【小白学机器学习33】 大数定律python的 pandas.Dataframe 和 pandas.Series基础内容
目录
0 总结
0.1pd.Dataframe有一个比较麻烦琐碎的地方,就是引号 和括号
0.2 pd.Dataframe关于括号的原则
0.3 分清楚几个数据类型和对应的方法的范围
0.4 几个数据结构的构造关系
list → np.array(list) → pd.Series(np.array)/pd.Dataframe
1 python 里的 pandas.Dataframe
2 pd.concat() 可以合并 pd.Dataframe
2.1 pd.concat() 合并规则
3 pd.Dataframe.drop() 删除行列的操作
4 pd.Dataframe 列操作
5 pd.Dataframe 行操作
5.1 sample_dataframe2.head(n=2) 取前面的n行,不能任意
5.2 sample_dataframe2.query("查询条件")取前面的n行,不能任意
6 可以用pd.Dataframe().query() 方法 同时进行行和列筛选!
7 序列 pandas.Series()
7.1 什么是序列
7.2 将pd.Dataframe取出1列会变成pd.Series
7.3 序列 pd.series 和数组array() 的转化
0 总结
0.1pd.Dataframe有一个比较麻烦琐碎的地方,就是引号 和括号
- ""用的比较多,记住这个原则:
- pd.Dataframe所有的方法里,基本都是加一个""括起来基本就够了,很少有多处多重引号的。
0.2 pd.Dataframe关于括号的原则
- 关于括号,记住一个原则
- 1层括号,一般表示一维数组,比如pd.Dataframe[]取出来的一般都是1列/1行等
- 2层括号,一般表示2维数组,比如pd.Dataframe[[]] 取出来的一般都是一个子二维表
- 有些地方需要多层的中括号,[] , 比如 [ [ ] ]
0.3 分清楚几个数据类型和对应的方法的范围
- python原生的
- 原生类型,列表list,list=[1,2,3],
- 原生方法 range(1,10,1)
- numpy和 pandas都是python的大包
- numpy里
- 对应的数据类型,数组array,arr1=np.array([1,2,3])
- 专有方法np.arange(1,10,1),np.arange(start=1,stop=10,step=1),
0.4 几个数据结构的构造关系
list → np.array(list) → pd.Series(np.array)/pd.Dataframe
- python原生的
- 列表list,list1=[1,2,3],
- numpy里
- 直接用列表生成np的数组array, arr1=np.array(list1)
- pandas里
- 用 np.array 为内容,直接生成pd.Series=pd.Series(np.array())
- 用 np.array 为列,生成pd.Dataframe({key1: np.array(),key2: np.array()})
- 取出pd.Dataframe的某列,生成pd.Series
- pd.Series.values()= np.array
1 python 里的 pandas.Dataframe
- 本质是一个二维表
- 特殊点,在于多了一个默认的序号列
- 语法
- pd.Dataframe({key1:value1,key2:value2})
2 pd.concat() 可以合并 pd.Dataframe
2.1 pd.concat() 合并规则
- pd.concat() 语法
- pd.concat([pd.Dataframe1,pd.Dataframe1],axis=0/1)
- pd.concat() 可以指定合并的方向,默认是axis=0,也就是按行的方向合并
- pd.concat() 可以指定合并的方向,如果是axis=1,就是按列的方向进行合并
import numpy as np
import pandas as pd
import scipy as sp# 可以用list 生成np.array()
sample_array1=np.array([1,2,3])
sample_array2=np.array([10,20,30])
sample_array3=np.array([100,200,300])# 进一步,可以用np.array()生成pd.Series
# 注意pd.Series 首字母一定大写
sample_series1=pd.Series(sample_array1)
print(sample_series1)
print()# 进一步,也可以用np.array()生成pd.DataFrame
# 注意pd.DataFrame 首字母一定大写
sample_dataframe1=pd.DataFrame({"col1":sample_array1,"col2":sample_array2,"col3":sample_array3,})
print(sample_dataframe1)
print()sample_dataframe2=pd.DataFrame({"col1":sample_array1,"col2":sample_array2+1,"col3":sample_array3+1,})
print(sample_dataframe2)
print()print(pd.concat([sample_dataframe1,sample_dataframe2])) # pd.concat()默认合并是axis=0, 按行合并
print()print(pd.concat([sample_dataframe1,sample_dataframe2],axis=1))
print()
3 pd.Dataframe.drop() 删除行列的操作
- pd.Dataframe.drop()
- pd.Dataframe.drop("行名/列名",axis=0/1)
- axis=0 是行
- 注意:列名一般是字符串,如 "col1"
- 注意:行名一般是数字,如 1

4 pd.Dataframe 列操作
- pd.Dataframe 数据帧
- 操作列的办法有两种
- 直接引用 pd.Dataframe 对象的属性,pd.Dataframe.列名(不加字符串引号)
- 类切片的列操作方法
- pd.Dataframe["列名1"]
- pd.Dataframe[["列名1","列名2","列名3"]] #注意是双层中括号

5 pd.Dataframe 行操作
- 行操作有两种方法
- sample_dataframe2.head() 方法
- sample_dataframe2.query()方法
5.1 sample_dataframe2.head(n=2) 取前面的n行,不能任意
- n 只能是前面的连续列
print(sample_dataframe2)
print()
print(sample_dataframe2.head(n=2))

5.2 sample_dataframe2.query("查询条件")取前面的n行,不能任意
- sample_dataframe2.query("查询条件")
- sample_dataframe2.query("可以是任意的一个行条件,不要求非是index的值!")
- sample_dataframe2.query("条件1 | 条件2") # or 关系
- sample_dataframe2.query("条件1& 条件2") # and关系

6 可以用pd.Dataframe().query() 方法 同时进行行和列筛选!
print(sample_dataframe2.query("col3==301")[["col2","col3"]])
7 序列 pandas.Series()
7.1 什么是序列
- 特殊之处:默认带一个序号列
- 可以认为是带 序号的 数组/列表
- pandas.Series( data, index, dtype, copy)
data:输入的数据,可以是列表、常量、ndarray 数组等。
index:索引值必须是唯一的,与data的长度相同,默认为np.arange(n)
dtype:数据类型
copy:是否复制数据,默认为false
7.2 将pd.Dataframe取出1列会变成pd.Series
- 将pd.Dataframe取出1列会变成pd.Series
- 也就是说 pd.Series 是 pd.Dataframe 的其中1列!
- 注意方法不同有差别
- 如果是单取出1列,生成pd.Series
- 如果是单取出多列,生成的只是更小的pd.Dataframe,并不是pd.Series,很好理解,不要搞错。
print(sample_dataframe2)
print()
print(sample_dataframe2.col2)
print()
print(sample_dataframe2["col2"])
print()
print(sample_dataframe2[["col2"]])
print()print(type(sample_dataframe2))
print()
print(type(sample_dataframe2.col2))
print()
print(type(sample_dataframe2["col2"]))
print()
print(type(sample_dataframe2[["col2"]]))

7.3 序列 pd.series 和数组array() 的转化
- pd.series.values 即可以生成对应的 np.array() 数组!
print(sample_dataframe2)
print()
print(sample_dataframe2.col2)
print()
print(sample_dataframe2.col2.values)
print()print(type(sample_dataframe2))
print()
print(type(sample_dataframe2.col2))
print()
print(type(sample_dataframe2.col2.values))
print()
相关文章:
【小白学机器学习33】 大数定律python的 pandas.Dataframe 和 pandas.Series基础内容
目录 0 总结 0.1pd.Dataframe有一个比较麻烦琐碎的地方,就是引号 和括号 0.2 pd.Dataframe关于括号的原则 0.3 分清楚几个数据类型和对应的方法的范围 0.4 几个数据结构的构造关系 list → np.array(list) → pd.Series(np.array)/pd.Dataframe 1 python 里…...

【shodan】(五)网段利用
shodan基础(五) 声明:该笔记为up主 泷羽的课程笔记,本节链接指路。 警告:本教程仅作学习用途,若有用于非法行为的,概不负责。 nsa ip address range www.nsa.gov需科学上网 搜索网段 shodan s…...
)
LeetCode739. 每日温度(2024冬季每日一题 15)
给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。 示例 1: 输入: temperatu…...

Node.js的http模块:创建HTTP服务器、客户端示例
新书速览|Vue.jsNode.js全栈开发实战-CSDN博客 《Vue.jsNode.js全栈开发实战(第2版)(Web前端技术丛书)》(王金柱)【摘要 书评 试读】- 京东图书 (jd.com) 要使用http模块,只需要在文件中通过require(http)引入即可。…...

加菲工具 - 好用免费的在线工具集合
加菲工具 https://orcc.online AI 工具 加菲工具 集合了目前主流的,免费可用的ai工具 文档处理 加菲工具 pdf转word、office与pdf互转等等工具都有链接 图片图标 加菲工具 统计了好用免费的在线工具 编码解码 加菲工具 base64编码解码、url编码解码、md5计算…...

.NET9 - 新功能体验(二)
书接上回,我们继续来聊聊.NET9和C#13带来的新变化。 01、新的泛型约束 allows ref struct 这是在 C# 13 中,引入的一项新的泛型约束功能,允许对泛型类型参数应用 ref struct 约束。 可能这样说不够直观,简单来说就是Span、ReadO…...

map和redis关系
Map 和 Redis 都是用于存储和管理数据的工具,但它们在用途、实现和应用场景上有所不同。下面详细解释 Map 和 Redis 之间的关系和区别。 1. Map 数据结构 定义 Map 是一种数据结构,用于存储键值对(key-value pairs)。每个键都是…...

《数据结构》学习系列——图(中)
系列文章目录 目录 图的遍历深度优先遍历递归算法堆栈算法 广度优先搜索 拓扑排序定义定理算法思想伪代码 关键路径基本概念关键活动有关量数学公式伪代码时间复杂性 图的遍历 从给定连通图的某一顶点出发,沿着一些边访问遍图中所有的顶点,且使每个顶点…...

探索Python的HTTP之旅:揭秘Requests库的神秘面纱
文章目录 **探索Python的HTTP之旅:揭秘Requests库的神秘面纱**第一部分:背景介绍第二部分:Requests库是什么?第三部分:如何安装Requests库?第四部分:Requests库的五个简单函数使用方法第五部分&…...

Python 爬虫从入门到(不)入狱学习笔记
爬虫的流程:从入门到入狱 1 获取网页内容1.1 发送 HTTP 请求1.2 Python 的 Requests 库1.2 实战:豆瓣电影 scrape_douban.py 2 解析网页内容2.1 HTML 网页结构2.2 Python 的 Beautiful Soup 库 3 存储或分析数据(略) 一般爬虫的基…...
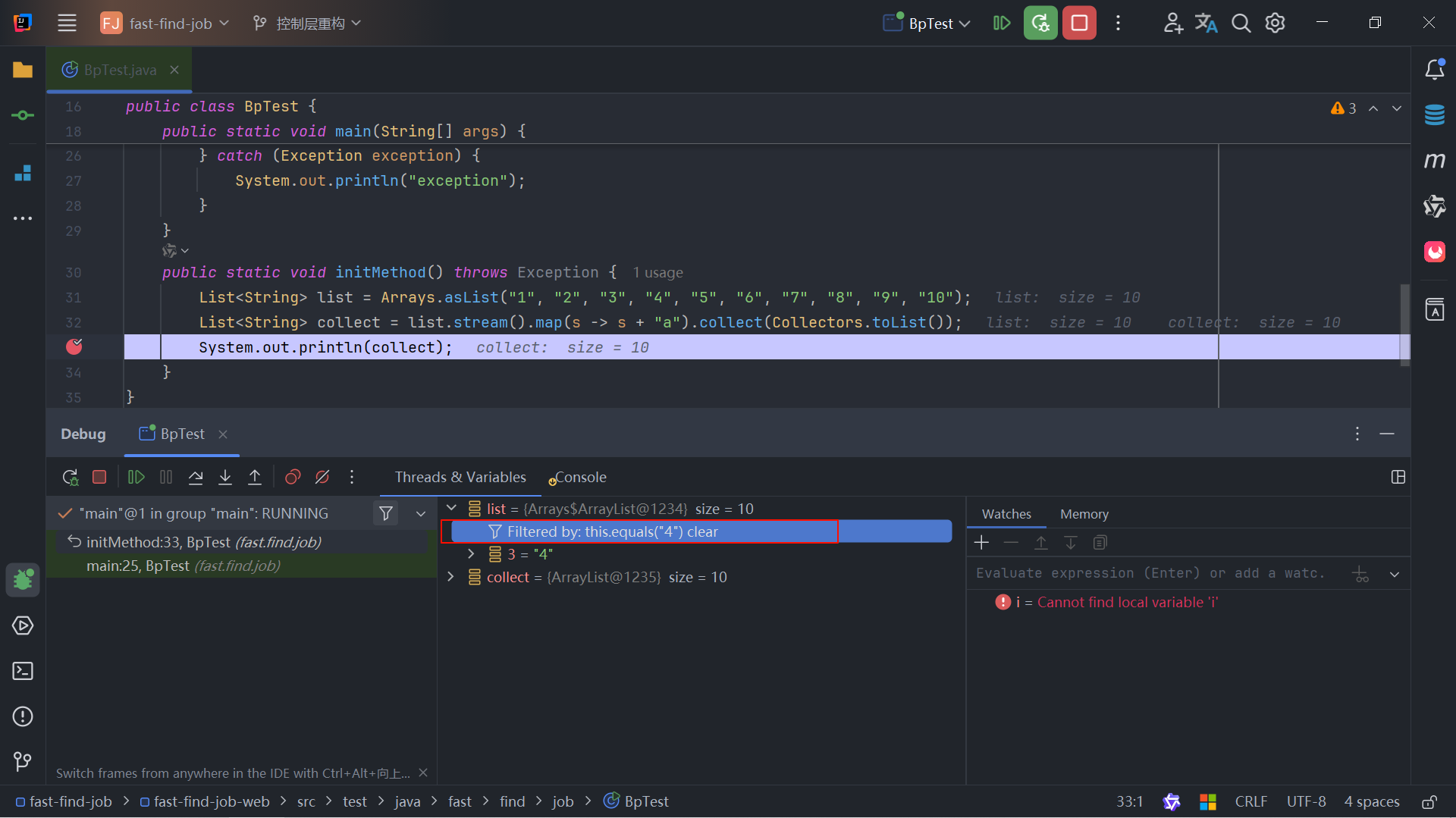
IDEA优雅debug
目录 引言一、断点分类🎄1.1 行断点1.2 方法断点1.3 属性断点1.4 异常断点1.5 条件断点1.6 源断点1.7 多线程断点1.8 Stream断点 二、调试动作✨三、Debug高级技巧🎉3.1 watch3.2 设置变量3.3 异常抛出3.4 监控JVM堆大小3.5 数组过滤和筛选 引言 使用ID…...

wp the_posts_pagination 与分类页面搭配使用
<ul> <?php while( have_posts() ) : the_post(); <li > <a href"<?php the_permalink(); ?>"> <?php xizhitbu_get_thumbnail(thumb-pro); ?> </a> <p > <a href&q…...

大数据-231 离线数仓 - DWS 层、ADS 层的创建 Hive 执行脚本
点一下关注吧!!!非常感谢!!持续更新!!! Java篇开始了! 目前开始更新 MyBatis,一起深入浅出! 目前已经更新到了: Hadoop࿰…...

【Python】分割秘籍!掌握split()方法,让你的字符串处理轻松无敌!
在Python开发中,字符串处理是最常见也是最基础的任务之一。而在众多字符串操作方法中,split()函数无疑是最为重要和常用的一个。无论你是Python新手,还是经验丰富的开发者,深入理解并熟练运用split()方法,都将大大提升…...

免费实用在线AI工具集合 - 加菲工具
免费在线工具-加菲工具 https://orcc.online/ 在线录屏 https://orcc.online/recorder 时间戳转换 https://orcc.online/timestamp Base64 编码解码 https://orcc.online/base64 URL 编码解码 https://orcc.online/url Hash(MD5/SHA1/SHA256…) 计算 https://orcc.online/h…...

正则表达式灾难:重新认识“KISS原则”的意义
RSS Feed 文章标题整理 微积分在生活中的应用与思维启发 捕鹿到瞬时速度的趣味探索 微积分是一扇通往更广阔世界的门,从生活中学习思维的工具。 数据库才是最强架构 你还在被“复杂架构”误导吗? 把业务逻辑写入数据库,重新定义简单与效率。…...
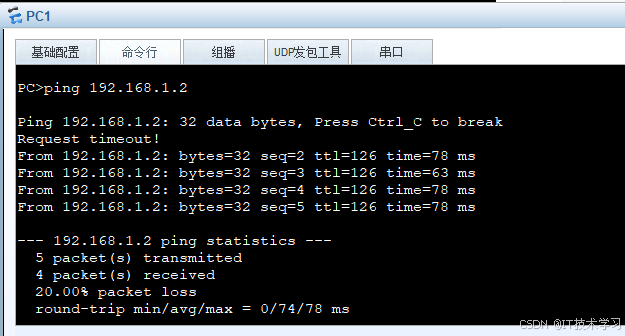
eNSP-缺省路由配置
缺省路由是一种特殊的静态路由,其目的地址为0.0.0.0,子网掩码为0.0.0.0。 1.拓扑图搭建 2.配置路由器 AR2 <Huawei>sys #进入系统视图 [Huawei]ip route-static 0.0.0.0 0.0.0.0 192.168.3.2 #设置缺省路由 [Huawei]q #返回上一层 <Huawe…...

solr 远程命令执行 (CVE-2019-17558)
漏洞描述 Apache Velocity是一个基于Java的模板引擎,它提供了一个模板语言去引用由Java代码定义的对象。Velocity是Apache基金会旗下的一个开源软件项目,旨在确保Web应用程序在表示层和业务逻辑层之间的隔离(即MVC设计模式)。 Apa…...

STM32端口模拟编码器输入
文章目录 前言一、正交编码器是什么?二、使用步骤2.1开启时钟2.2配置编码器引脚 TIM3 CH1(PA6) CH2 (PA7)上拉输入2.3.初始化编码器时基2.4 初始化编码器输入2.5 配置编码器接口2.6 开启定时器2.7获取编码器数据 三、参考程序四、测试结果4.1测试方法4.2串口输出结果…...

Centos 8, add repo
Centos repo前言 Centos 8更换在线阿里云创建一键更换repo 自动化脚本 华为Centos 源 , 阿里云Centos 源 华为epel 源 , 阿里云epel 源vim /centos8_repo.sh #!/bin/bash # -*- coding: utf-8 -*- # Author: make.han...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...
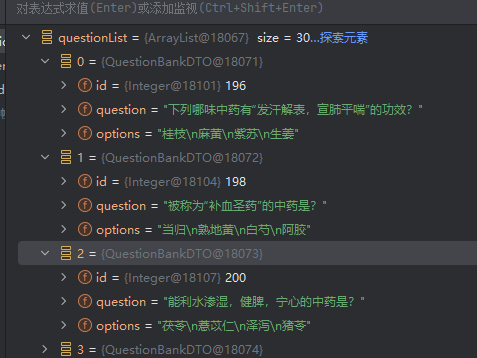
jdbc查询mysql数据库时,出现id顺序错误的情况
我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。 Query("SELECT NEW com…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...