网络爬虫——分布式爬虫架构
分布式爬虫在现代大数据采集中是不可或缺的一部分。随着互联网信息量的爆炸性增长,单机爬虫在性能、效率和稳定性上都面临巨大的挑战。分布式爬虫通过任务分发、多节点协作以及结果整合,成为解决大规模数据抓取任务的核心手段。
本节将从 Scrapy 框架的基本使用、Scrapy-Redis 的分布式实现、分布式爬虫的优化策略 等多个方面展开,结合实际案例,帮助开发者掌握分布式爬虫的设计与实现。
1. Scrapy 框架的核心概念与高效使用
1.1 什么是 Scrapy?
Scrapy 是 Python 中最流行的爬虫框架之一,它支持异步 IO,拥有高度模块化的结构,尤其适合高效抓取任务。Scrapy 的设计遵循爬虫的核心逻辑:请求发送、数据提取、数据存储。
1.2 Scrapy 的核心组件
理解 Scrapy 的核心组件对于优化爬虫性能至关重要。
-
Spider(爬虫模块)
定义抓取目标与逻辑的核心模块。例如:- 爬取的 URL 列表。
- 页面解析规则(如 XPath、CSS 选择器)。
- 数据提取与存储逻辑。
-
Request(请求模块)
负责构造 HTTP 请求,支持 GET/POST 方法、Cookie、Headers 等高级配置。 -
Scheduler(调度器)
调度请求的优先级和顺序,是分布式爬虫的核心环节。 -
Item(数据模块)
定义爬取的结构化数据格式。 -
Pipeline(数据处理模块)
负责清洗、格式化和存储爬取到的数据,例如存入 CSV、数据库或其他存储系统。
1.3 提升 Scrapy 性能的关键点
-
使用异步下载器
Scrapy 默认使用 Twisted 异步网络库,可以极大提高并发性能。 -
优化并发数和延迟设置
配置settings.py:CONCURRENT_REQUESTS = 32 # 并发请求数量 DOWNLOAD_DELAY = 0.25 # 每个请求的间隔时间 -
缓存与去重
启用 HTTP 缓存以避免重复下载:HTTPCACHE_ENABLED = True HTTPCACHE_EXPIRATION_SECS = 3600 # 缓存过期时间 -
扩展功能
利用中间件、扩展和插件提高灵活性,如自定义代理池、用户代理切换等。
1.4 实战:构建 Scrapy 爬虫
以下代码展示如何使用 Scrapy 爬取示例网站,并提取标题与链接:
import scrapyclass ExampleSpider(scrapy.Spider):name = "example_spider"start_urls = ["https://example.com"]def parse(self, response):# 提取所有标题和链接for item in response.css('div.article'):yield {'title': item.css('h2::text').get(),'link': item.css('a::attr(href)').get(),}# 继续爬取下一页next_page = response.css('a.next::attr(href)').get()if next_page:yield response.follow(next_page, self.parse)2. Scrapy-Redis 实现分布式爬虫
2.1 分布式爬虫的挑战
- 任务分发:如何将 URL 或任务均匀分布到各节点。
- 结果整合:如何将多个爬虫节点的抓取结果统一存储和处理。
- 去重与调度:如何避免重复爬取,并确保任务按优先级进行。
2.2 Scrapy-Redis 的核心思想
-
Redis 作为任务调度中心
- Scrapy-Redis 将所有任务存入 Redis 的任务队列,爬虫节点从 Redis 中提取任务,实现分布式协作。
-
去重机制
- 利用 Redis 的集合结构对 URL 去重,避免重复抓取。
2.3 安装与配置
-
安装 Scrapy 和 Scrapy-Redis:
pip install scrapy scrapy-redis -
修改 Scrapy 项目的配置文件
settings.py:SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 启用分布式调度器 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用 Redis 去重 SCHEDULER_PERSIST = True # 任务队列持久化 REDIS_HOST = 'localhost' # Redis 地址 REDIS_PORT = 6379 # Redis 端口 -
编写爬虫代码:
from scrapy_redis.spiders import RedisSpiderclass DistributedSpider(RedisSpider):name = "distributed_spider"redis_key = "distributed:start_urls" # Redis 中的任务队列名称def parse(self, response):title = response.xpath('//title/text()').get()yield {'title': title} -
启动 Redis 服务:
redis-server -
添加任务到 Redis:
redis-cli lpush distributed:start_urls "https://example.com" -
启动多个爬虫节点:
scrapy runspider distributed_spider.py
2.4 分布式爬虫的优化
-
动态代理池
使用 IP 池应对 IP 封禁,例如通过开源库 ProxyPool 构建代理服务。 -
分层任务调度
将不同优先级的任务分配到不同的队列,提升调度效率。 -
去重优化
配置 Redis 的过期策略,清理长时间未使用的 URL。 -
分布式存储
结合 Redis 和分布式文件系统(如 HDFS),提高数据存储和访问效率。
3. 分布式爬虫的应用场景与实践
3.1 应用场景
-
新闻爬取与实时监控
实时抓取新闻网站的最新内容,用于舆情分析和关键词挖掘。 -
电商数据采集
抓取多个电商平台的价格、评价、库存等信息,构建价格比较系统。 -
知识图谱构建
抓取学术论文、百科内容,构建知识图谱。
3.2 实战:大型新闻爬取案例
以下是一个抓取新闻数据的分布式爬虫示例:
from scrapy_redis.spiders import RedisSpiderclass NewsSpider(RedisSpider):name = 'news_spider'redis_key = 'news:start_urls'def parse(self, response):for article in response.css('div.news-item'):yield {'title': article.css('h2::text').get(),'url': article.css('a::attr(href)').get(),'summary': article.css('p.summary::text').get(),}3.3 优缺点总结
-
优点:
- 高效率:支持多节点并行,显著提升爬取速度。
- 可扩展性:支持动态扩展节点。
- 容错性:单节点故障不会影响整体任务。
-
缺点:
- 部署复杂:需要配置 Redis、代理池等。
- 数据一致性:分布式环境下的数据整合难度较大。
总结
分布式爬虫通过任务分发和节点协作,解决了单机爬虫性能瓶颈问题。Scrapy-Redis 提供了灵活的分布式架构,使得任务调度和数据整合更加高效。在实际项目中,根据业务需求选择合理的分布式策略,结合动态代理、数据存储优化等技术,构建性能稳定的爬虫系统。
相关文章:

网络爬虫——分布式爬虫架构
分布式爬虫在现代大数据采集中是不可或缺的一部分。随着互联网信息量的爆炸性增长,单机爬虫在性能、效率和稳定性上都面临巨大的挑战。分布式爬虫通过任务分发、多节点协作以及结果整合,成为解决大规模数据抓取任务的核心手段。 本节将从 Scrapy 框架的…...

RT_Thread内核源码分析(三)——线程
目录 1. 线程结构 2. 线程创建 2.1 静态线程创建 2.2 动态线程创建 2.3 源码分析 2.4 线程内存结构 3. 线程状态 3.1 线程状态分类 3.2 就绪状态和运行态 3.3 阻塞/挂起状态 3.3.1 阻塞工况 3.4 关闭状态 3.4.1 线程关闭接口 3.4.2 静态线程关闭 3.4.3 动态线程关…...

正排索引和倒排索引
一、简介 正排索引:一个未经处理的数据库中,一般是以文档ID作为索引,以文档内容作为记录。 倒排索引:Inverted index,指的是将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或…...

丹摩 | 重返丹摩(上)
目录 一.登录平台 二. 数据管理与预处理 1.数据清洗 2.数据格式转换 3.特征工程 二.数据可视化 1.快速可视化 2.数据洞察 3.自定义视图 三.技术支持与帮助 1.技术支持 (1). 帮助文档 (2). 用户社区 2.客服支持 (1). 在线客服 (2). 反馈与建议 总结 一.登录平台…...

Frontend - 防止多次请求,避免重复请求
目录 一、避免重复执行的多种情况 (一)根据用途 (二)根据用户操作 二、具体实现 (一)“Ajax ”结合disabled (防止多次请求),避免多次点击重复请求 1. 适用场景 2. 解决办法 3. 示例 &…...
)
RHCE的学习(22)
第四章 流程控制之条件判断 条件判断语句是一种最简单的流程控制语句。该语句使得程序根据不同的条件来执行不同的程序分支。本节将介绍Shell程序设计中的简单的条件判断语句。 if语句语法 单分支结构 # 语法1: if <条件表达式> then指令 fi #语法2&#x…...

【前端知识】简单讲讲什么是微前端
微前端介绍 一、定义二、背景三、核心思想四、基本要素五、核心价值六、实现方式七、应用场景八、挑战与解决方案 什么是single-spa一、核心特点二、核心原理三、应用加载流程四、最佳实践五、优缺点六、应用场景 什么是 qiankun一、概述二、特点与优势三、核心功能四、使用场景…...

AWS IAM
一、介绍 1、简介 AWS Identity and Access Management (IAM) 是 Amazon Web Services 提供的一项服务,用于管理 AWS 资源的访问权限。通过 IAM,可以安全地控制用户、组和角色对 AWS 服务和资源的访问权限。IAM 是 AWS 安全模型的核心组成部分,确保只有经过授权的用户和应…...

丹摩|丹摩助力selenium实现大麦网抢票
丹摩|丹摩助力selenium实现大麦网抢票 声明:非广告,为用户体验 1.引言 在人工智能飞速发展的今天,丹摩智算平台(DAMODEL)以其卓越的AI算力服务脱颖而出,为开发者提供了一个简化AI开发流程的强…...

基于Qt/C++/Opencv实现的一个视频中二维码解析软件
本文详细讲解了如何利用 Qt 和 OpenCV 实现一个可从视频和图片中检测二维码的软件。代码实现了视频解码、多线程处理和界面更新等功能,是一个典型的跨线程图像处理项目。以下分模块对代码进行解析。 一、项目的整体结构 项目分为以下几部分: 主窗口 (M…...

智慧理财项目测试文档
目录 幕布思维导图链接:https://www.mubu.com/doc/6xk3c7DzgFs学习链接:https://www.bilibili.com/video/BV15J4m147vZ/?spm_id_from333.999.0.0&vd_source078d5d025b9cb472d70d8fda1a7dc5a6智慧理财项目测试文档项目介绍项目基本信息项目业务特性系…...

R | 统一栅格数据的坐标系、分辨率和行列号
各位同学,在做相关性等分析时,经常会遇到各栅格数据间的行列号不统一等问题,下面的代码能直接解决这类麻烦。以某个栅格数据的坐标系、分辨率和行列号为准,统一文件夹内所有栅格并输出到新的文件夹。 代码只需要更改输入输出和ti…...

C++学习——编译的过程
编译的过程——预处理 引言预处理包含头文件宏定义指令条件编译 编译、链接 引言 C程序编译的过程:预处理 -> 编译(优化、汇编)-> 链接 编译和链接的内容可以查阅这篇文章(点击查看) 预处理 编译预处理是指&a…...

当你要改文件 但是原来的文件内容又不能丢失的时候,拷贝一份(备注原来的),然后添加后缀:.bak
当你要改文件 但是原来的文件内容又不能丢失的时候,拷贝一份(备注原来的),然后添加后缀:.bak !!!文件不要直接删除,若你以后要还原的话会找不到...

MATLAB神经网络(五)——R-CNN视觉检测
5.1 目标分类、检测与分割 在计算机视觉领域,目标分类、检测与分割是常用计数。三者的联系与区分又在哪呢?目标分类是解决图像中的物体是什么的问题;目标检测是解决图像中的物体是什么,在哪里的问题;目标分割时将目标和…...

mock.js:定义、应用场景、安装、配置、使用
前言:什么是mock.js? 作为一个前端程序员,没有mockjs你不感觉很被动吗?你不感觉你的命脉被后端那个男人掌握了吗?所以,我命由我不由天!学学mock.js吧! mock.js 是一个用于生成随机…...

【GAT】 代码详解 (1) 运行方法【pytorch】可运行版本
GRAPH ATTENTION NETWORKS 代码详解 前言0.引言1. 环境配置2. 代码的运行2.1 报错处理2.2 运行结果展示 3.总结 前言 在前文中,我们已经深入探讨了图卷积神经网络和图注意力网络的理论基础。还没看的同学点这里补习下。接下来,将开启一个新的阶段&#…...
Transformer中的Self-Attention机制如何自然地适应于目标检测任务
Transformer中的Self-Attention机制如何自然地适应于目标检测任务: 特征图的降维与重塑 首先,Backbone(如ResNet、VGG等)会输出一个特征图,这个特征图通常具有较高的通道数、高度和宽度(例如CHWÿ…...

2411rust,1.75.0
原文 Rust团队很高兴地声明推出Rust的新版本1.75.0. 如果你rustup安装了以前版本的Rust,你可如下取1.75.0: $ rustup update stable1.75.0稳定版中的功能 async fn和特征中的返回位置impl Trait. 指针字节偏移API 原始指针(*const T和*mutT)过去主要支持,T为单位的操作.如…...

远程办公新宠:分享8款知识共享软件
远程办公模式下,知识共享软件成为了团队协作和沟通的重要工具。以下是8款备受推崇的知识共享软件: 1、HelpLook AI知识库 简介:HelpLook是一款快速搭建AI知识库的系统,具备强大功能,如快速精准的知识检索、灵活定制的…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...
:LeetCode 142. 环形链表 II(Linked List Cycle II)详解)
Java详解LeetCode 热题 100(26):LeetCode 142. 环形链表 II(Linked List Cycle II)详解
文章目录 1. 题目描述1.1 链表节点定义 2. 理解题目2.1 问题可视化2.2 核心挑战 3. 解法一:HashSet 标记访问法3.1 算法思路3.2 Java代码实现3.3 详细执行过程演示3.4 执行结果示例3.5 复杂度分析3.6 优缺点分析 4. 解法二:Floyd 快慢指针法(…...
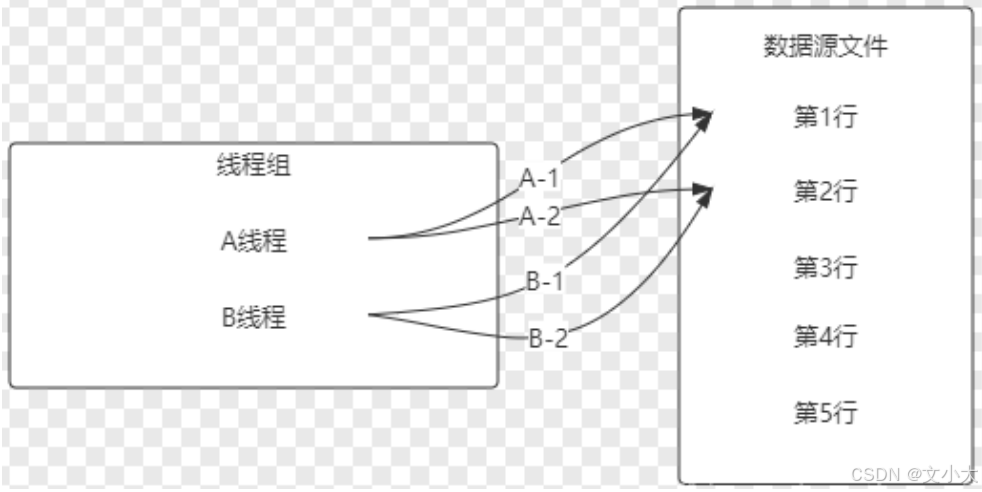
五、jmeter脚本参数化
目录 1、脚本参数化 1.1 用户定义的变量 1.1.1 添加及引用方式 1.1.2 测试得出用户定义变量的特点 1.2 用户参数 1.2.1 概念 1.2.2 位置不同效果不同 1.2.3、用户参数的勾选框 - 每次迭代更新一次 总结用户定义的变量、用户参数 1.3 csv数据文件参数化 1、脚本参数化 …...
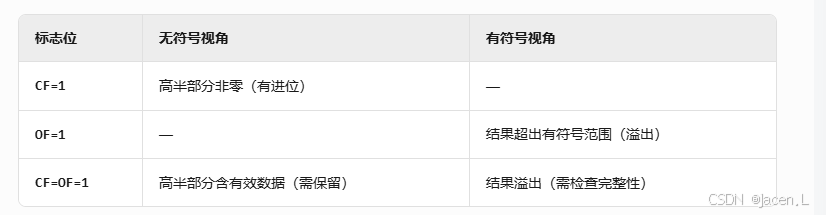
【汇编逆向系列】六、函数调用包含多个参数之多个整型-参数压栈顺序,rcx,rdx,r8,r9寄存器
从本章节开始,进入到函数有多个参数的情况,前面几个章节中介绍了整型和浮点型使用了不同的寄存器在进行函数传参,ECX是整型的第一个参数的寄存器,那么多个参数的情况下函数如何传参,下面展开介绍参数为整型时候的几种情…...

SpringCloud优势
目录 完善的微服务支持 高可用性和容错性 灵活的配置管理 强大的服务网关 分布式追踪能力 丰富的社区生态 易于与其他技术栈集成 完善的微服务支持 Spring Cloud 提供了一整套工具和组件来支持微服务架构的开发,包括服务注册与发现、负载均衡、断路器、配置管理等功能…...

linux设备重启后时间与网络时间不同步怎么解决?
linux设备重启后时间与网络时间不同步怎么解决? 设备只要一重启,时间又错了/偏了,明明刚刚对时还是对的! 这在物联网、嵌入式开发环境特别常见,尤其是开发板、树莓派、rk3588 这类设备。 解决方法: 加硬件…...