w~视觉~合集25
我自己的原文哦~ https://blog.51cto.com/whaosoft/12627822
#Mean Shift
简单的介绍 Mean Shift 的数学原理和代码实现,基于均值漂移法 Mean Shift 的图像分割
Mean Shift 算法简介
从分割到聚类
对于图像分割算法,一个视角就是将图像中的某些点集分为一类(前景),另外一些点集分为另一类(后景),从而达到分割的目的。而 Mean Shift 就是这样一类基于聚类的分割方法。
如果只是需要前景和背景的分割,那么就可以看成一个簇为2的一个聚类任务
这篇文章就简单介绍一下 Mean Shift 的数学原理和代码实现。
用概率密度估计函数的极大值点来聚类!
不同于KMeans 这样的原型聚类,Mean Shift 有一套自己的聚类方法,原理其实也很简单。相信部分读者在看到这个子标题时就已经茅塞顿开。但是,为了照顾其他读者,我仍然打算完整描述 Mean Shift 的聚类流程。此处,我借用 MeanShift_py(https//github.com/mattnedrich/MeanShift_py) 这个项目中的图:
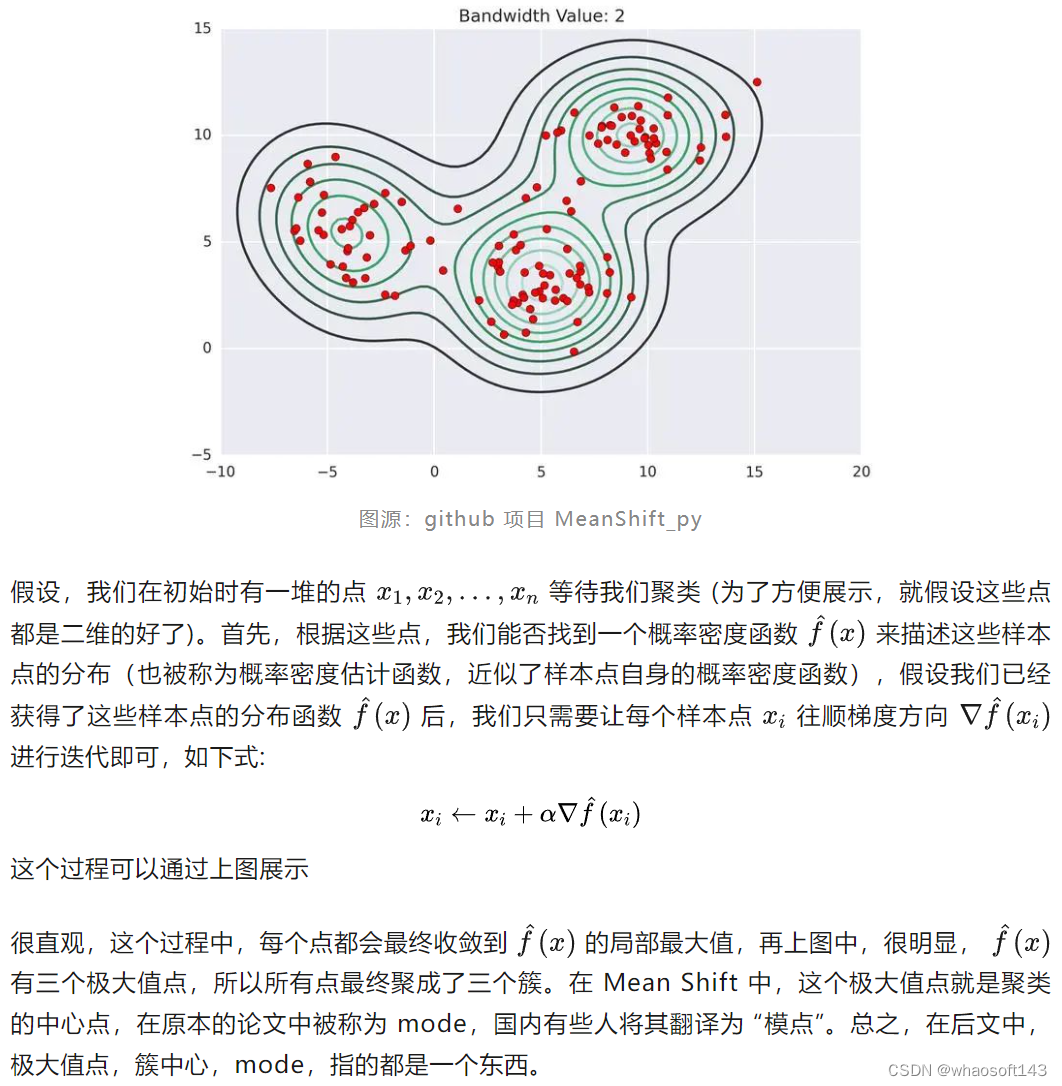

核密度估计 KDE

好啦好啦,我们接下来就可以非常简单愉快地实现基于 Mean Shift 的图像分割了。
从聚类到分割
下面是 Mean Shift 图像分割算法的流程

这样,我们就得到了分割之后的图,当然,如果希望制定分割的类数,可以尝试调整 bandwidth 或者在聚类完成后改变数量较小的点的label (大概率会得到很多的簇)
代码实现
我们先预装一下要用到的库:
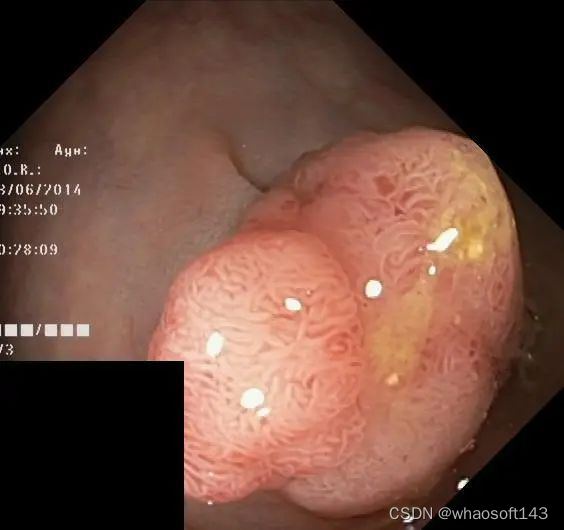
pip install numpy scikit-learn opencv-python简单介绍一下本次需要分割的对象,为 kvasir-seg 中的图像,需要分割的为下图中的息肉
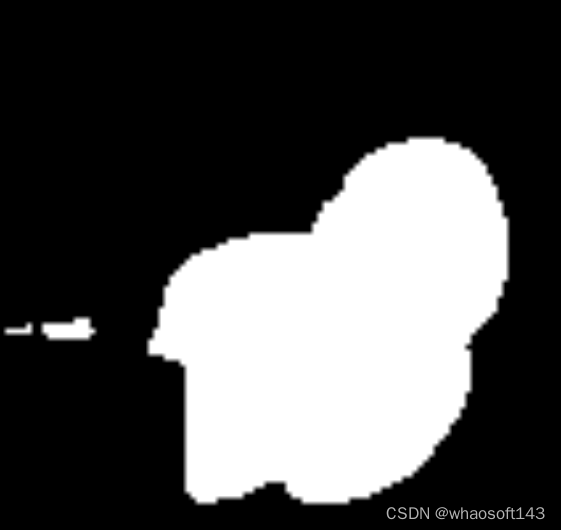
它的 ground truth 为:

下面尝试使用 Mean Shift 和 KMeans 来解决。
Mean Shift
先引入需要的库。
from collection import Counter
import numpy as np
from PIL import Image
import cv2
from sklearn.cluster import MeanShift, KMeansMean Shift 对于噪音非常敏感,我们先进行去噪,并降采样:
image = cv2.imread('./test.png')
image = cv2.GaussianBlur(image, ksize=(15, 15), sigmaX=10)
origin_h = image.shape[0]
# resize 函数详见结尾附录
image = resize(image, height=100)然后制作每个像素点对应的五维特征:
h, w = image.shape[:2]
features = []
for i in range(h):for j in range(w):pixel = image[i, j]if len(pixel.shape) == 0:pixel = [pixel.tolist()]else:pixel = pixel.tolist()pixel.append(i * 1.)pixel.append(j * 1.)features.append(pixel)features = np.array(features)normalized_features = features / features.max(axis=0)然后进行 Mean Shift 聚类,并保存簇的个数:
mean_shift_model = MeanShift(bandwidth=50)
clusters = mean_shift_model.fit(normalized_features)
cluster_num = Counter(clusters.labels_)
cluster_num如果簇太多,就调大
bandwidth 的值
run in 44.6 s:
可以看到,有 8 个簇,一般簇在20个以内算是比较正常的,太多说明效果不佳。
我们来看一下这8个簇合在一起的可视化效果:
seg = clusters.labels_.reshape(h, w)
seg = (seg / seg.max() * 255).astype('uint8')
seg = resize(seg, height=origin_h)
image = Image.fromarray(seg)
image.save('mean_shift.png')
image渲染效果如下:

可以看到,目标区域被两个mask给覆盖了,我们只需要将这两个 mask 合并一下就是最终的结果了:
masks = []
for cluster_id in range(cluster_num):seg = np.where(clusters.labels_.reshape(h, w) == cluster_id, 255, 0)masks.append(seg.astype('uint8'))# 通过可视化每一个 masks 中的元素找到需要的元素索引 0 和 3
select_mask_ids = [0, 3]
final_mask = np.zeros((h, w)).astype(np.bool_)
for mask_id in select_mask_ids:mask = masks[mask_id].astype(np.bool_)final_mask |= mask
final_mask = final_mask.astype('uint8') * 255
final_mask = resize(final_mask, height=origin_h)
final_mask_image = Image.fromarray(final_mask)
final_mask_image.save('mean_shift.mask.png')
final_mask_image最终效果:
KMeans
接下来我们再试试 KMeans,步骤和上面几乎完全一样,只需要注意使用 KMeans 不需要下采样,并且,高斯平滑的参数设的小一些,我设置的如下:
image = cv2.GaussianBlur(image, ksize=(5, 5), sigmaX=2)调用 KMeans 的函数如下:
kmean_model = KMeans(n_clusters=5, n_init='auto')
clusters = kmean_model.fit(normalized_features)
cluster_num = len(Counter(clusters.labels_))
cluster_num其余都一样,值得一提的是,KMeans 在我的 256 核服务器上瞬间就跑完了,打上 Mean Shift 却需要 44 秒。下来看看 KMeans 的所有 mask 堆叠的效果:

可以看到,效果非常不错,我们只需要选一个部分就可以,最终效果如下:

指标计算
我们最后可以算一下分割指标。
分割指标的代码可以 copy 我的博客:(https//kirigaya.cn/blog/article%3Fseq%3D141)
| 指标 | KMeans | Mean Shift |
| Dice | 0.900 | 0.898 |
| IoU | 0.818 | 0.815 |
| Sensitivity | 0.829 | 0.832 |
| PPV | 0.984 | 0.975 |
| HD95 | 6.650 | 114.0 |
可以看到,两者性能难分伯仲(但是Mean Shift 的 HD95 却很大)。但是从笔者使用体验下来,无论是调参难度还是运行速度,都是 KMeans 更胜一筹。因为 KMeans 只需要控制生成的簇的个数。且原型聚类本身就很适合图像这种样本点比较多的情况下的快速聚类。
附录
resize函数:
def resize(img : np.ndarray, height=None, width=None) -> np.ndarray:if height is None and width is None:raise ValueError("not None at the same time")if height is not None and width is not None:raise ValueError("not not None at the same time")h, w = img.shape[0], img.shape[1]if height:width = int(w / h * height)else:height = int(h / w * width)target_img = cv2.resize(img, dsize=(width, height))return target_img#VadCLIP
论文VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection。首个基于视觉-语言模型的弱监督视频异常检测方法
一个新的WSVAD检测方法,即VadCLIP,它涉及双分支网络,分别以视觉分类和语言-视觉对齐的方式检测视频异常。借助双分支的优势,VadCLIP实现了粗粒度(二分类)和细粒度(异常类别多分类)的WSVAD。VadCLIP是第一个将预先训练的语言视觉知识有效地转移到WSVAD的工作。
- Code&CLIP features:https://github.com/nwpu-zxr/VadCLIP)
- 论文链接:https://arxiv.org/abs/2308.11681
- 作者:吴鹏,周学荣(研二,学生一作),庞观松(SMU),周玲茹,闫庆森,王鹏,张艳宁。
一、引言
近年来,弱监督视频异常检测(WSVAD,VAD)因其广阔的应用前景而受到越来越多的关注,在WSVAD任务中,期望异常检测器在仅提供视频级注释的情况下生成的精细化帧级异常置信度。
然而当前该领域的大多数研究遵循一个系统性的框架,即,首先是使用预先训练的视觉模型来提取帧级特征,例如C3D、I3D和ViT等,然后将这些特征输入到基于多实例学习(MIL)的二分类器中进行训练,最后一步是用预测的异常置信度检测异常事件。
尽管这类方案很简单,分类效果也很有效,但这种基于分类的范式未能充分利用跨模态关系,例如视觉语言关联。
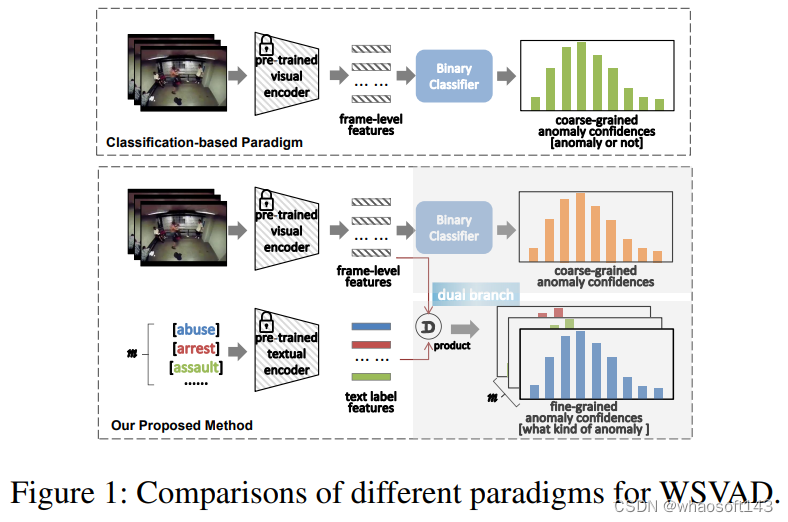
在过去的两年里,我们见证了视觉语言预训练(VLP)模型取得了巨大进展,例如CLIP,用于学习具有语义概念的广义视觉表示。CLIP的主要思想是通过对比学习来对齐图像和文本,即将图像和匹配的文本描述在联合特征空间拉近,同时分离不匹配的图文对。
鉴于CLIP的突破性的潜力,在CLIP之上构建任务专用模型正成为新兴的研究课题,并应用于广泛的视觉任务,这些模型取得了前所未有的性能。最近,越来越多的视频理解领域的工作利用CLIP构建专用模型并解决各种视频理解任务。基于此,我们认为CLIP对于WSVAD任务同样有巨大的潜力。
为了有效利用广义知识,使CLIP在WSVAD任务中充分发挥其潜力,基于WSVAD的特点,有几个关键的挑战需要解决。
- 首先,如何进行时序关系建模,捕获上下文的依赖关系;
- 其次,如何利用视觉信息和文本信息联系;
- 第三,如何在弱监督下优化基于CLIP的模型。
针对上述的问题,我们提出了一种基于CLIP的WSVAD新范式,称为VadCLIP。VadCLIP由几个组件组成,包括一个局部-全局时序关系适配器(LGT Adapter),一个由视觉分类器和视觉语言对齐模块组成的双分支异常检测器(Dual Branch)。
我们的方法既可以利用传统WSVAD的分类范式,又可以利用CLIP提供的视觉语言对齐功能,从而基于CLIP语义信息和两个分支共同优化以获得更高的异常检测性能。
总的来说,我们工作的主要贡献是:
- 我们提出了一个新的WSVAD检测方法,即VadCLIP,它涉及双分支网络,分别以视觉分类和语言-视觉对齐的方式检测视频异常。借助双分支的优势,VadCLIP实现了粗粒度(二分类)和细粒度(异常类别多分类)的WSVAD。据我们所知,VadCLIP是第一个将预先训练的语言视觉知识有效地转移到WSVAD的工作。
- 我们提出的方法包括三个重要的组成部分,以应对新范式带来的新挑战。LGT适配器用于从不同的角度捕获时间依赖关系;设计了两种提示机制来有效地使冻结的预训练模型适应WSVAD任务;MIL对齐实现了在弱监督下对视觉文本对齐范式的优化,从而尽可能地保留预先训练好的知识。
- 我们在两个大规模公共基准上展示了VadCLIP的性能和有效性,VadCLIP均实现了最先进的性能。例如,它在XD Violence和UCFCrime上分别获得了84.51%的AP和88.02%的AUC分数,大大超过了当前基于分类的方法。
二、方法
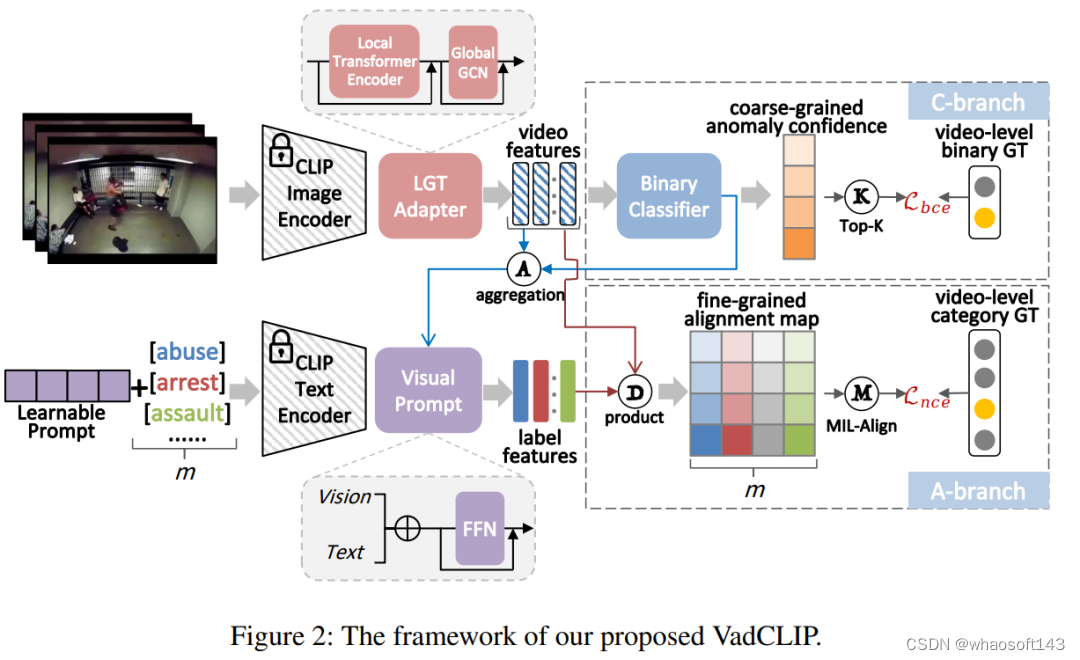
VadCLIP的模型结构如图所示,主要包括了三个部分,分别为局部全局时序关系适配器(LGT Adapter)、视觉二分类分支和视觉文本对齐细粒度分类分支。
2.1 LGT Adapter
LGT Adapter由局部关系Transformer和全局关系图卷积串联组成。考虑到常规的Transformer在长时视频时序关系建模时冗余信息较多、计算复杂度较高,我们改进了局部Transformer的mask,从时序上将输入视频帧特征分割为多个等长块,令自注意力计算局限于块内,减少了冗余信息建模,降低计算复杂度。
为了进一步捕获全局时间依赖性,我们在局部模块之后引入了一个轻量级的图卷积模块,由于其在WSVAD任务中得到广泛采用,性能已经被证明,我们采用GCN来捕获全局时间依赖关系。根据之前的工作,我们使用GCN从特征相似性和相对距离的角度对全局时间依赖性进行建模,可以总结如下:
特征相似性分支通过计算两帧之间的特征的余弦相似度生成GCN邻接矩阵:
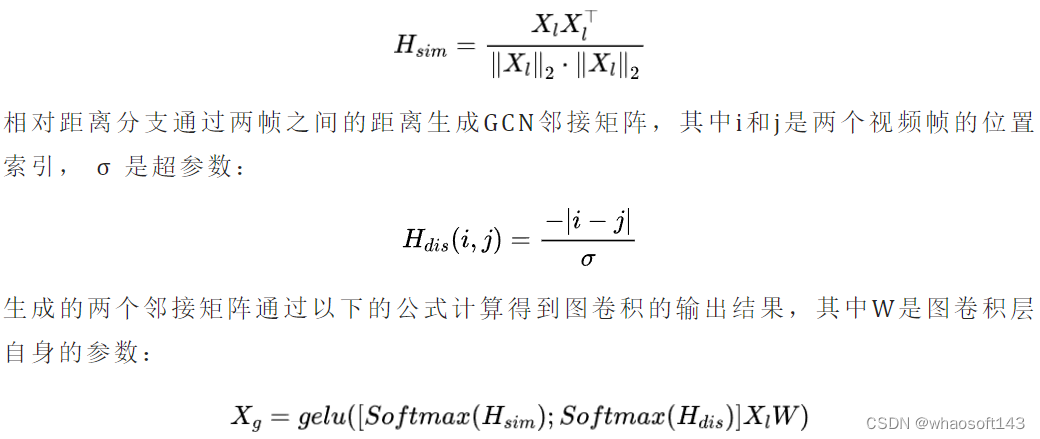
2.2 双分支结构
与之前的其他WSVAD工作不同,我们的VadCLIP包含双分支,除了传统的异常二分类分支之外,我们还引入了一种新颖的视觉-文本对齐分支。二分类分支和传统的WSVAD工作类似,使用一个带有残差连接的FFN和二分类器,直接计算经过时序关系建模的视觉特征的帧级别异常置信度:

将组装好的新嵌入和位置信息嵌入相加,送入冻结的CLIP文本编码器中得到类嵌入。
为了进一步提高文本标签对异常事件的表示能力,我们研究了如何使用视觉上下文来细化类嵌入,因为视觉上下文可以使简洁的文本标签更加准确。
为此,我们提出了一种异常聚焦视觉提示,它关注异常片段中的视觉嵌入,并将这些嵌入聚合为类嵌入的视频级提示。
我们首先使用从二分类分支获得的异常置信度A作为异常注意力,然后通过异常注意力和视频特征X的点积计算视频级别提示,然后进行归一化,如下所示:

通过可训练文本提示和异常聚焦视觉提示,我们将最终的类嵌入和视觉特征计算余弦相似度,并得到视觉文本对齐分支的细粒度分类置信度。
2.3 损失函数

三、实验结果
3.1 对比结果
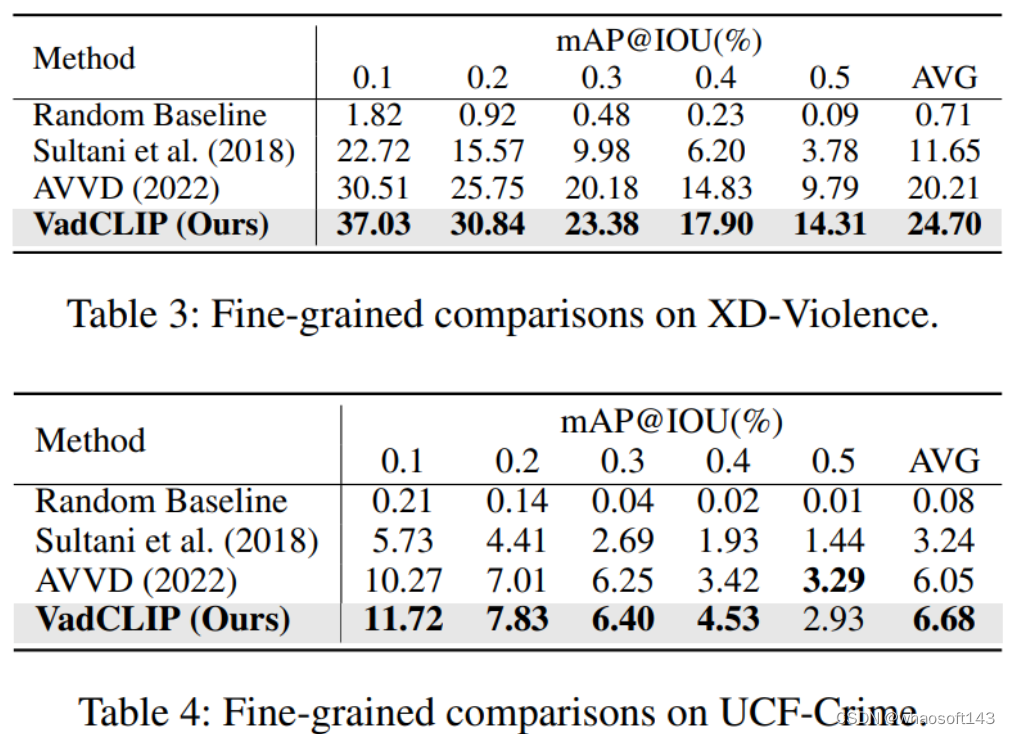
表1和表2展示了在两个常用的WSVAD数据集UCF-Crime和XD-Violence中,我们的方法和之前的工作的对比结果,为了保证公平,上述列出结果的工作均使用CLIP特征进行重新训练,可以看出我们的方法在两个数据集中相较之前的工作有较大的提升。
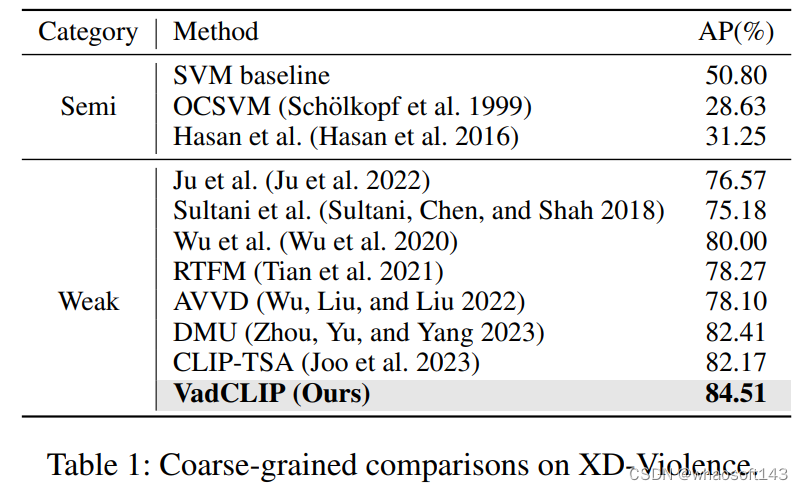
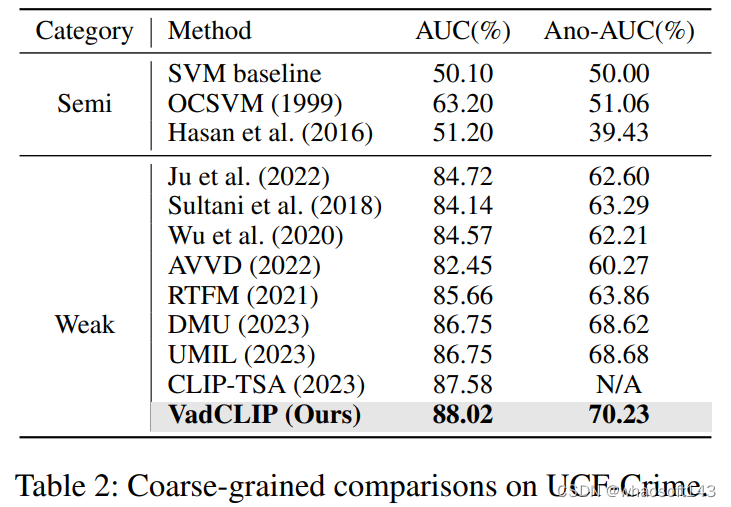
表3和表4展示了使用了细粒度多类别标签进行异常检测,且计算帧mAP@IOU结果的情况,可以看出我们的方法在进行细粒度多分类异常检测时也有明显的提升。
3.2 可视化
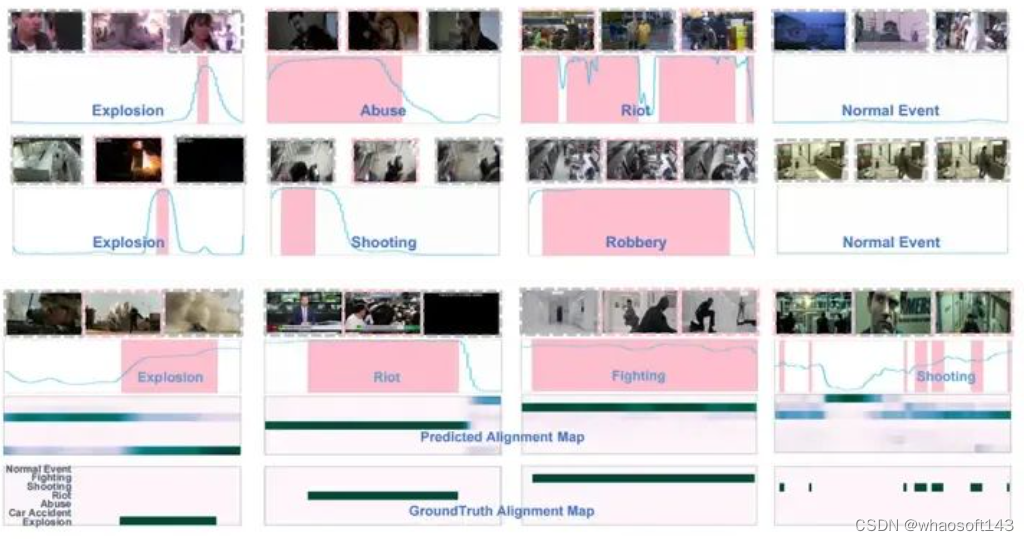
上图分别展示了帧级别粗粒度异常检测可视化结果和细粒度多分类异常检测结果。
四、总结
在这项工作中,我们提出了一种新的范式VadCLIP,用于弱监督视频异常检测。
为了有效地将预训练的知识和视觉语言关联从冻结的CLIP迁移到WSVAD任务,我们首先设计了一个LGT适配器来增强时间建模的能力,然后设计了一系列提示机制来提高通用知识对特定任务的适应能力。
最后,我们设计了MIL对齐操作,以便于在弱监督下优化视觉语言对齐。我们通过和最先进的工作对比和在两个WSVAD基准数据集上的充分消融,验证了VadCLIP的有效性。未来,我们将继续探索视觉语言预训练知识,并进一步致力于开放集VAD任务。
#TAP (Tokenize Anything via Prompting)
智源研究院视觉团队推出以视觉感知为中心的基础模型 TAP (Tokenize Anything via Prompting), 利用视觉提示同时完成任意区域的分割、识别与描述任务。将基于提示的分割一切基础模型 (SAM) 升级为标记一切基础模型 (TAP) ,高效地在单一视觉模型中实现对任意区域的空间理解和语义理解。 顶配版SAM!由分割一切迈向感知一切
在计算机视觉领域,分割被视为感知的基础要素。通过分割,系统得以准确地定位和区分图像中的各个对象,为更深层次的感知提供了必要基础。全面的视觉感知不仅包括对图像进行分割,更涵盖对图像中对象与场景的语义理解、关系推断等高层次认知。
现有的视觉分割基础模型,如 SAM 及其变体,集中优势在形状、边缘等初级定位感知,或依赖外部模型完成更高级的语义理解任务。然而,迈向更高效的视觉感知则需要在单个模型中实现全面的视觉理解,以助力于更广泛的应用场景,如自动驾驶、安防监控、遥感以及医学图像分析等。
近日,智源研究院视觉团队推出以视觉感知为中心的基础模型 TAP (Tokenize Anything via Prompting), 利用视觉提示同时完成任意区域的分割、识别与描述任务。将基于提示的分割一切基础模型 (SAM) 升级为标记一切基础模型 (TAP) ,高效地在单一视觉模型中实现对任意区域的空间理解和语义理解。相关的模型、代码均已开源,并提供了 Demo 试用,更多技术细节请参考 TAP 论文。
论文地址:
https://arxiv.org/abs/2312.09128
项目&代码:
https://github.com/baaivision/tokenize-anything
模型地址:
https://huggingface.co/BAAI/tokenize-anything
Demo:
https://huggingface.co/spaces/BAAI/tokenize-anything
1 模型介绍
1.1 亮点
通用能力:TAP 是一个统一的可提示视觉基础模型,根据视觉提示(点、框、涂鸦)对任意区域内的目标同时进行分割、识别以及描述,最终汇聚成一组可用于综合评估区域内容的输出结果。
通用表征:TAP 将任意区域中的内容表示为紧凑的掩码标记和语义标记,掩码标记负责空间理解,语义标记则负责语义理解。因此,TAP 模型可以替代 SAM,CLIP 作为下游应用的新基础模型。
通用预训练:TAP 利用大量无语义的分割掩码,直接从通用 CLIP 模型中汲取开放世界知识。这种预训练新范式避免了使用与任意数据集相关的有偏差人工标注,缓解了物体在开放语义下的定义冲突与不完备问题。
1.2 方法
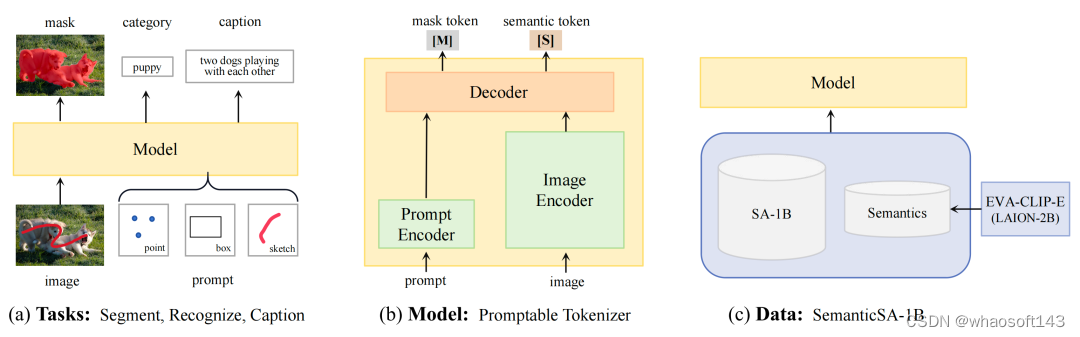
视觉感知中的一个关键研究目标是如何高效地定位与识别任意感兴趣区域。这要求单一的可提示视觉模型同时具备分割、识别、与描述能力来充分地理解任意区域中的内容。同时,通过观察模型的多角度输出(分割、识别、文本生成),可以更加充分地评估和解释模型的理解能力(图a)。
现有的视觉基础模型因其预训练目标的不同,通常集中优势在单一的任务。例如 SAM 专注于空间理解能力,可以定位出与语义类别无关的分割掩码。另一方面,CLIP 及其各种变体则在视觉语义理解方面表现出色。因此,在 SAM 的架构中学习 CLIP 模型的语义先验,为全面的视觉感知提供了一个有效的途径。TAP 沿这一途径提出了如下的核心设计:
模型架构:为了实现一个统一的模型,TAP 在 SAM 架构的基础上,将掩码解码器升级为通用的图像解码器,同时输出掩码标记与语义标记(图b)。掩码标记负责预测分割掩码,语义标记则用于预测对应的语义标签和文本描述。
数据获取:训练一个多能力的视觉基础模型需要多样化标注的大规模数据集。然而,目前尚无公开的可同时用于分割与区域识别的大规模数据源。SA-1B 构建了 11 亿高质量掩码标注,用于训练分割基础模型,如 SAM。LAION-2B 收集了 20 亿图像-文本对,用于训练图文对齐模型,如 CLIP。
为了解决分割-文本对齐数据缺乏的问题,TAP 引入了 SemanticSA-1B 数据集(图c)。该数据集将来自 LAION-2B 的语义隐式地集成到 SA-1B 的分割数据中。具体而言,TAP 利用在 LAION-2B 数据集上训练的具有 50 亿参数的 EVA-CLIP 模型,预测 SA-1B 中的每一个分割区域在一个概念词汇上的分布。该分布提供信息最大化的语义监督, 避免模型在偏差过大的伪标签上训练。
模型训练:TAP 模型在 256 块寒武纪 MLU370 加速器上进行预训练,并行优化可提示分割与概念预测两个任务。给定一张图片及一个视觉提示,TAP 模型将感兴趣区域表示为一个掩码标记和一个语义标记。基于语义标记,扩展一个 MLP 预测器可实现开放词汇分类任务。同时,扩展一个轻量化的自回归文本解码器即可实现文本生成任务。
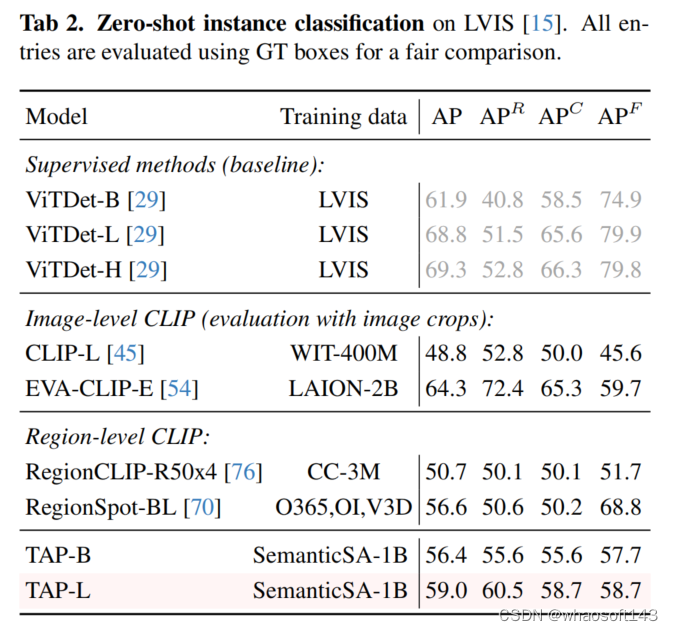
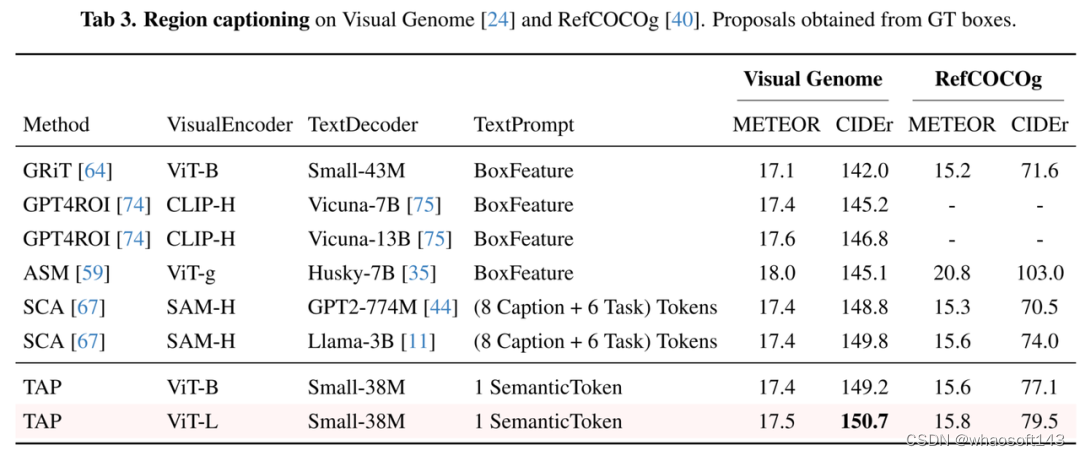
2 量化结果、可视化展示
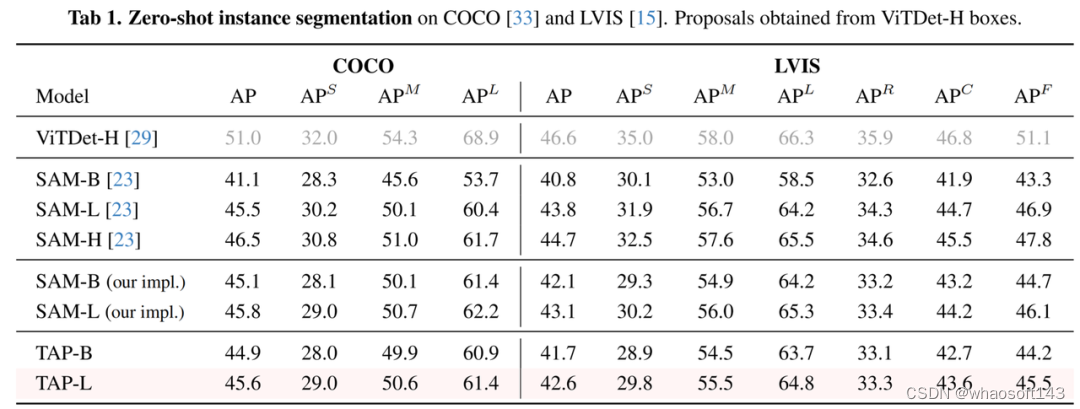
TAP 模型在零样本实例分割任务中取得了与 SAM 接近的分割精度(表1)。在零样本LVIS实例识别任务中,TAP 性能趋近于有监督检测模型的基线(表2)。基于 TAP 扩展的 38M 参数“小语言模型”在 Visual Genome 区域描述任务中取得了当前最优的 CIDEr 基准(表3),且参数量仅为此前最优方案 LLAMA-3B 的 1%。
简单点击或涂鸦图片中感兴趣的目标,TAP 即可自动生成目标区域的分割掩码、类别标签、以及对应的文本描述,实现了一个模型同时完成任意的分割、分类和图像描述。


对于需要全景理解的场景,采用密集网格点作为提示,模型即可对场景内所有的目标进行分割、识别以及描述。

#CLIP-VG
这里提出了一个简单而高效的端到端网络架构来实现CLIP到视觉定位任务的无监督和全监督迁移。该方法在单源和多源场景下的RefCOCO/+/g数据集上都明显优于当前最先进的无监督方法,提升幅度分别为从6.78%至10.67%和11.39%至14.87%,同时优于现有的弱监督方法。此外,在全监督设置下也具有显著能效优势。端到端网络架构CLIP-VG开源:简单高效实现CLIP到视觉定位任务的无监督和全监督迁移
发表期刊: IEEE Transactions on Multimedia 中科院/JCR一区顶刊
论文发表链接: https://ieeexplore.ieee.org/abstract/document/10269126
Arxiv: https://arxiv.org/abs/2305.08685
代码: https://github.com/linhuixiao/CLIP-VG(已开源)
第一作者: 肖麟慧(中科院自动化所博士)
作者单位: 中国科学院自动化所多模态人工智能系统全国重点实验室;鹏城实验室;中国科学院大学人工智能学院
摘要
视觉定位(VG)是视觉语言领域的一个重要课题,它涉及到在图像中定位由表达句子所描述的特定区域。为了减少对人工标记数据的依赖,无监督的方法使用伪标签进行学习区域定位。然而,现有的无监督方法的性能高度依赖于伪标签的质量,并且这些方法总是遇到可靠性低多样性差的问题。
为了利用视觉语言预训练模型来解决定位问题,并合理利用伪标签,我们提出了一种新颖的方法CLIP-VG,它可以使用伪语言标签对CLIP进行自步式课程自适应。我们提出了一个简单而高效的端到端网络架构来实现CLIP到视觉定位任务的迁移。在以CLIP为基础的架构上,我们进一步提出了单源和多源课程自适应算法,这些算法可以逐步找到更可靠的伪语言标签来学习最优模型,从而实现伪语言标签的可靠度和多样性之间的平衡。
我们的方法在单源和多源场景下的RefCOCO/+/g数据集上都明显优于当前最先进的无监督方法,提升幅度分别为从6.78%至10.67%和11.39%至14.87%。同时,我们的方法甚至优于现有的弱监督方法。此外,我们的模型在全监督设置下也具有一定的竞争力,同时达到SOTA的速度和能效优势。代码和模型可在https://github.com/linhuixiao/CLIP-VG上获得。
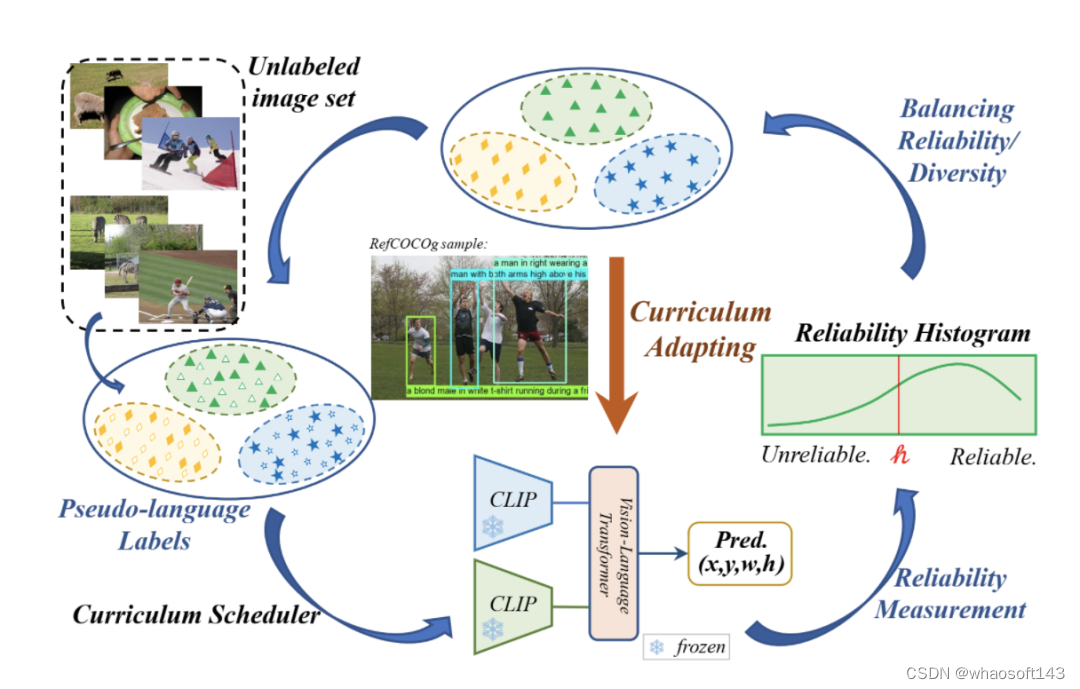
图1. CLIP-VG的主要思想,它在自步课程自适应的范式中使用伪语言标签来实现CLIP在视觉定位任务上的迁移学习
一、引言
视觉定位(Visual Grounding,VG),又称指代表达理解(Referring Expression Comprehension,REC),或短语定位(Phrase Grounding, PG),是指在特定图像中定位文本表达句子所描述的边界框(bounding box,即bbox)区域,这一技术已成为视觉问答、视觉语言导航等视觉语言(Vision-Language, V-L)领域的关键技术之一。
由于其跨模态的特性,定位需要同时理解语言表达和图像的语义,这一直是一项具有挑战性的任务。考虑到其任务复杂性,现有的方法大多侧重于全监督设置(即,使用手工三元组数据作为监督信号)。然而,有监督的定位要求使用高质量的手工标注信息。具体来说,表达句子需要与bbox配对,同时在指代上是唯一的,并且需要具有丰富的语义信息。为了减少对手工高成本的标记数据的依赖,弱监督(即,仅给定图像和查询对,没有配对的bbox)和无监督定位(即,不使用任何与任务相关的标注信息去学习定位图像区域)最近受到越来越多的关注。
现有的无监督定位方法主要是利用预训练的检测器和额外的大规模语料库实现对未配对数据的指代定位。最先进的无监督方法提出使用人工设计的模板和空间关系先验知识来匹配目标和属性检测器,再与相应的目标bbox匹配。这将生成文本表达和bbox的伪配对数据,它们被用作为伪标签,进而以监督的方式学习定位模型。然而,这些现有方法中的伪标注信息有效与否严重依赖于在特定数据集上预训练的目标或属性检测器。这可能会限制语言词汇和匹配模式的多样性,以及上下文语义的丰富度,最终损害模型的泛化能力。
在过去的几年里,视觉语言预训练(Vision-Language Pre-trained, VLP)基础模型(如CLIP)通过适应(adapting)或提示(prompting)的范式在使用少量任务相关数据的基础上进行迁移,在许多下游任务上取得了出色的结果。这些基础模型的主要优点是,它们可以通过自监督约束从网络数据和各种下游任务数据(例如,BeiT-3)中学习通用的知识。这启发我们考虑迁移VLP模型(本工作中使用CLIP),以无监督的方式解决下游定位问题。然而由于缺乏与任务相关的标记数据,因此,这是一项具有挑战性的任务。一个直接的解决方案是利用以前的无监督定位方法中生成的伪标签来微调预训练模型。然而,这将影响预训练模型的泛化能力,因为特定的伪标签和真实特定任务的标签之间存在差距。
在本文中,我们提出了CLIP-VG,如图 1 所示,这是一种新颖的方法,它可以通过利用伪语言标签对CLIP进行自步地课程自适应,进而解决视觉定位问题。首先,我们提出一个简单而高效的端到端纯 Transformer 且仅编码器的网络架构。我们只需要调整少量的参数,花费最少的训练资源,就能实现CLIP向视觉定位任务的迁移。其次,为了通过寻找可靠的伪标签来实现对CLIP网络架构更稳定的自适应迁移,我们提出了一种评估实例级标签质量的方法和一种基于自步课程学习(SPL)的渐进自适应算法,即可靠度评估(III-C部分)和单源自步自适应算法(SSA,III-D部分)。实例级可靠度被定义为特定标签源学习的评估器模型对其样本正确预测的可能性。具体而言,我们学习一个初步的定位模型作为可靠度评估器,以CLIP为模型的主干,然后对样本的可靠度进行评分,构建可靠度直方图(RH)。接下来,根据构建的直方图,以自步的方式执行SSA算法,逐步采样更可靠的伪标签,以提高定位的性能。为了有效地选择伪配对的数据子集,我们设计了一种基于改进的二叉搜索的贪心样本选择策略,以实现可靠度和多样性之间的最优平衡。
我们所提出的CLIP-VG的一个主要优点是其渐进式自适应框架,其不依赖于伪标签的特定形式或质量。因此,CLIP-VG可以灵活扩展,从而可以访问多个伪标签源。在多源场景中,我们首先独立学习每个伪标签源特定源的定位模型。然后,我们提出了源级复杂度的评估标准。具体而言,在SPL的不同步骤中,我们根据每个表达文本中实体的平均数量,从简单到复杂逐步选择伪标签源。在SSA的基础上,我们进一步提出了特定源可靠度(SR)和跨源可靠度(CR),以及多源自适应(MSA)算法(III-E节)。特定源的可靠度定义为使用当前标签源学习的定位模型正确预测当前伪标签的近似可能性。相应的,交叉源可靠度的定义是通过与其他标签源学习的定位模型正确预测当前源伪标签的近似可能性。因此,整个方法可以渐进式地利用伪标签以由易到难的课程范式来学习定位模型,最大限度地利用不同源的伪标签,从而保证基础模型的泛化能力。
在RefCOCO/+/g、RefitGame和Flickr30K Entities这五个主流测试基准中,我们的模型在单源和多源场景下的性能都明显优于SOTA无监督定位方法Pseudo-Q,分别达到6.78% ~ 10.67% 和11.39% ~ 14.87%。所提出的SSA算法和MSA算法的性能增益为3%以上。此外,我们的方法甚至优于现有的弱监督方法。与全监督SOTA模型QRNet相比,我们仅使用其更新参数的7.7% 就获得了相当的结果,同时在训练和推理方面都获得了显著的加速,分别高达26.84倍和7.41倍。与最新报道的结果相比,我们的模型在速度和能效方面也达到了SOTA。综上所述,本文的贡献有四个方面:
- 据我们所知,我们是第一个使用CLIP实现无监督视觉定位的工作。我们的方法可以将CLIP的跨模态学习能力迁移到视觉定位上,而且训练成本很小。
- 我们首次在无监督视觉定位中引入自步课程学习的范式。我们提出的可靠度评估和单源自步自适应的方法可以通过使用伪标签在由易到难的学习范式中逐步增强基于CLIP的视觉定位模型。
- 我们首先提出了多源自步自适应算法来扩展了我们的方法,同时可以获取多个伪标签源的信息,进而灵活地提高语言分类的多样性。
- 我们进行了大量的实验来评估我们方法的有效性。结果表明,我们的方法在无监督环境下取得了显著的改进,同样,我们的模型在全监督环境下也具有一定的竞争力。
二、方法
我们提出CLIP- VG,它是一种可以通过利用伪语言标签进行自步课程自适应来解决视觉定位问题的新颖方法。我们的方法主要包括: (1)、一个简单而高效的基于CLIP的纯Transformer的视觉定位模型; (2)、一个样本可靠度评估方案; (3)、一个单源场景下的自适应算法; (4)、一个进一步扩展的多源自适应算法。
A. 任务定义
我们的方法遵循之前的无监督方法Pseudo-Q的设置,即在训练期间不使用任何与任务相关的手工标注。

B.网络架构
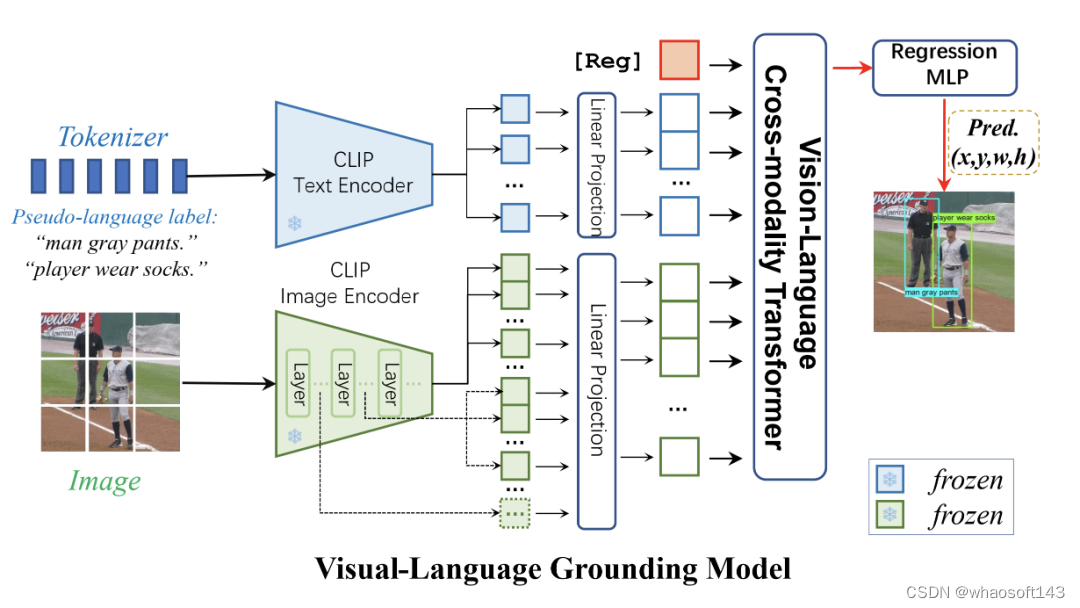
图2. CLIP-VG的模型架构

C. 可靠度评估(Reliability Measurement)
我们的方法建立在通用的课程学习范式的基础上,其中模型通过利用自己过去的预测,经过多轮由易到难的训练。为了促进定位任务中的无监督迁移,我们首先利用一个在原始伪标签上训练过的模型,应用伪标签质量评估来选择伪标签子集,然后在自训练循环中迭代重复这一过程。
在单模态任务中,我们可以很容易地通过预定义的规则来衡量数据的难度,例如句子长度、NLP中的词性熵、CV中的目标数量等,但由于跨模态定位数据的语义相关性,无法直接评估视觉定位中伪标签的质量。因此,我们定义了一个度量方法来评估伪标签的质量,称为可靠度,它被定义为通过特定标签源学习到的定位模型对其本身伪标签样本正确预测的可能性。我们认为,可靠度越高,伪标签越接近正确的标签,而更加不是噪音或不可靠的数据。

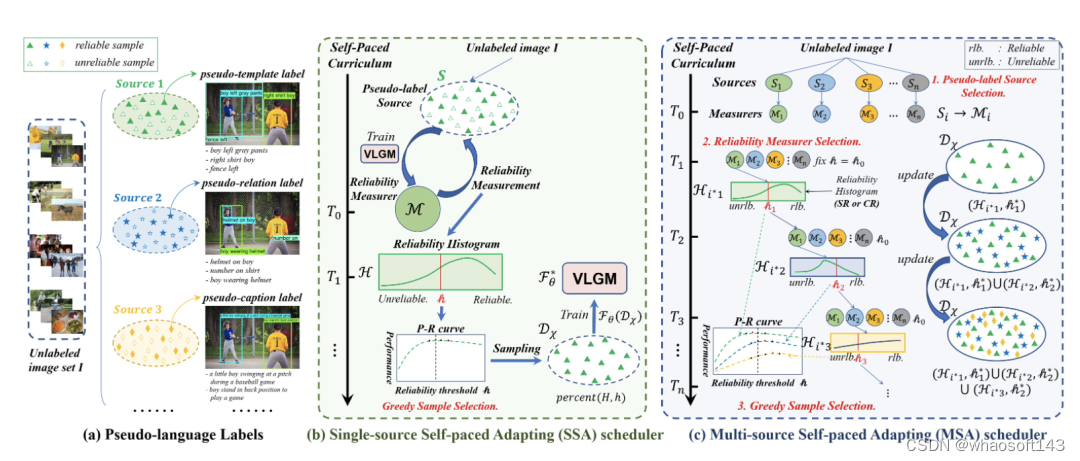
图3. 利用伪语言标签和自步课程学习实现无监督视觉定位。
图中,(a) 伪语言标签的示意图;(b)单源自步自适应(Single-source self-paced Adapting, SSA)利用视觉语言定位模型(VLGM)对伪模板标签进行可靠度评估和贪心样本选择,通过寻找可靠的伪标签实现对CLIP的自适应迁移;(c)多源自适应(Multi-source Self-paced Adapting, MSA)在SSA的基础上进一步提出了特定源可靠度(SR)和跨源可靠度(CR)。它依次进行伪标签源选择、可靠度评估器选择和贪心样本选择,从而达到可靠度和多样性的最佳平衡。
D.单源自步课程自适应算法 (Single-source Self-paced Adapting,SSA)
算法1. 单源自步课程自适应算法(SSA算法)

为了通过寻找可靠的伪标签来实现对基于CLIP的网络架构的稳定自适应,我们提出了单源自步课程自适应算法(Single-source Self-pace Curriculum Adapting algorithm, SSA),通过基于可靠度评估的课程选择的方式,逐步采样可靠的三元组伪标签。

E.多源自步课程自适应算法(Multi-source Self-paced Adapting,MSA)
算法2. 多源自步课程自适应算法(MSA算法)

我们提出的自步自适应算法不依赖于伪标签的具体形式和质量,因此可以灵活扩展用于访问多个伪标签源。使用多个伪标签源将增加语言分类和匹配模式的多样性,以及上下文语义的丰富性,从而提高视觉定位模型的泛化能力。在真实场景中,从各种视觉和语言上下文中获取多个来源的伪语言标签并不困难(如大规模语料库、视觉问答、图像描述、场景图生成、视觉语言导航等)。我们将在实验部分中详细介绍如何获得多个伪语言标签源。
随着多源伪标签的加入,不可靠数据的影响将更加严重。此外,由于不同标签源在语言分类上的分布差异,解决这一问题并不容易。因此,我们提出了基于SSA的多源自适应算法(MSA),如图3-(c) 和算法 2 所示。


三、实验
多源伪语言标签的生成
在单源情况下,我们使用Pseudo-Q中模块生成的模板伪标签。这些标签是由空间关系先验知识和检测器提供的目标标签合成的,包括类别信息和属性信息。然而,模板伪标签缺乏语法和逻辑结构,而语言词汇受到检测器识别类别的限制。
在多源情况下,除了模板伪标签外,我们利用基于场景图生成(SGG)工作RelTR生成的场景图关系作为伪关系标签,利用基于图像字幕(IC)工作M2 / CLIPCap 生成的标题作为伪标题标签。

图4. RefCOCO/+/g数据集(val split)中ground-truth查询标签的文本特征和定位难度定性对比图
A. 与最先进方法的比较
在本节中,我们在五个主流基准上验证了我们的方法,分别是 RefCOCO/+/g,ReferItGame和Flickr30K Entities。图 4 显示了RefCOCO/+/g数据集中的验证样本,这可以清晰表明三种数据集的真实定位查询标签的语言特征和定位困难程度存在显著差异。从RefCOCO到RefCOCOg,随着语言实体数量的增加,其语言复杂度也增加。
我们将我们的方法应用于单源伪模板标签和多源伪语言标签,以验证我们的方法在无监督设置中的有效性。此外,我们同样使用手工高质量的三元组手工标注在全监督设置下比较目前主流的SOTA模型,以证实我们的模型在速度和能效方面的优势。
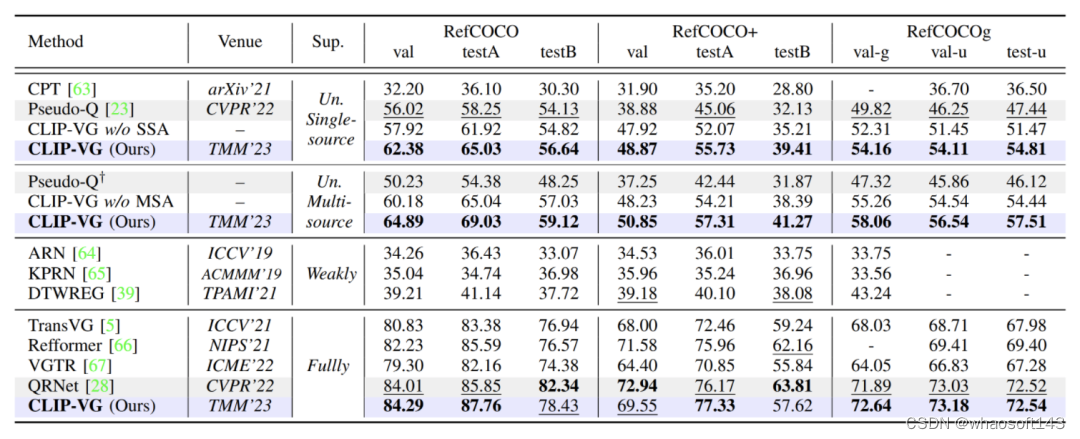
表1. 与SOTA方法在RefCOCO/+/g三个数据集上Top-1精度(Accu@0.5%)的对比结果
A.1 RefCOCO / RefCOCO + / RefCOCOg
如表1所示,我们在全监督和无监督两种情况下都提供了实验结果。我们将我们的方法与现有的SOTA无监督方法 Pseudo-Q 在单源和多源场景下进行了比较。虽然 Pseudo-Q 与之前的工作相比有了很大的提升,但我们所提方法在三个数据集上的性能都优于 Pseudo-Q,在单源数据集上分别提升了6.78%(testA)、10.67%(testA)、7.37%(test-u),在多源数据集上分别提升了14.65%(testA)、14.87%(testA)、11.39%(test-u)。伪标签很容易导致模型过拟合,从表中可知,从单源到多源,由于不可靠数据的影响,Pseudo-Q的性能下降(参见表 VIII),而我们的模型避免了多源不可靠伪标签的影响。此外,我们的结果也优于所有的弱监督方法,并且这一模型在全监督环境下也具有竞争力。
值得注意的是,我们没有在全监督的情况下比较MDETR,因为MDETR利用预训练方法通过使用来自多个数据集的混合定位数据来重新训练主干。因此,将其结果与我们的工作进行比较是不公平的。
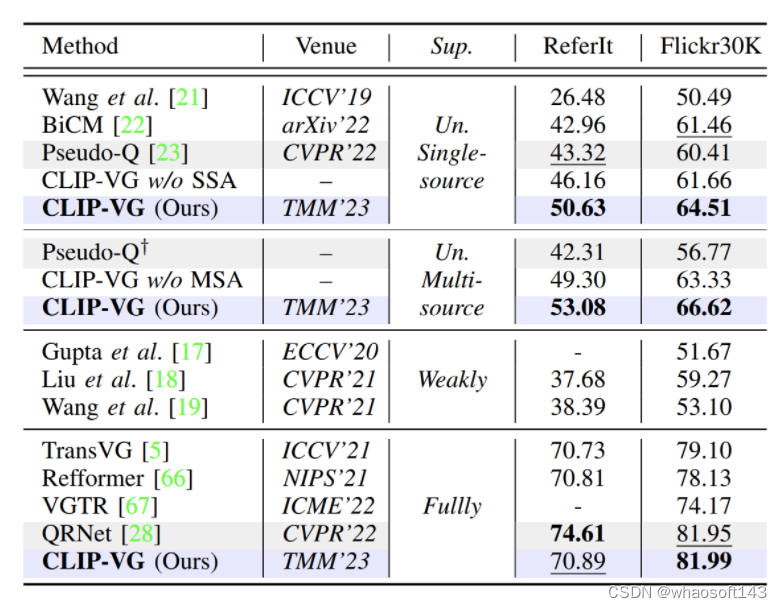
表2. 与SOTA方法在RferItGame和Flickr30K Entity两个数据集上基于Top-1精度(Accu@0.5%)的对比结果
A.2 ReferItGame 和 Flickr30K Entity
在表II中,在单源数据集和多源数据集上,我们所提方法分别比Pseudo-Q方法提高了7.31%和4.1%,以及9.77%和9.85%,并且优于所有弱监督方法。

表3. 模型的能效、推理训练速度的优势对比
B. 训练/推理成本和速度
如表 III 所示,我们比较了目前基于Transformer 的竞争模型在视觉和语言主干、模型参数、训练成本和推理速度方面的差异。其结果是在单个 NVIDIA 3090 GPU上得到的。Pseudo-Q、TransVG和 MDETR 使用的预训练主干是Resnet、BERT和DETR,而QRNet使用Resnet、Swin Transformer和BERT,而我们只使用 CLIP-ViT-B/16。从结果中我们可以看到,现有的全监督SOTA模型(如QRNet,MDETR)在训练和推理方面都特别慢。与QRNet相比,我们仅更新了其7.7%的参数,并取得了出色的训练和推理速度,分别高达26.84倍和7.41倍,同时还获得了具有竞争力的结果。基于 YORO 报告的结果,我们的模型在速度和能效方面也是最先进的。
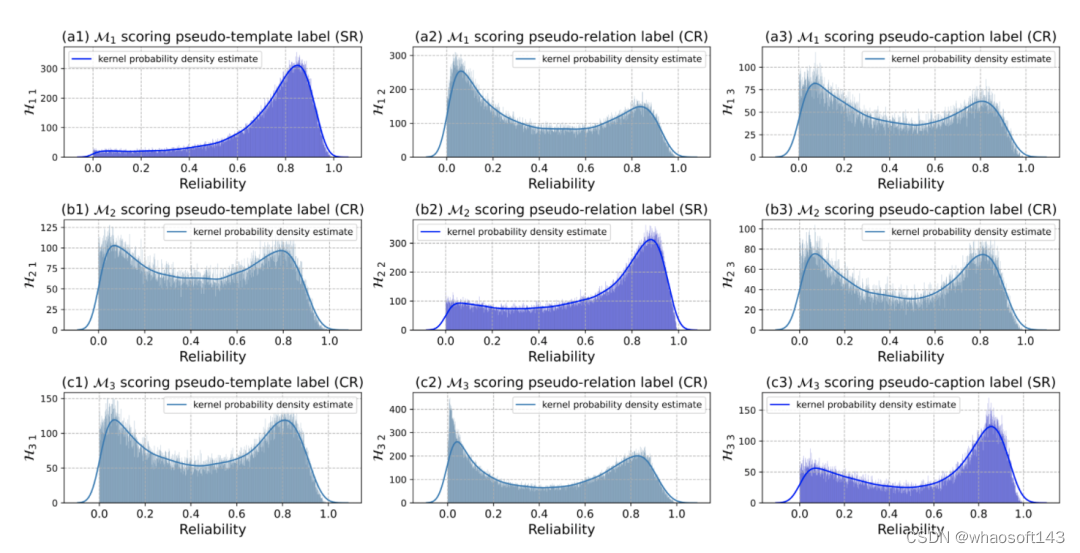
图5. 特定源可靠度和跨源可靠度分布直方图
C. 可靠度直方图的可视化
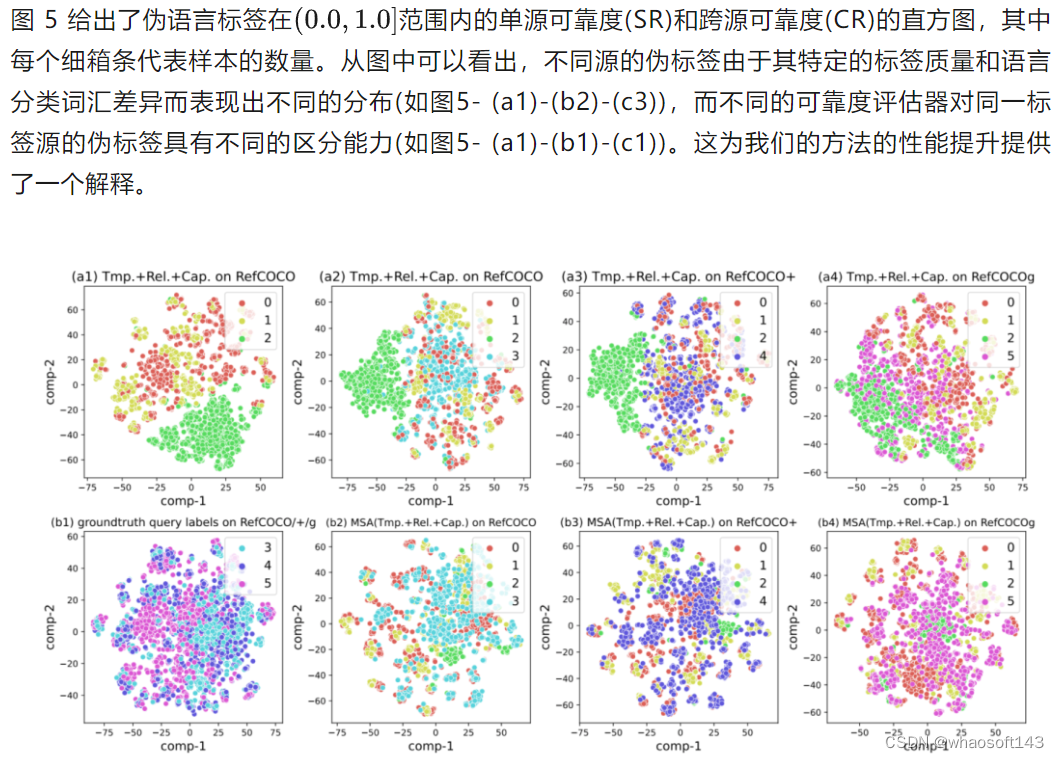
图6. 利用t-SNE对RefCOCO/+/g数据集上的伪语言标签和真实查询标签的CLIP文本特征可视化对比图
D. MSA泛化能力的可视化
如图 6 所示,我们使用 t-SNE 可视化RefCOCO/+/g数据集上伪语言标签和真值查询标签的CLIP文本特征。图6-(a1)是在RefCOCO数据集上的三个伪标签的特征,图6-(b1)是在RefCOCO/+/g在验证集上的ground-truth查询标签的特征,我们分别展示了3个伪标签源的特征分布与3个真实查询标签的特征分别的差异。图6-(a2)至(a4)和图6-(b2)至(b4)分别是在RefCOCO/+/g数据集上使用 MSA 前后三个伪标签来源和真实查询标签的特征分布对比。在MSA算法执行前,伪语言标签和真实查询标签的分布差异较大,但在MSA算法执行后,分布差异明显变小。这表明MSA可以有效地选择更可靠或更接近真实查询标签分布的伪标签。
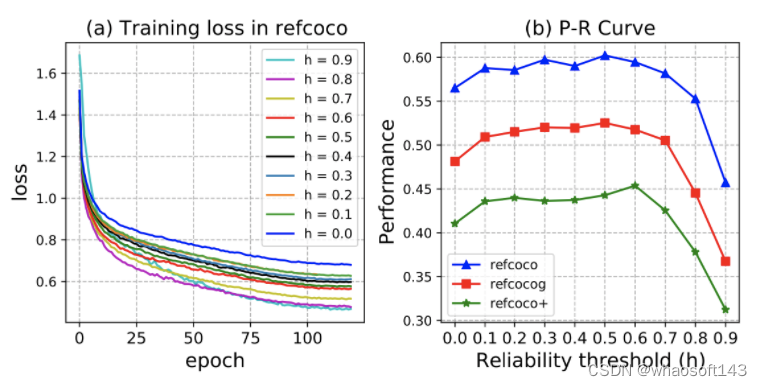
图7. 在RefCOCO/+/g数据集上执行SSA算法时,可靠性阈值 h 在 0.9 ~ 0 之间的结果。
E. 性能-可靠度(P-R)曲线与收敛性

F. 最不可靠样本分析
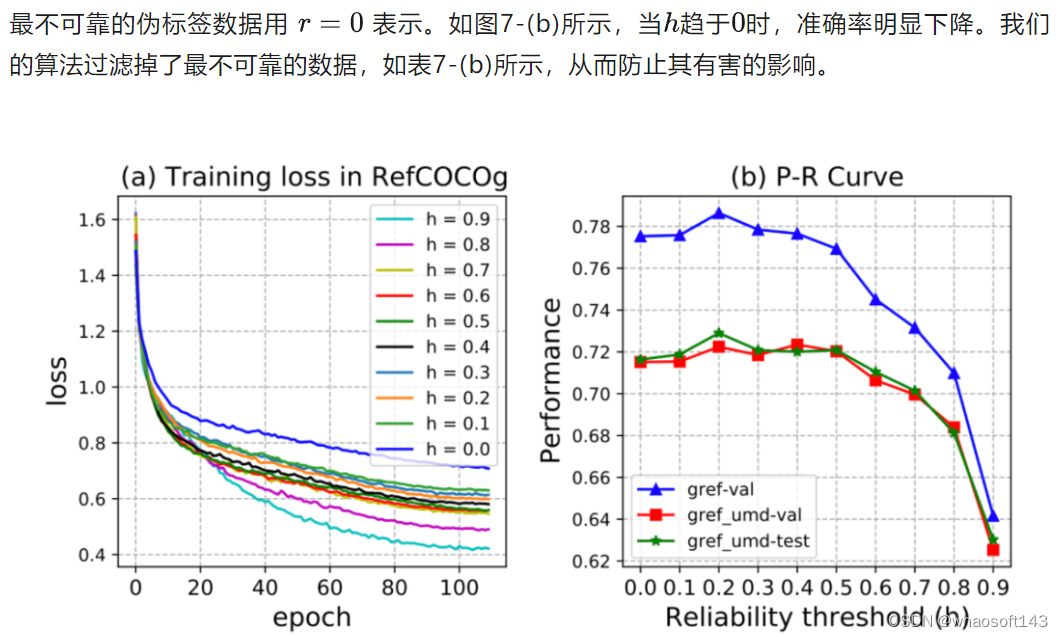
图7. 在RefCOCOg全监督数据集上执行SSA算法时,可靠性阈值 h 在 0.9 ~ 0 之间的结果。
G. 全监督设置下不可靠样本分析

图9. 最不可靠伪模板标签示意图

图10. 最不可靠伪关系标签示意图

图11. 最不可靠伪标题标签示意图
H. 不可靠伪语言标签的定性分析

在伪模板标签(图9)中,我们将不可靠数据大致分为四类:(a)、表达文本不明确,即缺乏唯一性; (b)、检测结果不正确导致的错误标签; (c)、先验信息不完整(例如,Pseudo-Q中定义的空间关系,如“前端”、“中间”、“底部”等不准确); (d)、其他问题,如偏僻的词汇、不重要或小规模的目标等。
在伪关系标签(图10)中,我们将不可靠数据大致分为(a)、模棱两可的表达文本和(b)、不显著或小尺度的目标。
在伪标题标签(图11)中,我们将不可靠数据大致分为(a)、描述整个图像的伪语言标签和(b)、边界框与标题之间的不匹配。
在各种类型的不可靠伪语言标签中,指代歧义的频率最高,特别是在具有相似分类目标的图像中。如果未来的研究希望进一步提高模型性能,解决模糊性是一个关键问题。
四、讨论
对性能提升的解释。 完成定位任务的关键在于理解语言表达文本与目标区域之间的对应关系。我们的方法为无监督设置引入了伪语言标签和伪标签质量评估方法。SSA和MSA算法实现了可靠和不可靠伪标签之间的最优平衡,使得基于CLIP的视觉定位模型学习更加稳定,进而显著提高了模型的泛化能力。
局限性。 我们提出了三种类型的伪标签,但它们的质量仍然很低。为了在可靠和不可靠的标签之间取得平衡,我们直接过滤了后者,并没有进一步使用它们,即使它们仍然可能包含有价值的信息。此外,SSA和MSA所采用的贪婪样本选择策略体现了训练成本和最优解之间的权衡。这些可以在未来的研究中进一步探索。
五、结论
在本文中,我们提出了一种新颖的CLIP-VG方法,该方法通过结合伪语言标签来实现CLIP到定位任务的无监督迁移。我们是第一次尝试在视觉定位任务中应用自步课程自适应的概念。随着下游视觉和语言文本多样性的不断演变,多源的伪标签很可能成为未来的趋势。 本文提出的多源伪语言标签和课程自适应的方法为未来的研究提供了一个新的视角。我们方法的思想简单而有效,未来可以作为即插即用的插件用于各种跨模态伪标签任务。
#NVEdit
一篇关于文本驱动的视频编辑工作NVEdit(Neural Video Fields Editing)。 基于现有 T2I 模型的帧间一致长视频编辑方法,北大张健团队提出显存高效的神经视频编辑场
本文针对现有的基于扩散模型的算法编辑结果存在明显抖动,且受限于显存限制,难以编辑长视频的缺陷,提出了一种显存高效的长视频编辑算法NVEdit,基于现有的T2I模型实现帧间一致的长视频编辑。具体来说,本文以隐式神经表示显存高效地编码视频信号,并用T2I模型优化神经网络参数,注入编辑效果,实现帧间一致的长视频编辑。实验证明:NVEdit足以编辑几百上千帧的长视频,且编辑效果高度符合文本指令并保留了原始视频的语义布局。
- 项目地址:https://nvedit.github.io/
- 代码地址:https://github.com/Ysz2022/NVEdit
- 作者:Shuzhou Yang, Chong Mou, Jiwen Yu, Yuhan Wang, Xiandong Meng, Jian Zhang
本文针对现有的基于扩散模型的算法编辑结果存在明显抖动,且受限于显存限制,难以编辑长视频的缺陷,提出了一种显存高效的长视频编辑算法NVEdit,基于现有的T2I模型实现帧间一致的长视频编辑。
具体来说,本文以隐式神经表示显存高效地编码视频信号,并用T2I模型优化神经网络参数,注入编辑效果,实现帧间一致的长视频编辑。
实验证明NVEdit足以编辑几百上千帧的长视频,且编辑效果高度符合文本指令并保留了原始视频的语义布局。

如上图所示,用户可向NVEdit提供文本指令实现帧间一致的高质量视频编辑。比如左侧第一行展示的是狼的视频,用户输入“把狼变成熊的文本”后,NVEdit成功输出一段新的视频(左侧第二行)。
本文方法支持各种编辑操作,包括变形、场景变化和风格迁移等,同时保留原始场景的运动和语义布局。由于其高效的编码率,具有几百上千帧的长视频也可被很好地编辑。
方法概述
如下图所示,本文方法由两阶段训练组成:视频拟合阶段和场编辑阶段。
在视频拟合阶段,作者先用一个神经网络(Neural Video Field)将视频信号编码为模型参数,学习原视频的运动和语义布局等先验。
在场编辑阶段,作者逐帧地让神经网络渲染出图片,调用现有的T2I模型对渲染帧进行文本驱动编辑,以编辑帧为伪GT优化网络参数,注入编辑效果。
视频拟合阶段
受益于已有的基于神经场的视频编辑算法[1,2],本文选用了一种混合的显隐式编码结构,其将视频建模为一个x-y-t的三维空间,并以三平面和稀疏网格结构显式地编码视频信号。
编码后的特征可由一个定制的轻量级MLP(multilayer perceptron)解码回RGB的像素信号。
在场编辑阶段中,作者令MLP解码的像素与原始视频对应坐标处的像素值一致,实现以神经网络参数记录视频信号的功能。此过程中,模型充分学习了原始视频的运动及语义布局等先验。
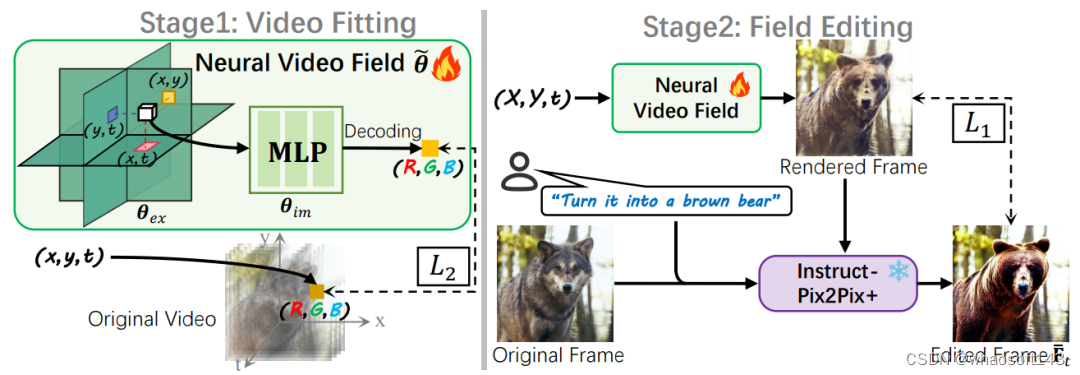
场编辑阶段
考虑到T2I算法的蓬勃发展,本文选用现有的T2I模型(Instruct-Pix2Pix[3])为视频编辑提供编辑效果。如图所示,作者逐帧渲染图像,并以原视频对应帧和用户指令为条件,调用T2I模型生成编辑帧。编辑帧可作为伪GT进一步优化上一阶段训练好的神经视频场,从而注入编辑效果。
实验结果
主观结果
如下图所示,本文展示了四组来自 NVEdit 的视觉结果,它支持多种类型的编辑,包括风格迁移和形状变化。每组结果对应的编辑文本都在下方给出。

此外,本文也与其他SOTA的文本驱动视频编辑算法做了对比实验。注意由于本文主要选用Instruct-Pix2Pix(IP2P)提供编辑效果,IP2P作为基准模型也被纳入对比范围。
为了尽可能让这个T2I模型生成帧间一致的结果,作者固定了它的随机种子。下图给出了NVEdit和其他 SOTA 方法之间的主观比较。
可以看到IP2P无法输出帧间一致的结果,例如箭头指向的区域的差异。其他方法要么扭曲形状,要么编辑了错误的区域,要么无法在不同的视点上运行稳定。
NVEdit不仅生成时序一致的内容,而且还能精确控制要编辑的区域。

定量结果
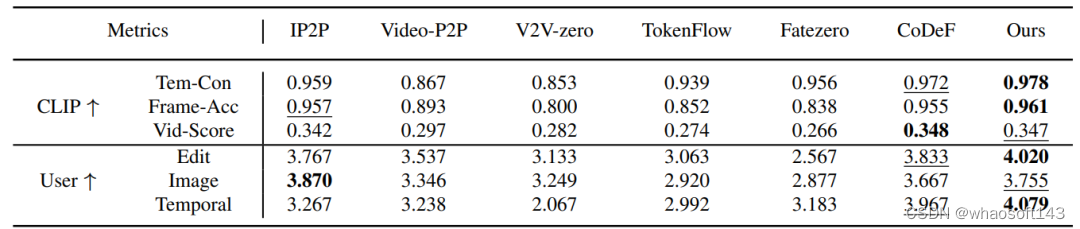
本文还设计了一些定量指标以客观对比不同方法的视频编辑效果。具体来说,作者设计了两组六个指标,分别为由CLIP计算的3个指标:
- Tem-Con:测量帧间一致性。只采用CLIP中的图像编码器,计算所有连续帧对之间的余弦相似度。
- Frame-Acc:逐帧编辑精度,表示编辑视频中与目标文本具有更高的CLIP相似度的帧占总帧数的百分比。
- Vid-Score:编辑帧和目标文本之间的余弦相似度的平均值,表示语义差异。
以及根据21名志愿者打分的3个指标,包括“Edit”、“Image”和“Temporal”。这些指标分别衡量编辑帧和目标文本之间的一致性、编辑帧的图像质量和编辑视频的时间一致性。
结果如下表所示。
显存对比
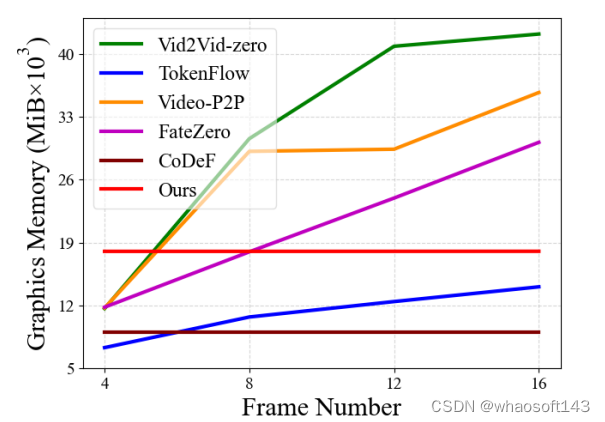
如下图所示,作者在NVIDIA A40显卡上测试了不同的视频编辑算法处理不同帧数时的显存占用情况。
横坐标为视频的帧数,纵坐标为显存开销。可以看到基于扩散模型的方法处理更多帧时都需要更大的显存,而NVEdit和CoDeF的显存开销基本稳定,这是因为他们都是基于隐式神经表示的方法,能实现长视频编辑。
而CoDeF的显存占用比NVEdit还要低一些,这是因为其采用了全隐式的编码方式,而NVEdit基于显-隐式的编码框架(三平面编码与MLP解码)。
以往的工作[4]证明了显-隐式的混合框架比隐式的方案具有更好的表示效果。CoDeF选择将视频内容映射到规范图像,从而可以仅编码运动信息,减少图形内存需求。但是对于变化较大的视频,其内容映射和运动编码往往不准确。
相比之下,本文的方法通过有效的混合结构将内容和运动一起编码解决了这个问题。
其他讨论
更换/改进T2I模型
本文还讨论了NVEdit其他有趣的性质,比如可通过更换或改进场编辑阶段调用的T2I模型,实现不同功能或更高质量的图像处理任务。
具体来说,由于NVEdit对视频的编辑效果高度依赖于T2I模型对图像的编辑性能,对T2I模型的改进可有效提升视频编辑效果。
此外,通过将T2I模型更换为其他下游的图像处理算法,NVEdit也能实现不同的视频下游任务。
作者在文中详细阐述了他们对IP2P的改进,提出了Instruct-Pix2Pix+以提升其在局部区域的图像编辑时的编辑性能,IP2P与IP2P+的效果对比如下图所示。

此外,作者还尝试了将T2I模型替换为其他的图像处理算法(如R-ESRGAN [5])使NVEdit实现其他的视频下游任务,训练操作与用T2I模型的流程一样。下图是其对视频进行4倍超分的结果,上行帧来自低分辨率视频,下行帧来自NVEdit最终的输出视频。

神经视频场的其他性质
以往的工作[1,2]已经证明了神经视频场天然具有视频插帧等性质。由于NVEdit基于视频场进行编码及编辑,因此也继承了神经表示的这些性质。
本文主要展示了视频插帧的效果,如下图所示,黄圈中的水滴在第一帧()和第二帧()会有一个从无到有的变化,而NVEdit很好地预测了中间帧()的运动。
此外,该视频是根据“Make it sunset”的文本编辑的,可以看到编辑效果也被很好地传播到了插帧的新图中,即便训练集中并不含有此帧。

实验室简介:
视觉信息智能学习实验室(VILLA)由张健助理教授在2019年创立并负责,致力于AI内容生成与安全、底层视觉、三维场景理解等研究方向,已在CVPR、ICCV、ECCV、NeurIPS、ICLR、TPAMI、TIP、IJCV、AAAI等高水平国际期刊会议上发表成果50余篇。VILLA在图像合成与编辑领域发布多款爆火技术和产品,包括T2I-Adapter、DragonDiffusion、FreeDoM。其中T2I-Adapter已被AIGC领域的独角兽公司Stability AI与其旗舰模型StableDiffusion-XL结合,推出涂鸦生成产品Stable Doodle。近期,VILLA在AIGC内容生成和安全方面推出了多项工作,包括零样本图生视频新方法AnimateZero,联合篡改定位与版权保护的多功能图像水印EditGuard,扩散隐写新范式CRoSS,基于物理的动态人机交互模拟框架PhysHOI,渐进式3D内容生成框架Progressive3D等。
更多信息可关注:
实验室主页:https://villa.jianzhang.tech/ 张健老师主页:https://jianzhang.tech/
#Upscale-A-Video
扩散模型在图像生成方面取得了显著的成功,但由于对输出保真度和时间一致性的高要求,将这些模型应用于视频超分辨率仍然具有挑战性,特别是其固有的随机性使这变得复杂。「花果山名场面」有了高清画质版,NTU提出视频超分框架
来自南洋理工大学 S-Lab 的研究团队提出了一种用于视频超分的文本指导(text-guided)潜在扩散框架 ——Upscale-A-Video。该框架通过两个关键机制确保时间一致性:在局部,它将时间层集成到 U-Net 和 VAE-Decoder 中,保持短序列的一致性;在全局范围内,无需训练,就引入了流指导(flow-guided)循环潜在传播模块,通过在整个序列中传播和融合潜在来增强整体视频的稳定性。
论文地址:https://arxiv.org/abs/2312.06640
得益于扩散范式,Upscale-A-Video 还提供了很大的灵活性,允许文本 prompt 指导纹理创建,并且可调节噪声水平以平衡恢复(restoration)和生成,从而实现保真度和质量之间的权衡。
实验结果表明,Upscale-A-Video 在合成和现实世界基准上都超越了现有方法,展示了令人印象深刻的视觉真实感和时间一致性。
我们先来看几个具体例子,例如,借助 Upscale-A-Video,「花果山名场面」有了高清画质版:

相比于 StableSR,Upscale-A-Video 让视频中的松鼠毛发纹理清晰可见:

方法简介
一些研究通过引入时间一致性策略来调整图像扩散模型以适应视频任务,其中包括:1)使用时间层微调视频模型,例如 3D 卷积和时间注意力;2)在预训练模型中采用零样本(zero-shot)机制,例如跨帧注意力和流指导注意力。
尽管这些解决方案显著提高了视频稳定性,但仍然存在两个主要问题:
- 当前在 U-Net 特征或潜在空间中运行的方法难以保持低级一致性,纹理闪烁等问题仍然存在。
- 现有的时间层和注意力机制只能对短的局部输入序列施加约束,限制了它们确保较长视频中全局时间一致性的能力。
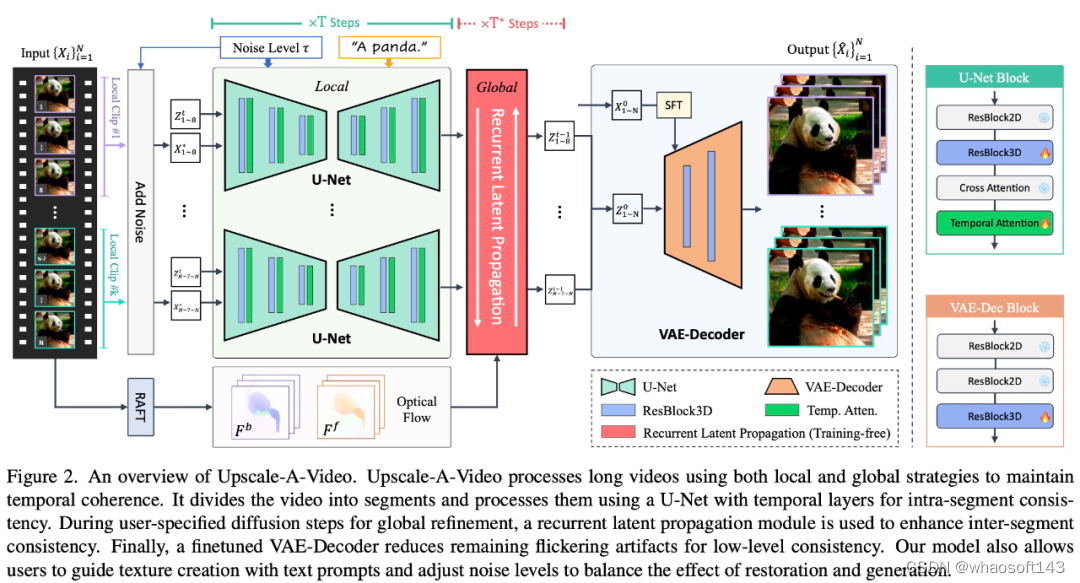
为了解决这些问题,Upscale-A-Video 采用局部-全局策略来维持视频重建中的时间一致性,重点关注细粒度纹理和整体一致性。在局部视频剪辑上,该研究探索使用视频数据上的附加时间层来微调预训练图像 ×4 超分模型。
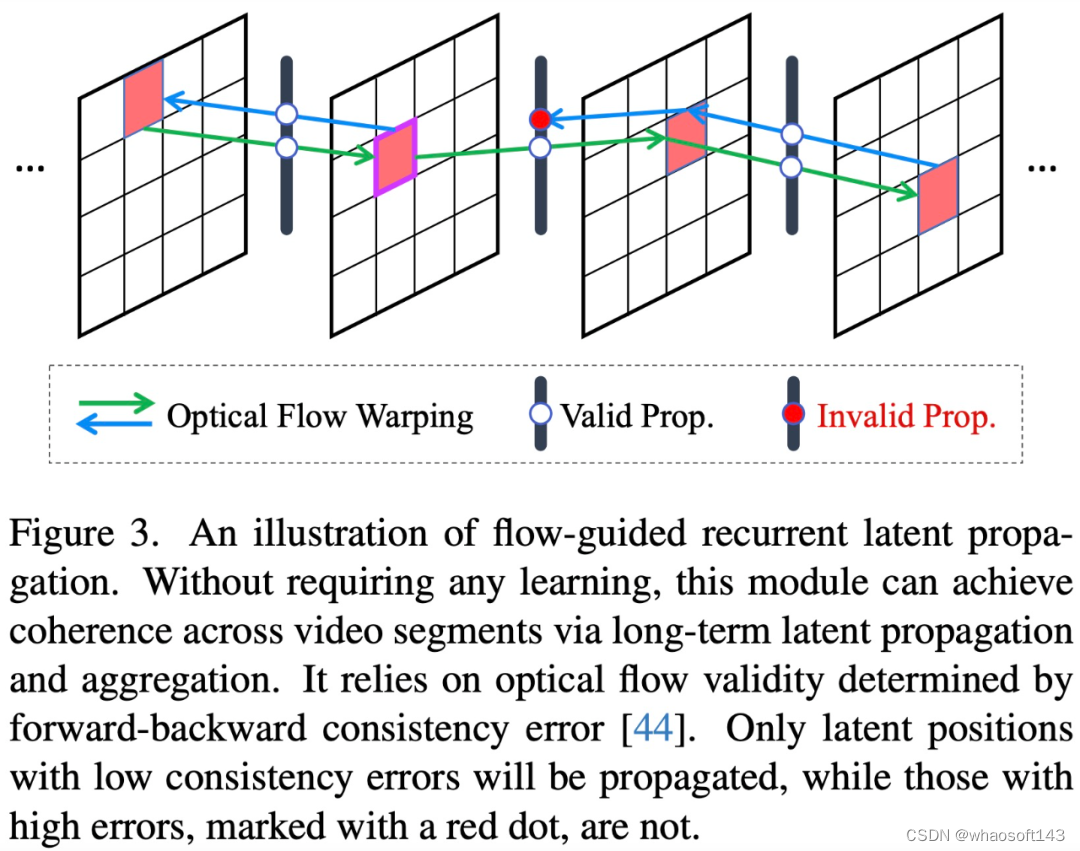
具体来说,在潜在扩散框架内,该研究首先使用集成的 3D 卷积和时间注意力层对 U-Net 进行微调,然后使用视频条件输入和 3D 卷积来调整 VAE 解码器。前者显著实现了局部序列的结构稳定性,后者进一步提高了低级一致性,减少了纹理闪烁。在全局范围内,该研究引入了一种新颖的、免训练的流指导循环潜在传播模块,在推理过程中双向进行逐帧传播和潜在融合,促进长视频的整体稳定性。
Upscale-A-Video 模型可以利用文本 prompt 作为可选条件来指导模型产生更真实、更高质量的细节,如图 1 所示。

Upscale-A-Video 将视频划分为多个片段,并使用具有时间层的 U-Net 对其进行处理,以实现片段内的一致性。在用户指定的全局细化扩散期间,使用循环潜在传播模块来增强片段间的一致性。最后,经过微调的 VAE 解码器可减少闪烁伪影,实现低级一致性。
实验结果
Upscale-A-Video 在现有基准上实现了SOTA性能,展现出卓越的视觉真实感和时间一致性。
定量评估。如表 1 所示,Upscale-A-Video在所有四个合成数据集中实现了最高的 PSNR,表明其具有出色的重建能力。
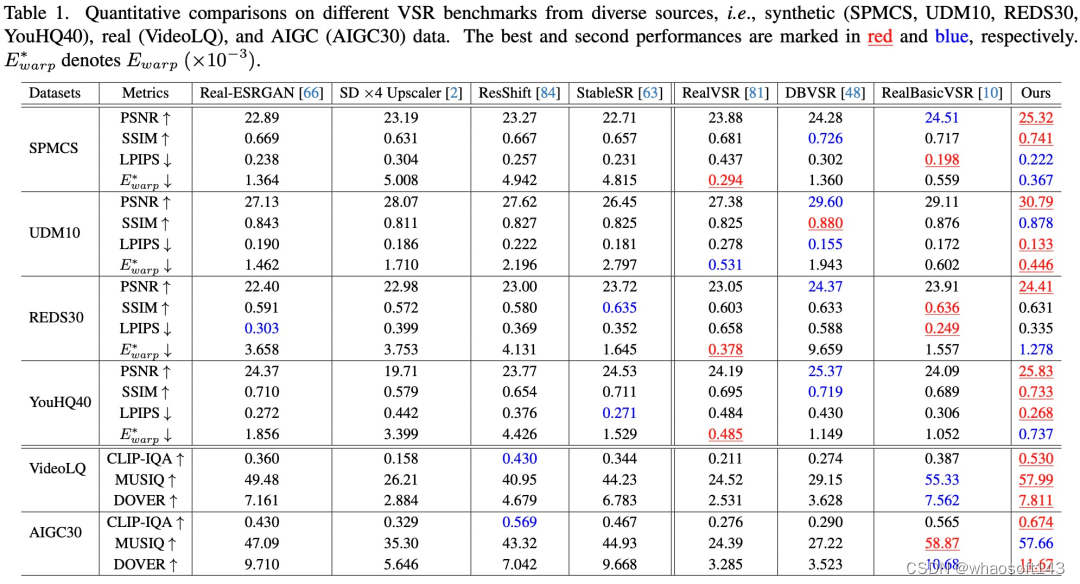
定性评估。该研究分别在图 4 和图 5 中展示了合成和真实世界视频的视觉结果。Upscale-A-Video 在伪影去除和细节生成方面都显著优于现有的 CNN 和基于扩散的方法。


相关文章:
w~视觉~合集25
我自己的原文哦~ https://blog.51cto.com/whaosoft/12627822 #Mean Shift 简单的介绍 Mean Shift 的数学原理和代码实现,基于均值漂移法 Mean Shift 的图像分割 Mean Shift 算法简介 从分割到聚类 对于图像分割算法,一个视角就是将图像中的某些点集分为一类&a…...

Applicaiton配置文件
server:port: 8080 # 配置 Spring Boot 启动端口,默认为 8080mybatis-plus:mapper-locations: classpath:com/xtl/mapper/xml/*.xml # 指定 MyBatis Mapper XML 文件的路径,确保 MyBatis 能够正确加载 Mapper 文件global-config:db-config:id-type: au…...

(已解决)wps无法加载此加载项程序mathpage.wll
今天,在安装Mathtype的时候遇到了点问题,如图所示 尝试了网上的方法,将C:\Users\Liai_\AppData\Roaming\Microsoft\Word\STARTUP路径中的替换为32位的Mathtype加载项。但此时,word又出现了问题 后来知道了,这是因为64位…...

ubity3D基础
Unity是一个流行的游戏开发引擎,它使用C#作为其主要的编程语言。以下是一些Unity中C#编程的基础概念: • Unity编辑器: • Unity编辑器是Unity游戏引擎的核心,提供了一个可视化界面,用于创建和管理游戏项目。 • C#脚本…...

Python2和Python3的区别
和python 2.x相比,python 3.x版本在语句输出、编码、运算和异常等方面做出了一些调整,我们这篇文章就对这些调整做一个简单的介绍。 Python3.x print函数代替了print语句 在python 2.x中,输出数据使用的是print语句,例如ÿ…...

Spring框架整合单元测试
目录 一、配置文件方式 1.导入依赖 2.编写类和方法 3.配置文件applicationContext-test.xml 4.测试类 5.运行结果 二、全注解方式 1.编写类和方法 2.配置类 3.测试类 4.运行结果 每次进行单元测试的时候,都需要编写创建工厂,加载配置文件等相关…...

docker-mysql
一、创建mysql 1、docker run --name mysql8.0-container -e MYSQL_ROOT_PASSWORDmy-secret-pw -d -p 3306:3306 mysql:8.0 参数解释: --name mysql8.0-container:指定容器的名称为mysql8.0-container。 -e MYSQL_ROOT_PASSWORDmy-secret-pw:…...

Java程序基础⑤Java数组的定义和使用+引用的概念
目录 1. Java数组的基本概念 1.1 数组的定义 1.2 数组存在的意义 1.3 数组的使用 1.4 二维数组 2. 引用类型JVM的内存分布 2.1 JVM的内存分布 2.2 基本数据类型和引用型数据类型的区别 2.3 引用注意事项 2.4 传值传递 3. 数组总结和应用场景 3.1 一维数组和二维数组…...

electron主进程和渲染进程之间的通信
主进程 (main.js) const { app, BrowserWindow, ipcMain } require("electron"); const path require("node:path"); // 导入fs模块 const fs require("fs");const createWindow () > {const win new BrowserWindow({width: 800,height…...

uniapp 安卓和ios震动方法,支持息屏和后台震动,ios和安卓均通过测试
最近使用uniapp开发震动功能,发现uniapp提供的 uni.vibrateLong()的方法震动比较弱,而且不支持息屏和后台震动。plus.ios.importClass("UIImpactFeedbackGenerator")是在网上看到的,这个震动也比较弱,ios也不支持息屏和…...

# DBeaver 连接hive数仓
前提 前提是基于hadoop的hive服务已经启动,其中hive的服务包括metastore元数据服务和hiveserver2服务已经启动。hiveserver2服务在默认端口10000启动,且通过telnet xx.xx.xx.xx 10000 能通。 满足以上要求后,再可以看以下连接文档ÿ…...
STM32H7开发笔记(2)——H7外设之多路定时器中断
STM32H7开发笔记(2)——H7外设之多路定时器中断 文章目录 STM32H7开发笔记(2)——H7外设之多路定时器中断0.引言1.CubeMX配置2.软件编写 0.引言 本文PC端采用Win11STM32CubeMX4.1.0.0Keil5.24.2的配置,硬件使用STM32H…...
)
Pytorch使用手册-Build the Neural Network(专题五)
在 PyTorch 中如何构建一个用于 FashionMNIST 数据集分类的神经网络模型,并解析了 PyTorch 的核心模块 torch.nn 的使用方法。以下是具体内容的讲解: 构建神经网络 在 PyTorch 中,神经网络的核心在于 torch.nn 模块,它提供了构建神经网络所需的所有工具。关键点如下: nn.…...

16. Springboot集成Tika实现文档解析
目录 1、什么是Tika 2、基本特性 3、Tika可视化提取 4、Springboot集成 4.1、maven依赖 4.2、Tika配置文件 4.3、注入tika bean 4.4、Service类 4.5、测试类TikaParserDemoTest 1、什么是Tika Tika是一款Apache开源的,跨平台,支持多品种文本类…...

【单片机毕业设计12-基于stm32c8t6的智能称重系统设计】
【单片机毕业设计12-基于stm32c8t6的智能称重系统设计】 前言一、功能介绍二、硬件部分三、软件部分总结 前言 🔥这里是小殷学长,单片机毕业设计篇12-基于stm32c8t6的智能称重系统设计 🧿创作不易,拒绝白嫖可私 一、功能介绍 ----…...

[网络]无线通信中的AMPDU
定义 AMPDU(Aggregate MAC Protocol Data Unit)即聚合MAC协议数据单元。在无线通信中,特别是在IEEE 802.11n及后续的Wi - Fi标准(如802.11ac、802.11ax)中,它是一种用于提高数据传输效率的技术。简单来说&a…...
[QDS]从零开始,写第一个Qt Design Studio到程序调用的项目
前言 最近在使用Qt Design Studio进行开发,但是简中网上要不就是只搜得到Qt Designer(Qt Creator内部库),要不就只搜得到一点营销号不知道从哪里搬来的账号,鉴于Qt Design Studio是一个这么强大的软件,自然是需要来进行一下小小的…...

Selenium Chrome Options 总结
ChromeOptions 是 Selenium 提供的一种工具,用于配置和自定义 Chrome 浏览器的启动行为。通过设置 ChromeOptions,可以添加扩展功能、设置无头模式、禁用弹窗等,满足多种测试需求。 1. 基本用法 初始化和应用 ChromeOptions from selenium…...

11、PyTorch中如何进行向量微分、矩阵微分与计算雅克比行列式
文章目录 1. Jacobian matrix2. python 代码 1. Jacobian matrix 计算 f ( x ) [ f 1 x 1 2 2 x 2 f 2 3 x 1 4 x 2 2 ] , J [ ∂ f 1 ∂ x 1 ∂ f 1 ∂ x 2 ∂ f 2 ∂ x 1 ∂ f 2 ∂ x 2 ] [ 2 x 1 2 3 8 x 2 ] \begin{equation} f(x)\begin{bmatrix} f_1x_1^22x_2\\…...

【软件方案】智慧城市,智慧园区,智慧校园,智慧社区,大数据平台建设方案,大数据中台综合解决方案(word原件)
第1章 总体说明 1.1 建设背景 1.2 建设目标 1.3 项目建设主要内容 1.4 设计原则 第2章 对项目的理解 2.1 现状分析 2.2 业务需求分析 2.3 功能需求分析 第3章 大数据平台建设方案 3.1 大数据平台总体设计 3.2 大数据平台功能设计 3.3 平台应用 第4章 政策标准保障…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...

排序算法总结(C++)
目录 一、稳定性二、排序算法选择、冒泡、插入排序归并排序随机快速排序堆排序基数排序计数排序 三、总结 一、稳定性 排序算法的稳定性是指:同样大小的样本 **(同样大小的数据)**在排序之后不会改变原始的相对次序。 稳定性对基础类型对象…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...