.1.110,子网掩码 255.255.255.…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...

探索Selenium:自动化测试的神奇钥匙
目录 一、Selenium 是什么1.1 定义与概念1.2 发展历程1.3 功能概述 二、Selenium 工作原理剖析2.1 架构组成2.2 工作流程2.3 通信机制 三、Selenium 的优势3.1 跨浏览器与平台支持3.2 丰富的语言支持3.3 强大的社区支持 四、Selenium 的应用场景4.1 Web 应用自动化测试4.2 数据…...
基础)
6个月Python学习计划 Day 16 - 面向对象编程(OOP)基础
第三周 Day 3 🎯 今日目标 理解类(class)和对象(object)的关系学会定义类的属性、方法和构造函数(init)掌握对象的创建与使用初识封装、继承和多态的基本概念(预告) &a…...