GNN系统学习:消息传递图神经网络
引言
在开篇中我们介绍了,为节点生成节点表征(Node Representation)是图计算任务成功的关键,我们要利用神经网络来学习节点表征。
消息传递范式是一种聚合邻接节点信息来更新中心节点信息的范式,它将卷积算子推广到了不规则数据领域,实现了图与神经网络的连接。消息传递范式因为简单、强大的特性,于是被人们广泛地使用。遵循消息传递范式的图神经网络被称为消息传递图神经网络。本节中,
- 首先我们将学习图神经网络生成节点表征的范式–消息传递(Message Passing)范式。
- 接着我们将初步分析PyG中的
MessagePassing基类,通过继承此基类我们可以方便地构造一个图神经网络。 - 然后我们以继承
MessagePassing基类的GCNConv类为例,学习如何通过继承MessagePassing基类来构造图神经网络。 - 再接着我们将对
MessagePassing基类进行剖析。 - 最后我们将学习在继承
MessagePassing基类的子类中覆写message(),aggreate(),message_and_aggreate()和update(),这些方法的规范。
消息传递范式介绍
下方图片展示了基于消息传递范式的聚合邻接节点信息来更新中心节点信息的过程:
- 图中黄色方框部分展示的是一次邻接节点信息传递到中心节点的过程:B节点的邻接节点(A,C)的信息经过变换后聚合到B节点,接着B节点信息与邻接节点聚合信息一起经过变换得到B节点的新的节点信息。同时,分别如红色和绿色方框部分所示,遵循同样的过程,C、D节点的信息也被更新。实际上,同样的过程在所有节点上都进行了一遍,所有节点的信息都更新了一遍。
- 这样的“邻接节点信息传递到中心节点的过程”会进行多次。如图中蓝色方框部分所示,A节点的邻接节点(B,C,D)的已经发生过一次更新的节点信息,经过变换、聚合、再变换产生了A节点第二次更新的节点信息。多次更新后的节点信息就作为节点表征。

消息传递图神经网络遵循上述的“聚合邻接节点信息来更新中心节点信息的过程”,来生成节点表征。用 x ( k − 1 ) i ∈ R F \mathbf{x}^{(k-1)}i\in\mathbb{R}^F x(k−1)i∈RF表示 ( k − 1 ) (k-1) (k−1)层中节点 i i i的节点表征, e j , i ∈ R D \mathbf{e}{j,i} \in \mathbb{R}^D ej,i∈RD 表示从节点 j j j到节点 i i i的边的属性,消息传递图神经网络可以描述为 x i ( k ) = γ ( k ) ( x i ( k − 1 ) , □ j ∈ N ( i ) ϕ ( k ) ( x i ( k − 1 ) , x j ( k − 1 ) , e j , i ) ) , \mathbf{x}_i^{(k)} = \gamma^{(k)} \left( \mathbf{x}_i^{(k-1)}, \square_{j \in \mathcal{N}(i)} \phi^{(k)}\left(\mathbf{x}_i^{(k-1)}, \mathbf{x}_j^{(k-1)},\mathbf{e}_{j,i}\right) \right), xi(k)=γ(k)(xi(k−1),□j∈N(i)ϕ(k)(xi(k−1),xj(k−1),ej,i)), 其中 □ \square □表示可微分的、具有**排列不变性(函数输出结果与输入参数的排列无关)**的函数。具有排列不变性的函数有,sum()函数、mean()函数和max()函数。 γ \gamma γ和 ϕ \phi ϕ表示可微分的函数,如MLPs(多层感知器)。
注(1):神经网络的生成节点表征的操作称为节点嵌入(Node Embedding),节点表征也可以称为节点嵌入。为了统一此次组队学习中的表述,我们规定节点嵌入只代指神经网络生成节点表征的操作。
注(2):未经过训练的图神经网络生成的节点表征还不是好的节点表征,好的节点表征可用于衡量节点之间的相似性。通过监督学习对图神经网络做很好的训练,图神经网络才可以生成好的节点表征。我们将在第5节介绍此部分内容。
注(3),节点表征与节点属性的区分:遵循被广泛使用的约定,此次组队学习我们也约定,节点属性data.x是节点的第0层节点表征,第 h h h层的节点表征经过一次的节点间信息传递产生第 h + 1 h+1 h+1层的节点表征。不过,节点属性不单指data.x,广义上它就指节点的属性,如节点的度等。
MessagePassing基类初步分析
Pytorch Geometric(PyG)提供了MessagePassing基类,它封装了“消息传递”的运行流程。通过继承MessagePassing基类,可以方便地构造消息传递图神经网络。构造一个最简单的消息传递图神经网络类,我们只需定义message()方法( ϕ \phi ϕ)、update()方法( γ \gamma γ),以及使用的消息聚合方案(aggr=“add”、aggr="mean"或aggr=“max”)。这一切是在以下方法的帮助下完成的:
MessagePassing(aggr="add", flow="source_to_target", node_dim=-2)(对象初始化方法):
aggr:定义要使用的聚合方案(“add”、"mean "或 “max”);
flow:定义消息传递的流向("source_to_target "或 “target_to_source”);
node_dim:定义沿着哪个维度传播,默认值为**-2**,也就是节点表征张量(Tensor)的哪一个维度是节点维度。节点表征张量x形状为[num_nodes, num_features],其第0维度(也是第-2维度)是节点维度,其第1维度(也是第-1维度)是节点表征维度,所以我们可以设置node_dim=-2。
注:MessagePassing(……)等同于MessagePassing.__init__(……)MessagePassing.propagate(edge_index, size=None, **kwargs):
开始传递消息的起始调用,在此方法中message、update等方法被调用。
它以edge_index(边的端点的索引)和flow(消息的流向)以及一些额外的数据为参数。
请注意,propagate()不局限于基于形状为[N, N]的对称邻接矩阵进行“消息传递过程”。基于非对称的邻接矩阵进行消息传递(当图为二部图时),需要传递参数size=(N, M)。
如果设置size=None,则认为邻接矩阵是对称的。MessagePassing.message(...):
首先确定要给节点 i i i传递消息的边的集合:
如果flow=“source_to_target”,则是 ( j , i ) ∈ E (j,i) \in \mathcal{E} (j,i)∈E的边的集合;
如果flow=“target_to_source”,则是 ( i , j ) ∈ E (i,j) \in \mathcal{E} (i,j)∈E的边的集合。
接着为各条边创建要传递给节点 i i i的消息,即实现 ϕ \phi ϕ函数。
MessagePassing.message(…)方法可以接收传递给MessagePassing.propagate(edge_index, size=None, **kwargs)方法的所有参数,我们在message()方法的参数列表里定义要接收的参数,例如我们要接收x,y,z参数,则我们应定义message(x,y,z)方法。
传递给propagate()方法的参数,如果是节点的属性的话,可以被拆分成属于中心节点的部分和属于邻接节点的部分,只需在变量名后面加上_i或_j。例如,我们自己定义的message方法包含参数x_i,那么首先propagate()方法将节点表征拆分成中心节点表征和邻接节点表征,接着propagate()方法调用message方法并传递中心节点表征给参数x_i。而如果我们自己定义的meassage方法包含参数x_j,那么propagate()方法会传递邻接节点表征给参数x_j。
我们用 i i i表示“消息传递”中的中心节点,用 j j j表示“消息传递”中的邻接节点。MessagePassing.aggregate(...):
将从源节点传递过来的消息聚合在目标节点上,一般可选的聚合方式有sum, mean和max。MessagePassing.message_and_aggregate(...):
在一些场景里,邻接节点信息变换和邻接节点信息聚合这两项操作可以融合在一起,那么我们可以在此方法里定义这两项操作,从而让程序运行更加高效。MessagePassing.update(aggr_out, ...):
为每个节点 i ∈ V i \in \mathcal{V} i∈V更新节点表征,即实现 γ \gamma γ函数。此方法以aggregate方法的输出为第一个参数,并接收所有传递给propagate()方法的参数。
MessagePassing子类实例
我们以继承MessagePassing基类的GCNConv类为例,学习如何通过继承MessagePassing基类来实现一个简单的图神经网络。
GCNConv的数学定义为 x i ( k ) = ∑ j ∈ N ( i ) ∪ i 1 deg ( i ) ⋅ deg ( j ) ⋅ ( Θ ⋅ x j ( k − 1 ) ) , \mathbf{x}_i^{(k)} = \sum_{{j \in \mathcal{N}(i) \cup { i }}} \frac{1}{\sqrt{\deg(i)} \cdot \sqrt{\deg(j)}} \cdot \left( \mathbf{\Theta} \cdot \mathbf{x}_j^{(k-1)} \right), xi(k)=j∈N(i)∪i∑deg(i)⋅deg(j)1⋅(Θ⋅xj(k−1)), 其中,邻接节点的表征 x j ( k − 1 ) \mathbf{x}_j^{(k-1)} xj(k−1)首先通过与权重矩阵 Θ \mathbf{\Theta} Θ相乘进行变换,然后按端点的度 deg ( i ) , deg ( j ) \deg(i), \deg(j) deg(i),deg(j)进行归一化处理,最后进行求和。这个公式可以分为以下几个步骤:
- 向邻接矩阵添加自环边。
- 对节点表征做线性转换。
- 计算归一化系数。
- 归一化邻接节点的节点表征。
- 将相邻节点表征相加("求和 "聚合)。
步骤1-3通常是在消息传递发生之前计算的。步骤4-5可以使用MessagePassing基类轻松处理。该层的全部实现如下所示。
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degreeclass GCNConv(MessagePassing):def __init__(self, in_channels, out_channels):super(GCNConv, self).__init__(aggr='add', flow='source_to_target')# "Add" aggregation (Step 5).# flow='source_to_target' 表示消息从源节点传播到目标节点self.lin = torch.nn.Linear(in_channels, out_channels)def forward(self, x, edge_index):# x has shape [N, in_channels]# edge_index has shape [2, E]# Step 1: Add self-loops to the adjacency matrix.edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))# Step 2: Linearly transform node feature matrix.x = self.lin(x)# Step 3: Compute normalization.row, col = edge_indexdeg = degree(col, x.size(0), dtype=x.dtype)deg_inv_sqrt = deg.pow(-0.5)norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]# Step 4-5: Start propagating messages.return self.propagate(edge_index, x=x, norm=norm)def message(self, x_j, norm):# x_j has shape [E, out_channels]# Step 4: Normalize node features.return norm.view(-1, 1) * x_j
GCNConv继承了MessagePassing并以"求和"作为领域节点信息聚合方式。该层的所有逻辑都发生在其forward()方法中。在这里,我们首先使用torch_geometric.utils.add_self_loops()函数向我们的边索引添加自循环边(步骤1),以及通过调用torch.nn.Linear实例对节点表征进行线性变换(步骤2)。propagate()方法也在forward方法中被调用,propagate()方法被调用后节点间的信息传递开始执行。
归一化系数是由每个节点的节点度得出的,它被转换为每条边的节点度。结果被保存在形状为[num_edges,]的变量norm中(步骤3)。
edge_index 是一个形状为 [2, E] 的张量,其中 E 是边的数量。
row = edge_index[0] 表示边的源节点索引。
col = edge_index[1] 表示边的目标节点索引。
简写就是 row, col = edge_index
通过 row 和 col,可以获取每条边连接的两个节点,从而访问节点的度数信息。
deg = degree(col, x.size(0), dtype=x.dtype)
在 PyTorch Geometric 中,torch_geometric.utils.degree 是一个用于计算节点度数的工具函数。
它的输入是图中每条边的目标节点索引,输出是每个节点的度数。
通过 degree(col, x.size(0)),计算每个节点的度数。col 表示每条边的目标节点,因此按 col 统计得到每个节点的入度。
x.size(0):表示图中节点的总数 N。表示张量 x 在第 0 维度(即行数)上的大小。在图神经网络(GCN)代码中,x.size(0) 通常用于获取节点的数量,因为 x 是节点特征矩阵。这个值用于指定度数数组的长度,确保每个节点(包括孤立节点)的度数都能被正确计算。
dtype=x.dtype:确保返回的度数张量 deg 的数据类型与输入特征张量 x 的类型一致。
deg 是一个长度为节点数 N 的张量,表示每个节点的度数。
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]
通过 row 和 col 索引得到相应节点的度数倒数平方根,并将其相乘。最终得到的 norm 是一个长度为 E(边的个数) 的张量。
该 norm 表示每条边的归一化因子,用于后续消息传递过程中的特征归一化。

在message()方法中,我们需要通过norm对邻接节点表征x_j进行归一化处理。
x_j 是从邻接节点传来的特征,形状为 [E, out_channels],其中 E 是边的数量。
norm 是每条边的归一化因子,形状为 [E]。
-
归一化因子调整形状:
norm.view(-1, 1)
norm 是形状 [E] 的张量。使用 .view(-1, 1) 将其调整为 [E, 1] 的形状,使其可以广播(broadcast)到 x_j 的形状 [E, out_channels]。 -
归一化特征:
norm.view(-1, 1) * x_j
逐元素乘法,将归一化因子 norm 应用于每条边的特征 x_j。这一步相当于将邻接矩阵的归一化权重应用于节点特征,确保每条边的信息根据归一化因子缩放。
通过以上内容的学习,我们便掌握了创建一个仅包含一次“消息传递过程”的图神经网络的方法。如下方代码所示,我们可以很方便地初始化和调用它:
from torch_geometric.datasets import Planetoiddataset = Planetoid(root='dataset', name='Cora')
data = dataset[0]net = GCNConv(data.num_features, 64)
h_nodes = net(data.x, data.edge_index)
print(h_nodes.shape)
通过串联多个这样的简单图神经网络,我们就可以构造复杂的图神经网络模型。我们将在第5节介绍复杂图神经网络模型的构建。
MessagePassing基类剖析
在__init__()方法中,我们看到程序会检查子类是否实现了message_and_aggregate()方法,并将检查结果赋值给fuse属性。
class MessagePassing(torch.nn.Module):def __init__(self, aggr: Optional[str] = "add", flow: str = "source_to_target", node_dim: int = -2):super(MessagePassing, self).__init__()# 此处省略n行代码# Support for "fused" message passing.self.fuse = self.inspector.implements('message_and_aggregate')# 此处省略n行代码
“消息传递过程”是从propagate方法被调用开始执行的。
class MessagePassing(torch.nn.Module):# 此处省略n行代码def propagate(self, edge_index: Adj, size: Size = None, **kwargs):# 此处省略n行代码# Run "fused" message and aggregation (if applicable).if (isinstance(edge_index, SparseTensor) and self.fuse and not self.__explain__):coll_dict = self.__collect__(self.__fused_user_args__, edge_index, size, kwargs)msg_aggr_kwargs = self.inspector.distribute('message_and_aggregate', coll_dict)out = self.message_and_aggregate(edge_index, **msg_aggr_kwargs)update_kwargs = self.inspector.distribute('update', coll_dict)return self.update(out, **update_kwargs)# Otherwise, run both functions in separation.elif isinstance(edge_index, Tensor) or not self.fuse:coll_dict = self.__collect__(self.__user_args__, edge_index, size, kwargs)msg_kwargs = self.inspector.distribute('message', coll_dict)out = self.message(**msg_kwargs)# 此处省略n行代码aggr_kwargs = self.inspector.distribute('aggregate', coll_dict)out = self.aggregate(out, **aggr_kwargs)update_kwargs = self.inspector.distribute('update', coll_dict)return self.update(out, **update_kwargs)
参数简介:
- edge_index: 边端点索引,它可以是Tensor类型或SparseTensor类型。
当flow="source_to_target"时,节点edge_index[0]的信息将被传递到节点edge_index[1],
当flow="target_to_source"时,节点edge_index[1]的信息将被传递到节点edge_index[0] - size: 邻接节点的数量与中心节点的数量。
对于普通图,邻接节点的数量与中心节点的数量都是N,我们可以不给size传参数,即让size取值为默认值None。
对于二部图,邻接节点的数量与中心节点的数量分别记为M, N,于是我们需要给size参数传一个元组(M, N)。 - kwargs: 图其他属性或额外的数据。
propagate()方法首先检查edge_index是否为SparseTensor类型以及是否子类实现了message_and_aggregate()方法,如是就执行子类的message_and_aggregate方法;否则依次执行子类的message(),aggregate(),update()三个方法。
message方法的覆写
前面我们介绍了,传递给propagate()方法的参数,如果是节点的属性的话,可以被拆分成属于中心节点的部分和属于邻接节点的部分,只需在变量名后面加上_i或_j。现在我们有一个额外的节点属性,节点的度deg,我们希望meassge方法还能接收中心节点的度,我们对前面GCNConv的message方法进行改造得到新的GCNConv类:
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degreeclass GCNConv(MessagePassing):def __init__(self, in_channels, out_channels):super(GCNConv, self).__init__(aggr='add', flow='source_to_target')# "Add" aggregation (Step 5).# flow='source_to_target' 表示消息从源节点传播到目标节点self.lin = torch.nn.Linear(in_channels, out_channels)def forward(self, x, edge_index):# x has shape [N, in_channels]# edge_index has shape [2, E]# Step 1: Add self-loops to the adjacency matrix.edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))# Step 2: Linearly transform node feature matrix.x = self.lin(x)# Step 3: Compute normalization.row, col = edge_indexdeg = degree(col, x.size(0), dtype=x.dtype)deg_inv_sqrt = deg.pow(-0.5)norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]# Step 4-5: Start propagating messages.return self.propagate(edge_index, x=x, norm=norm, deg=deg.view((-1, 1)))def message(self, x_j, norm, deg_i):# x_j has shape [E, out_channels]# deg_i has shape [E, 1]# Step 4: Normalize node features.return norm.view(-1, 1) * x_j * deg_ifrom torch_geometric.datasets import Planetoiddataset = Planetoid(root='dataset', name='Cora')
data = dataset[0]net = GCNConv(data.num_features, 64)
h_nodes = net(data.x, data.edge_index)
print(h_nodes.shape)
若一个数据可以被拆分成属于中心节点的部分和属于邻接节点的部分,其形状必须是[num_nodes, *],因此在上方代码的第29行,我们执行了**deg.view((-1, 1))**操作,使得数据形状为[num_nodes, 1],然后才将数据传给propagate()方法。
aggregate方法的覆写
在前面的例子的基础上,我们增加如下的aggregate方法。通过观察运行结果我们可以看到,我们覆写的aggregate方法被调用,同时在super(GCNConv, self).__init__(aggr='add')中传递给aggr参数的值被存储到了self.aggr属性中。
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degreeclass GCNConv(MessagePassing):def __init__(self, in_channels, out_channels):super(GCNConv, self).__init__(aggr='add', flow='source_to_target')# "Add" aggregation (Step 5).# flow='source_to_target' 表示消息从源节点传播到目标节点self.lin = torch.nn.Linear(in_channels, out_channels)def forward(self, x, edge_index):# x has shape [N, in_channels]# edge_index has shape [2, E]# Step 1: Add self-loops to the adjacency matrix.edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))# Step 2: Linearly transform node feature matrix.x = self.lin(x)# Step 3: Compute normalization.row, col = edge_indexdeg = degree(col, x.size(0), dtype=x.dtype)deg_inv_sqrt = deg.pow(-0.5)norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]# Step 4-5: Start propagating messages.return self.propagate(edge_index, x=x, norm=norm, deg=deg.view((-1, 1)))def message(self, x_j, norm, deg_i):# x_j has shape [E, out_channels]# deg_i has shape [E, 1]# Step 4: Normalize node features.return norm.view(-1, 1) * x_j * deg_idef aggregate(self, inputs, index, ptr, dim_size):print('self.aggr:', self.aggr)print("`aggregate` is called")return super().aggregate(inputs, index, ptr=ptr, dim_size=dim_size)from torch_geometric.datasets import Planetoiddataset = Planetoid(root='dataset', name='Cora')
data = dataset[0]net = GCNConv(data.num_features, 64)
h_nodes = net(data.x, data.edge_index)
print(h_nodes.shape)
message_and_aggregate方法的覆写
在一些案例中,“消息传递”与“消息聚合”可以融合在一起。对于这种情况,我们可以覆写message_and_aggregate方法,在message_and_aggregate方法中一块实现“消息传递”与“消息聚合”,这样能使程序的运行更加高效。
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
from torch_sparse import SparseTensorclass GCNConv(MessagePassing):def __init__(self, in_channels, out_channels):super(GCNConv, self).__init__(aggr='add', flow='source_to_target')# "Add" aggregation (Step 5).# flow='source_to_target' 表示消息从源节点传播到目标节点self.lin = torch.nn.Linear(in_channels, out_channels)def forward(self, x, edge_index):# x has shape [N, in_channels]# edge_index has shape [2, E]# Step 1: Add self-loops to the adjacency matrix.edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))# Step 2: Linearly transform node feature matrix.x = self.lin(x)# Step 3: Compute normalization.row, col = edge_indexdeg = degree(col, x.size(0), dtype=x.dtype)deg_inv_sqrt = deg.pow(-0.5)norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]# Step 4-5: Start propagating messages.adjmat = SparseTensor(row=edge_index[0], col=edge_index[1], value=torch.ones(edge_index.shape[1]))# 此处传的不再是edge_idex,而是SparseTensor类型的Adjancency Matrixreturn self.propagate(adjmat, x=x, norm=norm, deg=deg.view((-1, 1)))def message(self, x_j, norm, deg_i):# x_j has shape [E, out_channels]# deg_i has shape [E, 1]# Step 4: Normalize node features.return norm.view(-1, 1) * x_j * deg_idef aggregate(self, inputs, index, ptr, dim_size):print('self.aggr:', self.aggr)print("`aggregate` is called")return super().aggregate(inputs, index, ptr=ptr, dim_size=dim_size)def message_and_aggregate(self, adj_t, x, norm):print('`message_and_aggregate` is called')# 没有实现真实的消息传递与消息聚合的操作from torch_geometric.datasets import Planetoiddataset = Planetoid(root='dataset', name='Cora')
data = dataset[0]net = GCNConv(data.num_features, 64)
h_nodes = net(data.x, data.edge_index)
# print(h_nodes.shape)
运行程序后我们可以看到,虽然我们同时覆写了message方法和aggregate方法,然而只有message_and_aggregate方法被执行。
update方法的覆写
from torch_geometric.datasets import Planetoid
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
from torch_sparse import SparseTensorclass GCNConv(MessagePassing):def __init__(self, in_channels, out_channels):super(GCNConv, self).__init__(aggr='add', flow='source_to_target')# "Add" aggregation (Step 5).# flow='source_to_target' 表示消息从源节点传播到目标节点self.lin = torch.nn.Linear(in_channels, out_channels)def forward(self, x, edge_index):# x has shape [N, in_channels]# edge_index has shape [2, E]# Step 1: Add self-loops to the adjacency matrix.edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))# Step 2: Linearly transform node feature matrix.x = self.lin(x)# Step 3: Compute normalization.row, col = edge_indexdeg = degree(col, x.size(0), dtype=x.dtype)deg_inv_sqrt = deg.pow(-0.5)norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]# Step 4-5: Start propagating messages.adjmat = SparseTensor(row=edge_index[0], col=edge_index[1], value=torch.ones(edge_index.shape[1]))# 此处传的不再是edge_idex,而是SparseTensor类型的Adjancency Matrixreturn self.propagate(adjmat, x=x, norm=norm, deg=deg.view((-1, 1)))def message(self, x_j, norm, deg_i):# x_j has shape [E, out_channels]# deg_i has shape [E, 1]# Step 4: Normalize node features.return norm.view(-1, 1) * x_j * deg_idef aggregate(self, inputs, index, ptr, dim_size):print('self.aggr:', self.aggr)print("`aggregate` is called")return super().aggregate(inputs, index, ptr=ptr, dim_size=dim_size)def message_and_aggregate(self, adj_t, x, norm):print('`message_and_aggregate` is called')# 没有实现真实的消息传递与消息聚合的操作def update(self, inputs, deg):print(deg)return inputsdataset = Planetoid(root='dataset', name='Cora')
data = dataset[0]net = GCNConv(data.num_features, 64)
h_nodes = net(data.x, data.edge_index)
# print(h_nodes.shape)
update方法接收聚合的输出作为第一个参数,此外还可以接收传递给propagate方法的任何参数。在上方的代码中,我们覆写的update方法接收了聚合的输出作为第一个参数,此外接收了传递给propagate的deg参数。
相关文章:
GNN系统学习:消息传递图神经网络
引言 在开篇中我们介绍了,为节点生成节点表征(Node Representation)是图计算任务成功的关键,我们要利用神经网络来学习节点表征。 消息传递范式是一种聚合邻接节点信息来更新中心节点信息的范式,它将卷积算子推广到了…...

基于gewe制作第一个微信聊天机器人
现在我们制作一个微信智能聊天机器人。发送文字它可以回复一段话,或一张图片,是不是有点小酷! 当然,这种智能回复的算法和数据库我们自己肯定是没有的,所以我们借助于gewe框架的开放API接口来完成我们的功能。 请求参…...

【Python】python使用Moviepy库对mp3文件进行剪切,并设置输出文件的码率
【Python】python使用Moviepy库对mp3文件进行剪切,设置输出文件的码率 一、安装Moviepy库二、代码 一、安装Moviepy库 pip install -i https://mirrors.aliyun.com/pypi/simple/ moviepy二、代码 #!/usr/bin/python # -*- coding: UTF-8 -*- from moviepy.editor …...

海外云手机在出海业务中的优势有哪些?
随着互联网技术的快速发展,海外云手机已在出海电商、海外媒体推广和游戏行业都拥有广泛的应用。对于国内的出海电商企业来说,短视频引流和社交平台推广是带来有效流量的重要手段。借助云手机,企业能够更高效地在新兴社交平台上推广产品和品牌…...
这10款PDF转Word在线转换工具的个人使用经历!!
身为现代办公室中的一位经常需要处理各种文件格式的牛马,在PDF和Word之间转换文件是我时常要处理的事。我试过不少PDF转Word的在线工具,前前后后尝试了10款左右的PDF转word转换工具,其中有四大霸主,深深占据了我对这方面的印象。下…...

认识QT以及QT的环境搭建
认识QT 什么是QT? Qt 是⼀个 跨平台的 C 图形⽤⼾界⾯应⽤程序框架 。 认识客户端 现在我们所说的客户端开发其实大致分为三种: 1.网页前端开发。 2.桌面应用开发(电脑的应用层序) 3.移动应用开发。 而我们的QT的主战场就是在…...

Rollup failed to resolve import “destr“ from ***/node_modules/pinia-plugin-pers
在使用uni-appvuu3piniapinia-plugin-persistedstate开发中, 使用pinia-plugin-persistedstate 一直在报错,其实代码也是比较简单的, import { createPinia } from pinia // 创建 pinia 实例 const pinia createPinia(); import piniaPlugi…...

Python小白学习教程从入门到入坑------第三十课 文件定位操作(语法进阶)
一、文件指针 python中严格来说没有指针这个说法,但有指针这个用法的体现。指针概念常用于c语言、c语言中 在Python的文件操作中,文件指针(也称为文件游标或文件句柄的位置)是一个内部标记,它指示了当前文件操作的读…...
人工智能、机器学习与深度学习:层层递进的技术解读
引言 在当今科技快速发展的时代,人工智能(AI)已经成为一个热门话题,几乎渗透到了我们生活的方方面面。从智能手机的语音助手,到自动驾驶汽车,再到医疗诊断中的图像识别,人工智能的应用正在改变我…...

Code Inspector——页面开发提效的神器
写在前面 优点: 开发提效:点击页面上的 DOM 元素,它能自动打开 IDE 并将光标定位至 DOM 的源代码位置,大幅提升开发体验和效率简单易用:对源代码无任何侵入,只需要在打包工具中引入就能够生效,…...

如何定制RockyLinux ISO
目标 基于Rocky9官方ISO做定制,构建自己的ISO 可以添加非官方预装的RPM包实现Kickstart自动化安装, 完成分区等操作ISO安装后,可以执行自定义脚本,比如安装你手动添加的RPM包 Rocky9 官方ISO内容分析 挂载Rocky9 ISO,得到如下…...

python基于深度学习的音乐推荐方法研究系统
需求设计 一款好的音乐推荐系统其目的是为用户进行合理的音乐推荐,普通的用户在登录到系统之后,能够通过搜索的方式获取与输入内容相关的音乐推荐,而以管理员登录到系统之后,则可以进行徐昂管的数据管理等内容操作。此次的需求主…...
)
机器学习系列----介绍前馈神经网络和卷积神经网络 (CNN)
前言 在深度学习领域,神经网络是一种模拟人脑神经元结构和功能的数学模型。它通过大量的层次结构和参数调整来实现模式识别、分类、回归等任务。常见的神经网络结构有前馈神经网络(Feedforward Neural Networks,简称 FNN)和卷积神…...

vue.js组件和传值以及微信小程序组件和传值
微信小程序组件以及vue.js组件 一.微信小程序组件引用1.创建组件Component2.页面组件引用3.组件传值3.1 父视图传值到子组件 (父---->子)3.2 子组件传值给父组件 (子---->父)3.3 父组件方法传递到子组件 4. 界面之间的传值4.1 正向传值4.2 反向传值…...
)
c语言编程题(函数)
1编写函数将一个仅包含整数(可能为负)的字符串转换为对应的整数 方法一使用标准库函数 atoi atoi 函数是C语言标准库中的一个函数,用于将字符串转换为整数。 代码: #include <stdio.h> #include <stdlib.h> // 包含…...

华为eNSP:QinQ
一、什么是QinQ? QinQ是一种网络技术,全称为"Quantum Insertion",也被称为"Q-in-Q"、"Double Tagging"或"VLAN stacking"。它是一种在现有的VLAN(Virtual Local Area Network࿰…...

JAVA基础-多线程线程池
文章目录 1. 多线程1.1什么是多线程(1)并发和并行(2)进程和线程 1.2多线程的实现方式1.2.1 方式一:继承Thread类1.2.2 方式二:实现Runnable接口1.2.3方式三: 实现Callable接口 1.3 常见的成员方法1.3.1 设置…...

HarmonyOS 沉浸式状态实现的多种方式
1. HarmonyOS 沉浸式状态实现的多种方式 HarmonyOS 沉浸式状态实现的多种方式 1.1. 方法一 1.1.1. 实现讲解 (1)首先设置setWindowLayoutFullScreen(true)(设置全屏布局)。 布局将从屏幕最顶部开始到最底部结束,…...

Python3.11.9下载和安装
Python3.11.9下载和安装 1、下载 下载地址:https://www.python.org/downloads/windows/ 选择版本下载,例如:Python 3.11.9 - April 2, 2024 2、安装 双击exe安装 3、配置环境变量 pathD:\Program Files\python3.11.9...
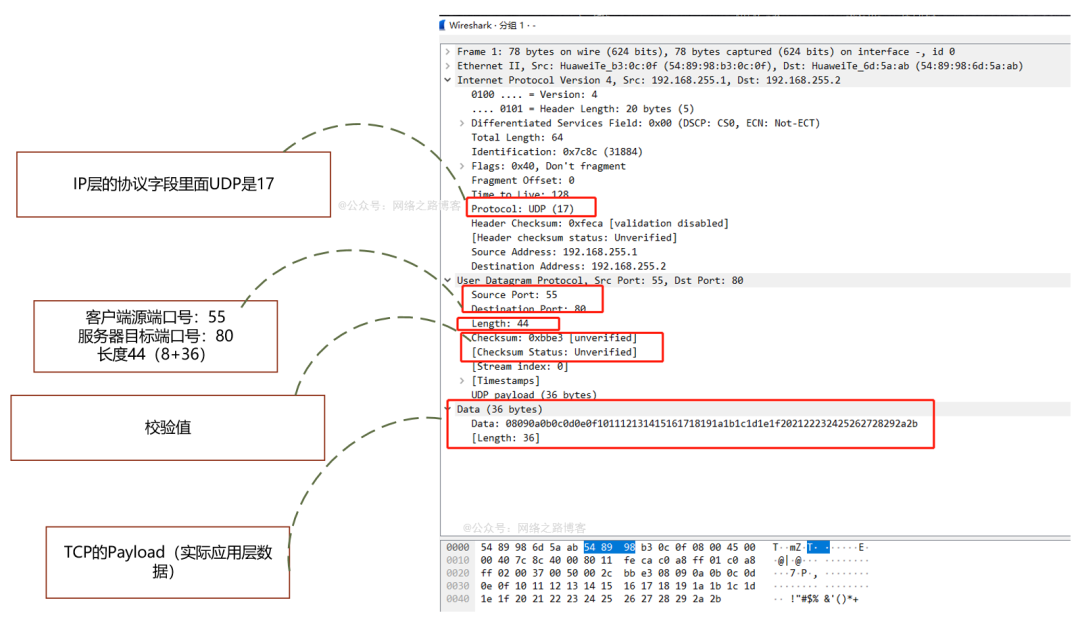
简简单单的UDP
前言 上一篇了解了TCP的三次握手过程,目的、以及如何保证可靠性、序列号与ACK的作用,最后离开的时候四次挥手的内容,这还只是TCP内容中的冰山一角,是不是觉得TCP这个协议非常复杂,这一篇我们来了解下传输层另外一个协…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

LOOI机器人的技术实现解析:从手势识别到边缘检测
LOOI机器人作为一款创新的AI硬件产品,通过将智能手机转变为具有情感交互能力的桌面机器人,展示了前沿AI技术与传统硬件设计的完美结合。作为AI与玩具领域的专家,我将全面解析LOOI的技术实现架构,特别是其手势识别、物体识别和环境…...

全面解析数据库:从基础概念到前沿应用
在数字化时代,数据已成为企业和社会发展的核心资产,而数据库作为存储、管理和处理数据的关键工具,在各个领域发挥着举足轻重的作用。从电商平台的商品信息管理,到社交网络的用户数据存储,再到金融行业的交易记录处理&a…...

高防服务器价格高原因分析
高防服务器的价格较高,主要是由于其特殊的防御机制、硬件配置、运营维护等多方面的综合成本。以下从技术、资源和服务三个维度详细解析高防服务器昂贵的原因: 一、硬件与技术投入 大带宽需求 DDoS攻击通过占用大量带宽资源瘫痪目标服务器,因此…...

aardio 自动识别验证码输入
技术尝试 上周在发学习日志时有网友提议“在网页上识别验证码”,于是尝试整合图像识别与网页自动化技术,完成了这套模拟登录流程。核心思路是:截图验证码→OCR识别→自动填充表单→提交并验证结果。 代码在这里 import soImage; import we…...