Datawhale模型减肥秘籍Tasking之模型量化
Datawhale模型减肥秘籍Tasking之模型量化
- 什么是量化?为什么量化?
- 量化基本方法
- 基于k-means的量化
- 线性量化
- 训练后量化
- 量化粒度
- 动态量化参数的计算 ( Cliping )
- 指数移动平均(EMA)
- Min-Max
- KL 量化
- 均方误差(MSE)
- Rounding
- 量化感知训练
- 前向传播
- 反向传播
- 实践内容
- 训练kmeans量化模型
- 参考资料
什么是量化?为什么量化?
剪枝操作能够减少网络的参数量,从而起到压缩模型的作用。而量化 (quantization) 是另一种能够压缩模型参数的方法。量化将神经网络的浮点算法转换为定点,修改网络中每个参数占用的比特数,从而减少模型参数占用的空间。
移动端的硬件资源有限,比如内存和算力。而量化可以减少模型的大小,从而减少内存和算力的占用。同时,量化可以提高模型的推理速度。下图为不同数据类型的加法和乘法操作的耗时对比。

模型量化的好处如下:
- 减小模型大小:如 int8 量化可减少 75% 的模型大小,int8 量化模型大小一般为 32 位浮点模型大小的 1/4。
- 减少存储空间:在端侧存储空间不足时更具备意义。
- 减少内存占用:更小的模型当然就意味着不需要更多的内存空间。
- 减少设备功耗:内存耗用少了推理速度快了自然减少了设备功耗。
- 加快推理速度:浮点型可以访问四次 int8 整型,整型运算比浮点型运算更快;CPU 用 int8 计算的速度更快。
某些硬件加速器如 DSP/NPU 只支持 int8。比如有些微处理器属于 8 位的,低功耗运行浮点运算速度慢,需要进行 8bit 量化。
量化基本方法
这里可以理解成要进行模型压缩,就是利用尽可能少的权重表示全局的量,那么意思就是说把一个连续的序列取尽可能少的值来表示整体模型的取值分布,也就是区间离散化
主要两种方法
- 基于 k-means 的量化(K-means-based Quantization):存储方式为整型权重 + 浮点型的转换表),计算方式为浮点计算。
- 线性量化(Linear Quantization):存储方式为整型权重存储,计算方式为整型计算。
基于k-means的量化
k-means是一个经典的聚类方法,这里属于是将k-means运用到了模型压缩的内容当中,我认为这样子是因为k-means首先比较经典,再加上实现起来比较简单所以会比较常用
如下图所示,k-means 量化将weights聚类。每个权重的位置只需要存储聚类的索引值。将权重聚类成4类(0,1,2,3),就可以实现2-bit的压缩。 存储占用从 32bit x 16 = 512 bit = 64 B => 2bit x 16 + 32 bit x 4 = 32 bit + 128 bit = 160 bit = 20 B
 当weight更大时,压缩比例将会更大。
当weight更大时,压缩比例将会更大。
下面是剪枝和k-means之间相结合的内容,首先循环得到最优的剪枝模型,然后利用量化的方法循环迭代尽可能少的权重

线性量化
线性量化是将原始浮点数据和量化后的定点数据之间建立一个简单的线性变换关系,因为卷积、全连接等网络层本身只是简单的线性计算,因此线性量化中可以直接用量化后的数据进行直接计算。
我们用 r r r表示浮点实数, q q q表示量化后的定点整数。浮点和整型之间的换算公式为:
r = S ( q − Z ) r=S(q-Z) r=S(q−Z)
q = r o u n d ( r / S + Z ) q=round(r/S+Z) q=round(r/S+Z)
其中, S S S是量化放缩的尺度,表示实数和整数之间的比例关系, Z Z Z是偏移量,表示浮点数中的 0 经过量化后对应的数(量化偏移),根据偏移量 Z Z Z是否为0,可以将浮点数的线性量化分为对称量化( Z = 0 Z=0 Z=0)和非对称量化( Z ≠ 0 Z≠0 Z=0)。大多数情况下量化是选用无符号整数,比如INT8的值域为[0,255],这种情况下需要要用非对称量化。
计算方法为:
S = r m a x − r m i n q m a x − q m i n S=\frac{r_{max}-r_{min}}{q_{max}-q_{min}} S=qmax−qminrmax−rmin
Z = r o u n d ( q m a x − r m a x S Z=round(q_{max}-\frac{r_{max}}{S} Z=round(qmax−Srmax
其中, r m i n r_{min} rmin 和 r m a x r_{max} rmax分别表示浮点数中的最小值和最大值, q m i n q_{min} qmin和 q m a x q_{max} qmax分别表示定点数中的最小值和最大值。

下面是计算的例子:

然后就可以计算量化后的矩阵:

这方面还有线性矩阵乘量化,最大值量化,全连接层线性量化等,其实基本上的思路就是给定一个规定,给一个范围的值映射到一个具体的值,从浮点数转成整数的方法去做
训练后量化
训练后量化(Post-Training Quantization, PTQ)是指在训练完成后,对模型进行量化,因此也叫做离线量化。
量化会带来精度损失,那么如何选取量化时所用参数(如scaling factor,zero point)可以尽可能地减少对准确率的影响呢?这也是我们需要关注的地方。量化误差来自两方面,一个是clip操作,一个是round操作。因此,我们还要介绍动态量化参数的计算方式,以及 round 这个操作带来的影响。
量化粒度
量化通常会导致模型精度下降。这就是量化粒度发挥作用的地方。选择正确的粒度有助于最大化量化,而不会大幅降低准确性性能。
逐张量量化(Per-Tensor Quantization)是指对每一层进行量化。在逐张量量化中,相同的量化参数应用于张量内的所有元素。在张量之间应用相同的参数会导致精度下降,因为张量内参数值的范围可能会有所不同。如下图的红框所示,3个channel共享一个量化参数。但是我们可以看到不同channel的数据范围是不同的。因此当 Layer-wise 量化效果不好时,需要对每个channel进行量化。

逐通道量化(Channel-wise Quantization就是将数据按照通道维度进行拆分,分别对每一通道的数据进行量化。相较于逐张量量化,逐通道量化可以减少量化误差,但需要更多的存储空间。逐通道量化可以更准确地捕获不同通道中的变化。这通常有助于 CNN 模型,因为不同通道的权重范围不同。由于现阶段模型越来越大,每个通道的参数也原来越多,参数的数值范围也越来越大,因此我们需要更细粒度的量化方式。
逐张量量化与逐通道量化的对比结果如下图所示。从图中可以看出:使用逐通道量化的误差更小,但付出的代价是必须存储更多信息(多个r和S) 。

组量化(Group Quantization)是指对通道内的数据拆分成多组向量,每组向量共享一个量化参数。VS-Quant 对张量的单个维度内的每个元素向量应用比例因子。它将通道维度细分为一组向量。
- 较小粒度时,使用较简单的整数缩放因子;
- 较大粒度时,使用较复杂的浮点缩放因子。
存储开销:对于两级缩放因子,假设使用4-bit的量化,每16个元素有一个4-bit的向量缩放因子,那么有效位宽为4+4/16=4.25bits。

为了提高能源效率,引入了两级缩放方案MX (Microscaling)。微缩放 (MX) 规范是从著名的 Microsoft 浮点 (MSFP) 数据类型升级而来的。该算法首先以每个向量的粒度计算浮点比例因子。然后,它通过将每向量比例因子分成整数逐向量分量和浮点逐通道分量来量化它们。MX 系列(如 MX4、MX6、MX9)表示了不同量化方案,它们的主要区别在于数据类型、缩放因子的设计以及组大小,目的在于通过压缩模型权重数据,优化神经网络的性能。
下图是不同的多级缩放方案对比结果。有效位宽 = (L0 数据位宽 + L0 量化尺度位宽 / L0 组大小 + L1 量化尺度位宽 / L1 组大小)。L0缩放因子通常采用较低的精度,用定点数表示,L1缩放因子则采用浮点数的表示方式。以MX6为例:L0数据类型是S1M4,表示1位符号位+4位尾数,共5位,用于表示数值。L0 量化尺度数据类型为E1M0,表示1位指数位,因此占1位。L0组大小是 2,这意味着L0量化尺度是针对每2个元素进行分组。L1 量化尺度数据类型为E8M0,表示8位指数位,因此占8 位。L1 组大小是 16,意味着 L1 量化尺度是针对每 16 个元素进行分组。所以可得到:有效位宽 = 5 + 1/2 + 8/16 = 6 bits。

动态量化参数的计算 ( Cliping )
指数移动平均(EMA)
指数移动平均(Exponential Moving Average, EMA)是一种常用的统计方法,用于计算数据的指数移动平均值。
EMA 收集了训练过程中激活函数的取值范围 r m i n r_{min} rmin和 r m a x r_{max} rmax,然后在每个 epoch 对这些取值范围进行平滑处理。
EMA的计算公式如下:
r min, max t + 1 = α r min,max t + ( 1 − α ) r min, t a x t + 1 r_{\text {min, } \max ^{t+1}}=\alpha r_{\text {min,max }}^{t}+(1-\alpha) r_{\text {min, }{ }^{t a x}}^{t+1} rmin, maxt+1=αrmin,max t+(1−α)rmin, taxt+1
其中, r m i n , m a x t r_{min,max}^t rmin,maxt表示第 t 步的取值范围, α α α 表示平滑系数。
Min-Max
Min-Max 是一种常用的校准方法,通过在训练好的 fp32 模型上跑少量的校准数据。统计校准数据的 r m i n , m a x r_{min,max} rmin,max并取平均值作为量化参数。
KL 量化
KL 量化是用 KL 散度来衡量数据和量化后的数据之间的相似性;这种方法是去寻找一个阈值 ∣ T ∣ < max ( ∣ max ∣ , ∣ min ∣ ) |T|<\max (|\max |,|\min |) ∣T∣<max(∣max∣,∣min∣),将
[ − T , T ] [−T,T] [−T,T]映射到 [−127,128] 。并假设只要阈值选取得当,使得两个数据之间的分布相似,就不会对精度损失造成影响。
D K L ( P ∥ Q ) = ∑ i = 1 n P ( x i ) log P ( x i ) Q ( x i ) D_{K L}(P \| Q)=\sum_{i=1}^{n} P\left(x_{i}\right) \log \frac{P\left(x_{i}\right)}{Q\left(x_{i}\right)} DKL(P∥Q)=i=1∑nP(xi)logQ(xi)P(xi)
均方误差(MSE)
均方误差量化是指通过最小化输入数据 X 和量化后的数据 Q(X) 之间的均方误差,计算得到最合适的量化参数。
min ∣ r ∣ max E ∣ ( X − Q ( X ) ) 2 ∣ \min _{|r|_{\max }} E\left|(X-Q(X))^{2}\right| ∣r∣maxminE (X−Q(X))2
通过动态调整 | r | m a x |r| max |r|max来最小化均方误差。
Rounding
Rounding 是指将浮点数进行舍入操作,将浮点数映射到整数。最常用的 Rounding 方法是最近整数(Rounding-to-nearest)。权重是互相关联的,对每个权重的最好舍入不一定是对整个张量的最好舍入。如下图所示,如果我们考虑整体的数据分布,将权重 0.5 舍入为 1 不是一个好的选择。

我们最终想要的量化效果是输出数据的损失尽可能小,因此我们可以通过评判 rounding 对输出的影响来决定权重的舍入方式,也就是 AdaRound。简化的计算公式如下所示:
argmin ∥ ( W x − W ^ x ) ∥ \operatorname{argmin}\|(W x-\widehat{W} x)\| argmin∥(Wx−W x)∥
其中,
W ^ = ⌊ ⌊ W ⌋ + σ ⌉ , σ ∈ [ 0 , 1 ] \widehat{W}=⌊⌊W⌋+σ⌉ , σ∈[0,1] W =⌊⌊W⌋+σ⌉,σ∈[0,1],表示当前值是向上取整还是向下取整。
量化感知训练
量化感知训练(Quantization-Aware Training, QAT)是指在训练过程中,对模型添加模拟量化算子,模拟量化模型在推理阶段的舍入和裁剪操作,引入量化误差。并通过反向传播更新模型参数,使得模型在量化后和量化前保持一致。
前向传播

反向传播

实践内容
进行了kmeans量化的训练,训练函数和验证函数如下
def train(model: nn.Module,dataloader: DataLoader,criterion: nn.Module,optimizer: Optimizer,scheduler: LambdaLR,callbacks = None
) -> None:model.train()for inputs, targets in tqdm(dataloader, desc='train', leave=False):# Move the data from CPU to GPU# inputs = inputs.to('mps')# targets = targets.to('mps')# Reset the gradients (from the last iteration)optimizer.zero_grad()# Forward inferenceoutputs = model(inputs)loss = criterion(outputs, targets)# Backward propagationloss.backward()# Update optimizer and LR scheduleroptimizer.step()scheduler.step()if callbacks is not None:for callback in callbacks:callback()
@torch.inference_mode()
def evaluate(model: nn.Module,dataloader: DataLoader,extra_preprocess = None
) -> float:model.eval()num_samples = 0num_correct = 0for inputs, targets in tqdm(dataloader, desc="eval", leave=False):# Move the data from CPU to GPU# inputs = inputs.to('mps')if extra_preprocess is not None:for preprocess in extra_preprocess:inputs = preprocess(inputs)# targets = targets.to('mps')# Inferenceoutputs = model(inputs)# Convert logits to class indicesoutputs = outputs.argmax(dim=1)# Update metricsnum_samples += targets.size(0)num_correct += (outputs == targets).sum()return (num_correct / num_samples * 100).item()
构建k-means量化模型参数
from fast_pytorch_kmeans import KMeans
from collections import namedtuple
import pdb
Codebook = namedtuple('Codebook', ['centroids', 'labels'])
def k_means_quantize(fp32_tensor: torch.Tensor, bitwidth=4, codebook=None):"""quantize tensor using k-means clustering:param fp32_tensor::param bitwidth: [int] quantization bit width, default=4:param codebook: [Codebook] (the cluster centroids, the cluster label tensor):return:[Codebook = (centroids, labels)]centroids: [torch.(cuda.)FloatTensor] the cluster centroidslabels: [torch.(cuda.)LongTensor] cluster label tensor"""if codebook is None:# 首先计算聚类的中心点个数# get number of clusters based on the quantization precisionn_clusters = 2**bitwidth# print(n_clusters)# 用kmeans算法得到聚类的中心# use k-means to get the quantization centroidskmeans = KMeans(n_clusters=n_clusters, mode='euclidean', verbose=0)labels = kmeans.fit_predict(fp32_tensor.view(-1, 1)).to(torch.long)centroids = kmeans.centroids.to(torch.float).view(-1)codebook = Codebook(centroids, labels)# decode the codebook into k-means quantized tensor for inference# 解码codebook,得到k-means量化后的tensorquantized_tensor = codebook.centroids[codebook.labels]fp32_tensor.set_(quantized_tensor.view_as(fp32_tensor))return codebookdef plot_matrix(tensor, ax, title, cmap=ListedColormap(['white'])):ax.imshow(tensor.cpu().numpy(), vmin=-0.5, vmax=0.5, cmap=cmap)ax.set_title(title)ax.set_yticklabels([])ax.set_xticklabels([])for i in range(0,tensor.shape[0]):for j in range(0,tensor.shape[1]):text = ax.text(j, i, f'{tensor[i, j].item():.2f}',ha="center", va="center", color="k") if __name__ == "__main__":bitwidth = 2test_tensor = torch.tensor([[-0.3747, 0.0874, 0.3200, -0.4868, 0.4404],[-0.0402, 0.2322, -0.2024, -0.4986, 0.1814],[ 0.3102, -0.3942, -0.2030, 0.0883, -0.4741]])fig, axes = plt.subplots(1,2, figsize=(8, 12))ax_left, ax_right = axes.ravel()plot_matrix(test_tensor, ax_left, 'original tensor')num_unique_values_before_quantization = test_tensor.unique().numel()codebook_test = k_means_quantize(fp32_tensor=test_tensor, bitwidth=bitwidth)# pdb.set_trace()num_unique_values_after_quantization = test_tensor.unique().numel()print(f' target bitwidth: {bitwidth} bits')print(f' num unique values before k-means quantization: {num_unique_values_before_quantization}')print(f' num unique values after k-means quantization: {num_unique_values_after_quantization}')assert num_unique_values_after_quantization == min((1 << bitwidth), num_unique_values_before_quantization)plot_matrix(test_tensor, ax_right, f'{bitwidth}-bit k-means quantized tensor', \cmap='tab20c')fig.tight_layout()plt.show()
运行结果如下:

训练kmeans量化模型

accuracy_drop_threshold = 0.5
quantizers_before_finetune = copy.deepcopy(quantizers)
quantizers_after_finetune = quantizersfor bitwidth in [8, 4, 2]:quantizer = quantizers[bitwidth]print(f'k-means quantizing model into {bitwidth} bits')quantizer.apply(model, update_centroids=False)quantized_model_size = get_model_size(model, bitwidth)print(f" {bitwidth}-bit k-means quantized model has size={quantized_model_size/MiB:.2f} MiB")quantized_model_accuracy = evaluate(model, test_loader)print(f" {bitwidth}-bit k-means quantized model has accuracy={quantized_model_accuracy:.2f}% before quantization-aware training ")accuracy_drop = fp32_model_accuracy - quantized_model_accuracyif accuracy_drop > accuracy_drop_threshold:print(f" Quantization-aware training due to accuracy drop={accuracy_drop:.2f}% is larger than threshold={accuracy_drop_threshold:.2f}%")num_finetune_epochs = 10optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, num_finetune_epochs)criterion = nn.CrossEntropyLoss()best_accuracy = 0epoch = num_finetune_epochswhile accuracy_drop > accuracy_drop_threshold and epoch > 0:train(model, train_loader, criterion, optimizer, scheduler,callbacks=[lambda: quantizer.apply(model, update_centroids=True)])model_accuracy = evaluate(model, test_loader)is_best = model_accuracy > best_accuracybest_accuracy = max(model_accuracy, best_accuracy)print(f' Epoch {num_finetune_epochs-epoch} Accuracy {model_accuracy:.2f}% / Best Accuracy: {best_accuracy:.2f}%')accuracy_drop = fp32_model_accuracy - best_accuracyepoch -= 1else:print(f" No need for quantization-aware training since accuracy drop={accuracy_drop:.2f}% is smaller than threshold={accuracy_drop_threshold:.2f}%")
训练过程截图:


参考资料
- 模型减肥秘籍:https://www.datawhale.cn/learn/content/68/963
- MIT教学课程:https://hanlab.mit.edu/courses/2024-fall-65940
相关文章:
Datawhale模型减肥秘籍Tasking之模型量化
Datawhale模型减肥秘籍Tasking之模型量化 什么是量化?为什么量化?量化基本方法基于k-means的量化线性量化 训练后量化量化粒度动态量化参数的计算 ( Cliping )指数移动平均(EMA)Min-MaxKL 量化均方误差(MSE)…...
在云服务器搭建 Docker
操作场景 本文档介绍如何在腾讯云云服务器上搭建和使用 Docker。本文适用于熟悉 Linux 操作系统,刚开始使用腾讯云云服务器的开发者。如需了解更多关于 Docker 相关信息,请参见 Docker 官方。 说明: Windows Subsystem for Linuxÿ…...

Redis 的代理类注入失败,连不上 redis
在测试 redis 是否成功连接时,发现 bean 没有被创建成功,导致报错 根据报错提示,需要我们添加依赖: <dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId>&l…...

版本控制【Git Bash】【Gitee】
目录 一、什么是版本控制? 二、版本控制的种类: 1、本地版本控制 2、集中版本控制 3、分布式版本控制 三、下载Git Bash 四、Git Bash 配置 五、Git Bash使用 1、切换目录:cd 2.查看当前文件路径:pwd 3.列出当前目录下文件…...

Neo4j Desktop 和 Neo4j Community Edition 区别
Neo4j Desktop 和 Neo4j Community Edition 的主要区别在于它们的用途、功能以及安装和管理方式。以下是这两者的详细对比: 1. Neo4j Desktop Neo4j Desktop 是一个图形化的桌面应用程序,主要为开发人员和个人使用提供了一个便捷的环境来安装、管理和运…...

使用uniapp开发微信小程序使用uni_modules导致主包文件过大,无法发布的解决方法
在使用uniapp开发微信小程序时候,过多的引入uni_modules的组件库,会导致主包文件过大,导致无法上传微信小程序,主包要求大小不超过1.5MB.分包大小每个不能超过2M。 解决方法:分包。 1.对每个除了主页面navbar的页面进…...
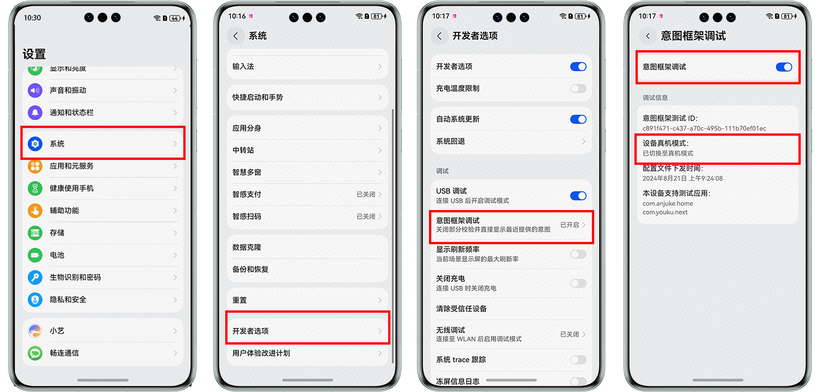
HarmonyOS NEXT应用元服务开发Intents Kit(意图框架服务)事件推荐开发者测试
意图框架向开发者提供真机测试能力,即开发者可连接设备进行调测。开发者完成代码开发之后,功能正式上架应用市场前,可以在HarmonyOS NEXT设备上面进行自验证,打磨体验。真机测试分为三个步骤:基础信息提供,…...

GD32F103 实践-- MCU编译运行
编译 打开固件库示例工程:在SDK路径下找到固件库示例工程,路径通常是SDK\GD32F10x_Firmware_Library_Template\Keil5_project\Project 选择芯片型号:根据你的MCU型号选择,例如GD32F103RCT6 修改宏定义:根据MCU型号修…...

SQL复杂数据类型处理
背景 数据处理中,经常碰到复杂数据类型,需要将他们进行解析才能利用。 复杂数据类型 1、MAP结构转为列 WITH tmp AS ( SELECT {"Users":{"4418":{"UserId":4418,"Score":0,"IsStudent":true},&q…...

ROS第九梯:ROS+VSCode+Python+C++自定义消息发布和订阅
首先,Python版本的ROS项目和C++版本的ROS项目前期创建功能包的步骤基本一致,具体可参考第二章。 费一步:新建msg文件 在功能包(data_input)目录下创建一个msg文件夹,并在msg文件夹下创建一个名为Box的msg文件,具体如下图所示: 该msg文件为一个用于描述3D Box的文件,…...

【Linux】指令 + 压缩与解压
Linux 一.Linux基本指令1.grep2.zip和unzip1.Linux中的压缩文件发送Windows中2.Linux中接收Windows中压缩文件 3.tar(重要)1.Linux与Linux互传压缩文件 4.bc5.uname 二.Linux相关知识点1.Linux常用热键2.关机操作 一.Linux基本指令 1.grep 行文本过滤工…...

力扣(leetcode)题目总结——动态规划篇
leetcode 经典题分类 链表数组字符串哈希表二分法双指针滑动窗口递归/回溯动态规划二叉树辅助栈 本系列专栏:点击进入 leetcode题目分类 关注走一波 前言:本系列文章初衷是为了按类别整理出力扣(leetcode)最经典题目,…...

数据仓库数据湖湖仓一体解决方案
一、资料介绍 数据仓库与数据湖是现代数据管理的两大核心概念。数据仓库是结构化的数据存储仓库,用于支持企业的决策分析,其数据经过清洗、整合,以固定的模式存储,适合复杂查询。数据湖则是一个集中存储大量原始数据的存储库&…...

微信小程序 最新获取用户头像以及用户名
一.在小程序改版为了安全起见 使用用户填写来获取头像以及用户名 二.代码实现 <view class"login_box"><!-- 头像 --><view class"avator_box"><button wx:if"{{ !userInfo.avatarUrl }}" class"avatorbtn" op…...

无人机在森林中的应用!
一、森林资源调查 无人机可以利用遥感技术快速获取所需区域高精度的空间遥感信息,对森林图斑进行精确区划。相较于传统手段,无人机调查具有低成本、高效率、高时效的特点,尤其在地理环境条件不好的区域,调查人员无法或难以到达的…...

Seatunnel解决Excel中无法将数字类型转换成字符串类型以及源码打包
需求 需要实现将Excel中的数字类型的单元格像数据库中字符串类型的字段中推送 问题原因 Seatunnel在读取字段类型的时候都是使用强转的形式去获取数据的 假如说数据类型不一样的话直接强转就会报错 修改位置 org/apache/seatunnel/api/table/type/SeaTunnelRow.java org…...

在阿里云快速启动Appsmith搭建前端页面
什么是Appsmith Appsmith是一个开源的低代码开发平台,它使得开发者能够快速地构建内部工具、业务管理系统、CRM系统等。Appsmith通过提供一系列预建的UI组件(如表格、图表、表单等),以及对数据库、API调用的直接支持,…...

「51媒体」:企业成长助推器
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 「51媒体」(51meiti media PR)作为国内具有影响力的媒体邀约服务商,确实在助力企业成长方面发挥着重要作用。以下是对「51媒体」的详细介绍࿰…...

安全、便捷、效率高,明达边缘计算网关助力制药装备企业远程调机
随着药厂对设备运维需求的增长,制药装备企业需要在提高运维效率的同时,降低人工及差旅成本。制药装备因其数据具有高度的保密性,要求运维工程师提供安全可靠的远程调试方式。本案例介绍了明达技术MBox20系列5口WIFI通用网关在制药装备上的应用…...

海康威视和大华视频设备对接方案
目录 一、海康威视 【老版本】 【新版本】 二、大华 一、海康威视 【老版本】 URL规定: rtsp://username:password[ipaddress]/[videotype]/ch[number]/[streamtype] 注:VLC可以支持解析URL里的用户名密码,实际发给设备的RTSP请求不支…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...

Spring AI Chat Memory 实战指南:Local 与 JDBC 存储集成
一个面向 Java 开发者的 Sring-Ai 示例工程项目,该项目是一个 Spring AI 快速入门的样例工程项目,旨在通过一些小的案例展示 Spring AI 框架的核心功能和使用方法。 项目采用模块化设计,每个模块都专注于特定的功能领域,便于学习和…...