架构篇(04理解架构的演进)
目录
学习前言
一、架构演进
1. 初始阶段的网站架构
2. 应用服务和数据服务分离
3. 使用缓存改善网站性能
4. 使用应用服务器集群改善网站的并发处理能力
5. 数据库读写分离
6. 使用反向代理和CDN加上网站相应
7. 使用分布式文件系统和分布式数据库系统
8. 使用NoSQL和搜索引擎
9. 业务拆分
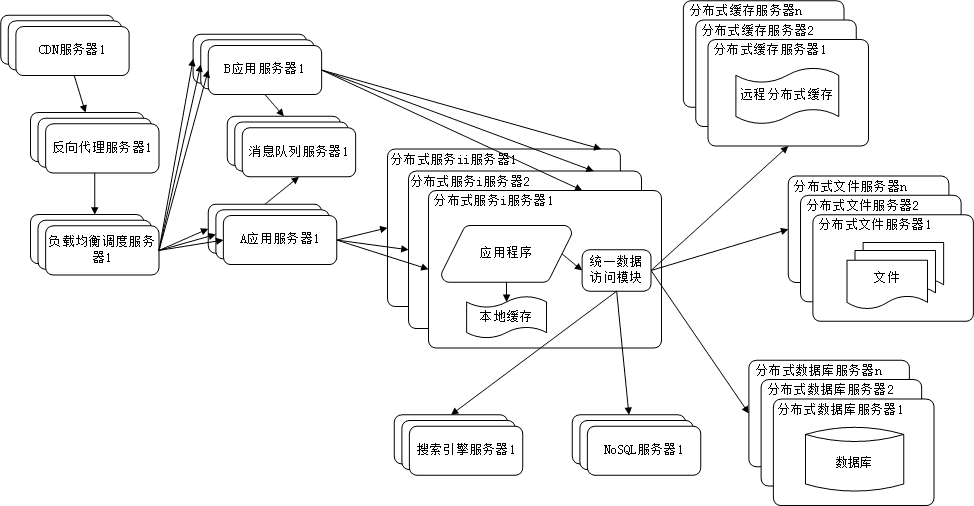
10. 分布式服务
二、示例:电商系统架构演进
1.0 时代
2.0 时代
3.0 时代
读写分离
4.0 业务垂直拆分
使用CDN来缓存信息
分库分表架构
同城双机房
5.0 单元化
三、参考文献
学习前言
在学习架构时,第一步不要去学习框架,而是要学习架构的演进。
强烈推荐李智慧老师的《大型网站技术架构》,这本书翻起来很快,对构筑你自己的体系很有帮助,本文的内容
来源于它,在此基础上拓展了下。@pdai
一、架构演进
大型网站的技术挑战主要来自于庞大的用户,高并发的访问和海量的数据,任何简单的业务一旦需要处理数以P计
的数据和面对数以亿计的用户,问题就会变得很棘手。大型网站架构主要就是解决这类问题。
架构选型是根据当前业务需要来的,在满足业务需求的前提下,既要有足够的扩展性也不能过度设计,每次的架
构升级都是为了解决系统瓶颈而做的。
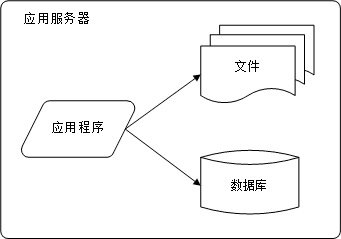
1. 初始阶段的网站架构
初始阶段都比较简单,通常一台服务器就可以搞定一个网站了,看图。
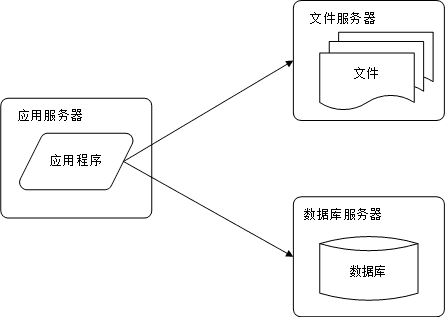
2. 应用服务和数据服务分离
随着网站业务的发展,一台服务器逐渐不能满足需求;这时候就需要将应用和数据分离,如图。
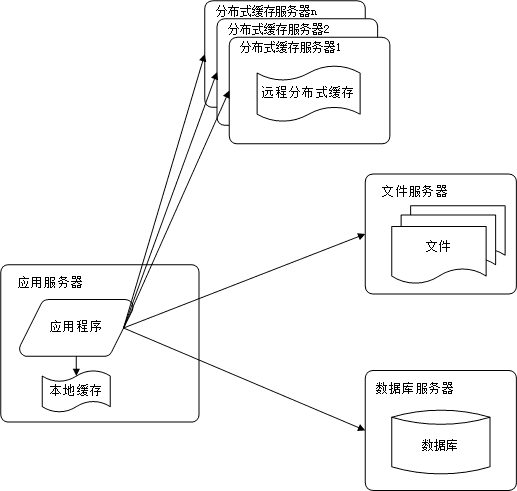
3. 使用缓存改善网站性能
毫无疑问,现在的网站基本上都会使用缓存,即:80%的业务访问都会集中在20%的数据上。
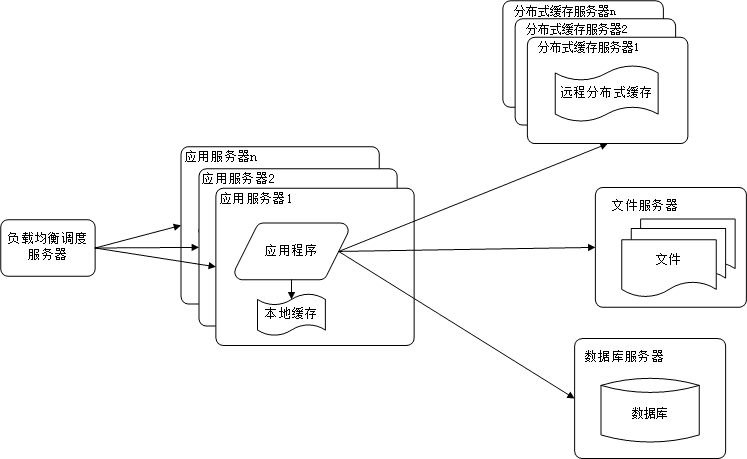
4. 使用应用服务器集群改善网站的并发处理能力
因为单一应用服务器能够处理的请求连接有限,在网站访问高峰时期,应用服务器会成为整个网站的瓶颈。因此
使用负载均衡处理器势在必然。通过负载均衡调度服务器,可将来自浏览器的访问请求分发到应用的集群中的任
何一台服务器上。
5. 数据库读写分离
当用户达到一定规模后,数据库因为负载压力过高而成为网站的瓶颈。而目前主流的数据库都提供主从热备功能,通过配置两台数据库主
从关系,可以将一台数据库的数据更新同步到另一台服务器上。网站利用数据库这一功能实现数据库读写分离,从而改善数据库负载压
力。
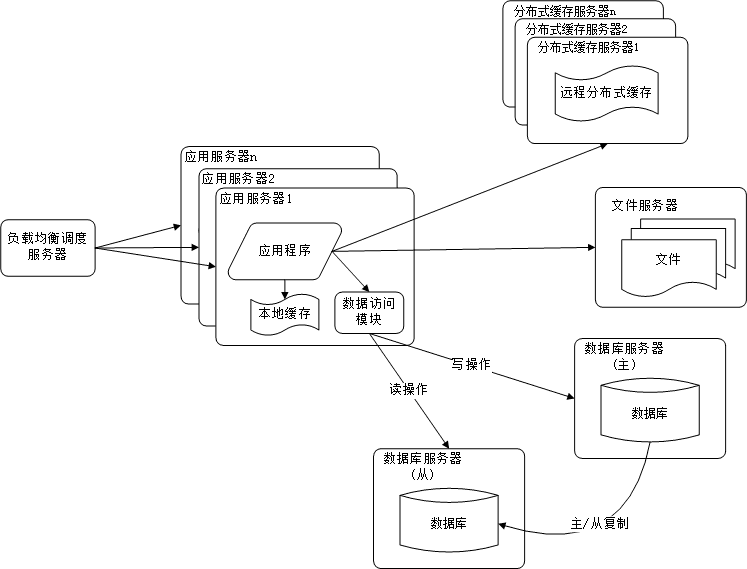
6. 使用反向代理和CDN加上网站相应
提高网站的访问速度,主要手段有使用CDN和反向代理。
CDN和反向代理的基本原理都是缓存,区别在于CDN部署在网络提供商的机房,而反向代理是部署在网站的中心
机房,当用户请求到达中心机房后,首先访问的反向代理,如果反向代理缓存着用户请求的资源,则直接返回给
用户。
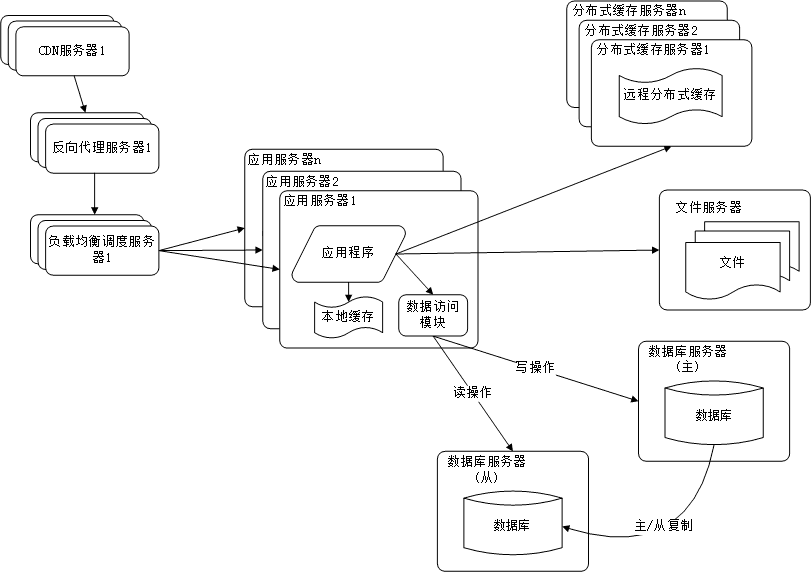
7. 使用分布式文件系统和分布式数据库系统
任何强大的单一服务器都满足不了大型网站持续增长的业务需求。
分布式数据库时网站数据库拆分的最后手段,只用在单表数据规模非常大的时候才使用。不到不得已时,网站更
常用的数据库拆分手段是业务拆分,将不同业务的数据部署在不同的物理服务器上。
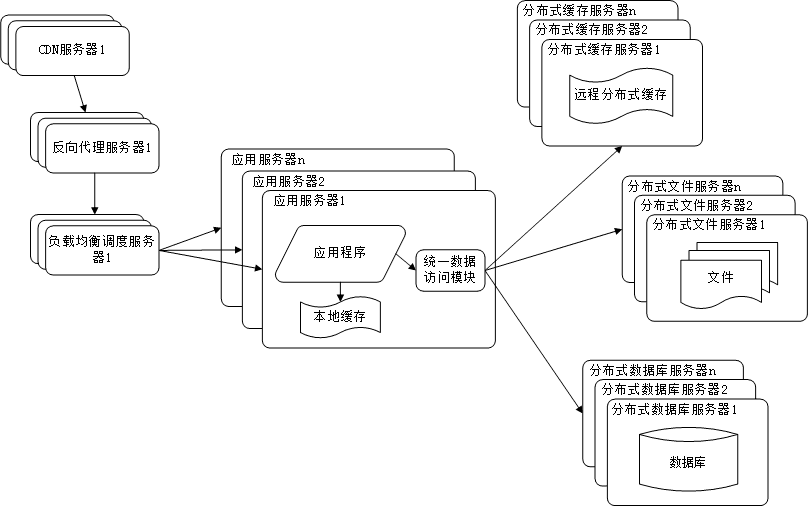
8. 使用NoSQL和搜索引擎
搜索引擎也基本已经形成现在大型网站必须提供的功能了,
网站需要采用一些非关系数据库技术如NoSQL和非数据库查询技术如搜索引擎。
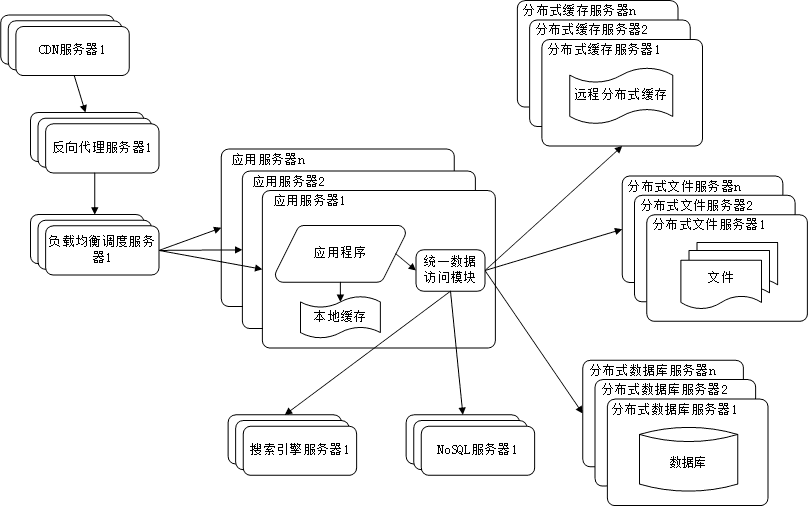
9. 业务拆分
大型网站为了应对日益复杂的业务场景,通过使用分而治之的手段将真个网站业务拆分成不同的产品线。
具体到技术上,也会根据产品线话费,将一个网站拆分成许多不同的应用,每个应用独立部署维护。应用之间可
以通过超链接建立管理,也可以通过消息队列进行数据分发,当然最多的还是通过访问同一个数据存储系统来构
成一个关联的完整系统。
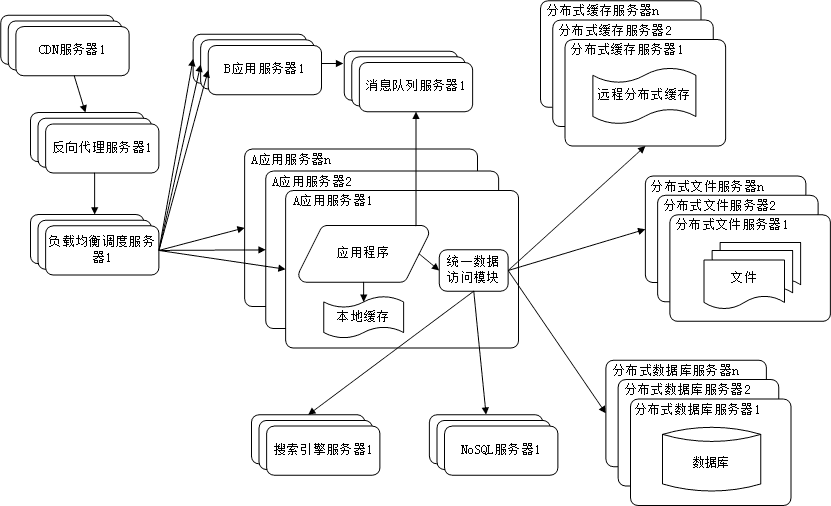
10. 分布式服务
由于每一个应用系统都需要执行许多相同的业务操作,比如用户管理,session管理,那么可以将这些公用的业务
提取出来,独立部署。
二、示例:电商系统架构演进
具体以电子商务网站为例, 展示web应用的架构演变过程。
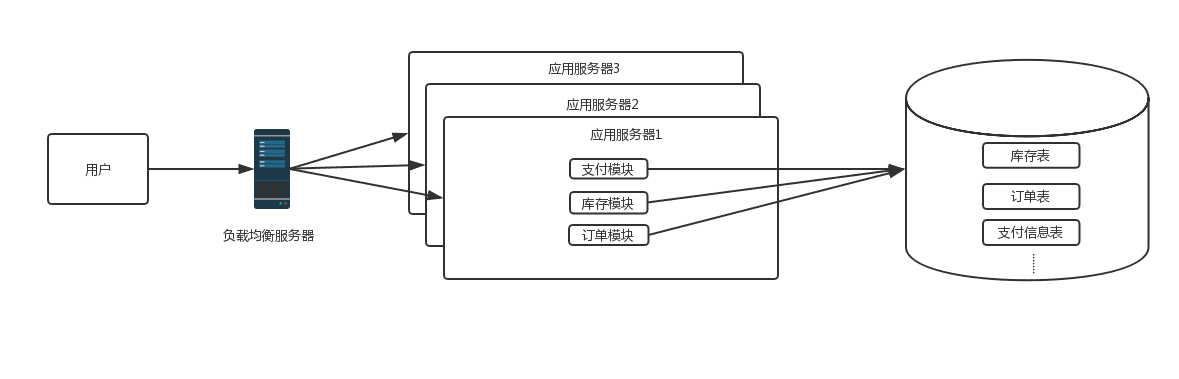
1.0 时代

这个时候是一个web项目里包含了所有的模块,一个数据库里包含了所需要的所有表,这时候网站访问量增加时,
首先遇到瓶颈的是应用服务器连接数,比如tomcat连接数不能无限增加,线程数上限受进程内存大小、CPU内核
数等因素影响,当线程数到达一定数时候,线程上下文的切换对性能的损耗会越来越严重,响应会变慢,通过增
加web应用服务器方式的横向扩展对架构影响最小,这时候架构会变成下面这样:
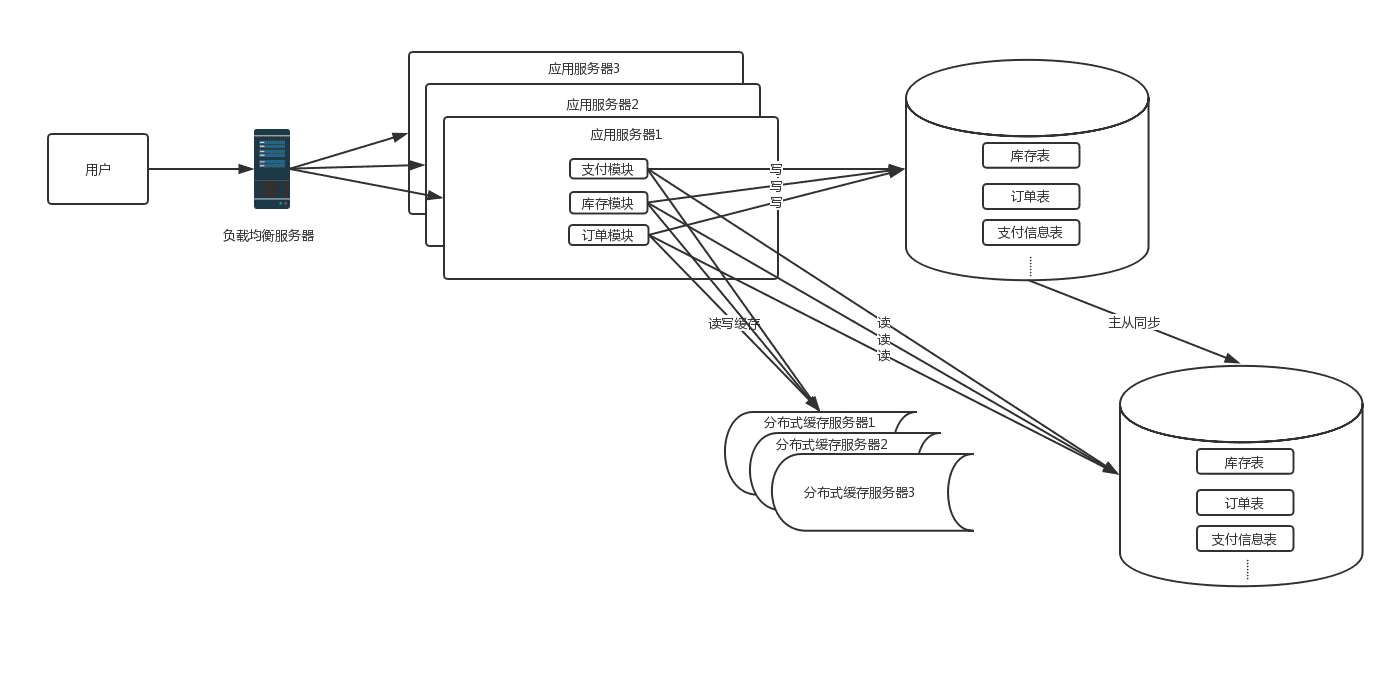
2.0 时代
这时候随着网站访问量继续增加,继续增加应用服务器数量后发现数据库成了瓶颈,而数据库的最主要的瓶颈体
现在两方面:
- 数据库的最大连接数是有限的,比如当前数据库的连接数设置8000,如果每个应用服务器与数据库的初始连接数设置40,那么200台web服务器是极限, 并且连接数太多后,数据库的读写压力增大,耗时增加
- 当单表数量过大时,对该表的操作耗时会增加,索引优化也是缓兵之计
这时,根据业务特点,如果读写比差距不大,并且对数据一致性要求不是很高的情况下,数据库可以采用主从方
式进行读写分离的方案,并且引入缓存机制来抗读流量。如果读写比差距很大或者对数据一致性要求高时,就不
适合用读写分离方案,需要考虑业务的垂直拆分,这时期的系统架构图如下:
3.0 时代
读写分离
这时候仍然是垂直架构,所有业务集中在一个项目里。项目维护、快速迭代问题会越来越严重,单个模块的开发
都需要发布整个项目,项目稳定性也受到很大挑战,这是需要考虑业务的垂直拆分,需要将一些大的模块单独拆
出来,这时候的架构图如下:
4.0 业务垂直拆分
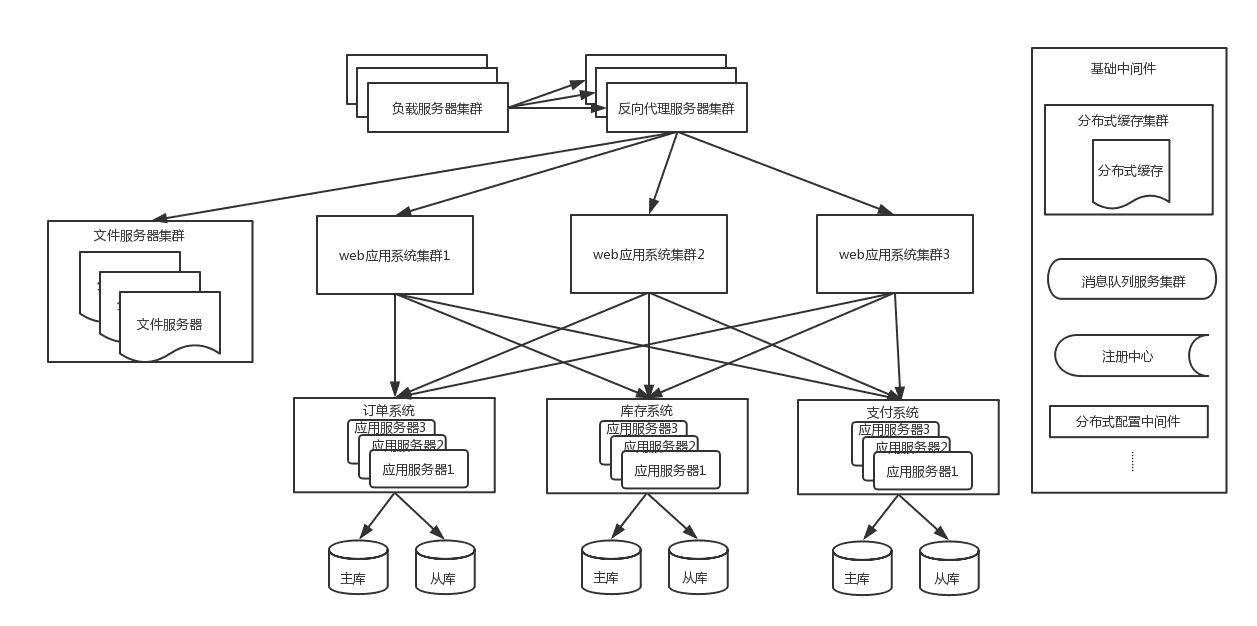
这时候为了进一步提升用户体验,加速用户的网站访问速度,会使用CDN来缓存信息,用户会访问最近的CDN节
点来提升访问速度。
此时的架构图如下:
使用CDN来缓存信息
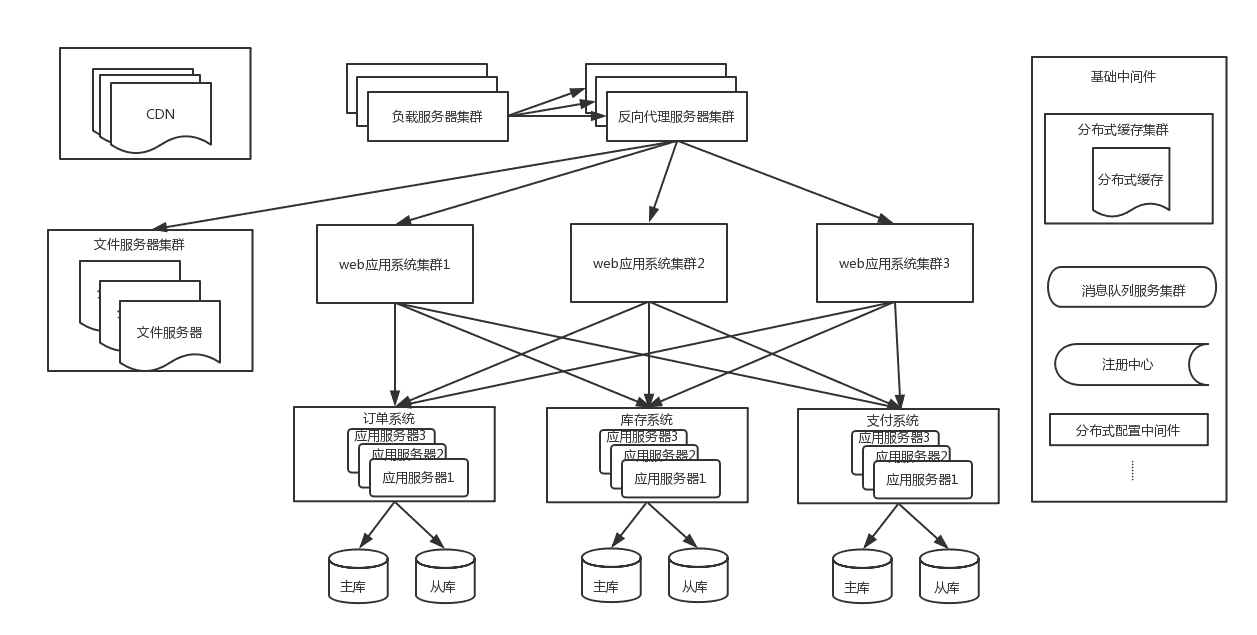
随着业务量增大,一些核心系统数据库单表数量达到几千万甚至亿级,这时候对该表的数据操作效率会大大降
低,并且虽然有缓存来抗读的压力,但是对于大量的写操作和一些缓存miss的流量到达一定量时,单库的负荷也
会到达极限,这时候需要将表拆分,一般直接采用分库分表,因为只做分表的话,单个库的连接瓶颈仍然无法解
决。分库分表后的架构如下:
分库分表架构
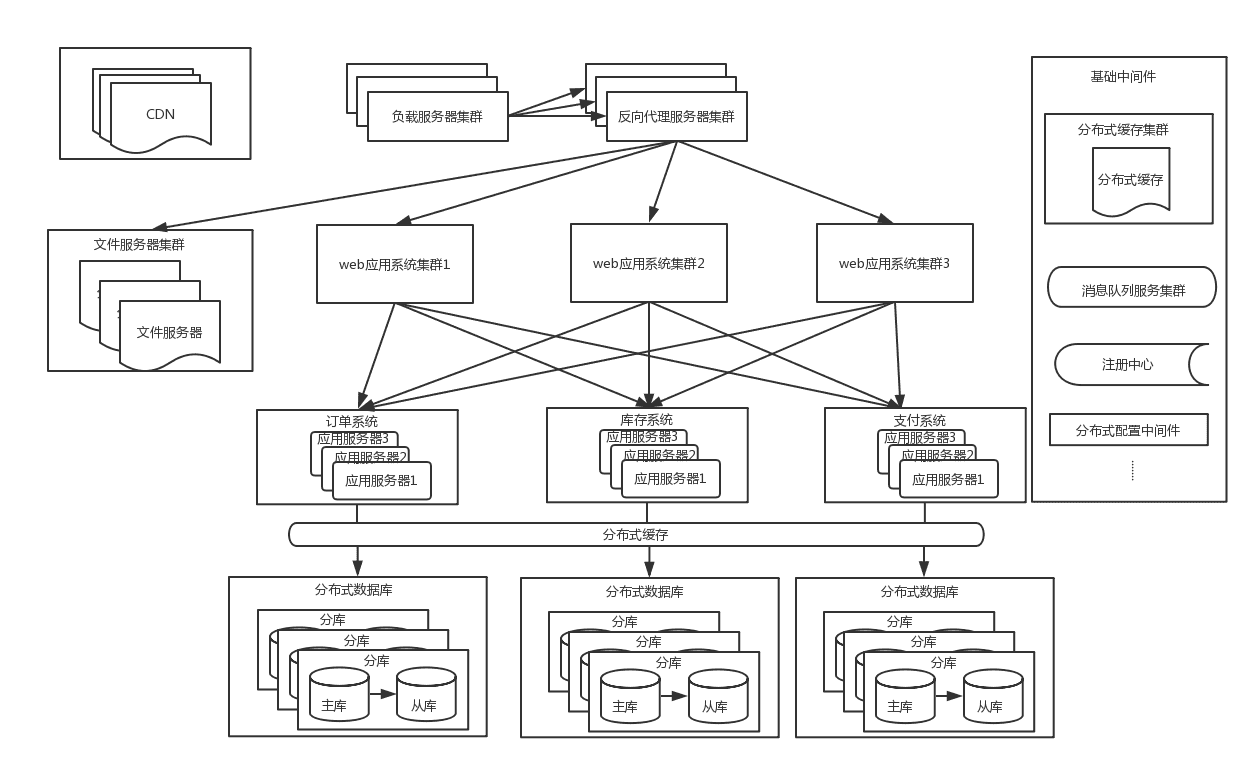
随着流量的进一步增大,这时候系统仍然会有瓶颈出现,以订单系统为例: 单个机房的机器是有限的,不能一直
新增下去,并且基于容灾的考虑,一般采用同城双机房的方式,机房之间用专线链接,同城跨机房质检的延时在
几毫秒,此时的架构图如下:
同城双机房
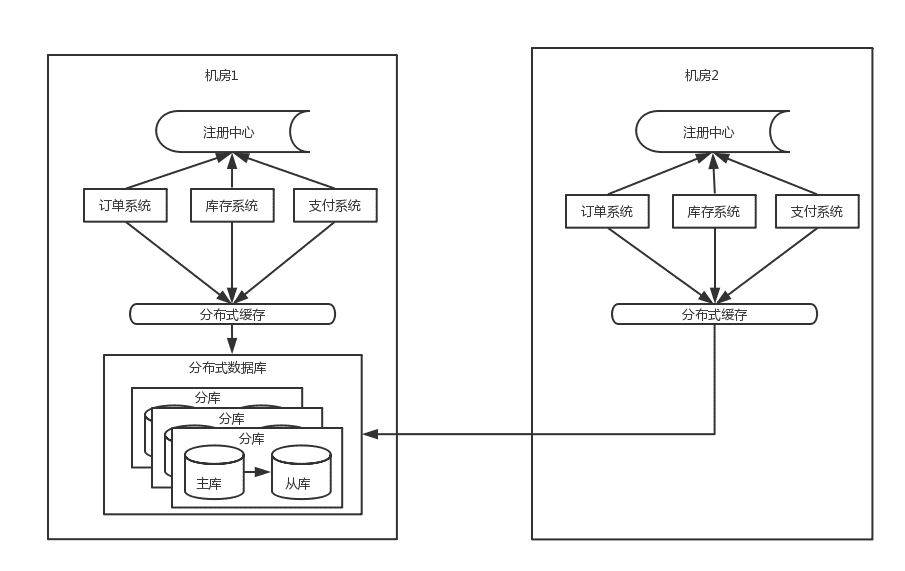
由于数据库主库只能是在一个机房,所以仍然会有一半的数据库访问是跨机房的,虽然延时只有几毫秒,但是一
个调用链里的数据库访问太多后,这个延时也会积少成多。其次这个架构还是没能解决数据库连接数瓶颈问题
- 随着应用服务器的增加,虽然是分库分表,但每增加一台应用服务器,都会与每个分库建立连接,比如数据
库连接池默认连接数是40,而如果mysql数据库的最大连接数是8000的话,那么200台应用服务器就是极
限。
- 当应用的量级太大后,单个城市的机器、电、带宽等资源无法满足业务的持续增长。这时就需要考虑SET化架
构,也就是单元化架构,大体思路就是将一些核心系统拆成多个中心,每个中心成为一个单元,流量会按照
一定的规则分配给每个单元,这样每个单元只负责处理自己的流量就可以了。每个单元要尽量自包含、高内
聚。这是从整体层面将流量分而治之的思路。这是单元化后的机构简图如下:
5.0 单元化
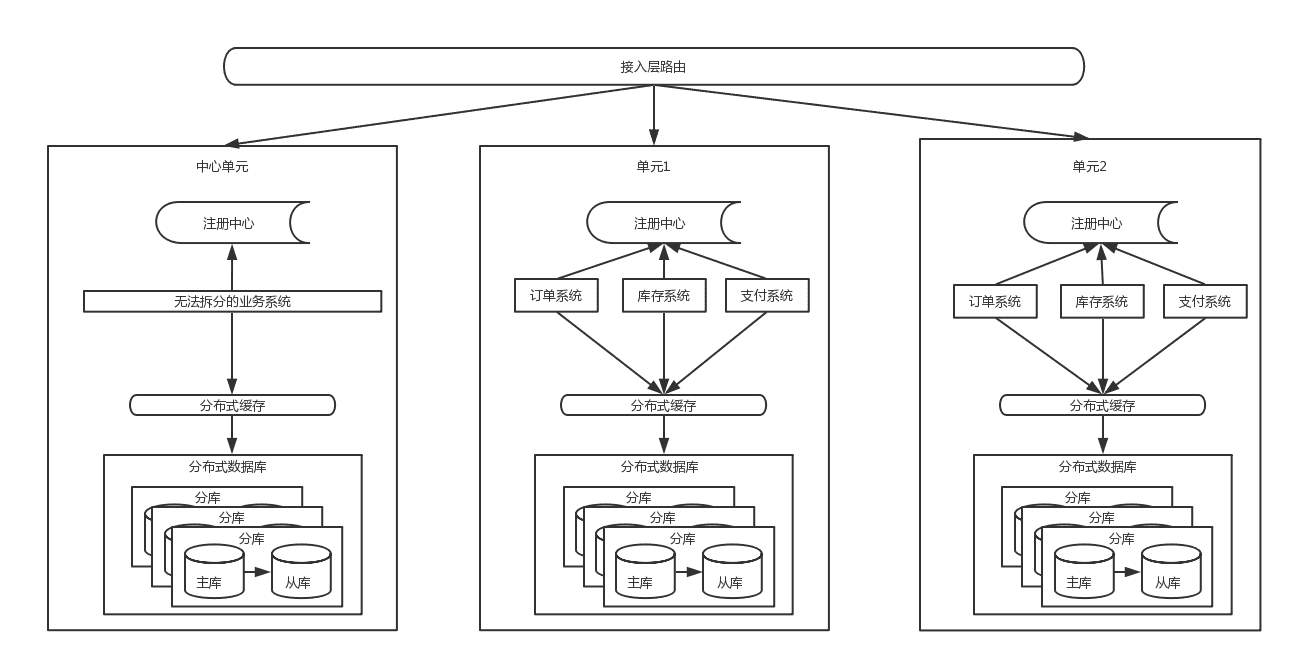
从上面的架构图里能看到,流量从接入层按照路由规则(比如以用户ID来路由)路由到不同单元,每个单元内都
是高内聚,包含了核心系统,数据层面的分片逻辑是与接入层路有逻辑一致,也解决了数据库连接的瓶颈问题,
但是一些跨单元的调用是无法避免的,同时也有些无法拆分的业务需要放在中心单元,供所有其他单元调用。
三、参考文献
文章主要参考自 李智慧的 《大型网站技术架构》,在此基础上还参考了(基本也是从这本书里自己画的):
- 互联网架构演变过程
- 大型分布式电商系统架构演进史?
- 大型网站架构演化历程
相关文章:
架构篇(04理解架构的演进)
目录 学习前言 一、架构演进 1. 初始阶段的网站架构 2. 应用服务和数据服务分离 3. 使用缓存改善网站性能 4. 使用应用服务器集群改善网站的并发处理能力 5. 数据库读写分离 6. 使用反向代理和CDN加上网站相应 7. 使用分布式文件系统和分布式数据库系统 8. 使用NoSQL和…...
【363】基于springboot的高校竞赛管理系统
摘 要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统高校竞赛管理系统信息管理难度大,容错率低&am…...

Spring Boot 监视器
一、Spring Boot 监视器概述 (一)什么是 Spring Boot 监视器 定义与作用 Spring Boot 监视器(Spring Boot Actuator)是一个用于监控和管理 Spring Boot 应用程序的工具集。它提供了一系列的端点,可以获取应用程序的运…...

Javascript如何获取指定网页中的内容?
这两天有一个需求,就是通过JS去获取网页的内容,当然,除了今天我要分享的这个方法以外,其实通过Ajax的Get方法也是可以实现这个功能的,但是Ajax就比较麻烦一些了,如果只是单纯的想要获取一下纯内容ÿ…...

第2章2.3立项【硬件产品立项的核心内容】
硬件产品立项的核心内容 2.3 硬件产品立项的核心内容2.3.1 第一步:市场趋势判断2.3.2 第二步:竞争对手分析1.竞争对手识别2.根据竞争对手分析制定策略 2.3.3 第三步:客户分析2.3.4 第四步:产品定义2.3.5 第五步:开发执…...

区块链:Raft协议
Raft 协议是一种分布式共识机制,这种机制适用于网络中存在一定数量的故障节点,但不考虑“恶意”节点的情况,所以更适合作为私有链和联盟链的共识算法。 在此协议中,每个节点有三种状态: 候选者 ,可以被选…...

【C语言】位运算
我们在上学计算机的第一节课,就应该见过这些常见的运算符。然而,你可能有印象,但记不住众多操作符当中的位运算符,以及它们的作用和使用场景,我们的大脑会选择性地遗忘它认为没用的信息,存储下那些“有实际…...

计算机体系结构之多级缓存、缓存miss及缓存hit(二)
前面章节《计算机体系结构之缓存机制原理及其应用(一)》讲了关于缓存机制的原理及其应用,其中提出了多级缓存、缓存miss以及缓存hit的疑问。故,本章将进行展开讲解, 多级缓存、缓存miss以及缓存hit存在的意义是为了保持…...

【R78/G15 开发板测评】串口打印 DHT11 温湿度传感器、DS18B20 温度传感器数据,LabVIEW 上位机绘制演化曲线
【R78/G15 开发板测评】串口打印 DHT11 温湿度传感器、DS18B20 温度传感器数据,LabVIEW 上位机绘制演化曲线 主要介绍了 R78/G15 开发板基于 Arduino IDE 环境串口打印温湿度传感器 DHT11 和温度传感器 DS18B20 传感器的数据,并通过LabVIEW上位机绘制演…...

Oracle Fetch子句
FETCH 子句在 Oracle 中可以用来限制查询返回的行数 Oracle FETCH 子句语法 以下说明了行限制子句的语法: [ OFFSET offset ROWS]FETCH NEXT [ row_count | percent PERCENT ] ROWS [ ONLY | WITH TIES ]OFFSET 子句 OFFSET 子句指定在行限制开始之前要跳过行…...

Linux应用——线程池
1. 线程池要求 我们创建线程池的目的本质上是用空间换取时间,而我们选择于 C 的类内包装原生线程库的形式来创建,其具体实行逻辑如图 可以看到,整个线程池其实就是一个大型的 CP 模型,接下来我们来完成它 2. 整体模板 #pragma …...

95.【C语言】数据结构之双向链表的头插,头删,查找,中间插入,中间删除和销毁函数
目录 1.双向链表的头插 方法一 方法二 2.双向链表的头删 3.双向链表的销毁 4.双向链表的某个节点的数据查找 5.双向链表的中间插入 5.双向链表的中间删除 6.对比顺序表和链表 承接94.【C语言】数据结构之双向链表的初始化,尾插,打印和尾删文章 1.双向链表的头插 方法…...

leetcode82:删除排序链表中的重复节点||
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。 示例 1: 输入:head [1,2,3,3,4,4,5] 输出:[1,2,5]示例 2: 输入:head [1,1,1,2…...

【C#】使用.net9在C#中向现有对象动态添加属性
在 C# 中向现有对象动态添加属性并不像在 Python 或 JavaScript 中那样容易,因为 C# 是一种强类型语言。 但是,我们可以通过使用一些技术和库来实现这一点,例如扩展方法、字典等。本文将详细介绍如何在 C# 中实现这一点。ExpandoObject 方法 …...

Linux进程信号(信号的产生)
目录 什么是信号? 信号的产生 信号产生方式1:键盘 前台进程 后台进程 查看信号 signal系统调用 案例 理解进程记录信号 软件层面 硬件层面 信号产生方式2:指令 信号产生方式3:系统调用 kill系统调用 案例 其他产生信号的函数调用 1.rais…...

97_api_intro_imagerecognition_pdf2word
通用 PDF OCR 到 Word API 数据接口 文件处理,OCR,PDF 高可用图像识别引擎,基于机器学习,超精准识别率。 1. 产品功能 通用识别接口;支持中英文等多语言字符混合识别;formdata 格式 PDF 文件流传参…...

【算法】【优选算法】二分查找算法(上)
目录 一、二分查找简介1.1 朴素二分模板1.2 查找区间左端点模版1.3 查找区间右端点模版 二、leetcode 704.⼆分查找2.1 二分查找2.2 暴力枚举 三、Leetcode 34.在排序数组中查找元素的第⼀个和最后⼀个位置3.1 二分查找3.2 暴力枚举 四、35.搜索插⼊位置4.1 二分查找4.2 暴力枚…...

springboot初体验
目录 环境 controller 修改端口号 更改banner图标 运行结果 最核心的:自动装配 环境 jdk17springboot3.3.5maven3.8.2 controller controller层和启动类同级 package com.example.demo.controller; import org.springframework.web.bind.annotation.RequestMapping;…...
使用kalibr_calibration标定相机(realsense)和imu(h7min)
vslam-evaluation/VINS/Installation documentation/4.IMU和相机联合标定kalibr_calibration.md at master DroidAITech/vslam-evaluation GitHub 目录 1.kalibr安装 1.1安装依赖项 1.2创建工作空间 1.3下载kalibr并编译 1.4设置环境变量 2.准备标定板 3.配置驱动和打…...

绿色工厂认定流程
以下是认定绿色工厂的一般流程: 编制年度创建计划 各省辖市、省直管县(市)会结合本地区重点产业发展现状,挑选一批基础条件良好、有创建意愿和条件的企业进行储备培育,并依据当地工业企业发展实际情况按年度制定绿色工…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...