深度学习之循环神经网络(RNN)
1 为什么需要RNN?
时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。一般的神经网络,在训练数据足够、算法模型优越的情况下,给定特定的x,就能得到期望y。其一般处理单个的输入,前一个输入和后一个输入完全无关,但实际应用中,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。比如:
当我们在理解一句话意思时,孤立的理解这句话的每个词不足以理解整体意思,我们通常需要处理这些词连接起来的整个序列; 当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN就由此诞生了。
2 图解RNN基本结构
2.1 基本的单层网络结构
在进一步了解RNN之前,先给出最基本的单层网络结构,输入是$x$,经过变换Wx+b和激活函数f得到输出y:

2.2 图解经典RNN结构
在实际应用中,我们还会遇到很多序列形的数据,如:
-
自然语言处理问题。x1可以看做是第一个单词,x2可以看做是第二个单词,依次类推。
-
语音处理。此时,x1、x2、x3……是每帧的声音信号。
-
时间序列问题。例如每天的股票价格等等。
其单个序列如下图所示:

前面介绍了诸如此类的序列数据用原始的神经网络难以建模,基于此,RNN引入了隐状态 h h h(hidden state), h h h可对序列数据提取特征,接着再转换为输出。
为了便于理解,先计算 h 1 h_1 h1:

注:图中的圆圈表示向量,箭头表示对向量做变换。
RNN中,每个步骤使用的参数
$U,W,b$相同,$h_2$的计算方式和$h_1$类似,其计算结果如下:
计算 h 3 h_3 h3, h 4 h_4 h4也相似,可得:

接下来,计算RNN的输出 y 1 y_1 y1,采用 S o f t m a x Softmax Softmax作为激活函数,根据 y n = f ( W x + b ) y_n=f(Wx+b) yn=f(Wx+b),得 y 1 y_1 y1:

使用和 y 1 y_1 y1相同的参数 V , c V,c V,c,得到 y 1 , y 2 , y 3 , y 4 y_1,y_2,y_3,y_4 y1,y2,y3,y4的输出结构:

以上即为最经典的RNN结构,其输入为 x 1 , x 2 , x 3 , x 4 x_1,x_2,x_3,x_4 x1,x2,x3,x4,输出为 y 1 , y 2 , y 3 , y 4 y_1,y_2,y_3,y_4 y1,y2,y3,y4,当然实际中最大值为 y n y_n yn,这里为了便于理解和展示,只计算4个输入和输出。从以上结构可看出,RNN结构的输入和输出等长。
2.3 vector-to-sequence结构
有时我们要处理的问题输入是一个单独的值,输出是一个序列。此时,有两种主要建模方式:
方式一:可只在其中的某一个序列进行计算,比如序列第一个进行输入计算,其建模方式如下:

方式二:把输入信息X作为每个阶段的输入,其建模方式如下:

2.4 sequence-to-vector结构
有时我们要处理的问题输入是一个序列,输出是一个单独的值,此时通常在最后的一个序列上进行输出变换,其建模如下所示:

2.5 Encoder-Decoder结构
原始的sequence-to-sequence结构的RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
其建模步骤如下:
步骤一:将输入数据编码成一个上下文向量 c c c,这部分称为Encoder,得到 c c c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给 c c c,还可以对最后的隐状态做一个变换得到 c c c,也可以对所有的隐状态做变换。其示意如下所示:

步骤二:用另一个RNN网络(我们将其称为Decoder)对其进行编码,方法一是将步骤一中的 c c c作为初始状态输入到Decoder,示意图如下所示:

方法二是将 c c c作为Decoder的每一步输入,示意图如下所示:

2.6 以上三种结构各有怎样的应用场景
| 网络结构 | 结构图示 | 应用场景举例 |
|---|---|---|
| 1 vs N |  | 1. 从图像生成文字,输入为图像的特征,输出为一段句子 2. 根据图像生成语音或音乐,输入为图像特征,输出为一段语音或音乐 |
| N vs 1 |  | 1. 输出一段文字,判断其所属类别 2. 输入一个句子,判断其情感倾向 3. 输入一段视频,判断其所属类别 |
| N vs M |  | 1. 机器翻译,输入一种语言文本序列,输出另外一种语言的文本序列 2. 文本摘要,输入文本序列,输出这段文本序列摘要 3. 阅读理解,输入文章,输出问题答案 4. 语音识别,输入语音序列信息,输出文字序列 |
2.7 图解RNN中的Attention机制
在上述通用的Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征 c c c再解码,因此, c c c中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个 c c c可能存不下那么多信息,就会造成翻译精度的下降。Attention机制通过在每个时间输入不同的 c c c来解决此问题。
引入了Attention机制的Decoder中,有不同的 c c c,每个 c c c会自动选择与当前输出最匹配的上下文信息,其示意图如下所示:

举例,比如输入序列是“我爱中国”,要将此输入翻译成英文:
假如用 a i j a_{ij} aij衡量Encoder中第 j j j阶段的 h j h_j hj和解码时第 i i i阶段的相关性, a i j a_{ij} aij从模型中学习得到,和Decoder的第 i − 1 i-1 i−1阶段的隐状态、Encoder 第 j j j个阶段的隐状态有关,比如 a 3 j a_{3j} a3j的计算示意如下所示:

最终Decoder中第 i i i阶段的输入的上下文信息 c i c_i ci来自于所有 h j h_j hj对 a i j a_{ij} aij的加权和。
其示意图如下图所示:

在Encoder中, h 1 , h 2 , h 3 , h 4 h_1,h_2,h_3,h_4 h1,h2,h3,h4分别代表“我”,“爱”,“中”,“国”所代表信息。翻译的过程中, c 1 c_1 c1会选择和“我”最相关的上下午信息,如上图所示,会优先选择 a 11 a_{11} a11,以此类推, c 2 c_2 c2会优先选择相关性较大的 a 22 a_{22} a22, c 3 c_3 c3会优先选择相关性较大的 a 33 , a 34 a_{33},a_{34} a33,a34,这就是attention机制。
3 RNNs典型特点?
- RNNs主要用于处理序列数据。对于传统神经网络模型,从输入层到隐含层再到输出层,层与层之间一般为全连接,每层之间神经元是无连接的。但是传统神经网络无法处理数据间的前后关联问题。例如,为了预测句子的下一个单词,一般需要该词之前的语义信息。这是因为一个句子中前后单词是存在语义联系的。
- RNNs中当前单元的输出与之前步骤输出也有关,因此称之为循环神经网络。具体的表现形式为当前单元会对之前步骤信息进行储存并应用于当前输出的计算中。隐藏层之间的节点连接起来,隐藏层当前输出由当前时刻输入向量和之前时刻隐藏层状态共同决定。
- 标准的RNNs结构图,图中每个箭头代表做一次变换,也就是说箭头连接带有权值。
- 在标准的RNN结构中,隐层的神经元之间也是带有权值的,且权值共享。
- 理论上,RNNs能够对任何长度序列数据进行处理。但是在实践中,为了降低复杂度往往假设当前的状态只与之前某几个时刻状态相关,下图便是一个典型的RNNs:


输入单元(Input units):输入集 { x 0 , x 1 , . . . , x t , x t + 1 , . . . } \bigr\{x_0,x_1,...,x_t,x_{t+1},...\bigr\} {x0,x1,...,xt,xt+1,...},
输出单元(Output units):输出集 { y 0 , y 1 , . . . , y t , y y + 1 , . . . } \bigr\{y_0,y_1,...,y_t,y_{y+1},...\bigr\} {y0,y1,...,yt,yy+1,...},
隐藏单元(Hidden units):输出集 { s 0 , s 1 , . . . , s t , s t + 1 , . . . } \bigr\{s_0,s_1,...,s_t,s_{t+1},...\bigr\} {s0,s1,...,st,st+1,...}。
图中信息传递特点:
- 一条单向流动的信息流是从输入单元到隐藏单元。
- 一条单向流动的信息流从隐藏单元到输出单元。
- 在某些情况下,RNNs会打破后者的限制,引导信息从输出单元返回隐藏单元,这些被称为“Back Projections”。
- 在某些情况下,隐藏层的输入还包括上一时刻隐藏层的状态,即隐藏层内的节点可以自连也可以互连。
- 当前单元(cell)输出是由当前时刻输入和上一时刻隐藏层状态共同决定。
4 CNN和RNN的区别 ?
| 类别 | 特点描述 |
|---|---|
| 相同点 | 1、传统神经网络的扩展。 2、前向计算产生结果,反向计算模型更新。 3、每层神经网络横向可以多个神经元共存,纵向可以有多层神经网络连接。 |
| 不同点 | 1、CNN空间扩展,神经元与特征卷积;RNN时间扩展,神经元与多个时间输出计算 2、RNN可以用于描述时间上连续状态的输出,有记忆功能,CNN用于静态输出 |
5 RNNs和FNNs有什么区别?
- 不同于传统的前馈神经网络(FNNs),RNNs引入了定向循环,能够处理输入之间前后关联问题。
- RNNs可以记忆之前步骤的训练信息。
定向循环结构如下图所示:

6.6 RNNs训练和传统ANN训练异同点?
相同点:
- RNNs与传统ANN都使用BP(Back Propagation)误差反向传播算法。
不同点:
- RNNs网络参数W,U,V是共享的(具体在本章6.2节中已介绍),而传统神经网络各层参数间没有直接联系。
- 对于RNNs,在使用梯度下降算法中,每一步的输出不仅依赖当前步的网络,还依赖于之前若干步的网络状态。
7 为什么RNN 训练的时候Loss波动很大
由于RNN特有的memory会影响后期其他的RNN的特点,梯度时大时小,learning rate没法个性化的调整,导致RNN在train的过程中,Loss会震荡起伏,为了解决RNN的这个问题,在训练的时候,可以设置临界值,当梯度大于某个临界值,直接截断,用这个临界值作为梯度的大小,防止大幅震荡。
8 标准RNN前向输出流程
以 x x x表示输入, h h h是隐层单元, o o o是输出, L L L为损失函数, y y y为训练集标签。 t t t表示 t t t时刻的状态, V , U , W V,U,W V,U,W是权值,同一类型的连接权值相同。以下图为例进行说明标准RNN的前向传播算法:

对于 t t t时刻:
h ( t ) = ϕ ( U x ( t ) + W h ( t − 1 ) + b ) h^{(t)}=\phi(Ux^{(t)}+Wh^{(t-1)}+b) h(t)=ϕ(Ux(t)+Wh(t−1)+b)
其中 ϕ ( ) \phi() ϕ()为激活函数,一般会选择tanh函数, b b b为偏置。
t t t时刻的输出为:
o ( t ) = V h ( t ) + c o^{(t)}=Vh^{(t)}+c o(t)=Vh(t)+c
模型的预测输出为:
y ^ ( t ) = σ ( o ( t ) ) \widehat{y}^{(t)}=\sigma(o^{(t)}) y (t)=σ(o(t))
其中 σ \sigma σ为激活函数,通常RNN用于分类,故这里一般用softmax函数。
9 BPTT算法推导
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。需要寻优的参数有三个,分别是U、V、W。与BP算法不同的是,其中W和U两个参数的寻优过程需要追溯之前的历史数据,参数V相对简单只需关注目前,那么我们就来先求解参数V的偏导数。
∂ L ( t ) ∂ V = ∂ L ( t ) ∂ o ( t ) ⋅ ∂ o ( t ) ∂ V \frac{\partial L^{(t)}}{\partial V}=\frac{\partial L^{(t)}}{\partial o^{(t)}}\cdot \frac{\partial o^{(t)}}{\partial V} ∂V∂L(t)=∂o(t)∂L(t)⋅∂V∂o(t)
RNN的损失也是会随着时间累加的,所以不能只求t时刻的偏导。
L = ∑ t = 1 n L ( t ) L=\sum_{t=1}^{n}L^{(t)} L=t=1∑nL(t)
∂ L ∂ V = ∑ t = 1 n ∂ L ( t ) ∂ o ( t ) ⋅ ∂ o ( t ) ∂ V \frac{\partial L}{\partial V}=\sum_{t=1}^{n}\frac{\partial L^{(t)}}{\partial o^{(t)}}\cdot \frac{\partial o^{(t)}}{\partial V} ∂V∂L=t=1∑n∂o(t)∂L(t)⋅∂V∂o(t)
W和U的偏导的求解由于需要涉及到历史数据,其偏导求起来相对复杂。为了简化推导过程,我们假设只有三个时刻,那么在第三个时刻 L对W,L对U的偏导数分别为:
∂ L ( 3 ) ∂ W = ∂ L ( 3 ) ∂ o ( 3 ) ∂ o ( 3 ) ∂ h ( 3 ) ∂ h ( 3 ) ∂ W + ∂ L ( 3 ) ∂ o ( 3 ) ∂ o ( 3 ) ∂ h ( 3 ) ∂ h ( 3 ) ∂ h ( 2 ) ∂ h ( 2 ) ∂ W + ∂ L ( 3 ) ∂ o ( 3 ) ∂ o ( 3 ) ∂ h ( 3 ) ∂ h ( 3 ) ∂ h ( 2 ) ∂ h ( 2 ) ∂ h ( 1 ) ∂ h ( 1 ) ∂ W \frac{\partial L^{(3)}}{\partial W}=\frac{\partial L^{(3)}}{\partial o^{(3)}}\frac{\partial o^{(3)}}{\partial h^{(3)}}\frac{\partial h^{(3)}}{\partial W}+\frac{\partial L^{(3)}}{\partial o^{(3)}}\frac{\partial o^{(3)}}{\partial h^{(3)}}\frac{\partial h^{(3)}}{\partial h^{(2)}}\frac{\partial h^{(2)}}{\partial W}+\frac{\partial L^{(3)}}{\partial o^{(3)}}\frac{\partial o^{(3)}}{\partial h^{(3)}}\frac{\partial h^{(3)}}{\partial h^{(2)}}\frac{\partial h^{(2)}}{\partial h^{(1)}}\frac{\partial h^{(1)}}{\partial W} ∂W∂L(3)=∂o(3)∂L(3)∂h(3)∂o(3)∂W∂h(3)+∂o(3)∂L(3)∂h(3)∂o(3)∂h(2)∂h(3)∂W∂h(2)+∂o(3)∂L(3)∂h(3)∂o(3)∂h(2)∂h(3)∂h(1)∂h(2)∂W∂h(1)
∂ L ( 3 ) ∂ U = ∂ L ( 3 ) ∂ o ( 3 ) ∂ o ( 3 ) ∂ h ( 3 ) ∂ h ( 3 ) ∂ U + ∂ L ( 3 ) ∂ o ( 3 ) ∂ o ( 3 ) ∂ h ( 3 ) ∂ h ( 3 ) ∂ h ( 2 ) ∂ h ( 2 ) ∂ U + ∂ L ( 3 ) ∂ o ( 3 ) ∂ o ( 3 ) ∂ h ( 3 ) ∂ h ( 3 ) ∂ h ( 2 ) ∂ h ( 2 ) ∂ h ( 1 ) ∂ h ( 1 ) ∂ U \frac{\partial L^{(3)}}{\partial U}=\frac{\partial L^{(3)}}{\partial o^{(3)}}\frac{\partial o^{(3)}}{\partial h^{(3)}}\frac{\partial h^{(3)}}{\partial U}+\frac{\partial L^{(3)}}{\partial o^{(3)}}\frac{\partial o^{(3)}}{\partial h^{(3)}}\frac{\partial h^{(3)}}{\partial h^{(2)}}\frac{\partial h^{(2)}}{\partial U}+\frac{\partial L^{(3)}}{\partial o^{(3)}}\frac{\partial o^{(3)}}{\partial h^{(3)}}\frac{\partial h^{(3)}}{\partial h^{(2)}}\frac{\partial h^{(2)}}{\partial h^{(1)}}\frac{\partial h^{(1)}}{\partial U} ∂U∂L(3)=∂o(3)∂L(3)∂h(3)∂o(3)∂U∂h(3)+∂o(3)∂L(3)∂h(3)∂o(3)∂h(2)∂h(3)∂U∂h(2)+∂o(3)∂L(3)∂h(3)∂o(3)∂h(2)∂h(3)∂h(1)∂h(2)∂U∂h(1)
可以观察到,在某个时刻的对W或是U的偏导数,需要追溯这个时刻之前所有时刻的信息。根据上面两个式子得出L在t时刻对W和U偏导数的通式:
∂ L ( t ) ∂ W = ∑ k = 0 t ∂ L ( t ) ∂ o ( t ) ∂ o ( t ) ∂ h ( t ) ( ∏ j = k + 1 t ∂ h ( j ) ∂ h ( j − 1 ) ) ∂ h ( k ) ∂ W \frac{\partial L^{(t)}}{\partial W}=\sum_{k=0}^{t}\frac{\partial L^{(t)}}{\partial o^{(t)}}\frac{\partial o^{(t)}}{\partial h^{(t)}}(\prod_{j=k+1}^{t}\frac{\partial h^{(j)}}{\partial h^{(j-1)}})\frac{\partial h^{(k)}}{\partial W} ∂W∂L(t)=k=0∑t∂o(t)∂L(t)∂h(t)∂o(t)(j=k+1∏t∂h(j−1)∂h(j))∂W∂h(k)
∂ L ( t ) ∂ U = ∑ k = 0 t ∂ L ( t ) ∂ o ( t ) ∂ o ( t ) ∂ h ( t ) ( ∏ j = k + 1 t ∂ h ( j ) ∂ h ( j − 1 ) ) ∂ h ( k ) ∂ U \frac{\partial L^{(t)}}{\partial U}=\sum_{k=0}^{t}\frac{\partial L^{(t)}}{\partial o^{(t)}}\frac{\partial o^{(t)}}{\partial h^{(t)}}(\prod_{j=k+1}^{t}\frac{\partial h^{(j)}}{\partial h^{(j-1)}})\frac{\partial h^{(k)}}{\partial U} ∂U∂L(t)=k=0∑t∂o(t)∂L(t)∂h(t)∂o(t)(j=k+1∏t∂h(j−1)∂h(j))∂U∂h(k)
整体的偏导公式就是将其按时刻再一一加起来。
9 RNN中为什么会出现梯度消失?
首先来看tanh函数的函数及导数图如下所示:

sigmoid函数的函数及导数图如下所示:

从上图观察可知,sigmoid函数的导数范围是(0,0.25],tanh函数的导数范围是(0,1],他们的导数最大都不大于1。
基于6.8中式(9-10)中的推导,RNN的激活函数是嵌套在里面的,如果选择激活函数为 t a n h tanh tanh或 s i g m o i d sigmoid sigmoid,把激活函数放进去,拿出中间累乘的那部分可得:
∏ j = k + 1 t ∂ h j ∂ h j − 1 = ∏ j = k + 1 t t a n h ′ ⋅ W s \prod_{j=k+1}^{t}{\frac{\partial{h^{j}}}{\partial{h^{j-1}}}} = \prod_{j=k+1}^{t}{tanh^{'}}\cdot W_{s} j=k+1∏t∂hj−1∂hj=j=k+1∏ttanh′⋅Ws
∏ j = k + 1 t ∂ h j ∂ h j − 1 = ∏ j = k + 1 t s i g m o i d ′ ⋅ W s \prod_{j=k+1}^{t}{\frac{\partial{h^{j}}}{\partial{h^{j-1}}}} = \prod_{j=k+1}^{t}{sigmoid^{'}}\cdot W_{s} j=k+1∏t∂hj−1∂hj=j=k+1∏tsigmoid′⋅Ws
梯度消失现象:基于上式,会发现累乘会导致激活函数导数的累乘,如果取tanh或sigmoid函数作为激活函数的话,那么必然是一堆小数在做乘法,结果就是越乘越小。随着时间序列的不断深入,小数的累乘就会导致梯度越来越小直到接近于0,这就是“梯度消失“现象。
实际使用中,会优先选择tanh函数,原因是tanh函数相对于sigmoid函数来说梯度较大,收敛速度更快且引起梯度消失更慢。
10 如何解决RNN中的梯度消失问题?
上节描述的梯度消失是在无限的利用历史数据而造成,但是RNN的特点本来就是能利用历史数据获取更多的可利用信息,解决RNN中的梯度消失方法主要有:
1、选取更好的激活函数,如Relu激活函数。ReLU函数的左侧导数为0,右侧导数恒为1,这就避免了“梯度消失“的发生。但恒为1的导数容易导致“梯度爆炸“,但设定合适的阈值可以解决这个问题。
2、加入BN层,其优点包括可加速收敛、控制过拟合,可以少用或不用Dropout和正则、降低网络对初始化权重不敏感,且能允许使用较大的学习率等。
2、改变传播结构,LSTM结构可以有效解决这个问题。
相关文章:
深度学习之循环神经网络(RNN)
1 为什么需要RNN? 时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。一般的神经网络,在训练数据足够、算法模型优越的情况下,给定特定的x,就能得到期望y。其一…...

Autosar CP Network Management模块规范导读
Network Management模块的主要功能 网络管理适配:作为通信管理器和总线特定网络管理模块之间的适配层,实现不同总线网络管理功能的统一接口,确保系统中各种网络的协同工作。协调功能 网络协调关闭:使用协调算法协调多个网络的关闭,确保它们在合适的时间同步进入睡眠模式,…...

Xshell 7 偏好设置
1 Xshell7 工具——更改用户数据文件夹 就是此电脑目录下的文档 该目录下的7 Xshell下的 applog ColorScheme Files 配色方案文件目录 HighlightSet Files 突出显示集目录 Logs 日志 QuickButton Files 快速命令集 Scripts 脚本文件 Sessions 会话文件 会话文件目录就…...

云计算答案
情境一习题练习 一、选择题 1、在虚拟机VMware软件中实现联网过程,图中箭头所指的网络连接方式与下列哪个相关( C )。 A.仅主机模式 B.桥接 C.NAT D.嫁接 2、请问下图这个虚拟化架构属于什么类型( A …...

浅谈现货白银与白银td的价格差异
西方资本主义世界崇尚自由经济,而我国实行社会主义市场经济,因此二者在金融系统上存在不少差异,反映在贵金属市场中,可能直接表现为价格上的差异。如果投资者对此能有基本的了解,日后面对交易中的特殊价格波动…...

【QT常用技术讲解】任务栏图标+socket网络服务+开机自启动
前言 首先看网络编程的定义:两个不同主机设备之间的进程通信。C/S(Client-Server)是早期非常典型的软件架构,C/S架构虽然简单,但却非常适用于桌面图形化的QT项目。 本篇的QT项目是从真实的项目中简化出来,满足很多相似的场景&…...

【计算机基础——数据结构——AVL平衡二叉树】
1. BST二叉查找树 1.1 BST二叉查找树的特性 左子树上所有结点的值均小于或等于它的根结点的值。右子树上所有结点的值均大于或等于它的根结点的值。左、右子树也分别为二叉排序树。 1.2 BST二叉查找树的缺点 二叉查找树是有缺点的,在不断插入的时候,…...
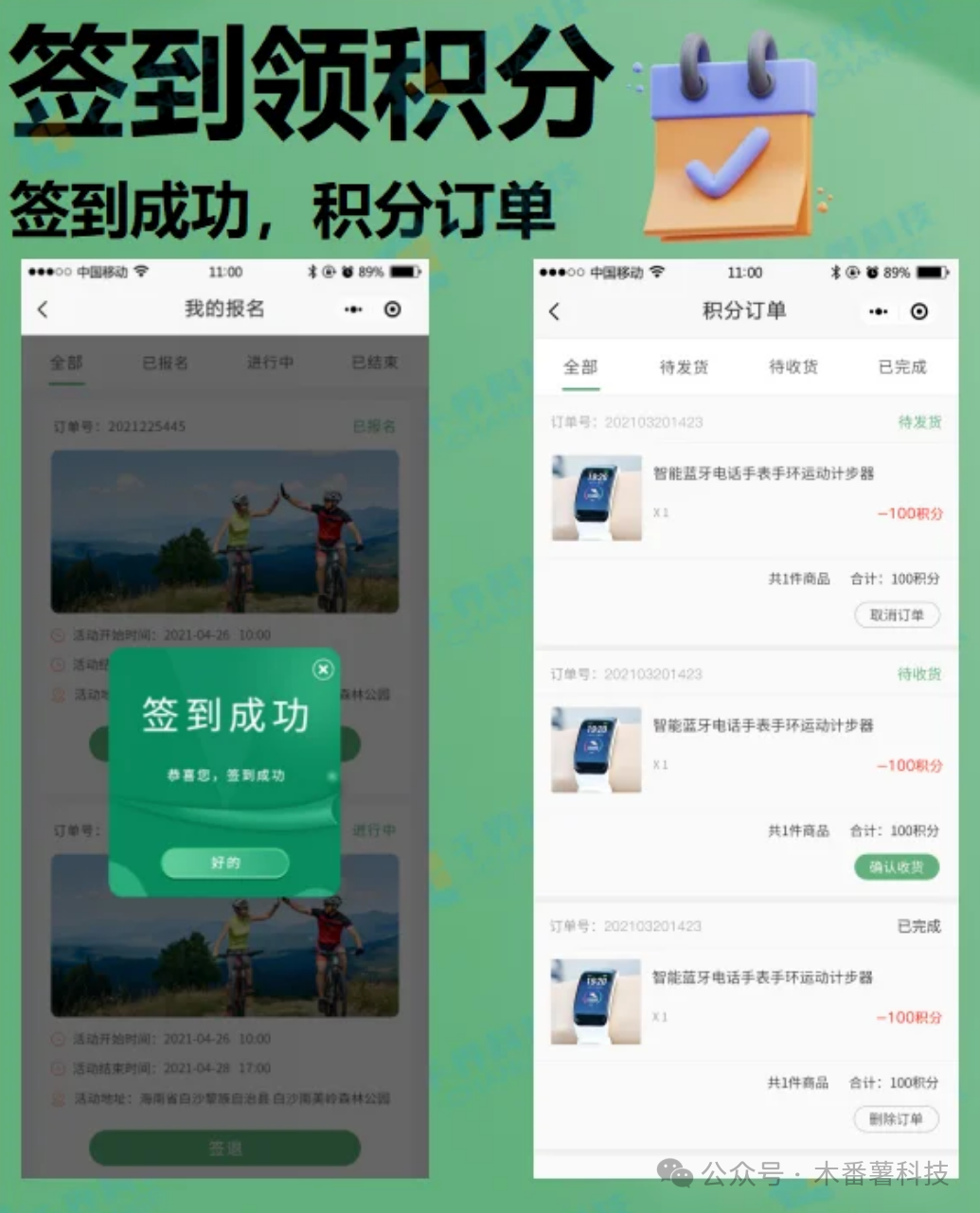
体育活动赛事报名马拉松微信小程序开发
功能描述 体育活动赛事报名马拉松微信小程序,该项目是一个体育活动报名小程序,主要功能有活动报名、扫码签到、签到积分、排行奖励、积分兑换等功能。 用户端🔶登录:◻️1.微信授权登录 ◻️2.手机号码授权 🔶首页&am…...

【C++】C++基础知识
一.函数重载 1.函数重载的概念 函数重载是函数的一种特殊情况,C允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表必须不同。函数重载常用来处理实现功能类似,而数据类型不同的问题。 #include <iostream> using…...

中间件安全
IIS IIS短文件漏洞 此漏洞实际是由HTTP请求中旧DOS 8.3名称约定(SFN)的代字符(~)波浪号引起的。它允许远程攻击者在Web根目录下公开文件和文件夹名称(不应该可被访问)。攻击者可以找到通常无法从外部直接访问的重要文件,并获取有关应用程序基础结构的信息。 利用工具 https…...

Zabbix中文监控指标数据乱码
1)点击主机,选择Zabbix server 中的 图形 一项,可以看到当前显示的为乱码 2) 下载字体文件: https://gitcode.com/open-source-toolkit/4a3db/blob/main/SimHei.zip 解压unzip -x SimHei.zip 3) 替换字体文…...

【AI】AI如何赋能软件开发流程
方向一:流程与模式介绍【传统软件开发 VS AI参与的软件开发】 传统软件开发流程 传统软件开发流程一般可以分为以下几个阶段: 1. 需求分析:在这个阶段,开发团队与客户沟通,明确软件的需求和目标。团队会收集、整理和分…...

恒创科技:什么是 RAID 3 ? RAID 3、4 和5之间有什么区别?
RAID 是一种存储数据以提高性能并减少数据丢失的特定技术。您可以根据自己的需求选择多种 RAID 类型。RAID 3 是列表中比较有效的类型之一。本文将重点介绍这种特定的 RAID 技术,并比较 RAID 3、4 和 5。 RAID 3 的定义 RAID 3 是一种特定的磁盘配置,用于…...

python获取iOS最近业务日志的两种方法
当iOS UI自动化用例执行失败的时候,需要获取当时的业务日志,供后续分析使用。 现在已经把iOS沙盒目录挂载到本地,剩下的事情就是从沙盒目录中捞取当前的日志,沙盒中的日志文件较大,整体导出来也可以,但是会…...

【如何获取股票数据43】Python、Java等多种主流语言实例演示获取股票行情api接口之沪深指数历史交易数据获取实例演示及接口API说明文档
最近一两年内,股票量化分析逐渐成为热门话题。而从事这一领域工作的第一步,就是获取全面且准确的股票数据。因为无论是实时交易数据、历史交易记录、财务数据还是基本面信息,这些数据都是我们进行量化分析时不可或缺的宝贵资源。我们的主要任…...
:从零配置 ESLint)
ESLint 使用教程(一):从零配置 ESLint
前言 在现代前端开发中,代码质量和风格一致性是团队合作和项目维护的重要因素。而 ESLint 作为一款强大的 JavaScript 静态代码分析工具,能够帮助开发者发现和修复代码中的潜在问题。本文将详细介绍 ESLint 的常用规则配置,并结合实际应用场…...

openssl对称加密代码讲解实战
文章目录 一、openssl对称加密和非对称加密算法对比1. 加密原理2. 常用算法3. 加密速度4. 安全性5. 应用场景6. 优缺点对比综合分析 二、代码实战代码说明:运行输出示例代码说明:注意事项 一、openssl对称加密和非对称加密算法对比 OpenSSL 是一个广泛使…...

web前端动画按钮(附源代码)
效果图 源代码 HTML部分 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title> …...

go函数传值是值传递?还是引用传递?slice案例加图解
先说下结论 Go语言中所有的传参都是值传递(传值),都是一个副本,一个拷贝。 值语义类型:参数传递的时候,就是值拷贝,这样就在函数中就无法修改原内容数据。 基本类型:byte、int、bool…...

PostgreSQL数据库笔记
PostgreSQL 是什么 PostgreSQL(简称Postgres或PG)是一个功能强大、可靠性高、可扩展性好的开源对象-关系数据库服务器(ORDBMS),它以加州大学伯克利分校计算机系开发的POSTGRES版本4.2为基础。 发展历程 起源与发展&a…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现企业微信功能
1. 开发环境准备 安装DevEco Studio 3.1: 从华为开发者官网下载最新版DevEco Studio安装HarmonyOS 5.0 SDK 项目配置: // module.json5 {"module": {"requestPermissions": [{"name": "ohos.permis…...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...