MySQL深度剖析-索引原理由浅入深
什么是索引?
官方上面说索引是帮助MySQL高效获取数据的数据结构,通俗点的说,数据库索引好比是一本书的目录,可以直接根据页码找到对应的内容,目的就是为了加快数据库的查询速度。
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
如果没有加索引,我们会对数据库中的数据逐行比对,效率极低,所以我们可以根据索引快速定位到我们需要查询的数据,拿到定位后的信息再去查找。
索引的原理
那么问题来了,索引肯定要高效,如果只是用一个普通数组存下来,那不依然是遍历一遍效率很低吗,所以索引一定是一个非常高效的数据结构
索引的存储原理可以概括为一句话:以空间换时间
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往是存储在磁盘上的文件中的(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。
数据库在未添加索引进行查询的时候默认是进行全文搜索,也就是说有多少数据就进行多少次查询,然后找到相应的数据就把它们放到结果集中,直到全文扫描完毕。
索引有哪些?
主键索引
- 设定为主键后,数据库自动建立索引,InnoDB为聚簇索引,主键索引列值不能为空(Null)
# (1) 创建表添加主键索引
CREATE TABLE `table_name` ([...] ,PRIMARY KEY (`col_name`),
)
# (2) 添加主键索引
ALTER TABLE `table_name` ADD PRIMARY KEY (`col_name`);普通索引(单列索引)
- 普通索引(单列索引):单列索引是最基本的索引,它没有任何限制。
# (1) 直接创建索引
CREATE INDEX index_name ON table_name(`col_name`);
# (2) 修改表结构的方式添加索引
ALTER TABLE `table_name` ADD INDEX index_name(`col_name`);
# (3) 创建表的时候同时创建索引
CREATE TABLE `table_name` ([...] ,PRIMARY KEY (`id`),INDEX index_name (`col_name`)
)
# (4) 删除索引
DROP INDEX index_name ON table_name;
alter table `表名` drop index 索引名;复合索引(组合索引)
- 复合索引:复合索引是在多个字段上创建的索引。复合索引遵守“最左前缀”原则,即在查询条件中使用了复合索引的第一个字段,索引才会被使用。因此,在复合索引中索引列的顺序至关重要。
# (1)创建一个复合索引
create index index_name on table_name(`col_name1`,`col_name2`,...);
# (2)修改表结构的方式添加索引
alter table table_name add index index_name(`col_name1`,`col_name2`,...);唯一索引
唯一索引:唯一索引和普通索引类似,主要的区别在于,唯一索引限制列的值必须唯一,但允许存在空值(只允许存在一条空值)。
如果在已经有数据的表上添加唯一性索引的话:
- 如果添加索引的列的值存在两个或者两个以上的空值,则不能创建唯一性索引会失败。(一般在创建表的时候,要对自动设置唯一性索引,需要在字段上加上 not null)
- 如果添加索引的列的值存在两个或者两个以上的null值,还是可以创建唯一性索引,只是后面创建的数据不能再插入null值 ,并且严格意义上此列并不是唯一的,因为存在多个null值。
- 对于多个字段创建唯一索引规定列值的组合必须唯一
-- (1)创建唯一索引
# 创建单个索引
CREATE UNIQUE INDEX index_name ON table_name(`col_name`);# 创建多个索引
CREATE UNIQUE INDEX index_name on table_name(`col_name`,...);-- (2)修改表结构
# 单个
ALTER TABLE table_name ADD UNIQUE index index_name(`col_name`);
# 多个
ALTER TABLE table_name ADD UNIQUE index index_name(`col_name`,...);-- (3)创建表的时候直接指定索引
CREATE TABLE `table_name` ([...] ,PRIMARY KEY (`id`),UNIQUE index_name_unique(`col_name`)
)
“空值” 和”NULL”的概念:
1:空值是不占用空间的 .
2: MySQL中的NULL其实是占用空间的.长度验证:注意空值的之间是没有空格的。> select length(''),length(null),length(' ');
+------------+--------------+-------------+
| length('') | length(null) | length(' ') |
+------------+--------------+-------------+
| 0 | NULL | 1 |
+------------+--------------+-------------+全文索引
- Full Text类型索引(FULLTEXT 索引在 MySQL 5.6 版本之后支持 InnoDB,而之前的版本只支持 MyISAM 表)。
- 全文索引主要用来查找文本中的关键字,而不是直接与索引中的值相比较,目前只有char、varchar,text 列上可以创建全文索引。
-- (1)创建表的适合添加全文索引
CREATE TABLE `table_name` ([...] ,PRIMARY KEY (`id`),FULLTEXT (`col_name`)
)-- (2)修改表结构添加全文索引
ALTER TABLE table_name ADD FULLTEXT index_fulltext_content(`col_name`)-- (3)直接创建索引
CREATE FULLTEXT INDEX index_fulltext_content ON table_name(`col_name`)注意:
- 默认 MySQL 不支持中文全文检索!
- MySQL 全文搜索只是一个临时方案,对于全文搜索场景,更专业的做法是使用全文搜索引擎,例如 ElasticSearch 或 Solr。
索引的查询和删除命令:
#查看:
show indexes from `表名`;
#或
show keys from `表名`;#删除
alter table `表名` drop index 索引名;索引的优缺点
优点:
- 大大提高数据查询速度。
- 可以提高数据检索的效率,降低数据库的IO成本,类似于书的目录。
- 通过索引列对数据进行排序,降低数据的排序成本降低了CPU的消耗。
- 被索引的列会自动进行排序,包括【单例索引】和【组合索引】,只是组合索引的排序需要复杂一些。
- 如果按照索引列的顺序进行排序,对order 不用语句来说,效率就会提高很多。
缺点:
- 索引会占据磁盘空间。
- 索引虽然会提高查询效率,但是会降低更新表的效率。比如每次对表进行增删改查操作,MySQL不仅要保存数据,还有保存或者更新对应的索引文件。
- 维护索引需要消耗数据库资源。
所以,综合索引的优缺点:
数据库表中不是索引越多越好,而是仅为那些常用的搜索字段建立索引效果最佳!(也即where后面常用到的字段建立索引效果最佳)
索引的数据结构
前面我们说到,索引就类似于目录,索引也是一个数据结构,存放一些字段对应的磁盘地址,索引的特点就是要高效快速定位查找等,不然就简简单单用一个数组查询,还是一样的全表扫描遍历。
所以,索引一定是用高效查找的数据结构来实现的!!!
我们来依次看看有哪些数据结构用来做索引,以及各种数据结构的优缺点和为什么InnoDB默认采用的B+树(对应的面试题:为什么MySQL存储引擎InnoDB索引的底层数据结构采用B+树)
Hash
Hash表,在Java中的HashMap,TreeMap就是Hash表结构,以键值对的形式存储数据。我们使用hash表存储表数据结构,Key可以存储索引列,Value可以存储行记录或者行磁盘地址。Hash表在等值查询时效率很高,时间复杂度为O(1);但是不支持范围快速查找(因为Hash表是无序的呀!),范围查找时只能通过扫描全表的方式,筛选出符合条件的数据。
显然这种方式,不适合我们经常需要查找和范围查找的数据库索引使用。
二叉树

上面这个图就是我们常说的二叉树:每个节点最多有两个分叉节点,左子树和右子树数据按顺序左小右大。
二叉树的特点就是为了保证每次查找都可以进行折半查找,从而减少IO次数。
但是二叉树不是一直保持二叉平衡,因为二叉树很考验根节点的取值,因为很容易在某个节点下不分叉了,这样的话二叉树就不平衡了,也就没有了所谓的能进行折半查找了,如下图:

对于MySQL每次从磁盘加载的大小为16kb,如果刚好一个节点就是16kb,那么这里查找5号节点就要做5次磁盘IO
显然这种不稳定的情况,我们在选择存储数据结构的时候就会尽量避免这种的情况发生。
另外,二叉树也不适合范围查询,进行范围查询每次都只能从根节点往后找(只找一个)
平衡二叉树(AVL树)
为了解决二叉树在极端情况下会退化成链表的问题,考虑使用平衡二叉树,其特点就是每个节点的左子树和右子树高度差不能超过1,所以他会通过旋转来维护二叉树的平衡性,所以就不会像普通二叉树一样出现“歪脖子”问题
平衡二叉树采用的是二分法思维,平衡二叉查找树除了具备二叉树的特点,最主要的特征是树的左右两个子树的层级最多差1。在插入删除数据时通过左旋/右旋操作保持二叉树的平衡,不会出现左子树很高、右子树很矮的情况。
使用平衡二叉查找树查询的性能接近与二分查找,时间复杂度为O(log2n),查询id=6,只需要两次IO。

就上述平衡二叉树的特点来看,其实是我们理想的状态下,然而其实内部还是存在一些问题:
- 时间复杂度和树的高度有关。树有多高就需要检索多少次,每个节点的读取,都对应一次磁盘的IO操作。树的高度就等于每次查询数据时磁盘IO操作的次数。磁盘每次寻道的时间为10ms,在数据量大时,查询性能会很差。(1百万的数据量,log2n约等于20次磁盘IO读写,时间消耗约等于:20*10=0.2S)。
- 平衡二叉树不支持范围查询快速查找,范围查询需要从根节点多次遍历,查询效率不高。
B树
AVL树、红黑树都是常见的平衡二叉树,不管是哪个,其一个节点最多只能有两个分支,都会随着插入的元素增多,而导致树的高度变高,就意味着磁盘IO的次数变多,会影响整体数据的查询效率
那么就有一个需求了:在树的高度不那么高的情况下,如何能满足存储大数据量
答:多叉平衡树

MySQL的数据是存储在磁盘文件中的,查询处理数据时,需要先把磁盘中的数据加载到内存中,磁盘IO操作非常耗时,所以我们优化的重点就是尽量减少磁盘的IO操作。访问二叉树的每个节点都会发生一次IO,如果想要减少磁盘IO操作,就需要尽量降低树的高度。
那如何降低树的高度呢?
假如key为bigint=8字节,每个节点有两个指针,每个指针为4个字节,一个节点占用的空间为(8+4*2=16)。
因为在MySQL的InnoDB引擎的一次IO操作会读取一页的数据量(默认一页大小为16K),而二叉树一次IO操作的有效数据量只有16字节,空间利用率极低。为了最大化的利用一次IO操作空间,一个解决方法就是在一个节点处存储多个元素,在每个节点尽可能多的存储数据。每个节点可以存储1000个索引(16k/16=1000),这样就将二叉树改造成了多叉树,通过增加树的分叉树,将树的体型从高瘦变成了矮胖。构建1百万条数据,树的高度需要2层就可以(1000*1000=1百万),也就是说只需要两次磁盘IO操作就可以查询到数据,磁盘IO操作次数变少了,查询数据的效率整体也就提高了。
这种数据结构我们称之为B树,B树是一种多叉平衡查找树,如下图主要特点:
- B树的节点中存储这多个元素,每个内节点有多个分叉。
- 节点中的元素包含键值和数据,节点中的键值从小到大排列。也就是说,在所有的节点中都存储数据。
- 父节点当中的元素不会出现在子节点中。
- 所有的叶子节点都位于同一层,叶子节点具有相同的深度,叶子节点之间没有指针连接。

举个简单的例子,在B树中查询数据的情况:
假如我们要查询key等于10对应的数据data,根据上图我们可知在磁盘中的查询路径是:磁盘块1->磁盘块2->磁盘块6- 第一次磁盘IO:将磁盘块1加载到内存中,在内存中从头遍历比较,10<15,走左子树,到磁盘中寻址到磁盘块2。
- 第二次磁盘IO:将磁盘块2加载到内存中,在内存中从头遍历比较,10>7,走右子树,到磁盘中寻址到磁盘块6。
- 第三次磁盘IO:将磁盘块6加载到内存中,在内存中从头遍历比较,10=10,找到key=10的位置,取出对应的数据data,如果data存储的是行记录,直接取出数据,查询结束;如果data存储的是行磁盘地址,还需要根据磁盘地址到对应的磁盘中取出数据,查询结束。
相比较二叉平衡查找树,在整个查找过程中,
虽然数据的比较次数并没有明显减少,但是对于磁盘IO的次数会大大减少,
同时,由于我们是在内存中进行的数据比较,所以比较数据所消耗的时间可以忽略不计。
B树的高度一般2至3层就能满足大部分的应用场景,所以使用B树构建索引可以很好的提升查询的效率。
看到上面的情况,觉得B树已经很理想了,但是其中还是存在可以优化的地方:
- B树不支持范围查询的快速查找,例如:仍然根据上图,我们想要查询10到35之间的数据,查找到10之后,需要回到根节点重新遍历查找,需要从根节点进行多次遍历,查询效率有待提高。
- 如果data存储的是行记录,行的大小随着列数的增加,所占空间会变大,这时一页中可存储的数据量就会减少,树相应就会变高,磁盘IO次数就会随之增加,有待优化。
B+树
B+树,作为B树的升级版,MySQL在B树的基础上继续进行改造,使用B+树构建索引。B+树和B树最主要的区别在于非叶子节点是否存储数据的问题。
- B树:叶子节点和非叶子节点都会存储数据。
- B+树:只有叶子节点才会存储数据,非叶子节点只存储键值key;叶子节点之间使用双向指针连接,最底层的叶子节点形成了一个双向有序链表。

B+树的最底层叶子节点包含了所有的索引项。从图上可以看到,B+树在查找数据的时候,由于数据都存放在最底层的叶子节点上,所以每次查找都需要检索到叶子节点才能查询到数据。所以在需要查询数据的情况下每次的磁盘的IO跟树高有直接的关系,但是从另一方面来说,由于数据都被放到了叶子节点,所以放索引的磁盘块锁存放的索引数量是会跟这增加的,所以相对于B树来说,B+树的树高理论上情况下是比B树要矮的。也存在索引覆盖查询的情况,在索引中数据满足了当前查询语句所需要的全部数据,此时只需要找到索引即可立刻返回,不需要检索到最底层的叶子节点。
举例:等值查询
假如我们查询值等于9的数据。查询路径磁盘块1->磁盘块2->磁盘块6。
- 第一次磁盘IO:将磁盘块1加载到内存中,在内存中从头遍历比较,9<15,走左路,到磁盘寻址磁盘块2。
- 第二次磁盘IO:将磁盘块2加载到内存中,在内存中从头遍历比较,7<9<12,到磁盘中寻址定位到磁盘块6。
- 第三次磁盘IO:将磁盘块6加载到内存中,在内存中从头遍历比较,在第三个索引中找到9,取出data,如果data存储的行记录,取出data,查询结束。如果存储的是磁盘地址,还需要根据磁盘地址到磁盘中取出数据,查询终止。(这里需要区分的是在InnoDB中Data存储的为行数据,而MyIsam中存储的是磁盘地址。)

举例:范围查询
假如我们想要查找9和26之间的数据,查找路径为:磁盘块1->磁盘块2->磁盘块6->磁盘块7
- 前三次磁盘IO:首先查找到键值为9对应的数据(定位到磁盘块6),然后缓存大结果集中。这一步和前面等值查询流程一样,发生了三次磁盘IO。
- 继续查询,查找到节点15之后,底层的所有叶子节点是一个有序列表,我们从磁盘块6中的键值9开始向后遍历筛选出所有符合条件的数据。
- 第四次磁盘IO:根据磁盘块6的后继指针到磁盘中寻址定位到磁盘块7,将磁盘块7加载到内存中,在内存中从头遍历比较,9<25<26,9<26<=26,将数据data缓存到结果集中。
- 逐渐具备唯一性(后面不会再有<=26的数据),不需要再向后查找,查询结束,将结果集返回给用户。
 可以看到B+树可以保证等值和范围查询的快速查找,MySQL的索引就采用了B+树的数据结构。
可以看到B+树可以保证等值和范围查询的快速查找,MySQL的索引就采用了B+树的数据结构。
MySQL是如何实现索引的
介绍完了索引数据结构,那肯定是要带入到Mysql里面看看真实的使用场景的,所以这里分析Mysql的两种存储引擎的索引实现:MyISAM索引和InnoDB索引
InnoDB索引
以下介绍其实在“什么是索引?#索引有哪些?”,下面的介绍会做一些补充
聚簇索引(主键索引)
每个InnoDB表都有一个聚簇索引 ,聚簇索引使用B+树构建,叶子节点存储的数据是整行记录。一般情况下,聚簇索引等同于主键索引,当一个表没有创建主键索引时,InnoDB会自动创建一个ROWID字段来构建聚簇索引。
InnoDB创建索引的具体规则如下:
- 在表上定义主键PRIMARY KEY,InnoDB将主键索引用作聚簇索引。
- 如果表没有定义主键,InnoDB会选择第一个不为NULL的唯一索引列用作聚簇索引。
- 如果以上两个都没有,InnoDB 会使用一个6 字节长整型的隐式字段 ROWID字段构建聚簇索引。该ROWID字段会在插入新行时自动递增。
除聚簇索引之外的所有索引都称为辅助索引。在中InnoDB,辅助索引中的叶子节点存储的数据是该行的主键值。 在检索时,InnoDB使用此主键值在聚簇索引中搜索行记录。
这里以user_innodb为例,user_innodb的id列为主键,age列为普通索引。
CREATE TABLE `user_innodb`
(`id` int(11) NOT NULL AUTO_INCREMENT,`username` varchar(20) DEFAULT NULL,`age` int(11) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,KEY `idx_age` (`age`) USING BTREE
) ENGINE = InnoDB;
- InnoDB的数据和索引存储在
t_user_innodb.ibd文件中,InnoDB的数据组织方式,是聚簇索引。 - 主键索引的叶子节点会存储数据行,辅助索引的叶子节点只会存储主键值。

等值查询数据:
select * from user_innodb where id = 28;- 先在主键树中从根节点开始检索,将根节点加载到内存,比较28<75,走左路。(1次磁盘IO)
- 将左子树节点加载到内存中,比较16<28<47,向下检索。(1次磁盘IO)
- 检索到叶节点,将节点加载到内存中遍历,比较16<28,18<28,28=28。查找到值等于28的索引项,直接可以获取整行数据。将改记录返回给客户端。(1次磁盘IO)
磁盘IO数量:3次。

辅助索引(普通索引)
除聚簇索引之外的所有索引都称为辅助索引,InnoDB的辅助索引只会存储主键值而非磁盘地址也非行记录。
以表user_innodb的age列为例,age索引的索引结果如下图。

- 辅助索引的底层叶子节点是按照(age,id)的顺序排序,先按照age列从小到大排序,age相同时按照id列从小到大排序。
- 使用辅助索引需要检索两遍索引:首先检索辅助索引获得主键,然后根据主键到主键索引中检索获得数据记录。
辅助索引等值查询的情况:
select * from t_user_innodb where age=19;
根据在辅助索引树中获取的主键id,到主键索引树检索数据的过程称为回表查询。
磁盘IO数:辅助索引3次+获取记录回表3次
请记住,这里产生了回表,显然,回表是消耗很多性能的,使查询效率大大降低(磁盘IO次数显而易见的增多),所以我们有覆盖索引来优化他
联合索引
刚才介绍的辅助索引其实就是对单一字段做一个普通索引罢了,其实联合索引就是创建普通索引的时候,多索引几个字段
# (1)创建一个复合索引
create index index_name on table_name(`col_name1`,`col_name2`,...);
# (2)修改表结构的方式添加索引
alter table table_name add index index_name(`col_name1`,`col_name2`,...);最左匹配原则
它指出,查询条件必须从联合索引的最左边的列开始匹配,且必须连续匹配。只有当查询条件包含联合索引的最左边的列时,数据库引擎才会使用该索引。
使用联合索引时,存在‘最左匹配原则’,要求where后面的查询条件,需要包含构建联合索引的第一个字段
最左前缀匹配原则和联合索引的索引存储结构和检索方式是有关系的。
上面的col_name1/col_name2/col_name3,我在下面就称为a/b/c列
在组合索引树中,最底层的叶子节点按照第一列a列从左到右递增排序,但是b列和c列是无序的,b列只有在a列值相等的情况下小范围内有序递增;而c列只能在a和b两列值相等的情况下小范围内有序递增。
就像上面的查询,B+ 树会先比较a列来确定下一步应该检索的方向,往左还是往右。如果a列相同再比较b列,但是如果查询条件中没有a列,B+树就不知道第一步应该从那个节点开始查起。
可以说创建的idx_(a,b,c)索引,相当于创建了(a)、(a,b)、(a,b,c)三个索引。

接下来通过几条sql来看看最左匹配原则的匹配过程,以及不遵循最左匹配原则导致的索引失效问题
CREATE TABLE `abc_innodb`
(`id` int(11) NOT NULL AUTO_INCREMENT,`a` int(11) DEFAULT NULL,`b` int(11) DEFAULT NULL,`c` varchar(10) DEFAULT NULL,`d` varchar(10) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,KEY `idx_abc` (`a`, `b`, `c`)
) ENGINE = InnoDB;show index from abc_innodb-- 是否会匹配索引
-- (1)
explain select * from abc_innodb where a = 1 and b = 2
explain select * from abc_innodb where b = 2 and a = 1-- (2)
explain select * from abc_innodb where b = 2-- (3)
explain select * from abc_innodb where a = 1 and b>2 and c=3哪几条SQL会使用索引?(索引的匹配过程)
explain select * from abc_innodb where a = 1 and b = 2
这一条肯定是匹配的,完全满足最左匹配原则,先按照a来查询索引,a相同的时候,再按照b来找explain select * from abc_innodb where b = 2 and a = 1
这一条也是匹配的,但是这里是先按照b来找啊,应该不满足最左匹配原则了啊?
因为这里MySQL的优化器对我们的sql进行了优化:即只要where后面包含了联合索引的第一个字段,我就能匹配到索引explain select * from abc_innodb where b = 2
这个是无法匹配索引的,因为这里只按照b来进行索引查找,而b只是局部有序,只有a才是全局有序explain select * from abc_innodb where a = 1 and b>2 and c=3
这个是可以匹配的,但是只能部分匹配,a=1肯定是匹配的,但是遇到了b>2,b只是在a的小范围有序
其他a范围的b可能也包含>2的数据,搜易到这里肯定不能继续使用索引了注:使用组合索引查询时,mysql会一直向右匹配直至遇到范围查询(>、<、between、like)等就会停止匹配。
总结:如何用好联合索引?
除了在写sql的时候满足最左匹配原则之外,还应该把频繁使用的列、区分度高的列放在前面,频繁使用代表索引利用率高,区分度高代表筛选粒度大,这些都是在索引创建时候需要考虑的优化场景
覆盖索引原则
如何避免回表?
覆盖索引并不是一种索引结构,覆盖索引是一种很常用的优化手段。因为在使用辅助索引的时候,我们只可以拿到相应的主键值,想要获取最终的数据记录,还需要根据主键通过主键索引再去检索,最终获取到符合条件的数据记录。
那么,覆盖索引是指一个索引包含了查询所需的全部列。当查询只需要这些列时,数据库引擎可以直接从索引中读取数据,而不需要访问表中的数据行。这种优化可以减少磁盘 I/O 和提高查询速度。
显然,覆盖索引会增加索引的大小,因为索引中包含更多的列。因此,需要权衡索引的大小和查询性能。
如何使用覆盖索引
CREATE TABLE orders (order_id INT PRIMARY KEY,customer_id INT,order_date DATE,total_amount DECIMAL(10, 2),status VARCHAR(50)
);如果你经常执行以下查询:
SELECT order_id, customer_id, order_date FROM orders WHERE status = 'Completed';你可以用辅助索引把他们三个字段都圈起来(创建多个字段的联合索引),这样就能避免单一的辅助索引致使回表问题
这其实是一种数据库索引调优方案
CREATE INDEX idx_covering ON orders (status, order_id, customer_id, order_date);在这个索引中,status 是查询条件列,order_id、customer_id 和 order_date 是查询结果列。这样,索引包含了查询所需的全部列,可以作为覆盖索引使用。
一旦创建了覆盖索引,数据库引擎会自动选择使用它来优化查询。你可以通过执行计划来验证是否使用了覆盖索引。例如,在 MySQL 中,可以使用 EXPLAIN 命令来查看查询计划:
EXPLAIN SELECT order_id, customer_id, order_date FROM orders WHERE status = 'Completed';在查询计划中,如果看到 Using index,则表示使用了覆盖索引
MyIsam索引
对于MyIsam索引我们了解一下就行,主要是了解与InnoDB的区别
以一个简单的user表为例。user表存在两个索引,id列为主键索引,age列为普通索引
CREATE TABLE `user`
(`id` int(11) NOT NULL AUTO_INCREMENT,`username` varchar(20) DEFAULT NULL,`age` int(11) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,KEY `idx_age` (`age`) USING BTREE
) ENGINE = MyISAMAUTO_INCREMENT = 1DEFAULT CHARSET = utf8;MyISAM的数据文件和索引文件是分开存储的。MyISAM使用B+树构建索引树时,叶子节点中存储的键值为索引列的值,数据为索引所在行的磁盘地址。

在磁盘IO次数上,MyIsam要比InnoDB多一次根据地址去磁盘拿数据的操作
在MyISAM存储引擎中,辅助索引和主键索引的结构是一样的,没有任何区别,叶子节点中data阈存储的都是行记录的磁盘地址。 主键列索引的键值是唯一的,而辅助索引的键值是可以重复的。
相关文章:
MySQL深度剖析-索引原理由浅入深
什么是索引? 官方上面说索引是帮助MySQL高效获取数据的数据结构,通俗点的说,数据库索引好比是一本书的目录,可以直接根据页码找到对应的内容,目的就是为了加快数据库的查询速度。 索引是对数据库表中一列或多列的值进…...
路径规划——RRT-Connect算法
路径规划——RRT-Connect算法 算法原理 RRT-Connect算法是在RRT算法的基础上进行的扩展,引入了双树生长,分别以起点和目标点为树的根节点同时扩展随机树从而实现对状态空间的快速搜索。在此算法中以两棵随机树建立连接为路径规划成功的条件。并且&…...

数据科学与SQL:如何计算排列熵?| 基于SQL实现
目录 0 引言 1 排列熵的计算原理 2 数据准备 3 问题分析 4 小结 0 引言 把“熵”应用在系统论中的信息管理方法称为熵方法。熵越大,说明系统越混乱,携带的信息越少;熵越小,说明系统越有序,携带的信息越多。在传感…...

Redis/Codis性能瓶颈揭秘:网卡软中断的影响与优化
目录 现象回顾 问题剖析 现场分析 解决方案 总结与反思 1.调整中断亲和性(IRQ Affinity): 2.RPS(Receive Packet Steering)和 RFS(Receive Flow Steering): 近期,…...
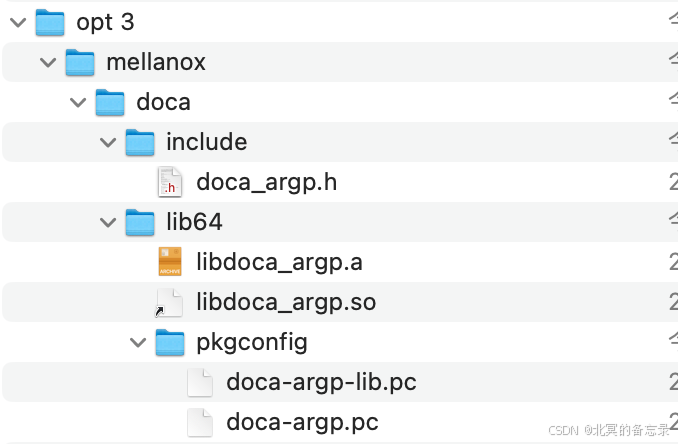
微知-DOCA ARGP参数模块的相关接口和用法(config单元、params单元,argp pipe line,回调)
文章目录 1. 背景2. 设置参数的主要流程2.1 初始化2.2 注册某个params的处理方式以及回调函数2.4 定义好前面的params以及init指定config地点后start处理argv 3. 其他4. DOCA ARGP包相关4.1 主要接口4.2 DOCA ARGP的2个rpm包4.2.1 doca-sdk-argp-2.9.0072-1.el8.x86_64.rpm4.2.…...
)
PostgreSQL高可用Patroni安装(超详细)
目录 一 安装Patroni 0 Patroni 对Python的版本要求 1 卸载原来的Python 3.6 版本 2 安装Python 3.7 之上版本 3 安装依赖 psycopg3 4 安装patroni 5 卸载 patroni 二 安装ETCD 1 使用 yum 安装 etcd 2 etcd 配置文件 3 管理 etcd 4 设置密码 5 常用命令 三 安装…...
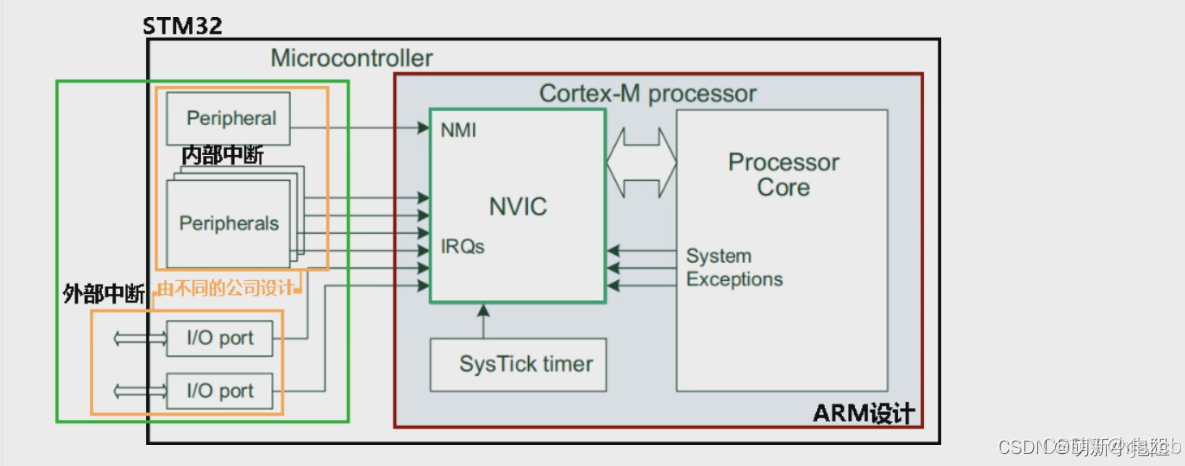
mcu之,armv7架构,contex-M4系列,时钟树,中断,IO架构(一)
写这篇文章的目的,是记录一下arm架构的32mcu,方便记忆芯片架构原理,方便我展开对,BootLoader的研究。 arm架构,时钟树,先做个记录,有空写。...
)
论文解析:基于区块链的去中心化服务选择,用于QoS感知的云制造(四区)
目录 论文解析:基于区块链的去中心化服务选择,用于QoS感知的云制造(四区) 基于区块链的去中心化云制造服务选择方法 一、核心内容概述 二、核心创新点及原理与理论 三、实验与理论分析 PBFT(实用拜占庭容错) 论文解析:基于区块链的去中心化服务选择,用于QoS感知的…...
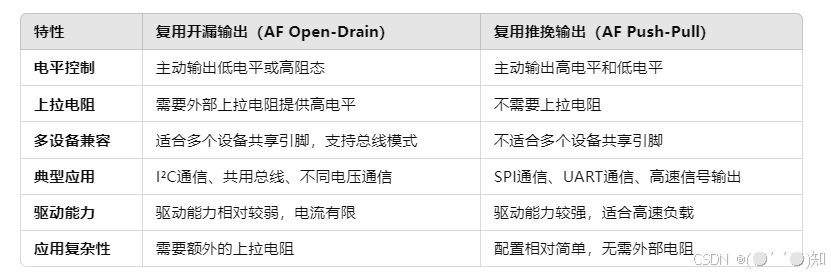
详细解析STM32 GPIO引脚的8种模式
目录 一、输入浮空(Floating Input):GPIO引脚不连接任何上拉或下拉电阻,处于高阻态 1.浮空输入的定义 2.浮空输入的特点 3.浮空输入的应用场景 4.浮空输入的缺点 5.典型配置方式 6.注意事项 二、输入上拉(Inpu…...

【hacker送书第16期】Python数据分析、挖掘与可视化、AI全能助手ChatGPT职场工作效率提升技巧与案例
解锁数据分析与AI应用的双重秘密:全面推广《Python数据分析、挖掘与可视化从入门到精通》与《AI全能助手ChatGPT职场工作效率提升技巧与案例》 前言Python数据分析、挖掘与可视化从入门到精通💕内容简介获取方式 AI全能助手ChatGPT职场工作效率提升技巧与…...

翼鸥教育:从OceanBase V3.1.4 到 V4.2.1,8套核心集群升级实践
引言:自2021年起,翼鸥教育便开始应用OceanBase社区版,两年间,先后部署了总计12套生产集群,其中核心集群占比超过四分之三,所承载的数据量已突破30TB。自2022年10月,OceanBase 社区发布了4.2.x 版…...

WebGIS开发中不同坐标系坐标转换问题
在 JavaScript 中,使用 proj4 库进行坐标系转换是一个非常常见的操作。proj4 是一个支持多种坐标系的 JavaScript 库,提供了从一种坐标系到另一种坐标系的转换功能。 以下是使用 proj4 进行坐标系转换的基本步骤: 1. 安装 proj4 你可以通过…...
【青牛科技】视频监控器应用
1、简介: 我司安防产品广泛应用在视频监控器上,产品具有性能优良,可 靠性高等特点。 2、图示: 实物图如下: 3、具体应用: 标题:视频监控器应用 简介:视频监控器工作原理是光&#x…...
AWTK-WIDGET-WEB-VIEW 实现笔记 (3) - MacOS
MacOS 上实现 AWTK-WIDGET-WEB-VIEW 有点麻烦,主要原因是没有一个简单的办法将一个 WebView 嵌入到一个窗口中。所以,我们只能通过创建一个独立的窗口来实现。 1. 创建窗口 我对 Object-C 不熟悉,也不熟悉 Cocoa 框架,在 ChatGPT…...
PgSQL即时编译JIT | 第1期 | JIT初识
PgSQL即时编译JIT | 第1期 | JIT初识 JIT是Just-In-Time的缩写,也就是说程序在执行的时候生成可以执行的代码,然后执行它。在介绍JIT之前,需要说下两种执行方式:解释执行和编译执行。其中解释执行是通过解释器,将代码逐…...

Go小记:使用Go实现ssh客户端
一、前言 SSH(Secure Shell)是一种用于在不安全网络上安全访问远程计算机的网络协议。它通过加密的方式提供远程登录会话和其他网络服务,保证通信的安全性和数据的完整性。 本文使用golang.org/x/crypto/ssh包来实现SSH客户端 可以通过go …...

Nginx Spring boot指定域名跨域设置
1、Nginx配置跨域: server {listen 80;server_name your-backend-service.com;location / {proxy_pass http://localhost:8080; # Spring Boot应用的内部地址proxy_set_header Host $host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-F…...

深入理解Redis(七)----Redis实现分布式锁
基于Redis的实现方式 1、选用Redis实现分布式锁原因: (1)Redis有很高的性能; (2)Redis命令对此支持较好,实现起来比较方便 2、使用命令介绍: (1)SETNX SETNX …...
)
Database Advantages (数据库系统的优点)
数据库管理系统(DBMS)提供了一种结构化的方式来存储、管理和访问数据,与传统的文件处理系统相比,数据库提供了许多显著的优点。以下是数据库系统的主要优势: 1. Data Integrity (数据完整性) 概念:数据完整…...
Qt桌面应用开发 第五天(常用控件)
目录 1.QPushButton和ToolButton 1.1QPushButton 1.2ToolButton 2.RadioButton和CheckBox 2.1RadioButton单选按钮 2.2CheckBox多选按钮 3.ListWidget 4.TreeWidget控件 5.TableWidget控件 6.Containers控件 6.1QScrollArea 6.2QToolBox 6.3QTabWidget 6.4QStacke…...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

Raspberry Pi Debug Probe:RP2040嵌入式开发的调试利器与实战指南
1. 项目概述:为什么你需要一个Raspberry Pi Debug Probe?如果你玩过树莓派Pico或者任何基于RP2040芯片的开发板,肯定遇到过这样的场景:写好的代码,点一下“上传”,然后……就没有然后了。板子上的LED没按你…...

具身智能:面向新兴交叉学科建设的思考与建议 2026
这份由 CCF YOCSEF 长三角五地学术委员会 2026 年 5 月发布的白皮书,聚焦具身智能作为新兴交叉学科的建设,明确其并非 AI 与机器人学的简单拼接,而是围绕物理交互中的智能行为形成的新问题域,提出 “三大基本问题 一个应用需求”…...

如何用HsMod解锁炉石传说60+项隐藏功能:终极优化指南
如何用HsMod解锁炉石传说60项隐藏功能:终极优化指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx开发的炉石传说功能增强插件,为玩家提供…...
)
CentOS 8.5最小化安装后,这5个必做的安全与效率优化设置(附一键脚本)
CentOS 8.5最小化安装后的5个必做安全与效率优化刚完成CentOS 8.5最小化安装的系统就像一张白纸——干净但缺乏生产力。作为运维老手,我见过太多人跳过基础优化直接部署应用,结果在后续使用中频繁遇到权限混乱、软件安装慢、SSH爆破等问题。本文将分享我…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...

【C++】零基础入门 · 第 6 节:数组
上一节我们学习了函数,知道了如何把代码封装起来方便复用。但在实际编程中,你很快就会遇到一个问题:如果要存储 100 个学生的成绩,难道要定义 100 个变量吗?这显然不现实。数组就是 C++ 给出的答案——它让我们能用一个变量名管理一组相同类型的数据。 1. 为什么需要数组…...