SpringBoot 集成 Sharding-JDBC(一):数据分片
在深入探讨 Sharding-JDBC 之前,建议读者先了解数据库分库分表的基本概念和应用场景。如果您还没有阅读过相关的内容,可以先阅读我们之前的文章:
关系型数据库海量数据存储策略-CSDN博客
这篇文章将帮助您更好地理解分库分表的基本原理和实现方法。
1. Sharding-JDBC 介绍
1.1. 背景
Sharding-JDBC 最初是由当当网内部开发的一款分库分表框架,于2017年开始对外开源。经过社区贡献者的不断迭代,功能逐渐完善,并于2020年4月16日正式成为 Apache 软件基金会的顶级项目,更名为 ShardingSphere。
Sharding-Sphere官网:Apache ShardingSphere
Sharding-Sphere官方文档:Overview :: ShardingSphere
Sharding-Sphere中文文档:概览 :: ShardingSphere
Sharding-Sphere中文文档2:概览 :: ShardingSphere
1.2. 生态圈
现在的 ShardingSphere 不再仅仅指某个框架,而是一个完整的生态圈,包括以下三个主要组件:
- Sharding-JDBC: 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供额外服务。
- Sharding-Proxy: 提供数据库代理服务,支持多种数据库协议。
- Sharding-Sidecar: 以容器化方式部署,支持 Kubernetes 环境。

1.3. Sharding-Sphere 与 MyCat 的区别
| Mycat | Sharding-JDBC | Sharding-Proxy | Sharding-Sidecar | |
|---|---|---|---|---|
| 官方网站 | 官方网站 | 官方网站 | 官方网站 | 官方网站 |
| 源码地址 | GitHub | GitHub | GitHub | GitHub |
| 官方文档 | Mycat 权威指南 | 官方文档 | 官方文档 | 官方文档 |
| 开发语言 | Java | Java | Java | Java |
| 开源协议 | GPL-2.0/GPL-3.0 | Apache-2.0 | Apache-2.0 | Apache-2.0 |
| 数据库 | MySQL | MySQL | MySQL/PostgreSQL | MySQL/PostgreSQL |
| 连接数 | 低 | 高 | 低 | 高 |
| 应用语言 | 任意 | Java | 任意 | 任意 |
| 代码入侵 | 无 | 需要修改代码 | 无 | 无 |
| 性能 | 损耗略高 | 损耗低 | 损耗略高 | 损耗低 |
| 无中心化 | 否 | 是 | 否 | 是 |
| 静态入口 | 有 | 无 | 有 | 无 |
| 管理控制台 | Mycat-web | Sharding-UI | Sharding-UI | Sharding-UI |
| 分库分表 | 单库多表/多库单表 | ✔️ | ✔️ | ✔️ |
| 多租户方案 | ✔️ | -- | -- | -- |
| 读写分离 | ✔️ | ✔️ | ✔️ | ✔️ |
| 分片策略定制化 | ✔️ | ✔️ | ✔️ | ✔️ |
| 分布式主键 | ✔️ | ✔️ | ✔️ | ✔️ |
| 标准化事务接口 | ✔️ | ✔️ | ✔️ | ✔️ |
| XA强一致事务 | ✔️ | ✔️ | ✔️ | ✔️ |
| 柔性事务 | -- | ✔️ | ✔️ | ✔️ |
| 配置动态化 | 开发中 | ✔️ | ✔️ | ✔️ |
| 编排治理 | 开发中 | ✔️ | ✔️ | ✔️ |
| 数据脱敏 | -- | ✔️ | ✔️ | ✔️ |
| 可视化链路追踪 | -- | ✔️ | ✔️ | ✔️ |
| 弹性伸缩 | 开发中 | 开发中 | 开发中 | 开发中 |
| 多节点操作 | 分页 | 分页 | 分页 | 分页 |
| 跨库关联 | 跨库 2 表 Join | -- | -- | -- |
| IP 白名单 | ✔️ | -- | -- | -- |
| SQL 黑名单 | ✔️ | -- | -- | -- |
1.4. Sharding-JDBC 特点
- 轻量级框架: 在 Java 的 JDBC 层提供额外服务,使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖。
- 兼容性强: 完全兼容 JDBC 和各种 ORM 框架,如 JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
- 支持多种数据库连接池: 如 DBCP, C3P0, BoneCP, Druid, HikariCP 等。
- 广泛支持数据库: 支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。

1.5. Sharding-JDBC优点
1. 透明性:
- Sharding-JDBC 作为 JDBC 驱动的增强,对应用程序来说是透明的,无需修改业务代码即可实现数据库分片。
- 配置简单,通过配置文件或注解方式,可以方便地进行分片规则的配置。
2. 高性能:
- Sharding-JDBC 是基于 Java 的字节码增强技术,性能损耗较小,能够高效地处理高并发请求。
- 支持并行执行多个分片上的查询,提高查询效率。
3. 功能丰富:支持读写分离、分布式事务、数据加密。
1.6. Sharding-JDBC缺点
1. 功能限制
- 跨库操作存在限制,性能和效率可能受影响。
- 不支持所有复杂的 SQL 语句,需要手动优化或改写。
2. 维护成本
- 分片后的数据库管理和维护复杂,需要更多运维工作。
- 故障恢复面临更大挑战,需要完善的备份和恢复机制。
3. 复杂性
- 虽然配置相对简单,但对于复杂的分片规则和多表关联查询,配置和管理可能会变得复杂。
- 对于初学者来说,理解和掌握 Sharding-JDBC 的全部功能和配置可能需要一定的时间。
2. 数据分片
2.1. 核心概念
- 逻辑表:水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
-
真实表:在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
-
数据节点:数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。
-
绑定表:指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果SQL为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);在不配置绑定表关系时,假设分片键order_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);其中t_order在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order的条件。故绑定表之间的分区键要完全相同。
- 广播表:指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
2.2. Sharding-JDBC 数据分片执行原理

2.2.1. SQL解析

1. 解析规则(Parsing Rules)
- 作用:定义如何将 SQL 语句解析成抽象语法树(AST)。
- 实现:
- 词法分析:将 SQL 语句分解成一个个的词法单元(Token)。
- 语法分析:将词法单元组合成抽象语法树(AST)。
- 示例:对于 SQL 语句 SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18;,解析规则会生成如下的 AST:

为了便于理解,抽象语法树中的关键字的Token用绿色表示,变量的Token用红色表示,灰色表示需要进一步拆分。
2. 提取规则(Extraction Rules)
- 作用:从解析生成的 AST 中提取关键信息,如表名、列名、条件等。
- 实现:
- 遍历 AST:通过递归或迭代的方式遍历 AST,提取所需的信息。
- 信息提取:提取表名、列名、条件表达式等。
- 示例:对于 SQL 语句 SELECT * FROM table WHERE id = 1;,提取规则会提取以下信息:
- 表名:table
- 条件:id = 1
3. 填充规则(Filling Rules)
- 作用:根据提取的关键信息和分片规则,填充路由信息。
- 实现:
- 分片键提取:从提取的信息中找到分片键。
- 路由计算:根据分片规则计算出目标数据源和表。
- 示例:假设分片规则是按 user_id 的奇偶性分片,对于 SQL 语句 SELECT * FROM order WHERE user_id = 1001;,填充规则会计算出目标表为 order_1。
4. 优化规则(Optimization Rules)
- 作用:对解析和填充后的 SQL 语句进行优化,提高执行效率。
- 实现:
- 子查询优化:将复杂的子查询转换为更高效的查询。
- 索引优化:根据索引信息优化查询计划
- 并行执行:将可以并行执行的查询拆分成多个子查询,提高执行速度。
- 示例:对于 SQL 语句 SELECT * FROM order WHERE user_id IN (1001, 1002, 1003);,优化规则可能会将其拆分成多个子查询:
SELECT * FROM order_1 WHERE user_id = 1001;SELECT * FROM order_0 WHERE user_id = 1002;SELECT * FROM order_1 WHERE user_id = 1003;2.2.2. SQL路由
根据解析上下文匹配数据库和表的分片策略,并生成路由路径。 对于携带分片键的SQL,根据分片键的不同可以划分为单片路由(分片键的操作符是等号)、多片路由(分片键的操作符是IN)和范围路由(分片键的操作符是BETWEEN)。 不携带分片键的SQL则采用广播路由。路由引擎的整体结构划分如下图。

2.2.2.1. 分片路由
分片路由根据分片键进行路由,将 SQL 请求路由到特定的数据库和表中。根据分片键的不同操作符,分片路由可以进一步划分为以下几种类型:
1. 直接路由:
- 条件:通过 Hint API 直接指定路由至库表,且只分库不分表。
- 特点:避免 SQL 解析和结果归并,兼容性强,支持复杂 SQL。
2. 标准路由:
- 条件:不包含关联查询或仅包含绑定表之间的关联查询。
- 特点:分片键操作符为等号时路由到单库(表),操作符为 BETWEEN 或 IN 时可能路由到多库(表)。
- 示例:
SELECT * FROM t_order WHERE order_id IN (1, 2);路由结果:
SELECT * FROM t_order_0 WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 WHERE order_id IN (1, 2);3. 笛卡尔路由:
条件:非绑定表之间的关联查询。
特点:无法根据绑定表关系定位分片规则,需要拆解为笛卡尔积组合执行,性能较低。
示例:
SELECT * FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE order_id IN (1, 2);路由结果:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2); 2.2.2.2. 广播路由
广播路由将 SQL 请求路由到所有配置的数据源或表中,适用于不携带分片键的 SQL。根据 SQL 类型,广播路由可以进一步划分为以下几种类型:
1. 全库表路由:
- 条件:处理对数据库中与其逻辑表相关的所有真实表的操作,如不带分片键的 DQL 和 DML,以及 DDL。
- 示例:
SELECT * FROM t_order WHERE good_prority IN (1, 10);路由结果:
SELECT * FROM t_order_0 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_1 WHERE good_prority IN (1, 10);2. 全库路由:
- 条件:处理对数据库的操作,如 SET 类型的数据库管理命令和 TCL 事务控制语句。
- 示例:
SET autocommit=0;路由结果:
SET autocommit=0; -- 在 t_order_0 上执行
SET autocommit=0; -- 在 t_order_1 上执行3. 全实例路由:
- 条件:处理 DCL 操作,如授权语句。
- 示例:
CREATE USER customer@127.0.0.1 identified BY '123';路由结果:
CREATE USER customer@127.0.0.1 identified BY '123'; -- 在所有实例上执行4. 单播路由:
- 条件:获取某一真实表信息的场景,仅需要从任意库中的任意真实表中获取数据。
- 示例:
DESCRIBE t_order;路由结果:
DESCRIBE t_order_0; -- 任意选择一个真实表执行5. 阻断路由:
- 条件:屏蔽 SQL 对数据库的操作,如 USE 命令。
- 示例:
USE order_db;路由结果:
-- 不执行该命令2.2.3. SQL改写
SQL 改写是将面向逻辑库与逻辑表编写的 SQL 转换为在真实数据库中可执行的 SQL。它主要包括正确性改写和优化改写两部分。

2.2.3.1. 正确性改写
将面向逻辑库与逻辑表编写的 SQL 转换为在真实数据库中可以正确执行的 SQL。
| 场景 | 逻辑 SQL | 改写后的 SQL |
| 简单场景 | SELECT order_id FROM t_order WHERE order_id=1; | SELECT order_id FROM t_order_1 WHERE order_id=1; |
| 复杂场景 | SELECT order_id FROM t_order WHERE order_id=1 AND remarks=' t_order xxx'; | SELECT order_id FROM t_order_1 WHERE order_id=1 AND remarks=' t_order xxx'; |
| 表名作为字段标识符 | SELECT t_order.order_id FROM t_order WHERE t_order.order_id=1 AND remarks=' t_order xxx'; | SELECT t_order_1.order_id FROM t_order_1 WHERE t_order_1.order_id=1 AND remarks=' t_order xxx'; |
| 表别名 | SELECT t_order.order_id FROM t_order AS t_order WHERE t_order.order_id=1 AND remarks=' t_order xxx'; | SELECT t_order.order_id FROM t_order_1 AS t_order WHERE t_order.order_id=1 AND remarks=' t_order xxx'; |
2.2.3.1.1. 标识符改写
| 标识符 | 描述 |
| 表名称 | 将逻辑表名称改写为真实表名称。 |
| 索引 名称 | 在某些数据库中,索引以表为维度创建,可以重名;在另一些数据库中,索引以数据库为维度创建,要求名称唯一。 |
| Schema 名称 | 将逻辑 Schema 替换为真实 Schema。 |
2.2.3.1.2. 补列
| 场景 | 逻辑 SQL | 改写后的 SQL |
| GROUP BY 和 ORDER BY | SELECT order_id FROM t_order ORDER BY user_id; | SELECT order_id, user_id AS ORDER_BY_DERIVED_0 FROM t_order ORDER BY user_id; |
| 复杂场景 | SELECT o.* FROM t_order o, t_order_item i WHERE o.order_id=i.order_id ORDER BY user_id, order_item_id; | SELECT o.*, order_item_id AS ORDER_BY_DERIVED_0 FROM t_order o, t_order_item i WHERE o.order_id=i.order_id ORDER BY user_id, order_item_id; |
| AVG 聚合函数 | SELECT AVG(price) FROM t_order WHERE user_id=1; | SELECT COUNT(price) AS AVG_DERIVED_COUNT_0, SUM(price) AS AVG_DERIVED_SUM_0 FROM t_order WHERE user_id=1; |
| 自增主键 | INSERT INTO t_order (field1,field2) VALUES (10, 1); | INSERT INTO t_order (field1,field2, order_id) VALUES (10, 1, xxxxx); |
2.2.3.1.3. 分页修正
| 场景 | 逻辑 SQL | 改写后的 SQL |
| 分页查询 | SELECT score FROM t_score ORDER BY score DESC LIMIT 1, 2; | SELECT score FROM t_score_0 ORDER BY score DESC LIMIT 0, 3; SELECT score FROM t_score_1 ORDER BY score DESC LIMIT 0, 3; |
2.2.3.1.4. 批量拆分
| 场景 | 逻辑 SQL | 改写后的 SQL(order_id 按奇偶分片) |
| 批量插入 | INSERT INTO t_order (order_id, xxx) VALUES (1, 'xxx'), (2, 'xxx'), (3, 'xxx'); | INSERT INTO t_order_0 (order_id, xxx) VALUES (2, 'xxx'); INSERT INTO t_order_1 (order_id, xxx) VALUES (1, 'xxx'), (3, 'xxx'); |
| IN 查询 | SELECT * FROM t_order WHERE order_id IN (1, 2, 3); | SELECT * FROM t_order_0 WHERE order_id IN (2); SELECT * FROM t_order_1 WHERE order_id IN (1, 3); |
2.2.3.2. 优化改写
| 类型 | 描述 |
| 单节点优化 | 如果 SQL 路由到单个节点,无需进行额外的改写,以减少不必要的开销。 |
| 流式归并优化 | 为包含 GROUP BY 的 SQL 增加 ORDER BY 以实现流式归并,提高性能。 |
2.2.4. SQL执行

2.2.4.1. 连接模式
ShardingSphere 提出了两种连接模式:内存限制模式(MEMORY_STRICTLY) 和 连接限制模式(CONNECTION_STRICTLY)。
1. 内存限制模式(MEMORY_STRICTLY)
- 特点:不对数据库连接数量做限制。
- 适用场景:适合 OLAP 操作,通过多线程并发处理多个表的查询,提升执行效率。
- 优点:最大化执行效率,优先选择流式归并,节省内存。
- 缺点:可能占用大量数据库连接资源。
2. 连接限制模式(CONNECTION_STRICTLY)
- 特点:严格控制数据库连接数量。
- 适用场景:适合 OLTP 操作,通常带有分片键,路由到单一的分片。
- 优点:防止过多占用数据库连接资源,保证在线系统数据库资源的充分利用。
- 缺点:可能牺牲一定的执行效率,采用内存归并。
2.2.4.2. 自动化执行引擎
ShardingSphere 的自动化执行引擎在内部消化了连接模式的概念,用户无需手动选择模式,执行引擎会根据当前场景自动选择最优的执行方案。
1. 准备阶段
- 结果集分组:根据 maxConnectionSizePerQuery 配置项,将 SQL 的路由结果按数据源名称分组。
- 连接模式计算:
- 计算每个数据库实例在 maxConnectionSizePerQuery 允许范围内,每个连接需要执行的 SQL 路由结果组。
- 如果一个连接需要执行的请求数量大于1,采用内存归并;否则,采用流式归并。

- 执行单元创建:创建执行单元时,以原子性方式一次性获取所需的所有数据库连接,避免死锁
2. 执行阶段
- 分组执行:将准备阶段生成的执行单元分组下发至底层并发执行引擎,并发送执行事件。
- 归并结果集生成:根据连接模式生成内存归并结果集或流式归并结果集,并传递至结果归并引擎。
2.2.4.3. 关键优化
- 避免锁定:对于只需要获取1个数据库连接的操作,不进行锁定,提升并发效率。
- 资源锁定:仅在内存限制模式下进行资源锁定,连接限制模式下不会产生死锁。
2.2.5. 结果归并

ShardingSphere 支持的结果归并类型从功能上分为五种:遍历、排序、分组、分页和聚合。从结构上划分,可分为流式归并、内存归并和装饰者归并。
2.2.5.1. 结构划分
1. 流式归并
- 特点:逐条获取数据,减少内存消耗。
- 适用场景:适用于大多数查询,尤其是大数据量的查询。
- 类型:遍历归并、排序归并、流式分组归并。
2. 内存归并
- 特点:将所有数据加载到内存中进行处理。
- 适用场景:适用于分组项与排序项不一致的查询。
- 类型:内存分组归并。
3. 装饰者归并
- 特点:在流式归并和内存归并的基础上进行功能增强。
- 类型:分页归并、聚合归并。
2.2.5.2. 功能划分
1. 遍历归并
- 特点:最简单的归并方式,将多个数据结果集合并为一个单向链表。
- 实现:遍历完当前数据结果集后,链表元素后移一位,继续遍历下一个数据结果集。
2. 排序归并
- 特点:适用于包含 ORDER BY 语句的查询。
- 实现:使用优先级队列对多个有序结果集进行归并排序。
- 示例:
- 假设有3个数据结果集,每个结果集已经根据分数排序。
- 使用优先级队列将每个结果集的当前数据值进行排序。
- 每次 next 调用时,弹出队列首位的数据值,并将游标下移一位,重新加入队列。


3. 分组归并
- 特点:分为流式分组归并和内存分组归并。
- 流式分组归并:
- 适用场景:分组项与排序项一致。
- 实现:一次将多个数据结果集中分组项相同的数据全数取出,并进行聚合计算。
- 内存分组归并:
- 适用场景:分组项与排序项不一致。
- 实现:将所有数据加载到内存中进行分组和聚合。


4. 聚合归并
- 特点:处理聚合函数,如 MAX、MIN、SUM、COUNT 和 AVG。
- 实现:
- 比较类型:MAX 和 MIN,直接返回最大或最小值。
- 累加类型:SUM 和 COUNT,将同组的数据进行累加。
- 求平均值:AVG,通过 SUM 和 COUNT 计算。
5. 分页归并
- 特点:在其他归并类型基础上追加分页功能。
- 实现:通过 LIMIT 语句进行分页,但不会将大量无意义的数据加载到内存中。
- 示例:
- 使用 ID 进行分页,例如:SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id;
- 记录上次查询结果的最后一条记录的 ID 进行下一页查询,例如:SELECT * FROM t_order WHERE id > 10000000 LIMIT 10;
2.3. 使用步骤
2.3.1. 引入依赖
在 pom.xml 文件中添加 Sharding-JDBC 的依赖:
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.1.1</version>
</dependency>2.3.2. 添加配置文件
注意:
- 多个数据源的数据库连接池可以不同。
- 多个数据源的数据库驱动类型必须相同。
2.3.2.1. 精确分片
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
1. 编写yaml文件
spring:main:allow-bean-definition-overriding: trueshardingsphere:datasource: # 数据源配置,可配置多个data_source_namenames: ds0,ds1ds0: # <!!数据库连接池实现类> `!!`表示实例化该类type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名url: jdbc:mysql://localhost:3306/database1?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false # 数据库url连接,如果是HikariCP连接池,需要换成jdbcurlusername: root # 数据库用户名password: root # 数据库密码ds1: # <!!数据库连接池实现类> `!!`表示实例化该类type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名url: jdbc:mysql://localhost:3306/database2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false # 数据库url连接,如果是HikariCP连接池,需要换成jdbcurlusername: root # 数据库用户名password: root # 数据库密码sharding:# 唯一库数据default-data-source-name: ds0# 分库default-database-strategy:standard: # 用于单分片键的标准分片场景# 添加数据分库字段(根据字段插入数据到那个表)sharding-column: id# 精确分片precise-algorithm-class-name: ${common.algorithm.db}# 分表tables:t_user:actual-data-nodes: ds$->{0..1}.t_user_$->{1..2} #由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况key-generator:column: id # 自增列名称,缺省表示不使用自增主键生成器type: SNOWFLAKE #自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID# props: #属性配置, 注意:使用SNOWFLAKE算法,需要配置worker.id与max.tolerate.time.difference.milliseconds属性。若使用此算法生成值作分片值,建议配置max.vibration.offset属性table-strategy: # 分表策略,同分库策略standard: # 用于单分片键的标准分片场景# 分片列名称sharding-column: id# 精确分片算法类名称,用于=和IN。该类需实现PreciseShardingAlgorithm接口并提供无参数的构造器precise-algorithm-class-name: ${common.algorithm.tb}props: # 属性配置sql:show: true #是否开启SQL显示,默认值: false# executor.size: #工作线程数量,默认值: CPU核数# max.connections.size.per.query: # 每个查询可以打开的最大连接数量,默认为1# check.table.metadata.enabled: #是否在启动时检查分表元数据一致性,默认值: false# 配置分片策略
common:algorithm:db: com.zjp.shadingjdbcdemo.strategy.database.DatabasePreciseAlgorithmtb: com.zjp.shadingjdbcdemo.strategy.table.TablePreciseAlgorithm
2. 添加分库规则
实现 PreciseShardingAlgorithm 接口,重写 doSharding 方法。
package com.zjp.shadingjdbcdemo.strategy.database;import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;import java.util.Collection;public class DatabasePreciseAlgorithm implements PreciseShardingAlgorithm<Long> {/*** 精确分片** @param collection 数据源集合* @param preciseShardingValue 分片参数* @return 数据库*/@Overridepublic String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {// 自定义分片方法// 1.获取分片键的值Long value = preciseShardingValue.getValue();// 2.获取逻辑表名String logicTableName = preciseShardingValue.getLogicTableName();// 3.获取数据库名称,并排序List<String> dbNames = collection.stream().sorted(String::compareTo).collect(Collectors.toList());// 4.根据分片键的值,计算出对应的数据源名称return dbNames.get((int) (value % 2));}
}3. 添加分表规则
实现 PreciseShardingAlgorithm 接口,重写 doSharding 方法。
package com.zjp.shadingjdbcdemo.strategy.table;import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;import java.util.Collection;public class TablePreciseAlgorithm implements PreciseShardingAlgorithm<Long> {/*** 精确分片** @param collection 数据源集合* @param preciseShardingValue 分片参数* @return 数据库*/@Overridepublic String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {// 自定义分片方法// 1.获取分片键值Long value = preciseShardingValue.getValue();// 2.获取逻辑表名String logicTableName = preciseShardingValue.getLogicTableName();// 3.获取真实表总数int size = collection.size();// 4.计算表名int v;long n;do {v = (int) (Math.pow(2, Math.ceil(Math.log(size) / Math.log(2))) - 1);n = value & v;} while (n >= size);// 5.获取真实表名称,并排序List<String> dbNames = collection.stream().sorted(String::compareTo).collect(Collectors.toList());// 6.返回真实表return dbNames.get((int) n);}
}2.3.2.2. 范围分片
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND、>、<、>=、<=进行分片的场景。需要配合StandardShardingStrategy使用。
标准分片策略(StandardShardingStrategy)提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND, >, <, >=, <=分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
1. 编写yaml文件
spring:main:allow-bean-definition-overriding: trueshardingsphere:datasource: # 数据源配置,可配置多个data_source_namenames: ds0,ds1ds0: # <!!数据库连接池实现类> `!!`表示实例化该类type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名url: jdbc:mysql://localhost:3306/database1?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false # 数据库url连接,如果是HikariCP连接池,需要换成jdbcurlusername: root # 数据库用户名password: root # 数据库密码ds1: # <!!数据库连接池实现类> `!!`表示实例化该类type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名url: jdbc:mysql://localhost:3306/database2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false # 数据库url连接,如果是HikariCP连接池,需要换成jdbcurlusername: root # 数据库用户名password: root # 数据库密码sharding:# 唯一库数据default-data-source-name: ds0# 分库default-database-strategy:standard: # 用于单分片键的标准分片场景# 添加数据分库字段(根据字段插入数据到那个表)sharding-column: id# 精确分片precise-algorithm-class-name: ${common.algorithm.db}# 范围分片range-algorithm-class-name: ${common.algorithm.db}#分表tables:t_user:actual-data-nodes: ds$->{0..1}.t_user_$->{1..2} #由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况key-generator:column: id # 自增列名称,缺省表示不使用自增主键生成器type: SNOWFLAKE #自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID# props: #属性配置, 注意:使用SNOWFLAKE算法,需要配置worker.id与max.tolerate.time.difference.milliseconds属性。若使用此算法生成值作分片值,建议配置max.vibration.offset属性table-strategy: # 分表策略,同分库策略standard: # 用于单分片键的标准分片场景# 分片列名称sharding-column: id# 精确分片算法类名称,用于=和IN。该类需实现PreciseShardingAlgorithm接口并提供无参数的构造器precise-algorithm-class-name: ${common.algorithm.tb}# 范围分片算法类名称,用于BETWEEN,可选。该类需实现RangeShardingAlgorithm接口并提供无参数的构造器range-algorithm-class-name: ${common.algorithm.tb}props: # 属性配置sql:show: true #是否开启SQL显示,默认值: false# executor.size: #工作线程数量,默认值: CPU核数# max.connections.size.per.query: # 每个查询可以打开的最大连接数量,默认为1# check.table.metadata.enabled: #是否在启动时检查分表元数据一致性,默认值: false# 配置分片策略
common:algorithm:db: com.zjp.shadingjdbcdemo.strategy.database.DatabaseRangeAlgorithmtb: com.zjp.shadingjdbcdemo.strategy.table.TableRangeAlgorithm
2. 添加分库范围查询和精确查询规则
- 范围查询:实现 RangeShardingAlgorithm 接口,重写 doSharding 方法。
- 精确查询:实现 PreciseShardingAlgorithm 接口,重写 doSharding 方法实现。
可以用两个类分别实现,也可以一个类同时实现。
package com.zjp.shadingjdbcdemo.strategy.database;import com.google.common.collect.Range;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;import java.util.Collection;public class DatabaseRangeAlgorithm implements PreciseShardingAlgorithm<Long>, RangeShardingAlgorithm<Long> {/*** 精确分片** @param collection 数据源集合* @param preciseShardingValue 分片参数* @return 数据库*/@Overridepublic String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {// 自定义分片方法// 1.获取分片键的值Long value = preciseShardingValue.getValue();// 2.获取逻辑表名String logicTableName = preciseShardingValue.getLogicTableName();// 3.获取数据库名称,并排序List<String> dbNames = collection.stream().sorted(String::compareTo).collect(Collectors.toList());// 4.根据分片键的值,计算出对应的数据源名称return dbNames.get((int) (value % 2));}/*** 范围分片** @param collection 数据源集合* @param rangeShardingValue 分片参数* @return 直接返回源*/@Overridepublic Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {// 1.获取分片键名String shardingColumn = rangeShardingValue.getColumnName();// 2.获取逻辑表名String logicTableName = rangeShardingValue.getLogicTableName();// 3.获取分片键值范围Range<Long> valueRange = rangeShardingValue.getValueRange();// 4.根据分片键值范围,进行范围匹配long lower = 0L;long upper = Long.MAX_VALUE;// 存在下限if (valueRange.hasLowerBound()) {lower = valueRange.lowerEndpoint();}// 存在上限if (valueRange.hasUpperBound()) {upper = valueRange.upperEndpoint();}// 5.过滤并返回return collection;}
}3. 添加分表规则
- 范围查询:实现 RangeShardingAlgorithm 接口,重写 doSharding 方法。
- 精确查询:实现 PreciseShardingAlgorithm 接口,重写 doSharding 方法。
可以用两个类分别实现,也可以一个类同时实现。
package com.zjp.shadingjdbcdemo.strategy.table;import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;import java.util.Arrays;
import java.util.Collection;public class TableRangeAlgorithm implements PreciseShardingAlgorithm<Long>, RangeShardingAlgorithm<Long> {/*** 精确分片** @param collection 数据源集合* @param preciseShardingValue 分片参数* @return 数据库*/@Overridepublic String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {// 自定义分片方法// 1.获取分片键值Long value = preciseShardingValue.getValue();// 2.获取逻辑表名String logicTableName = preciseShardingValue.getLogicTableName();// 3.获取真实表总数int size = collection.size();// 4.计算表名long n;int v = (int) (Math.pow(13, Math.ceil(Math.log(size * 7) / Math.log(2))) - 1);do {n = value & v;v = v / 2;} while (n >= size);// 5.获取真实表名称,并排序List<String> dbNames = collection.stream().sorted(String::compareTo).collect(Collectors.toList());// 6.返回真实表return dbNames.get((int) n);}/*** 范围分片** @param collection 数据源集合* @param rangeShardingValue 分片参数* @return 直接返回源*/@Overridepublic Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {//逻辑表名称// 1.获取分片键名String shardingColumn = rangeShardingValue.getColumnName();// 2.获取逻辑表名String logicTableName = rangeShardingValue.getLogicTableName();// 3.获取分片键值范围Range<Long> valueRange = rangeShardingValue.getValueRange();// 4.根据分片键值范围,进行范围匹配long lower = 0L;long upper = Long.MAX_VALUE;// 存在下限if (valueRange.hasLowerBound()) {lower = valueRange.lowerEndpoint();}// 存在上限if (valueRange.hasUpperBound()) {upper = valueRange.upperEndpoint();}return collection;}
}2.3.2.3. 行表达式分片
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 2} 表示t_user表根据u_id模2,而分成2张表,表名称为t_user_0到t_user_1。
spring:main:allow-bean-definition-overriding: trueshardingsphere:datasource: # 数据源配置,可配置多个data_source_namenames: ds0,ds1ds0: # <!!数据库连接池实现类> `!!`表示实例化该类type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名url: jdbc:mysql://localhost:3306/database1?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false # 数据库url连接,如果是HikariCP连接池,需要换成jdbcurlusername: root # 数据库用户名password: root # 数据库密码ds1: # <!!数据库连接池实现类> `!!`表示实例化该类type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名url: jdbc:mysql://localhost:3306/database2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false # 数据库url连接,如果是HikariCP连接池,需要换成jdbcurlusername: root # 数据库用户名password: root # 数据库密码sharding:# 唯一库数据default-data-source-name: ds0# 分库default-database-strategy:inline: # 行表达式分片策略# 添加数据分库字段(根据字段插入数据到那个表)sharding-column: id# 分片算法表达式 => 通过id取余algorithm-expression: ds$->{id % 2}# 分表tables:t_user:actual-data-nodes: ds$->{0..1}.t_user_$->{1..2} #由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况key-generator:column: id # 自增列名称,缺省表示不使用自增主键生成器type: SNOWFLAKE #自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID# props: #属性配置, 注意:使用SNOWFLAKE算法,需要配置worker.id与max.tolerate.time.difference.milliseconds属性。若使用此算法生成值作分片值,建议配置max.vibration.offset属性table-strategy: # 分表策略,同分库策略inline: # 行表达式分片策略# 分片列名称sharding-column: id# 分片算法表达式 => 通过id取余algorithm-expression: t_user_$->{id % 2 + 1}props: # 属性配置sql:show: true #是否开启SQL显示,默认值: false# executor.size: #工作线程数量,默认值: CPU核数# max.connections.size.per.query: # 每个查询可以打开的最大连接数量,默认为1# check.table.metadata.enabled: #是否在启动时检查分表元数据一致性,默认值: false
2.3.2.4. 复合分片
用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
复合分片策略(ComplexShardingStrategy)提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
注意:
分片键只支持Integer类型,虽然能传其他类型,但是值是无法处理的。
1. 编写yaml文件
spring:main:allow-bean-definition-overriding: trueshardingsphere:datasource: # 数据源配置,可配置多个data_source_namenames: ds0,ds1ds0: # <!!数据库连接池实现类> `!!`表示实例化该类type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名url: jdbc:mysql://localhost:3306/database1?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false # 数据库url连接,如果是HikariCP连接池,需要换成jdbcurlusername: root # 数据库用户名password: root # 数据库密码ds1: # <!!数据库连接池实现类> `!!`表示实例化该类type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名url: jdbc:mysql://localhost:3306/database2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false # 数据库url连接,如果是HikariCP连接池,需要换成jdbcurlusername: root # 数据库用户名password: root # 数据库密码sharding:# 唯一库数据default-data-source-name: ds0# 分库default-database-strategy:complex: #用于多分片键的复合分片场景# 添加数据分库字段(根据字段插入数据到那个表)sharding-columns: id,agealgorithm-class-name: ${common.algorithm.db}#分表tables:t_user:actual-data-nodes: ds$->{0..1}.t_user_$->{1..2} #由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况key-generator:column: id # 自增列名称,缺省表示不使用自增主键生成器type: SNOWFLAKE #自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID# props: #属性配置, 注意:使用SNOWFLAKE算法,需要配置worker.id与max.tolerate.time.difference.milliseconds属性。若使用此算法生成值作分片值,建议配置max.vibration.offset属性table-strategy: # 分表策略,同分库策略complex: #用于多分片键的复合分片场景sharding-columns: id,agealgorithm-class-name: ${common.algorithm.tb}props: # 属性配置sql:show: true #是否开启SQL显示,默认值: false# executor.size: #工作线程数量,默认值: CPU核数# max.connections.size.per.query: # 每个查询可以打开的最大连接数量,默认为1# check.table.metadata.enabled: #是否在启动时检查分表元数据一致性,默认值: false# 配置分片策略
common:algorithm:db: com.zjp.shadingjdbcdemo.strategy.database.DatabaseComplexAlgorithmtb: com.zjp.shadingjdbcdemo.strategy.table.TableComplexAlgorithm2. 添加分库范围查询和精确查询规则
实现 ComplexKeysShardingAlgorithm 接口,重写 doSharding 方法。
package com.zjp.shadingjdbcdemo.strategy.database;import com.google.common.collect.Range;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;import java.util.Collection;
import java.util.List;
import java.util.stream.Collectors;public class DatabaseComplexAlgorithm implements ComplexKeysShardingAlgorithm<Integer> {/*** 复合分片** @param collection 数据源集合* @param complexKeysShardingValue 分片键的值集合* @return 需要查找的数据源集合*/@Overridepublic Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Integer> complexKeysShardingValue) {// 自定义复合分片规则// 1.获取分片键的值// 等于号 in 的值Map<String, Collection<Integer>> columnNameAndShardingValuesMap = complexKeysShardingValue.getColumnNameAndShardingValuesMap();// 实现 >,>=, <=,< 和 BETWEEN AND 等操作Map<String, Range<Integer>> columnNameAndRangeValuesMap = complexKeysShardingValue.getColumnNameAndRangeValuesMap();// 2. 获取逻辑表名String logicTableName = complexKeysShardingValue.getLogicTableName();// 获取age的值Collection<Integer> ageValues = columnNameAndShardingValuesMap.get("age");Range<Integer> ageRange = columnNameAndRangeValuesMap.get("age");// 获取id的值Collection<Integer> idValues = columnNameAndShardingValuesMap.get("id");Range<Integer> idRange = columnNameAndRangeValuesMap.get("id");// 3.获取数据库名称,并排序List<String> dbNames = collection.stream().sorted(String::compareTo).collect(Collectors.toList());// 4.根据分片键的值,计算出对应的数据源名称if (CollectionUtils.isNotEmpty(ageValues)) {// 如果 ageValues 不为空,根据 age 值对 dbNames 进行取模操作return ageValues.stream().map(age -> dbNames.get(age % 2)).collect(Collectors.toSet());} else if (ageRange != null) {// 如果 ageRange 不为空,根据 age 范围判断属于哪个分区int numPartitions = dbNames.size();int maxAge = 150;int partitionSize = (maxAge + 1) / numPartitions;// 遍历每个分区Set<String> resultDbs = new HashSet<>();for (int i = 0; i < numPartitions; i++) {int start = i * partitionSize;int end = (i + 1) * partitionSize - 1;if (i == numPartitions - 1) {end = maxAge;}try {// 检查 ageRange 是否与当前分区范围有交集,如果两个区间没有交集,该方法将抛出IllegalArgumentException。ageRange.intersection(Range.closed(start, end));resultDbs.add(dbNames.get(i));} catch (IllegalArgumentException e) {}}return resultDbs;}// 默认情况下返回 collectionreturn collection;}
}
3. 添加分表规则
实现 ComplexKeysShardingAlgorithm 接口,重写 doSharding 方法。
package com.zjp.shadingjdbcdemo.strategy.table;import com.google.common.collect.Range;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;import java.util.Collection;
import java.util.List;
import java.util.stream.Collectors;public class TableRangeAlgorithm implements PreciseShardingAlgorithm<Long>, RangeShardingAlgorithm<Long> {/*** 精确分片** @param collection 数据源集合* @param preciseShardingValue 分片参数* @return 数据库*/@Overridepublic String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {// 自定义分片方法// 1.获取分片键值Long value = preciseShardingValue.getValue();// 2.获取逻辑表名String logicTableName = preciseShardingValue.getLogicTableName();// 3.获取真实表总数int size = collection.size();// 4.计算表名long n;int v = (int) (Math.pow(13, Math.ceil(Math.log(size * 7) / Math.log(2))) - 1);do {n = value & v;v = v / 2;} while (n >= size);// 5.获取真实表名称,并排序List<String> dbNames = collection.stream().sorted(String::compareTo).collect(Collectors.toList());// 6.返回真实表return dbNames.get((int) n);}/*** 范围分片** @param collection 数据源集合* @param rangeShardingValue 分片参数* @return 直接返回源*/@Overridepublic Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {//逻辑表名称// 1.获取分片键名String shardingColumn = rangeShardingValue.getColumnName();// 2.获取逻辑表名String logicTableName = rangeShardingValue.getLogicTableName();// 3.获取分片键值范围Range<Long> valueRange = rangeShardingValue.getValueRange();// 4.根据分片键值范围,进行范围匹配long lower = 0L;long upper = Long.MAX_VALUE;// 存在下限if (valueRange.hasLowerBound()) {lower = valueRange.lowerEndpoint();}// 存在上限if (valueRange.hasUpperBound()) {upper = valueRange.upperEndpoint();}return collection;}
}拓展:
Range 方法:
示例代码:
方法名
参数
返回值
说明
是否静态
closed(T lower, T upper)
T lower, T upper
Range<T>
创建一个闭区间 [lower, upper],包括下界和上界。
是
open(T lower, T upper)
T lower, T upper
Range<T>
创建一个开区间 (lower, upper),不包括下界和上界。
是
closedOpen(T lower, T upper)
T lower, T upper
Range<T>
创建一个半闭区间 [lower, upper),包括下界但不包括上界。
是
openClosed(T lower, T upper)
T lower, T upper
Range<T>
创建一个半闭区间 (lower, upper],不包括下界但包括上界。
是
greaterThan(T lower)
T lower
Range<T>
创建一个大于给定值的区间 (lower, +∞)。
是
lessThan(T upper)
T upper
Range<T>
创建一个小于给定值的区间 (-∞, upper)。
是
atLeast(T lower)
T lower
Range<T>
创建一个大于或等于给定值的区间 [lower, +∞)。
是
atMost(T upper)
T upper
Range<T>
创建一个小于或等于给定值的区间 (-∞, upper]。
是
all()
无
Range<T>
创建一个包含所有可能值的区间 (-∞, +∞)。
是
contains(T value)
T value
boolean
检查区间是否包含给定值。
否
encloses(Range<T> other)
Range<T> other
boolean
检查当前区间是否完全包含另一个区间。
否
isConnected(Range<T> other)
Range<T> other
boolean
检查两个区间是否有交集或相邻。
否
intersection(Range<T> other)
Range<T> other
Range<T>
返回两个区间的交集。如果两个区间没有交集,该方法将抛出IllegalArgumentException。
否
span(Range<T> other)
Range<T> other
Range<T>
返回两个区间的并集。
否
hasLowerBound()
无
boolean
检查区间是否有下界。
否
hasUpperBound()
无
boolean
检查区间是否有上界。
否
lowerEndpoint()
无
T
返回区间的下界。
否
upperEndpoint()
无
T
返回区间的上界。
否
lowerBoundType()
无
BoundType
返回区间的下界类型(闭合或开放)。
否
upperBoundType()
无
BoundType
返回区间的上界类型(闭合或开放)。
否
import com.google.common.collect.BoundType; import com.google.common.collect.Range; import lombok.extern.slf4j.Slf4j; import org.junit.jupiter.api.Test; import org.springframework.boot.test.context.SpringBootTest;@Slf4j @SpringBootTest public class ShardingJdbcDemoApplicationTests {public static void main(String[] args) {// 创建一个闭区间 [1, 5]Range<Integer> closedRange = Range.closed(1, 5);System.out.println("Closed range: " + closedRange);// 创建一个开区间 (1, 5)Range<Integer> openRange = Range.open(1, 5);System.out.println("Open range: " + openRange);// 创建一个半闭区间 [1, 5)Range<Integer> closedOpenRange = Range.closedOpen(1, 5);System.out.println("Closed-open range: " + closedOpenRange);// 创建一个半闭区间 (1, 5]Range<Integer> openClosedRange = Range.openClosed(1, 5);System.out.println("Open-closed range: " + openClosedRange);// 创建一个大于给定值的区间 (3, +∞)Range<Integer> greaterThanRange = Range.greaterThan(3);System.out.println("Greater than range: " + greaterThanRange);// 创建一个小于给定值的区间 (-∞, 3)Range<Integer> lessThanRange = Range.lessThan(3);System.out.println("Less than range: " + lessThanRange);// 创建一个大于或等于给定值的区间 [3, +∞)Range<Integer> atLeastRange = Range.atLeast(3);System.out.println("At least range: " + atLeastRange);// 创建一个小于或等于给定值的区间 (-∞, 3]Range<Integer> atMostRange = Range.atMost(3);System.out.println("At most range: " + atMostRange);// 创建一个包含所有可能值的区间 (-∞, +∞)Range<Integer> allRange = Range.all();System.out.println("All range: " + allRange);// 检查区间是否包含给定值boolean contains = closedRange.contains(3);System.out.println("Contains 3: " + contains);// 检查一个区间是否完全包含另一个区间boolean encloses = closedRange.encloses(openRange);System.out.println("Encloses open range: " + encloses);// 检查两个区间是否有交集或相邻boolean isConnected = closedRange.isConnected(openRange);System.out.println("Is connected: " + isConnected);// 返回两个区间的交集Range<Integer> intersection = closedRange.intersection(openRange);System.out.println("Intersection: " + intersection);// 返回两个区间的并集Range<Integer> span = closedRange.span(openRange);System.out.println("Span: " + span);// 检查区间是否有下界和上界boolean hasLowerBound = closedRange.hasLowerBound();boolean hasUpperBound = closedRange.hasUpperBound();System.out.println("Has lower bound: " + hasLowerBound);System.out.println("Has upper bound: " + hasUpperBound);// 返回区间的下界和上界int lowerEndpoint = closedRange.lowerEndpoint();int upperEndpoint = closedRange.upperEndpoint();System.out.println("Lower endpoint: " + lowerEndpoint);System.out.println("Upper endpoint: " + upperEndpoint);// 返回区间的下界类型和上界类型BoundType lowerBoundType = closedRange.lowerBoundType();BoundType upperBoundType = closedRange.upperBoundType();System.out.println("Lower bound type: " + lowerBoundType);System.out.println("Upper bound type: " + upperBoundType);} }
2.3.2.5. Hint分片
用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
对应HintShardingStrategy。通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略。
对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint支持通过Java API和SQL注释(待实现)两种方式使用。
1. 编写yaml文件
spring:main:allow-bean-definition-overriding: trueshardingsphere:datasource: # 数据源配置,可配置多个data_source_namenames: ds0,ds1ds0: # <!!数据库连接池实现类> `!!`表示实例化该类type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名url: jdbc:mysql://localhost:3306/database1?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false # 数据库url连接,如果是HikariCP连接池,需要换成jdbcurlusername: root # 数据库用户名password: root # 数据库密码ds1: # <!!数据库连接池实现类> `!!`表示实例化该类type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名url: jdbc:mysql://localhost:3306/database2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false # 数据库url连接,如果是HikariCP连接池,需要换成jdbcurlusername: root # 数据库用户名password: root # 数据库密码sharding:# 唯一库数据default-data-source-name: ds0# 分库default-database-strategy:hint: #Hint分片策略algorithm-class-name: ${common.algorithm.db}# 分表tables:t_user:actual-data-nodes: ds$->{0..1}.t_user_$->{1..2} #由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况key-generator:column: id # 自增列名称,缺省表示不使用自增主键生成器type: SNOWFLAKE #自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID# props: #属性配置, 注意:使用SNOWFLAKE算法,需要配置worker.id与max.tolerate.time.difference.milliseconds属性。若使用此算法生成值作分片值,建议配置max.vibration.offset属性table-strategy: # 分表策略,同分库策略hint: #Hint分片策略algorithm-class-name: ${common.algorithm.tb}props: # 属性配置sql:show: true #是否开启SQL显示,默认值: false# executor.size: #工作线程数量,默认值: CPU核数# max.connections.size.per.query: # 每个查询可以打开的最大连接数量,默认为1# check.table.metadata.enabled: #是否在启动时检查分表元数据一致性,默认值: false# 配置分片策略
common:algorithm:db: com.zjp.shadingjdbcdemo.strategy.database.DatabaseHintAlgorithmtb: com.zjp.shadingjdbcdemo.strategy.table.TableHintAlgorithm2. 添加分库范围查询和精确查询规则
实现 HintShardingAlgorithm 接口,重写 doSharding 方法。
package com.zjp.shadingjdbcdemo.strategy.database;import org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.hint.HintShardingValue;import java.util.Collection;
import java.util.HashSet;public class DatabaseHintAlgorithm implements HintShardingAlgorithm<Integer> {/*** 执行自定义Hint分片逻辑。** @param collection 数据库名称集合* @param hintShardingValue 分片值对象,包含分片键和逻辑表名* @return 分片后的数据源名称集合*/@Overridepublic Collection<String> doSharding(Collection<String> collection, HintShardingValue<Integer> hintShardingValue) {// 自定义Hint分片方法// 1.获取分片键的值Collection<Integer> values = hintShardingValue.getValues();// 2.获取逻辑表名String logicTableName = hintShardingValue.getLogicTableName();// 3.获取数据库名称,并排序List<String> dbNames = collection.stream().sorted(String::compareTo).collect(Collectors.toList());// 4.根据分片键的值,计算出对应的数据源名称return values.stream().map(value -> dbNames.get((int) (value % 2))).collect(Collectors.toSet());}
}3. 添加分表规则
实现 HintShardingAlgorithm 接口,重写 doSharding 方法。
package com.zjp.shadingjdbcdemo.strategy.table;import org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.hint.HintShardingValue;import java.util.Collection;
import java.util.List;
import java.util.stream.Collectors;public class TableHintAlgorithm implements HintShardingAlgorithm<Integer> {/*** 强制路由** @param collection 数据源集合* @param hintShardingValue 分片参数* @return 数据库集合*/@Overridepublic Collection<String> doSharding(Collection<String> collection, HintShardingValue<Integer> hintShardingValue) {// 自定义Hint分片方法// 1.获取分片键的值Collection<Integer> values = hintShardingValue.getValues();// 2.获取逻辑表名String logicTableName = hintShardingValue.getLogicTableName();// 3.获取数据库名称,并排序List<String> dbNames = collection.stream().sorted(String::compareTo).collect(Collectors.toList());// 4.获取真实表总数int size = collection.size();// 5.根据分片键的值,计算出对应的数据源名称return values.stream().map(value -> {long n;int v = (int) (Math.pow(13, Math.ceil(Math.log(size * 7) / Math.log(2))) - 1);do {n = value & v;v = v / 2;} while (n >= size);return dbNames.get((int) n);}).collect(Collectors.toSet());}
}2.3.2.6. 不分片
对应NoneShardingStrategy。不分片的策略。
spring:main:allow-bean-definition-overriding: trueshardingsphere:datasource: # 数据源配置,可配置多个data_source_namenames: ds0,ds1ds0: # <!!数据库连接池实现类> `!!`表示实例化该类type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名url: jdbc:mysql://localhost:3306/database1?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false # 数据库url连接,如果是HikariCP连接池,需要换成jdbcurlusername: root # 数据库用户名password: root # 数据库密码ds1: # <!!数据库连接池实现类> `!!`表示实例化该类type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名url: jdbc:mysql://localhost:3306/database2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false # 数据库url连接,如果是HikariCP连接池,需要换成jdbcurlusername: root # 数据库用户名password: root # 数据库密码sharding:# 唯一库数据default-data-source-name: ds0# 分库default-database-strategy:none: # 不分片# 分表tables:t_user:actual-data-nodes: ds$->{0..1}.t_user_$->{1..2} #由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况key-generator:column: id # 自增列名称,缺省表示不使用自增主键生成器type: SNOWFLAKE #自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID# props: #属性配置, 注意:使用SNOWFLAKE算法,需要配置worker.id与max.tolerate.time.difference.milliseconds属性。若使用此算法生成值作分片值,建议配置max.vibration.offset属性table-strategy: # 分表策略,同分库策略none: # 不分片props: # 属性配置sql:show: true #是否开启SQL显示,默认值: false# executor.size: #工作线程数量,默认值: CPU核数# max.connections.size.per.query: # 每个查询可以打开的最大连接数量,默认为1# check.table.metadata.enabled: #是否在启动时检查分表元数据一致性,默认值: false2.3.3. 解决jdk8新时间类与Sharding-Sphere兼容问题
以 LocalDate 和 LocalDateTime 为例:
1. 引入依赖
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.17</version>
</dependency>2. 编写 BaseTypeHandler 的实现类:
- LocalDate适配:
package com.zjp.shadingjdbcdemo.handler;import cn.hutool.core.convert.Convert;
import cn.hutool.core.lang.TypeReference;
import org.apache.ibatis.type.BaseTypeHandler;
import org.apache.ibatis.type.JdbcType;
import org.apache.ibatis.type.MappedJdbcTypes;
import org.apache.ibatis.type.MappedTypes;
import org.springframework.stereotype.Component;import java.sql.CallableStatement;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.time.LocalDate;@Component
@MappedTypes(LocalDate.class)
@MappedJdbcTypes(value = JdbcType.DATE, includeNullJdbcType = true)
public class LocalDateTypeHandler extends BaseTypeHandler<LocalDate> {@Overridepublic void setNonNullParameter(PreparedStatement ps, int i, LocalDate parameter, JdbcType jdbcType)throws SQLException {ps.setObject(i, parameter);}@Overridepublic LocalDate getNullableResult(ResultSet rs, String columnName) throws SQLException {return Convert.convert(new TypeReference<LocalDate>() {@Overridepublic String getTypeName() {return super.getTypeName();}},rs.getObject(columnName));}@Overridepublic LocalDate getNullableResult(ResultSet rs, int columnIndex) throws SQLException {return Convert.convert(new TypeReference<LocalDate>() {@Overridepublic String getTypeName() {return super.getTypeName();}},rs.getObject(columnIndex));}@Overridepublic LocalDate getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {return Convert.convert(new TypeReference<LocalDate>() {@Overridepublic String getTypeName() {return super.getTypeName();}},cs.getObject(columnIndex));}
}- LocalDateTime适配:
package com.zjp.shadingjdbcdemo.handler;import cn.hutool.core.convert.Convert;
import org.apache.ibatis.type.BaseTypeHandler;
import org.apache.ibatis.type.JdbcType;
import org.apache.ibatis.type.MappedJdbcTypes;
import org.apache.ibatis.type.MappedTypes;
import org.springframework.stereotype.Component;import java.sql.CallableStatement;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.time.LocalDateTime;@Component
@MappedTypes(LocalDateTime.class)
@MappedJdbcTypes(value = JdbcType.DATE, includeNullJdbcType = true)
public class LocalDateTimeTypeHandler extends BaseTypeHandler<LocalDateTime> {@Overridepublic void setNonNullParameter(PreparedStatement ps, int i, LocalDateTime parameter, JdbcType jdbcType)throws SQLException {ps.setObject(i, parameter);}@Overridepublic LocalDateTime getNullableResult(ResultSet rs, String columnName) throws SQLException {return Convert.toLocalDateTime(rs.getObject(columnName));}@Overridepublic LocalDateTime getNullableResult(ResultSet rs, int columnIndex) throws SQLException {return Convert.toLocalDateTime(rs.getObject(columnIndex));}@Overridepublic LocalDateTime getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {return Convert.toLocalDateTime(cs.getObject(columnIndex));}
}其他时间类可仿照上述方案仿写。
2.3.4. 关于雪花算法配置
雪花算法生成的id总共64位8个字节,结构如下:
| 符号位 | 时间位 | 工作机器标识位 | 序列位 |
| 1位(固定位0) | 41位 | 10位 | 12位 |
源码如下图:

通过源码可以看出,雪花算法可以额外配置三个参数:
- worker.id:工作机器标识位,表示一个唯一的工作进程id,取值范围(整数):0(包含)~1024(不包含),默认值为0。
- max.vibration.offset:序列位,同一毫秒内生成不同的ID,取值范围(整数):0(包含)~4095(包含),默认值为1。
- max.tolerate.time.difference.milliseconds:最大容忍的时钟回拨毫秒数,默认值为10。如下图源码所示,最后一次生成主键的时间 lastMilliseconds 与 当前时间currentMilliseconds 做比较,如果 lastMilliseconds > currentMilliseconds则意味着时钟回调了。那么接着判断两个时间的差值(timeDifferenceMilliseconds)是否在设置的最大容忍时间阈值 max.tolerate.time.difference.milliseconds内,在阈值内则线程休眠差值时间 Thread.sleep(timeDifferenceMilliseconds),否则大于差值直接报异常。

配置示例:
spring:shardingsphere:sharding:tables:key-generator:column: id # 主键IDtype: SNOWFLAKEprops:work:id: 0max:vibration:offset: 1tolerate:time:difference:milliseconds: 102.3.5. 测试
1. 创建数据表
CREATE DATABASE IF NOT EXISTS database1;USE database1;DROP TABLE IF EXISTS `t_user_1`;
DROP TABLE IF EXISTS `t_user_2`;CREATE TABLE `t_user_1` (`id` bigint(20) NOT NULL COMMENT '用户编号',`name` varchar(255) DEFAULT NULL COMMENT '用户名',`age` int(11) DEFAULT NULL COMMENT '用户年龄',`salary` double DEFAULT NULL COMMENT '用户薪资',`birthday` datetime DEFAULT NULL COMMENT '用户生日',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `t_user_2` (`id` bigint(20) NOT NULL COMMENT '用户编号',`name` varchar(255) DEFAULT NULL COMMENT '用户名',`age` int(11) DEFAULT NULL COMMENT '用户年龄',`salary` double DEFAULT NULL COMMENT '用户薪资',`birthday` datetime DEFAULT NULL COMMENT '用户生日',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE DATABASE IF NOT EXISTS database2;USE database2;DROP TABLE IF EXISTS `t_user_1`;
DROP TABLE IF EXISTS `t_user_2`;CREATE TABLE `t_user_1` (`id` bigint(20) NOT NULL COMMENT '用户编号',`name` varchar(255) DEFAULT NULL COMMENT '用户名',`age` int(11) DEFAULT NULL COMMENT '用户年龄',`salary` double DEFAULT NULL COMMENT '用户薪资',`birthday` datetime DEFAULT NULL COMMENT '用户生日',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `t_user_2` (`id` bigint(20) NOT NULL COMMENT '用户编号',`name` varchar(255) DEFAULT NULL COMMENT '用户名',`age` int(11) DEFAULT NULL COMMENT '用户年龄',`salary` double DEFAULT NULL COMMENT '用户薪资',`birthday` datetime DEFAULT NULL COMMENT '用户生日',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;2. 项目依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.zjp</groupId><artifactId>shading-jdbc-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>shading-jdbc-demo</name><description>shading-jdbc-demo</description><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.17</version><relativePath/> <!-- lookup parent from repository --></parent><properties><java.version>1.8</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><spring-boot.version>2.6.13</spring-boot.version></properties><dependencies><!--springboot--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!--lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><!--mybatis-plus--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.0</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.20</version></dependency><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><scope>runtime</scope></dependency><!--sharding-jdbc--><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.1.1</version></dependency><!--hutool工具包--><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.17</version></dependency><!--测试数据--><dependency><groupId>com.github.javafaker</groupId><artifactId>javafaker</artifactId><version>1.0.2</version></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>${spring-boot.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>${spring-boot.version}</version><configuration><mainClass>com.zjp.shadingjdbcdemo.ShadingJdbcDemoApplication</mainClass><skip>true</skip></configuration><executions><execution><id>repackage</id><goals><goal>repackage</goal></goals></execution></executions></plugin></plugins></build></project>
3. 编写配置文件(非Sharding-JDBC配置部分)
server:port: 18080
spring:application:name: sharding-jdbc-demologging:level:com.zjp.shadingjdbcdemo: debug
mybatis-plus:mapper-locations: classpath:mapper/*.xmlconfiguration:log-impl: org.apache.ibatis.logging.stdout.StdOutImplmap-underscore-to-camel-case: true# 设置当查询结果值为null时,同样映射该查询字段给实体(Mybatis-Plus默认会忽略查询为空的实体字段返回)。call-setters-on-nulls: true4. 创建实体类
注意:
- @TableName 注解指定的表为虚拟表 t_user。
- @TableId 的 type 属性为 IdType.AUTO 则采用 Sharding-JDBC 数据源生成策略,否则采用 MyBatis Plus 主键生成策略。
- 主键的数据类型为包装类,否则主键赋值失败,为默认值0。
package com.zjp.shadingjdbcdemo.entity;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.experimental.Accessors;import java.io.Serializable;
import java.time.LocalDate;
import java.time.LocalDateTime;@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
@TableName("t_user")
public class User implements Serializable {private static final long serialVersionUID = 1L;/*** 用户编号*/@TableId(value = "id", type = IdType.AUTO)private Long id;/*** 用户名*/private String name;/*** 用户年龄*/private Integer age;/*** 用户薪资*/private Double salary;/*** 用户生日*/private LocalDateTime birthday;
}
5. 编写Service层和mapper层
package com.zjp.shadingjdbcdemo.service;import com.zjp.shadingjdbcdemo.entity.User;
import com.baomidou.mybatisplus.extension.service.IService;public interface UserService extends IService<User> {
}package com.zjp.shadingjdbcdemo.service.impl;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.zjp.shadingjdbcdemo.entity.User;
import com.zjp.shadingjdbcdemo.mapper.UserMapper;
import com.zjp.shadingjdbcdemo.service.UserService;
import org.springframework.stereotype.Service;@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}package com.zjp.shadingjdbcdemo.mapper;import com.zjp.shadingjdbcdemo.entity.User;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Mapper;@Mapper
public interface UserMapper extends BaseMapper<User> {
}6. 编写测试类
package com.zjp.shadingjdbcdemo;import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.github.javafaker.Faker;
import com.zjp.shadingjdbcdemo.entity.User;
import com.zjp.shadingjdbcdemo.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.apache.shardingsphere.api.hint.HintManager;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.time.LocalDateTime;
import java.time.Year;
import java.time.ZoneId;
import java.util.Date;
import java.util.List;
import java.util.Random;@Slf4j
@SpringBootTest
public class ShadingJdbcDemoTests {@Autowiredprivate UserService userService;private static final Faker FAKER = new Faker();/*** 测试精确分片、行表达式分片、复合分片和不分片*/@Testpublic void testSaveUser() {Date birthday = FAKER.date().birthday(18, 70);User user = new User().setName(FAKER.name().fullName()).setAge(Year.now().getValue() - birthday.getYear() - 1900).setSalary(10000.0).setBirthday(birthday.toInstant().atZone(ZoneId.systemDefault()).toLocalDateTime());userService.save(user);}/*** 测试范围分片*/@Testpublic void testGetUser() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.ge(User::getId,1L);List<User> list = userService.list(wrapper);list.forEach(System.out::println);}/*** 测试hint分片*/@Testpublic void testHint() {Date birthday = FAKER.date().birthday(18, 100);// 创建一个HintManager对象, 确保线程内只存在一个HintManager对象,否则会抛出异常"Hint has previous value, please clear first."HintManager.clear();HintManager hintManager = HintManager.getInstance();// 根据数据库hint分片规则选取数据库hintManager.addDatabaseShardingValue("t_user", 3);// 根据数据表hint分片规则选取数据表hintManager.addTableShardingValue("t_user", 1);User user = new User().setName(FAKER.name().fullName()).setAge(18).setSalary(10000.0).setBirthday(birthday.toInstant().atZone(ZoneId.systemDefault()).toLocalDateTime());userService.save(user);// HintManager存放在线程变量中, 所以需要清除HintManager.clear();}
}
7. 测试
在对应的策略上打断点,以debug方式启动测试方法,查看是否走断点。
2.4. 自定义主键生成策略
2.4.1. 源码参考
1. Ctrl + 左键点击 type,点击定位文件位置,如下图所示,这三个文件即为主键生成策略的配置文件。org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator文件指定了两种生成策略,分别为UUID和雪花算法。


2. 以UUID为例,通过实现 ShardingKeyGenerator 接口,重新 getType 方法指定配置文件的文件名称和重新 generateKey 方法自定义主键生成策略来实现主键生成。

2.4.2. 自定义主键生成策略步骤
1. 编写 ShardingKeyGenerator 实现类
package com.zjp.shadingjdbcdemo.strategy.keygen;import lombok.Getter;
import lombok.Setter;
import lombok.extern.slf4j.Slf4j;
import org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator;import java.util.Properties;
import java.util.Random;@Slf4j
@Getter
@Setter
public class MyShardingKeyGenerator implements ShardingKeyGenerator {private Properties properties = new Properties();/*** 重写generateKey方法以生成唯一的键值* 此方法用于生成一个随机的长整型数字作为键值,* 键值范围为1到1000,旨在用于需要唯一标识符的场景** @return 生成的键值作为一个Comparable对象返回,由于键值为Long类型,* 而Long实现了Comparable接口,这使得返回值可以与其它对象进行比较*/@Overridepublic Comparable<?> generateKey() {Random random = new Random();Long id = (long) (random.nextInt(1000) + 1);log.info("自定义主键生成策略,主键为:{}", id);return id;}/*** 重写getType方法* 返回一个预定义的键值,用于标识特定的类型或功能这个方法总是返回"MyKey",* 表示当前对象或方法的特定类型或功能** @return String 表示当前对象或方法类型的预定义键值*/@Overridepublic String getType() {return "MyKey";}
}2. 在resource目录下创建META-INF/services/org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator文件,文件内容为自定义主键生成策略类的全限定名。
com.zjp.shadingjdbcdemo.strategy.keygen.MyShardingKeyGenerator3. 配置文件指定自定义主键生成策略
spring:shardingsphere:sharding:tables:key-generator:column: id # 主键IDtype: MyKey # 自定义主键生成策略4. 如果是MyBatis Plus,则需要将主键生成策略换成IdType.AUTO
package com.zjp.shadingjdbcdemo.entity;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.experimental.Accessors;import java.io.Serializable;
import java.time.LocalDate;
import java.time.LocalDateTime;@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
@TableName("t_user")
public class User implements Serializable {private static final long serialVersionUID = 1L;/*** 用户编号*/@TableId(value = "id", type = IdType.AUTO)private Long id;/*** 用户名*/private String name;/*** 用户年龄*/private Integer age;/*** 用户薪资*/private Double salary;/*** 用户生日*/private LocalDateTime birthday;
}
5. 编写测试类
package com.zjp.shadingjdbcdemo;import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.github.javafaker.Faker;
import com.zjp.shadingjdbcdemo.entity.User;
import com.zjp.shadingjdbcdemo.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.apache.shardingsphere.api.hint.HintManager;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.time.LocalDateTime;
import java.time.Year;
import java.time.ZoneId;
import java.util.Date;
import java.util.List;
import java.util.Random;@Slf4j
@SpringBootTest
public class ShadingJdbcDemoTests {@Autowiredprivate UserService userService;private static final Faker FAKER = new Faker();@Testpublic void testSaveUser() {Date birthday = FAKER.date().birthday(18, 70);User user = new User().setName(FAKER.name().fullName()).setAge(Year.now().getValue() - birthday.getYear() - 1900).setSalary(10000.0).setBirthday(birthday.toInstant().atZone(ZoneId.systemDefault()).toLocalDateTime());userService.save(user);}/*** 测试范围分片*/@Testpublic void testGetUser() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.ge(User::getId,1L);List<User> list = userService.list(wrapper);list.forEach(System.out::println);}
}
6. 启动测试
通过日志和数据库可以看出主键生成成功。

 2.5. 广播表
2.5. 广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
2.5.1. 配置步骤
编写配置文件,指定广播表:
spring:main:allow-bean-definition-overriding: trueshardingsphere:datasource:names: ds0,ds1ds0:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/database1?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=falseusername: rootpassword: rootds1:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/database2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=falseusername: rootpassword: rootsharding:broadcast-tables: # 广播表规则列表- t_dicttables:t_dict:key-generator:column: dict_idtype: SNOWFLAKEprops: # 属性配置sql:show: true #是否开启SQL显示,默认值: false# executor.size: #工作线程数量,默认值: CPU核数# max.connections.size.per.query: # 每个查询可以打开的最大连接数量,默认为1# check.table.metadata.enabled: #是否在启动时检查分表元数据一致性,默认值: false2.5.2. 测试
1. 创建表结构
CREATE DATABASE IF NOT EXISTS database1;USE database1;DROP TABLE IF EXISTS `t_dict`;CREATE TABLE `t_dict` (`dict_id` bigint(20) NOT NULL COMMENT '字典id',`type` varchar(50) NOT NULL COMMENT '字典类型',`code` varchar(50) NOT NULL COMMENT '字典编码',`value` varchar(50) NOT NULL COMMENT '字典值',PRIMARY KEY (`dict_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;CREATE DATABASE IF NOT EXISTS database2;USE database2;DROP TABLE IF EXISTS `t_dict`;CREATE TABLE `t_dict` (`dict_id` bigint(20) NOT NULL COMMENT '字典id',`type` varchar(50) NOT NULL COMMENT '字典类型',`code` varchar(50) NOT NULL COMMENT '字典编码',`value` varchar(50) NOT NULL COMMENT '字典值',PRIMARY KEY (`dict_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;2. 创建实体类
package com.zjp.shadingjdbcdemo.entity;import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.experimental.Accessors;import java.io.Serializable;@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
@TableName("t_dict")
public class TDict implements Serializable {private static final long serialVersionUID = 1L;/*** 字典id*/private Long dictId;/*** 字典类型*/private String type;/*** 字典编码*/private String code;/*** 字典值*/private String value;
}3. 编写sevice层和mapper层
package com.zjp.shadingjdbcdemo.service;import com.zjp.shadingjdbcdemo.entity.TDict;
import com.baomidou.mybatisplus.extension.service.IService;public interface ITDictService extends IService<TDict> {
}package com.zjp.shadingjdbcdemo.service.impl;import com.zjp.shadingjdbcdemo.entity.TDict;
import com.zjp.shadingjdbcdemo.mapper.TDictMapper;
import com.zjp.shadingjdbcdemo.service.ITDictService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.springframework.stereotype.Service;@Service
public class TDictServiceImpl extends ServiceImpl<TDictMapper, TDict> implements ITDictService {
}
package com.zjp.shadingjdbcdemo.mapper;import com.zjp.shadingjdbcdemo.entity.TDict;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Mapper;@Mapper
public interface TDictMapper extends BaseMapper<TDict> {
}4. 编写测试类
package com.zjp.shadingjdbcdemo;import com.zjp.shadingjdbcdemo.entity.TDict;
import com.zjp.shadingjdbcdemo.service.ITDictService;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.util.List;@SpringBootTest
public class ShadingJdbcDemoTests {@Autowiredprivate ITDictService itDictService;@Testpublic void testSaveDict() {TDict dict = new TDict().setCode("001").setValue("男").setType("sex");itDictService.save(dict);}
}
7. 测试
运行发现两个库的 t_dict 表均插入成功。

2.6. 绑定表
指分片规则一致的主表和子表。例如:t_user表和t_user_item表,均按照user_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果SQL为:
SELECT i.*, o.* FROM t_user o JOIN t_user_item i ON o.id = i.user_id WHERE o.id IN (10, 11);在不配置绑定表关系时,假设分片键user_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
SELECT i.*, o.* FROM t_user_1 o JOIN t_user_item_1 i ON o.id = i.user_id WHERE o.id IN (10, 11);
SELECT i.*, o.* FROM t_user_1 o JOIN t_user_item_2 i ON o.id = i.user_id WHERE o.id IN (10, 11);
SELECT i.*, o.* FROM t_user_2 o JOIN t_user_item_1 i ON o.id = i.user_id WHERE o.id IN (10, 11);
SELECT i.*, o.* FROM t_user_2 o JOIN t_user_item_2 i ON o.id = i.user_id WHERE o.id IN (10, 11);在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.*, o.* FROM t_user_1 o JOIN t_user_item_1 i ON o.id = i.user_id WHERE o.id IN (10, 11);
SELECT i.*, o.* FROM t_user_2 o JOIN t_user_item_2 i ON o.id = i.user_id WHERE o.id IN (10, 11);其中t_user在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么t_user_item表的分片计算将会使用t_user的条件。故绑定表之间的分区键要完全相同。
2.6.1. 配置步骤
编写配置文件,指定绑定表:
spring:main:allow-bean-definition-overriding: trueshardingsphere:datasource:names: ds0,ds1ds0:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/database1?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=falseusername: rootpassword: rootds1:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/database2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=falseusername: rootpassword: rootsharding:default-data-source-name: ds0default-database-strategy:inline:sharding-column: idalgorithm-expression: ds$->{id % 2}tables:t_user:actual-data-nodes: ds$->{0..1}.t_user_$->{1..2}key-generator:column: idtype: SNOWFLAKEtable-strategy:inline:sharding-column: idalgorithm-expression: t_user_$->{id % 2 + 1}t_user_item:actual-data-nodes: ds$->{0..1}.t_user_item_$->{1..2}key-generator:column: item_idtype: SNOWFLAKEtable-strategy:inline:sharding-column: user_idalgorithm-expression: t_user_item_$->{user_id % 2 + 1}binding-tables: # 绑定表规则列表- t_user,t_user_itemprops: # 属性配置sql:show: true #是否开启SQL显示,默认值: false# executor.size: #工作线程数量,默认值: CPU核数# max.connections.size.per.query: # 每个查询可以打开的最大连接数量,默认为1# check.table.metadata.enabled: #是否在启动时检查分表元数据一致性,默认值: false2.5.2. 测试
1. 创建表结构
CREATE DATABASE IF NOT EXISTS database1;USE database1;DROP TABLE IF EXISTS `t_user_item_1`;
DROP TABLE IF EXISTS `t_user_item_2`;CREATE TABLE `t_user_item_1` (`item_id` bigint(20) NOT NULL,`user_id` bigint(20) DEFAULT NULL,PRIMARY KEY (`item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `t_user_item_2` (`item_id` bigint(20) NOT NULL,`user_id` bigint(20) DEFAULT NULL,PRIMARY KEY (`item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE DATABASE IF NOT EXISTS database2;USE database2;DROP TABLE IF EXISTS `t_user_item_1`;
DROP TABLE IF EXISTS `t_user_item_2`;CREATE TABLE `t_user_item_1` (`item_id` bigint(20) NOT NULL,`user_id` bigint(20) DEFAULT NULL,PRIMARY KEY (`item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `t_user_item_2` (`item_id` bigint(20) NOT NULL,`user_id` bigint(20) DEFAULT NULL,PRIMARY KEY (`item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;2. 创建实体类
package com.zjp.shadingjdbcdemo.entity;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;import java.time.LocalDateTime;public class UserItemVo {/*** 用户编号*/@TableId(value = "id", type = IdType.AUTO)private Long id;/*** 用户名*/private String name;/*** 用户年龄*/private Integer age;/*** 用户薪资*/private Double salary;/*** 用户生日*/private LocalDateTime birthday;private Long itemId;
}3. 编写mapper层
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.zjp.shadingjdbcdemo.mapper.UserItemMapper"><select id="getList" resultType="com.zjp.shadingjdbcdemo.entity.UserItemVo">SELECT i.*, o.*FROM t_user oJOIN t_user_item i ON o.id = i.user_idWHERE o.id IN (10, 11);</select>
</mapper>4. 编写测试类
package com.zjp.shadingjdbcdemo;import com.zjp.shadingjdbcdemo.entity.UserItemVo;
import com.zjp.shadingjdbcdemo.service.UserItemService;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;@Slf4j
@SpringBootTest
public class ShadingJdbcDemoTests {@Autowiredprivate UserItemService userItemService;@Testpublic void test() {UserItemVo result = userItemService.selectList();log.info("查询结果为:{}", result);}
}
7. 测试
在注释掉spring.shardingsphere.sharding.binding-tables配置项时,日志为:

在配置 spring.shardingsphere.sharding.binding-tables配置项时,日志为:

本篇文章示例代码:GitHub - kerrsixy/sharding-jdbc-demo
相关文章:
SpringBoot 集成 Sharding-JDBC(一):数据分片
在深入探讨 Sharding-JDBC 之前,建议读者先了解数据库分库分表的基本概念和应用场景。如果您还没有阅读过相关的内容,可以先阅读我们之前的文章: 关系型数据库海量数据存储策略-CSDN博客 这篇文章将帮助您更好地理解分库分表的基本原理和实现…...

django-ninja 实现cors跨域请求
要在Django-Ninja项目中实现跨域(CORS),你可以使用django-cors-headers库,这是一个专门用于处理跨域资源共享(CORS)问题的Django应用程序。以下是具体的步骤和配置: 安装依赖: 使用p…...

【论文阅读】InstructPix2Pix: Learning to Follow Image Editing Instructions
摘要: 提出了一种方法,用于教导生成模型根据人类编写的指令进行图像编辑:给定一张输入图像和一条书面指令,模型按照指令对图像进行编辑。 由于为此任务获取大规模训练数据非常困难,我们提出了一种生成配对数据集的方…...

常用在汽车PKE无钥匙进入系统的高度集成SOC芯片:CSM2433
CSM2433是一款集成2.4GHz频段发射器、125KHz接收器和8位RISC(精简指令集)MCU的SOC芯片,用在汽车PKE无钥匙进入系统里。 什么是汽车PKE无钥匙进入系统? 无钥匙进入系统具有无钥匙进入并且启动的功能,英文名称是PKE&…...

【第四课】rust声明式宏理解与实战
目录 前言 理解宏 实战宏 前言 上一课在介绍vector时,我们再一次提到了rust中的宏,在初始化vector时使用了vec!宏,当时补了一句有机会会好好说明一下rust中的宏,并且写一个hashmap宏来初始化hashmap。想了想一直介绍基本语法还…...

渗透测试--Linux下的文件传输方法
渗透测试过程中,我们经常会需要文件传输,本文主要探讨Linux主机上我们对文件传输的方法。 编码方式 Linux 检查MD5 md5sum id_rsa Linux Base64 编码/解码 编码 cat id_rsa |base64 -w 0;echo 解码 echo -n LS0tLS1CRUdJTiBPUEVOU1NIIFBSSVZBVE…...
浅议Flink中的通讯工具: Akka
在Flink中,各个组件之间需要频繁交换数据和控制信息。Flink选择了基于Actor模型的Akka框架作为通信基础。 Akka是什么 Actor模型 Actor模型是用于单个进程中并发的场景。 在Actor模型中: ActorSystem负责管理actor生命周期 将每个实体视为独立的 Ac…...
基于YOLOv8深度学习的独居老人情感状态监护系统(PyQt5界面+数据集+训练代码)
本研究提出了一种创新的独居老人情感状态监护系统,基于YOLOV8深度学习模型,旨在通过对老年人面部表情的实时监测与分析,来精准识别其情感变化,从而提高独居老人的生活质量,确保其心理健康。本系统通过整合先进的YOLOV8…...

Qt添加外部库:静态库和动态库,批量添加头文件
Qt添加外部库需要知道库文件的位置才能正确链接,如果是静态库,要确保LIBS变量中包含正确的库文件路径和库文件名;如果是动态库,除了库路径外,还需要考虑动态库的加载路径。在 Windows 下,可以将动态库所在路径添加到系…...

Unity类银河战士恶魔城学习总结(P132 Merge skill tree with skill Manager 把技能树和冲刺技能相组合)
【Unity教程】从0编程制作类银河恶魔城游戏_哔哩哔哩_bilibili 教程源地址:https://www.udemy.com/course/2d-rpg-alexdev/ 本章节实现了解锁技能后才可以使用技能,先完成了冲刺技能的锁定解锁 Dash_Skill.cs using System.Collections; using System…...

Docker入门之Windows安装Docker初体验
在之前我们认识了docker的容器,了解了docker的相关概念:镜像,容器,仓库:面试官让你介绍一下docker,别再说不知道了 之后又带大家动手体验了一下docker从零开始玩转 Docker:一站式入门指南&#…...

DNS实验作业
实验要求 1.搭建dns服务器能够对自定义的正向或者反向域完成数据解析查询。 2.配置从DNS服务器,对主dns服务器进行数据备份。 实验步骤: 1.关闭防护墙 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2.正向解析 [rootlo…...

CSS回顾-CSS选择器详解
一、引言 我来填坑啦!之前在CSS基础知识详解中介绍过,CSS 是一门基于规则的语言。是由选择器与样式信息组成:选择器 {样式信息}。CSS 选择器是 CSS 规则的关键,能精准定位 HTML 元素,CSS3 新增选择器更是增强了设计能…...

FFMPEG录像推流时遇到的问题
FFMPEG录像推流时遇到的问题,记录一下供大参考 1. ret avformat_write_header( ofmt_ctx, NULL ); 执行写入头后,所有的流的时间基都会被内部重新设置,所以并不你想象的把原来的时间直接入到avPACKET中就可以发送了。必须要把你每个流的P…...
)
【STM32+K210项目】基于K210智能人脸识别+车牌识别系统(完整工程资料源码)
运行效果: 基于K210的智能人脸与车牌识别系统工程 目录: 运行效果: 目录: 前言: 一、国内外研究现状与发展趋势 二、相关技术基础 2.1 人脸识别技术 2.2 车牌识别技术 三、智能小区门禁系统设计 3.1 系统设计方案 3.2 系统设计目标 3.3 智能小区门禁系统硬件设计 3.3.1 控…...
Unity脚本基础规则
Unity脚本基础规则 如何在Unity中创建一个脚本文件? 在Project窗口中的Assets目录下,选择合适的文件夹,右键,选择第一个Create,在新出现的一栏中选择C# Script,此时文件夹内会出现C#脚本图标,…...

基于AIRTEST和Jmeter、Postman的自动化测试框架
基于目前项目和团队技术升级,采用了UI自动化和接口自动化联动数据,进行相关测试活动,获得更好的测试质量和测试结果。...

使用 Azure OpenAI 服务对数据进行联合 SharePoint 搜索
作者:来自 Elastic Gustavo Llermaly 使用 Azure OpenAI 服务处理你的数据,并使用 Elastic 作为向量数据库。 在本文中,我们将探索 Azure OpenAI 服务 “On Your Data”,使用 Elasticsearch 作为数据源。我们将使用 Elastic Shar…...

JavaScript学习笔记 1】初识JS
目录 一、JS是什么? 二、JS的作用? 三、JS的组成 四、JS的书写位置 1. 内部JS 2. 外部JS(外部导入) 3. 内联JS 4. 练习 五、JS的注释与结束符 1. 注释 2. 结束符 3. JS该不该加分号? 六、JS的输入和输出语法 1. 输出语法 a. 输出在页面中 b. …...

Linux-Samba
文章目录 Samba配置服务配置 🏡作者主页:点击! 🤖Linux专栏:点击! ⏰️创作时间:2024年11月18日13点20分 Samba配置 Samba是一个能让 Linux 系统应用与 Microsoft 网络通讯协议的软件&#x…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...
零知开源——STM32F103RBT6驱动 ICM20948 九轴传感器及 vofa + 上位机可视化教程
STM32F1 本教程使用零知标准板(STM32F103RBT6)通过I2C驱动ICM20948九轴传感器,实现姿态解算,并通过串口将数据实时发送至VOFA上位机进行3D可视化。代码基于开源库修改优化,适合嵌入式及物联网开发者。在基础驱动上新增…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...
EasyRTC音视频实时通话功能在WebRTC与智能硬件整合中的应用与优势
一、WebRTC与智能硬件整合趋势 随着物联网和实时通信需求的爆发式增长,WebRTC作为开源实时通信技术,为浏览器与移动应用提供免插件的音视频通信能力,在智能硬件领域的融合应用已成必然趋势。智能硬件不再局限于单一功能,对实时…...
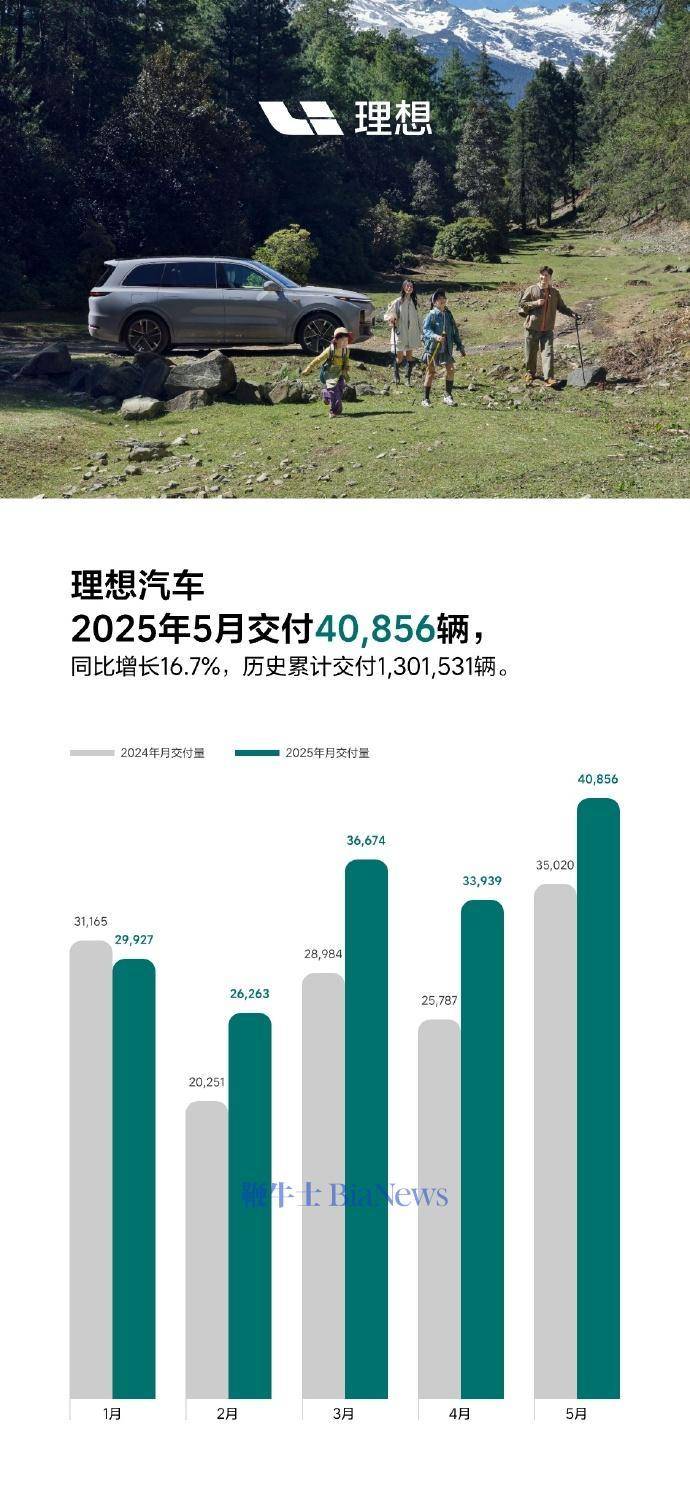
理想汽车5月交付40856辆,同比增长16.7%
6月1日,理想汽车官方宣布,5月交付新车40856辆,同比增长16.7%。截至2025年5月31日,理想汽车历史累计交付量为1301531辆。 官方表示,理想L系列智能焕新版在5月正式发布,全系产品力有显著的提升,每…...