7、深入剖析PyTorch nn.Module源码
文章目录
- 1. 重要类
- 2. add_modules
- 3. Apply(fn)
- 4. register_buffer
- 5. nn.Parameters®ister_parameters
- 6. 后续测试
1. 重要类
- nn.module --> 所有神经网络的父类,自定义神经网络需要继承此类,并且自定义__init__,forward函数即可:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @FileName :MyModelNet.py
# @Time :2024/11/20 13:38
# @Author :Jason Zhang
import torch
from torch import nnclass NeuralNetwork(nn.Module):def __init__(self):super(NeuralNetwork,self).__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28 * 28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10))def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x)return logitsif __name__ == "__main__":run_code = 0x_row = 28x_column = 28x_total = x_row * x_columnx = torch.arange(x_total, dtype=torch.float).reshape((1, x_row, x_column))my_net = NeuralNetwork()y = my_net(x)print(f"y.shape={y.shape}")print(my_net)
- 结果:
y.shape=torch.Size([1, 10])
NeuralNetwork((flatten): Flatten(start_dim=1, end_dim=-1)(linear_relu_stack): Sequential((0): Linear(in_features=784, out_features=512, bias=True)(1): ReLU()(2): Linear(in_features=512, out_features=512, bias=True)(3): ReLU()(4): Linear(in_features=512, out_features=10, bias=True))
)
2. add_modules
通过add_modules在旧的网络里面添加新的网络
- 重点: 用nn.ModuleList自带的insert,新的网络继承自老网络中,直接用按位置插入
- python
import torch
from torch import nn
from pytorch_model_summary import summarytorch.manual_seed(2323)class MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.flatten = nn.Flatten()self.block = nn.ModuleList([nn.Linear(28 * 28, 512),nn.ReLU(),nn.Linear(512, 10)])def forward(self, x):x = self.flatten(x)for layer in self.block:x = layer(x)return xclass MyNewNet(MyModel):def __init__(self):super(MyNewNet, self).__init__()self.block.insert(2, nn.Linear(512, 256)) # 插入新层self.block.insert(3, nn.ReLU()) # 插入新的激活函数self.block.insert(4, nn.Linear(256, 512)) # 插入另一层self.block.insert(5, nn.ReLU()) # 插入激活函数if __name__ == "__main__":# 测试原始模型my_model = MyModel()print("Original Model:")print(summary(my_model, torch.ones((1, 28, 28))))# 测试新模型my_new_model = MyNewNet()print("\nNew Model:")print(summary(my_new_model, torch.ones((1, 28, 28))))
- 结果:
Original Model:
-----------------------------------------------------------------------Layer (type) Output Shape Param # Tr. Param #
=======================================================================Flatten-1 [1, 784] 0 0Linear-2 [1, 512] 401,920 401,920ReLU-3 [1, 512] 0 0Linear-4 [1, 10] 5,130 5,130
=======================================================================
Total params: 407,050
Trainable params: 407,050
Non-trainable params: 0
-----------------------------------------------------------------------New Model:
-----------------------------------------------------------------------Layer (type) Output Shape Param # Tr. Param #
=======================================================================Flatten-1 [1, 784] 0 0Linear-2 [1, 512] 401,920 401,920ReLU-3 [1, 512] 0 0Linear-4 [1, 256] 131,328 131,328ReLU-5 [1, 256] 0 0Linear-6 [1, 512] 131,584 131,584ReLU-7 [1, 512] 0 0Linear-8 [1, 10] 5,130 5,130
=======================================================================
Total params: 669,962
Trainable params: 669,962
Non-trainable params: 0
-----------------------------------------------------------------------
3. Apply(fn)
模型权重weight,bias 的初始化
- python
import torch.nn as nn
import torchclass MyAwesomeModel(nn.Module):def __init__(self):super(MyAwesomeModel, self).__init__()self.fc1 = nn.Linear(3, 4)self.fc2 = nn.Linear(4, 5)self.fc3 = nn.Linear(5, 6)# 定义初始化函数
@torch.no_grad()
def init_weights(m):print(m)if type(m) == nn.Linear:m.weight.fill_(1.0)print(m.weight)# 创建神经网络实例
model = MyAwesomeModel()# 应用初始化权值函数到神经网络上
model.apply(init_weights)
- 结果:
Linear(in_features=3, out_features=4, bias=True)
Parameter containing:
tensor([[1., 1., 1.],[1., 1., 1.],[1., 1., 1.],[1., 1., 1.]], requires_grad=True)
Linear(in_features=4, out_features=5, bias=True)
Parameter containing:
tensor([[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]], requires_grad=True)
Linear(in_features=5, out_features=6, bias=True)
Parameter containing:
tensor([[1., 1., 1., 1., 1.],[1., 1., 1., 1., 1.],[1., 1., 1., 1., 1.],[1., 1., 1., 1., 1.],[1., 1., 1., 1., 1.],[1., 1., 1., 1., 1.]], requires_grad=True)
MyAwesomeModel((fc1): Linear(in_features=3, out_features=4, bias=True)(fc2): Linear(in_features=4, out_features=5, bias=True)(fc3): Linear(in_features=5, out_features=6, bias=True)
)Process finished with exit code 04. register_buffer
将模型中添加常数项。比如加1
- python:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @FileName :RegisterBuffer.py
# @Time :2024/11/23 19:21
# @Author :Jason Zhang
import torch
from torch import nnclass MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.register_buffer("my_buffer_a", torch.ones(2, 3))def forward(self, x):x = x + self.my_buffer_areturn xif __name__ == "__main__":run_code = 0my_test = MyNet()in_x = torch.arange(6).reshape((2, 3))y = my_test(in_x)print(f"x=\n{in_x}")print(f"y=\n{y}")
- 结果:
x=
tensor([[0, 1, 2],[3, 4, 5]])
y=
tensor([[1., 2., 3.],[4., 5., 6.]])
5. nn.Parameters®ister_parameters
- python
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @FileName :ParameterTest.py
# @Time :2024/11/23 19:37
# @Author :Jason Zhang
import torch
from torch import nnclass MyModule(nn.Module):def __init__(self, in_size, out_size):self.in_size = in_sizeself.out_size = out_sizesuper(MyModule, self).__init__()self.test = torch.rand(self.in_size, self.out_size)self.linear = nn.Linear(self.in_size, self.out_size)def forward(self, x):x = self.linear(x)return xclass MyModuleRegister(nn.Module):def __init__(self, in_size, out_size):self.in_size = in_sizeself.out_size = out_sizesuper(MyModuleRegister, self).__init__()self.test = torch.rand(self.in_size, self.out_size)self.linear = nn.Linear(self.in_size, self.out_size)def forward(self, x):x = self.linear(x)return xclass MyModulePara(nn.Module):def __init__(self, in_size, out_size):self.in_size = in_sizeself.out_size = out_sizesuper(MyModulePara, self).__init__()self.test = nn.Parameter(torch.rand(self.in_size, self.out_size))self.linear = nn.Linear(self.in_size, self.out_size)def forward(self, x):x = self.linear(x)return xif __name__ == "__main__":run_code = 0test_in = 4test_out = 6my_test = MyModule(test_in, test_out)my_test_para = MyModulePara(test_in, test_out)test_list = list(my_test.named_parameters())test_list_para = list(my_test_para.named_parameters())my_test_register = MyModuleRegister(test_in, test_out)para_register = nn.Parameter(torch.rand(test_in, test_out))my_test_register.register_parameter('para_add_register', para_register)test_list_para_register = list(my_test_register.named_parameters())print(f"*" * 50)print(f"test_list=\n{test_list}")print(f"*" * 50)print(f"*" * 50)print(f"test_list_para=\n{test_list_para}")print(f"*" * 50)print(f"*" * 50)print(f"test_list_para_register=\n{test_list_para_register}")print(f"*" * 50)
- 结果:
**************************************************
test_list=
[('linear.weight', Parameter containing:
tensor([[ 0.3805, -0.3368, 0.2348, 0.4525],[-0.4557, -0.3344, 0.1368, -0.3471],[-0.3961, 0.3302, 0.1904, -0.0111],[ 0.4542, -0.3325, -0.3782, 0.0376],[ 0.2083, -0.3113, -0.3447, -0.1503],[ 0.0343, 0.0410, -0.4216, -0.4793]], requires_grad=True)), ('linear.bias', Parameter containing:
tensor([-0.3465, -0.4510, 0.4919, 0.1967, -0.1366, -0.2496],requires_grad=True))]
**************************************************
**************************************************
test_list_para=
[('test', Parameter containing:
tensor([[0.1353, 0.9934, 0.0462, 0.2103, 0.3410, 0.0814],[0.7509, 0.2573, 0.8030, 0.0952, 0.1381, 0.5360],[0.1972, 0.1241, 0.5597, 0.2691, 0.3226, 0.0660],[0.3333, 0.8031, 0.9226, 0.4290, 0.3660, 0.6159]], requires_grad=True)), ('linear.weight', Parameter containing:
tensor([[-0.0633, -0.4030, -0.4962, 0.1928],[-0.1707, 0.2259, 0.0373, -0.0317],[ 0.4523, 0.2439, -0.1376, -0.3323],[ 0.3215, 0.1283, 0.0729, 0.3912],[ 0.0262, -0.1087, 0.4721, -0.1661],[-0.1055, -0.2199, -0.4974, -0.3444]], requires_grad=True)), ('linear.bias', Parameter containing:
tensor([ 0.3702, -0.0142, -0.2098, -0.0910, -0.2323, -0.0546],requires_grad=True))]
**************************************************
**************************************************
test_list_para_register=
[('para_add_register', Parameter containing:
tensor([[0.2428, 0.1388, 0.6612, 0.4215, 0.0215, 0.2618],[0.4234, 0.0160, 0.8947, 0.4784, 0.4403, 0.4800],[0.8845, 0.1469, 0.6894, 0.7050, 0.5911, 0.7702],[0.7694, 0.0491, 0.3583, 0.4451, 0.2282, 0.4293]], requires_grad=True)), ('linear.weight', Parameter containing:
tensor([[ 0.1358, -0.4704, -0.4181, -0.4504],[ 0.0903, 0.3235, -0.3164, -0.4163],[ 0.1342, 0.3108, 0.0612, -0.2910],[ 0.3527, 0.3397, -0.0414, -0.0408],[-0.4877, 0.1925, -0.2912, -0.2239],[-0.0081, -0.1730, 0.0921, -0.4210]], requires_grad=True)), ('linear.bias', Parameter containing:
tensor([-0.2194, 0.2233, -0.4950, -0.3260, -0.0206, -0.0197],requires_grad=True))]
**************************************************
6. 后续测试
- register_module
- get_submodule
- get_parameter
相关文章:

7、深入剖析PyTorch nn.Module源码
文章目录 1. 重要类2. add_modules3. Apply(fn)4. register_buffer5. nn.Parametersister_parameters6. 后续测试 1. 重要类 nn.module --> 所有神经网络的父类,自定义神经网络需要继承此类,并且自定义__init__,forward函数即可: #!/usr…...

如何提升编程能力第二篇
如何提升编程能力2 1. 引言2. 掌握理论基础2.1 理解编程语言的核心2.2 数据结构与算法2.3 计算机基础与系统设计3.1 多写代码3.2 参与开源项目3.3 开发自己的项目 4. 提高代码质量4.1 代码风格与可读性4.2 测试驱动开发 1. 引言 编程是推动现代科技发展的核心技能,…...

问:SpringBoot核心配置文件都有啥,怎么配?
在SpringBoot的开发过程中,核心配置文件扮演着至关重要的角色。这些文件用于配置应用程序的各种属性和环境设置,使得开发者能够灵活地定制和管理应用程序的行为。本文将探讨SpringBoot的核心配置文件,包括它们的作用、区别,并通过…...

RHCSA作业
课后练习 将整个 /etc 目录下的文件全部打包并用 gzip 压缩成/back/etcback.tar.gz [rootlocalhost ~]# tar -czvf /back/etcback.tar.gz -C / etc 使当前用户永久生效的命令别名:写一个命令命为hello,实现的功能为每输入一次hello命令,就有hello&#…...
——SoftwareTimer)
ESP32学习笔记_FreeRTOS(3)——SoftwareTimer
摘要(From AI): 这篇笔记全面介绍了 FreeRTOS 软件定时器的核心概念和使用方法,包括定时器的创建、管理、常用 API 和辅助函数,并通过示例代码演示了如何启动、重置和更改定时器的周期。它强调了软件定时器的灵活性、平台无关性以及与硬件定时器的对比 …...

文心一言与千帆大模型平台的区别:探索百度AI生态的双子星
随着人工智能技术的迅猛发展,越来越多的公司开始投入资源开发自己的AI解决方案。在中国,百度作为互联网巨头之一,不仅在搜索引擎领域占据重要位置,还在AI领域取得了显著成就。其中,“文心一言”和“千帆大模型平台”便…...

【c语言】文件操作详解 - 从打开到关闭
文章目录 1. 为什么使用文件?2. 什么是文件?3. 如何标识文件?4. 二进制文件和文本文件?5. 文件的打开和关闭5.1 流和标准流5.1.1 流5.1.2 标准流 5.2 文件指针5.3 文件的打开和关闭 6. 文件的读写顺序6.1 顺序读写函数6.2 对比一组…...

Flink Sink的使用
经过一系列Transformation转换操作后,最后一定要调用Sink操作,才会形成一个完整的DataFlow拓扑。只有调用了Sink操作,才会产生最终的计算结果,这些数据可以写入到的文件、输出到指定的网络端口、消息中间件、外部的文件系统或者是…...

pcl::PointCloud<PointType>::Ptr extractedCloud; 尖括号里的值表示什么含义?
在C中,pcl::PointCloud<PointType>::Ptr是一种智能指针,它是Point Cloud Library (PCL)中用于管理pcl::PointCloud对象的智能指针类型。这里的<pcl::PointCloud<PointType>::Ptr>尖括号里的值表示智能指针所指向的对象类型。 让我们分…...

《基于FPGA的便携式PWM方波信号发生器》论文分析(三)——数码管稳定显示与系统调试
一、论文概述 基于FPGA的便携式PWM方波信号发生器是一篇由任青颖、庹忠曜、黄洵桢、李智禺和张贤宇 等人发表的一篇期刊论文。该论文主要研究了一种新型的信号发生器,旨在解决传统PWM信号发生器在移动设备信号调控中存在的精准度低和便携性差的问题 。其基于现场可编…...

VsCode 插件推荐(个人常用)
VsCode 插件推荐(个人常用)...

路由策略与路由控制实验
AR1、AR2、AR3在互联接口、Loopback0接口上激活OSPF。AR3、AR4属于IS-IS Area 49.0001,这两者都是Level-1路由器,AR3、AR4的系统ID采用0000.0000.000x格式,其中x为设备编号 AR1上存在三个业务网段A、B、C(分别用Loopback1、2、3接…...

训练的decoder模型文本长度不一致,一般设置为多大合适,需要覆盖最长的文本长度么
在训练解码器模型时,文本长度不一致是常见的情况,需要根据任务的特性和数据集的长度分布来设置合理的最大长度 (max_length)。以下是一些指导原则,帮助你设置合适的最大长度: 1. 是否需要覆盖最长文本长度 覆盖最长文本长度: 如果任务对完整性要求很高(例如生成数学公式、…...
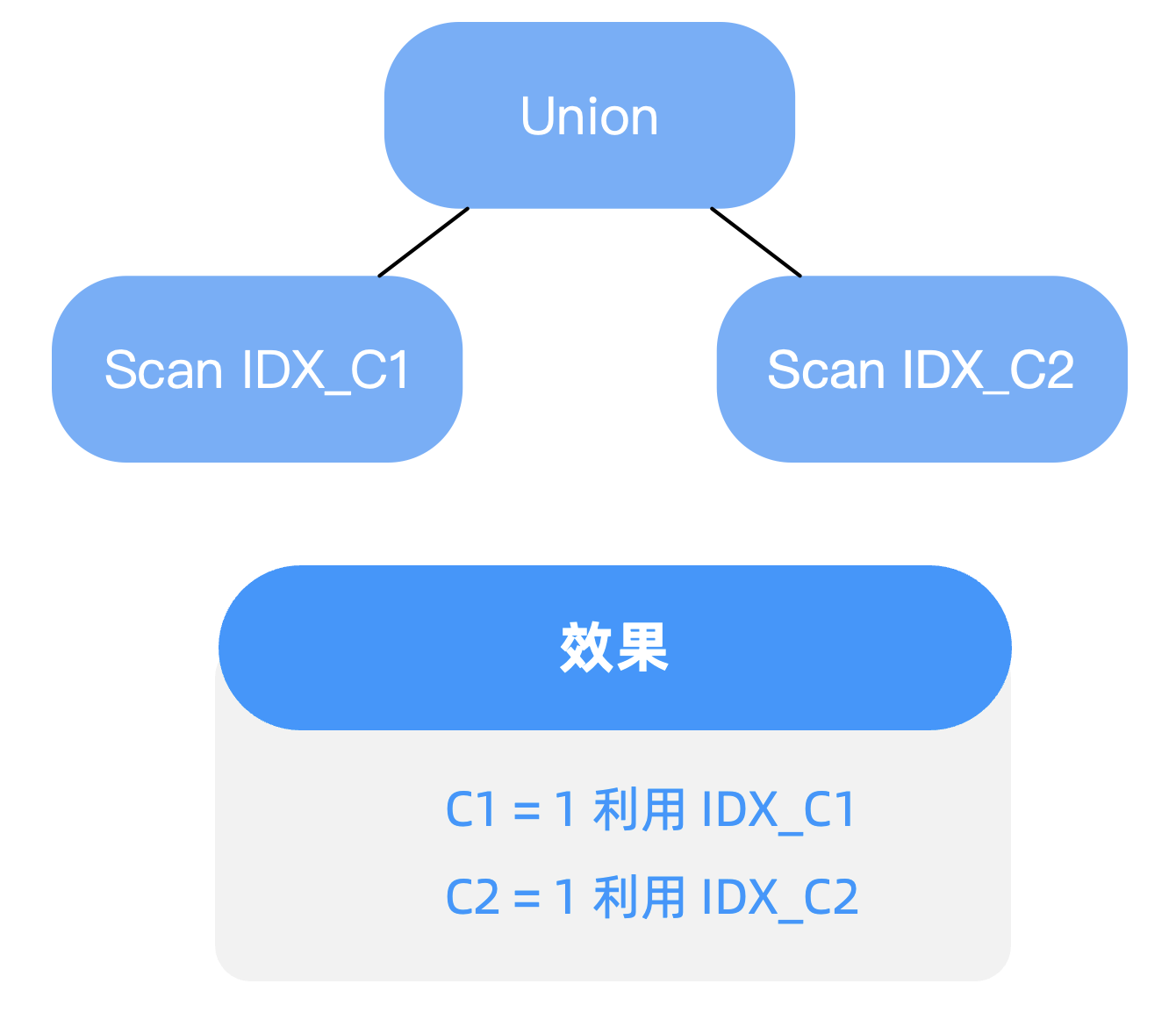
过滤条件包含 OR 谓词,如何进行查询优化——OceanBase SQL 优化实践
这篇博客涉及两个点,一个是 “OR Expansion 改写”,另一个是 “基于代价的改写”。 背景 在写SQL查询时,难以避免在过滤条件中使用 OR 谓词,但其往往会导致索引利用效率下降的问题 。本文将分享如何通过查询改写的2种方式进行优化…...

通过异步使用消息队列优化秒杀
通过异步使用消息队列优化秒杀 同步秒杀流程异步优化秒杀异步秒杀流程基于lua脚本保证Redis操作原子性代码实现阻塞队列的缺点 同步秒杀流程 public Result seckillVoucher(Long voucherId) throws InterruptedException {SeckillVoucher seckillVoucher iSeckillVoucherServi…...

AI产业告别“独奏”时代,“天翼云息壤杯”高校AI大赛奏响产学研“交响乐”
文 | 智能相对论 作者 | 陈泊丞 人工智能产业正在从“独奏”时代进入“大合奏”时代。 在早期的AI发展阶段,AI应用主要集中在少数几个领域,如语音识别、图像处理等。这些领域的研究和开发工作往往由少数几家公司或研究机构即可独立完成,犹…...

Hot100 - 字母异位词分组
Hot100 - 字母异位词分组 最佳思路:排序 时间复杂度: O(nmlogm),其中 n 为 strs 数组的长度,m 为每个字符串的长度。 代码: class Solution {public List<List<String>> groupAnagrams(String[] strs) …...

力扣hot100-->排序
排序 1. 56. 合并区间 中等 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 示例 1: 输…...

【VRChat 全身动捕】VIVE 手柄改 tracker 定位器教程,低成本光学动捕解决方案(持续更新中2024.11.26)
更新 0.0.1(2024/11/26): 1.解决了内建蓝牙无法识别、“steamVR 蓝牙不可用” 的解决方案 2.解决了 tracker 虽然建立了连接但是在 steamVR 界面上看不到的问题 3.解决了 VIVE 基站1.0 无法被蓝牙识别 && 无法被 steamVR 搜索到 &…...

【Nginx】核心概念与安装配置解释
文章目录 1. 概述2. 核心概念2.1.Http服务器2.2.反向代理2.3. 负载均衡 3. 安装与配置3.1.安装3.2.配置文件解释3.2.1.全局配置块3.2.2.HTTP 配置块3.2.3.Server 块3.2.4.Location 块3.2.5.upstream3.2.6. mine.type文件 3.3.多虚拟主机配置 4. 总结 1. 概述 Nginx是我们常用的…...

ESP32 vs STM32:实战对比移植SmartKnob,谁更适合你的下一个触觉交互项目?
ESP32 vs STM32:实战对比移植SmartKnob,谁更适合你的下一个触觉交互项目? 在触觉反馈技术快速发展的今天,智能旋钮(SmartKnob)作为人机交互的重要载体,正在从汽车中控、音频设备扩展到智能家居、…...

从开源贡献到知识付费:软件测试工程师的专业变现路径
在技术快速迭代的今天,软件测试工程师的职业技能边界早已超越传统的“找缺陷、保质量”。敏锐的缺陷洞察力、自动化脚本开发能力以及贯穿全流程的质量保障思维,构成了测试从业者坚实的专业壁垒。当这些专业技能不再仅仅服务于公司内部项目,而…...

生产环境已全面切换!Docker 27监控增强配置落地指南:从零部署27项增强指标采集链路,含Grafana 11.2仪表盘一键导入包
第一章:Docker 27监控增强配置全景概览Docker 27 引入了原生、轻量级的运行时监控增强机制,通过深度集成 cgroups v2、eBPF 和 Prometheus 兼容指标端点,显著提升容器资源可见性与故障定位效率。该版本默认启用 docker stats 的低开销采样模式…...

从生物神经元到人工神经网络:演化与深度学习革命
1. 从生物神经元到人工神经网络的演化之路"我们正在用硅基电路模拟碳基智慧的本质。"——Geoffrey Hinton1943年,当Warren McCulloch和Walter Pitts在《数学生物物理学通报》上发表那篇开创性论文时,他们可能没想到自己正在为一场持续至今的认…...

轻松解包网易游戏资源:unnpk工具完全指南
轻松解包网易游戏资源:unnpk工具完全指南 【免费下载链接】unnpk 解包网易游戏NeoX引擎NPK文件,如阴阳师、魔法禁书目录。 项目地址: https://gitcode.com/gh_mirrors/un/unnpk 你是否曾好奇阴阳师、魔法禁书目录等网易游戏中的精美角色、场景和音…...
)
告别Dev C++!用VScode+MinGW-W64打造你的C++开发环境(附一键配置脚本)
从Dev C到VScode:现代C开发环境高效配置指南 第一次打开VScode编写C代码时,那种流畅的代码补全体验让我瞬间理解了为什么这么多开发者选择迁移到这个现代化的编辑器。作为一个从Dev C时代走过来的程序员,我深刻体会过在老旧IDE中反复调试环境…...
上配置和优化802.11ax的RU分配策略)
网工实战笔记:如何在企业级AP(如Aruba或Cisco)上配置和优化802.11ax的RU分配策略
企业级AP实战:802.11ax RU分配策略的配置与优化指南 当企业Wi-Fi网络从传统802.11ac升级到802.11ax(Wi-Fi 6)时,最关键的突破莫过于OFDMA技术和资源单元(RU)的动态分配能力。想象一下这样的场景:…...

别再死记硬背公式了!用HEC-RAS 1D模拟洪水,你得先搞懂这几个核心概念
HEC-RAS洪水模拟实战:从理论公式到软件操作的思维跃迁 当第一次打开HEC-RAS软件界面时,许多水利工程师都会陷入一种认知困境——那些在教科书上清晰明了的能量方程和动量方程,怎么到了实际操作中就变成了难以理解的参数选项和计算警告&#x…...
)
Xtensa寄存器窗口机制实战解析:手把手教你理解ESP32 FreeRTOS的堆栈初始化(附避坑指南)
Xtensa寄存器窗口机制实战解析:手把手教你理解ESP32 FreeRTOS的堆栈初始化(附避坑指南) 在嵌入式系统开发领域,Xtensa架构以其独特的寄存器窗口机制闻名,却也成为许多开发者进阶路上的"拦路虎"。当你在ESP32…...

python pycryptodome
# 聊聊Python里的加密库:PyCryptodome 今天想和大家分享一个在Python加密领域里经常被用到的库,叫PyCryptodome。如果你在项目里处理过密码、加密文件或者设计过安全通信,很可能已经和它打过交道了。这个库表面上看起来只是一个工具集&#x…...