机器学习(基础1)
数据集
sklearn玩具数据集
数据量小,数据在sklearn库的本地,只要安装了sklearn,不用上网就可以获取

sklearn现实世界数据集
数据量大,数据只能通过网络获取(为国外数据集,下载需要梯子)

sklearn加载玩具数据集
示例:获取鸢尾花数据
以鸢尾花数据集为例:
from sklearn.datasets import load_iris
iris = load_iris() # 鸢尾花数据
print(iris.data) # 特征数据
print(iris.feature_names) # 特征描述
print(iris.target) # 目标形状
print(iris.target_names) # 目标描述
![]()


特征有:
花萼长 sepal length;花萼宽sepal width; 花瓣长 petal length;花瓣宽 petal width。
三分类:
0-Setosa山鸢尾
1-Versicolour变色鸢尾
2-Virginica维吉尼亚鸢尾
可使用numpy,pandas将特征和目标一起显示出来
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
feature = iris.data
target = iris.target
target.shape = (len(target),1)
data = np.hstack([feature,target])
cols = iris.feature_names
cols.append('target')
arr = pd.DataFrame(data,columns=cols)
print(arr)

sklearn获取现实世界数据集
所有现实世界数据,通过网络才能下载后,默认保存的目录可以使用下面api获取。实际上就是保存到home目录
from sklearn import datasets
datasets.get_data_home() #查看数据集默认存放的位置获取现实世界数据需要"科学上网"。
示例:获取20分类新闻数据
from sklearn.datasets import fetch_20newsgroups #这是一个20分类的数据
news = fetch_20newsgroups(data_home='./src',subset='all')
print(len(news.data)) #18846
print(news.target.shape) #(18846,)
print(len(news.target_names)) #20
print(len(news.filenames)) #18846本地csv数据
创建csv文件
方式1:打开计事本,写出如下数据,数据之间使用英文下的逗号, 保存文件后把后缀名改为csv
csv文件可以使用excel打开

方式2:创建excel 文件, 填写数据,以csv为后缀保存文件.

pandas加载csv
使用pandas的read_csv(“文件路径”)函数可以加载csv文件,得到的结果为数据的DataFrame形式
语法:
pd.read_csv("./src/ss.csv")

数据集的划分
(1) 函数
sklearn.model_selection.train_test_split(*arrays,**options)
参数
(1) *array
这里用于接收1到多个"列表、numpy数组、稀疏矩阵或padas中的DataFrame"。
(2) **options, 重要的关键字参数有:
test_size 值为0.0到1.0的小数,表示划分后测试集占的比例
random_state 值为任意整数,表示随机种子,使用相同的随机种子对相同的数据集多次划分结果是相同的。否则多半不同
2 返回值说明
返回值为列表list, 列表长度与形参array接收到的参数数量相关联, 形参array接收到的是什么类型,list中对应被划分出来的两部分就是什么类型
(2)示例
列表数据集划分
因为随机种子都使用了相同的整数(22),所以划分的划分的情况是相同的。
示例:
from sklearn.model_selection import train_test_split
data1 = [1,2,3,4,5]
data2 = ['1a','2a','3a','4a','5a']
a,b = train_test_split(data1,train_size=0.8,random_state=22)
print(a,b)a,b = train_test_split(data2,train_size=0.8,random_state=22)
print(a,b)x_train,x_test,y_train,y_test = train_test_split(data1,data2,train_size=0.8,random_state=22)
print(x_train,x_test)
print(y_train,y_test)
当train_test_split函数参数传入两个data时,会将两个data,按照二八分,分割的值也是对应起来的,如,data1和data2中,1对应1a,2对应2a,分割后,也是相对应得
ndarray数据集划分
划分前和划分后的数据类型是相同的 data1为list,划分后的a、b也是list data2为ndarray,划分后的c、d也是ndarray
from sklearn.model_selection import train_test_split
import numpy as np
data1 = [1,2,3,4,5]
data2 = np.array(['1a','2a','3a','4a','5a'])
x_train,x_test,y_train,y_test = train_test_split(data1,data2,train_size=0.8,random_state=22)
print(x_train,x_test)
print(y_train,y_test)
print(type(x_train),type(x_test),type(y_train),type(y_test))
二维数组数据集划分
train_test_split只划分第一维度,第二维度保持不变
from sklearn.model_selection import train_test_split
import numpy as np
data1 = np.arange(1,16,1)
data1.shape = (5,3)
print(data1)
x_train,x_test = train_test_split(data1,train_size=0.8,random_state=22)
print('x_train=\n',x_train)
print('x_test=\n',x_test)
DataFrame数据集划分
可以划分DataFrame, 划分后的两部分还是DataFrame
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
data1 = np.arange(1,16,1).reshape(5,3)
data1 = pd.DataFrame(data1,index=[1,2,3,4,5],columns=['one','two','three'])
print(data1)x_train,x_test = train_test_split(data1,train_size=0.8,random_state=22)
print(x_train)
print(x_test)


字典数据集划分
可以划分非稀疏矩阵
用于将字典列表转换为特征向量。这个转换器主要用于处理类别数据和数值数据的混合型数据集
1.对于类别特征DictVectorizer 会为每个不同的类别创建一个新的二进制特征,如果原始数据中的某个样本具有该类别,则对应的二进制特征值为1,否则为0。
2.对于数值特征保持不变,直接作为特征的一部分
示例:
from sklearn.feature_extraction import DictVectorizer
data = [{'city':'成都', 'age':30, 'temperature':20}, {'city':'重庆','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80},{'city':'上海', 'age':22, 'temperature':70},{'city':'成都', 'age':72, 'temperature':40},]
model = DictVectorizer(sparse=False)#sparse=False表示返回一个完整的矩阵,sparse=True表示返回一个稀疏矩阵
data1 = model.fit_transform(data)#提取特征
print('data:\n',data1)x_train,x_test = train_test_split(data1,train_size=0.8,random_state=22)
print('x_train:\n',x_train)
print('x_test:\n',x_train)print(type(x_train),type(x_test))

![]()
鸢尾花数据集划分
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
list = train_test_split(iris.data,iris.target,train_size=0.8,random_state=22)
x_train,x_test,y_train,y_test = list
print(x_train.shape,x_test.shape,y_train.shape,y_test.shape)
现实世界数据集划分
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_20newsgroups
import numpy as np
news = fetch_20newsgroups(data_home='./src',subset='all')
list = train_test_split(news.data,news.target,train_size=0.8,random_state=22)
x_train,x_test,y_train,y_test = list
print(len(x_train), len(x_test), y_train.shape, y_test.shape)![]()
相关文章:

机器学习(基础1)
数据集 sklearn玩具数据集 数据量小,数据在sklearn库的本地,只要安装了sklearn,不用上网就可以获取 sklearn现实世界数据集 数据量大,数据只能通过网络获取(为国外数据集,下载需要梯子) skle…...

我谈维纳(Wiener)复原滤波器
Rafael Gonzalez的《数字图像处理》中,图像复原这章内容几乎全错。上篇谈了图像去噪,这篇谈图像复原。 图像复原也称为盲解卷积,不处理点扩散函数(光学传递函数)的都不是图像复原。几何校正不属于图像复原,…...

怎么看真假国企啊?怎么识别假冒国企的千层套路?
一、怎么看真假国企啊? 1.使用具有迷惑性的名称:假冒国企往往在名称中使用“中国”、“中”、“国”等字样,或与知名国企名称相似的字号,以增加其可信度。 2.注册资本虚高:为了显示实力,假冒国企可能会在…...

C#中break和continue的区别?
在C#编程语言中,break和continue是两个用于控制循环流程的关键字,但它们的作用和用途有所不同。 break关键字 break关键字用于立即终止它所在的最内层循环或switch语句,并跳出该循环或switch块。程序执行将继续进行循环或switch语句之后的下一…...

Linux部署nginx访问文件403
问题描述:在linux服务器上通过nginx部署,访问文件403 新配置了一个用户来部署服务,将部署文件更新到原有目录下,结果nginx访问403 原因:没有配置文件的读写权限,默认不可读写,nginx无法访问到文…...

华为OD机试 - 数字排列 - 深度优先搜索dfs算法(Python/JS/C/C++ 2024 C卷 200分)
华为OD机试 2024E卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试真题(Python/JS/C/C)》。 刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加入华为OD刷题交流群,…...

Scrapy爬取heima论坛所有页面内容并保存到数据库中
前期准备: Scrapy入门_win10安装scrapy-CSDN博客 新建 Scrapy项目 scrapy startproject mySpider03 # 项目名为mySpider03 进入到spiders目录 cd mySpider03/mySpider03/spiders 创建爬虫 scrapy genspider heima bbs.itheima.com # 爬虫名为heima &#…...

Kafka参数了解
Kafka配置参数完整说明 1. 基础配置 参数名说明推荐值参考值broker.idbroker的唯一标识符每个节点唯一的整数1delete.topic.enable是否允许删除topictruetruelistenersbroker监听地址SASL_PLAINTEXT://host:9092SASL_PLAINTEXT://172.24.77.15:9092advertised.listeners对外发…...

sql专题 之 where和join on
文章目录 前言where介绍使用过滤结果集关联两个表 连接外连接内连接自然连接 使用inner join和直接使用where关联两个表的区别总结 前言 从数据库查询数据时,一张表不足以查询到我们想要的数据,更多的时候我们需要联表查询。 联表查询我们一般会使用连接…...

day12:版本控制器
版本控制 使用到的命令: ls -al查看当前目录下的文件及文件夹mkdir新建目录rm -rf递归强制删除文件夹 一、安装配置 1、下载地址 Git 2、初始配置 #用户名 git config --global user.name "自定义用户名" #邮箱(公司的联系方式--追责&…...

第四十一章 Vue之初识VueX
目录 一、引言 1.1. vuex的概念 1.2. vuex使用场景 1.3. 优势 二、创建演示项目 2.1. 构建项目步骤 2.2. 项目最终生成结构 2.3. 创建项目文件 2.3.1. App.vue 2.3.2. Son1.vue 2.3.3. Son2.vue 三、创建一个空仓库 3.1. 安装vuex 3.2. 新建仓库 3.3. 挂载仓库…...
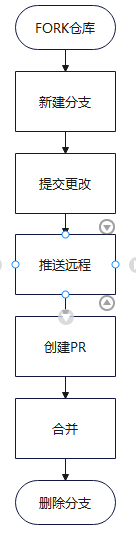
GIT的基本使用与进阶
GIT的简单入门 一.什么是git? Git 是一个开源的分布式版本控制系统,用于跟踪文件更改、管理代码版本以及协作开发。它主要由 Linus Torvalds 于 2005 年创建,最初是为 Linux 内核开发而设计的。如今,Git 已经成为现代软件开发中…...

【Linux系统】—— 基本指令(二)
【Linux系统】—— 基本指令(二) 1 「alias」命令1.1 「ll」命令1.2 「alias」命令 2 「rmdir」指令与「rm」指令2.1 「rmdir」2.2 「rm」2.2.1 「rm」 删除普通文件2.2.2 「rm」 删除目录2.2.3 『 * 』 通配符 3 「man」 指令4 「cp」 指令4.1 拷贝普通…...

MFC工控项目实例三十实现一个简单的流程
启动按钮夹紧 密闭,时间0到平衡 进气,时间1到进气关,时间2到平衡关 检测,时间3到平衡 排气,时间4到夹紧开、密闭开、排气关。 相关代码 void CSEAL_PRESSUREDlg::OnTimer_2(UINT nIDEvent_2) {// if (nIDEvent_21 &am…...

【Android、IOS、Flutter、鸿蒙、ReactNative 】文本点击事件
Android Studio 版本 Android Java TextView 实现 点击事件 参考 import androidx.appcompat.app.AppCompatActivity; import android.os.Bundle; import android.util.Log; import android.view.View; import android.widget.TextView; import android.widget.Toast;public c…...

json转excel,读取json文件写入到excel中【rust语言】
一、rust代码 将json文件写入到 excel中。(保持json :key原始顺序) use indexmap::IndexMap; use serde::Deserialize; use serde_json::{Value, from_str}; use std::error::Error; use std::io::{self, Write}; use std::path::{Path}; u…...

Java面试要点06 - static关键字、静态属性与静态方法
本文目录 一、引言二、静态属性(Static Fields)三、静态方法(Static Methods)四、静态代码块(Static Blocks)五、静态内部类(Static Nested Classes)六、静态导入(Static…...

动态规划-背包问题——416.分割等和子集
1.题目解析 题目来源 416.分割等和子集——力扣 测试用例 2.算法原理 1.状态表示 这里背包问题基本上和母题的思路大相径庭,母题请见 [模板]01.背包 ,这里的状态表示与装满背包的情况类似,第二个下标就是当选择的物品体积直接等于j时是否可…...

Pr:视频过渡快速参考(合集 · 2025版)
Adobe Premiere Pro 自带七组约四十多个视频过渡 Video Transitions效果,包含不同风格和用途,可在两个剪辑之间创造平滑、自然的转场,用来丰富时间、地点或情绪的变化。恰当地应用过渡可让观众更好地理解故事或人物。 提示: 点击下…...

网络安全---安全见闻2
网络安全—安全见闻 拓宽视野不仅能够丰富我们的知识体系,也是自我提升和深造学习的重要途径!!! 设备漏洞问题 操作系统漏洞 渗透测试视角:硬件设备上的操作系统可能存在各种漏洞,攻击者可以利用这些漏洞…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

从面试角度回答Android中ContentProvider启动原理
Android中ContentProvider原理的面试角度解析,分为已启动和未启动两种场景: 一、ContentProvider已启动的情况 1. 核心流程 触发条件:当其他组件(如Activity、Service)通过ContentR…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...