对subprocess启动的子进程使用VSCode python debugger
文章目录
- 1 情况概要(和文件结构)
- 2 具体设置和启动步骤
- 2.1 具体配置
- Step 1 针对attach debugger到子进程
- Step 2 针对子进程的暂停
- (可选) Step 3 判断哪个进程id是需要的子进程
- 2.2 启动步骤和过程
- 3 其他问题解决
- 3.1
- 3.2 ptrace: Operation not permitted
- 其他解决方案*2
- 方案一(ChatGPT提供,对我不可行)
- 方案二(Github issue翻到)
- 参考
1 情况概要(和文件结构)
环境:Linux Ubuntu
最近在跑大模型,遇到一份代码的具体程序是通过subprocess.run()来启动的,而vscode的debug功能无法追踪进去。也就是说,我有父进程launch.py来启动subprocess.run(),调用子进程文件run.py。我可以单步调试追踪到subprocess这一步并进入run()函数,但是无法继续进入子进程的工作,无法追踪到run.py看我真正想看的代码。
这里父进程文件和子进程文件的概念我没有细究,大概意思是主动调用subprocess.run()来创建子进程的是父进程文件,被subprocess.run()跑起来的是子进程文件。
附上文件结构的简单示意。
-
test.sh:
python launch.py并传一堆参数 -
launch.py:父进程,主要内容为
def python_launch(args):"""Vanilla python launcher for degbugging purposes"""# ....# 构造cmdcmd = f"python {args.run_file}" # 省略一堆参数# 启动subprocesssubprocess.run(cmd, shell=True)- run.py:子进程,主要内容为
def main(cfg):# 环境变量设置,数据读取,新建文件夹之类的之类的# ...# 初始化trainer并训练trainer = build_trainer(cfg)trainer.run()2 具体设置和启动步骤
我们的目标是,我从某个地方把程序起起来并创建了子进程,然后把debugger连接到子进程上,于是它可以在子进程的断点地方停下、正常调试。
那么我们需要做到两件事情:1)把Debugger attach到子进程;2)子进程要能等待我们attach,而不是一股脑往下运行,那就来不及停在断点。
2.1 具体配置
我们分别对这两件事情做配置。
Step 1 针对attach debugger到子进程
采用vscode的python debugger插件,新建debugger config如下(编辑的是launch.json)
{"name": "Python: Attach to Subprocess", //随便起名"type": "python","request": "attach", //附加到子进程"processId": "${command:pickProcess}" //选择进程id
}
这里用${command:pickProcess}是采用vscode自带的命令,从进程列表中手动选择,而不是写死进程id。
实测这些内容就够了,不需要其他key比如ChatGPT建议的justMyCode和subProcess。
Step 2 针对子进程的暂停
在子进程文件,你需要断点的代码前面,或者索性最前面,加上一行:
input("Continue...")
这行会让代码停下,直到你在命令行中随便敲点什么,回车也行,才继续执行。
(可选) Step 3 判断哪个进程id是需要的子进程
因为我实在小白,我不确定哪个进程才是我要的,所以我在子进程文件里加了几行,输出父进程id和子进程id。
print(f"Parent PID (PPID): {os.getppid()}")print(f"Current PID: {os.getpid()}")
Current PID就是我们要的子进程id
以上,配置完了,我的run.py最终长这样:
def main(cfg):#### for debug ########## 输出父进程和子进程idprint(f"Parent PID (PPID): {os.getppid()}")print(f"Current PID: {os.getpid()}")# 可选,用来检查user id,原因后面说print(f"UID: {os.getuid()}, EUID: {os.geteuid()}") # 暂停input("Continue...")########################## 环境变量设置,数据读取,新建文件夹之类的之类的# ...trainer = build_trainer(cfg)trainer.run()2.2 启动步骤和过程
需要你操作的地方写了人工,其他的是自动执行顺序。
-
(人工)正常通过命令行执行sh test.sh,启动脚本
-
程序进入
launch.py,启动subprocess -
程序进入
run.py
3.1. 输出父进程id和子进程id供参考
3.2. 在input(Continue...)处暂停,等待键入字符才能继续执行

-
(人工)启动debug的Subprocess Attach,选择子进程,附加到正确的id上,等待…


-
attach到子进程,可能需要一会。
在DEBUG CONSOLE里会提示结果,要么是attach成功(如图),要么是弹窗报错然后在DEBUG CONSOLE里看错误信息。
此时可以看到调试工具栏表示正在执行、没有暂停,因为我们还在被input()暂停着。

-
(人工)在命令行里敲个回车,跳出
input(Continue...) -
断点停止在run.py中的对应位置
-
(人工)正常调试
3 其他问题解决
3.1
--- Starting attach to pid: 1103 ---
/bin/sh: 1: gdb: not found
解决方案是安装gdb
apt-get update
apt-get upgrade -y
apt-get install gdb
3.2 ptrace: Operation not permitted
解释一下前面python里为什么写了一句进程创建用户id查询
我在第5步attach环节遇到了一个错误,ptrace: Operation not permitted,是个权限错误。
--- Starting attach to pid: 654608 ---
Could not attach to process. If your uid matches the uid of the target
process, check the setting of /proc/sys/kernel/yama/ptrace_scope, or try
again as the root user. For more details, see /etc/sysctl.d/10-ptrace.conf
ptrace: Operation not permitted.
问了下ChatGPT:
/proc/sys/kernel/yama/ptrace_scope 文件
这个文件控制了 ptrace 系统调用的访问权限。ptrace 是 Linux 的一个系统调用,允许一个进程跟踪和控制另一个进程,是调试器工作的核心。
ptrace_scope 参数的值
0: 允许任何进程使用 ptrace 附加到其他进程(受用户权限约束)。
1: 仅允许父进程(如直接启动的调试器进程)附加到子进程。
2: 禁止所有非父子关系的调试。
3: 禁止所有 ptrace 附加操作。
默认值通常为 1,为了安全性避免恶意进程滥用 ptrace。
查询了一下这个值(cat /proc/sys/kernel/yama/ptrace_scope),输出是1。但是显然我的父进程和子进程都是同一个user启用的,不懂为什么说我权限错误。
查询进程创建用户有好几个方法,我是在python里写了一句这个。(解释了前文的查询用户id是啥用)
print(f"UID: {os.getuid()}, EUID: {os.geteuid()}")
但是到处折腾了一圈别的方案没解决,还是回来把这个值设为0了,真就解决了。
这个值的设置需要root权限。废话,如果本来就是用root在跑的话权限统一也不会报这个错了。
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
ChatGPT也说了,这个值设置为0的话不太安全,建议用完就给它改回去。于是写了个脚本方便切换值,插入在.bashrc文件里(vim ~/.bashrc)
ptrace_scope() {current_value=$(cat /proc/sys/kernel/yama/ptrace_scope) echo "[INTRO] Script for changing between 0 & 1 value for /proc/sys/kernel/yama/ptrace_scope. The value should vary from [0,3] for different safety levels, default as 1"echo; # 换行echo "current value = $current_value" # 获取当前值# 根据当前值,在0和1之间切换if [ "$current_value" -eq 1 ]; thenecho "Now changing to 0..."echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scopeelif [ "$current_value" -eq 0 ]; thenecho "Now changing to 1 ..."echo 1 | sudo tee /proc/sys/kernel/yama/ptrace_scopeelseecho "[Warning] Unknown ptrace_scope current value. Nothing takes effect."exit 1fi# 检查是否执行成功,并提醒恢复0值current_value=$(cat /proc/sys/kernel/yama/ptrace_scope)echo "[INFO] ptrace_scope changed to $current_value"echo;if [ "$current_value" -eq 1 ]; thenecho "[INFO] Safe default setting ^-^"elif [ "$current_value" -eq 0 ]; thenecho "[INFO] Unsafe setting, remember to change back to value = 1."fiecho;
}
记得source ~/.bashrc使配置生效。
效果如下,通过ptrace_scope change指令实现0-1切换。

其他解决方案*2
方案一(ChatGPT提供,对我不可行)
针对debugger监听子进程这个事情,ChatGPT还给了我一套方案,但用不了。记一下大概配置,哪哪都折腾过了,这个debugpy的wait for client啊就是不知道wait到了什么,直接就监听到了,但我明明还没开debugger的attach!
在子进程文件里写
import debugpyint main():# 启动调试服务debugpy.listen(("0.0.0.0", 5678))print("Debugpy is listening on port 5678")# 等待客户端连接debugpy.wait_for_client()print("Debugger is attached!")# trainer.......
在debugger config里写一个针对test脚本执行的config,和debug普通python文件一个写法。另外再写一个attach用的config,用的监听路径,大概如下:
{"name": "Python: Attach to Subprocess","type": "python","request": "attach","connect": {"host": "localhost","port": 5678},"justMyCode": false,"subProcess": false
}
方案二(Github issue翻到)
还看到一个更暴力的是是直接改写,不用subprocess,见GitHub: embodied-generalist/issues/33
因为它只是inference但是我要train…小白还不知道不开子进程会不会有影响,就没碰
参考
- StackOverflow Attaching a VSCode Debugger to a Sub Process in Python
- GitHub: embodied-generalist/issues/33
相关文章:
对subprocess启动的子进程使用VSCode python debugger
文章目录 1 情况概要(和文件结构)2 具体设置和启动步骤2.1 具体配置Step 1 针对attach debugger到子进程Step 2 针对子进程的暂停(可选) Step 3 判断哪个进程id是需要的子进程 2.2 启动步骤和过程 3 其他问题解决3.13.2 ptrace: Operation not permitted…...

Django启用国际化支持(2)—实现界面内切换语言:activate()
文章目录 ⭐注意⭐1. 配置项目全局设置:启用国际化2. 编写视图函数3. 配置路由4. 界面演示5、扩展自动识别并切换到当前语言设置语言并保存到Session设置语言并保存到 Cookie ⭐注意⭐ 以下操作依赖于 Django 项目的国际化支持。如果你不清楚如何启用国际化功能&am…...

基于单片机的多功能跑步机控制系统
本设计基于单片机的一种多功能跑步机控制系统。该系统以STM32单片机为主控制器,由七个电路模块组成,分别是:单片机模块、电机控制模块、心率检测模块、音乐播放模块、液晶显示模块、语音控制模块、电源模块。其中,单片机模块是整个…...

VSCode 如何选中包含某个字母的所有行
文章目录 写在前面一、需求描述二、解决方法参考链接 写在前面 自己的测试环境:VSCode 一、需求描述 由于需要处理文件,需求是删除文件中包含某个字母的所有行。 二、解决方法 在 Visual Studio Code (VSCode) 中,如果你想选中所有包含某…...

CSRF保护--laravel进阶篇
laravel对csrf非常重视,专门针对csrf作出了很多的保护。如果您是刚刚接触laravel的路由不久,那么您可能对于web.php路由文件的post请求很疑惑,因为get请求很顺利,而post请求则可能会遭遇失败。其中一个失败的原因是由于laravel的c…...

计算机网络-理论部分(二):应用层
网络应用体系结构 Client-Server客户-服务器体系结构:如Web,FTP,Telnet等Peer-Peer:点对点P2P结构,如BitTorrent 应用层协议定义了: 交换的报文类型,请求or响应报文类型的语法字段的含义如何…...

k8s1.31版本最新版本集群使用容器镜像仓库Harbor
虚拟机 rocky9.4 linux master node01 node02 已部署k8s集群版本 1.31 方法 一 使用容器部署harbor (1) wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo yum -y install docker-ce systemctl enable docker…...

QT中使用json格式存取矩阵数据
在 Qt 中,可以通过 QJsonDocument 和 QJsonArray 方便地存取 JSON 格式的矩阵数据。以下是存储和读取矩阵数据的完整实现示例。 1. 矩阵存储为 JSON 将矩阵(QVector<QVector<double>> 或其他二维数组)存储为 JSON 文件。 实现代码 #include <QJsonArray&g…...

k8s 集群安装
安装rockylinux https://www.jianshu.com/p/a5fe20318b8e https://www.cnblogs.com/haoee/p/18290506 配置VirtualBox双网卡 https://www.cnblogs.com/ShineLeBlog/p/17580311.html https://zhuanlan.zhihu.com/p/341328334 https://blog.csdn.net/qq_36544785/article/deta…...

Elasticsearch面试内容整理-核心概念与数据模型
在 Elasticsearch 中,理解核心概念与数据模型是非常重要的,因为它们定义了数据如何被组织、存储和搜索。以下是 Elasticsearch 的核心概念和数据模型的详细介绍。 核心概念 集群(Cluster) ● 集群是由一个或多个节点组成的,用于共同存储和搜索数据的集合。...

Spring Boot实现License生成和校验
Spring Boot实现License生成和校验 证书准备 # 1. 生成私钥库 # validity:私钥的有效期(天) # alias:私钥别称 # keystore:私钥库文件名称(生成在当前目录) # storepass:私钥库密码…...
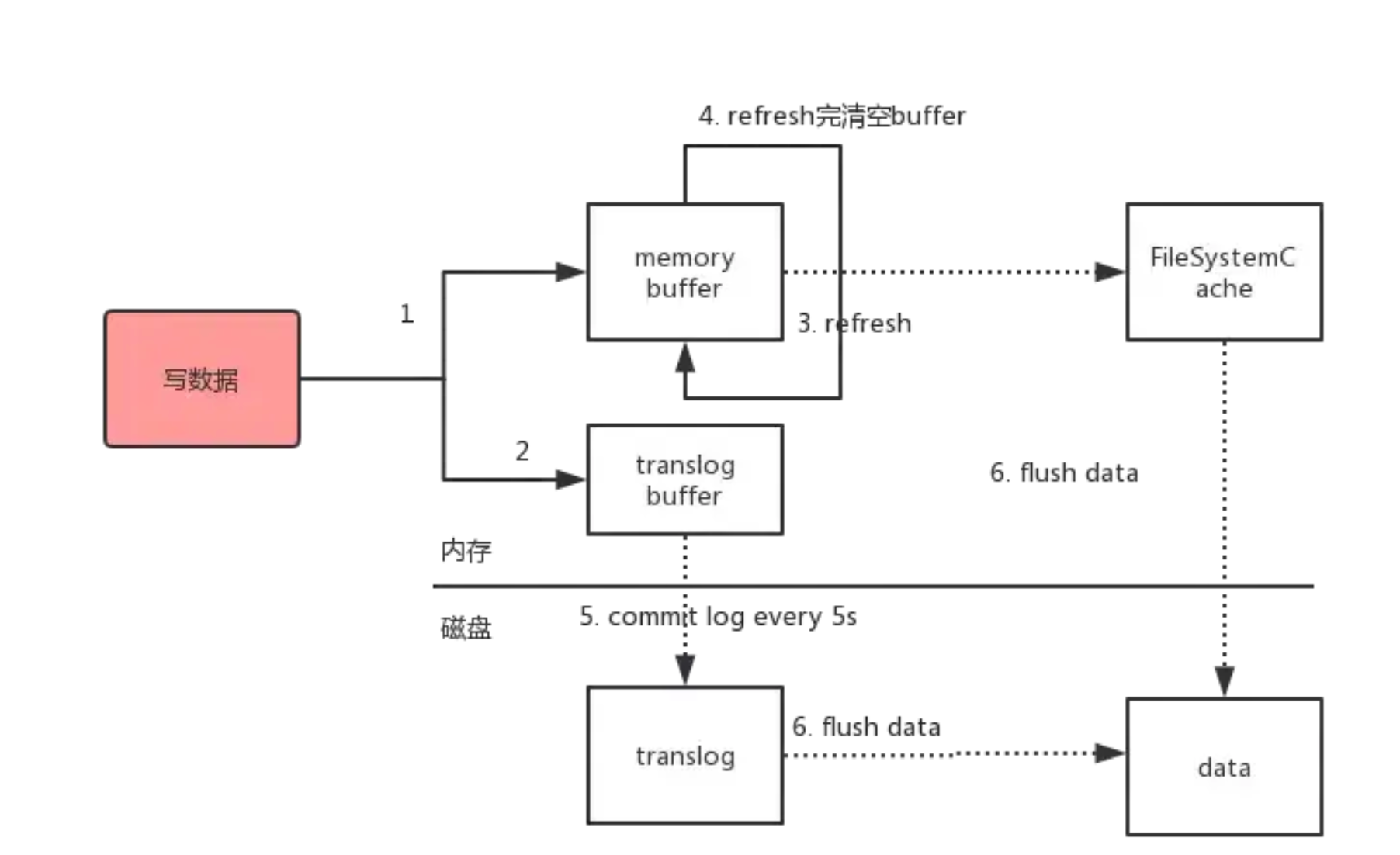
es写入磁盘的过程以及相关优化
数据写入到内存buffer同时写入到数据到translog buffer,这是为了防止数据不会丢失每隔1s数据从buffer中refresh到FileSystemCache中,生成segment文件,这是因为写入磁盘的过程相对耗时,借助FileSystemCache,一旦生成segment文件,就能通过索引查询到了refresh完,memory bu…...

十大网络安全事件
一、私有云平台遭攻击,美国数千家公司工资难以发放 1月,专门提供劳动力与人力资本管理解决方案的美国克罗诺斯(Kronos)公司私有云平台遭勒索软件攻击,事件造成的混乱在数百万人中蔓延。 克罗诺斯母公司UKG集团…...

【数据结构】【线性表】栈的基本概念(附c语言源码)
栈的基本概念 讲基本概念还是回到数据结构的三要素:逻辑结构,物理结构和数据运算。 从逻辑结构来讲,栈的各个数据元素之间是通过是一对一的线性连接,因此栈也是属于线性表的一种从物理结构来说,栈可以是顺序存储和顺…...

修改ffmpeg实现https-flv内容加密
目录 1 前言 2 ffmpeg源码修改 2.1 增加头文件 2.2 http上下文增加解密密钥和AVAESCTR结构体 2.3 aes解密上下文初始化 2.4 对http数据部分解密 2.5 http关闭时清理资源 3 ffmpeg使用 1 前言 当前视频拉流已经通过URL鉴权方式来对访客身份进行识别和过滤,但…...

react中useMemo的使用场景
useMemo 是 React 的一个 Hook,用来优化性能,尤其是在计算复杂值时。它会记住(缓存)计算结果,只有在依赖项变化时才重新计算,避免不必要的重复计算。 import React, { useMemo } from react; function Ex…...

Pytorch自定义算子反向传播
文章目录 自定义一个线性函数算子如何实现反向传播 有关 自定义算子的实现前面已经提到,可以参考。本文讲述自定义算子如何前向推理反向传播进行模型训练。 自定义一个线性函数算子 线性函数 Y X W T B Y XW^T B YXWTB 定义输入M 个X变量,输出N个…...
机密数据存储)
aws服务(二)机密数据存储
在AWS(Amazon Web Services)中存储机密数据时,安全性和合规性是最重要的考虑因素。AWS 提供了多个服务和工具,帮助用户确保数据的安全性、机密性以及合规性。以下是一些推荐的存储机密数据的AWS服务和最佳实践: 一、A…...
VMware Workstation 17.6.1
概述 目前 VMware Workstation Pro 发布了最新版 v17.6.1: 本月11号官宣:针对所有人免费提供,包括商业、教育和个人用户。 使用说明 软件安装 获取安装包后,双击默认安装即可: 一路单击下一步按钮: 等待…...

高校企业数据挖掘平台推荐
TipDM数据挖掘建模平台是由广东泰迪智能科技股份有限公司自主研发打造的可视化、一站式、高性能的数据挖掘与人工智能建模服务平台,致力于为使用者打通从数据接入、数据预处理、模型开发训练、模型评估比较、模型应用部署到模型任务调度的全链路。平台内置丰富的机器…...

7个技巧让JoyCon-Driver实现Switch手柄完美适配:从入门到精通
7个技巧让JoyCon-Driver实现Switch手柄完美适配:从入门到精通 【免费下载链接】JoyCon-Driver A vJoy feeder for the Nintendo Switch JoyCons and Pro Controller 项目地址: https://gitcode.com/gh_mirrors/jo/JoyCon-Driver JoyCon-Driver是一款开源驱动…...

Windows系统苹果设备驱动安装完全指南:从问题诊断到高效应用
Windows系统苹果设备驱动安装完全指南:从问题诊断到高效应用 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/…...

视频资源管理新范式:douyin-downloader的效率革命
视频资源管理新范式:douyin-downloader的效率革命 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 当你第3次在杂乱无章的"下载"文件夹中翻找上周保存的教学视频时,当你意识…...

LiuJuan20260223Zimage部署教程:解决Gradio跨域访问、Xinference模型加载超时等典型问题
LiuJuan20260223Zimage部署教程:解决Gradio跨域访问、Xinference模型加载超时等典型问题 你是不是也遇到过这样的问题?好不容易部署了一个AI模型服务,结果在浏览器里访问时,页面一片空白,控制台报了一堆跨域错误。或者…...

基于CW32F030与EC-01G模块的NBIoT+GPS定位与心知天气API接入实战
基于CW32F030与EC-01G模块的NBIoTGPS定位与心知天气API接入实战 最近在做一个户外环境监测的小项目,需要把GPS定位数据和传感器信息上传到云端,同时还想获取当地的天气信息。我选择了国产的CW32F030C8T6单片机搭配安信可的EC-01G NBIoTGPS模块࿰…...

Cosmos-Reason1-7B效果展示:手术室视频中器械摆放是否符合无菌区物理规则
Cosmos-Reason1-7B效果展示:手术室视频中器械摆放是否符合无菌区物理规则 1. 模型能力概览 Cosmos-Reason1-7B是NVIDIA开源的一款7B参数量的多模态视觉语言模型,专注于物理理解与思维链推理能力。作为Cosmos世界基础模型平台的核心组件,它能…...

ESP32-S3高保真网络音频终端设计与实现
1. 项目概述本项目是一款面向高保真音频应用的嵌入式网络播放终端,定位于兼顾工程实用性与音频性能的开源硬件实践平台。系统以ESP32-S3为主控核心,集成Wi-Fi 6(802.11ax)无线通信能力、蓝牙5.3音频传输通道、多格式流媒体解码引擎…...

基于ESP32的电动升降桌智能控制系统设计
1. 项目概述电动升降桌作为现代办公与居家环境中的智能化家具,其核心价值在于通过机电一体化设计实现人体工学高度的动态调节。本项目基于二手畅腾CTHT3-F4200双电机三节升降桌架进行二次开发,构建了一套具备高度记忆、网络授时、本地交互与快充扩展能力…...

智能客服知识库语料格式优化实战:从混乱到高效的结构化处理
最近在搭建一个智能客服系统,知识库的构建真是让人头大。最初的语料就是一堆从客服对话日志里导出的文本文件,格式五花八门,夹杂着各种表情符号、错别字、口语化表达,甚至还有客服和用户的个人信息。直接用这些“脏数据”去训练模…...

电脑端制作泳道图超便捷 零基础快速做出专业业务流程图
在企业管理、软件开发、流程梳理等工作场景中,泳道图作为一种清晰呈现多角色、多部门协作流程的可视化图表,被广泛应用于需求分析、业务流程优化、系统设计等环节。对于职场从业者和开发者而言,快速绘制出规范、专业的泳道图,能够…...