设计模式之美总结(开源实战篇)
title: 设计模式之美总结(开源实战篇)
date: 2023-01-10 17:13:05
tags:
- 设计模式
categories: - 设计模式
cover: https://cover.png
feature: false
文章目录
- 1. Java JDK 应用到的设计模式
- 1.1 工厂模式在 Calendar 类中的应用
- 1.2 建造者模式在 Calendar 类中的应用
- 1.3 装饰器模式在 Collections 类中的应用
- 1.4 适配器模式在 Collections 类中的应用
- 1.5 模板模式在 Collections 类中的应用
- 1.6 观察者模式在 JDK 中的应用
- 1.7 单例模式在 Runtime 类中的应用
- 1.8 其他模式在 JDK 中的应用汇总
- 2. 从 Unix 学习应对大型复杂项目开发
- 2.1 设计原则和思想
- 2.1.1 封装与抽象
- 2.1.2 分层与模块化
- 2.1.3 基于接口通信
- 2.1.4 高内聚、松耦合
- 2.1.5 为扩展而设计
- 2.1.6 KISS 首要原则
- 2.1.7 最小惊奇原则
- 2.2 研发管理和开发技巧
- 2.2.1 吹毛求疵般地执行编码规范
- 2.2.2 编写高质量的单元测试
- 2.2.3 不流于形式的 Code Review
- 2.2.4 开发未动、文档先行
- 2.2.5 持续重构、重构、重构
- 2.2.6 对项目与团队进行拆分
- 2.3 Code Review
- 2.3.1 优势
- 2.3.2 如何在团队中落地执行 Code Review?
- 3. Google Guava
- 3.1 如何发现通用的功能模块?
- 3.2 如何开发通用的功能模块?
- 3.3 Google Guava 中用到的几种设计模式
- 3.3.1 Builder 模式
- 3.3.2 Wrapper 模式
- 3.3.3 Immutable 模式
- 3.4 函数式编程
- 3.4.1 概念
- 3.4.2 Java 对函数式编程的支持
- 3.4.3 Guava 对函数式编程的增强
- 4. Spring 框架
- 4.1 蕴含的设计思想
- 4.1.1 约定优于配置
- 4.1.2 低侵入、松耦合
- 4.1.3 模块化、轻量级
- 4.1.4 再封装、再抽象
- 4.2 用来支持扩展的两种设计模式
- 4.2.1 观察者模式在 Spring 中的应用
- 4.2.2 模板模式在 Spring 中的应用
- 4.3 Spring 框架用到的 11 种设计模式
- 4.3.1 适配器模式在 Spring 中的应用
- 4.3.2 策略模式在 Spring 中的应用
- 4.3.3 组合模式在 Spring 中的应用
- 4.3.4 装饰器模式在 Spring 中的应用
- 4.3.5 工厂模式在 Spring 中的应用
- 4.3.6 其他模式在 Spring 中的应用
- 5. MyBatis
- 5.1 Mybatis 和 ORM 框架介绍
- 5.2 如何平衡易用性、性能和灵活性?
- 5.3 如何利用职责链与代理模式实现 MyBatis Plugin?
- 5.3.1 MyBatis Plugin 功能介绍
- 5.3.2 MyBatis Plugin 的设计与实现
- 5.4 总结 MyBatis 框架中用到的 10 种设计模式
- 5.4.1 SqlSessionFactoryBuilder:为什么要用建造者模式来创建SqlSessionFactory?
- 5.4.2 SqlSessionFactory:到底属于工厂模式还是建造器模式?
- 5.4.3 BaseExecutor:模板模式跟普通的继承有什么区别?
- 5.4.4 SqlNode:如何利用解释器模式来解析动态 SQL?
- 5.4.5 ErrorContext:如何实现一个线程唯一的单例模式?
- 5.4.6 Cache:为什么要用装饰器模式而不设计成继承子类?
- 5.4.7 PropertyTokenizer:如何利用迭代器模式实现一个属性解析器?
- 5.4.8 Log:如何使用适配器模式来适配不同的日志框架?
设计模式相关的详细知识见如下三篇:
- 设计模式之美总结(创建型篇)_凡 223 的博客
- 设计模式之美总结(结构型篇)_凡 223 的博客
- 设计模式之美总结(行为型篇)_凡 223 的博客
1. Java JDK 应用到的设计模式
1.1 工厂模式在 Calendar 类中的应用
在前面讲到工厂模式的时候,大部分工厂类都是以 Factory 作为后缀来命名,并且工厂类主要负责创建对象这样一件事情。但在实际的项目开发中,工厂类的设计更加灵活。比如工厂模式在 Java JDK 中的一个应用:java.util.Calendar。从命名上,我们无法看出它是一个工厂类
Calendar 类提供了大量跟日期相关的功能代码,同时,又提供了一个 getInstance() 工厂方法,用来根据不同的 TimeZone 和 Locale 创建不同的 Calendar 子类对象。也就是说,功能代码和工厂方法代码耦合在了一个类中。所以,即便去查看它的源码,如果不细心的话,也很难发现它用到了工厂模式。同时,因为它不单单是一个工厂类,所以,它并没有以 Factory 作为后缀来命名
Calendar 类的相关代码如下所示,大部分代码都已经省略,只给出了 getInstance() 工厂方法的代码实现。从代码中可以看出,getInstance() 方法可以根据不同 TimeZone 和 Locale,创建不同的 Calendar 子类对象,比如 BuddhistCalendar、JapaneseImperialCalendar、GregorianCalendar,这些细节完全封装在工厂方法中,使用者只需要传递当前的时区和地址,就能够获得一个 Calendar 类对象来使用,而获得的对象具体是哪个 Calendar 子类的对象,使用者在使用的时候并不关心
public abstract class Calendar implements Serializable, Cloneable, Comparable<Calendar> {//...public static Calendar getInstance(TimeZone zone, Locale aLocale) {return createCalendar(zone, aLocale);}private static Calendar createCalendar(TimeZone zone,Locale aLocale) {CalendarProvider provider = LocaleProviderAdapter.getAdapter(CalendarProvider.class, aLocale).getCalendarProvider();if (provider != null) {try {return provider.getInstance(zone, aLocale);} catch (IllegalArgumentException iae) {// fall back to the default instantiation}}Calendar cal = null;if (aLocale.hasExtensions()) {String caltype = aLocale.getUnicodeLocaleType("ca");if (caltype != null) {switch (caltype) {case "buddhist":cal = new BuddhistCalendar(zone, aLocale);break;case "japanese":cal = new JapaneseImperialCalendar(zone, aLocale);break;case "gregory":cal = new GregorianCalendar(zone, aLocale);break;}}}if (cal == null) {if (aLocale.getLanguage() == "th" && aLocale.getCountry() == "TH") {cal = new BuddhistCalendar(zone, aLocale);} else if (aLocale.getVariant() == "JP" && aLocale.getLanguage() == "ja") {cal = new JapaneseImperialCalendar(zone, aLocale);} else {cal = new GregorianCalendar(zone, aLocale);}}return cal;}//...
}
1.2 建造者模式在 Calendar 类中的应用
还是刚刚的 Calendar 类,它不仅仅用到了工厂模式,还用到了建造者模式。建造者模式有两种实现方法,一种是单独定义一个 Builder 类,另一种是将 Builder 实现为原始类的内部类。Calendar 就采用了第二种实现思路
public abstract class Calendar implements Serializable, Cloneable, Comparable<Calendar> {//...public static class Builder {private static final int NFIELDS = FIELD_COUNT + 1;private static final int WEEK_YEAR = FIELD_COUNT;private long instant;private int[] fields;private int nextStamp;private int maxFieldIndex;private String type;private TimeZone zone;private boolean lenient = true;private Locale locale;private int firstDayOfWeek, minimalDaysInFirstWeek;public Builder() {}public Builder setInstant(long instant) {if (fields != null) {throw new IllegalStateException();}this.instant = instant;nextStamp = COMPUTED;return this;}//...省略n多set()方法public Calendar build() {if (locale == null) {locale = Locale.getDefault();}if (zone == null) {zone = TimeZone.getDefault();}Calendar cal;if (type == null) {type = locale.getUnicodeLocaleType("ca");}if (type == null) {if (locale.getCountry() == "TH" && locale.getLanguage() == "th") {type = "buddhist";} else {type = "gregory";}}switch (type) {case "gregory":cal = new GregorianCalendar(zone, locale, true);break;case "iso8601":GregorianCalendar gcal = new GregorianCalendar(zone, locale, true);// make gcal a proleptic Gregoriangcal.setGregorianChange(new Date(Long.MIN_VALUE));// and week definition to be compatible with ISO 8601setWeekDefinition(MONDAY, 4);cal = gcal;break;case "buddhist":cal = new BuddhistCalendar(zone, locale);cal.clear();break;case "japanese":cal = new JapaneseImperialCalendar(zone, locale, true);break;default:throw new IllegalArgumentException("unknown calendar type: " + type)}cal.setLenient(lenient);if (firstDayOfWeek != 0) {cal.setFirstDayOfWeek(firstDayOfWeek);cal.setMinimalDaysInFirstWeek(minimalDaysInFirstWeek);}if (isInstantSet()) {cal.setTimeInMillis(instant);cal.complete();return cal;}if (fields != null) {boolean weekDate = isSet(WEEK_YEAR) && fields[WEEK_YEAR] > fields[YEAR]if (weekDate && !cal.isWeekDateSupported()) {throw new IllegalArgumentException("week date is unsupported by " + t}for (int stamp = MINIMUM_USER_STAMP; stamp < nextStamp; stamp++) {for (int index = 0; index <= maxFieldIndex; index++) {if (fields[index] == stamp) {cal.set(index, fields[NFIELDS + index]);break;}}}if (weekDate) {int weekOfYear = isSet(WEEK_OF_YEAR) ? fields[NFIELDS + WEEK_OF_YEAR] : 1;int dayOfWeek = isSet(DAY_OF_WEEK)? fields[NFIELDS + DAY_OF_WEEK] : cal.getFirstDayOfWeek();cal.setWeekDate(fields[NFIELDS + WEEK_YEAR], weekOfYear, dayOfWeek);}cal.complete();}return cal;}}
}
看了上面的代码,有一个问题思考一下:既然已经有了 getInstance() 工厂方法来创建 Calendar 类对象,为什么还要用 Builder 来创建 Calendar 类对象呢?这两者之间的区别在哪里呢?
实际上,在前面讲到这两种模式的时候,对它们之间的区别做了详细的对比。工厂模式是用来创建不同但是相关类型的对象(继承同一父类或者接口的一组子类),由给定的参数来决定创建哪种类型的对象。建造者模式用来创建一种类型的复杂对象,通过设置不同的可选参数,“定制化”地创建不同的对象
粗看 Calendar 的 Builder 类的 build() 方法,可能会觉得它有点像工厂模式。前面一半代码确实跟 getInstance() 工厂方法类似,根据不同的 type 创建了不同的 Calendar 子类。实际上,后面一半代码才属于标准的建造者模式,根据 setXXX() 方法设置的参数,来定制化刚刚创建的 Calendar 子类对象
这时可能会说,这还能算是建造者模式吗?引用前面提到过的一段话
我们也不要太学院派,非得把工厂模式、建造者模式分得那么清楚,我们需要知道的是,每个模式为什么这么设计,能解决什么问题。只有了解了这些最本质的东西,我们才能不生搬硬套,才能灵活应用,甚至可以混用各种模式,创造出新的模式来解决特定场景的问题
实际上,从 Calendar 这个例子也能学到,不要过于死板地套用各种模式的原理和实现,不要不敢做丝毫的改动。模式是死的,用的人是活的。在实际上的项目开发中,不仅各种模式可以混合在一起使用,而且具体的代码实现,也可以根据具体的功能需求做灵活的调整
1.3 装饰器模式在 Collections 类中的应用
前面讲到,Java IO 类库是装饰器模式的非常经典的应用。实际上,Java 的 Collections 类也用到了装饰器模式
Collections 类是一个集合容器的工具类,提供了很多静态方法,用来创建各种集合容器,比如通过 unmodifiableColletion() 静态方法,来创建 UnmodifiableCollection 类对象。而这些容器类中的 UnmodifiableCollection 类、CheckedCollection 和 SynchronizedCollection 类,就是针对 Collection 类的装饰器类
因为刚刚提到的这三个装饰器类,在代码结构上几乎一样,所以这里只拿其中的 UnmodifiableCollection 类来举例讲解一下。UnmodifiableCollection 类是 Collections 类的一个内部类
public class Collections {private Collections() {}public static <T> Collection<T> unmodifiableCollection(Collection<? extends T> c) {return new UnmodifiableCollection<>(c);}/*** @serial include*/static class UnmodifiableCollection<E> implements Collection<E>, Serializable {private static final long serialVersionUID = 1820017752578914078L;final Collection<? extends E> c;UnmodifiableCollection(Collection<? extends E> c) {if (c==null)throw new NullPointerException();this.c = c;}public int size() {return c.size();}public boolean isEmpty() {return c.isEmpty();}public boolean contains(Object o) {return c.contains(o);}public Object[] toArray() {return c.toArray();}public <T> T[] toArray(T[] a) {return c.toArray(a);}public String toString() {return c.toString();}public Iterator<E> iterator() {return new Iterator<E>() {private final Iterator<? extends E> i = c.iterator();public boolean hasNext() {return i.hasNext();}public E next() {return i.next();}public void remove() {throw new UnsupportedOperationException();}@Overridepublic void forEachRemaining(Consumer<? super E> action) {// Use backing collection versioni.forEachRemaining(action);}};}public boolean add(E e) {throw new UnsupportedOperationException();}public boolean remove(Object o) {hrow new UnsupportedOperationException();}public boolean containsAll(Collection<?> coll) {return c.containsAll(coll);}public boolean addAll(Collection<? extends E> coll) {throw new UnsupportedOperationException();}public boolean removeAll(Collection<?> coll) {throw new UnsupportedOperationException();}public boolean retainAll(Collection<?> coll) {throw new UnsupportedOperationException();}public void clear() {throw new UnsupportedOperationException();}// Override default methods in Collection@Overridepublic void forEach(Consumer<? super E> action) {c.forEach(action);}@Overridepublic boolean removeIf(Predicate<? super E> filter) {throw new UnsupportedOperationException();}@SuppressWarnings("unchecked")@Overridepublic Spliterator<E> spliterator() {return (Spliterator<E>)c.spliterator();}@SuppressWarnings("unchecked")@Overridepublic Stream<E> stream() {return (Stream<E>)c.stream();}@SuppressWarnings("unchecked")@Overridepublic Stream<E> parallelStream() {return (Stream<E>)c.parallelStream();}}
}
看了上面的代码思考一下,为什么说 UnmodifiableCollection 类是 Collection 类的装饰器类呢?这两者之间可以看作简单的接口实现关系或者类继承关系吗?
前面讲过,装饰器模式中的装饰器类是对原始类功能的增强。尽管 UnmodifiableCollection 类可以算是对 Collection 类的一种功能增强,但这点还不具备足够的说服力来断定 UnmodifiableCollection 就是 Collection 类的装饰器类
实际上,最关键的一点是,UnmodifiableCollection 的构造函数接收一个 Collection 类对象,然后对其所有的函数进行了包裹(Wrap):重新实现(比如 add() 函数)或者简单封装(比如 stream() 函数)。而简单的接口实现或者继承,并不会如此来实现 UnmodifiableCollection 类。所以,从代码实现的角度来说, UnmodifiableCollection类是典型的装饰器类
1.4 适配器模式在 Collections 类中的应用
前面讲到适配器模式的时候说到,适配器模式可以用来兼容老的版本接口。当时举了一个 JDK 的例子,这里再重新仔细看一下
老版本的 JDK 提供了 Enumeration 类来遍历容器。新版本的 JDK 用 Iterator 类替代 Enumeration 类来遍历容器。为了兼容老的客户端代码(使用老版本 JDK 的代码),保留了 Enumeration 类,并且在 Collections 类中,仍然保留了 enumaration() 静态方法(因为一般都是通过这个静态函数来创建一个容器的 Enumeration 类对象)
不过,保留 Enumeration 类和 enumeration() 函数,都只是为了兼容,实际上,跟适配器没有一点关系。那到底哪一部分才是适配器呢?
在新版本的 JDK 中,Enumeration 类是适配器类。它适配的是客户端代码(使用 Enumeration 类)和新版本 JDK 中新的迭代器 Iterator 类。不过,从代码实现的角度来说,这个适配器模式的代码实现,跟经典的适配器模式的代码实现,差别稍微有点大。enumeration() 静态函数的逻辑和 Enumeration 适配器类的代码耦合在一起,enumeration() 静态函数直接通过 new 的方式创建了匿名类对象。具体的代码如下所示:
/**
* Returns an enumeration over the specified collection. This provides
* interoperability with legacy APIs that require an enumeration
* as input.
*
* @param <T> the class of the objects in the collection
* @param c the collection for which an enumeration is to be returned.
* @return an enumeration over the specified collection.
* @see Enumeration
*/
public static <T> Enumeration<T> enumeration(final Collection<T> c) {return new Enumeration<T>() {private final Iterator<T> i = c.iterator();public boolean hasMoreElements() {return i.hasNext();}public T nextElement() {return i.next();}};
}
1.5 模板模式在 Collections 类中的应用
前面提到,策略、模板、职责链三个模式常用在框架的设计中,提供框架的扩展点,让框架使用者,在不修改框架源码的情况下,基于扩展点定制化框架的功能。Java 中的 Collections 类的 sort() 函数就是利用了模板模式的这个扩展特性
首先,看下 Collections.sort() 函数是如何使用的。示例代码如下所示。这个代码实现了按照不同的排序方式(按照年龄从小到大、按照名字字母序从小到大、按照成绩从大到小)对 students 数组进行排序
public class Demo {public static void main(String[] args) {List<Student> students = new ArrayList<>();students.add(new Student("Alice", 19, 89.0f));students.add(new Student("Peter", 20, 78.0f));students.add(new Student("Leo", 18, 99.0f));Collections.sort(students, new AgeAscComparator());print(students);Collections.sort(students, new NameAscComparator());print(students);Collections.sort(students, new ScoreDescComparator());print(students);}public static void print(List<Student> students) {for (Student s : students) {System.out.println(s.getName() + " " + s.getAge() + " " + s.getScore());}}public static class AgeAscComparator implements Comparator<Student> {@Overridepublic int compare(Student o1, Student o2) {return o1.getAge() - o2.getAge();}}public static class NameAscComparator implements Comparator<Student> {@Overridepublic int compare(Student o1, Student o2) {return o1.getName().compareTo(o2.getName());}}public static class ScoreDescComparator implements Comparator<Student> {@Overridepublic int compare(Student o1, Student o2) {if (Math.abs(o1.getScore() - o2.getScore()) < 0.001) {return 0;} else if (o1.getScore() < o2.getScore()) {return 1;} else {return -1;}}}
}
结合刚刚这个例子,再来看下,为什么说 Collections.sort() 函数用到了模板模式?Collections.sort() 实现了对集合的排序。为了扩展性,它将其中“比较大小”这部分逻辑,委派给用户来实现。如果把比较大小这部分逻辑看作整个排序逻辑的其中一个步骤,那就可以把它看作模板模式。不过,从代码实现的角度来看,它看起来有点类似之前讲过的 JdbcTemplate,并不是模板模式的经典代码实现,而是基于 Callback 回调机制来实现的
不过,在其他资料中,还看到有人说,Collections.sort() 使用的是策略模式。这样的说法也不是没有道理的。如果并不把“比较大小”看作排序逻辑中的一个步骤,而是看作一种算法或者策略,那就可以把它看作一种策略模式的应用。不过,这也不是典型的策略模式,前面讲到在典型的策略模式中,策略模式分为策略的定义、创建、使用这三部分。策略通过工厂模式来创建,并且在程序运行期间,根据配置、用户输入、计算结果等这些不确定因素,动态决定使用哪种策略。而在 Collections.sort() 函数中,策略的创建并非通过工厂模式,策略的使用也非动态确定
1.6 观察者模式在 JDK 中的应用
在前面讲到观察者模式的时候,重点讲解了 Google Guava 的 EventBus 框架,它提供了观察者模式的骨架代码。使用 EventBus,我们不需要从零开始开发观察者模式。实际上,Java JDK 也提供了观察者模式的简单框架实现。在平时的开发中,如果不希望引入 Google Guava 开发库,可以直接使用 Java 语言本身提供的这个框架类
不过,它比 EventBus 要简单多了,只包含两个类:java.util.Observable 和 java.util.Observer。前者是被观察者,后者是观察者。它们的代码实现也非常简单
public interface Observer {void update(Observable o, Object arg);
}
public class Observable {private boolean changed = false;private Vector<Observer> obs;public Observable() {obs = new Vector<>();}public synchronized void addObserver(Observer o) {if (o == null)throw new NullPointerException();if (!obs.contains(o)) {obs.addElement(o);}}public synchronized void deleteObserver(Observer o) {obs.removeElement(o);}public void notifyObservers() {notifyObservers(null);}public void notifyObservers(Object arg) {Object[] arrLocal;synchronized (this) {if (!changed)return;arrLocal = obs.toArray();clearChanged();}for (int i = arrLocal.length-1; i>=0; i--)((Observer)arrLocal[i]).update(this, arg);}public synchronized void deleteObservers() {obs.removeAllElements();}protected synchronized void setChanged() {changed = true;}protected synchronized void clearChanged() {changed = false;}
}
对于 Observable、Observer 的代码实现,大部分都很好理解,重点来看其中的两个地方。一个是 changed 成员变量,另一个是 notifyObservers() 函数
先来看 changed 成员变量
它用来表明被观察者(Observable)有没有状态更新。当有状态更新时,需要手动调用 setChanged() 函数,将 changed 变量设置为 true,这样才能在调用 notifyObservers() 函数的时候,真正触发观察者(Observer)执行 update() 函数。否则,即便调用了 notifyObservers() 函数,观察者的 update() 函数也不会被执行。也就是说,当通知观察者被观察者状态更新的时候,需要依次调用 setChanged() 和
notifyObservers() 两个函数,单独调用 notifyObservers() 函数是不起作用的
再来看 notifyObservers() 函数
为了保证在多线程环境下,添加、移除、通知观察者三个操作之间不发生冲突,Observable 类中的大部分函数都通过 synchronized 加了锁,不过,也有特例,notifyObservers() 这函数就没有加 synchronized 锁。这是为什么呢?在 JDK 的代码实现中,notifyObservers() 函数是如何保证跟其他函数操作不冲突的呢?这种加锁方法是否存在问题?又存在什么问题呢?
notifyObservers() 函数之所以没有像其他函数那样,一把大锁加在整个函数上,主要还是出于性能的考虑
notifyObservers() 函数依次执行每个观察者的 update() 函数,每个 update() 函数执行的逻辑提前未知,有可能会很耗时。如果在 notifyObservers() 函数上加 synchronized 锁,notifyObservers() 函数持有锁的时间就有可能会很长,这就会导致其他线程迟迟获取不到锁,影响整个 Observable 类的并发性能
Vector 类不是线程安全的,在多线程环境下,同时添加、删除、遍历 Vector 类对象中的元素,会出现不可预期的结果。所以,在 JDK 的代码实现中,为了避免直接给 notifyObservers() 函数加锁而出现性能问题,JDK 采用了一种折中的方案。这个方案有点类似于之前讲过的让迭代器支持”快照“的解决方案
在 notifyObservers() 函数中,先拷贝一份观察者列表,赋值给函数的局部变量,局部变量是线程私有的,并不在线程间共享。这个拷贝出来的线程私有的观察者列表就相当于一个快照。遍历快照,逐一执行每个观察者的 update() 函数。而这个遍历执行的过程是在快照这个局部变量上操作的,不存在线程安全问题,不需要加锁。所以,只需要对拷贝创建快照的过程加锁,加锁的范围减少了很多,并发性能提高了
为什么说这是一种折中的方案呢?这是因为,这种加锁方法实际上是存在一些问题的。在创建好快照之后,添加、删除观察者都不会更新快照,新加入的观察者就不会被通知到,新删除的观察者仍然会被通知到。这种权衡是否能接受完全看你的业务场景。实际上,这种处理方式也是多线程编程中减小锁粒度、提高并发性能的常用方法
1.7 单例模式在 Runtime 类中的应用
每个 Java 应用在运行时会启动一个 JVM 进程,每个 JVM 进程都只对应一个 Runtime 实例,用于查看 JVM 状态以及控制 JVM 行为。进程内唯一,所以比较适合设计为单例。在编程的时候,我们不能自己去实例化一个 Runtime 对象,只能通过 getRuntime() 静态方法来获得
Runtime 类的的代码实现如下所示。这里面只包含部分相关代码,其他代码做了省略。从代码中也可以看出,它使用了最简单的饿汉式的单例实现方式
/**
* Every Java application has a single instance of class
* <code>Runtime</code> that allows the application to interface with
* the environment in which the application is running. The current
* runtime can be obtained from the <code>getRuntime</code> method.
* <p>
* An application cannot create its own instance of this class.
*
* @author unascribed
* @see java.lang.Runtime#getRuntime()
* @since JDK1.0
*/
public class Runtime {private static Runtime currentRuntime = new Runtime();public static Runtime getRuntime() {return currentRuntime;}/** Don't let anyone else instantiate this class */private Runtime() {}//....public void addShutdownHook(Thread hook) {SecurityManager sm = System.getSecurityManager();if (sm != null) {sm.checkPermission(new RuntimePermission("shutdownHooks"));}ApplicationShutdownHooks.add(hook);}//...
}
1.8 其他模式在 JDK 中的应用汇总
实际上,在讲解理论部分的时候(见文章开头的前三篇内容),已经讲过很多模式在 Java JDK 中的应用了。这里再回顾一下:
- 在讲到模板模式的时候,结合 Java Servlet、JUnit TestCase、Java InputStream、Java AbstractList 四个例子,来具体讲解了它的两个作用:扩展性和复用性
- 在讲到享元模式的时候,讲到 Integer 类中的 -128~127 之间的整型对象是可以复用的,还讲到 String 类型中的常量字符串也是可以复用的。这些都是享元模式的经典应用
- 在讲到职责链模式的时候,讲到Java Servlet 中的 Filter 就是通过职责链来实现的,同时还对比了 Spring 中的 interceptor。实际上,拦截器、过滤器这些功能绝大部分都是采用职责链模式来实现的
- 在讲到的迭代器模式的时候,重点剖析了 Java 中 Iterator 迭代器的实现
2. 从 Unix 学习应对大型复杂项目开发
软件开发的难度无外乎两点,一是技术难,意思是说,代码量不一定多,但要解决的问题比较难,需要用到一些比较深的技术解决方案或者算法,不是靠“堆人”就能搞定的,比如自动驾驶、图像识别、高性能消息队列等;二是复杂度,意思是说,技术不难,但项目很庞大,业务复杂,代码量多,参与开发的人多,比如物流系统、财务系统等。第一点涉及细分专业的领域知识,这里重点来讲第二点,如何应对软件开发的复杂度
简单的“hello world”程序,谁都能写得出来。几千行的代码谁都能维护得了。但是,当代码超过几万行、十几万,甚至几十万行、上百万行的时候,软件的复杂度就会呈指数级增长。这种情况下,不仅仅要求程序运行得了,运行得正确,还要求代码看得懂、维护得了。实际上,复杂度不仅仅体现在代码本身,还体现在协作研发上,如何管理庞大的团队,来进行有条不紊地协作开发,也是一个很复杂的难题
如何应对复杂软件开发?Unix 开源项目就是一个值得学习的例子
Unix 从 1969 年诞生,一直演进至今,代码量有几百万行,如此庞大的项目开发,能够如此完美的协作开发,并且长期维护,保持足够的代码质量,这里面有很多成功的经验可以借鉴。所以,接下来就以 Unix 开源项目的开发为引子,通过下面三个话题,详细地讲讲应对复杂软件开发的方法论
- 从设计原则和思想的角度来看,如何应对庞大而复杂的项目开发?
- 从研发管理和开发技巧的角度来看,如何应对庞大而复杂的项目开发?
- 聚焦在 Code Review 上来看,如何通过 Code Reviwe 保持项目的代码质量?
2.1 设计原则和思想
2.1.1 封装与抽象
在 Unix、Linux 系统中,有一句经典的话,“Everything is a file”,翻译成中文就是“一切皆文件”。这句话的意思就是,在 Unix、Linux 系统中,很多东西都被抽象成“文件”这样一个概念,比如 Socket、驱动、硬盘、系统信息等。它们使用文件系统的路径作为统一的命名空间(namespace),使用统一的 read、write 标准函数来访问
比如要查看 CPU 的信息,在 Linux 系统中,只需要使用 Vim、Gedit 等编辑器或者 cat 命令,像打开其他文件一样,打开 /proc/cpuinfo,就能查看到相应的信息。除此之外,还可以通过查看 /proc/uptime 文件,了解系统运行了多久,查看 /proc/version 了解系统的内核版本等
实际上,“一切皆文件”就体现了封装和抽象的设计思想
封装了不同类型设备的访问细节,抽象为统一的文件访问方式,更高层的代码就能基于统一的访问方式,来访问底层不同类型的设备。这样做的好处是,隔离底层设备访问的复杂性
统一的访问方式能够简化上层代码的编写,并且代码更容易复用。除此之外,抽象和封装还能有效控制代码复杂性的蔓延,将复杂性封装在局部代码中,隔离实现的易变性,提供简单、统一的访问接口,让其他模块来使用,其他模块基于抽象的接口而非具体的实现编程,代码会更加稳定
2.1.2 分层与模块化
模块化是构建复杂系统的常用手段
对于像 Unix 这样的复杂系统,没有人能掌控所有的细节。之所以能开发出如此复杂的系统,并且能维护得了,最主要的原因就是将系统划分成各个独立的模块,比如进程调度、进程通信、内存管理、虚拟文件系统、网络接口等模块。不同的模块之间通过接口来进行通信,模块之间耦合很小,每个小的团队聚焦于一个独立的高内聚模块来开发,最终像搭积木一样,将各个模块组装起来,构建成一个超级复杂的系统
除此之外,Unix、Linux 等大型系统之所以能做到几百、上千人有条不紊地协作开发,也归功于模块化做得好。不同的团队负责不同的模块开发,这样即便在不了解全部细节的情况下,管理者也能协调各个模块,让整个系统有效运转
实际上,除了模块化之外,分层也是常用来架构复杂系统的方法
我们常说,计算机领域的任何问题都可以通过增加一个间接的中间层来解决,这本身就体现了分层的重要性。比如,Unix 系统也是基于分层开发的,它可以大致上分为三层,分别是内核、系统调用、应用层。每一层都对上层封装实现细节,暴露抽象的接口来调用。而且,任意一层都可以被重新实现,不会影响到其他层的代码
面对复杂系统的开发,要善于应用分层技术,把容易复用、跟具体业务关系不大的代码,尽量下沉到下层,把容易变动、跟具体业务强相关的代码,尽量上移到上层
2.1.3 基于接口通信
前面讲了分层、模块化,那不同的层之间、不同的模块之间,是如何通信的呢?一般来讲都是通过接口调用。在设计模块(module)或者层(layer)要暴露的接口的时候,要学会隐藏实现,接口从命名到定义都要抽象一些,尽量少涉及具体的实现细节
比如,Unix 系统提供的 open() 文件操作函数,底层实现非常复杂,涉及权限控制、并发控制、物理存储,但用起来却非常简单。除此之外,因为 open() 函数基于抽象而非具体的实现来定义,所以在改动 open() 函数的底层实现的时候,并不需要改动依赖它的上层代码
2.1.4 高内聚、松耦合
高内聚、松耦合是一个比较通用的设计思想,内聚性好、耦合少的代码,能让我们在修改或者阅读代码的时候,聚集到在一个小范围的模块或者类中,不需要了解太多其他模块或类的代码,让焦点不至于太发散,也就降低了阅读和修改代码的难度。而且,因为依赖关系简单,耦合小,修改代码不会牵一发而动全身,代码改动比较集中,引入 bug 的风险也就减少了很多
实际上,前面讲到的很多方法,比如封装、抽象、分层、模块化、基于接口通信,都能有效地实现代码的高内聚、松耦合。反过来,代码的高内聚、松耦合,也就意味着,抽象、封装做到比较到位、代码结构清晰、分层和模块化合理、依赖关系简单,那代码整体的质量就不会太差。即便某个具体的类或者模块设计得不怎么合理,代码质量不怎么高,影响的范围也是非常有限的。可以聚焦于这个模块或者类做相应的小型重构。而相对于代码结构的调整,这种改动范围比较集中的小型重构的难度就小多了
2.1.5 为扩展而设计
越是复杂项目,越要在前期设计上多花点时间。提前思考项目中未来可能会有哪些功能需要扩展,提前预留好扩展点,以便在未来需求变更的时候,在不改动代码整体结构的情况下,轻松地添加新功能
做到代码可扩展,需要代码满足开闭原则。特别是像 Unix 这样的开源项目,有 N 多人参与开发,任何人都可以提交代码到代码库中。代码满足开闭原则,基于扩展而非修改来添加新功能,最小化、集中化代码改动,避免新代码影响到老代码,降低引入 bug 的风险
除了满足开闭原则,做到代码可扩展,前面也提到很多方法,比如封装和抽象,基于接口编程等。识别出代码可变部分和不可变部分,将可变部分封装起来,隔离变化,提供抽象化的不可变接口,供上层系统使用。当具体的实现发生变化的时候,只需要基于相同的抽象接口,扩展一个新的实现,替换掉老的实现即可,上游系统的代码几乎不需要修改
2.1.6 KISS 首要原则
简单清晰、可读性好,是任何大型软件开发要遵循的首要原则。只要可读性好,即便扩展性不好,顶多就是多花点时间、多改动几行代码的事情。但是,如果可读性不好,连看都看不懂,那就不是多花时间可以解决得了的了。如果对现有代码的逻辑似懂非懂,抱着尝试的心态去修改代码,引入 bug 的可能性就会很大
不管是自己还是团队,在参与大型项目开发的时候,要尽量避免过度设计、过早优化,在扩展性和可读性有冲突的时候,或者在两者之间权衡,模棱两可的时候,应该选择遵循 KISS原则,首选可读性
2.1.7 最小惊奇原则
《Unix 编程艺术》一书中提到一个 Unix 的经典设计原则,叫“最小惊奇原则”,英文是“The Least Surprise Priciple”。实际上,这个原则等同于“遵守开发规范”,意思是,在做设计或者编码的时候要遵守统一的开发规范,避免反直觉的设计
遵从统一的编码规范,所有的代码都像一个人写出来的,能有效地减少阅读干扰。在大型软件开发中,参与开发的人员很多,如果每个人都按照自己的编码习惯来写代码,那整个项目的代码风格就会千奇百怪,这个类是这种编码风格,另一个类又是另外一种风格。在阅读的时候,要不停地切换去适应不同的编码风格,可读性就变差了。所以,对于大型项目的开发来说,要特别重视遵守统一的开发规范
2.2 研发管理和开发技巧
项目越复杂、代码量越多、参与开发人员越多、开发维护时间越长,就越是要重视代码质量。代码质量下降会导致项目研发困难重重,比如:开发效率低,招了很多人,天天加班,出活却不多;线上 bug 频发,查找 bug 困难,领导发飙,中层束手无策,工程师抱怨不断
导致代码质量不高的原因有很多,比如:代码无注释,无文档,命名差,层次结构不清晰,调用关系混乱,到处 hardcode,充斥着各种临时解决方案等等。那怎么才能时刻保证代码质量呢?当然,首要的是团队技术素质要过硬,能够适当地利用设计原则、思想、模式编写高质量的代码。除此之外,还有一些外在的方法可循
2.2.1 吹毛求疵般地执行编码规范
严格执行代码规范,可以使一个项目乃至整个公司的代码具有完全统一的风格,就像同一个人编写的。而且,命名良好的变量、函数、类和注释,也可以提高代码的可读性。编码规范不难掌握,关键是要严格执行。在 Code Review 时,一定要严格要求,看到不符合规范的代码,一定要指出并要求修改
但是,实际情况往往事与愿违。虽然大家都知道优秀的代码规范是怎样的,但在具体写代码的过程中,执行得却不好。这种情况产生的主要原因还是不够重视。很多人会觉得,一个变量或者函数命名成啥样,关系并不大。所以命名时不推敲,注释也不写,Code Review 的时候也都一副事不关己的心态,觉得没必要太抠细节。日积月累,项目代码就会变得越来越差。所以这里还是要强调一下,细节决定成败,代码规范的严格执行极为关键
2.2.2 编写高质量的单元测试
单元测试是最容易执行且对提高代码质量见效最快的方法之一。高质量的单元测试不仅仅要求测试覆盖率要高,还要求测试的全面性,除了测试正常逻辑的执行之外,还要重点、全面地测试异常下的执行情况。毕竟代码出问题的地方大部分都发生在异常、边界条件下
对于大型复杂项目,集成测试、黑盒测试都很难测试全面,因为组合爆炸,穷举所有测试用例的成本很高,几乎是不可能的。单元测试就是很好的补充。它可以在类、函数这些细粒度的代码层面,保证代码运行无误。底层细粒度的代码 bug 少了,组合起来构建而成的整个系统的 bug 也就相应的减少了
2.2.3 不流于形式的 Code Review
如果说很多工程师对单元测试不怎么重视,那对 Code Review 就是不怎么接受。我之前跟一些同行聊起 Code Review 的时候,很多人的反应是,这玩意儿不可能很好地执行,形式大于效果,纯粹是浪费时间。是的,即便 Code Review 做得再流畅,也是要花时间的。所以,在业务开发任务繁重的时候,Code Review 往往会流于形式、虎头蛇尾,效果确实不怎么好
但并不能因此就否定 Code Review 本身的价值。在 Google、Facebook 等外企中,Code Review 应用得非常成功,已经成为了开发流程中不可或缺的一部分。所以,要想真正发挥 Code Review 的作用,关键还是要执行到位,不能流于形式
2.2.4 开发未动、文档先行
对大部分工程师来说,编写技术文档是件挺让人“反感”的事情。一般来讲,在开发某个系统或者重要模块或者功能之前,应该先写技术文档,然后,发送给同组或者相关同事审查,在审查没有问题的情况下再开发。这样能够保证事先达成共识,开发出来的东西不至于走样。而且,当开发完成之后,进行 Code Review 的时候,代码审查者通过阅读开发文档,也可以快速理解代码
除此之外,对于团队和公司来讲,文档是重要的财富。对新人熟悉代码或任务的交接等,技术文档很有帮助。而且,作为一个规范化的技术团队,技术文档是一种摒弃作坊式开发和个人英雄主义的有效方法,是保证团队有效协作的途径
2.2.5 持续重构、重构、重构
我个人比较反对平时不注重代码质量,堆砌烂代码,实在维护不了了就大刀阔斧地重构甚至重写。有的时候,因为项目代码太多,重构很难做到彻底,最后又搞出来一个四不像的怪物,这就更麻烦了!
优秀的代码或架构不是一开始就能设计好的,就像优秀的公司或产品也都是迭代出来的。我们无法 100% 预见未来的需求,也没有足够的精力、时间、资源为遥远的未来买单。所以,随着系统的演进,重构是不可避免的
虽然刚刚说不支持大刀阔斧、推倒重来式的大重构,但持续的小重构还是比较提倡的。它也是时刻保证代码质量、防止代码腐化的有效手段。换句话说,不要等到问题堆得太多了再去解决,要时刻有人对代码整体质量负责任,平时没事就改改代码
特别是一些业务开发团队,有时候为了快速完成一个业务需求,只追求速度,到处 hardcode,在完全不考虑非功能性需求、代码质量的情况下,堆砌烂代码。实际上,这种情况还是比较常见的。不过没关系,等有时间了,一定要记着重构,不然烂代码越堆越多,总有一天代码会变得无法维护
2.2.6 对项目与团队进行拆分
团队人比较少,比如十几个人的时候,代码量不多,不超过 10 万行,怎么开发、怎么管理都没问题,大家互相都比较了解彼此做的东西。即便代码质量太差了,我们大不了把它重写一遍。但是,对于一个大型项目来说,参与开发的人员会比较多,代码量很大,有几十万、甚至几百万行代码,有几十、甚至几百号人同时开发维护,那研发管理就变得极其重要
面对大型复杂项目,不仅仅需要对代码进行拆分,还需要对研发团队进行拆分。前讲到了一些代码拆分的方法,比如模块化、分层等。同理,也可以把大团队拆成几个小团队。每个小团队对应负责一个小的项目(模块、微服务等),这样每个团队负责的项目包含的代码都不至于很多,也不至于出现代码质量太差无法维护的情况
2.3 Code Review
2.3.1 优势
1、Code Review 践行“三人行必有我师”
有时候可能会觉得,团队中的资深员工或者技术 leader 的技术比较牛,写的代码很好,他们的代码就不需要 Review 了,重点 Review 资历浅的员工的代码就可以了。实际上,这种认识是不对的
Google 工程师的平均研发水平都很高,但即便如此,不管谁提交的代码,包括 Jeff Dean 的,只要需要 Review,都会收到很多 comments(修改意见)。“三人行必有我师”,即便自己觉得写得已经很好的代码,只要经过不停地推敲,都有持续改进的空间
所以,永远不要觉得自己很厉害,写的代码就不需要别人 Review 了;永远不要觉得自己水平很一般,就没有资格给别人 Review 了;更不要觉得技术大牛让你 Review 代码只是缺少你的一个“approve”,随便看看就可以
2、Code Review 能摒弃“个人英雄主义”
在一个成熟的公司里,所有的架构设计、实现,都应该是一个团队的产出。尽管这个过程可能会由某个人来主导,但应该是整个团队共同智慧的结晶
如果一个人默默地写代码提交,不经过团队的 Review,这样的代码蕴含的是一个人的智慧。代码的质量完全依赖于这个人的技术水平。这就会导致代码质量参差不齐。如果经过团队多人 Review、打磨,代码蕴含的是整个团队的智慧,可以保证代码按照团队中的最高水准输出
3、Code Review 能有效提高代码可读性
前面反复强调,在大部分情况下,代码的可读性比任何其他方面(比如扩展性等)都重要。可读性好,代表后期维护成本低,线上 bug 容易排查,新人容易熟悉代码,老人离职时代码容易接手。而且,可读性好,也说明代码足够简单,出错可能性小、bug 少
不过,自己看自己写的代码,总是会觉得很易读,但换另外一个人来读你的代码,可能就不这么认为了。毕竟自己写的代码,其中涉及的业务、技术自己很熟悉,别人不一定会熟悉。既然自己对可读性的判断很容易出现错觉,那 Code Review 就是一种考察代码可读性的很好手段。如果代码审查者很费劲才能看懂你写的代码,那就说明代码的可读性有待提高了
4、Code Review 是技术传帮带的有效途径
良好的团队需要技术和业务的“传帮带”,那如何来做“传帮带”呢?当然,业务上面,可能通过文档或口口相传的方式,那技术呢?如何培养初级工程师的技术能力呢?Code Review 就是一种很好的途径。每次 Code Review 都是一次真实案例的讲解。通过 Code Review,在实践中将技术传递给初级工程师,比让他们自己学习、自己摸索来得更高效!
5、Code Review 保证代码不止一个人熟悉
如果一段代码只有一个人熟悉,如果这个同事休假了或离职了,代码交接起来就比较费劲。有时候,单纯只看代码还看不大懂,又要跟 PM、业务团队、或者其他技术团队,再重复来一轮沟通,搞的其他团队的人都很烦。而 Code Review 能保证任何代码同时都至少有两个同事熟悉,互为备份,有备无患,除非两个同事同时都离职……
6、Code Review 能打造良好的技术氛围
提交代码 Review 的人,希望自己写的代码足够优秀,毕竟被同事 Review 出很多问题,是件很丢人的事情。而做 Code review 的人,也希望自己尽可能地提出有建设性意见,展示自己的能力。所以,Code Review 还能增进技术交流,活跃技术氛围,培养大家的极客精神,以及对代码质量的追求
一个良好的技术氛围,能让团队有很强的自驱力。不用技术 leader 反复强调代码质量有多重要,团队中的成员就会自己主动去关注代码质量的问题。这比制定各种规章制度、天天督促执行要更加有效。实际上,好的技术氛围也能降低团队的离职率
7、Code Review 是一种技术沟通方式
Talk is cheap,show me the code。怎么“show”,通过 Code Review 工具来“show”,这样也方便别人反馈意见。特别是对于跨不同办公室、跨时区的沟通,Code Review 是一种很好的沟通方式。今天白天写的代码,明天来上班的时候,跨时区的同事已经 Review 好了,改改提交,继续写新的代码了。这样的协作效率会很高
8、Code Review 能提高团队的自律性
在开发过程中,难免会有人不自律,存在侥幸心理:反正写的代码也没人看,随便写写就提交了。Code Review 相当于一次代码直播,曝光 dirty code,有一定的威慑力。这样大家就不敢随便应付一下就提交代码了
2.3.2 如何在团队中落地执行 Code Review?
1、有人认为,Code Review 流程太长,太浪费时间,特别是工期紧的时候,今天改的代码,明天就要上,如果要等同事 Review,同事有可能没时间,这样就来不及。这个时候该怎么办呢?
我所经历的项目还没有一个因为工期紧,导致没有时间 Code Review 的。工期都是人排的,稍微排松点就行了。关键还是在于整个公司对 Code Review 的接受程度。而且,Code Review 熟练之后,并不需要花费太长的时间。尽管开始做 Code Review 的时候,可能因为不熟练,需要有一个 checklist 对照着来做。起步阶段可能会比较耗时。但熟练之后,Code Review 就像键盘盲打一样,已经忘记了哪个手指按的是哪个键了,扫一遍代码就能揪出绝大部分问题
2、有人认为,业务一直在变,今天写的代码明天可能就要再改,代码可能不会长期维护,写得太好也没用。这种情况下是不是就不需要 Code Review 了呢?
这种现象在游戏开发、一些早期的创业公司或者项目验证阶段比较常见。项目讲求短平快,先验证产品,再优化技术。如果确实面对的还只是生存问题,代码质量确实不是首要的,特殊情况下,不做 Code Review 是支持的!
3、有人说,团队成员技术水平不高,过往也没有 Code Review 的经验,不知道 Review 什么,也 Review 不出什么。自己代码都没写明白,不知道什么样的代码是好的,什么样的代码是差的,更不要说 Review 别人的代码了。在 Code Review 的时候,团队成员大眼瞪小眼,只能 Review 点语法,形式大于效果。这种情况该怎么办?
这种情况也挺常见。不过没关系,团队的技术水平都是可以培养的。可以先让资深同事、技术好的同事或技术 leader,来 Review 其他所有人的代码。Review 的过程本身就是一种“传帮带”的过程。慢慢地,整个团队就知道该如何 Review 了。虽然这可能会有一个相当长的过程,但如果真的想在团队中执行 Code Review,这不失为一种“曲线救国”的方法
4、还有人说,刚开始 Code Review 的时候,大家都还挺认真,但时间长了,大家觉得这事跟 KPI 无关,而且还要看别人的代码,理解别人写的代码的业务,多浪费时间啊。慢慢地,Code Review 就变得流于形式了。有人提交了代码,随便抓个人 Review。Review 的人也不认真,随便扫一眼就点“approve”。这种情况该如何应对?
首先,要明确的告诉 Code Review 的重要性,要严格执行,让大家不要懈怠,适当的时候可以“杀鸡儆猴”。其次,可以像 Google 一样,将 Code Review 间接地跟 KPI、升职等联系在一块,高级工程师有义务做 Code Review,就像有义务做技术面试一样。再次,想办法活跃团队的技术氛围,把 Code Review 作为一种展示自己技术的机会,带动起大家对 Code Review 的积极性,提高大家对 Code Review 的认同感
3. Google Guava
Google Guava 是 Google 公司内部 Java 开发工具库的开源版本。Google 内部的很多 Java 项目都在使用它。它提供了一些 JDK 没有提供的功能,以及对 JDK 已有功能的增强功能。其中就包括:集合(Collections)、缓存(Caching)、原生类型支持(Primitives Support)、并发库(Concurrency Libraries)、通用注解(Common Annotation)、字符串处理(Strings Processing)、数学计算(Math)、I/O、事件总线(EventBus)等等
JDK 的全称是 Java Development Kit。它本身就是 Java 提供的工具类库。那既然有了 JDK,为什么 Google 还要开发一套新的类库 Google Guava?是否是重复造轮子?两者的差异化在哪里?
3.1 如何发现通用的功能模块?
很多人觉得做业务开发没有挑战,实际上,做业务开发也会涉及很多非业务功能的开发,比如前面讲到的 ID 生成器、性能计数器、EventBus、DI 容器,以及后面会讲到的限流框架、幂等框架、灰度组件。关键在于,要有善于发现、善于抽象的能力,并且具有扎实的设计、开发能力,能够发现这些非业务的、可复用的功能点,并且从业务逻辑中将其解耦抽象出来,设计并开发成独立的功能模块
在我看来,在业务开发中,跟业务无关的通用功能模块,常见的一般有三类:类库(library)、框架(framework)、功能组件(component)等
其中,Google Guava 属于类库,提供一组 API 接口。EventBus、DI 容器属于框架,提供骨架代码,能让业务开发人员聚焦在业务开发部分,在预留的扩展点里填充业务代码。ID生成器、性能计数器属于功能组件,提供一组具有某一特殊功能的 API 接口,有点类似类库,但更加聚焦和重量级,比如,ID 生成器有可能会依赖 Redis 等外部系统,不像类库那么简单
前面提到的限流、幂等、灰度,到底是属于框架还是功能组件,要视具体情况而定。如果业务代码嵌套在它们里面开发,那就可以称它们为框架。如果它们只是开放 API 接口,供业务系统调用,那就可以称它们为组件。不过,叫什么没有太大关系,不必太深究概念
那如何发现项目中的这些通用的功能模块呢?
实际上,不管是类库、框架还是功能组件,这些通用功能模块有两个最大的特点:复用和业务无关。Google Guava 就是一个典型的例子
如果没有复用场景,那也就没有了抽离出来,设计成独立模块的必要了。如果与业务有关又可复用,大部分情况下会设计成独立的系统(比如微服务),而不是类库、框架或功能组件。所以,如果负责开发的代码,与业务无关并且可能会被复用,那就可以考虑将它独立出来,开发成类库、框架、功能组件等通用功能模块
这里讲的是,在业务开发中,如何发现通用的功能模块。除了业务开发团队之外,很多公司还有一些基础架构团队、架构开发团队,他们除了开发类库、框架、功能组件之外,也会开发一些通用的系统、中间件,比如,Google MapReduce、Kafka 消息中间件、监控系统、分布式调用链追踪系统等
3.2 如何开发通用的功能模块?
当发现了通用功能模块的开发需求之后,如何将它设计开发成一个优秀的类库、框架或功能组件呢?这里先不讲具体的开发技巧,先讲一些更普适的开发思想
作为通用的类库、框架、功能组件,我们希望开发出来之后,不仅仅是自己项目使用,还能用在其他团队的项目中,甚至可以开源出来供更多人所用,这样才能发挥它更大的价值,构建自己的影响力
所以,对于这些类库、框架、功能组件的开发,不能闭门造车,要把它们当作“产品”来开发。这个产品是一个“技术产品”,目标用户是“程序员”,解决的是他们的“开发痛点”。要多换位思考,站在用户的角度上,来想他们到底想要什么样的功能
对于一个技术产品来说,尽管 Bug 少、性能好等技术指标至关重要,但是否易用、易集成、易插拔、文档是否全面、是否容易上手等,这些产品素质也非常重要,甚至还能起到决定性作用。往往就是这些很容易忽视、不被重视的东西,会决定一个技术产品是否能在众多的同类中脱颖而出
具体到 Google Guava,它是一个开发类库,目标用户是 Java 开发工程师,解决用户主要痛点是,相对于 JDK,提供更多的工具类,简化代码编写,比如,它提供了用来判断 null 值的 Preconditions 类;Splitter、Joiner、CharMatcher 字符串处理类;Multisets、Multimaps、Tables 等更丰富的 Collections 类等等
它的优势有这样几点:第一,由 Google 管理、长期维护,经过充分的单元测试,代码质量有保证;第二,可靠、性能好、高度优化,比如 Google Guava 提供的 Immutable Collections 要比 JDK 的 unmodifiableCollection 性能好;第三,全面、完善的文档,容易上手,学习成本低,可以去看下它的 Github Wiki
刚刚讲的是“产品意识”,再来讲讲“服务意识”。如果开发的东西是提供给其他团队用的,一定要有“服务意识”。对于程序员来说,这点可能比“产品意识”更加欠缺
首先,从心态上,别的团队使用我们开发出来的技术产品,要学会感谢。这点很重要。心态不同了,做起事来就会有微妙的不同。其次,除了写代码,还要有抽出大量时间答疑、充当客服角色的心理准备。有了这个心理准备,别的团队的人在问问题的时候,也就不会很烦了
相对于业务代码来说,开发这种被多处复用的通用代码,对代码质量的要求更高些,因为这些项目的影响面更大,一旦出现 bug,会牵连很多系统或其他项目。特别是如果你要把项目开源,影响就更大了。所以,这类项目的代码质量一般都很好,开发这类项目对代码能力的锻炼更有大
具体到 Google Guava,它是 Google 员工开发的,单元测试很完善,注释写得很规范,代码写得也很好,可以说是学习 Google 开发经验的一手资料,建议你如果有时间的话,可以认真阅读一下它的代码
尽管开发这些通用功能模块更加锻炼技术,但也不要重复造轮子,能复用的尽量复用。而且,在项目中,如果想把所有的通用功能都开发为独立的类库、框架、功能组件,这就有点大动干戈了,有可能会得不到领导的支持。毕竟从项目中将这部分通用功能独立出来开发,比起作为项目的一部分来开发,会更加耗时
所以,权衡一下的话,建议初期先把这些通用的功能作为项目的一部分来开发。不过,在开发的时候,做好模块化工作,将它们尽量跟其他模块划清界限,通过接口、扩展点等松耦合的方式跟其他模式交互。等到时机成熟了,再将它从项目中剥离出来。因为之前模块化做的好,耦合程度低,剥离出来的成本也就不会很高
3.3 Google Guava 中用到的几种设计模式
3.3.1 Builder 模式
在项目开发中,经常用到缓存。它可以非常有效地提高访问速度。常用的缓存系统有 Redis、Memcache 等。但是,如果要缓存的数据比较少,完全没必要在项目中独立部署一套缓存系统。毕竟系统都有一定出错的概率,项目中包含的系统越多,那组合起来,项目整体出错的概率就会升高,可用性就会降低。同时,多引入一个系统就要多维护一个系统,项目维护的成本就会变高
取而代之,可以在系统内部构建一个内存缓存,跟系统集成在一起开发、部署。那如何构建内存缓存呢?可以基于 JDK 提供的类,比如 HashMap,从零开始开发内存缓存。不过,从零开发一个内存缓存,涉及的工作就会比较多,比如缓存淘汰策略等。为了简化开发,就可以使用 Google Guava 提供的现成的缓存工具类
com.google.common.cache.*,如下例:
public class CacheDemo {public static void main(String[] args) {Cache<String, String> cache = CacheBuilder.newBuilder().initialCapacity(100).maximumSize(1000).expireAfterWrite(10, TimeUnit.MINUTES).build();cache.put("key1", "value1");String value = cache.getIfPresent("key1");System.out.println(value);}
}
从上面的代码中,可以发现,Cache 对象是通过 CacheBuilder 这样一个 Builder 类来创建的。为什么要由 Builder 类来创建 Cache 对象呢?
构建一个缓存,需要配置 n 多参数,比如过期时间、淘汰策略、最大缓存大小等等。相应地,Cache 类就会包含 n 多成员变量。需要在构造函数中,设置这些成员变量的值,但又不是所有的值都必须设置,设置哪些值由用户来决定。为了满足这个需求,就需要定义多个包含不同参数列表的构造函数
为了避免构造函数的参数列表过长、不同的构造函数过多,一般有两种解决方案。其中,一个解决方案是使用 Builder 模式;另一个方案是先通过无参构造函数创建对象,然后再通过 setXXX() 方法来逐一设置需要的设置的成员变量
为什么 Guava 选择第一种而不是第二种解决方案呢?使用第二种解决方案是否也可以呢?答案是不行的,先看下源码如下:
public <K1 extends K, V1 extends V> Cache<K1, V1> build() {this.checkWeightWithWeigher();this.checkNonLoadingCache();return new LocalManualCache(this);
}
private void checkNonLoadingCache() {Preconditions.checkState(this.refreshNanos == -1L, "refreshAfterWrite require");
}
private void checkWeightWithWeigher() {if (this.weigher == null) {Preconditions.checkState(this.maximumWeight == -1L, "maximumWeight requires");} else if (this.strictParsing) {Preconditions.checkState(this.maximumWeight != -1L, "weigher requires maximnum");} else if (this.maximumWeight == -1L) {logger.log(Level.WARNING, "ignoring weigher specified without maximumWeight");}
}
必须使用 Builder 模式的主要原因是,在真正构造 Cache 对象的时候,必须做一些必要的参数校验,也就是 build() 函数中前两行代码要做的工作。如果采用无参默认构造函数加 setXXX() 方法的方案,这两个校验就无处安放了。而不经过校验,创建的 Cache 对象有可能是不合法、不可用的
3.3.2 Wrapper 模式
在 Google Guava 的 collection 包路径下,有一组以 Forwarding 开头命名的类
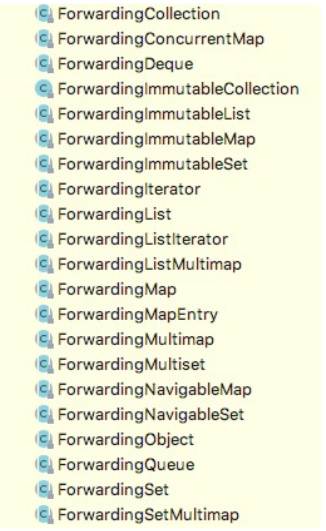
这组 Forwarding 类很多,但实现方式都很相似。这里摘抄了其中的 ForwardingCollection 中的部分代码到这里
@GwtCompatible
public abstract class ForwardingCollection<E> extends ForwardingObject implement Collection {protected ForwardingCollection() {}protected abstract Collection<E> delegate();public Iterator<E> iterator() {return this.delegate().iterator();}public int size() {return this.delegate().size();}@CanIgnoreReturnValuepublic boolean removeAll(Collection<?> collection) {return this.delegate().removeAll(collection);}public boolean isEmpty() {return this.delegate().isEmpty();}public boolean contains(Object object) {return this.delegate().contains(object);}@CanIgnoreReturnValuepublic boolean add(E element) {return this.delegate().add(element);}@CanIgnoreReturnValuepublic boolean remove(Object object) {return this.delegate().remove(object);}public boolean containsAll(Collection<?> collection) {return this.delegate().containsAll(collection);}@CanIgnoreReturnValuepublic boolean addAll(Collection<? extends E> collection) {return this.delegate().addAll(collection);}@CanIgnoreReturnValuepublic boolean retainAll(Collection<?> collection) {return this.delegate().retainAll(collection);}public void clear() {this.delegate().clear();}public Object[] toArray() {return this.delegate().toArray();}//...省略部分代码...
}
再来看他的用法示例:
public class AddLoggingCollection<E> extends ForwardingCollection<E> {private static final Logger logger = LoggerFactory.getLogger(AddLoggingCollecprivate Collection<E> originalCollection;public AddLoggingCollection(Collection<E> originalCollection) {this.originalCollection = originalCollection;}@Overrideprotected Collection delegate() {return this.originalCollection;}@Overridepublic boolean add(E element) {logger.info("Add element: " + element);return this.delegate().add(element);}@Overridepublic boolean addAll(Collection<? extends E> collection) {logger.info("Size of elements to add: " + collection.size());return this.delegate().addAll(collection);}
}
在上面的代码中,AddLoggingCollection 是基于代理模式实现的一个代理类,它在原始 Collection 类的基础之上,针对“add”相关的操作,添加了记录日志的功能
前面讲到,代理模式、装饰器、适配器模式可以统称为 Wrapper 模式,通过 Wrapper 类二次封装原始类。它们的代码实现也很相似,都可以通过组合的方式,将 Wrapper 类的函数实现委托给原始类的函数来实现
public interface Interf {void f1();void f2();
}
public class OriginalClass implements Interf {@Overridepublic void f1() {//...}@Overridepublic void f2() {//...}
}
public class WrapperClass implements Interf {private OriginalClass oc;public WrapperClass(OriginalClass oc) {this.oc = oc;}@Overridepublic void f1() {//...附加功能...this.oc.f1();//...附加功能...}@Overridepublic void f2() {this.oc.f2();}
}
实际上,这个 ForwardingCollection 类是一个“默认 Wrapper 类”或者叫“缺省Wrapper 类”。Java IO 的 FilterInputStream 缺省装饰器类
如果不使用这个 ForwardinCollection 类,而是让 AddLoggingCollection 代理类直接实现 Collection 接口,那 Collection 接口中的所有方法,都要在 AddLoggingCollection 类中实现一遍,而真正需要添加日志功能的只有 add() 和 addAll() 两个函数,其他函数的实现,都只是类似 Wrapper 类中 f2() 函数的实现那样,简单地委托给原始 collection 类对象的对应函数
为了简化 Wrapper 模式的代码实现,Guava 提供一系列缺省的 Forwarding 类。用户在实现自己的 Wrapper 类的时候,基于缺省的 Forwarding 类来扩展,就可以只实现自己关心的方法,其他不关心的方法使用缺省 Forwarding 类的实现,就像 AddLoggingCollection 类的实现那样
3.3.3 Immutable 模式
Immutable 模式,中文叫作不变模式,它并不属于经典的 23 种设计模式,但作为一种较常用的设计思路,可以总结为一种设计模式来学习
一个对象的状态在对象创建之后就不再改变,这就是所谓的不变模式。其中涉及的类就是不变类(Immutable Class),对象就是不变对象(Immutable Object)。在 Java 中,最常用的不变类就是 String 类,String 对象一旦创建之后就无法改变
不变模式可以分为两类,一类是普通不变模式,另一类是深度不变模式(Deeply Immutable Pattern)。普通的不变模式指的是,对象中包含的引用对象是可以改变的。如果不特别说明,通常所说的不变模式,指的就是普通的不变模式。深度不变模式指的是,对象包含的引用对象也不可变。它们两个之间的关系,有点类似之前讲过的浅拷贝和深拷贝之间的关系。如下例:
// 普通不变模式
public class User {private String name;private int age;private Address addr;public User(String name, int age, Address addr) {this.name = name;this.age = age;this.addr = addr;}// 只有getter方法,无setter方法...
}
public class Address {private String province;private String city;public Address(String province, String city) {this.province = province;this.city= city;}// 有getter方法,也有setter方法...
}
// 深度不变模式
public class User {private String name;private int age;private Address addr;public User(String name, int age, Address addr) {this.name = name;this.age = age;this.addr = addr;}// 只有getter方法,无setter方法...
}
public class Address {private String province;private String city;public Address(String province, String city) {this.province = province;this.city= city;}// 只有getter方法,无setter方法..
}
在某个业务场景下,如果一个对象符合创建之后就不会被修改这个特性,那就可以把它设计成不变类。显式地强制它不可变,这样能避免意外被修改。那如何将一个不变类呢?方法很简单,只要这个类满足:所有的成员变量都通过构造函数一次性设置好,不暴露任何 set 等修改成员变量的方法。除此之外,因为数据不变,所以不存在并发读写问题,因此不变模式常用在多线程环境下,来避免线程加锁。所以,不变模式也常被归类为多线程设计模式
接下来,来看一种特殊的不变类,那就是不变集合。Google Guava 针对集合类(Collection、List、Set、Map…)提供了对应的不变集合类(ImmutableCollection、ImmutableList、ImmutableSet、ImmutableMap…)。上面讲过,不变模式分为两种,普通不变模式和深度不变模式。Google Guava 提供的不变集合类属于前者,也就是说,集合中的对象不会增删,但是对象的成员变量(或叫属性值)是可以改变的
实际上,Java JDK 也提供了不变集合类(UnmodifiableCollection、UnmodifiableList、UnmodifiableSet、UnmodifiableMap…)。那它跟 Google Guava 提供的不变集合类的区别在哪里呢?如下例:
public class ImmutableDemo {public static void main(String[] args) {List<String> originalList = new ArrayList<>();originalList.add("a");originalList.add("b");originalList.add("c");List<String> jdkUnmodifiableList = Collections.unmodifiableList(originalList);List<String> guavaImmutableList = ImmutableList.copyOf(originalList);//jdkUnmodifiableList.add("d"); // 抛出UnsupportedOperationException// guavaImmutableList.add("d"); // 抛出UnsupportedOperationExceptionoriginalList.add("d");print(originalList); // a b c dprint(jdkUnmodifiableList); // a b c dprint(guavaImmutableList); // a b c}private static void print(List<String> list) {for (String s : list) {System.out.print(s + " ");}System.out.println();}
}
3.4 函数式编程
现在主流的编程范式主要有三种,面向过程、面向对象和函数式编程。函数式编程并非一个很新的东西,早在 50 多年前就已经出现了。近几年,函数式编程越来越被人关注,出现了很多新的函数式编程语言,比如 Clojure、Scala、Erlang 等。一些非函数式编程语言也加入了很多特性、语法、类库来支持函数式编程,比如 Java、Python、Ruby、JavaScript 等。除此之外,Google Guava 也有对函数式编程的增强功能
函数式编程因其编程的特殊性,仅在科学计算、数据处理、统计分析等领域,才能更好地发挥它的优势,所以个人觉得,它并不能完全替代更加通用的面向对象编程范式。但是,作为一种补充,它也有很大存在、发展和学习的意义
3.4.1 概念
函数式编程的英文翻译是 Functional Programming。 那到底什么是函数式编程呢?
前面讲到,面向过程、面向对象编程并没有严格的官方定义,实际上,函数式编程也是如此,也没有一个严格的官方定义。所以,接下来就从特性上来说说什么是函数式编程
严格上来讲,函数式编程中的“函数”,并不是指编程语言中的“函数”概念,而是指数学“函数”或者“表达式”(比如,y=f(x))。不过,在编程实现的时候,对于数学“函数”或“表达式”,一般习惯性地将它们设计成函数。所以,如果不深究的话,函数式编程中的“函数”也可以理解为编程语言中的“函数”
每个编程范式都有自己独特的地方,这就是它们会被抽象出来作为一种范式的原因。面向对象编程最大的特点是:以类、对象作为组织代码的单元以及它的四大特性。面向过程编程最大的特点是:以函数作为组织代码的单元,数据与方法相分离。那函数式编程最独特的地方又在哪里呢?
实际上,函数式编程最独特的地方在于它的编程思想。函数式编程认为,程序可以用一系列数学函数或表达式的组合来表示。函数式编程是程序面向数学的更底层的抽象,将计算过程描述为表达式。不过,真的可以把任何程序都表示成一组数学表达式吗?
理论上讲是可以的。但是,并不是所有的程序都适合这么做。函数式编程有它自己适合的应用场景,比如本节开头提到的科学计算、数据处理、统计分析等。在这些领域,程序往往比较容易用数学表达式来表示,比起非函数式编程,实现同样的功能,函数式编程可以用很少的代码就能搞定。但是,对于强业务相关的大型业务系统开发来说,费劲地将它抽象成数学表达式,硬要用函数式编程来实现,显然是自讨苦吃。相反,在这种应用场景下,面向对象编程更加合适,写出来的代码更加可读、可维护
具体到编程实现,函数式编程跟面向过程编程一样,也是以函数作为组织代码的单元。不过,它跟面向过程编程的区别在于,它的函数是无状态的。何为无状态?简单点讲就是,函数内部涉及的变量都是局部变量,不会像面向对象编程那样,共享类成员变量,也不会像面向过程编程那样,共享全局变量。函数的执行结果只与入参有关,跟其他任何外部变量无关。同样的入参,不管怎么执行,得到的结果都是一样的。这实际上就是数学函数或数学表达式的基本要求,如下例:
// 有状态函数: 执行结果依赖b的值是多少,即便入参相同,多次执行函数,函数的返回值有可能不同
int b;
int increase(int a) {return a + b;
}
// 无状态函数:执行结果不依赖任何外部变量值,只要入参相同,不管执行多少次,函数的返回值就相同
int increase(int a, int b) {return a + b;
}
不同的编程范式之间并不是截然不同的,总是有一些相同的编程规则。比如,不管是面向过程、面向对象还是函数式编程,它们都有变量、函数的概念,最顶层都要有 main 函数执行入口,来组装编程单元(类、函数等)。只不过,面向对象的编程单元是类或对象,面向过程的编程单元是函数,函数式编程的编程单元是无状态函数
3.4.2 Java 对函数式编程的支持
实现面向对象编程不一定非得使用面向对象编程语言,同理,实现函数式编程也不一定非得使用函数式编程语言。现在,很多面向对象编程语言,也提供了相应的语法、类库来支持函数式编程
Java 为函数式编程引入了三个新的语法概念:Stream 类、Lambda 表达式和函数接口(Functional Inteface)。Stream 类用来支持通过“.”级联多个函数操作的代码编写方式;引入 Lambda 表达式的作用是简化代码编写;函数接口的作用是可以把函数包裹成函数接口,来实现把函数当做参数一样来使用(Java 不像 C 一样支持函数指针,可以把函数直接当参数来使用)
详细的相关知识可自行了解
3.4.3 Guava 对函数式编程的增强
如果你是 Google Guava 的设计者,对于 Java 函数式编程,Google Guava 还能做些什么呢?
颠覆式创新是很难的。不过可以进行一些补充,一方面,可以增加 Stream 类上的操作(类似 map、filter、max 这样的终止操作和中间操作),另一方面,也可以增加更多的函数接口(类似 Function、Predicate 这样的函数接口)。实际上,还可以设计一些类似 Stream 类的新的支持级联操作的类。这样,使用 Java 配合 Guava 进行函数式编程会更加方便
但是,跟预期的相反,Google Guava 并没有提供太多函数式编程的支持,仅仅封装了几个遍历集合操作的接口,代码如下所示:
Iterables.transform(Iterable, Function);
Iterators.transform(Iterator, Function);
Collections.transfrom(Collection, Function);
Lists.transform(List, Function);
Maps.transformValues(Map, Function);
Multimaps.transformValues(Mltimap, Function);
...
Iterables.filter(Iterable, Predicate);
Iterators.filter(Iterator, Predicate);
Collections2.filter(Collection, Predicate);
...
从 Google Guava 的 GitHub Wiki 中发现,Google 对于函数式编程的使用还是很谨慎的,认为过度地使用函数式编程,会导致代码可读性变差,强调不要滥用。所以,在函数式编程方面,Google Guava 并没有提供太多的支持
之所以对遍历集合操作做了优化,主要是因为函数式编程一个重要的应用场景就是遍历集合。如果不使用函数式编程,只能 for 循环,一个一个的处理集合中的数据。使用函数式编程,可以大大简化遍历集合操作的代码编写,一行代码就能搞定,而且在可读性方面也没有太大损失
4. Spring 框架
4.1 蕴含的设计思想
4.1.1 约定优于配置
在使用 Spring 开发的项目中,配置往往会比较复杂、繁琐。比如利用 Spring MVC 来开发 Web 应用,需要配置每个 Controller 类以及 Controller 类中的接口对应的 URL。如何来简化配置呢?一般来讲,有两种方法,一种是基于注解,另一种是基于约定。这两种配置方式在 Spring 中都有用到。Spring 在最小化配置方面做得淋漓尽致,有很多值得借鉴的地方
- 基于注解的配置方式:在指定类上使用指定的注解,来替代集中的 XML 配置。比如,使用
@RequestMapping注解,在 Controller 类或者接口上,标注对应的 URL;使用@Transaction注解表明支持事务等 - 基于约定的配置方式:也常叫作“约定优于配置”或者“规约优于配置”(Convention over Configuration)。通过约定的代码结构或者命名来减少配置。说直白点,就是提供配置的默认值,优先使用默认值。程序员只需要设置那些偏离约定的配置就可以了
比如,在 Spring JPA(基于 ORM 框架、JPA 规范的基础上,封装的一套 JPA 应用框架)中,约定类名默认跟表名相同,属性名默认跟表字段名相同,String 类型对应数据库中的 varchar 类型,long 类型对应数据库中的 bigint 类型等等
基于刚刚的约定,代码中定义的 Order 类就对应数据库中的“order”表。只有在偏离这一约定的时候,例如数据库中表命名为“order_info”而非“order”,才需要显示地去配置类与表的映射关系(Order 类 -> order_info 表)
实际上,约定优于配置,很好地体现了“二八法则”。在平时的项目开发中,80% 的配置使用默认配置就可以了,只有 20% 的配置必须用户显式地去设置。所以,基于约定来配置,在没有牺牲配置灵活性的前提下,节省了大量编写配置的时间,省掉了很多不动脑子的纯体力劳动,提高了开发效率。除此之外,基于相同的约定来做开发,也减少了项目的学习成本和维护成本。
4.1.2 低侵入、松耦合
框架的侵入性是衡量框架好坏的重要指标。所谓低侵入指的是,框架代码很少耦合在业务代码中。低侵入意味着,当要替换一个框架的时候,对原有的业务代码改动会很少。相反,如果一个框架是高度侵入的,代码高度侵入到业务代码中,那替换成另一个框架的成本将非常高,甚至几乎不可能。这也是一些长期维护的老项目,使用的框架、技术比较老旧,又无法更新的一个很重要的原因
实际上,低侵入是 Spring 框架遵循的一个非常重要的设计思想
Spring 提供的 IOC 容器,在不需要 Bean 继承任何父类或者实现任何接口的情况下,仅仅通过配置,就能将它们纳入进 Spring 的管理中。如果换一个 IOC 容器,也只是重新配置一下就可以了,原有的 Bean 都不需要任何修改
除此之外,Spring 提供的 AOP 功能,也体现了低侵入的特性。在项目中,对于非业务功能,比如请求日志、数据采点、安全校验、事务等等,没必要将它们侵入进业务代码中。因为一旦侵入,这些代码将分散在各个业务代码中,删除、修改的成本就变得很高。而基于 AOP 这种开发模式,将非业务代码集中放到切面中,删除、修改的成本就变得很低了
4.1.3 模块化、轻量级
十几年前,EJB 是 Java 企业级应用的主流开发框架。但是,它非常臃肿、复杂,侵入性、耦合性高,开发、维护和学习成本都不低。所以,为了替代笨重的 EJB,Rod Johnson 开发了一套开源的 Interface21 框架,提供了最基本的 IOC 功能。实际上,Interface21 框架就是 Spring 框架的前身
但是,随着不断的发展,Spring 现在也不单单只是一个只包含 IOC 功能的小框架了,它显然已经壮大成了一个“平台”或者叫“生态”,包含了各种五花八门的功能。尽管如此,但它也并没有重蹈覆辙,变成一个像 EJB 那样的庞大难用的框架。那 Spring 是怎么做到的呢?
这就要归功于 Spring 的模块化设计思想,下图是 Spring Framework 的模块和分层介绍图
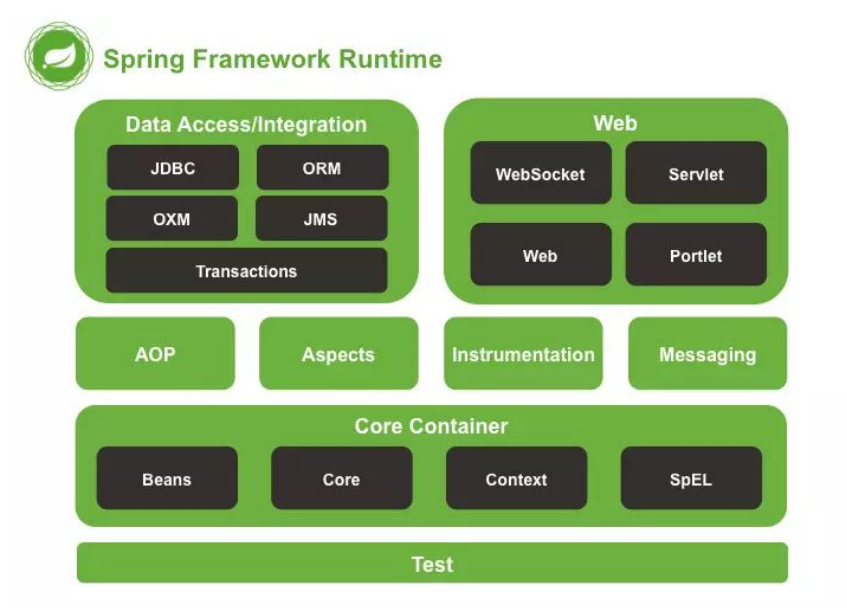
从图中可以看出,Spring 在分层、模块化方面做得非常好。每个模块都只负责一个相对独立的功能。模块之间关系,仅有上层对下层的依赖关系,而同层之间以及下层对上层,几乎没有依赖和耦合。除此之外,在依赖 Spring 的项目中,开发者可以有选择地引入某几个模块,而不会因为需要一个小的功能,就被强迫引入整个 Spring 框架。所以,尽管 Spring Framework 包含的模块很多,已经有二十几个,但每个模块都非常轻量级,都可以单独拿来使用。正因如此,到现在,Spring 框架仍然可以被称为是一个轻量级的开发框架
4.1.4 再封装、再抽象
Spring 不仅仅提供了各种 Java 项目开发的常用功能模块,而且还对市面上主流的中间件、系统的访问类库,做了进一步的封装和抽象,提供了更高层次、更统一的访问接口
比如,Spring 提供了 spring-data-redis 模块,对 Redis Java 开发类库(比如 Jedis、Lettuce)做了进一步的封装,适配 Spring 的访问方式,让编程访问 Redis 更加简单。还有 Spring Cache,实际上也是一种再封装、再抽象。它定义了统一、抽象的 Cache 访问接口,这些接口不依赖具体的 Cache 实现(Redis、Guava Cache、Caffeine 等)。在项目中,基于 Spring 提供的抽象统一的接口来访问 Cache。这样,就能在不修改代码的情况下,实现不同 Cache 之间的切换
除此之外,Spring 对 JDBC 异常也做了进一步的封装。封装的数据库异常继承自 DataAccessException 运行时异常。这类异常在开发中无需强制捕获,从而减少了不必要的异常捕获和处理。除此之外,Spring 封装的数据库异常,还屏蔽了不同数据库异常的细节(比如,不同的数据库对同一报错定义了不同的错误码),让异常的处理更加简单
4.2 用来支持扩展的两种设计模式
4.2.1 观察者模式在 Spring 中的应用
Spring 中实现的观察者模式包含三部分:Event 事件(相当于消息)、Listener 监听者(相当于观察者)、Publisher 发送者(相当于被观察者)。示例如下所示:
// Event事件
public class DemoEvent extends ApplicationEvent {private String message;public DemoEvent(Object source, String message) {super(source);}public String getMessage() {return this.message;}
}
// Listener监听者
@Component
public class DemoListener implements ApplicationListener<DemoEvent> {@Overridepublic void onApplicationEvent(DemoEvent demoEvent) {String message = demoEvent.getMessage();System.out.println(message);}
}
// Publisher发送者
@Component
public class DemoPublisher {@Autowiredprivate ApplicationContext applicationContext;public void publishEvent(DemoEvent demoEvent) {this.applicationContext.publishEvent(demoEvent);}
}
从代码中可以看出,框架使用起来并不复杂,主要包含三部分工作:定义一个继承 ApplicationEvent 的事件(DemoEvent);定义一个实现了 ApplicationListener 的监听器(DemoListener);定义一个发送者(DemoPublisher),发送者调用 ApplicationContext 来发送事件消息
public abstract class ApplicationEvent extends EventObject {private static final long serialVersionUID = 7099057708183571937L;private final long timestamp = System.currentTimeMillis();public ApplicationEvent(Object source) {super(source);}public final long getTimestamp() {return this.timestamp;}
}
public class EventObject implements java.io.Serializable {private static final long serialVersionUID = 5516075349620653480L;protected transient Object source;public EventObject(Object source) {if (source == null)throw new IllegalArgumentException("null source");this.source = source;}public Object getSource() {return source;}public String toString() {return getClass().getName() + "[source=" + source + "]";}
}
public interface ApplicationListener<E extends ApplicationEvent> extends EventObject {void onApplicationEvent(E var1);
}
在之前讲到观察者模式的时候提到,观察者需要事先注册到被观察者(JDK 的实现方式)或者事件总线(EventBus 的实现方式)中。那在 Spring 的实现中,观察者注册到了哪里呢?又是如何注册的呢?
Spring 把观察者注册到了 ApplicationContext 对象中。这里的 ApplicationContext 就相当于 Google EventBus 框架中的“事件总线”。不过,ApplicationContext 这个类并不只是为观察者模式服务的。它底层依赖 BeanFactory(IOC 的主要实现类),提供应用启动、运行时的上下文信息,是访问这些信息的最顶层接口
实际上,具体到源码来说,ApplicationContext 只是一个接口,具体的代码实现包含在它的实现类 AbstractApplicationContext 中。其中跟观察者模式相关的代码如下,只需要关注它是如何发送事件和注册监听者就好
public abstract class AbstractApplicationContext extends ...{private final Set<ApplicationListener<?>> applicationListeners;public AbstractApplicationContext() {this.applicationListeners = new LinkedHashSet();//...}public void publishEvent(ApplicationEvent event) {this.publishEvent(event, (ResolvableType) null);}public void publishEvent(Object event) {this.publishEvent(event, (ResolvableType) null);}protected void publishEvent(Object event, ResolvableType eventType) {//...Object applicationEvent;if (event instanceof ApplicationEvent) {applicationEvent = (ApplicationEvent) event;} else {applicationEvent = new PayloadApplicationEvent(this, event);if (eventType == null) {eventType = ((PayloadApplicationEvent) applicationEvent).getResolvableTy}}if (this.earlyApplicationEvents != null) {this.earlyApplicationEvents.add(applicationEvent);} else {this.getApplicationEventMulticaster().multicastEvent((ApplicationEvent) applicationEvent, eventType);}if (this.parent != null) {if (this.parent instanceof AbstractApplicationContext) {((AbstractApplicationContext) this.parent).publishEvent(event, eventType);} else {this.parent.publishEvent(event);}}}public void addApplicationListener(ApplicationListener<?> listener) {Assert.notNull(listener, "ApplicationListener must not be null");if (this.applicationEventMulticaster != null) {this.applicationEventMulticaster.addApplicationListener(listener);} else {this.applicationListeners.add(listener);}}public Collection<ApplicationListener<?>> getApplicationListeners() {return this.applicationListeners;}protected void registerListeners() {Iterator var1 = this.getApplicationListeners().iterator();while (var1.hasNext()) {ApplicationListener<?> listener = (ApplicationListener) var1.next();}String[] listenerBeanNames = this.getBeanNamesForType(ApplicationListener.cString[]var7 = listenerBeanNames;int var3 = listenerBeanNames.length;for (int var4 = 0; var4 < var3; ++var4) {String listenerBeanName = var7[var4];this.getApplicationEventMulticaster().addApplicationListenerBean(listene}Set<ApplicationEvent> earlyEventsToProcess = this.earlyApplicationEvents;this.earlyApplicationEvents = null;if (earlyEventsToProcess != null) {Iterator var9 = earlyEventsToProcess.iterator();while (var9.hasNext()) {ApplicationEvent earlyEvent = (ApplicationEvent) var9.next();this.getApplicationEventMulticaster().multicastEvent(earlyEvent);}}}
}
从上面的代码中可以发现,真正的消息发送,实际上是通过 ApplicationEventMulticaster 这个类来完成的。这个类的源码这里只摘抄了最关键的一部分,也就是 multicastEvent() 这个消息发送函数。不过,它的代码也并不复杂,它通过线程池,支持异步非阻塞、同步阻塞这两种类型的观察者模式
public void multicastEvent(ApplicationEvent event) {this.multicastEvent(event,this.resolveDefaultEventType(event));
}public void multicastEvent(final ApplicationEvent event,ResolvableType eventType) {ResolvableType type = eventType !=null ? eventType : this.resolveDefaultEvent;Iterator var4=this.getApplicationListeners(event,type).iterator();while(var4.hasNext()) {final ApplicationListener<?> listener=(ApplicationListener)var4.next();Executor executor=this.getTaskExecutor();if(executor!=null){executor.execute(new Runnable(){public void run(){SimpleApplicationEventMulticaster.this.invokeListener(listener,event}});}else{this.invokeListener(listener,event);}}
}
借助 Spring 提供的观察者模式的骨架代码,如果要在 Spring 下实现某个事件的发送和监听,只需要做很少的工作,定义事件、定义监听器、往 ApplicationContext 中发送事件就可以了,剩下的工作都由 Spring 框架来完成。实际上,这也体现了 Spring 框架的扩展性,也就是在不需要修改任何代码的情况下,扩展新的事件和监听
4.2.2 模板模式在 Spring 中的应用
一个经常在面试中被问到的一个问题:请你说下 Spring Bean 的创建过程包含哪些主要的步骤。这其中就涉及模板模式。它也体现了 Spring 的扩展性。利用模板模式,Spring 能让用户定制 Bean 的创建过程
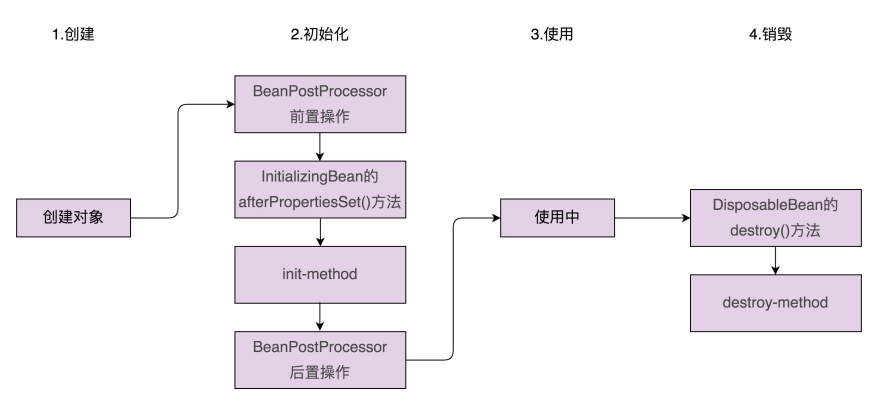
Spring Bean 的创建过程,可以大致分为两大步:对象的创建和对象的初始化
对象的创建是通过反射来动态生成对象,而不是 new 方法。不管是哪种方式,说白了,总归还是调用构造函数来生成对象,没有什么特殊的。对象的初始化有两种实现方式。一种是在类中自定义一个初始化函数,并且通过配置文件,显式地告知 Spring,哪个函数是初始化函数。如下所示,在配置文件中,通过 init-method 属性来指定初始化函数
public class DemoClass {//...public void initDemo() {//...初始化..}
}
// 配置:需要通过init-method显式地指定初始化方法
<bean id="demoBean" class="com.xzg.cd.DemoClass" init-method="initDemo"></bean>
这种初始化方式有一个缺点,初始化函数并不固定,由用户随意定义,这就需要 Spring 通过反射,在运行时动态地调用这个初始化函数。而反射又会影响代码执行的性能,那有没有替代方案呢?
Spring 提供了另外一个定义初始化函数的方法,那就是让类实现 Initializingbean 接口。这个接口包含一个固定的初始化函数定义(afterPropertiesSet() 函数)。Spring 在初始化 Bean 的时候,可以直接通过 bean.afterPropertiesSet() 的方式,调用 Bean 对象上的这个函数,而不需要使用反射来调用了。如下所示
public class DemoClass implements InitializingBean{@Overridepublic void afterPropertiesSet() throws Exception {//...初始化...}
}
// 配置:不需要显式地指定初始化方法
<bean id="demoBean" class="com.xzg.cd.DemoClass"></bean>
尽管这种实现方式不会用到反射,执行效率提高了,但业务代码(DemoClass)跟框架代码(InitializingBean)耦合在了一起。框架代码侵入到了业务代码中,替换框架的成本就变高了。所以,并不是太推荐这种写法
实际上,在 Spring 对 Bean 整个生命周期的管理中,还有一个跟初始化相对应的过程,那就是 Bean 的销毁过程。在 Java 中,对象的回收是通过 JVM 来自动完成的。但是可以在将 Bean 正式交给 JVM 垃圾回收前,执行一些销毁操作(比如关闭文件句柄等等)
销毁过程跟初始化过程非常相似,也有两种实现方式。一种是通过配置 destroy-method 指定类中的销毁函数,另一种是让类实现 DisposableBean 接口
实际上,Spring 针对对象的初始化过程,还做了进一步的细化,将它拆分成了三个小步骤:初始化前置操作、初始化、初始化后置操作。其中,中间的初始化操作就是刚刚讲的那部分,初始化的前置和后置操作,定义在接口 BeanPostProcessor 中。BeanPostProcessor 的接口定义如下所示:
public interface BeanPostProcessor {Object postProcessBeforeInitialization(Object var1, String var2) throws BeansException;Object postProcessAfterInitialization(Object var1, String var2) throws BeansException;
}
再来看下,如何通过 BeanPostProcessor 来定义初始化前置和后置操作?
只需要定义一个实现了 BeanPostProcessor 接口的处理器类,并在配置文件中像配置普通 Bean 一样去配置就可以了。Spring 中的 ApplicationContext 会自动检测在配置文件中实现了 BeanPostProcessor 接口的所有 Bean,并把它们注册到 BeanPostProcessor 处理器列表中。在 Spring 容器创建 Bean 的过程中,Spring 会逐一去调用这些处理器
到这里可能会说,这里哪里用到了模板模式啊?模板模式不是需要定义一个包含模板方法的抽象模板类,以及定义子类实现模板方法吗?
实际上,这里的模板模式的实现,并不是标准的抽象类的实现方式,而是有点类似前面讲到的 Callback 回调的实现方式,也就是将要执行的函数封装成对象(比如,初始化方法封装成 InitializingBean 对象),传递给模板(BeanFactory)来执行
4.3 Spring 框架用到的 11 种设计模式
4.3.1 适配器模式在 Spring 中的应用
在 Spring MVC 中,定义一个 Controller 最常用的方式是,通过 @Controller 注解来标记某个类是 Controller 类,通过 @RequesMapping 注解来标记函数对应的 URL。不过,定义一个 Controller 远不止这一种方法。还可以通过让类实现 Controller 接口或者 Servlet 接口,来定义一个 Controller。针对这三种定义方式,示例代码如下所示:
// 方法一:通过@Controller、@RequestMapping来定义
@Controller
public class DemoController {@RequestMapping("/employname")public ModelAndView getEmployeeName() {ModelAndView model = new ModelAndView("Greeting");model.addObject("message", "Dinesh");return model;}
}// 方法二:实现Controller接口 + xml配置文件:配置DemoController与URL的对应关系
public class DemoController implements Controller {@Overridepublic ModelAndView handleRequest(HttpServletRequest req, HttpServletResponse rep) {ModelAndView model = new ModelAndView("Greeting");model.addObject("message", "Dinesh Madhwal");return model;}
}// 方法三:实现Servlet接口 + xml配置文件:配置DemoController类与URL的对应关系
public class DemoServlet extends HttpServlet {@Overrideprotected void doGet(HttpServletRequest req, HttpServletResponse resp) throws Exception {this.doPost(req, resp);}@Overrideprotected void doPost(HttpServletRequest req, HttpServletResponse resp) throw Exception {resp.getWriter().write("Hello World.");}
}在应用启动的时候,Spring 容器会加载这些 Controller 类,并且解析出 URL 对应的处理函数,封装成 Handler 对象,存储到 HandlerMapping 对象中。当有请求到来的时候,DispatcherServlet 从 HanderMapping 中,查找请求 URL 对应的 Handler,然后调用执行 Handler 对应的函数代码,最后将执行结果返回给客户端
但是,不同方式定义的 Controller,其函数的定义(函数名、入参、返回值等)是不统一的。如上示例代码所示,方法一中的函数的定义很随意、不固定,方法二中的函数定义是 handleRequest()、方法三中的函数定义是 service()(看似是定义了 doGet()、doPost(),实际上,这里用到了模板模式,Servlet 中的 service() 调用了 doGet() 或 doPost() 方法,DispatcherServlet 调用的是 service() 方法)。DispatcherServlet 需要根据不同类型的 Controller,调用不同的函数。下面是具体的伪代码:
Handler handler = handlerMapping.get(URL);
if (handler instanceof Controller) {((Controller)handler).handleRequest(...);
} else if (handler instanceof Servlet) {((Servlet)handler).service(...);
} else if (hanlder 对应通过注解来定义的Controller) {反射调用方法...
}
从代码中可以看出,这种实现方式会有很多 if-else 分支判断,而且,如果要增加一个新的 Controller 的定义方法,就要在 DispatcherServlet 类代码中,对应地增加一段如上伪代码所示的 if 逻辑。这显然不符合开闭原则
实际上,可以利用适配器模式对代码进行改造,让其满足开闭原则,能更好地支持扩赞。在前面讲到适配器其中一个作用是“统一多个类的接口设计”。利用适配器模式,将不同方式定义的 Controller 类中的函数,适配为统一的函数定义。这样,就能在 DispatcherServlet 类代码中,移除掉 if-else 分支判断逻辑,调用统一的函数
具体看下 Spring 的代码实现,Spring 定义了统一的接口 HandlerAdapter,并且对每种 Controller 定义了对应的适配器类。这些适配器类包括:AnnotationMethodHandlerAdapter、SimpleControllerHandlerAdapter、SimpleServletHandlerAdapter 等,源码如下:
public interface HandlerAdapter {boolean supports(Object var1);ModelAndView handle(HttpServletRequest var1, HttpServletResponse var2, Objectlong getLastModified(HttpServletRequest var1, Object var2);}
// 对应实现Controller接口的Controller
public class SimpleControllerHandlerAdapter implements HandlerAdapter {public SimpleControllerHandlerAdapter() {}public boolean supports(Object handler) {return handler instanceof Controller;}public ModelAndView handle(HttpServletRequest request, HttpServletResponse rereturn ((Controller)handler).handleRequest(request, response);}public long getLastModified(HttpServletRequest request, Object handler) {return handler instanceof LastModified ? ((LastModified)handler).getLastMod}
}
// 对应实现Servlet接口的Controller
public class SimpleServletHandlerAdapter implements HandlerAdapter {public SimpleServletHandlerAdapter() {}public boolean supports(Object handler) {return handler instanceof Servlet;}public ModelAndView handle(HttpServletRequest request, HttpServletResponse response) {((Servlet)handler).service(request, response);return null;}public long getLastModified(HttpServletRequest request, Object handler) {return -1L;}
}
//AnnotationMethodHandlerAdapter对应通过注解实现的Controller,
//...
在 DispatcherServlet 类中,就不需要区分对待不同的 Controller 对象了,统一调用 HandlerAdapter 的 handle() 函数就可以了。按照这个思路实现的伪代码如下所示:
// 之前的实现方式
Handler handler = handlerMapping.get(URL);
if (handler instanceof Controller) {((Controller)handler).handleRequest(...);
} else if (handler instanceof Servlet) {((Servlet)handler).service(...);
} else if (hanlder 对应通过注解来定义的Controller) {反射调用方法...
}
// 现在实现方式
HandlerAdapter handlerAdapter = handlerMapping.get(URL);
handlerAdapter.handle(...);
4.3.2 策略模式在 Spring 中的应用
Spring AOP 是通过动态代理来实现的,具体到代码实现,Spring 支持两种动态代理实现方式,一种是 JDK 提供的动态代理实现方式,另一种是 Cglib 提供的动态代理实现方式
前者需要被代理的类有抽象的接口定义,后者不需要。针对不同的被代理类,Spring 会在运行时动态地选择不同的动态代理实现方式。这个应用场景实际上就是策略模式的典型应用场景
前面讲过,策略模式包含三部分,策略的定义、创建和使用。接下来具体看下,这三个部分是如何体现在 Spring 源码中的
在策略模式中,策略的定义这一部分很简单。只需要定义一个策略接口,让不同的策略类都实现这一个策略接口。对应到 Spring 源码,AopProxy 是策略接口,JdkDynamicAopProxy、CglibAopProxy 是两个实现了 AopProxy 接口的策略类。其中,AopProxy 接口的定义如下所示:
public interface AopProxy {Object getProxy();Object getProxy(ClassLoader var1);
}
在策略模式中,策略的创建一般通过工厂方法来实现。对应到 Spring 源码,AopProxyFactory 是一个工厂类接口,DefaultAopProxyFactory 是一个默认的工厂类,用来创建 AopProxy 对象。两者的源码如下所示:
public interface AopProxyFactory {AopProxy createAopProxy(AdvisedSupport var1) throws AopConfigException;
}public class DefaultAopProxyFactory implements AopProxyFactory, Serializable {public DefaultAopProxyFactory() {}public AopProxy createAopProxy(AdvisedSupport config) throws AopConfigException) {if (!config.isOptimize() && !config.isProxyTargetClass() && !this.hasNoUse) {return new JdkDynamicAopProxy(config);} else {Class<?> targetClass = config.getTargetClass();if (targetClass == null) {throw new AopConfigException("TargetSource cannot determine target class");} else {return (AopProxy)(!targetClass.isInterface() && !Proxy.isProxyClass(targetClass);}}}//用来判断用哪个动态代理实现方式private boolean hasNoUserSuppliedProxyInterfaces(AdvisedSupport config) {Class<?>[] ifcs = config.getProxiedInterfaces();return ifcs.length == 0 || ifcs.length == 1 && SpringProxy.class.isAssignab}
}
策略模式的典型应用场景,一般是通过环境变量、状态值、计算结果等动态地决定使用哪个策略。对应到 Spring 源码中,可以参看刚刚给出的 DefaultAopProxyFactory 类中的 createAopProxy() 函数的代码实现。其中,第 10 行代码是动态选择哪种策略的判断条件
4.3.3 组合模式在 Spring 中的应用
前面讲到 Spring“再封装、再抽象”设计思想的时候,提到了 Spring Cache。Spring Cache 提供了一套抽象的 Cache 接口。使用它我们能够统一不同缓存实现(Redis、Google Guava…)的不同的访问方式。Spring 中针对不同缓存实现的不同缓存访问类,都依赖这个接口,比如:EhCacheCache、GuavaCache、NoOpCache、RedisCache、JCacheCache、ConcurrentMapCache、CaffeineCache。Cache 接口的源码如下所示:
public interface Cache {String getName();Object getNativeCache();Cache.ValueWrapper get(Object var1);<T> T get(Object var1, Class<T> var2);<T> T get(Object var1, Callable<T> var2);void put(Object var1, Object var2);Cache.ValueWrapper putIfAbsent(Object var1, Object var2);void evict(Object var1);void clear();public static class ValueRetrievalException extends RuntimeException {private final Object key;public ValueRetrievalException(Object key, Callable<?> loader, Throwable exception) {super(String.format("Value for key '%s' could not be loaded using '%s'",this.key = key;}public Object getKey() {return this.key;}}public interface ValueWrapper {Object get();}
}
在实际的开发中,一个项目有可能会用到多种不同的缓存,比如既用到 Google Guava 缓存,也用到 Redis 缓存。除此之外,同一个缓存实例,也可以根据业务的不同,分割成多个小的逻辑缓存单元(或者叫作命名空间)
为了管理多个缓存,Spring 还提供了缓存管理功能。不过,它包含的功能很简单,主要有这样两部分:一个是根据缓存名字(创建 Cache 对象的时候要设置 name 属性)获取 Cache 对象;另一个是获取管理器管理的所有缓存的名字列表。对应的 Spring 源码如下所示:
public interface CacheManager {Cache getCache(String var1);Collection<String> getCacheNames();
}
刚刚给出的是 CacheManager 接口的定义,那如何来实现这两个接口呢?这就要用到了之前讲过的组合模式,组合模式主要应用在能表示成树形结构的一组数据上。树中的结点分为叶子节点和中间节点两类。对应到 Spring 源码,EhCacheManager、SimpleCacheManager、NoOpCacheManager、RedisCacheManager 等表示叶子节点,CompositeCacheManager 表示中间节点
叶子节点包含的是它所管理的 Cache 对象,中间节点包含的是其他 CacheManager 管理器,既可以是 CompositeCacheManager,也可以是具体的管理器,比如 EhCacheManager、RedisManager 等
CompositeCacheManger 的代码如下,其中,getCache()、getCacheNames() 两个函数的实现都用到了递归。这正是树形结构最能发挥优势的地方
public class CompositeCacheManager implements CacheManager, InitializingBean {private final List<CacheManager> cacheManagers = new ArrayList();private boolean fallbackToNoOpCache = false;public CompositeCacheManager() {}public CompositeCacheManager(CacheManager... cacheManagers) {this.setCacheManagers(Arrays.asList(cacheManagers));}public void setCacheManagers(Collection<CacheManager> cacheManagers) {this.cacheManagers.addAll(cacheManagers);}public void setFallbackToNoOpCache(boolean fallbackToNoOpCache) {this.fallbackToNoOpCache = fallbackToNoOpCache;}public void afterPropertiesSet() {if (this.fallbackToNoOpCache) {this.cacheManagers.add(new NoOpCacheManager());}}public Cache getCache(String name) {Iterator var2 = this.cacheManagers.iterator();Cache cache;do {if (!var2.hasNext()) {return null;}CacheManager cacheManager = (CacheManager)var2.next();cache = cacheManager.getCache(name);} while(cache == null);return cache;}public Collection<String> getCacheNames() {Set<String> names = new LinkedHashSet();Iterator var2 = this.cacheManagers.iterator();while(var2.hasNext()) {CacheManager manager = (CacheManager)var2.next();names.addAll(manager.getCacheNames());}return Collections.unmodifiableSet(names);}
}
4.3.4 装饰器模式在 Spring 中的应用
缓存一般都是配合数据库来使用的。如果写缓存成功,但数据库事务回滚了,那缓存中就会有脏数据。为了解决这个问题,需要将缓存的写操作和数据库的写操作,放到同一个事务中,要么都成功,要么都失败
实现这样一个功能,Spring 使用到了装饰器模式。TransactionAwareCacheDecorator 增加了对事务的支持,在事务提交、回滚的时候分别对 Cache 的数据进行处理
TransactionAwareCacheDecorator 实现 Cache 接口,并且将所有的操作都委托给 targetCache 来实现,对其中的写操作添加了事务功能。这是典型的装饰器模式的应用场景和代码实现
public class TransactionAwareCacheDecorator implements Cache {private final Cache targetCache;public TransactionAwareCacheDecorator(Cache targetCache) {Assert.notNull(targetCache, "Target Cache must not be null");this.targetCache = targetCache;}public Cache getTargetCache() {return this.targetCache;}public String getName() {return this.targetCache.getName();}public Object getNativeCache() {return this.targetCache.getNativeCache();}public ValueWrapper get(Object key) {return this.targetCache.get(key);}public <T> T get(Object key, Class<T> type) {return this.targetCache.get(key, type);}public <T> T get(Object key, Callable<T> valueLoader) {return this.targetCache.get(key, valueLoader);}public void put(final Object key, final Object value) {if (TransactionSynchronizationManager.isSynchronizationActive()) {TransactionSynchronizationManager.registerSynchronization(new Transaction() {public void afterCommit() {TransactionAwareCacheDecorator.this.targetCache.put(key, value);}});} else {this.targetCache.put(key, value);}}public ValueWrapper putIfAbsent(Object key, Object value) {return this.targetCache.putIfAbsent(key, value);}public void evict(final Object key) {if (TransactionSynchronizationManager.isSynchronizationActive()) {TransactionSynchronizationManager.registerSynchronization(new Transaction() {public void afterCommit() {TransactionAwareCacheDecorator.this.targetCache.evict(key);}});} else {this.targetCache.evict(key);}}public void clear() {if (TransactionSynchronizationManager.isSynchronizationActive()) {TransactionSynchronizationManager.registerSynchronization(new Transaction() {public void afterCommit() {TransactionAwareCacheDecorator.this.targetCache.clear();}});} else {this.targetCache.clear();}}
}
4.3.5 工厂模式在 Spring 中的应用
在 Spring 中,工厂模式最经典的应用莫过于实现 IOC 容器,对应的 Spring 源码主要是 BeanFactory 类和 ApplicationContext 相关类(AbstractApplicationContext、ClassPathXmlApplicationContext、FileSystemXmlApplicationContext…)
在 Spring 中,创建 Bean 的方式有很多种,比如前面提到的纯构造函数、无参构造函数加 setter 方法,如下例:
public class Student {private long id;private String name;public Student(long id, String name) {this.id = id;this.name = name;}public void setId(long id) {this.id = id;}public void setName(String name) {this.name = name;}
}
<bean id="student" class="com.xzg.cd.Student">< constructor arg="" name="id" value="1">< constructor arg="" name="name" value="wangzheng">< bean="">// 使用无参构造函数+setter方法来创建Bean <bean id="student" class="com.xzg.cd.Student"><property name="id" value="1">< property=""><property name="name" value="wangzheng">< property=""></ ></property></ ></property></bean></ ></ constructor></ constructor>
</bean>
实际上,除了这两种创建 Bean 的方式之外,还可以通过工厂方法来创建 Bean。还是刚刚这个例子,用这种方式来创建 Bean 的话就是下面这个样子:
public class StudentFactory {private static Map<Long, Student> students = new HashMap<>();static {map.put(1, new Student(1, "wang"));map.put(2, new Student(2, "zheng"));map.put(3, new Student(3, "xzg"));}public static Student getStudent(long id) {return students.get(id);}
}// 通过工厂方法getStudent(2)来创建BeanId="zheng""的Bean
<bean id="zheng" class="com.xzg.cd.StudentFactory" factory-method="getStudent"><constructor-arg value="2"></constructor-arg>
</bean>
4.3.6 其他模式在 Spring 中的应用
SpEL,全称叫 Spring Expression Language,是 Spring 中常用来编写配置的表达式语言。它定义了一系列的语法规则。只要按照这些语法规则来编写表达式,Spring 就能解析出表达式的含义。实际上,这就是前面讲到的解释器模式的典型应用场景
因为解释器模式没有一个非常固定的代码实现结构,而且 Spring 中 SpEL 相关的代码也比较多,所以这里就不进行过多讲述了。如果感兴趣或者项目中正好要实现类似的功能的时候,可以再去阅读、借鉴它的代码实现。代码主要集中在 spring-expresssion 这个模块下面
前面讲到单例模式的时候提到过,单例模式有很多弊端,比如单元测试不友好等。应对策略就是通过 IOC 容器来管理对象,通过 IOC 容器来实现对象的唯一性的控制。实际上,这样实现的单例并非真正的单例,它的唯一性的作用范围仅仅在同一个 IOC 容器内
除此之外,Spring 还用到了观察者模式、模板模式、职责链模式、代理模式
实际上,在 Spring 中,只要后缀带有 Template 的类,基本上都是模板类,而且大部分都是用 Callback 回调来实现的,比如 JdbcTemplate、RedisTemplate 等。剩下的两个模式在 Spring 中的应用应该人尽皆知了。职责链模式在 Spring 中的应用是拦截器(Interceptor),代理模式经典应用是 AOP
5. MyBatis
5.1 Mybatis 和 ORM 框架介绍
MyBatis 是一个 ORM(Object Relational Mapping,对象 · 关系映射)框架。ORM 框架主要是根据类和数据库表之间的映射关系,帮助程序员自动实现对象与数据库中数据之间的互相转化。说得更具体点就是,ORM 负责将程序中的对象存储到数据库中、将数据库中的数据转化为程序中的对象。实际上,Java 中的 ORM 框架
有很多,除了刚刚提到的 MyBatis 之外,还有 Hibernate、TopLink 等
在剖析 Spring 框架的时候讲到,如果用一句话来总结框架作用的话,那就是简化开发。MyBatis 框架也不例外。它简化的是数据库方面的开发。那 MyBatis 是如何简化数据库开发的呢?
前面讲到 Java 提供了 JDBC 类库来封装不同类型的数据库操作。不过,直接使用 JDBC 来进行数据库编程,还是有点麻烦的。于是,Spring 提供了 JdbcTemplate,对 JDBC 进一步封装,来进一步简化数据库编程
使用 JdbcTemplate 进行数据库编程,只需要编写跟业务相关的代码(比如,SQL 语句、数据库中数据与对象之间的互相转化的代码),其他流程性质的代码(比如,加载驱动、创建数据库连接、创建 statement、关闭连接、关闭 statement 等)都封装在了 JdbcTemplate 类中,不需要重复编写
还是同样这个例子,再来看下,使用 MyBatis 该如何实现,是不是比使用 JdbcTemplate 更加简单
因为 MyBatis 依赖 JDBC 驱动,所以,在项目中使用 MyBatis,除了需要引入 MyBatis 框架本身(mybatis.jar)之外,还需要引入 JDBC 驱动(比如,访问 MySQL 的 JDBC 驱动实现类库 mysql-connector-java.jar)。将两个 jar 包引入项目之后,就可以开始编程了。使用 MyBatis 来访问数据库中用户信息的代码如下所示:
// 1. 定义UserDO
public class UserDo {private long id;private String name;private String telephone;// 省略setter/getter方法
}
// 2. 定义访问接口
public interface UserMapper {public UserDo selectById(long id);
}
// 3. 定义映射关系:UserMapper.xml
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org/DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.xzg.cd.a87.repo.mapper.UserMapper"><select id="selectById" resultType="cn.xzg.cd.a87.repo.UserDo">select * from user where id=#{id}</select>
</mapper>
// 4. 全局配置文件: mybatis.xml
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration><environments default="dev"><environment id="dev"><transactionManager type="JDBC"></transactionManager><dataSource type="POOLED"><property name="driver" value="com.mysql.jdbc.Driver" /><property name="url" value="root" /><property name="password" value="..." /></dataSource></environment></environments><mappers><mapper resource="mapper/UserMapper.xml" /></mappers>
</configuration>
需要注意的是,在 UserMapper.xml 配置文件中,只定义了接口和 SQL 语句之间的映射关系,并没有显式地定义类(UserDo)字段与数据库表(user)字段之间的映射关系。实际上,这就体现了“约定优于配置”的设计原则。类字段与数据库表字段之间使用了默认映射关系:类字段跟数据库表中拼写相同的字段一一映射。当然,如果没办法做到一一映射,也可以自定义它们之间的映射关系
有了上面的代码和配置,就可以像下面这样来访问数据库中的用户信息了
public class MyBatisDemo {public static void main(String[] args) throws IOException {Reader reader = Resources.getResourceAsReader("mybatis.xml");SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(reader);SqlSession session = sessionFactory.openSession();UserMapper userMapper = session.getMapper(UserMapper.class);UserDo userDo = userMapper.selectById(8);//...}
}
从代码中可以看出,相对于使用 JdbcTemplate 的实现方式,使用 MyBatis 的实现方式更加灵活。在使用 JdbcTemplate 的实现方式中,对象与数据库中数据之间的转化代码、SQL 语句,是硬编码在业务代码中的。而在使用 MyBatis 的实现方式中,类字段与数据库字段之间的映射关系、接口与 SQL 之间的映射关系,是写在 XML 配置文件中的,是跟代码相分离的,这样会更加灵活、清晰,维护起来更加方便
5.2 如何平衡易用性、性能和灵活性?
刚刚对 MyBatis 框架做了简单介绍,接下来,再对比一下另外两个框架:JdbcTemplate 和 Hibernate。通过对比来看,MyBatis 是如何权衡代码的易用性、性能和灵活性的
先来看 JdbcTemplate。相对于 MyBatis 来说,JdbcTemplate 更加轻量级。因为它对 JDBC 只做了很简单的封装,所以性能损耗比较少。相对于其他两个框架来说,它的性能最好。但是,它的缺点也比较明显,那就是 SQL 与代码耦合在一起,而且不具备 ORM 的功能,需要自己编写代码,解析对象跟数据库中的数据之间的映射关系。所以,在易用性上它不及其他两个框架
再来看 Hibernate。相对于 MyBatis 来说,Hibernate 更加重量级。Hibernate 提供了更加高级的映射功能,能够根据业务需求自动生成 SQL 语句。不需要像使用 MyBatis 那样自己编写 SQL。因此,有的时候,也把 MyBatis 称作半自动化的 ORM框架,把 Hibernate 称作全自动化的 ORM 框架。不过,虽然自动生成 SQL 简化了开发,但是毕竟是自动生成的,没有针对性的优化。在性能方面,这样得到的 SQL 可能没有程序员编写得好。同时,这样也丧失了程序员自己编写 SQL 的灵活性
实际上,不管用哪种实现方式,从数据库中取出数据并且转化成对象,这个过程涉及的代码逻辑基本是一致的。不同实现方式的区别,只不过是哪部分代码逻辑放到了哪里。有的框架提供的功能比较强大,大部分代码逻辑都由框架来完成,程序员只需要实现很小的一部分代码就可以了。这样框架的易用性就更好些。但是,框架集成的功能越多,为了处理逻辑的通用性,就会引入更多额外的处理代码。比起针对具体问题具体编程,这样性能损耗就相对大一些
所以,粗略地讲,有的时候,框架的易用性和性能成对立关系。追求易用性,那性能就差一些。相反,追求性能,易用性就差一些。除此之外,使用起来越简单,那灵活性就越差,实际上,JdbcTemplate、MyBatis、Hibernate 这几个框架也体现了刚刚说的这个规律
JdbcTemplate 提供的功能最简单,易用性最差,性能损耗最少,用它编程性能最好。Hibernate 提供的功能最完善,易用性最好,但相对来说性能损耗就最高了。MyBatis 介于两者中间,在易用性、性能、灵活性三个方面做到了权衡。它支撑程序员自己编写 SQL,能够延续程序员对 SQL 知识的积累。相对于完全黑盒子的 Hibernate,很多程序员反倒是更加喜欢 MyBatis 这种半透明的框架。这也提醒我们,过度封装,提供过于简化的开发方式,也会丧失开发的灵活性
5.3 如何利用职责链与代理模式实现 MyBatis Plugin?
MyBatis Plugin,尽管名字叫 Plugin(插件),但它实际上跟之前讲到的 Servlet Filter(过滤器)、Spring Interceptor(拦截器)类似,设计的初衷都是为了框架的扩展性,用到的主要设计模式都是职责链模式
不过,相对于 Servlet Filter 和 Spring Interceptor,MyBatis Plugin 中职责链模式的代码实现稍微有点复杂。它是借助动态代理模式来实现的职责链
5.3.1 MyBatis Plugin 功能介绍
实际上,MyBatis Plugin 跟 Servlet Filter、Spring Interceptor 的功能是类似的,都是在不需要修改原有流程代码的情况下,拦截某些方法调用,在拦截的方法调用的前后,执行一些额外的代码逻辑。它们的唯一区别在于拦截的位置是不同的。Servlet Filter 主要拦截 Servlet 请求,Spring Interceptor 主要拦截 Spring 管理的 Bean 方法(比如 Controller 类的方法等),而 MyBatis Plugin 主要拦截的是 MyBatis 在执行 SQL 的过程中涉及的一些方法,MyBatis Plugin 使用起来比较简单,如下例:
假设需要统计应用中每个 SQL 的执行耗时,如果使用 MyBatis Plugin 来实现的话,只需要定义一个 SqlCostTimeInterceptor 类,让它实现 MyBatis 的 Interceptor 接口,并且,在 MyBatis 的全局配置文件中,简单声明一下这个插件就可以了。具体的代码和配置如下所示:
@Intercepts({@Signature(type = StatementHandler.class, method = "query", args = { StatementHandler }@Signature(type = StatementHandler.class, method = "update", args = { StatementHandler}@Signature(type = StatementHandler.class, method = "batch", args = { StatementHandler}
}
public class SqlCostTimeInterceptor implements Interceptor {private static Logger logger = LoggerFactory.getLogger(SqlCostTimeInterceptor);@Overridepublic Object intercept(Invocation invocation) throws Throwable {Object target = invocation.getTarget();long startTime = System.currentTimeMillis();StatementHandler statementHandler = (StatementHandler) target;try {return invocation.proceed();} finally {long costTime = System.currentTimeMillis() - startTime;BoundSql boundSql = statementHandler.getBoundSql();String sql = boundSql.getSql();logger.info("执行 SQL:[ {} ]执行耗时[ {} ms]", sql, costTime);}}@Overridepublic Object plugin(Object target) {return Plugin.wrap(target, this);}@Overridepublic void setProperties(Properties properties) {System.out.println("插件配置的信息:" + properties);}
}
<!-- MyBatis全局配置文件:mybatis-config.xml -->
<plugins><plugin interceptor="com.xzg.cd.a88.SqlCostTimeInterceptor"><property name="someProperty" value="100" /></plugin>
</plugins>
先重点看下 @Intercepts 注解这一部分,不管是拦截器、过滤器还是插件,都需要明确地标明拦截的目标方法。@Intercepts 注解实际上就是起了这个作用。其中,@Intercepts 注解又可以嵌套 @Signature 注解。一个 @Signature 注解标明一个要拦截的目标方法。如果要拦截多个方法,可以像例子中那样,编写多条 @Signature 注解
@Signature 注解包含三个元素:type、method、args。其中,type 指明要拦截的类、method 指明方法名、args 指明方法的参数列表。通过指定这三个元素,就能完全确定一个要拦截的方法
默认情况下,MyBatis Plugin 允许拦截的方法有下面这样几个:

为什么默认允许拦截的是这样几个类的方法呢?
MyBatis 底层是通过 Executor 类来执行 SQL 的。Executor 类会创建 StatementHandler、ParameterHandler、ResultSetHandler 三个对象,并且,首先使用 ParameterHandler 设置 SQL 中的占位符参数,然后使用 StatementHandler 执行SQL 语句,最后使用 ResultSetHandler 封装执行结果。所以,只需要拦截 Executor、ParameterHandler、ResultSetHandler、StatementHandler 这几个类的方法,基本上就能满足对整个 SQL 执行流程的拦截了
实际上,除了统计 SQL 的执行耗时,利用 MyBatis Plugin,还可以做很多事情,比如分库分表、自动分页、数据脱敏、加密解密等等
5.3.2 MyBatis Plugin 的设计与实现
职责链模式的实现一般包含处理器(Handler)和处理器链(HandlerChain)两部分。这两个部分对应到 Servlet Filter 的源码就是 Filter 和 FilterChain,对应到 Spring Interceptor 的源码就是 HandlerInterceptor 和 HandlerExecutionChain,对应到 MyBatis Plugin 的源码就是 Interceptor 和 InterceptorChain。除此之外,MyBatis Plugin 还包含另外一个非常重要的类:Plugin。它用来生成被拦截对象的动态代理
集成了 MyBatis 的应用在启动的时候,MyBatis 框架会读取全局配置文件(前面例子中的 mybatis-config.xml 文件),解析出 Interceptor(也就是例子中的 SqlCostTimeInterceptor),并且将它注入到 Configuration 类的 InterceptorChain 对象中。这部分逻辑对应到源码如下所示:
public class XMLConfigBuilder extends BaseBuilder {//解析配置private void parseConfiguration(XNode root) {try {//省略部分代码...pluginElement(root.evalNode("plugins")); //解析插件} catch (Exception e) {throw new BuilderException("Error parsing SQL Mapper Configuration. Cause");}}//解析插件private void pluginElement(XNode parent) throws Exception {if (parent != null) {for (XNode child : parent.getChildren()) {String interceptor = child.getStringAttribute("interceptor");Properties properties = child.getChildrenAsProperties();//创建Interceptor类对象Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor);//调用Interceptor上的setProperties()方法设置propertiesinterceptorInstance.setProperties(properties);//下面这行代码会调用InterceptorChain.addInterceptor()方法configuration.addInterceptor(interceptorInstance);}}}
}
// Configuration类的addInterceptor()方法的代码如下所示
public void addInterceptor(Interceptor interceptor) {interceptorChain.addInterceptor(interceptor);
}
再来看 Interceptor 和 InterceptorChain 这两个类的代码,如下所示。Interceptor 的 setProperties() 方法就是一个单纯的 setter 方法,主要是为了方便通过配置文件配置 Interceptor 的一些属性值,没有其他作用。Interceptor 类中 intecept() 和 plugin() 函数,以及 InterceptorChain 类中的 pluginAll() 函数,是最核心的三个函数
public class Invocation {private final Object target;private final Method method;private final Object[] args;// 省略构造函数和getter方法...public Object proceed() throws InvocationTargetException, IllegalAccessExceptreturn method.invoke(target, args);
}
}
public interface Interceptor {Object intercept(Invocation invocation) throws Throwable;Object plugin(Object target);void setProperties(Properties properties);
}
public class InterceptorChain {private final List<Interceptor> interceptors = new ArrayList<Interceptor>();public Object pluginAll(Object target) {for (Interceptor interceptor : interceptors) {target = interceptor.plugin(target);}return target;}public void addInterceptor(Interceptor interceptor) {interceptors.add(interceptor);}public List<Interceptor> getInterceptors() {return Collections.unmodifiableList(interceptors);}
}
解析完配置文件之后,所有的 Interceptor 都加载到了 InterceptorChain 中。接下来,再来看下,这些拦截器是在什么时候被触发执行的?又是如何被触发执行的呢?
前面提到,在执行 SQL 的过程中,MyBatis 会创建 Executor、StatementHandler、ParameterHandler、ResultSetHandler 这几个类的对象,对应的创建代码在 Configuration 类中,如下所示:
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {executorType = executorType == null ? defaultExecutorType : executorType;executorType = executorType == null ? ExecutorType.SIMPLE : executorType;Executor executor;if (ExecutorType.BATCH == executorType) {executor = new BatchExecutor(this, transaction);} else if (ExecutorType.REUSE == executorType) {executor = new ReuseExecutor(this, transaction);} else {executor = new SimpleExecutor(this, transaction);}if (cacheEnabled) {executor = new CachingExecutor(executor);}executor = (Executor) interceptorChain.pluginAll(executor);return executor;
}
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object object) {ParameterHandler parameterHandler = mappedStatement.getLang().createParameter);parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);return parameterHandler;
}
public ResultSetHandler newResultSetHandler(Executor executor, MappedStatement mappedStatement)
ResultHandler resultHandler, BoundSql boundSql) {ResultSetHandler resultSetHandler = new DefaultResultSetHandler(executor, map);resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler);return resultSetHandler;
}
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement) {StatementHandler statementHandler = new RoutingStatementHandler(executor, map);statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);return statementHandler;
}
从上面的代码中,可以发现,这几个类对象的创建过程都调用了 InteceptorChain 的 pluginAll() 方法。这个方法的代码前面已经给出了。它的代码实现很简单,嵌套调用 InterceptorChain 上每个 Interceptor 的 plugin() 方法。plugin()是一个接口方法(不包含实现代码),需要由用户给出具体的实现代码。在之前的例子中,SQLTimeCostInterceptor 的 plugin() 方法通过直接调用 Plugin 的 wrap() 方法来实现。
wrap() 方法的代码实现如下所示:
// 借助Java InvocationHandler实现的动态代理模式
public class Plugin implements InvocationHandler {private final Object target;private final Interceptor interceptor;private final Map<Class<?>, Set<Method>> signatureMap;private Plugin(Object target, Interceptor interceptor, Map < Class<?>, Set < Method>> signatureMap) {this.target = target;this.interceptor = interceptor;this.signatureMap = signatureMap;}// wrap()静态方法,用来生成target的动态代理,// 动态代理对象=target对象+interceptor对象。public static Object wrap(Object target, Interceptor interceptor) {Map<Class<?>, Set<Method>> signatureMap = getSignatureMap(interceptor);Class<?> type = target.getClass();Class<?>[] interfaces = getAllInterfaces(type, signatureMap);if (interfaces.length > 0) {return Proxy.newProxyInstance(type.getClassLoader(),interfaces,new Plugin(target, interceptor, signatureMap));}return target;}// 调用target上的f()方法,会触发执行下面这个方法。// 这个方法包含:执行interceptor的intecept()方法 + 执行target上f()方法。@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {try {Set<Method> methods = signatureMap.get(method.getDeclaringClass());if (methods != null && methods.contains(method)) {return interceptor.intercept(new Invocation(target, method, args));}return method.invoke(target, args);} catch (Exception e) {throw ExceptionUtil.unwrapThrowable(e);}}private static Map<Class<?>, Set<Method>> getSignatureMap(Interceptor interceptor) {Intercepts interceptsAnnotation = interceptor.getClass().getAnnotation(interceptor);// issue #251if (interceptsAnnotation == null) {throw new PluginException("No @Intercepts annotation was found in interce}Signature[] sigs = interceptsAnnotation.value();Map<Class<?>, Set<Method>> signatureMap = new HashMap < Class<?>, Set < Method>> signatureMap);for (Signature sig : sigs) {Set<Method> methods = signatureMap.get(sig.type());if (methods == null) {methods = new HashSet<Method>();signatureMap.put(sig.type(), methods);}try {Method method = sig.type().getMethod(sig.method(), sig.args());methods.add(method);} catch (NoSuchMethodException e) {throw new PluginException("Could not find method on " + sig.type() + "}}return signatureMap;}private static Class<?>[] getAllInterfaces(Class<?> type, Map < Class<?>, Set < Method>> signatureMap) {Set<Class<?>> interfaces = new HashSet<Class<?>>();while (type != null) {for (Class<?> c : type.getInterfaces()) {if (signatureMap.containsKey(c)) {interfaces.add(c);}}type = type.getSuperclass();}return interfaces.toArray(new Class<?>[interfaces.size()]);}
}
实际上,Plugin 是借助 Java InvocationHandler 实现的动态代理类。用来代理给 target 对象添加 Interceptor 功能。其中,要代理的 target 对象就是 Executor、StatementHandler、ParameterHandler、ResultSetHandler 这四个类的对象。wrap() 静态方法是一个工具函数,用来生成 target 对象的动态代理对象
当然,只有 interceptor 与 target 互相匹配的时候,wrap() 方法才会返回代理对象,否则就返回 target 对象本身。怎么才算是匹配呢?那就是 interceptor 通过 @Signature 注解要拦截的类包含 target 对象
MyBatis 中的职责链模式的实现方式比较特殊。它对同一个目标对象嵌套多次代理(也就是 InteceptorChain 中的 pluginAll() 函数要执行的任务)。每个代理对象(Plugin 对象)代理一个拦截器(Interceptor 对象)功能。pluginAll() 函数的代码如下:
public Object pluginAll(Object target) {// 嵌套代理for (Interceptor interceptor : interceptors) {target = interceptor.plugin(target);// 上面这行代码等于下面这行代码,target(代理对象)=target(目标对象)+interceptor(拦截器)// target = Plugin.wrap(target, interceptor);}return target;
}
// MyBatis像下面这样创建target(Executor、StatementHandler、ParameterHandler、Resul
Object target = interceptorChain.pluginAll(target);
当执行 Executor、StatementHandler、ParameterHandler、ResultSetHandler 这四个类上的某个方法的时候,MyBatis 会嵌套执行每层代理对象(Plugin 对象)上的 invoke() 方法。而 invoke() 方法会先执行代理对象中的 interceptor 的 intecept() 函数,然后再执行被代理对象上的方法。就这样,一层一层地把代理对象上的 intercept() 函数执行完之后,MyBatis 才最终执行那 4 个原始类对象上的方法
5.4 总结 MyBatis 框架中用到的 10 种设计模式
5.4.1 SqlSessionFactoryBuilder:为什么要用建造者模式来创建SqlSessionFactory?
前面的用户查询例子如下:
public class MyBatisDemo {public static void main(String[] args) throws IOException {Reader reader = Resources.getResourceAsReader("mybatis.xml");SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(reader);SqlSession session = sessionFactory.openSession();UserMapper userMapper = session.getMapper(UserMapper.class);UserDo userDo = userMapper.selectById(8);//...}
}
之前讲到建造者模式的时候,使用 Builder 类来创建对象,一般都是先级联一组 setXXX() 方法来设置属性,然后再调用 build() 方法最终创建对象。但是,在上面这段代码中,通过 SqlSessionFactoryBuilder 来创建 SqlSessionFactory 并不符合这个套路。它既没有 setter 方法,而且 build() 方法也并非无参,需要传递参数。除此之外,从上面的代码来看,SqlSessionFactory 对象的创建过程也并不复杂。那直接通过构造函数来创建 SqlSessionFactory 不就行了吗?为什么还要借助建造者模式创建 SqlSessionFactory呢?
要回答这个问题,我们就要先看下 SqlSessionFactoryBuilder 类的源码。源码如下所示:
public class SqlSessionFactoryBuilder {public SqlSessionFactory build(Reader reader) {return build(reader, null, null);}public SqlSessionFactory build(Reader reader, String environment) {return build(reader, environment, null);}public SqlSessionFactory build(Reader reader, Properties properties) {return build(reader, null, properties);}public SqlSessionFactory build(Reader reader, String environment, Properties properties) {try {XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties);return build(parser.parse());} catch (Exception e) {throw ExceptionFactory.wrapException("Error building SqlSession.", e);} finally {ErrorContext.instance().reset();try {reader.close();} catch (IOException e) {// Intentionally ignore. Prefer previous error.}}}public SqlSessionFactory build(InputStream inputStream) {return build(inputStream, null, null);}public SqlSessionFactory build(InputStream inputStream, String environment) {return build(inputStream, environment, null);}public SqlSessionFactory build(InputStream inputStream, Properties properties) {return build(inputStream, null, properties);}public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {try {XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);return build(parser.parse());} catch (Exception e) {throw ExceptionFactory.wrapException("Error building SqlSession.", e);} finally {ErrorContext.instance().reset();try {inputStream.close();} catch (IOException e) {// Intentionally ignore. Prefer previous error.}}}public SqlSessionFactory build(Configuration config) {return new DefaultSqlSessionFactory(config);}
}
SqlSessionFactoryBuilder 类中有大量的 build() 重载函数。为了方便查看,以及跟 SqlSessionFactory 类的代码作对比,这里把重载函数定义抽象出来如下:
public class SqlSessionFactoryBuilder {public SqlSessionFactory build(Reader reader);public SqlSessionFactory build(Reader reader, String environment);public SqlSessionFactory build(Reader reader, Properties properties);public SqlSessionFactory build(Reader reader, String environment, Properties properties);public SqlSessionFactory build(InputStream inputStream);public SqlSessionFactory build(InputStream inputStream, String environment);public SqlSessionFactory build(InputStream inputStream, Properties properties);public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties);// 上面所有的方法最终都调用这个方法public SqlSessionFactory build(Configuration config);
}
如果一个类包含很多成员变量,而构建对象并不需要设置所有的成员变量,只需要选择性地设置其中几个就可以。为了满足这样的构建需求,就要定义多个包含不同参数列表的构造函数。为了避免构造函数过多、参数列表过长,一般通过无参构造函数加 setter 方法或者通过建造者模式来解决
从建造者模式的设计初衷上来看,SqlSessionFactoryBuilder 虽然带有 Builder 后缀,但不要被它的名字所迷惑,它并不是标准的建造者模式。一方面,原始类 SqlSessionFactory 的构建只需要一个参数,并不复杂。另一方面,Builder 类 SqlSessionFactoryBuilder 仍然定义了 n 多包含不同参数列表的构造函数
实际上,SqlSessionFactoryBuilder 设计的初衷只不过是为了简化开发。因为构建 SqlSessionFactory 需要先构建 Configuration,而构建 Configuration 是非常复杂的,需要做很多工作,比如配置的读取、解析、创建 n 多对象等。为了将构建 SqlSessionFactory 的过程隐藏起来,对程序员透明,MyBatis 就设计了SqlSessionFactoryBuilder 类封装这些构建细节
5.4.2 SqlSessionFactory:到底属于工厂模式还是建造器模式?
在上面那段 MyBatis 示例代码中,通过 SqlSessionFactoryBuilder 创建了 SqlSessionFactory,然后再通过 SqlSessionFactory 创建了 SqlSession。前面讲了SqlSessionFactoryBuilder,现在再来看下 SqlSessionFactory
从名字上可能已经猜到,SqlSessionFactory 是一个工厂类,用到的设计模式是工厂模式。不过,它跟 SqlSessionFactoryBuilder 类似,名字有很大的迷惑性。实际上,它也并不是标准的工厂模式。为什么这么说呢?先来看下 SqlSessionFactory 类的源码
public interface SqlSessionFactory {SqlSession openSession();SqlSession openSession(boolean autoCommit);SqlSession openSession(Connection connection);SqlSession openSession(TransactionIsolationLevel level);SqlSession openSession(ExecutorType execType);SqlSession openSession(ExecutorType execType, boolean autoCommit);SqlSession openSession(ExecutorType execType, TransactionIsolationLevel level);SqlSession openSession(ExecutorType execType, Connection connection);Configuration getConfiguration();
}
SqlSessionFactory 是一个接口,DefaultSqlSessionFactory 是它唯一的实现类。DefaultSqlSessionFactory 源码如下所示:
public class DefaultSqlSessionFactory implements SqlSessionFactory {private final Configuration configuration;public DefaultSqlSessionFactory(Configuration configuration) {this.configuration = configuration;}@Overridepublic SqlSession openSession() {return openSessionFromDataSource(configuration.getDefaultExecutorType(), null);}@Overridepublic SqlSession openSession(boolean autoCommit) {return openSessionFromDataSource(configuration.getDefaultExecutorType(), null);}@Overridepublic SqlSession openSession(ExecutorType execType) {return openSessionFromDataSource(execType, null, false);}@Overridepublic SqlSession openSession(TransactionIsolationLevel level) {return openSessionFromDataSource(configuration.getDefaultExecutorType(), level);}@Overridepublic SqlSession openSession(ExecutorType execType, TransactionIsolationLevel level) {return openSessionFromDataSource(execType, level, false);}@Overridepublic SqlSession openSession(ExecutorType execType, boolean autoCommit) {return openSessionFromDataSource(execType, null, autoCommit);}@Overridepublic SqlSession openSession(Connection connection) {return openSessionFromConnection(configuration.getDefaultExecutorType(), co}@Overridepublic SqlSession openSession(ExecutorType execType, Connection connection) {return openSessionFromConnection(execType, connection);}@Overridepublic Configuration getConfiguration() {return configuration;}private SqlSession openSessionFromDataSource(ExecutorType execType, TransactiTransaction tx = null;try {final Environment environment = configuration.getEnvironment();final TransactionFactory transactionFactory = getTransactionFactoryFromEntx = transactionFactory.newTransaction(environment.getDataSource(), levelfinal Executor executor = configuration.newExecutor(tx, execType);return new DefaultSqlSession(configuration, executor, autoCommit);} catch (Exception e) {closeTransaction(tx); // may have fetched a connection so lets call closethrow ExceptionFactory.wrapException("Error opening session. Cause: " +} finally {ErrorContext.instance().reset();}
}
private SqlSession openSessionFromConnection(ExecutorType execType, Connection connection) {try {boolean autoCommit;try {autoCommit = connection.getAutoCommit();} catch (SQLException e) {// Failover to true, as most poor drivers// or databases won't support transactionsautoCommit = true;}final Environment environment = configuration.getEnvironment();final TransactionFactory transactionFactory = getTransactionFactoryFromEnfinal Transaction tx = transactionFactory.newTransaction(connection);final Executor executor = configuration.newExecutor(tx, execType);return new DefaultSqlSession(configuration, executor, autoCommit);} catch (Exception e) {throw ExceptionFactory.wrapException("Error opening session. Cause: " +} finally {ErrorContext.instance().reset();}
}
//...省略部分代码...
从 SqlSessionFactory 和 DefaultSqlSessionFactory 的源码来看,它的设计非常类似刚刚讲到的 SqlSessionFactoryBuilder,通过重载多个 openSession() 函数,支持通过组合 autoCommit、Executor、Transaction 等不同参数,来创建 SqlSession 对象。标准的工厂模式通过 type 来创建继承同一个父类的不同子类对象,而这里只不过是通过传递进不同的参数,来创建同一个类的对象。所以,它更像建造者模式
虽然设计思路基本一致,但一个叫 xxxBuilder(SqlSessionFactoryBuilder),一个叫 xxxFactory(SqlSessionFactory)。而且,叫 xxxBuilder 的也并非标准的建造者模式,叫 xxxFactory 的也并非标准的工厂模式。所以,个人觉得,MyBatis 对这部分代码的设计还是值得优化的
实际上,这两个类的作用只不过是为了创建 SqlSession 对象,没有其他作用。所以,更建议参照 Spring 的设计思路,把 SqlSessionFactoryBuilder 和 SqlSessionFactory 的逻辑,放到一个叫“ApplicationContext”的类中。让这个类来全权负责读入配置文件,创建 Congfiguration,生成 SqlSession
5.4.3 BaseExecutor:模板模式跟普通的继承有什么区别?
如果去查阅 SqlSession 与 DefaultSqlSession 的源码,会发现,SqlSession 执行 SQL的业务逻辑,都是委托给了 Executor 来实现。Executor 相关的类主要是用来执行 SQL
其中,Executor 本身是一个接口;BaseExecutor 是一个抽象类,实现了 Executor 接口;而 BatchExecutor、SimpleExecutor、ReuseExecutor 三个类继承 BaseExecutor 抽象类
那 BatchExecutor、SimpleExecutor、ReuseExecutor 三个类跟 BaseExecutor 是简单的继承关系,还是模板模式关系呢?怎么来判断呢?看一下 BaseExecutor 的源码就清楚了
public abstract class BaseExecutor implements Executor {//...省略其他无关代码...@Overridepublic int update(MappedStatement ms, Object parameter) throws SQLException {ErrorContext.instance().resource(ms.getResource()).activity("executing an update");if (closed) {throw new ExecutorException("Executor was closed.");}clearLocalCache();return doUpdate(ms, parameter);}public List<BatchResult> flushStatements(boolean isRollBack) throws SQLException) {if (closed) {throw new ExecutorException("Executor was closed.");}return doFlushStatements(isRollBack);}private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBouds rowBounds) {List<E> list;localCache.putObject(key, EXECUTION_PLACEHOLDER);try {list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);} finally {localCache.removeObject(key);}localCache.putObject(key, list);if (ms.getStatementType() == StatementType.CALLABLE) {localOutputParameterCache.putObject(key, parameter);}return list;}@Overridepublic <E> Cursor<E> queryCursor(MappedStatement ms, Object parameter, RowBouds rowBounds) {BoundSql boundSql = ms.getBoundSql(parameter);return doQueryCursor(ms, parameter, rowBounds, boundSql);}protected abstract int doUpdate(MappedStatement ms, Object parameter);protected abstract List<BatchResult> doFlushStatements(boolean isRollback);protected abstract <E> List<E> doQuery(MappedStatement ms, Object parameter);protected abstract <E> Cursor<E> doQueryCursor(MappedStatement ms, Object parameter);
}
模板模式基于继承来实现代码复用。如果抽象类中包含模板方法,模板方法调用有待子类实现的抽象方法,那这一般就是模板模式的代码实现。而且,在命名上,模板方法与抽象方法一般是一一对应的,抽象方法在模板方法前面多一个“do”,比如,在 BaseExecutor 类中,其中一个模板方法叫 update(),那对应的抽象方法就叫 doUpdate()
5.4.4 SqlNode:如何利用解释器模式来解析动态 SQL?
持配置文件中编写动态 SQL,是 MyBatis 一个非常强大的功能。所谓动态 SQL,就是在 SQL 中可以包含在 trim、if、#{}等语法标签,在运行时根据条件来生成不同的 SQL,如下例:
<update id="update" parameterType="com.xzg.cd.a89.User" UPDATE="" user="">
<trim prefix="SET" prefixOverrides=","><if test="name != null and name != ''">name = #{name}</if><if test="age != null and age != ''">, age = #{age}</if><if test="birthday != null and birthday != ''">, birthday = #{birthday}</if>
</trim>where id = ${id}</update>
显然,动态 SQL 的语法规则是 MyBatis 自定义的。如果想要根据语法规则,替换掉动态 SQL 中的动态元素,生成真正可以执行的 SQL 语句,MyBatis 还需要实现对应的解释器
这一部分功能就可以看做是解释器模式的应用。解释器模式在解释语法规则的时候,一般会把规则分割成小的单元,特别是可以嵌套的小单元,针对每个小单元来解析,最终再把解析结果合并在一起。这里也不例外。MyBatis 把每个语法小单元叫 SqlNode。SqlNode 的定义如下所示:
public interface SqlNode {boolean apply(DynamicContext context);
}
对于不同的语法小单元,MyBatis 定义不同的 SqlNode 实现类
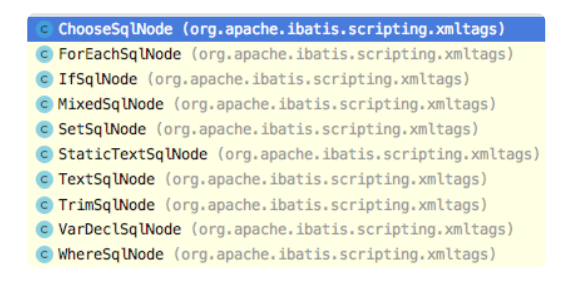
整个解释器的调用入口在 DynamicSqlSource.getBoundSql 方法中,它调用了 rootSqlNode.apply(context) 方法
5.4.5 ErrorContext:如何实现一个线程唯一的单例模式?
在单例模式那一部分讲到,单例模式是进程唯一的。同时还讲到单例模式的几种变形,比如线程唯一的单例、集群唯一的单例等。在 MyBatis 中,ErrorContext 这个类就是标准单例的变形:线程唯一的单例
代码实现如下,它基于 Java 中的 ThreadLocal 来实现,实际上,这里的 ThreadLocal 就相当于那里的 ConcurrentHashMap
public class ErrorContext {private static final String LINE_SEPARATOR = System.getProperty("line.separate");private static final ThreadLocal<ErrorContext> LOCAL = new ThreadLocal < ErrorContext> ();private ErrorContext stored;private String resource;private String activity;private String object;private String message;private String sql;private Throwable cause;private ErrorContext() {}public static ErrorContext instance() {ErrorContext context = LOCAL.get();if (context == null) {context = new ErrorContext();LOCAL.set(context);}return context;}
}
5.4.6 Cache:为什么要用装饰器模式而不设计成继承子类?
MyBatis 是一个 ORM 框架。实际上,它不只是简单地完成了对象和数据库数据之间的互相转化,还提供了很多其他功能,比如缓存、事务等。接下来,再讲讲它的缓存实现
在 MyBatis 中,缓存功能由接口 Cache 定义。PerpetualCache 类是最基础的缓存类,是一个大小无限的缓存。除此之外,MyBatis 还设计了 9 个包裹 PerpetualCache 类的装饰器类,用来实现功能增强。它们分别是:FifoCache、LoggingCache、LruCache、ScheduledCache、SerializedCache、SoftCache、SynchronizedCache、WeakCache、TransactionalCache
public interface Cache {String getId();void putObject(Object key, Object value);Object getObject(Object key);Object removeObject(Object key);void clear();int getSize();ReadWriteLock getReadWriteLock();
}
public class PerpetualCache implements Cache {private final String id;private Map<Object, Object> cache = new HashMap<Object, Object>();public PerpetualCache(String id) {this.id = id;}@Overridepublic String getId() {return id;}@Overridepublic int getSize() {return cache.size();}@Overridepublic void putObject(Object key, Object value) {cache.put(key, value);}@Overridepublic Object getObject(Object key) {return cache.get(key);}@Overridepublic Object removeObject(Object key) {return cache.remove(key);}@Overridepublic void clear() {cache.clear();}@Overridepublic ReadWriteLock getReadWriteLock() {return null;}//省略部分代码...
}
这 9 个装饰器类的代码结构都类似,这里只将其中的 LruCache 的源码贴到这里。从代码中可以看出,它是标准的装饰器模式的代码实现
public class LruCache implements Cache {private final Cache delegate;private Map<Object, Object> keyMap;private Object eldestKey;public LruCache(Cache delegate) {this.delegate = delegate;setSize(1024);}@Overridepublic String getId() {return delegate.getId();}@Overridepublic int getSize() {return delegate.getSize();}public void setSize(final int size) {keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {private static final long serialVersionUID = 4267176411845948333L;@Overrideprotected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {boolean tooBig = size() > size;if (tooBig) {eldestKey = eldest.getKey();}return tooBig;}};}@Overridepublic void putObject(Object key, Object value) {delegate.putObject(key, value);cycleKeyList(key);}@Overridepublic Object getObject(Object key) {keyMap.get(key); //touchreturn delegate.getObject(key);}@Overridepublic Object removeObject(Object key) {return delegate.removeObject(key);}@Overridepublic void clear() {delegate.clear();keyMap.clear();}@Overridepublic ReadWriteLock getReadWriteLock() {return null;}private void cycleKeyList(Object key) {keyMap.put(key, key);if (eldestKey != null) {delegate.removeObject(eldestKey);eldestKey = null;}}
}
之所以 MyBatis 采用装饰器模式来实现缓存功能,是因为装饰器模式采用了组合,而非继承,更加灵活,能够有效地避免继承关系的组合爆炸
5.4.7 PropertyTokenizer:如何利用迭代器模式实现一个属性解析器?
迭代器模式常用来替代 for 循环遍历集合元素。Mybatis 的 PropertyTokenizer 类实现了 Java Iterator 接口,是一个迭代器,用来对配置属性进行解析。具体的代码如下所示:
// person[0].birthdate.year 会被分解为3个PropertyTokenizer对象。其中,第一个Property
public class PropertyTokenizer implements Iterator<PropertyTokenizer> {private String name; // personprivate final String indexedName; // person[0]private String index; // 0private final String children; // birthdate.yearpublic PropertyTokenizer(String fullname) {int delim = fullname.indexOf('.');if (delim > -1) {name = fullname.substring(0, delim);children = fullname.substring(delim + 1);} else {name = fullname;children = null;}indexedName = name;delim = name.indexOf('[');if (delim > -1) {index = name.substring(delim + 1, name.length() - 1);name = name.substring(0, delim);}}public String getName() {return name;}public String getIndex() {return index;}public String getIndexedName() {return indexedName;}public String getChildren() {return children;}@Overridepublic boolean hasNext() {return children != null;}@Overridepublic PropertyTokenizer next() {return new PropertyTokenizer(children);}@Overridepublic void remove() {throw new UnsupportedOperationException("Remove is not supported, as it has");}
}
实际上,PropertyTokenizer 类也并非标准的迭代器类。它将配置的解析、解析之后的元素、迭代器,这三部分本该放到三个类中的代码,都耦合在一个类中,所以看起来稍微有点难懂。不过,这样做的好处是能够做到惰性解析。不需要事先将整个配置,解析成多个 PropertyTokenizer 对象。只有当在调用 next() 函数的时候,才会解析其中部分配置
5.4.8 Log:如何使用适配器模式来适配不同的日志框架?
在讲适配器模式的时候讲过,Slf4j 框架为了统一各个不同的日志框架(Log4j、JCL、Logback 等),提供了一套统一的日志接口。不过,MyBatis 并没有直接使用 Slf4j 提供的统一日志规范,而是自己又重复造轮子,定义了一套自己的日志访问接口
public interface Log {boolean isDebugEnabled();boolean isTraceEnabled();void error(String s, Throwable e);void error(String s);void debug(String s);void trace(String s);void warn(String s);
}
针对 Log 接口,MyBatis 还提供了各种不同的实现类,分别使用不同的日志框架来实现 Log 接口
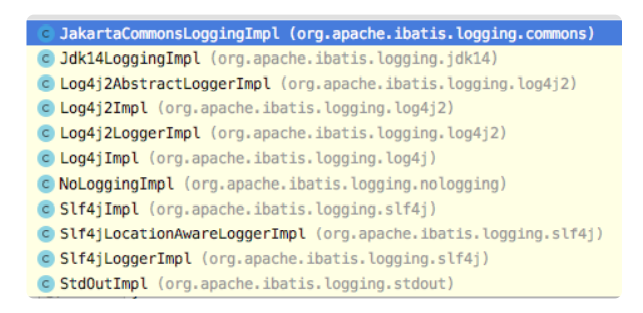
这几个实现类的代码结构基本上一致。其中的 Log4jImpl 的源码如下。在适配器模式中,传递给适配器构造函数的是被适配的类对象,而这里是 clazz(相当于日志名称 name),所以,从代码实现上来讲,它并非标准的适配器模式。但是,从应用场景上来看,这里确实又起到了适配的作用,是典型的适配器模式的应用场景
import org.apache.ibatis.logging.Log;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
public class Log4jImpl implements Log {private static final String FQCN = Log4jImpl.class.getName();private final Logger log;public Log4jImpl(String clazz) {log = Logger.getLogger(clazz);}@Overridepublic boolean isDebugEnabled() {return log.isDebugEnabled();}@Overridepublic boolean isTraceEnabled() {return log.isTraceEnabled();}@Overridepublic void error(String s, Throwable e) {log.log(FQCN, Level.ERROR, s, e);}@Overridepublic void error(String s) {log.log(FQCN, Level.ERROR, s, null);}@Overridepublic void debug(String s) {log.log(FQCN, Level.DEBUG, s, null);}@Overridepublic void trace(String s) {log.log(FQCN, Level.TRACE, s, null);}@Overridepublic void warn(String s) {log.log(FQCN, Level.WARN, s, null);}
}
相关文章:
设计模式之美总结(开源实战篇)
title: 设计模式之美总结(开源实战篇) date: 2023-01-10 17:13:05 tags: 设计模式 categories:设计模式 cover: https://cover.png feature: false 文章目录1. Java JDK 应用到的设计模式1.1 工厂模式在 Calendar 类中的应用1.2 建造者模式在 Calendar …...

两个月,测试转岗产品经理,我是怎么规划的?
本期同学依旧来自深圳 测试到产品转变,用了两个月 本周,为大家介绍M同学的佛系转岗经历 学员档 学员档案 原岗位:测试 转岗级别:中级产品经理 转岗特点: 1.未接触产品工作 2.对岗位地点要求严格 先看结果 …...
三数之和-力扣15-java排序+双指针
一、题目描述给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请你返回所有和为 0 且不重复的三元组。注意:答案中不可以包含重复的三元组。…...
【编程基础之Python】3、创建Python虚拟环境
【编程基础之Python】3、创建Python虚拟环境创建Python虚拟环境为什么需要虚拟环境Windows上的Anaconda创建虚拟环境conda 命令conda env 命令创建虚拟环境切换虚拟环境验证虚拟环境Linux上的Anaconda创建虚拟环境创建虚拟环境切换虚拟环境验证虚拟环境总结创建Python虚拟环境 …...
kettle开发-Day36-循环驱动作业
前言:在日常数据处理时,我们通过变量传参来完成某个日期的数据转换。但可能因程序或者网络原因导致某个时间段的数据抽取失败。常见导致kettle作业失败的原因大概分为三大类,数据源异常、数据库异常、程序异常。因此面对这些异常时࿰…...

2023秋招 新凯来 算法工程师 面经分享
本专栏分享 计算机小伙伴秋招春招找工作的面试经验和面试的详情知识点 专栏首页:秋招算法类面经分享 主要分享计算机算法类在面试互联网公司时候一些真实的经验 一面 技术面 30分钟左右 1.主要是问项目和论文上的东西,问的不深,中间还介绍他们是做缺陷检测的,大概问了16分钟…...

Web3CN|Damus刷频背后,大众在期待什么样的去中心化社交?
刚过去的一周,许多人的朋友圈包括Twitter、Faceboo在内都在被一串公钥字母刷屏,其重要起因就是 Twitter 前首席执行官 Jack Dorsey 发推称,(2月1日)基于去中心化社交协议 Nostr 的社交产品 Damus 和 Amethyst 已分别在…...

Jenkins自动发布到WindowsServer,在WindowsServer执行的命令
echo off set apppoolname"6.usegitee" set websitename"6.usegitee" set webfolder"usegitee" echo 停止站点的应用程序池 C:\Windows\System32\inetsrv\appcmd.exe stop apppool %apppoolname% echo 停止站点 c:\Windows\System32\inetsrv\a…...
【Git学习】Git如何Clone带有Submodule的仓库?
文章目录一、问题描述二、解决问题三、参考链接四、解决问题4.1 下载主模块4.2 查看主模块的配置4.2 子模块的添加4.3 查看子模块的配置4.4 查看子模块的检出状态4.5 检出submodule4.6 再次查看.git/config4.7 重新打开Android Studio运行代码一、问题描述 在GitHub上下载了一…...

C语言进阶——通讯录模拟实现
🌇个人主页:_麦麦_ 📚今日名言:只有走在路上,才能摆脱局限,摆脱执着,让所有的选择,探寻,猜测,想象都生机勃勃。——余秋雨《文化苦旅》 目录 一、前言 二、正…...

【C#基础】C# 变量和常量的使用
序号系列文章1【C#基础】C# 程序通用结构总结2【C#基础】C# 程序基础语法解析3【C#基础】C# 数据类型总结文章目录前言一. 变量(variable)1,变量定义及初始化2,变量的类别3,接收输出变量二. 常量(constant&…...
nvm安装后出现‘node‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件
出现这个问题多半是path地址不对。 打开系统环境变量。看看path里面有没有?没有的话,加上就行! 我的报错原因就是因为path里没有自动加上nvm的相关路径。 注意项: 1,在安装nvm之前,提前要把本机以前安装…...

张驰咨询:关于六西格玛,有一些常见的疑惑!
很多想要学习六西格玛的学员,经常会有这些困惑: 以前没有接触过六西格玛,需要什么基础吗?自学还是培训?哪些行业会用到六西格玛呢?学习六西格玛对以后的工作有哪些帮助?如何选择六西格玛培…...
【Vercel】教你部署imsyy/home个人主页
本篇博客教你如何部署一个自己的个人主页 项目地址:https://github.com/imsyy/home 本文首发于 慕雪的寒舍 1.fork仓库vercel部署 首先我们点击fork,将仓库复刻到自己的账户 随后进入vercel,点击dashboard-add new-project 选择你复刻的仓库…...
GeekChallenge
2.GeekChallenge 1.web 1.朋友的学妹 url:http://49.234.224.119:7413/ 右键点击查看源码,找到flagU1lDe0YxQF80c19oNExwZnVsbGxsbGx9 然后base64解码得到SYC{F1_4s_h4Lpfullllll} 2.EZwww url:http://47.100.46.169:3901/ 根据网站提示…...

Java文件IO
文章目录Java中的文件操作File常用构造方法方法文件内容的读写——数据流InputStreamFileInputStream利用Scanner进行字符读取OutputStreamPrintWriter按字符读取文件(FileReader)练习代码实例如何按字节进行数据读如何按字节进行数据写如何按字符进行数据读如何按字符进行数据…...
)
useSSL使用安全套接字协议(史上最全最详细)
useSSL使用安全套接字协议(史上最全最详细) SSL即为:Secure Sockets Layer 安全套接字协议。 useSSLfalse和useSSLtrue的区别: 在MySQL进行连接时: 如果MySQL的版本是5.7之后的版本必须要加上useSSLfalse,…...
)
面向对象复习(2)
面向对象(2) 对象与引用 java语言中除基本类型之外的变量都称之为引用类型 java中的对象时通过引用对其操作的 Car bm new Car(); 右边的new Car是以Car类为模板,调用无参构造函数,在堆空间中创建一个Car对象 左边的Car bm 在栈中创建了一个Car类型的引用变量,所谓Car的…...

python中使用numpy包的向量矩阵相乘
一直对np的线性运算不太清晰,正好上课讲到了,做一个笔记整个理解一下 1.向量和矩阵 在numpy中,一重方括号表示的是向量vector,vector没有行列的概念。二重方括号表示矩阵matrix,有行列。 代码显示如下: …...
)
ElasticSearch 学习(一)
目录一、Elasticsearch 简介二、Elasticsearch 发展史三、Elasticsearch 功能四、Elasticsearch 特点五、Elasticsearch 应用场景一、Elasticsearch 简介 Elasticsearch 是一个实时的分布式搜索分析引擎,它能让你以前所未有的速度和规模,去探索你的数据…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

安宝特方案丨XRSOP人员作业标准化管理平台:AR智慧点检验收套件
在选煤厂、化工厂、钢铁厂等过程生产型企业,其生产设备的运行效率和非计划停机对工业制造效益有较大影响。 随着企业自动化和智能化建设的推进,需提前预防假检、错检、漏检,推动智慧生产运维系统数据的流动和现场赋能应用。同时,…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

学习一下用鸿蒙DevEco Studio HarmonyOS5实现百度地图
在鸿蒙(HarmonyOS5)中集成百度地图,可以通过以下步骤和技术方案实现。结合鸿蒙的分布式能力和百度地图的API,可以构建跨设备的定位、导航和地图展示功能。 1. 鸿蒙环境准备 开发工具:下载安装 De…...