基于YOLOv8深度学习的汽车车身车损检测系统研究与实现(PyQt5界面+数据集+训练代码)
本文研究并实现了一种基于YOLOV8深度学习模型的汽车车身车损检测系统,旨在解决传统车损检测中效率低、精度不高的问题。该系统利用YOLOV8的目标检测能力,在单张图像上实现了车身损坏区域的精确识别和分类,尤其是在车身凹痕、车身裂纹和车身划痕等常见损伤类型的检测上取得了显著效果。通过使用YOLOV8模型,系统能够以较快的速度和较高的准确率对输入图像进行处理,满足实际应用中对实时性和可靠性的要求。
为了提升用户体验,系统采用了PyQt5框架构建了交互界面,使用户可以轻松地加载车辆图像,并查看检测到的损伤类型及其定位信息。用户界面设计直观,操作简便,可显示每个检测到的损伤类型及其在图像中的具体位置。此外,系统还支持批量图像处理功能,用户可以一次性上传多张图片,系统将逐一识别并输出损伤检测结果。这种交互设计不仅提高了系统的实用性,还为用户带来了便捷的操作体验。
在数据集方面,本文专门构建并标注了一个针对汽车车损检测的数据集,涵盖了不同类型和程度的车损案例,包括车身凹痕、裂纹和划痕等多个类别。该数据集包含了多样化的车损情况,保证了模型训练过程中的泛化能力,适用于不同车型和车损场景。同时,数据集还包含了各类车损的详细标注信息,以帮助YOLOV8模型进行深度学习训练。实验验证了模型的性能,其结果显示,该车损检测系统在不同的损伤类型上均表现出较高的检测精度和识别速度,能够有效减少漏检和误检情况。
系统的成功开发与应用为汽车保险理赔、车辆维护等领域提供了一种新型的智能化解决方案。相比于传统的人工检测方式,该系统显著提高了车损检测的效率和准确性。通过自动化的车损检测流程,保险公司可以更快速、准确地处理理赔案件,减少主观误差;而在车辆维护领域,维修人员也能够利用该系统快速定位车损,制定修复方案。总之,本文提出的车损检测系统不仅在技术上实现了创新突破,而且在实际应用中也具备了广泛的推广价值,为车损检测领域带来了新的发展前景。
算法流程

项目数据
通过搜集关于数据集为各种各样的车身车损相关图像,并使用Labelimg标注工具对每张图片进行标注,分3检测类别,分别是’车身凹痕’,’车身裂纹’,’车身划痕’。
目标检测标注工具
(1)labelimg:开源的图像标注工具,标签可用于分类和目标检测,它是用python写的,并使用Qt作为其图形界面,简单好用(虽然是英文版的)。其注释以 PASCAL VOC格式保存为XML文件,这是ImageNet使用的格式。此外,它还支持 COCO数据集格式。
(2)安装labelimg 在cmd输入以下命令 pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
![]()
结束后,在cmd中输入labelimg
![]()
初识labelimg
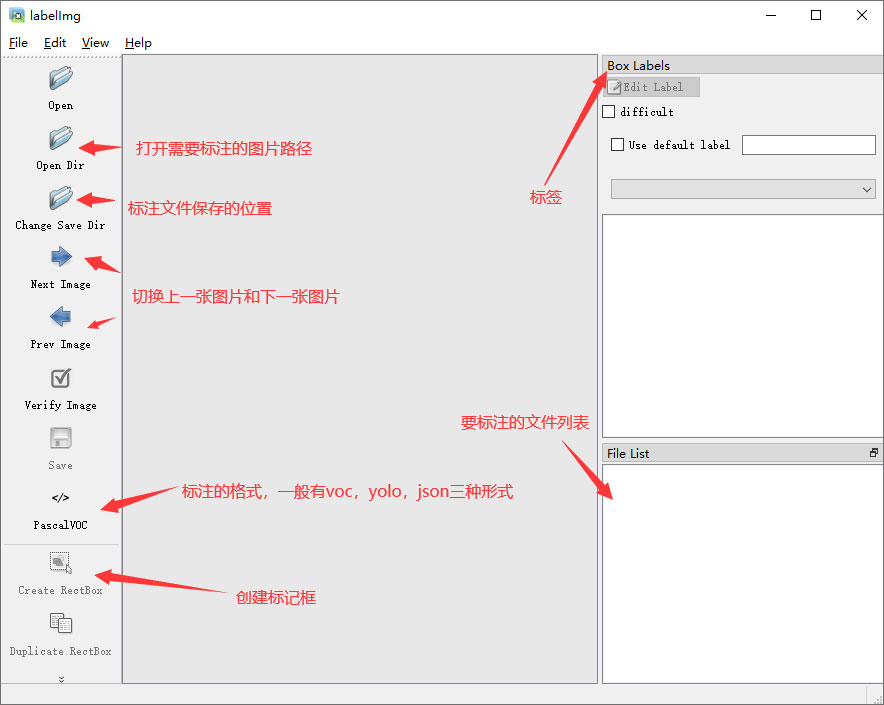
打开后,我们自己设置一下
在View中勾选Auto Save mode
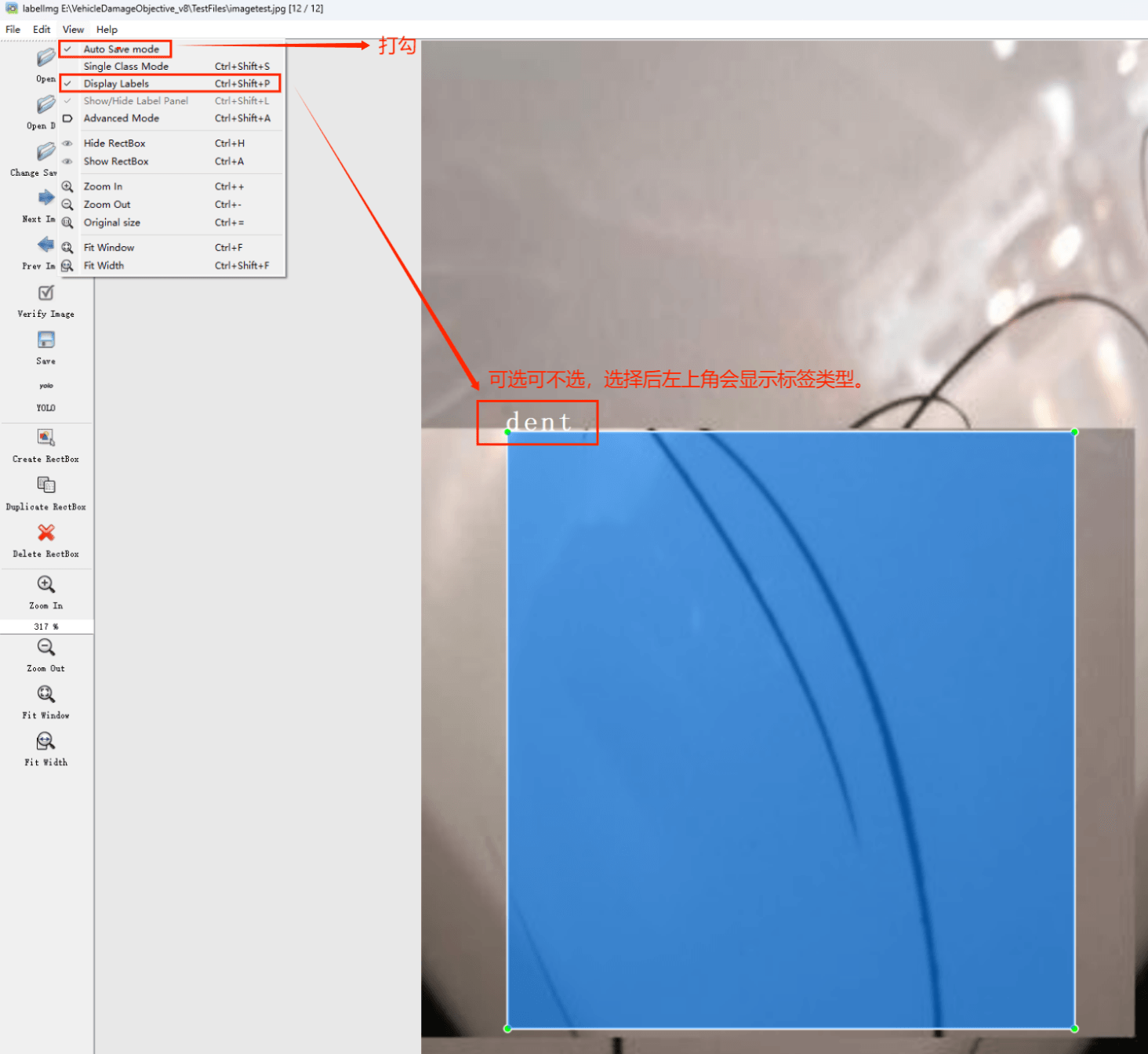
接下来我们打开需要标注的图片文件夹

并设置标注文件保存的目录(上图中的Change Save Dir)
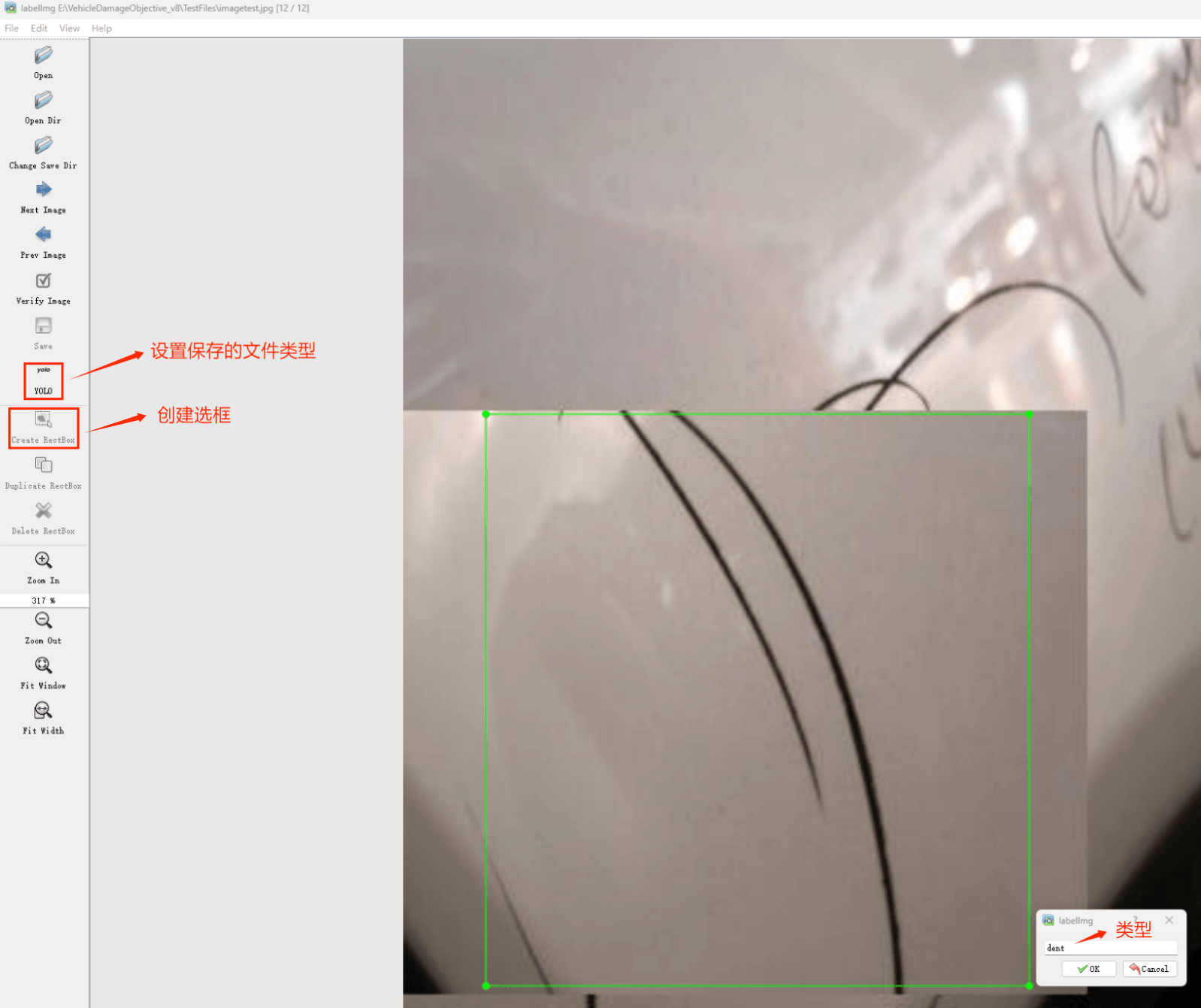
接下来就开始标注,画框,标记目标的label,然后d切换到下一张继续标注,不断重复重复。
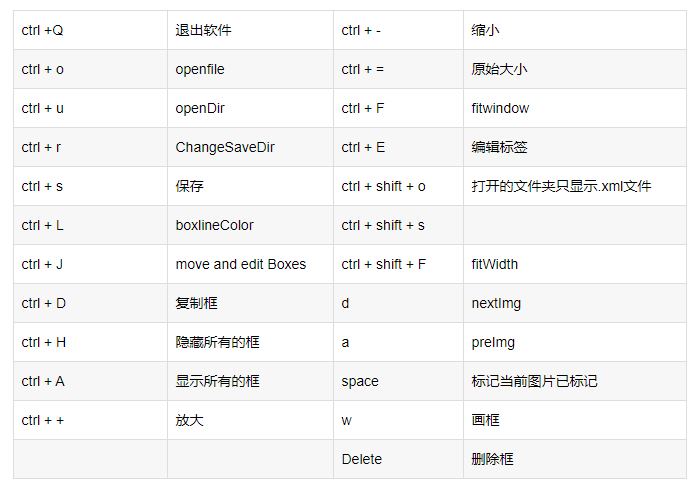
Labelimg的快捷键
(3)数据准备
这里建议新建一个名为data的文件夹(这个是约定俗成,不这么做也行),里面创建一个名为images的文件夹存放我们需要打标签的图片文件;再创建一个名为labels存放标注的标签文件;最后创建一个名为 classes.txt 的txt文件来存放所要标注的类别名称。
data的目录结构如下:
│─img_data
│─images 存放需要打标签的图片文件
│─labels 存放标注的标签文件
└ classes.txt 定义自己要标注的所有类别(这个文件可有可无,但是在我们定义类别比较多的时候,最好有这个创建一个这样的txt文件来存放类别)
首先在images这个文件夹放置待标注的图片。
生成文件如下:
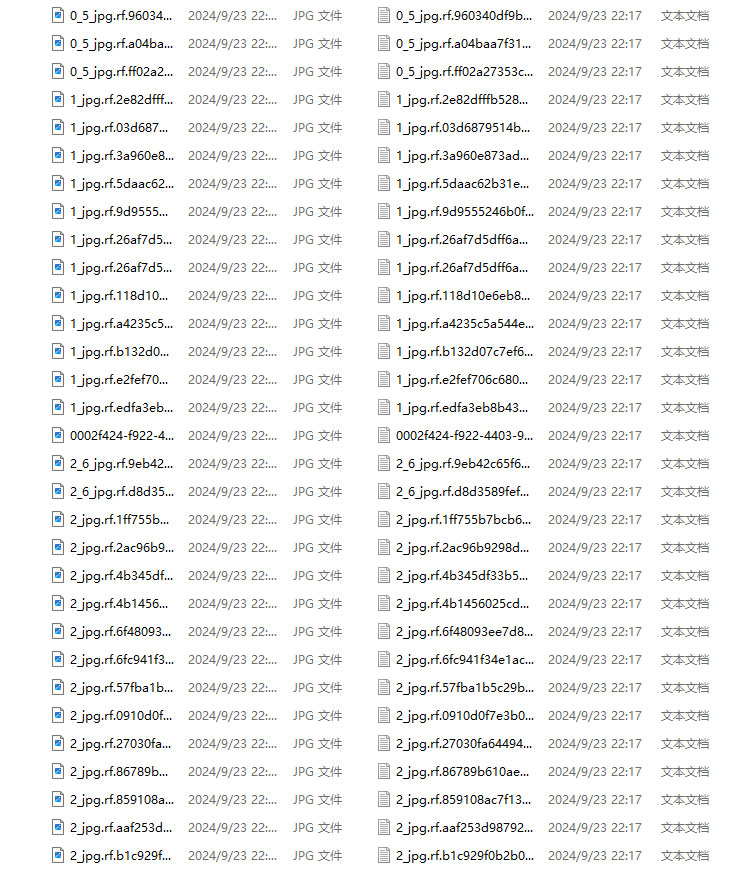
“classes.txt”定义了你的 YOLO 标签所引用的类名列表。
(4)YOLO模式创建标签的样式
存放标签信息的文件的文件名为与图片名相同,内容由N行5列数据组成。
每一行代表标注的一个目标,通常包括五个数据,从左到右依次为:类别id、x_center、y_center、width、height。
其中:
–x类别id代表标注目标的类别;
–x_center和y_center代表标注框的相对中心坐标;
–xwidth和height代表标注框的相对宽和高。
注意:这里的中心点坐标、宽和高都是相对数据!!!

存放标签类别的文件的文件名为classes.txt (固定不变),用于存放创建的标签类别。
完成后可进行后续的yolo训练方面的操作。
模型训练
模型的训练、评估与推理
1.YOLOv8的基本原理
YOLOv8是一个SOTA模型,它建立在Yolo系列历史版本的基础上,并引入了新的功能和改进点,以进一步提升性能和灵活性,使其成为实现目标检测、图像分割、姿态估计等任务的最佳选择。其具体创新点包括一个新的骨干网络、一个新的Ancher-Free检测头和一个新的损失函数,可在CPU到GPU的多种硬件平台上运行。
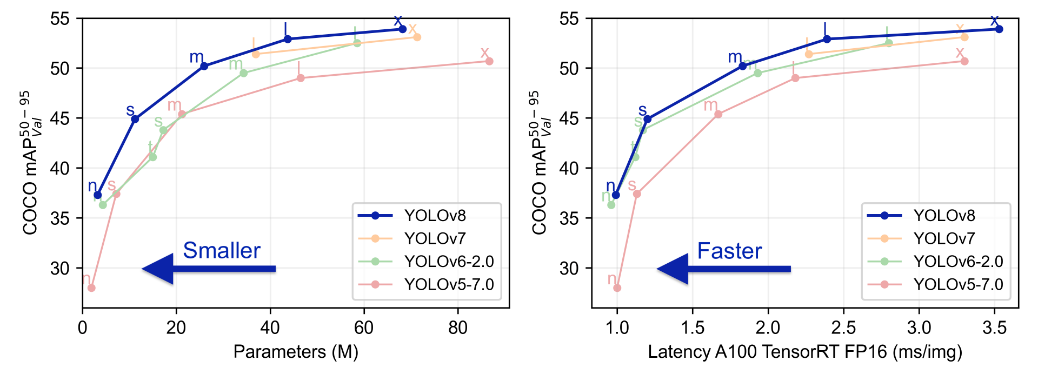
YOLOv8是Yolo系列模型的最新王者,各种指标全面超越现有对象检测与实例分割模型,借鉴了Yolov5、Yolov6、YoloX等模型的设计优点,在全面提升改进Yolov5模型结构的基础上实现,同时保持了Yolov5工程化简洁易用的优势。
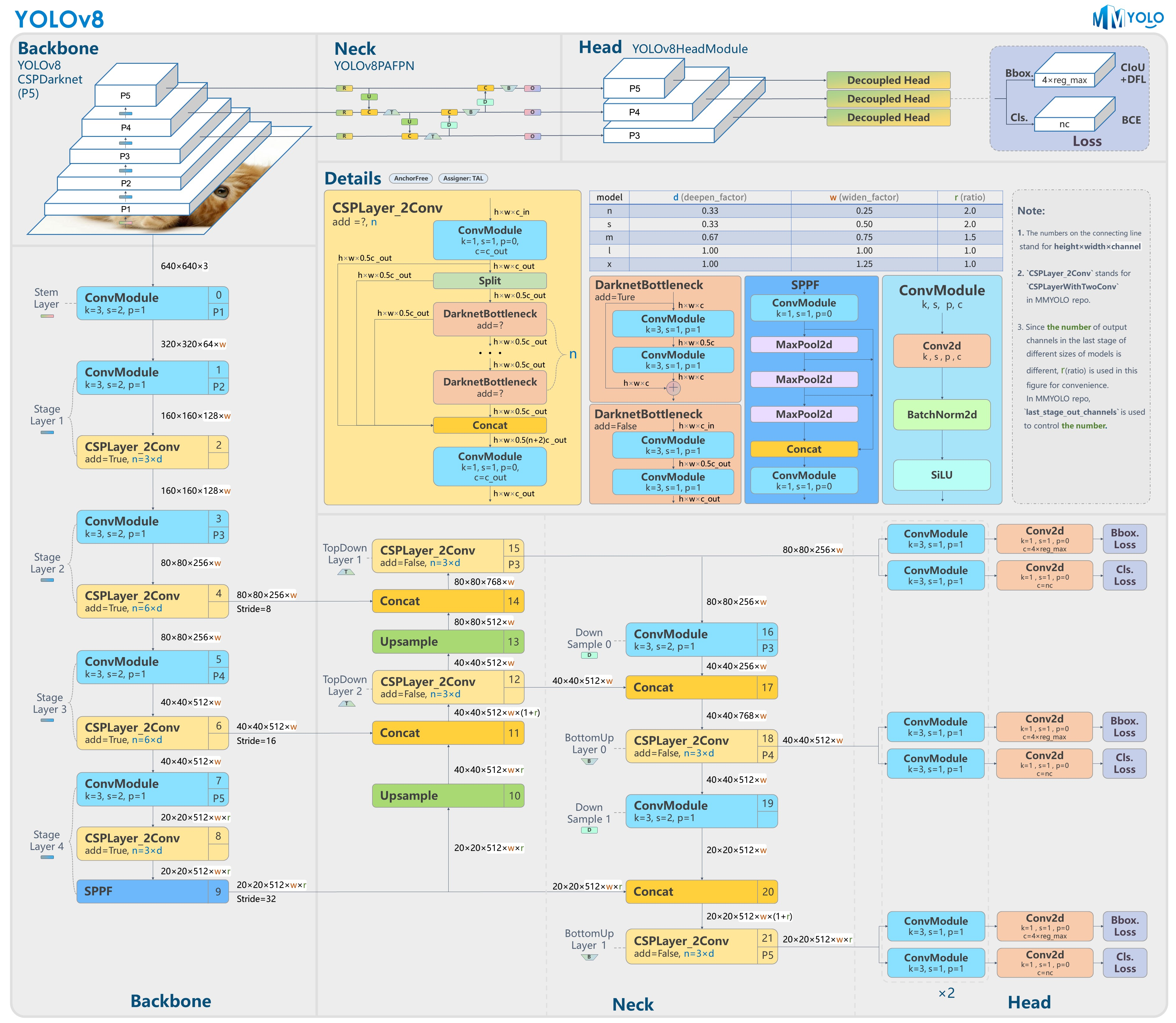
Yolov8模型网络结构图如下图所示:
2.数据集准备与训练
本研究使用了包含建筑外墙破损相关图像的数据集,并通过Labelimg标注工具对每张图像中的目标边框(Bounding Box)及其类别进行标注。然后主要基于YOLOv8n这种模型进行模型的训练,训练完成后对模型在验证集上的表现进行全面的性能评估及对比分析。模型训练和评估流程基本一致,包括:数据集准备、模型训练、模型评估。本次标注的目标类别为建筑外墙破损,数据集中共计包含3073张图像,其中训练集占2456张,验证集占617张。部分图像如下图所示:

部分标注如下图所示:

图片数据的存放格式如下,在项目目录中新建datasets目录,同时将检测的图片分为训练集与验证集放入datasets目录下。
接着需要新建一个data.yaml文件,用于存储训练数据的路径及模型需要进行检测的类别。YOLOv8在进行模型训练时,会读取该文件的信息,用于进行模型的训练与验证。
data.yaml的具体内容如下:

train: E:/VehicleDamageObjective_v8/datasets/train/images 训练集的路径
val: E:/VehicleDamageObjective_v8/datasets/val/images 验证集的路径
# test: E:/VehicleDamageObjective_v8/datasets/test/images 测试集的路径
nc: 3
names: [“dent”, “crack”, “scratch”]
这个文件定义了用于模型训练和验证的数据集路径,以及模型将要检测的目标类别。
数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小(根据内存大小调整,最小为1)。
CPU/GPU训练代码如下:
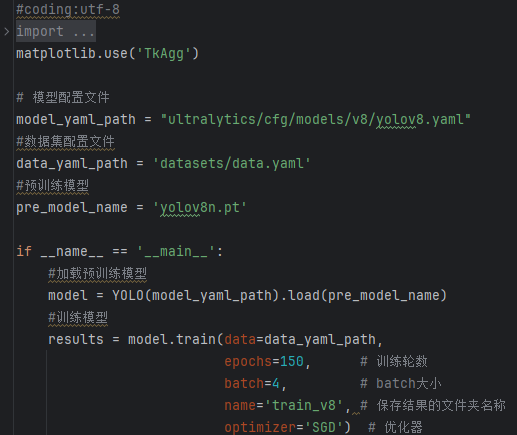
加载名为 yolov8n.pt 的预训练YOLOv8模型,yolov8n.pt是预先训练好的模型文件。
使用YOLO模型进行训练,主要参数说明如下:
(1)data=data_yaml_path: 指定了用于训练的数据集配置文件。
(2)epochs=150: 设定训练的轮数为150轮。
(3)batch=4: 指定了每个批次的样本数量为4。
(4)optimizer=’SGD’):SGD 优化器。
(7)name=’train_v8′: 指定了此次训练的命名标签,用于区分不同的训练实验。
3.训练结果评估
在深度学习的过程中,我们通常通过观察损失函数下降的曲线来了解模型的训练情况。对于YOLOv8模型的训练,主要涉及三类损失:定位损失(box_loss)、分类损失(cls_loss)以及动态特征损失(dfl_loss)。训练完成后,相关的训练过程和结果文件会保存在 runs/ 目录下,具体如下:
各损失函数作用说明:
定位损失box_loss:预测框与标定框之间的误差(GIoU),越小定位得越准;
分类损失cls_loss:计算锚框与对应的标定分类是否正确,越小分类得越准;
动态特征损失(dfl_loss):DFLLoss是一种用于回归预测框与目标框之间距离的损失函数。在计算损失时,目标框需要缩放到特征图尺度,即除以相应的stride,并与预测的边界框计算Ciou Loss,同时与预测的anchors中心点到各边的距离计算回归DFLLoss。这个过程是YOLOv8训练流程中的一部分,通过计算DFLLoss可以更准确地调整预测框的位置,提高目标检测的准确性。
训练结果如下:
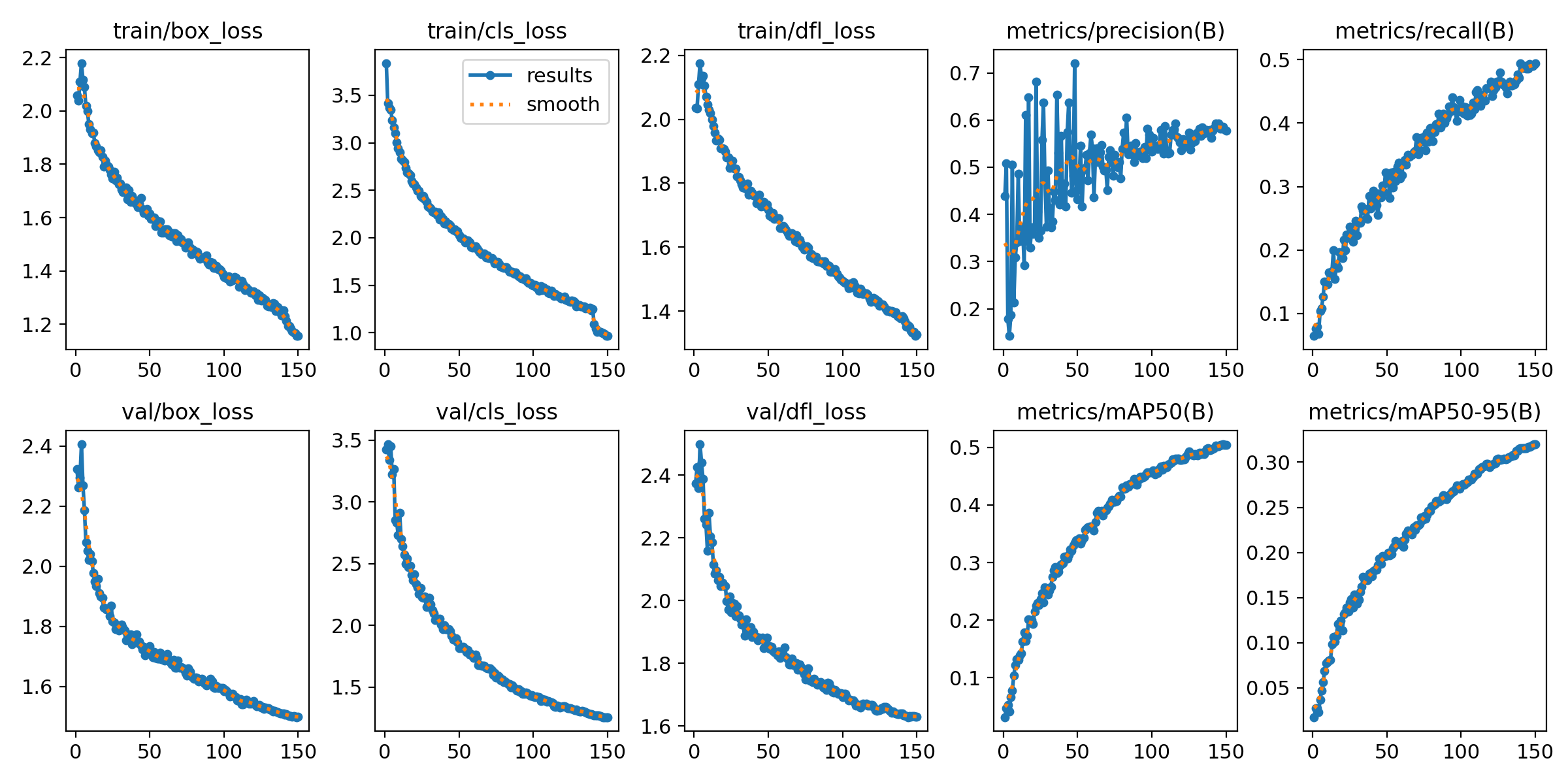
这张图展示了YOLOv8模型在训练和验证过程中的多个重要指标的变化趋势,具体如下:
train/box_loss:
(1)这是训练过程中边界框损失的变化。边界框损失用于衡量模型预测的目标框与实际目标框的差异。
(2)随着训练的进行,损失逐渐降低,说明模型在定位边界框方面的性能在提高。
train/cls_loss:
(1)这是训练集上的分类损失。分类损失衡量模型对目标类别的预测准确性。
(2)曲线逐渐下降,表明模型在类别分类任务上也在逐渐收敛。
train/dfl_loss:
(1)这是分布聚焦损失(distribution focal loss),用于帮助模型对目标框的精确定位。
(2)这一损失同样随着训练的进行而减小,表明模型在预测边界框时越来越准确。
metrics/precision(B):
(1)这是训练集上的精度(precision)曲线。精度表示模型在检测到的目标中有多少是真正的目标。
(2)尽管有波动,但整体趋势是上升的,表明模型误检减少。
metrics/recall(B):
(1)这是训练集上的召回率(recall)曲线。召回率表示模型检测出的真实目标的比例。
(2)召回率随着训练增加而提高,说明模型的漏检率降低。
val/box_loss:
(1)这是验证集上的边界框损失曲线。
(2)与训练中的趋势相似,损失逐渐减小,说明模型在验证数据上的表现也在提升。
val/cls_loss:
(1)这是验证集上的分类损失曲线。
(2)损失随训练过程下降,验证了模型在不同数据集上的一致性。
val/dfl_loss:
(1)这是验证集上的分布聚焦损失曲线。
(2)与训练集一样,损失逐渐下降。
metrics/mAP50(B):
(1)这是验证集上的mAP50曲线,表示在交并比阈值为0.5时模型的平均精度(mean Average Precision)。
(2)随着训练的增加,mAP50逐渐提高,说明模型的检测精度在不断提升。
metrics/mAP50-95(B):
(1)这是验证集上的mAP50-95曲线,表示在不同交并比阈值(从0.5到0.95)下模型的平均精度。
(2)曲线的上升趋势表明模型在更高的IoU阈值上表现良好,具有较好的泛化能力。
总结:
(1)损失函数(box_loss、cls_loss、dfl_loss)在训练和验证集上的逐步下降,说明模型在训练和验证集上的性能都在逐渐提高。
(2)精确率和召回率逐渐提高,表明模型在减少误检和漏检方面表现较好。
(3)mAP50和mAP50-95曲线的上升趋势显示了模型在不同阈值下的平均检测精度逐渐提升,验证了模型的收敛效果和准确性。
总体而言,模型在训练过程中表现出良好的收敛性和稳健性,表明其适用于车损检测任务,并具备较高的泛化性能。
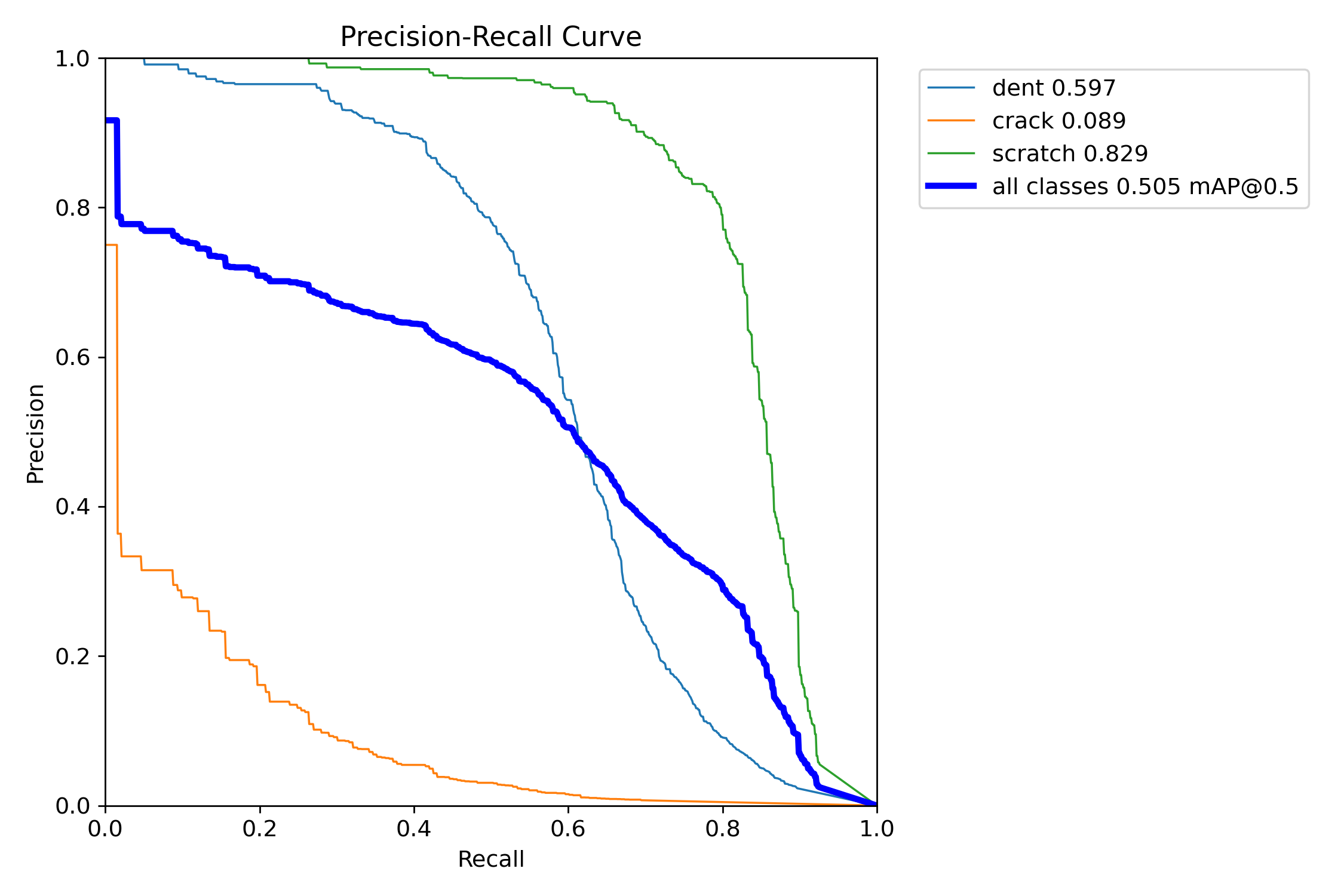
这张图展示的是 Precision-Recall 曲线,用于评估模型在不同类别下的检测性能。以下是详细解释:
曲线解释:
(1)蓝色粗线:表示整体的精确率-召回率曲线,展示了模型在所有类别上的平均表现。该曲线的区域表示整体的平均精度(mAP),在IoU阈值为0.5时的mAP值为0.505。
(2)浅蓝色线:代表“dent”(凹痕)类别。其mAP值为0.597,曲线显示出较高的精确率和中等的召回率,说明模型在识别凹痕时表现较好。
(3)橙色线:代表“crack”(裂纹)类别。mAP值为0.089,曲线在低召回率时的精确率急剧下降,显示出模型在检测裂纹时表现较弱。
(4)绿色线:代表“scratch”(划痕)类别。其mAP值为0.829,曲线显示出较高的精确率和召回率,说明模型在划痕检测方面表现非常出色。
整体性能(all classes):
(1)蓝色粗线代表所有类别的综合表现,mAP@0.5为0.505。这表明,虽然模型在某些类别上表现较好,但在整体上有进一步提升的空间。
这张精确率-召回率曲线图清晰地展示了YOLOv8模型在不同损伤类别上的检测性能差异。模型对划痕和凹痕检测表现较好,但在裂纹检测方面表现不佳,需要进一步优化。
4.检测结果识别
模型训练完成后,我们可以得到一个最佳的训练结果模型best.pt文件,在runs/train/weights目录下。我们可以使用该文件进行后续的推理检测。
imgTest.py 图片检测代码如下:
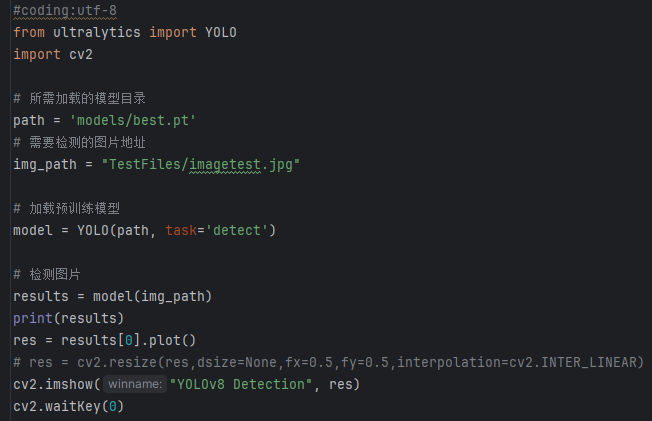
加载所需库:
(1)from ultralytics import YOLO:导入YOLO模型类,用于进行目标检测。
(2)import cv2:导入OpenCV库,用于图像处理和显示。
加载模型路径和图片路径:
(1)path = ‘models/best.pt’:指定预训练模型的路径,这个模型将用于目标检测任务。
(2)img_path = “TestFiles/imagetest.jpg”:指定需要进行检测的图片文件的路径。
加载预训练模型:
(1)model = YOLO(path, task=’detect’):使用指定路径加载YOLO模型,并指定检测任务为目标检测 (detect)。
(2)通过 conf 参数设置目标检测的置信度阈值,通过 iou 参数设置非极大值抑制(NMS)的交并比(IoU)阈值。
检测图片:
(1)results = model(img_path):对指定的图片执行目标检测,results 包含检测结果。
显示检测结果:
(1)res = results[0].plot():将检测到的结果绘制在图片上。
(2)cv2.imshow(“YOLOv8 Detection”, res):使用OpenCV显示检测后的图片,窗口标题为“YOLOv8 Detection”。
(3)cv2.waitKey(0):等待用户按键关闭显示窗口
此代码的功能是加载一个预训练的YOLOv8模型,对指定的图片进行目标检测,并将检测结果显示出来。
执行imgTest.py代码后,会将执行的结果直接标注在图片上,结果如下:

这段输出是基于YOLOv8模型对图片“imagetest.jpg”进行检测的结果,具体内容如下:
图像信息:
(1)处理的图像路径为:TestFiles/imagetest.jpg。
(2)图像尺寸为 416×416 像素。
检测结果:
(1)模型在该图片上检测到 1 个车身凹痕(”1 dent”)
处理速度:
(1)预处理时间: 3.9ms。
(2)推理时间: 4.7ms。
(3)后处理时间: 76.5ms。
输出的这些信息有助于了解检测到的车身车损类别,以及模型在该特定图像上的推理表现。
运行效果
– 运行 MainProgram.py
1.主要功能:
(1)可用于实时检测目标图片中的车身车损;
(2)支持图片、视频及摄像头进行检测,同时支持图片的批量检测;
(3)界面可实时显示目标位置、目标总数、置信度、用时等信息;
(4)支持图片或者视频的检测结果保存。
2.检测结果说明:
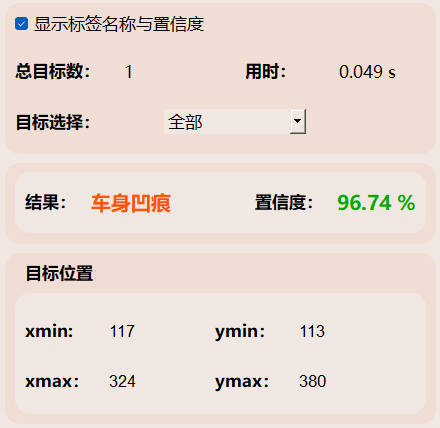
这张图表显示了基于YOLOv8模型的目标检测系统的检测结果界面。以下是各个字段的含义解释:
用时(Time taken):
(1)这表示模型完成检测所用的时间为0.049秒。
(2)这显示了模型的实时性,检测速度非常快。
目标数目(Number of objects detected):
(1)检测到的目标数目为1,表示这是当前检测到的第1个目标。
目标选择(下拉菜单):全部:
(1)这里有一个下拉菜单,用户可以选择要查看的目标类型。
(2)在当前情况下,选择的是“全部”,意味着显示所有检测到的目标信息。
类型(Type):
(1)当前选中的行为类型为 “车身凹痕”,表示系统正在高亮显示检测到的“dent”。
置信度(Confidence):
(1)这表示模型对检测到的目标属于“车身凹痕”类别的置信度为96.74%。
(2)置信度反映了模型的信心,置信度越高,模型对这个检测结果越有信心。
目标位置(Object location):
(1)xmin: 117, ymin: 113:目标的左上角的坐标(xmin, ymin),表示目标区域在图像中的位置。
(2)xmax: 324, ymax: 380:目标的右下角的坐标(xmax, ymax),表示目标区域的边界。
这些坐标表示在图像中的目标区域范围,框定了检测到的“车身凹痕”的位置。
这张图展示了车身车损的一次检测结果,包括检测时间、检测到的种类、各行为的置信度、目标的位置信息等。用户可以通过界面查看并分析检测结果,提升车身车损检测的效率。
3.图片检测说明
(1)车身凹痕
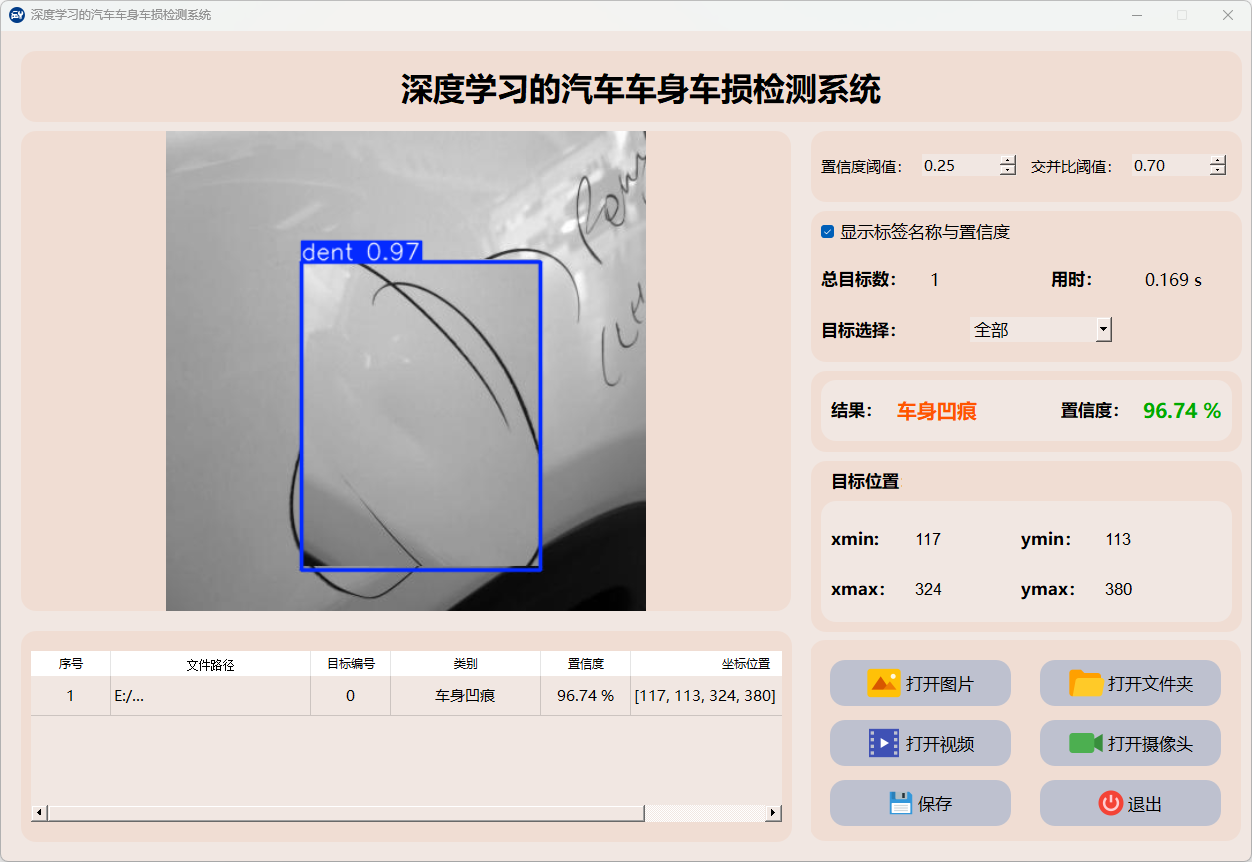
(2)车身划痕
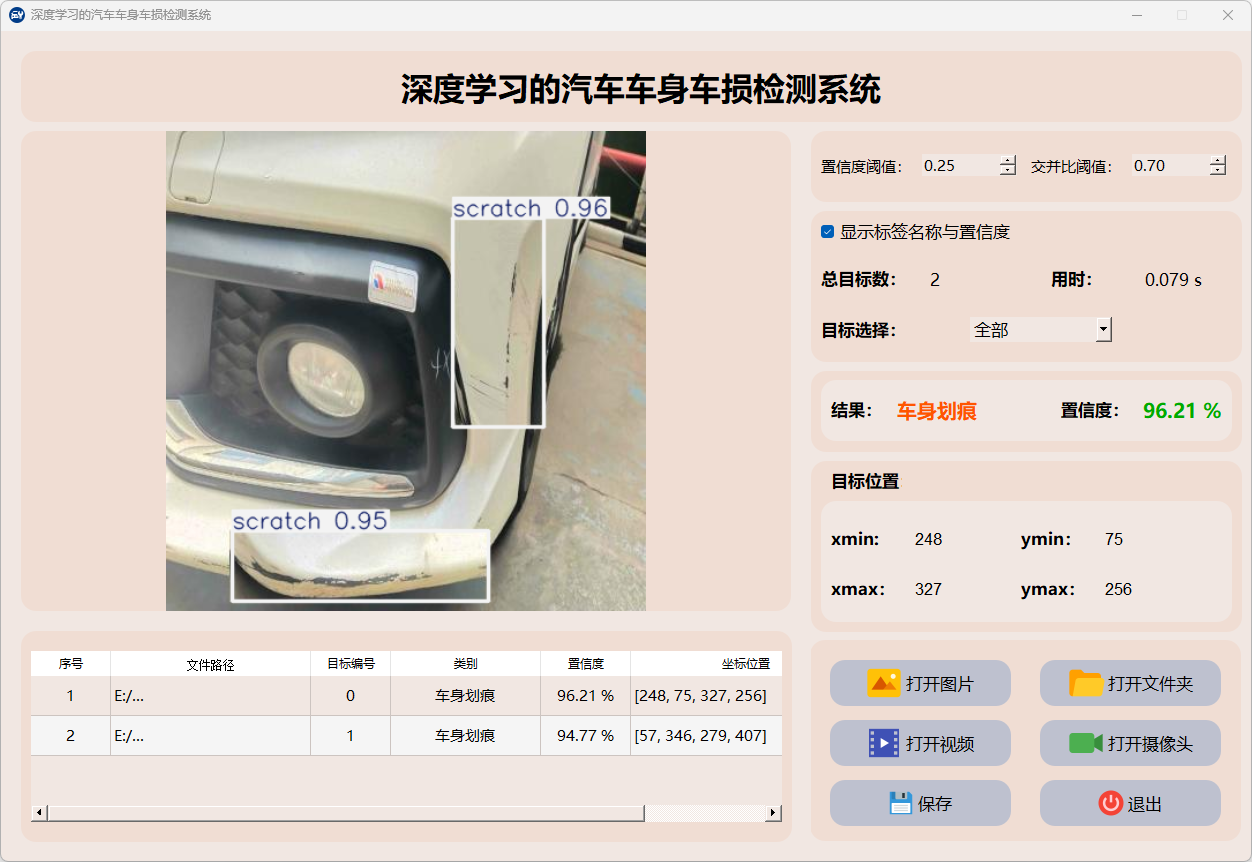
(3)车身裂纹
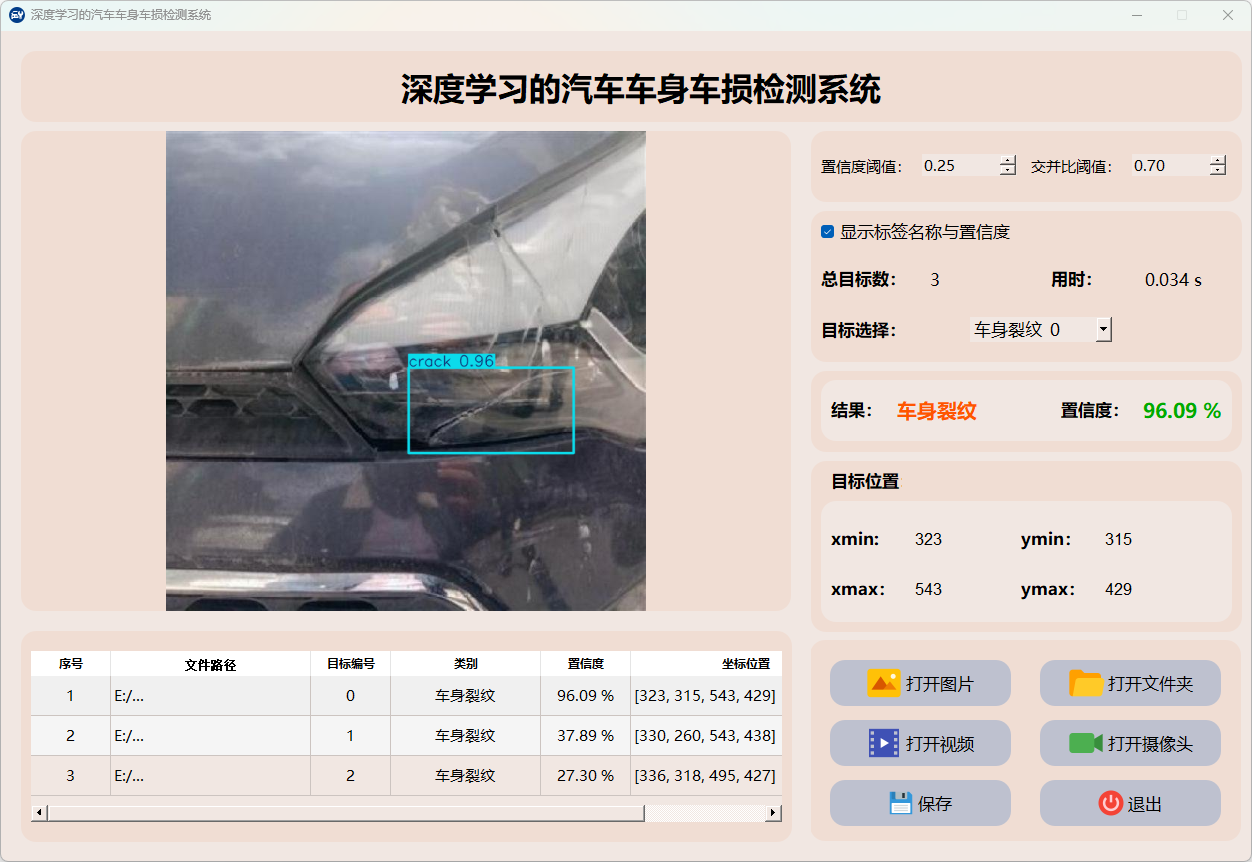
点击打开图片按钮,选择需要检测的图片,或者点击打开文件夹按钮,选择需要批量检测图片所在的文件夹。
操作演示如下:
(1)点击目标下拉框后,可以选定指定目标的结果信息进行显示。
(2)点击保存按钮,会对检测结果进行保存,存储路径为:save_data目录下。
检测结果:系统识别出图片中的车身车损,并显示检测结果,包括总目标数、用时、目标类型、置信度、以及目标的位置坐标信息。
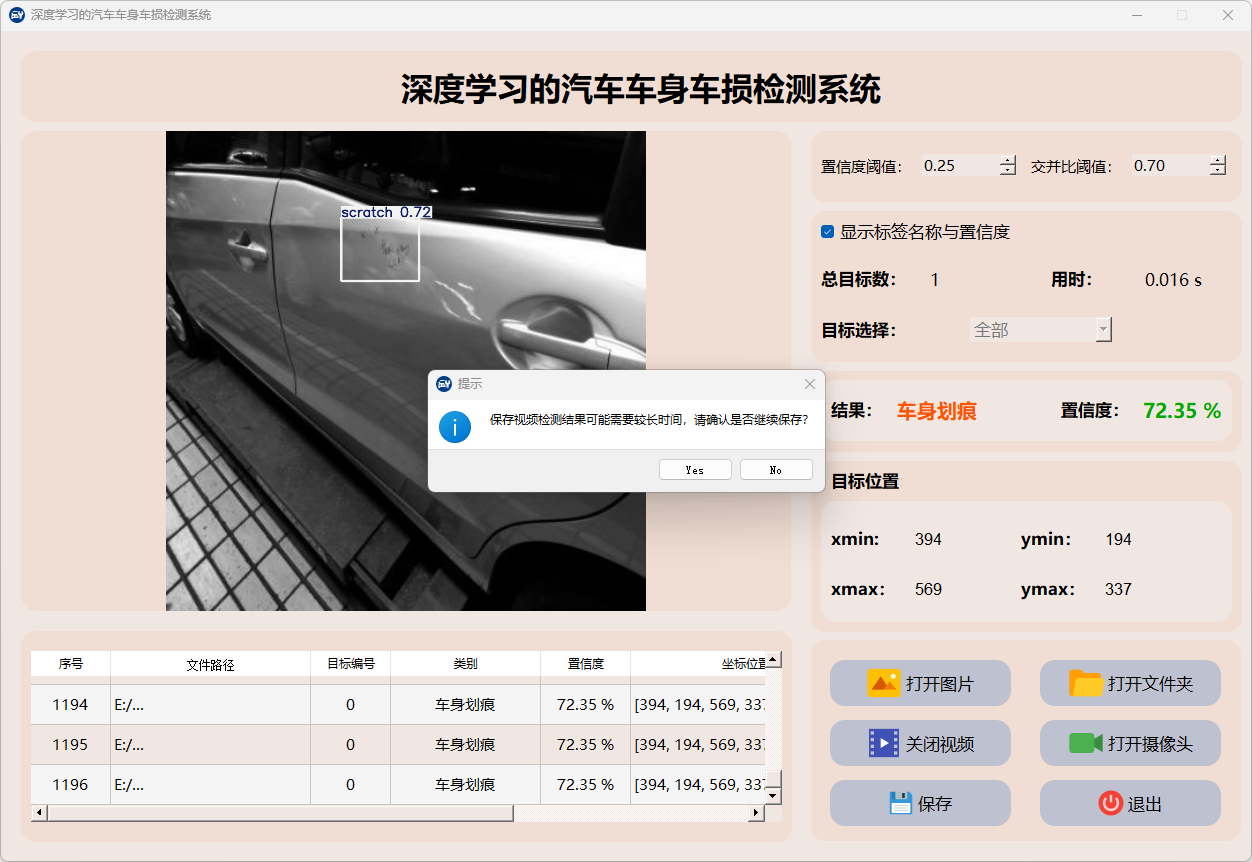
4.视频检测说明
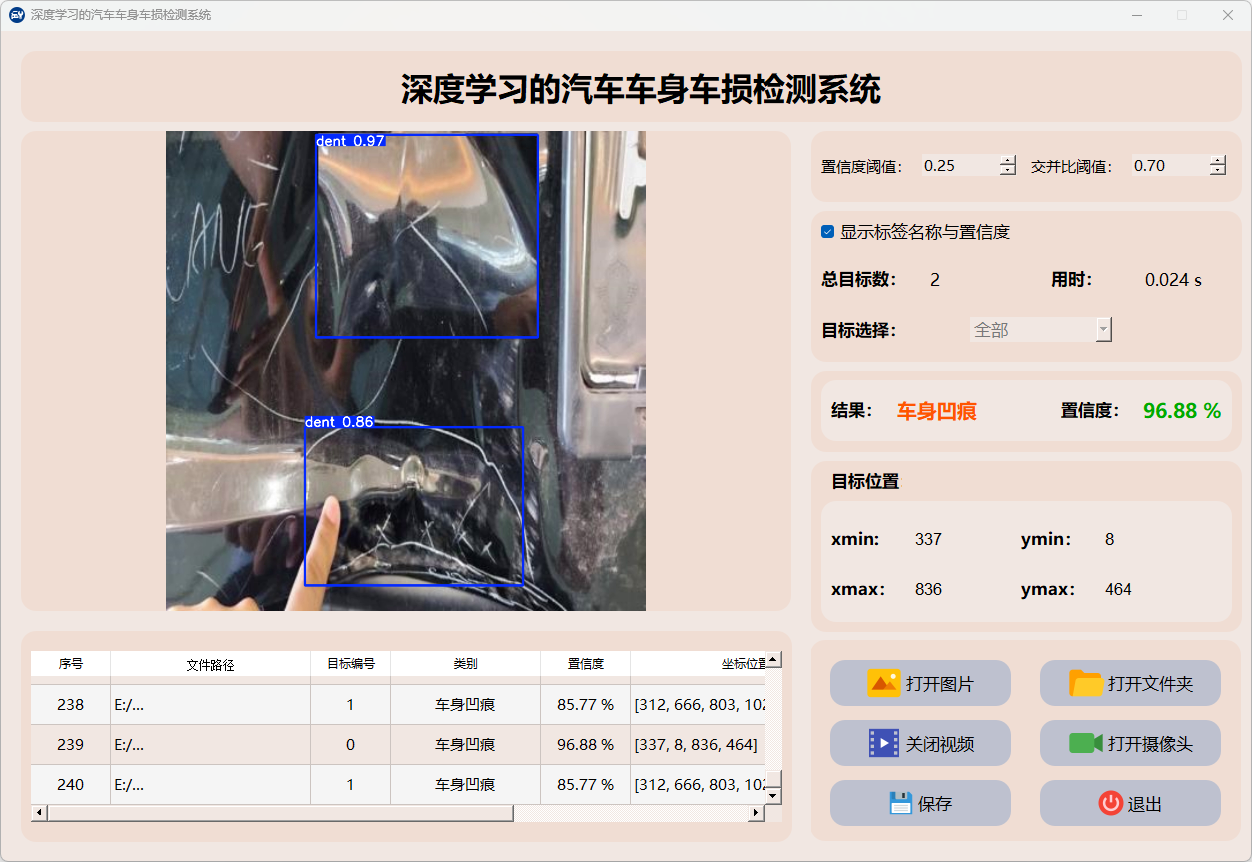
点击视频按钮,打开选择需要检测的视频,就会自动显示检测结果,再次点击可以关闭视频。
点击保存按钮,会对视频检测结果进行保存,存储路径为:save_data目录下。
检测结果:系统对视频进行实时分析,检测到车身车损并显示检测结果。表格显示了视频中多个检测结果的置信度和位置信息。
这个界面展示了系统对视频帧中的多目标检测能力,能够准确识别车身车损,并提供详细的检测结果和置信度评分。
5.摄像头检测说明

点击打开摄像头按钮,可以打开摄像头,可以实时进行检测,再次点击,可关闭摄像头。
检测结果:系统连接摄像头进行实时分析,检测到车身车损并显示检测结果。实时显示摄像头画面,并将检测到的行为位置标注在图像上,表格下方记录了每一帧中检测结果的详细信息。
6.保存图片与视频检测说明
点击保存按钮后,会将当前选择的图片(含批量图片)或者视频的检测结果进行保存。
检测的图片与视频结果会存储在save_data目录下。
保存的检测结果文件如下:
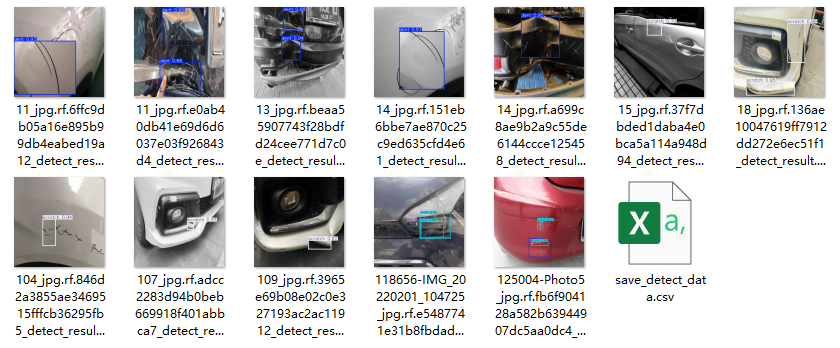
图片文件保存的csv文件内容如下,包括图片路径、目标在图片中的编号、目标类别、置信度、目标坐标位置。
注:其中坐标位置是代表检测框的左上角与右下角两个点的x、y坐标。
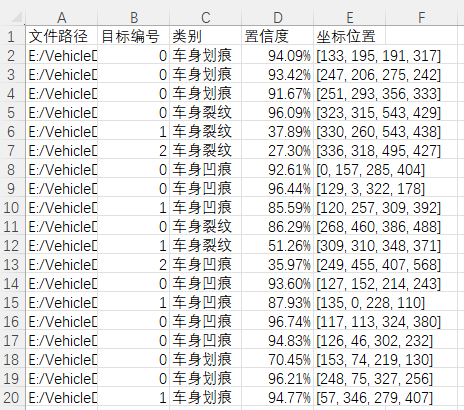
(1)图片保存
(2)视频保存
– 运行 train.py
1.训练参数设置
(1)data=data_yaml_path: 使用data.yaml中定义的数据集。
(2)epochs=150: 训练的轮数设置为100轮。
(3)batch=4: 每个批次的图像数量为4(批次大小)。
(4)name=’train_v8′: 训练结果将保存到以train_v8为名字的目录中。
(5)optimizer=’SGD’: 使用随机梯度下降法(SGD)作为优化器。
虽然在大多数深度学习任务中,GPU通常会提供更快的训练速度。
但在某些情况下,可能由于硬件限制或其他原因,用户需要在CPU上进行训练。
温馨提示:在CPU上训练深度学习模型通常会比在GPU上慢得多,尤其是像YOLOv8这样的计算密集型模型。除非特定需要,通常建议在GPU上进行训练以节省时间。
2.训练日志结果
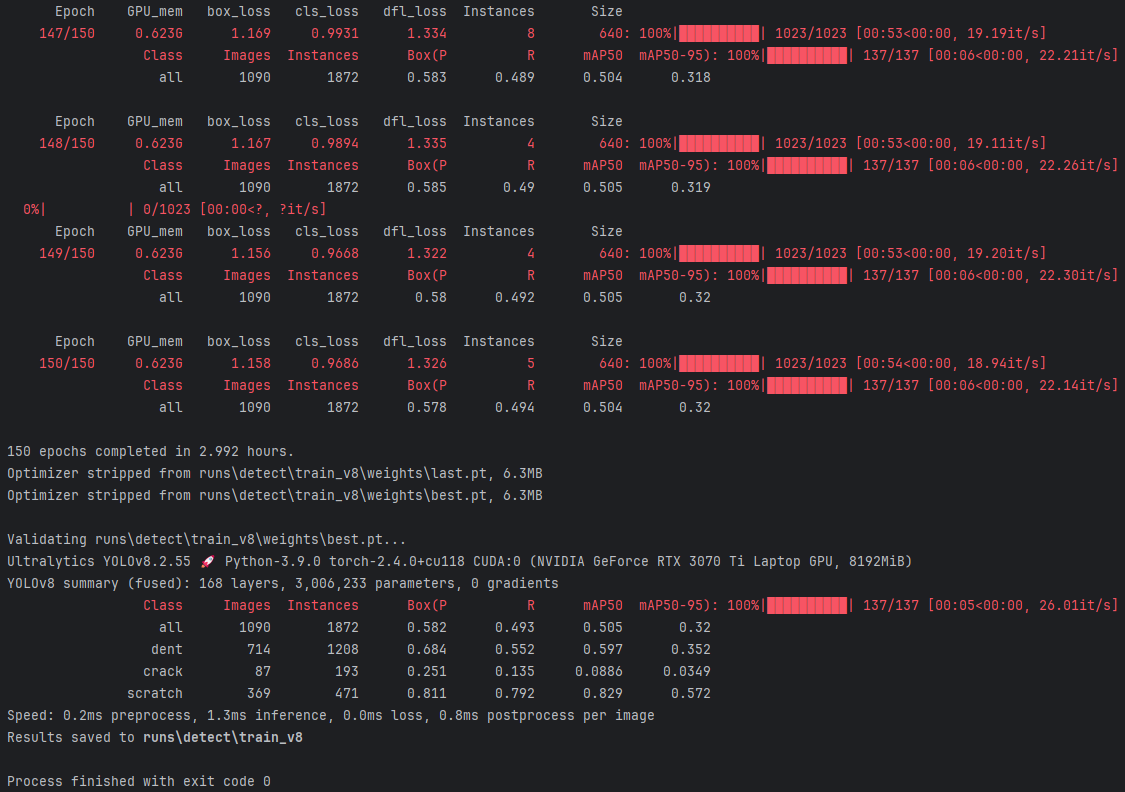
这张图展示了使用YOLOv8进行模型训练的详细过程和结果。
训练总时长:
(1)模型在训练了150轮后,总共耗时2.992小时。
各类指标:
(1)对于dent,精确率为0.684,召回率为0.552,mAP50为0.597,mAP50-95为0.352。
(2)对于crack,精确率为0.251,召回率为0.135,mAP50为0.0886,mAP50-95为0.0349,表现相对较低,表明模型在识别裂纹方面仍有较大提升空间。
(3)对于scratch,精确率为0.811,召回率为0.792,mAP50为0.829,mAP50-95为0.572,表现相对较好。
速度:
(1)0.2ms 预处理时间
(2)1.3ms 推理时间
(3)0.8ms 后处理时间
结果保存:
(1)Results saved to runs\detect\train_v8:验证结果保存在 runs\detect\train_v8 目录下。
完成信息:
(1)Process finished with exit code 0:表示整个验证过程顺利完成,没有报错。
这张图展示了使用YOLOv8模型训练和验证汽车车损检测系统的具体过程和性能指标,表明该模型在车损检测任务上具有良好的检测速度和较高的准确性。
相关文章:
基于YOLOv8深度学习的汽车车身车损检测系统研究与实现(PyQt5界面+数据集+训练代码)
本文研究并实现了一种基于YOLOV8深度学习模型的汽车车身车损检测系统,旨在解决传统车损检测中效率低、精度不高的问题。该系统利用YOLOV8的目标检测能力,在单张图像上实现了车身损坏区域的精确识别和分类,尤其是在车身凹痕、车身裂纹和车身划…...

力扣 LeetCode 144. 二叉树的前序遍历(Day6:二叉树)
解题思路: 方法一:递归(中左右) class Solution {List<Integer> res new ArrayList<>();public List<Integer> preorderTraversal(TreeNode root) {recur(root);return res;}public void recur(TreeNode roo…...
修图软件入门操作参考,收集查过的各个细节用法)
Adobe Illustrator(Ai)修图软件入门操作参考,收集查过的各个细节用法
到现在,对于Ai的使用也是一半一半,基本上都是用到啥就查啥。因为用得也不是很频繁,脑子也记不住很多操作,所以有时候靠肌肉记忆,很多时候,得再百度一遍…… 所以 我在这再备份一下,做个搬运工 …...

Apache Paimon、Apache Hudi、Apache Iceberg对比分析
Apache Paimon、Apache Hudi、Apache Iceberg 都是面向大数据湖的表格式存储管理框架。它们各自的架构、数据管理方式以及适用场景有所不同。下面是对三者的详细对比分析: 1. 基本简介 Apache Paimon: Paimon 是一个新兴的数据湖存储引擎,旨在支持流批一体的数据处理和管理…...

[ 网络安全介绍 5 ] 为什么要学习网络安全?
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...
生产环境centos8 Red Hat8部署ansible and 一键部署mysql两主两从ansible脚本预告
一、各节点服务器创建lvm逻辑卷组 1.初始化磁盘为物理卷(PV) 命令:sudo pvcreate /dev/vdb 2.创建卷组(VG) 命令:sudo vgcreate db_vg /dev/vdb 3.创建逻辑卷(LV) 命令:s…...

华为云stack网络服务流量走向
1.同VPC同子网同主机内ECS间互访流量走向 一句话通过主机内部br-int通信 2.同VPC同子网跨主机ECS间互访流量走向 3.同VPC不同子网同主机ECS间互访流量走向 查看ECS配置文件底层KVM技术 查看日志 查看ECS的ID号(管理员身份查询所有租户信息) 查看ECS的其…...

嵌入式硬件杂谈(二)-芯片输入接入0.1uf电容的本质(退耦电容)
引言:对于嵌入式硬件这个庞大的知识体系而言,太多离散的知识点很容易疏漏,因此对于这些容易忘记甚至不明白的知识点做成一个梳理,供大家参考以及学习,本文主要针对芯片输入接入0.1uf电容的本质的知识点的进行学习。 目…...

计算机网络HTTP——针对实习面试
目录 计算机网络HTTP什么是HTTP?HTTP和HTTPS有什么区别?分别说明HTTP/1.0、HTTP/2.0、HTTP/3.0请说明访问网页的全过程请说明HTTP常见的状态码Cookie和Session有什么区别?HTTP请求方式有哪些?请解释GET和POST的区别?HT…...

JAVA中对象实体与对象引用有何不同?举例说明
在 Java 中,对象实体(Object instance)和对象引用(Object reference)是两个不同的概念,虽然它们通常被一起讨论,但它们的作用和表现方式是不同的。下面我们来详细说明这两者的区别。 1. 对象实体…...

C++设计思想-001-设计模式-单例模式
1.单例模式优点 保证一个类仅有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享; 实现: 1.1 单例模式的类只提供私有的构造函数 1.2类定义中含有一个该类的静态私有对象 1.3该类提供了一个静态的公有的函数用于创建或获取它本身的静态私有对象 2.单…...

远程连接服务器
1、远程连接服务器简介 ssh secure shell 非对称加密:一对公钥私钥 对称加密:加密和解密使用的是同一把密钥;(同一秘钥既可以进行加密也可以进行解密 )优势:使用一个秘钥它的加密效率高一些(快一些) …...

【分布式技术】ES扩展知识-Elasticsearch分词器的知识与选择
ES知识扩展 分词器有哪些?1. 标准分词器(Standard Analyzer):示例示例文本分析配置参数与自定义应用场景 2. Simple Analyzer:示例示例文本分析应用场景与限制结论 3. Whitespace Analyzer:示例示例文本分析…...

【网络安全 | 漏洞挖掘】通过密码重置污染实现账户接管
未经许可,不得转载。 文章目录 密码重置污染攻击漏洞挖掘的过程目标选择与初步测试绕过 Cloudflare 的尝试发现两个域名利用 Origin 头部污染实现账户接管攻击流程总结在今天的文章中,我们将深入探讨一种 账户接管 漏洞,并详细分析如何绕过 Cloudflare 的保护机制,利用密码…...

【Nginx从入门到精通】01 、教程简介
讲师:张一鸣老师 课程简介 重量级课程 由浅入深,内容非常广泛 几十个线上的实战案例(图谱),几乎涵盖当前所有互联网主流应用场景 性能:由压测得出结果 调优:从操作系统开始,使你对高并发系统架构的技…...

MySQL面试之底层架构与库表设计
华子目录 mysql的底层架构客户端连接服务端连接的本质,连接用完会立马丢弃吗解析器和优化器的作用sql执行前会发生什么客户端的连接池和服务端的连接池数据库的三范式 mysql的底层架构 客户端连接服务端 连接的本质,连接用完会立马丢弃吗 解析器和优化器…...

C2 追踪器:监控指挥与控制的重要性
12 款暗网监控工具 20 款免费网络安全工具 移动取证软件:为什么 Belkasoft X 应该是您的首选工具 网络安全已成为不断演变的威胁形势中的关键领域。 网络攻击者经常使用命令和控制 (C2) 基础设施来执行和管理攻击。 这些基础设施使恶意软件和攻击者能够与受害设…...

二、神经网络基础与搭建
神经网络基础 前言一、神经网络1.1 基本概念1.2 工作原理 二、激活函数2.1 sigmoid激活函数2.1.1 公式2.1.2 注意事项 2.2 tanh激活函数2.2.1 公式2.2.2 注意事项 2.3 ReLU激活函数2.3.1 公式2.3.2 注意事项 2.4 SoftMax激活函数2.4.1 公式2.4.2 Softmax的性质2.4.3 Softmax的应…...

java导出pdf
引入包 <properties><itext.version>8.0.5</itext.version></properties><dependencies><dependency><groupId>com.itextpdf</groupId><artifactId>itext-core</artifactId><version>${itext.version}</…...

muduo之线程同步CountDownLatch
简介 CountDownLatch称为门阀,用于等待另外线程执行完成 结构 #mermaid-svg-6Azuu15vhIS2hCP1 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-6Azuu15vhIS2hCP1 .error-icon{fill:#552222;}#mermaid-s…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...

Python常用模块:time、os、shutil与flask初探
一、Flask初探 & PyCharm终端配置 目的: 快速搭建小型Web服务器以提供数据。 工具: 第三方Web框架 Flask (需 pip install flask 安装)。 安装 Flask: 建议: 使用 PyCharm 内置的 Terminal (模拟命令行) 进行安装,避免频繁切换。 PyCharm Terminal 配置建议: 打开 Py…...

在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南
在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南 背景介绍完整操作步骤1. 创建Docker容器环境2. 验证GUI显示功能3. 安装ROS Noetic4. 配置环境变量5. 创建ROS节点(小球运动模拟)6. 配置RVIZ默认视图7. 创建启动脚本8. 运行可视化系统效果展示与交互技术解析ROS节点通…...

CVE-2023-25194源码分析与漏洞复现(Kafka JNDI注入)
漏洞概述 漏洞名称:Apache Kafka Connect JNDI注入导致的远程代码执行漏洞 CVE编号:CVE-2023-25194 CVSS评分:8.8 影响版本:Apache Kafka 2.3.0 - 3.3.2 修复版本:≥ 3.4.0 漏洞类型:反序列化导致的远程代…...
【笔记】结合 Conda任意创建和配置不同 Python 版本的双轨隔离的 Poetry 虚拟环境
如何结合 Conda 任意创建和配置不同 Python 版本的双轨隔离的Poetry 虚拟环境? 在 Python 开发中,为不同项目配置独立且适配的虚拟环境至关重要。结合 Conda 和 Poetry 工具,能高效创建不同 Python 版本的 Poetry 虚拟环境,接下来…...