Flink Sink的使用
经过一系列Transformation转换操作后,最后一定要调用Sink操作,才会形成一个完整的DataFlow拓扑。只有调用了Sink操作,才会产生最终的计算结果,这些数据可以写入到的文件、输出到指定的网络端口、消息中间件、外部的文件系统或者是打印到控制台.
flink在批处理中常见的sink
- print 打印
- writerAsText 以文本格式输出
- writeAsCsv 以csv格式输出
- writeUsingOutputFormat 以指定的格式输出
- writeToSocket 输出到网络端口
- 自定义连接器(addSink)
参考官网:https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/dev/datastream/overview/#data-sinks
1、print
打印是最简单的一个Sink,通常是用来做实验和测试时使用。如果想让一个DataStream输出打印的结果,直接可以在该DataStream调用print方法。另外,该方法还有一个重载的方法,可以传入一个字符,指定一个Sink的标识名称,如果有多个打印的Sink,用来区分到底是哪一个Sink的输出。
以下演示了print打印,以及自定义print打印。
package com.bigdata.day03;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;public class SinkPrintDemo {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);DataStreamSource<String> dataStreamSource = env.socketTextStream("localhost", 8888);// 打印,普通的打印// 6> helllo world//dataStreamSource.print();dataStreamSource.addSink(new MySink());// 接着手动实现该print 打印env.execute();}static class MySink extends RichSinkFunction<String> {@Overridepublic void invoke(String value, Context context) throws Exception {// 得到一个分区号,因为要模仿print打印效果int partitionId = getRuntimeContext().getIndexOfThisSubtask() + 1;String msg = partitionId +"> " +value;System.out.println(msg);}}}
package com.bigdata.day03;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;public class Demo01 {static class MyPrint extends RichSinkFunction<String>{private String msg;public MyPrint(){}public MyPrint(String msg){this.msg = msg;}@Overridepublic void invoke(String value, Context context) throws Exception {int partition = getRuntimeContext().getIndexOfThisSubtask();if(msg == null){System.out.println(partition+"> "+value);}else{System.out.println(msg+">>>:"+partition+"> "+value);}}}public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStream<String> data = env.fromElements("hello", "world", "baotianman", "laoyan");//3. transformation-数据处理转换//4. sink-数据输出//data.print();//data.print("普通打印>>>");data.addSink(new MyPrint());data.addSink(new MyPrint("模仿:"));//5. execute-执行env.execute();}
}
下面的结果是WordCount例子中调用print Sink输出在控制台的结果,细心的读者会发现,在输出的单词和次数之前,有一个数字前缀,我这里是1~4,这个数字是该Sink所在subtask的Index + 1。有的读者运行的结果数字前缀是1~8,该数字前缀其实是与任务的并行度相关的,由于该任务是以local模式运行,默认的并行度是所在机器可用的逻辑核数即线程数,我的电脑是2核4线程的,所以subtask的Index范围是0~3,将Index + 1,显示的数字前缀就是1~4了。这里在来仔细的观察一下运行的结果发现:相同的单词输出结果的数字前缀一定相同,即经过keyBy之后,相同的单词会被shuffle到同一个subtask中,并且在同一个subtask的同一个组内进行聚合。一个subtask中是可能有零到多个组的,如果是有多个组,每一个组是相互独立的,累加的结果不会相互干扰。
sum之后的:
1> hello 3
2> world 4
汇总之前,keyBy之后
1> hello 1
1> hello 1
1> hello 1
2、writerAsText 以文本格式输出
该方法是将数据以文本格式实时的写入到指定的目录中,本质上使用的是TextOutputFormat格式写入的。每输出一个元素,在该内容后面同时追加一个换行符,最终以字符的形式写入到文件中,目录中的文件名称是该Sink所在subtask的Index + 1。该方法还有一个重载的方法,可以额外指定一个枚举类型的参数writeMode,默认是WriteMode.NO_OVERWRITE,如果指定相同输出目录下有相同的名称文件存在,就会出现异常。如果是WriteMode.OVERWRITE,会将以前的文件覆盖。
package com.bigdata.day03;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;public class SinkTextDemo {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);env.setParallelism(2);DataStreamSource<String> dataStreamSource = env.socketTextStream("localhost", 8880);// 写入到文件的时候,OVERWRITE 模式是重写的意思,假如以前有结果直接覆盖// 如果并行度为1 ,最后输出的结果是一个文件,假如并行度 > 1 最后的结果是一个文件夹,文件夹中的文件名是 分区号(任务号)dataStreamSource.writeAsText("F:\\BD230801\\FlinkDemo\\datas\\result", FileSystem.WriteMode.OVERWRITE);env.execute();}
}
package com.bigdata.day03;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Demo02 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据//3. transformation-数据处理转换//4. sink-数据输出//DataStreamSource<String> streamSource = env.socketTextStream("localhost", 8899);//streamSource.writeAsText("datas/socket", FileSystem.WriteMode.OVERWRITE).setParallelism(1);DataStreamSource<Tuple2<String, Integer>> streamSource = env.fromElements(Tuple2.of("篮球", 1),Tuple2.of("篮球", 2),Tuple2.of("篮球", 3),Tuple2.of("足球", 3),Tuple2.of("足球", 2),Tuple2.of("足球", 3));// writeAsCsv 只能保存 tuple类型的DataStream流,因为如果不是多列的话,没必要使用什么分隔符streamSource.writeAsCsv("datas/csv", FileSystem.WriteMode.OVERWRITE).setParallelism(1);//5. execute-执行env.execute();}
}3、连接器Connectors
JDBC Connector
该连接器可以向JDBC 数据库写入数据
JDBC | Apache Flink
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_2.11</artifactId><version>${flink.version}</version>
</dependency><!--假如你是连接低版本的,使用5.1.49--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.25</version></dependency>案例演示:
将结果读取,写入到MySQL
package com.bigdata.day03;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.sql.PreparedStatement;
import java.sql.SQLException;@Data
@AllArgsConstructor
@NoArgsConstructor
class Student{private int id;private String name;private int age;
}
public class JdbcSinkDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<Student> studentStream = env.fromElements(new Student(1, "jack", 54));JdbcConnectionOptions jdbcConnectionOptions = new JdbcConnectionOptions.JdbcConnectionOptionsBuilder().withUrl("jdbc:mysql://localhost:3306/test1").withDriverName("com.mysql.jdbc.Driver").withUsername("root").withPassword("123456").build();studentStream.addSink(JdbcSink.sink("insert into student values(null,?,?)",new JdbcStatementBuilder<Student>() {@Overridepublic void accept(PreparedStatement preparedStatement, Student student) throws SQLException {preparedStatement.setString(1,student.getName());preparedStatement.setInt(2,student.getAge());}// 假如是流的方式可以设置两条插入一次}, JdbcExecutionOptions.builder().withBatchSize(2).build(),jdbcConnectionOptions));env.execute();}
}
package com.bigdata.day03;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.sql.PreparedStatement;
import java.sql.SQLException;@Data
@AllArgsConstructor
@NoArgsConstructor
class Student{private int id;private String name;private int age;
}
public class Demo03 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);DataStreamSource<Student> studentDataStreamSource = env.fromElements(new Student(1, "张三", 19),new Student(2, "lisi", 20),new Student(3, "wangwu", 19));JdbcConnectionOptions jdbcConnectionOptions = new JdbcConnectionOptions.JdbcConnectionOptionsBuilder().withUrl("jdbc:mysql://localhost:3306/kettle").withDriverName("com.mysql.cj.jdbc.Driver").withUsername("root").withPassword("root").build();studentDataStreamSource.addSink(JdbcSink.sink("insert into student values(null,?,?)",new JdbcStatementBuilder<Student>() {@Overridepublic void accept(PreparedStatement preparedStatement, Student student) throws SQLException {preparedStatement.setString(1,student.getName());preparedStatement.setInt(2,student.getAge());}},jdbcConnectionOptions));//2. source-加载数据//3. transformation-数据处理转换//4. sink-数据输出//5. execute-执行env.execute();}
}运行结果正常:

KafkaConnector
Kafka | Apache Flink
从Kafka的topic1中消费日志数据,并做实时ETL,将状态为success的数据写入到Kafka的topic2中
kafka-topics.sh --bootstrap-server bigdata01:9092 --create --partitions 1 --replication-factor 3 --topic topic1
kafka-topics.sh --bootstrap-server bigdata01:9092 --create --partitions 1 --replication-factor 3 --topic topic2使用控制台当做kafka消息的生产者向kafka中的topic1 发送消息
kafka-console-producer.sh --bootstrap-server bigdata01:9092 --topic topic1消费kafka中topic2中的数据
kafka-console-consumer.sh --bootstrap-server bigdata01:9092 --topic topic2操作:
通过黑窗口向topic1中发送消息,含有success字样的消息,会出现在topic2中。

package com.bigdata.day03;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.kafka.clients.producer.KafkaProducer;import java.util.Properties;public class KafkaSinkDemo {// 从topic1中获取数据,放入到topic2中,训练了读和写public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据Properties properties = new Properties();properties.setProperty("bootstrap.servers", "bigdata01:9092");properties.setProperty("group.id", "g1");FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("topic1",new SimpleStringSchema(),properties);DataStreamSource<String> dataStreamSource = env.addSource(kafkaSource);//3. transformation-数据处理转换SingleOutputStreamOperator<String> filterStream = dataStreamSource.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String s) throws Exception {return s.contains("success");}});//4. sink-数据输出FlinkKafkaProducer kafkaProducer = new FlinkKafkaProducer<String>("topic2",new SimpleStringSchema(),properties);filterStream.addSink(kafkaProducer);//5. execute-执行env.execute();}
}Flink Kafka Consumer 需要知道如何将 Kafka 中的二进制数据转换为 Java 或者Scala 对象。KafkaDeserializationSchema 允许用户指定这样的 schema,每条 Kafka 中的消息会调用 T deserialize(ConsumerRecord<byte[], byte[]> record) 反序列化。
为了方便使用,Flink 提供了以下几种 schemas:
SimpleStringSchema:按照字符串方式序列化、反序列化
剩余还有 TypeInformationSerializationSchema、JsonDeserializationSchema、AvroDeserializationSchema等。
自定义Sink--模拟jdbcSink的实现
jdbcSink官方已经提供过了,此处仅仅是模拟它的实现,从而学习如何自定义sink
package com.bigdata.day03;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;public class CustomJdbcSinkDemo {@Data@AllArgsConstructor@NoArgsConstructorstatic class Student{private int id;private String name;private int age;}static class MyJdbcSink extends RichSinkFunction<Student> {Connection conn =null;PreparedStatement ps = null;@Overridepublic void open(Configuration parameters) throws Exception {// 这个里面编写连接数据库的代码Class.forName("com.mysql.jdbc.Driver");conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test1", "root", "123456");ps = conn.prepareStatement("INSERT INTO `student` (`id`, `name`, `age`) VALUES (null, ?, ?)");}@Overridepublic void close() throws Exception {// 关闭数据库的代码ps.close();conn.close();}@Overridepublic void invoke(Student student, Context context) throws Exception {// 将数据插入到数据库中ps.setString(1,student.getName());ps.setInt(2,student.getAge());ps.execute();}}public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<Student> studentStream = env.fromElements(new Student(1, "马斯克", 51));studentStream.addSink(new MyJdbcSink());env.execute();}
}相关文章:
Flink Sink的使用
经过一系列Transformation转换操作后,最后一定要调用Sink操作,才会形成一个完整的DataFlow拓扑。只有调用了Sink操作,才会产生最终的计算结果,这些数据可以写入到的文件、输出到指定的网络端口、消息中间件、外部的文件系统或者是…...

pcl::PointCloud<PointType>::Ptr extractedCloud; 尖括号里的值表示什么含义?
在C中,pcl::PointCloud<PointType>::Ptr是一种智能指针,它是Point Cloud Library (PCL)中用于管理pcl::PointCloud对象的智能指针类型。这里的<pcl::PointCloud<PointType>::Ptr>尖括号里的值表示智能指针所指向的对象类型。 让我们分…...

《基于FPGA的便携式PWM方波信号发生器》论文分析(三)——数码管稳定显示与系统调试
一、论文概述 基于FPGA的便携式PWM方波信号发生器是一篇由任青颖、庹忠曜、黄洵桢、李智禺和张贤宇 等人发表的一篇期刊论文。该论文主要研究了一种新型的信号发生器,旨在解决传统PWM信号发生器在移动设备信号调控中存在的精准度低和便携性差的问题 。其基于现场可编…...

VsCode 插件推荐(个人常用)
VsCode 插件推荐(个人常用)...

路由策略与路由控制实验
AR1、AR2、AR3在互联接口、Loopback0接口上激活OSPF。AR3、AR4属于IS-IS Area 49.0001,这两者都是Level-1路由器,AR3、AR4的系统ID采用0000.0000.000x格式,其中x为设备编号 AR1上存在三个业务网段A、B、C(分别用Loopback1、2、3接…...

训练的decoder模型文本长度不一致,一般设置为多大合适,需要覆盖最长的文本长度么
在训练解码器模型时,文本长度不一致是常见的情况,需要根据任务的特性和数据集的长度分布来设置合理的最大长度 (max_length)。以下是一些指导原则,帮助你设置合适的最大长度: 1. 是否需要覆盖最长文本长度 覆盖最长文本长度: 如果任务对完整性要求很高(例如生成数学公式、…...
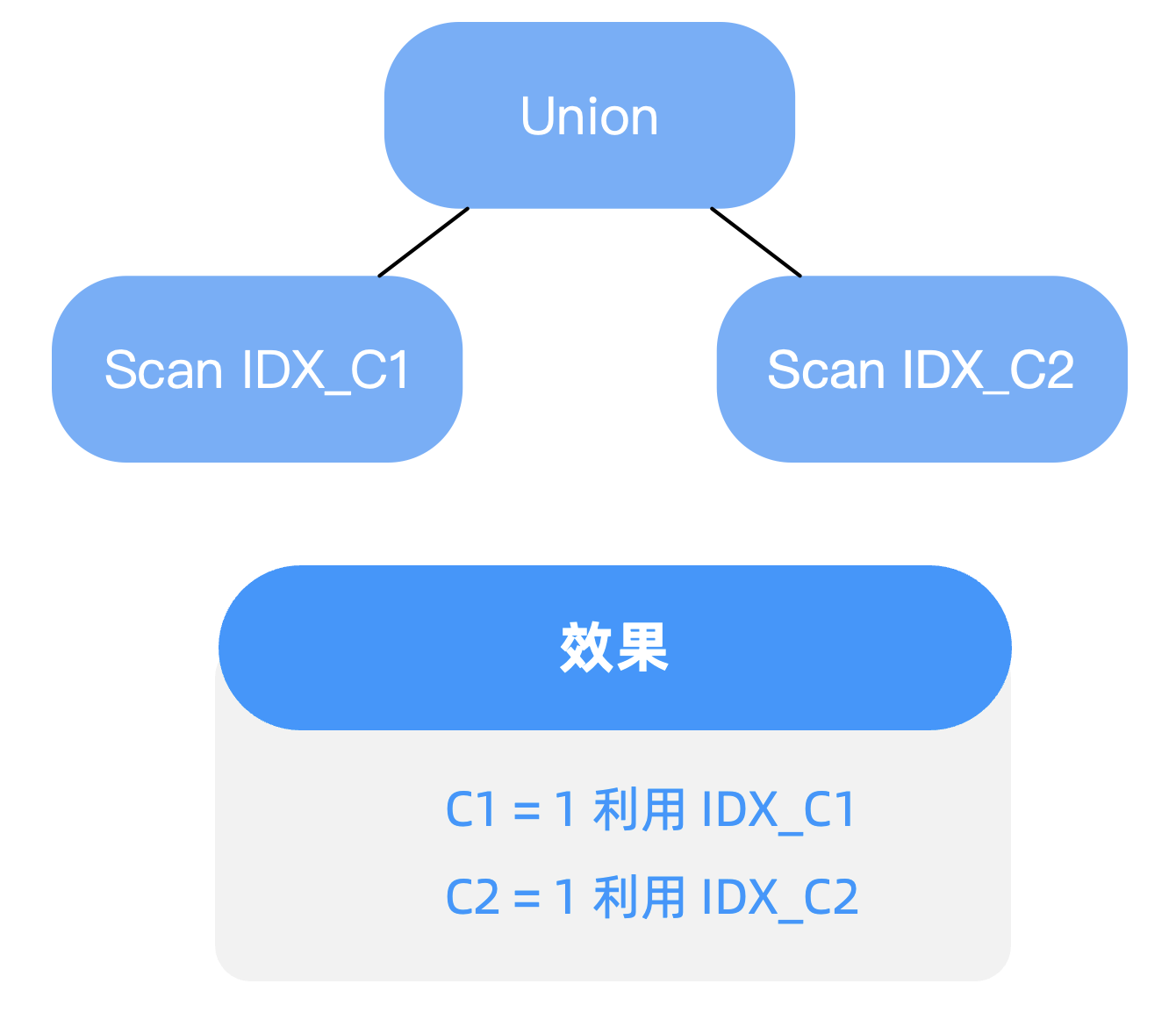
过滤条件包含 OR 谓词,如何进行查询优化——OceanBase SQL 优化实践
这篇博客涉及两个点,一个是 “OR Expansion 改写”,另一个是 “基于代价的改写”。 背景 在写SQL查询时,难以避免在过滤条件中使用 OR 谓词,但其往往会导致索引利用效率下降的问题 。本文将分享如何通过查询改写的2种方式进行优化…...

通过异步使用消息队列优化秒杀
通过异步使用消息队列优化秒杀 同步秒杀流程异步优化秒杀异步秒杀流程基于lua脚本保证Redis操作原子性代码实现阻塞队列的缺点 同步秒杀流程 public Result seckillVoucher(Long voucherId) throws InterruptedException {SeckillVoucher seckillVoucher iSeckillVoucherServi…...

AI产业告别“独奏”时代,“天翼云息壤杯”高校AI大赛奏响产学研“交响乐”
文 | 智能相对论 作者 | 陈泊丞 人工智能产业正在从“独奏”时代进入“大合奏”时代。 在早期的AI发展阶段,AI应用主要集中在少数几个领域,如语音识别、图像处理等。这些领域的研究和开发工作往往由少数几家公司或研究机构即可独立完成,犹…...

Hot100 - 字母异位词分组
Hot100 - 字母异位词分组 最佳思路:排序 时间复杂度: O(nmlogm),其中 n 为 strs 数组的长度,m 为每个字符串的长度。 代码: class Solution {public List<List<String>> groupAnagrams(String[] strs) …...

力扣hot100-->排序
排序 1. 56. 合并区间 中等 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 示例 1: 输…...

【VRChat 全身动捕】VIVE 手柄改 tracker 定位器教程,低成本光学动捕解决方案(持续更新中2024.11.26)
更新 0.0.1(2024/11/26): 1.解决了内建蓝牙无法识别、“steamVR 蓝牙不可用” 的解决方案 2.解决了 tracker 虽然建立了连接但是在 steamVR 界面上看不到的问题 3.解决了 VIVE 基站1.0 无法被蓝牙识别 && 无法被 steamVR 搜索到 &…...

【Nginx】核心概念与安装配置解释
文章目录 1. 概述2. 核心概念2.1.Http服务器2.2.反向代理2.3. 负载均衡 3. 安装与配置3.1.安装3.2.配置文件解释3.2.1.全局配置块3.2.2.HTTP 配置块3.2.3.Server 块3.2.4.Location 块3.2.5.upstream3.2.6. mine.type文件 3.3.多虚拟主机配置 4. 总结 1. 概述 Nginx是我们常用的…...

Qt界面篇:QMessageBox高级用法
1、演示效果 2、用法注意 2.1 设置图标 用于显示实际图标的pixmap取决于当前的GUI样式。也可以通过设置icon pixmap属性为图标设置自定义pixmap。 QMessageBox::Icon icon(...

【二叉树】【2.1遍历二叉树】【刷题笔记】【灵神题单】
关注二叉树的三个问题: 什么情况适合自顶向下?什么时候适合用自底向上?一般来说,DFS的递归边界是空节点,什么情况下要额外把叶子节点作为递归边界?在什么情况下,DFS需要有返回值?什…...

Mongo数据库 --- Mongo Pipeline
Mongo数据库 --- Mongo Pipeline 什么是Mongo PipelineMongo Pipeline常用的几个StageExplanation with example:MongoDB $matchMongoDB $projectMongoDB $groupMongoDB $unwindMongoDB $countMongoDB $addFields Some Query Examples在C#中使用Aggreagtion Pipeline**方法一: …...

Adobe Illustrator 2024 安装教程与下载分享
介绍一下 下载直接看文章末尾 Adobe Illustrator 是一款由Adobe Systems开发的矢量图形编辑软件。它广泛应用于创建和编辑矢量图形、插图、徽标、图标、排版和广告等领域。以下是Adobe Illustrator的一些主要特点和功能: 矢量绘图:Illustrator使用矢量…...

javax.xml.ws.soap.SOAPFaultException: ZONE_OFFSET
javax.xml.ws.soap.SOAPFaultException 表示 SOAP 调用过程中发生了错误,并且服务端返回了一个 SOAP Fault。 错误信息中提到的 ZONE_OFFSET 可能指的是时区偏移量。在日期和时间处理中,时区偏移量是指格林威治标准时间 (GMT) 的偏移量。如果服务期望特…...

常用的数据结构
队列(FIFO) 栈(LIFO) 链表 hash表 hash冲突处理 开放式寻址 线性探测 表示依次检查索引为 hash(key) + 1、hash(key) + 2 ... 的位置。i 是冲突后的探查步数。公式:hash(i) = (hash(key) + i) % TableSize二次探查 规则:冲突后探查的步长是平方递增的,例如,检查位置为 hash…...

javaweb-day01-html和css初识
html:超文本标记语言 CSS:层叠样式表 1.html实现新浪新闻页面 1.1 标题排版 效果图: 1.2 标题颜色样式 1.3 标签内颜色样式 1.4设置超链接 1.5 正文排版 1.6 页面布局–盒子 (1)盒子模型 (2)页面布局…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...