20241120-Milvus向量数据库快速体验
目录
- 20241120-Milvus向量数据库快速体验
- Milvus 向量数据库
- pymilvus
- 内嵌向量数据库模式
- 设置向量数据库
- 创建 Collections
- 准备数据
- 用向量表示文本
- 插入数据
- 语义搜索
- 向量搜索
- 带元数据过滤的向量搜索
- 查询
- 通过主键搜索
- 删除实体
- 加载现有数据
- 删除 Collections
- 了解更多
个人主页: 【⭐️个人主页】
需要您的【💖 点赞+关注】支持 💯

20241120-Milvus向量数据库快速体验
📖 本文核心知识点:
- 内嵌模式 Milvus Lite : pymilvus
- embedding 模型 下载
- milvus 库和collection
- curd操作
- 语义搜索
- 元数据搜索
Milvus 向量数据库
https://milvus.io/docs/zh/quickstart.md
pymilvus
内嵌向量数据库模式
pip install -U pymilvus
设置向量数据库
from pymilvus import MilvusClientclient = MilvusClient("milvus_demo.db")collection_name = "demo_collect"
创建 Collections
在 Milvus 中,我们需要一个 Collections来存储向量及其相关元数据。你可以把它想象成传统 SQL 数据库中的表格。创建 Collections 时,可以定义 Schema 和索引参数来配置向量规格,如维度、索引类型和远距离度量。此外,还有一些复杂的概念来优化索引以提高向量搜索性能。
现在,我们只关注基础知识,并尽可能使用默认设置。至少,你只需要设置 Collections 的名称和向量场的维度。
if client.has_collection(collection_name="demo_collect"):client.drop_collection(collection_name="demo_collect")
client.create_collection(collection_name="demo_collect",dimension=768)
在上述设置中
- 主键和向量字段使用默认名称("id "和 “vector”)。
- 度量类型(向量距离定义)设置为默认值(COSINE)。
- 主键字段接受整数,且不自动递增(即不使用自动 ID 功能)。 或者,您也可以按照此说明正式定义 Collections 的 Schema。
准备数据
在本指南中,我们使用向量对文本进行语义搜索。我们需要通过下载 embedding 模型为文本生成向量。使用pymilvus[model] 库中的实用功能可以轻松完成这项工作。
用向量表示文本
首先,安装模型库。该软件包包含 PyTorch 等基本 ML 工具。如果您的本地环境从未安装过 PyTorch,则软件包下载可能需要一些时间。
# 首次下载 ,取消注释
# pip install "pymilvus[model]"
用默认模型生成向量 Embeddings。Milvus 希望数据以字典列表的形式插入,每个字典代表一条数据记录,称为实体。
# potorch 安装
# cpu 处理器。或者根据您的gpu下载对应版本
## conda install。更新清华镜像,使用这个方式快
# conda install pytorch torchvision torchaudio cpuonly -c pytorch
pip install torch torchvision torchaudio
# pip install -U huggingface_hubimport os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# huggingface-cli download --resume-download paraphrase-albert-small-v2 --local-dir paraphrase-albert-small-v2
from pymilvus import model# If connection to https://huggingface.co/ failed, uncomment the following path
#import os
#os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'# This will download a small embedding model "paraphrase-albert-small-v2" (~50MB).embedding_fn = model.DefaultEmbeddingFunction()docs = ["Artificial intelligence was founded as an academic discipline in 1956.","Alan Turing was the first person to conduct substantial research in AI.","Born in Maida Vale, London, Turing was raised in southern England.",
]# The output vector has 768 dimensions, matching the collection that we just created.
vectors = embedding_fn.encode_documents(docs)
print("Dim:", embedding_fn.dim, vectors[0].shape) # Dim: 768 (768,)# Each entity has id, vector representation, raw text, and a subject label that we use
# to demo metadata filtering later.
data = [{"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"}for i in range(len(vectors))
]print("Data has", len(data), "entities, each with fields: ", data[0].keys())
print("Vector dim:", len(data[0]["vector"]))插入数据
让我们把数据插入 Collections:
res = client.insert(collection_name="demo_collect",data=data)
print(res)
语义搜索
现在我们可以通过将搜索查询文本表示为向量来进行语义搜索,并在 Milvus 上进行向量相似性搜索
向量搜索
Milvus 可同时接受一个或多个向量搜索请求。query_vectors 变量的值是一个向量列表,其中每个向量都是一个浮点数数组。
query_vectors = embedding_fn.encode_queries(["Who is Alan Turing?"])res = client.search(collection_name="demo_collect", # target collectiondata=query_vectors, # query vectorslimit=2, # number of returned entitiesoutput_fields=["text", "subject"], # specifies fields to be returned
)print(res)输出结果是一个结果列表,每个结果映射到一个向量搜索查询。每个查询都包含一个结果列表,其中每个结果都包含实体主键、到查询向量的距离以及指定output_fields 的实体详细信息。
带元数据过滤的向量搜索
你还可以在考虑元数据值(在 Milvus 中称为 "标量 "字段,因为标量指的是非向量数据)的同时进行向量搜索。这可以通过指定特定条件的过滤表达式来实现。让我们在下面的示例中看看如何使用subject 字段进行搜索和筛选
# Insert more docs in another subject.
docs = ["Machine learning has been used for drug design.","Computational synthesis with AI algorithms predicts molecular properties.","DDR1 is involved in cancers and fibrosis.",
]vectors = embedding_fn.encode_documents(docs)data = [{"id": 3+ i , "vector": vectors[i],"text":docs[i],"subject":"biology"}for i in range(len(vectors))
]client.insert(collection_name="demo_collect",data=data)res = client.search(collection_name="demo_collect",data=embedding_fn.encode_queries(["tell me AI related information"]),limit=3,output_fields=["text","subject"],filter="subject == 'biology'"
)
print(res)
默认情况下,标量字段不编制索引。如果需要在大型数据集中执行元数据过滤搜索,可以考虑使用固定 Schema,同时打开索引以提高搜索性能。
除了向量搜索,还可以执行其他类型的搜索:
查询
查询()是一种操作符,用于检索与某个条件(如过滤表达式或与某些 id 匹配)相匹配的所有实体。
例如,检索标量字段具有特定值的所有实体
res = client.query(collection_name=collection_name,filter="subject == 'history'",output_fields=["text","subject"]
)
print(res)通过主键搜索
res = client.query(collection_name="demo_collect",ids=[0, 2],output_fields=[ "text", "subject"] #"vector"*/#]
)print(res)删除实体
如果想清除数据,可以删除指定主键的实体,或删除与特定过滤表达式匹配的所有实体
res = client.delete(collection_name=collection_name, ids=[0, 2])print(res)res = client.delete(collection_name=collection_name,filter="subject == 'biology'",
)print(res)加载现有数据
由于 Milvus Lite 的所有数据都存储在本地文件中,因此即使在程序终止后,你也可以通过创建一个带有现有文件的MilvusClient ,将所有数据加载到内存中。例如,这将恢复 "milvus_demo.db "文件中的 Collections,并继续向其中写入数据。
from pymilvus import MilvusClientclient = MilvusClient("milvus_demo.db")删除 Collections
如果想删除某个 Collections 中的所有数据,可以通过以下方法丢弃该 Collections
res = client.drop_collection(collection_name=collection_name)
print(res)
了解更多
Milvus Lite 非常适合从本地 python 程序入门。如果你有大规模数据或想在生产中使用 Milvus,你可以了解在Docker和Kubernetes 上部署 Milvus。Milvus 的所有部署模式都共享相同的 API,因此如果转向其他部署模式,你的客户端代码不需要做太大改动。只需指定部署在任何地方的 Milvus 服务器的URI 和令牌即可:
client = MilvusClient(uri="http://localhost:19530", token="root:Milvus")
Milvus 提供 REST 和 gRPC API,并提供Python、Java、Go、C# 和Node.js 等语言的客户端库。
相关文章:
20241120-Milvus向量数据库快速体验
目录 20241120-Milvus向量数据库快速体验Milvus 向量数据库pymilvus内嵌向量数据库模式设置向量数据库创建 Collections准备数据用向量表示文本插入数据 语义搜索向量搜索带元数据过滤的向量搜索查询通过主键搜索 删除实体加载现有数据删除 Collections了解更多 个人主页: 【⭐…...

【Golang】——Gin 框架中间件详解:从基础到实战
中间件是 Web 应用开发中常见的功能模块,Gin 框架支持自定义和使用内置的中间件,让你在请求到达路由处理函数前进行一系列预处理操作。这篇博客将涵盖中间件的概念、内置中间件的用法、如何编写自定义中间件,以及在实际应用中的一些最佳实践。…...

量子计算来袭:如何保护未来的数字世界
目录 前言 一、量子计算安全的学习方向 1. 量子物理学基础 2. 量子计算原理与技术 3. 传统网络安全知识 4. 量子密码学 5. 量子计算安全政策与法规 二、量子计算的漏洞风险 1. 加密算法被破解风险 2. 区块链安全风险 3. 量子密钥分发风险 4. 量子计算系统自身风险 …...

VMware虚拟机(Ubuntu或centOS)共享宿主机网络资源
VMware虚拟机(Ubuntu或centOS)共享宿主机网络资源 由于需要在 Linux 环境下进行一些测试工作,于是决定使用 VMware 虚拟化软件来安装 Ubuntu 24.04 .1操作系统。考虑到测试过程中需要访问 Github ,要使用Docker拉去镜像等外部网络资源,因此产…...

光伏电站仿真系统的作用
光伏仿真系统有多方面的重要作用,不仅对前期的项目设计评估还是后期的运维效验都有非常重要的作用。 1、优化系统设计 通过输入不同的光伏组件参数、布局方案以及气象条件等,模拟各种设计场景下光伏电站的性能表现。例如,可以比较不同类型光…...

Golang文件操作
写文件   os模块可以创建文件,使用fmt可以写入文件。如以下例子: package mainimport ("fmt""os" )func main() {// 学习 golang的文件操作file, err : os.Create("test.txt")if err ! nil {fmt.P…...

爬虫开发工具与环境搭建——使用Postman和浏览器开发者工具
第三节:使用Postman和浏览器开发者工具 在网络爬虫开发过程中,我们经常需要对HTTP请求进行测试、分析和调试。Postman和浏览器开发者工具(特别是Network面板和Console面板)是两种最常用的工具,能够帮助开发者有效地捕…...

React(二)
文章目录 项目地址七、数据流7.1 子组件传递数据给父组件7.1.1 方式一:給父设置回调函数,传递给子7.1.2 方式二:直接将父的setState传递给子7.2 给props传递jsx7.2.1 方式一:直接传递组件给子类7.2.2 方式二:传递函数给子组件7.3 props类型验证7.4 props的多层传递7.5 cla…...
)
同步原语(Synchronization Primitives)
同步原语(Synchronization Primitives)是用于控制并发编程中多个线程或进程之间的访问顺序,确保共享资源的安全访问的一组机制或工具。它们解决了竞争条件(Race Condition)、死锁(Deadlock)等并…...

SpringBoot服务多环境配置
一个项目的的环境一般有三个:开发(dev)、测试(test)、生产(proc),一般对应三套环境,三套配置文件。 像下面这样直接写两个配置文件是不行的。 application.ymlserver:port: 8080application-dev.ymlspring:datasource:driver-class-name: co…...

STM32单片机CAN总线汽车线路通断检测-分享
目录 目录 前言 一、本设计主要实现哪些很“开门”功能? 二、电路设计原理图 1.电路图采用Altium Designer进行设计: 2.实物展示图片 三、程序源代码设计 四、获取资料内容 前言 随着汽车电子技术的不断发展,车辆通信接口在汽车电子控…...

【环境搭建】使用IDEA远程调试Docker中的Java Web
有时候要对Docker的Java Web远程调试其功能,于是就需要使用IDEA的远程调试功能,记录一下简单配置方法。 以Kylin4.0.0为例,首先拉取镜像并启动容器: $ docker pull apachekylin/apache-kylin-standalone:4.0.0$ docker run -d \-…...

贴代码框架PasteForm特性介绍之select,selects,lselect和reload
简介 PasteForm是贴代码推出的 “新一代CRUD” ,基于ABPvNext,目的是通过对Dto的特性的标注,从而实现管理端的统一UI,借助于配套的PasteBuilder代码生成器,你可以快速的为自己的项目构建后台管理端!目前管…...

STM32G4的数模转换器(DAC)的应用
目录 概述 1 DAC模块介绍 2 STM32Cube配置参数 2.1 参数配置 2.2 项目架构 3 代码实现 3.1 接口函数 3.2 功能函数 3.3 波形源代码 4 DAC功能测试 4.1 测试方法介绍 4.2 波形测试 概述 本文主要介绍如何使用STM32G4的DAC模块功能,笔者使用STM32Cube工具…...
和跨线程获取token信息)
SpringMVC跨线程获取requests请求对象(子线程共享servletRequestAttributes)和跨线程获取token信息
文章目录 引言I 跨线程共享数据跨线程获取requests请求对象基于org.slf4j.MDC存储共享数据InheritableThreadLocal解决异步线程,无法获取token信息问题II Feign 传递请求属性feign 模块处理被调用方处理请求头III 异步调用的方式CompletableFutureAsync注解Executors引言 本文…...
)
提取repo的仓库和工作树(无效)
问题 从供应商处获取的.repo的git仓库裸(project-object)仓库和工作树(projects)是分开的。 解决方案 根据工作树的软链接路劲,将工作树合并到project-object下。 import os import shutil import argparse import logging# 设置日志配置 logging.basicConfig(l…...

力扣整理版七:二叉树(待更新)
满二叉树:如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。深度为k,有2^k-1个节点的二叉树。 完全二叉树:在完全二叉树中,除了最底层节点可能没填满外&am…...
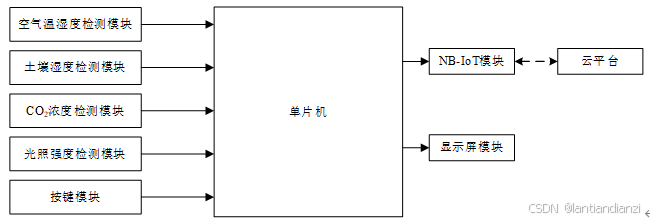
基于单片机的多功能环保宠物窝设计
本设计基于单片机设计的多功能环保宠物窝,利用温湿度传感器、压力传感模块、气味传感模块、红外测温传感器、通信模块、显示模块、清扫部件等,使其能够实现自动检测并调节温湿度、补充宠物食物、检测宠物体温健康并出现异常时进行报警、自动清扫消毒宠物…...

HBase 基础操作
一、启动HBase 首先,确保Hadoop和HBase服务已经启动。如果尚未启动,可以使用以下命令启动: # 启动Hadoop start-all.sh# 启动HBase start-hbase.sh二、HBase Shell操作 创建表 在HBase Shell中,使用create命令创建表。以下是一…...

小米顾此失彼:汽车毛利大增,手机却跌至低谷
科技新知 原创作者丨依蔓 编辑丨蕨影 三年磨一剑的小米汽车毛利率大增,手机业务毛利率却出现下滑景象。 11月18日,小米集团发布 2024年第三季度财报,公司实现营收925.1亿元,同比增长30.5%,预估902.8亿元;…...
漏洞原理与漏洞复现(基于vulhub))
log4j2(CVE-2021-44228)漏洞原理与漏洞复现(基于vulhub)
声明:部分内容来源于网络,如若侵权请联系删除 什么是log4j2? Log for Java,Apache的开源日志记录组件,是一个Java的日志记录工具。在log4j框架的基础上进行了改进,并引入了丰富的特性,可以控制日志信息输送…...

手把手教你为RV1126调试Sony IMX585:从设备树到驱动移植的完整避坑指南
RV1126平台Sony IMX585传感器移植实战:从设备树到图像调优的全流程解析 当拿到一块搭载RV1126芯片的开发板和Sony IMX585传感器模组时,如何快速完成从硬件对接到图像输出的完整流程?本文将深入剖析每个关键环节的技术细节与实战经验…...

WarcraftHelper:三步搞定魔兽争霸3兼容性难题的终极解决方案
WarcraftHelper:三步搞定魔兽争霸3兼容性难题的终极解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典游戏魔兽争霸3在现…...

如何用歌词滚动姬3分钟制作专业级LRC歌词:免费跨平台终极指南
如何用歌词滚动姬3分钟制作专业级LRC歌词:免费跨平台终极指南 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 歌词滚动姬是一款专为音乐爱好者设计的免费…...

inject源码解析:从Graph到Object的完整依赖图构建指南
inject源码解析:从Graph到Object的完整依赖图构建指南 【免费下载链接】inject Package inject provides a reflect based injector. 项目地址: https://gitcode.com/gh_mirrors/inje/inject inject是一个基于反射的Go语言依赖注入库,能够自动构建…...

为什么你的Gemini总在“浅层回答”?揭秘深度研究模式的3层激活机制与强制触发密钥
更多请点击: https://intelliparadigm.com 第一章:为什么你的Gemini总在“浅层回答”? 当你反复向 Gemini 提问却只得到泛泛而谈、回避细节或机械复述提示词的答案时,问题往往不在模型本身,而在于**交互范式与上下文工…...

3步高效启用Windows Insider预览计划:免登录离线方案终极指南
3步高效启用Windows Insider预览计划:免登录离线方案终极指南 【免费下载链接】offlineinsiderenroll OfflineInsiderEnroll - A script to enable access to the Windows Insider Program on machines not signed in with Microsoft Account 项目地址: https://g…...

为什么感觉苹果11的手机放歌音效比华为mate80好,大家觉得呢?什么原因?配置有何差别?——有没有音效好的手机推荐?——有带hifi效果的吗?
公开信息中没有直接对比两款机型音效的权威测试,结合硬件和系统规律来看,这种听感差异主要是调校风格不同导致的,并非绝对的音质好坏。 核心原因分析 系统与音频链路调校差异 苹果iOS是封闭式系统,对音频链路的优化更统一,没有第三方厂商的碎片化干扰,驱动调校成熟…...

3步实现AI动作复制:如何用ComfyUI-MimicMotionWrapper让普通人拥有专业舞者动作
3步实现AI动作复制:如何用ComfyUI-MimicMotionWrapper让普通人拥有专业舞者动作 【免费下载链接】ComfyUI-MimicMotionWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-MimicMotionWrapper 你是否想过让照片中的人物动起来,赋予静…...

深入CPU内部:8086的MUL指令是如何工作的?从硬件视角理解乘法结果为何放在AX和DX
深入CPU内部:8086的MUL指令硬件实现原理全解析 记得第一次在调试器中单步执行MUL指令时,看到AX和DX寄存器突然被一堆十六进制数填满,那种既兴奋又困惑的感觉至今难忘。作为x86架构中最基础的乘法指令,MUL表面看似简单,…...