徒手从零搭建一套ELK日志平台
徒手从零搭建一套ELK日志平台
- 日志分析的概述
- 日志分析的作用
- 主要收集工具
- 集中式日志系统主要特点
- 采集日志分类
- ELK概述
- 初级版ELK
- 终极版ELK
- 高级版ELK
- ELK收集日志的两种形式
- 搭建ELK平台
- Logstash工作原理
- Logstash核心概念
- 环境准备
- 安装部署docker
- 添加镜像加速器
- 安装部署Elasticsearch
- 安装ElasticSearch-head(可选)
- 拉取镜像
- 运行容器
- 页面无数据问题
- 测试
- 安装Kibana
- 测试
- Docker 安装 LogStash
- 启动容器并挂载
- 创建springboot应用
- 查看 es-head
- 查看Kibana
日志分析的概述
- 日志分析是运维工程师解决系统故障,发现问题的主要手段
- 日志主要包括系统日志、应用程序日志和安全日志
- 系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因
- 经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误
日志分析的作用
- 分析日志时刻监控系统运行的状态
- 分析日志来定位程序的bug
- 分析日志监控网站的访问流量
- 分析日志可以知道哪些sql语句需要优化
主要收集工具
- 日志易: 国内一款监控、审计、权限管理,收费软件
- splunk: 按流量收费,国外软件,主要三个部件组成(Indexer、Search Head、Forwarder)
- Indexder提供数据的存储,索引,类似于elasticsearch的作用
- Search Head负责搜索,客户接入,从功能上看,一部分是kibana的UI是运行,在Search Head上的,提供所有的客户端可视化功能,还有一部分,是提供分布式的搜索功能,具有Elasticsearch部分功能
- Forwarder负责数据接入,类似Logstash或者filebeat
- ELK: 海量日志分析平台(Elasticsearch、logstash、kibana),开源且在国内被广泛应用
集中式日志系统主要特点
| 动作 | 功能 |
|---|---|
| 收集 | 能够采集多种来源的日志数据 |
| 传输 | 能够稳定的把日志传数据传输到中央系统 |
| 存储 | 安全的存储日志数据 |
| 分析 | 可以支持UI分析 |
| 警告 | 能够提供错误报告 |
采集日志分类
| 维度 | 举例 |
|---|---|
| 代理层 | Nginx、HAproxy… |
| web层 | Nginx、httpd、tomcat、Java… |
| 数据库层 | MySQL、Redis、Elasticsearch、openGauss… |
| 系统层 | message、secure |
ELK概述
ELK是一个开源的数据分析平台,由三个开源项目Elasticsearch、Logstash和Kibana组成,因此被称为ELK
ELK主要用于处理和分析大量的日志数据,支持实时搜索、数据可视化和分析
- Elasticsearch是一个
分布式搜索引擎和分析引擎,能够实现实时搜索和分析大规模的数据集 - Logstash是一个数据收集、处理和转换工具,能够从不同来源收集、处理和传输数据
- Kibana是一个数据可视化工具,能够通过仪表盘、图形和地图等方式展示数据
- ELK 三个组件相互配合,能够构建一个强大的、可扩展的日志分析平台,支持数据的快速检索、可视化和分析。
初级版ELK

终极版ELK

高级版ELK

ELK收集日志的两种形式
不修改源日志的格式: 而是通过logstash的grok方式进行过滤清洗,将原始无规则的日志转换为规则的日志
优点: 不用修改原始日志输出格式,直接通过logstash的grok方式进行过滤分析,好处是对线上业务系统无任何影响缺点: logstash的grok方式在高压力情况下会成为性能瓶颈如果要分析的日志量超大时,日志过滤分析可能阻塞正常的日志输出;因此,在使用logstash时,能不用grok尽量不使用grok过滤功能。
修改源日志输出格式: 按照需要的日志格式输出规则日志,logstash只负责日志的收集和传输,不对日志做任何的过滤清洗。
优点: 因为已经定义好了需要的日志输出格式, logstash只负责日志的收集和传输,这样就大大减轻了logstash的负担,可以更高效的收集和传输日志。缺点: 需要事先定义好日志的输出格式,这可能有一定工作量,但目前常见的web服务器例如httpd、Nginx等都支持自定义日志输出格式。
搭建ELK平台
Elasticsearch 官网:
https://www.elastic.co/cn/elasticsearch
Elasticsearch是一个基于Lucene库的分布式搜索引擎和数据分析引擎,能够实现实时搜索和分析大规模的数据集,支持文本、数字、地理位置等多种类型的数据检索和分析。Elasticsearch是一个开源的、高度可扩展的平台,能够处理海量的数据,并支持分布式的数据存储和处理。Elasticsearch的主要特点包括:
分布式搜索引擎: Elasticsearch能够对海量的数据进行快速的搜索和查询,并支持实时搜索。分布式数据存储: Elasticsearch能够将数据分散存储在多个节点上,以提高数据的可用性和可靠性。多数据类型支持: Elasticsearch支持多种数据类型,包括文本、数字、日期、地理位置等。实时数据分析: Elasticsearch能够对数据进行实时的聚合、过滤和分析,并支持数据可视化。可扩展性: Elasticsearch能够扩展到数百个节点,处理PB级别的数据。开源: Elasticsearch是一个开源的软件,源代码可以公开获取和修改。Elasticsearch广泛应用于企业搜索、日志分析、安全分析和商业智能等领域。它提供了丰富的API和工具,包括RESTful API、Java API和Python API等,方便开发人员集成和使用。
Logstash 文档地址:
https://www.elastic.co/guide/en/logstash/current/getting-started-with-logstash.html
Logstash 是一个开源的数据收集、处理和转换工具,能够从不同来源收集、处理和传输数据。,主要用于处理和分析大量的日志数据,支持多种数据源和格式,包括文本文件、数据库、日志文件、消息队列等。Logstash能够实现以下功能:
数据收集: Logstash能够从不同的数据源收集数据,并支持多种数据格式,包括JSON、CSV、XML等。数据处理: Logstash能够对收集到的数据进行处理和转换,例如过滤、分析、标准化等。数据传输: Logstash能够将处理后的数据传输到目标位置,例如Elasticsearch、Kafka、Redis等。插件扩展: Logstash提供了丰富的插件,方便用户扩展和定制功能。实时数据处理: Logstash能够实现实时数据处理,支持流式数据处理。Logstash是一个高度可扩展的工具,能够处理大量的数据,并支持分布式部署。它能够与Elasticsearch、Kibana、Beats等工具集成,构建一个强大的、可扩展的数据分析平台。Logstash提供了丰富的文档和社区支持,方便用户学习和使用。
Logstash工作原理

如上图,Logstash的数据处理过程主要包括:Inputs, Filters, Outputs 三部分, 另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。这四个部分均以插件形式存在,用户通过定义pipeline配置文件,设置需要使用的input,filter,output, codec插件,以实现特定的数据采集,数据处理,数据输出等功能
-
Inputs: 用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等
-
Filters: 用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等
-
Outputs: 用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等
-
Codecs: Codecs不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline
Logstash核心概念
- Pipeline: 包含了input—filter-output三个阶段的处理流程、插件生命周期管理、队列管理
- Logstash Event: 数据在内部流转时的具体表现形式
- 数据在input 阶段被转换为Event,在 output被转化成目标格式数据
- Event 其实是一个Java Object,在配置文件中,对Event 的属性进行增删改查
- Codec (Code / Decode): 将原始数据decode成Event,将Event encode成目标数据

Kibana 文档地址:
https://www.elastic.co/guide/cn/kibana/current/install.html
Kibana是一个数据可视化工具,能够通过仪表盘、图形和地图等方式展示数据。主要用于展示和分析从Elasticsearch中获取的数据。Kibana能够实现以下功能:
- 数据可视化: Kibana能够通过仪表盘、图形和地图等方式展示数据,支持多种数据类型和格式。
- 数据查询: Kibana能够实现对Elasticsearch中存储的数据进行查询和搜索。
- 仪表盘管理: Kibana能够创建、管理和共享仪表盘,方便用户展示和分享数据。
- 可视化插件: Kibana提供了丰富的可视化插件,方便用户扩展和定制功能。
- 数据分析: Kibana能够实现对数据进行聚合、过滤和分析,支持实时数据处理。Kibana的主要优点包括易用性、可- 扩展性和丰富的功能。它能够与Elasticsearch、Logstash、Beats等工具集成,构建一个强大的、可扩展的数据分析平台。Kibana提供了丰富的文档和社区支持,方便用户学习和使用。
环境准备
使用模板机克隆elk并配置如下参数
| 主机 | IP地址 | 网关 | DNS | 配额 |
|---|---|---|---|---|
| elk | 192.168.8.111/24 | 192.168.8.254 | 192.168.8.254 | 1CPU2G内存 |
[root@template ~]# hostnamectl set-hostname elk #配置主机名
[root@elk ~]# nmcli connection modify ens160 ipv4.method manual ipv4.addresses 192.168.8.111/24 ipv4.gateway 192.168.8.254 ipv4.dns 192.168.8.254 connection.autoconnect yes #配置入网参数
[root@elk ~]# nmcli connection up ens160 #激活网卡
安装部署docker
开启路由转发,docker是通过虚拟交换机来进行通讯的,需要开启路由转发的功能
[root@elk ~]# echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
[root@elk ~]# sysctl -p #sysctl -p 让配置立刻生效(否则需要重启虚拟机)
将docker上传至虚拟机elk的/root
[root@docker-0001 ~]# dnf remove podman #卸载冲突的软件包
[root@docker-0001 ~]# dnf remove runc
[root@docker-0001 ~]# cd /root/docker
[root@docker-0001 docker]# dnf -y localinstall *.rpm #安装docker
添加镜像加速器
使用华为云的镜像加速器,每个人的都不一样
[root@elk ~]# vim /etc/docker/daemon.json
[root@elk ~]# vim /etc/docker/daemon.json
{"registry-mirrors": ["这里配置镜像仓库加速器地址"],"insecure-registries":[]
}
[root@elk ~]# systemctl restart docker
[root@elk ~]# docker info
安装部署Elasticsearch
[root@elk ~]# docker network create -d bridge elk #创建网络
[root@elk ~]# docker network ls #查看网络
[root@elk ~]# docker search elasticsearch #搜索镜像
[root@elk ~]# docker pull elasticsearch:7.12.1 #下载镜像elasticsearch:7.12.1
[root@elk ~]# docker images #查看镜像
# 运行 elasticsearch
[root@elk ~]# docker run -d --name es --net elk -P -e "discovery.type=single-node" elasticsearch:7.12.1# 进入容器查看配置文件路径
[root@elk ~]# docker exec -it es /bin/bash
[root@f84bda6f8389 elasticsearch] cd config[root@f84bda6f8389 config]# ls
elasticsearch.keystore jvm.options.d role_mapping.yml users_roles
elasticsearch.yml log4j2.file.properties roles.yml
jvm.options log4j2.properties users[root@f84bda6f8389 config]# pwd
/usr/share/elasticsearch/config
# 在 config 中可看到 elasticsearch.yml 配置文件,
# 再执行 pwd 可以看到当前目录为: /usr/share/elasticsearch/config,所以退出容器,执行文件的拷贝
[root@f84bda6f8389 config]# exit
# 将容器内的配置文件拷贝到 /usr/local/elk/elasticsearch/ 中
[root@elk ~]# mkdir -p /usr/local/elk/elasticsearch
[root@elk ~]# docker cp es:/usr/share/elasticsearch/config/elasticsearch.yml /usr/local/elk/elasticsearch[root@elk ~]# vim /usr/local/elk/elasticsearch/elasticsearch.yml
#此处省略1万字...在最后一行下方添加
http.cors.enabled: true
http.cors.allow-origin: "*"# 注意:这里要修改文件的权限为可写,否则进行挂载后,在外部修改配置文件,容器内部的配置文件不会更改
# 同时,创建 data 目录进行挂载。
# 修改文件权限
[root@elk ~]# chmod 666 /usr/local/elk/elasticsearch/elasticsearch.yml
[root@elk ~]# mkdir -p /usr/local/elk/elasticsearch/data
[root@elk ~]# chmod -R 777 /usr/local/elk/elasticsearch/data
#重新运行容器并挂载
[root@elk ~]# docker rm -f es #删除测试容器es
# 运行新的容器
[root@elk ~]# docker run -d --name es \
--net elk \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
--privileged=true \
-v /usr/local/elk/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /usr/local/elk/elasticsearch/data:/usr/share/elasticsearch/data \
elasticsearch:7.12.1[root@elk ~]# docker ps
浏览器访问地址:http://192.168.8.111:9200/

安装ElasticSearch-head(可选)
说明:ElasticSearch-head是 ES的可视化界面,是为了方便后面调试时看日志有没成功输入到 ES 用的,非必须安装的项目,也可跳过此步。
拉取镜像
[root@elk ~]# docker pull mobz/elasticsearch-head:5
运行容器
[root@elk ~]# docker run -d --name es_admin --net elk -p 9100:9100 mobz/elasticsearch-head:5
[root@elk ~]# docker ps
页面无数据问题
如果打开页面之后节点、索引等显示完全,但是数据浏览中无数据显示,那么我们还需要改一个配置文件,这是因为 ES 6 之后增加了请求头严格校验的原因(我们装的是 7.12.1 版本)
[root@elk ~]# docker cp es_admin:/usr/src/app/_site/vendor.js ./
[root@elk ~]# vim vendor.js
#6886行:contentType: "application/json;charset=UTF-8"
#7573行: contentType === "application/json;charset=UTF-8"
# 改完后再将配置文件 copy 回容器,不需重启,直接刷新页面即可。[root@elk ~]# docker cp vendor.js es_admin:/usr/src/app/_site/
测试
浏览器访问地址:http://192.168.8.111:9100/

安装Kibana
root@localhost ~]# docker search kibana
[root@elk ~]# docker pull kibana:7.12.1# 注意: -e “ELASTICSEARCH_HOSTS=http://es:9200” 表示连接刚才启动的 elasticsearch 容器,
# 因为在同一网络(elk)中,地址可直接填 容器名+端口,即 es:9200, 也可以填 http://192.168.138.174:9200,即 http://ip:端口。
[root@elk ~]# docker run -d --name kibana --net elk -P -e "ELASTICSEARCH_HOSTS=http://es:9200" -e "I18N_LOCALE=zh-CN" kibana:7.12.1 #运行容器
#将容器内kibana的配置文件拷贝出来
[root@elk ~]# mkdir -p /usr/local/elk/kibana/
[root@elk ~]# docker cp kibana:/usr/share/kibana/config/kibana.yml /usr/local/elk/kibana/
[root@elk ~]# chmod 666 /usr/local/elk/kibana/kibana.yml# 拷贝完成后,修改该配置文件,主要修改 elastissearch.hosts 并新增 i18n.locale 配置:
# 1. es 地址改为刚才安装的 es 地址,因容器的隔离性,这里最好填写 http://ip:9200
# 2. kibana 界面默认是英文的,可以在配置文件中加上 i18n.locale: zh-CN(注意冒号后面有个空格)
# 这样有了配置文件,在启动容器时就不用通过 -e 指定环境变量了
# 注意:
# 如果使用挂载配置文件的方式启动的话,elasticsearch.hosts 这需填写 http://ip:9200,而不能使用容器名了,否则后面 kibana 连接 es 会失败。
[root@elk ~]# vim /usr/local/elk/kibana/kibana.yml
# 注意这个ip是docker容器内部的IP,不是虚拟机的,可以使用 docker inspect es来查看
elasticsearch.hosts: [ "http://172.18.0.2:9200" ]
i18n.locale: zh-CN
#删除原来未挂载的容器
[root@elk ~]# docker rm -f kibana#启动容器并挂载
[root@elk ~]# docker run -d --name kibana -p 5601:5601 -v /usr/local/elk/kibana/kibana.yml:/usr/share/kibana/config/kibana.yml --net elk kibana:7.12.1
浏览器访问地址:http://192.168.8.111:9100/

测试
开始使用 Kibana 前,需要告诉 Kibana 您想要探索的 Elasticsearch 索引。第一次访问 Kibana 时,会提示您定义一个 index pattern(索引模式) 匹配一个或多个索引。这就是初次使用 Kibana 时所有需要配置的。任何时候都可以在 Management 页面增加索引模式。
默认情况下,Kibana 会连接运行在 localhost 上的 Elasticsearch 实例。如果需要连接不同的 Elasticsearch实例,可以修改 kibana.yml 配置文件中的 Elasticsearch URL 配置项并重启 Kibana。如果在生产环境节点上使用 Kibana
设置您想通过 Kibana 访问的 Elasticsearch 索引:
浏览器中指定端口号5601来访问 Kibana UI 页面。例如, localhost:5601 或者 http://YOURDOMAIN.com:5601

指定一个索引模式来匹配一个或多个 Elasticsearch 索引名称。默认情况下,Kibana 会认为数据是通过 Logstash 解析送进 Elasticsearch 的。这种情况可以使用默认的 logstash-* 作为索引模式。星号 (*) 匹配0或多个索引名称中的字符。如果 Elasticsearch 索引遵循其他命名约定,请输入一个恰当的模式。该模式也可以直接用单个索引的名称。
如果您想做一些基于时间序列的数据比较,可以选择索引中包含时间戳的字段。Kibana 会读取索引映射,列出包含时间戳的所有字段。如果索引中没有基于时间序列的数据,则禁用 Index contains time-based events 选项。
点击 Create 增加索引模式。默认情况下,第一个模式被自动配置为默认的。当索引模式不止一个时,可以通过点击 Management > Index Patterns 索引模式题目上的星星图标来指定默认的索引模式。
全部设置完毕!Kibana 连接了 Elasticsearch 的数据。展示了一个匹配到的索引的字段只读列表。
浏览器访问地址:http://192.168.8.111:5601/

Docker 安装 LogStash
拉取镜像并拷贝配置
[root@elk ~]# docker pull logstash:7.12.1
[root@elk ~]# docker run -d -P --name logstash --net elk logstash:7.12.1# 拷贝数据
[root@elk ~]# mkdir -p /usr/local/elk/logstash/
[root@elk ~]# docker cp logstash:/usr/share/logstash/config /usr/local/elk/logstash/
[root@elk ~]# docker cp logstash:/usr/share/logstash/data /usr/local/elk/logstash/
[root@elk ~]# docker cp logstash:/usr/share/logstash/pipeline /usr/local/elk/logstash/#文件夹赋权
[root@elk ~]# chmod -R 777 /usr/local/elk/logstash/
修改相应配置文件
修改 logstash/config 下的 logstash.yml 文件,主要修改 es 的地址(可通过 docker inspect es查看地址):
[root@elk ~]# vim /usr/local/elk/logstash/config/logstash.yml
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://172.18.0.2:9200" ]
修改 logstash/pipeline 下的logstash.conf文件:
[root@elk ~]# vim /usr/local/elk/logstash/pipeline/logstash.confinput {tcp {mode => "server"host => "0.0.0.0" # 允许任意主机发送日志port => 5044codec => json_lines # 数据格式}
}output {elasticsearch {hosts => ["http://172.18.0.2:9200"] # ElasticSearch 的地址和端口index => "elk" # 指定索引名codec => "json"}stdout {codec => rubydebug}
}
启动容器并挂载
#注意先删除之前的容器
[root@elk ~]# docker rm -f logstash# 启动容器并挂载
[root@elk ~]# docker run -d --name logstash --net elk \
--privileged=true \
-p 5044:5044 -p 9600:9600 \
-v /usr/local/elk/logstash/data/:/usr/share/logstash/data \
-v /usr/local/elk/logstash/config/:/usr/share/logstash/config \
-v /usr/local/elk/logstash/pipeline/:/usr/share/logstash/pipeline \
logstash:7.12.1
项目地址:
https://gitee.com/houyworking/elk.git
注意:该项目已经搭建好,只需要把对应 resource 下的 log/logback-springxml文件中的 <destination></destination>标签中 logstash 的地址换成对应自己的即可
创建springboot应用
这个比较简单,主要就是几个配置文件:
pom文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.tedu</groupId><artifactId>elk</artifactId><version>0.0.1-SNAPSHOT</version><name>elk</name><description>elk</description><properties><java.version>1.8</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><spring-boot.version>2.6.13</spring-boot.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>net.logstash.logback</groupId><artifactId>logstash-logback-encoder</artifactId><version>6.6</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>${spring-boot.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>${spring-boot.version}</version><configuration><mainClass>com.tedu.elk.ElkApplication</mainClass><skip>true</skip></configuration><executions><execution><id>repackage</id><goals><goal>repackage</goal></goals></execution></executions></plugin></plugins></build></project>
创建一个TestController,每次调用接口,都会打印日志
package com.tedu.elk.controller;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.UUID;@RestController
public class TestController {private final static Logger logger = LoggerFactory.getLogger(TestController.class);@GetMapping("/index")public String index() {String uuid = UUID.randomUUID().toString();logger.info("TestController info " + uuid);return "hello elk " + uuid;}
}
在 resource 下创建log/logback-springxml文件,这里我们主要填写 ip:端口,关于标签则看个人使用情况修改。
<?xml version="1.0" encoding="UTF-8"?>
<configuration><include resource="org/springframework/boot/logging/logback/base.xml" /><appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender"><destination>192.168.8.111:5044</destination><!-- 日志输出编码 --><encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"><providers><timestamp><timeZone>UTC</timeZone></timestamp><pattern><pattern>{<!--es索引名称 -->"index":"elk",<!--应用名称 -->"appname":"${spring.application.name}",<!--打印时间 -->"timestamp": "%d{yyyy-MM-dd HH:mm:ss.SSS}",<!--线程名称 -->"thread": "%thread",<!--日志级别 -->"level": "%level",<!--日志名称 -->"logger_name": "%logger",<!--日志信息 -->"message": "%msg",<!--日志堆栈 -->"stack_trace": "%exception"}</pattern></pattern></providers></encoder></appender><root level="INFO"><appender-ref ref="LOGSTASH" /><appender-ref ref="CONSOLE" /></root>
</configuration>
最后修改 application.yml 文件:
server:port: 8080logging:config: classpath:log/logback-spring.xml
查看 es-head


查看Kibana





测试:调用接口 http://localhost:8080/index
再次查看 Kibana ,已经显示了在代码中打印的日志:

相关文章:
徒手从零搭建一套ELK日志平台
徒手从零搭建一套ELK日志平台 日志分析的概述日志分析的作用主要收集工具集中式日志系统主要特点采集日志分类ELK概述初级版ELK终极版ELK高级版ELKELK收集日志的两种形式 搭建ELK平台Logstash工作原理Logstash核心概念环境准备安装部署docker添加镜像加速器安装部署Elasticsear…...

udp_socket
文章目录 UDP服务器封装系统调用socketbind系统调用bzero结构体清0sin_family端口号ip地址inet_addrrecvfromsendto 新指令 netstat -naup (-nlup)包装器 的两种类型重命名方式包装器使用统一可调用类型 关键字 typedef 类型重命名系统调用popen UDP服务器封装 系统调用socket …...

肝了半年,我整理出了这篇云计算学习路线(新手必备,从入门到精通)
大家好!我是凯哥,今天给大家分享一下云计算学习路线图。这是我按照自己最开始学习云计算的时候的学习路线,并且结合自己从业多年所涉及的知识精心总结的云计算的思维导图。这是凯哥精心总结的,花费了不少精力哦,希望对…...

【Golang】手搓DES加密
代码非常长 有六百多行 参考一位博主的理论实现 通俗易懂,十分钟读懂DES 还有很多不足的地方 感觉只是个思路 S盒(理论既定) package src// 定义S - 盒的置换表 var SBoxes [8][4][16]int{{{14, 4, 13, 1, 2, 15, 11, 8, 3, 10, 6, 12, …...

YouQu使用手册【元素定位】
元素定位 文章目录 前言一、气泡识别二、不依赖OpenCV的图像识别方案三、动态图像识别四、背景五、sniff(嗅探器)使用六、元素操作七、框架封装八、背景【OCR识别】九、实现原理十、使用说明十一、RPC服务端部署十二、负载均衡十三、链式调用十四、背景【相对坐标定位】十五、…...

Spark RDD sortBy算子什么情况会触发shuffle
在 Spark 的 RDD 中,sortBy 是一个排序算子,虽然它在某些场景下可能看起来是分区内排序,但实际上在需要全局排序时会触发 Shuffle。这里我们分析其底层逻辑,结合源码和原理来解释为什么会有 Shuffle 的发生。 1. 为什么 sortBy 会…...

机器视觉相机重要名词
机器视觉相机的重要名词包括: • 工业数字相机:又称工业相机,是机器视觉系统中的关键组件。 • 电荷偶合元件(CCD):一种图像传感器,能将光学影像转换为数字信号。 • 互补金属氧化物半导体&…...

Django:从入门到精通
一、Django背景 Django是一个由Python编写的高级Web应用框架,以其简洁性、安全性和高效性而闻名。Django最初由Adrian Holovaty和Simon Willison于2003年开发,旨在简化Web应用的开发过程。作为一个开放源代码项目,Django迅速吸引了大量的开发…...

android viewpager2 嵌套 recyclerview 手势冲突
老规矩直接上代码, 不分析: import android.content.Context import android.util.AttributeSet import android.view.MotionEvent import android.view.View import android.view.ViewConfiguration import android.view.ViewGroup import android.widg…...
)
依赖管理(go mod)
目录 各版本依赖管理的时间分布 一、GOPATH 1. GOROOT是什么 定义: 作用: 默认值: 是否需要手动设置: 查看当前的 GOROOT: 2. GOPATH:工作区目录 定义: 作用:…...

Apple Vision Pro开发001-开发配置
一、Vision Pro开发硬件和软件要求 硬件要求软件要求 1、Apple Silicon Mac(M系列芯片的Mac电脑) 2、Apple vision pro-真机调试 XCode15.2及以上,调试开发和打包发布Unity开发者账号&&苹果开发者账号 二 、开启无线调试 1、Apple Vision Pro和Mac连接同…...

android 动画原理分析
一 android 动画分为app内的view动画和系统动画 基本原理都是监听Choreographer的doframe回调 二 app端的实现是主要通过AnimationUtils来实现具体属性的变化通过invilate来驱动 wms来进行更新。这个流程是在app进程完成 这里不是我分析的重点 直接来看下系统动画里面的本地动…...

Elasticsearch 6.8 分析器
在 Elasticsearch 中,分析器(Analyzer)是文本分析过程中的一个关键组件,它负责将原始文本转换为一组词汇单元(tokens)。 分析器由三个主要部分组成:分词器(Tokenizer)、…...

实验室资源调度系统:基于Spring Boot的创新
2相关技术 2.1 MYSQL数据库 MySQL是一个真正的多用户、多线程SQL数据库服务器。 是基于SQL的客户/服务器模式的关系数据库管理系统,它的有点有有功能强大、使用简单、管理方便、安全可靠性高、运行速度快、多线程、跨平台性、完全网络化、稳定性等,非常…...

实验三:构建园区网(静态路由)
目录 一、实验简介 二、实验目的 三、实验需求 四、实验拓扑 五、实验任务及要求 1、任务 1:完成网络部署 2、任务 2:设计全网 IP 地址 3、任务 3:实现全网各主机之间的互访 六、实验步骤 1、在 eNSP 中部署网络 2、配置各主机 IP …...

3. SQL优化
SQL性能优化 在日常开发中,MySQL性能优化是一项必不可少的技能。本文以具体案例为主线,结合实际问题,探讨如何优化插入、排序、分组、分页、计数和更新等操作,帮助你实现数据库性能的飞跃。 一、索引设计原则 索引是MySQL优化的…...

web——upload-labs——第十一关——黑名单验证,双写绕过
还是查看源码, $file_name str_ireplace($deny_ext,"", $file_name); 该语句的作用是:从 $file_name 中去除所有出现在 $deny_ext 数组中的元素,替换为空字符串(即删除这些元素)。str_ireplace() 在处理时…...

AWS CLI
一、AWS CLI介绍 1、简介 AWS CLI(Amazon Web Services Command Line Interface)是一个命令行工具,它允许用户通过命令行与 Amazon Web Services(AWS)的各种云服务进行交互和管理。使用 AWS CLI,用户可以直接在终端或命令行界面中执行命令来配置、管理和自动化AWS资源,…...

springboot:责任链模式实现多级校验
责任链模式是将链中的每一个节点看作是一个对象,每个节点处理的请求不同,且内部自动维护一个下一节点对象。 当一个请求从链式的首段发出时,会沿着链的路径依此传递给每一个节点对象,直至有对象处理这个请求为止。 属于行为型模式…...
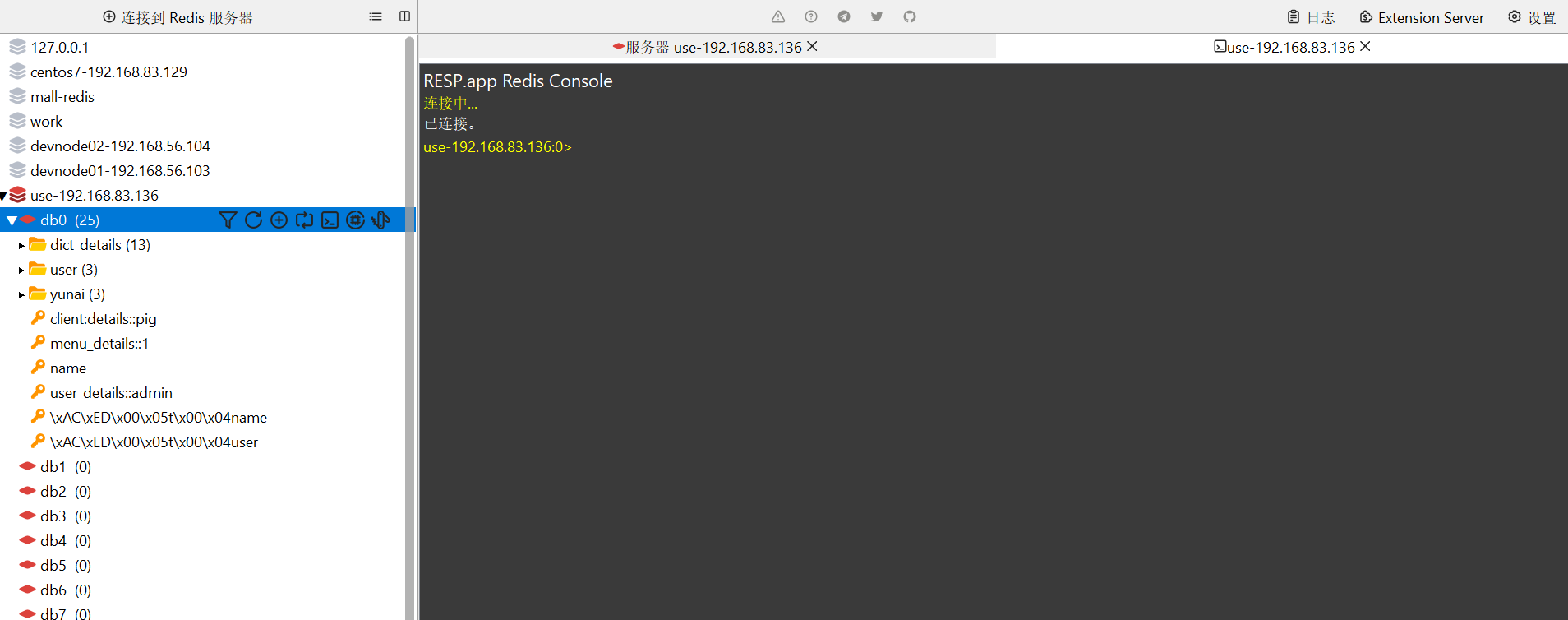
CentO7安装单节点Redis服务
本文目录 一、Redis安装与配置1.1 安装redis依赖1.2 上传压缩包并解压1.3 编译安装1.4 修改配置并启动1、复制配置文件2、修改配置文件3、启动Redis服务4、停止redis服务 1.5 redis连接使用1、 命令行客户端2、 图形界面客户端 一、Redis安装与配置 1.1 安装redis依赖 Redis是…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...

【电力电子】基于STM32F103C8T6单片机双极性SPWM逆变(硬件篇)
本项目是基于 STM32F103C8T6 微控制器的 SPWM(正弦脉宽调制)电源模块,能够生成可调频率和幅值的正弦波交流电源输出。该项目适用于逆变器、UPS电源、变频器等应用场景。 供电电源 输入电压采集 上图为本设计的电源电路,图中 D1 为二极管, 其目的是防止正负极电源反接, …...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...

【Linux】Linux 系统默认的目录及作用说明
博主介绍:✌全网粉丝23W,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物…...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...

深度剖析 DeepSeek 开源模型部署与应用:策略、权衡与未来走向
在人工智能技术呈指数级发展的当下,大模型已然成为推动各行业变革的核心驱动力。DeepSeek 开源模型以其卓越的性能和灵活的开源特性,吸引了众多企业与开发者的目光。如何高效且合理地部署与运用 DeepSeek 模型,成为释放其巨大潜力的关键所在&…...
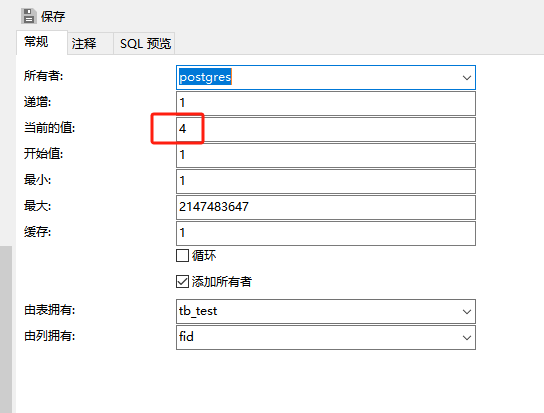
pgsql:还原数据库后出现重复序列导致“more than one owned sequence found“报错问题的解决
问题: pgsql数据库通过备份数据库文件进行还原时,如果表中有自增序列,还原后可能会出现重复的序列,此时若向表中插入新行时会出现“more than one owned sequence found”的报错提示。 点击菜单“其它”-》“序列”,…...