json文件在faster_rcnn中从测试到训练 可行性
1.确认任务
经过mydataset文件处理后 - > 在train_res50_fpn文件内应用
# load train data set
# VOCdevkit -> VOC2012 -> ImageSets -> Main -> train.txt
train_dataset = VOCDataSet(VOC_root, "2012", data_transform["train"], "train.txt")
train_sampler = None
在经过mydataset处理后,框出各项位置。
2.原mydataset内容
主要要做的就是在每个xml文件内提取出 类别+类别所在区域(xmin xmax ymin ymax)
2.1 split_data.py分类出训练集 and 验证集
得到结果:

2.2 构造函数 def_init
索引每一个xml文件
xml_list = 每一个训练集中的xml文件集合
assert year in ["2007", "2012"], "year must be in ['2007', '2012']"# 增加容错能力if "VOCdevkit" in voc_root:self.root = os.path.join(voc_root, f"VOC{year}")else:self.root = os.path.join(voc_root, "VOCdevkit", f"VOC{year}")self.img_root = os.path.join(self.root, "JPEGImages")self.annotations_root = os.path.join(self.root, "Annotations")# read train.txt or val.txt filetxt_path = os.path.join(self.root, "ImageSets", "Main", txt_name)assert os.path.exists(txt_path), "not found {} file.".format(txt_name)with open(txt_path) as read:xml_list = [os.path.join(self.annotations_root, line.strip() + ".xml")for line in read.readlines() if len(line.strip()) > 0]self.xml_list = []按行索引classes文件
class_dict 匹配类别对应的序号
# read class_indictjson_file = './pascal_voc_classes.json'assert os.path.exists(json_file), "{} file not exist.".format(json_file)with open(json_file, 'r') as f:self.class_dict = json.load(f)parse_xml_to_dict方法 把每一个xml文件检测到的类别提取出来<object>
xml = etree.fromstring(xml_str)data = self.parse_xml_to_dict(xml)["annotation"]提取每个类别的各项信息
位置信息放入boxes中
boxes = []labels = []iscrowd = []assert "object" in data, "{} lack of object information.".format(xml_path)for obj in data["object"]:xmin = float(obj["bndbox"]["xmin"])xmax = float(obj["bndbox"]["xmax"])ymin = float(obj["bndbox"]["ymin"])ymax = float(obj["bndbox"]["ymax"])# 进一步检查数据,有的标注信息中可能有w或h为0的情况,这样的数据会导致计算回归loss为nanif xmax <= xmin or ymax <= ymin:print("Warning: in '{}' xml, there are some bbox w/h <=0".format(xml_path))continueboxes.append([xmin, ymin, xmax, ymax])labels.append(self.class_dict[obj["name"]])if "difficult" in obj:iscrowd.append(int(obj["difficult"]))else:iscrowd.append(0)转为tensor
# convert everything into a torch.Tensorboxes = torch.as_tensor(boxes, dtype=torch.float32)labels = torch.as_tensor(labels, dtype=torch.int64)iscrowd = torch.as_tensor(iscrowd, dtype=torch.int64)image_id = torch.tensor([idx])area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])target = {}target["boxes"] = boxestarget["labels"] = labelstarget["image_id"] = image_idtarget["area"] = areatarget["iscrowd"] = iscrowdif self.transforms is not None:image, target = self.transforms(image, target)return image, target提取图像的高宽
def get_height_and_width(self, idx):# read xmlxml_path = self.xml_list[idx]with open(xml_path) as fid:xml_str = fid.read()xml = etree.fromstring(xml_str)data = self.parse_xml_to_dict(xml)["annotation"]data_height = int(data["size"]["height"])data_width = int(data["size"]["width"])return data_height, data_width被调用过的函数 --- 将xml解析为字典模式
def parse_xml_to_dict(self, xml):"""将xml文件解析成字典形式,参考tensorflow的recursive_parse_xml_to_dictArgs:xml: xml tree obtained by parsing XML file contents using lxml.etreeReturns:Python dictionary holding XML contents."""if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息return {xml.tag: xml.text}result = {}for child in xml:child_result = self.parse_xml_to_dict(child) # 递归遍历标签信息if child.tag != 'object':result[child.tag] = child_result[child.tag]else:if child.tag not in result: # 因为object可能有多个,所以需要放入列表里result[child.tag] = []result[child.tag].append(child_result[child.tag])return {xml.tag: result}3.关于json文件
如何在Python中优雅地处理JSON文件 - 知乎
JSON结构看起来和Python中的字典非常类似。需要注意的是,JSON格式通常是由key:<value> 结对组成,其中key是字符串形式,value是字符串、数字、布尔值、数组、对象或null。
为了更直观的进行说明,在下图中我们以蓝色突出显示了所有的key,同时以橙色突出显示了所有的value。
请注意,以下每组key/value间均使用逗号进行区分。

首先我们需要导入 json库, 接着我们使用open函数来读取JSON文件,最后利用json.load()函数将JSON字符串转化为Python字典形式.
4.提取出相应json文件的每个类别以及对应区域
注:中文的时候encoding=‘gbk’
import json
import torch
with open('test.json',encoding="gbk") as f:json_dict = json.load(f)#print(type(json_dict))
data = json_dict['shapes']
for data_ in data:#print(data_)#print(data[0]['label'])#print(data[0]['points'])label=data_['label']xmin=float(data_['points'][0][0])xmax=float(data_['points'][1][0])ymin=float(data_['points'][0][1])ymax=float(data_['points'][1][1])print(label , xmin , xmax , ymin , ymax)
4.不支持png格式预测

使用了几乎一样的

jpg文件基本都没问题
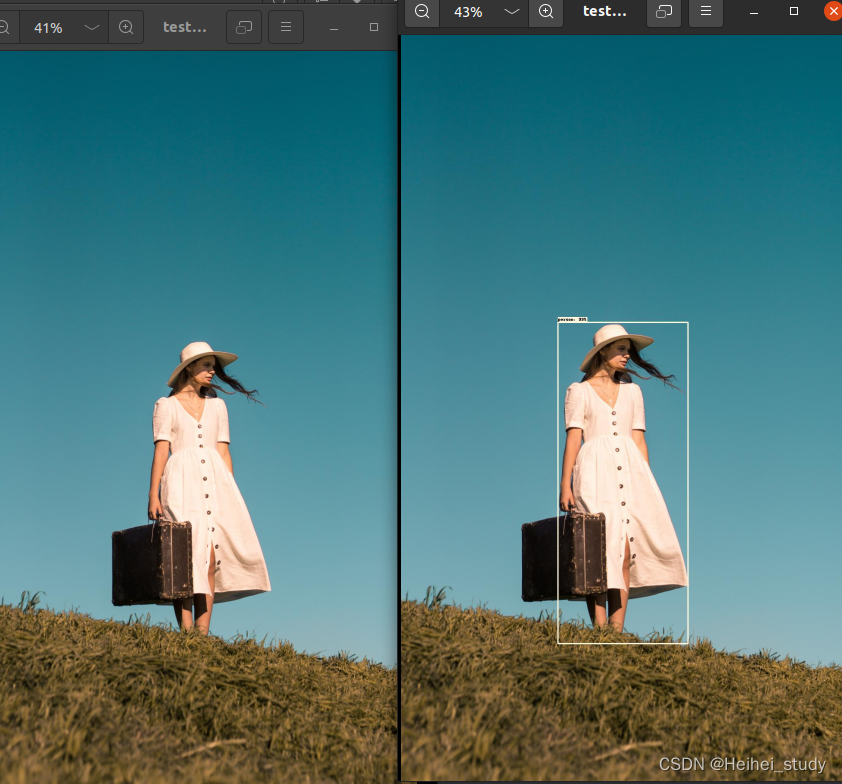
png文件没有成功的。
相关文章:
json文件在faster_rcnn中从测试到训练 可行性
1.确认任务 经过mydataset文件处理后 - > 在train_res50_fpn文件内应用 # load train data set # VOCdevkit -> VOC2012 -> ImageSets -> Main -> train.txt train_dataset VOCDataSet(VOC_root, "2012", data_transform["train"], &…...

golang 1.20正式发布,更好更易更强
预期中的Go 2不会有了,1.20也算是一个小gap,从中可以一窥Go未来的发展之路。对于Go来说,未来保持1.x持续演进和兼容性之外,重点就是让Go性能更优,同时保持大道至简原则,使用尽可能容易,从这两个…...

图片显示一半怎么回事?
不知道小伙伴是否遇到过,刚刚上传的一个文件夹,有一多半的图片突然就变成了无法显示该图片或者是图片显示一半,而另外一半就显示灰色蓝色粉色条状。而且还把原文件删除了。面对这种情况,有什么解决方法呢?下面让我们一起来来看看…...
102-并发编程详解(中篇)
这里续写上一章博客 Phaser新特性 : 特性1:动态调整线程个数 CyclicBarrier 所要同步的线程个数是在构造方法中指定的,之后不能更改,而 Phaser 可以在运行期间动态地 调整要同步的线程个数,Phaser 提供了下面这些方…...
jsp羽毛球场馆管理系统Myeclipse开发mysql数据库web结构java编程计算机网页项目
一、源码特点 jsp 羽毛球场馆管理系统 是一套完善的web设计系统,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为 TOMCAT7.0,Myeclipse8.5开发,数据库为Mysql,…...
CacheLib 原理说明
CacheLib 介绍 CacheLib 是 facebook 开源的一个用于访问和管理缓存数据的 C 库。它是一个线程安全的 API,使开发人员能够构建和自定义可扩展的并发缓存。 主要功能: 实现了针对 DRAM 和 NVM 的混合缓存,可以将从 DRAM 驱逐的缓存数据持久…...
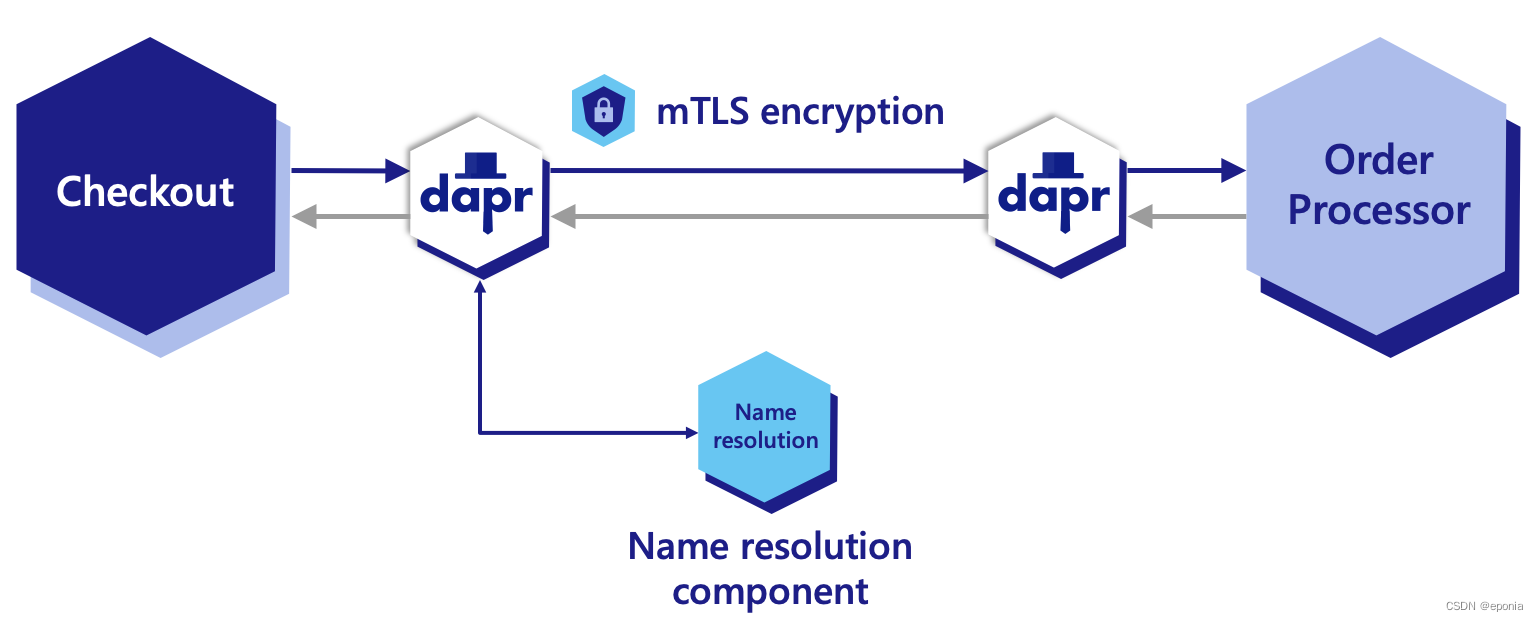
【dapr】服务调用(Service Invokation) - app id的解析
逻辑图解 上图来自Dapr官网教程,其中Checkout是一个服务,负责生成订单号, Order Processor是另一个服务,负责处理订单。Checkout服务需要调用Order Processor的API, 让Order Processor获取到其生成的订单号并进行处理。…...
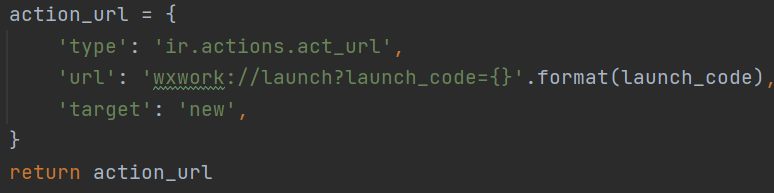
Odoo丨5步轻松实现在Odoo中打开企微会话框
Odoo丨5步轻松实现在Odoo中打开企微会话框 在Odoo中开启企微会话框 企业微信作为一个很好的企业级应用发布平台,尤其是提供的数据和接口,极大地为很多企业级应用提供便利,在日常中应用广泛! 最近在项目中就遇到一个与企业微信相…...
python读取.stl文件
目录 .1 文本方式读取 1.2 stl解析 1.3 stl创建 .2 把点转换为.stl .1 文本方式读取 代码如下 stl_path/home/pxing/codes/point_improve/data/003_cracker_box/0.stlpoints[] f open(stl_path) lines f.readlines() prefixvertex num3 for line in lines:#print (l…...
vue2.0项目第一部分
论坛项目后端管理系统服务器地址:http://172.16.11.18:9090swagger地址:http://172.16.11.18:9090/doc.html前端h5地址:http://172.16.11.18:9099/h5/#/前端管理系统地址:http://172.16.11.18:9099/admin/#/搭建项目vue create . …...
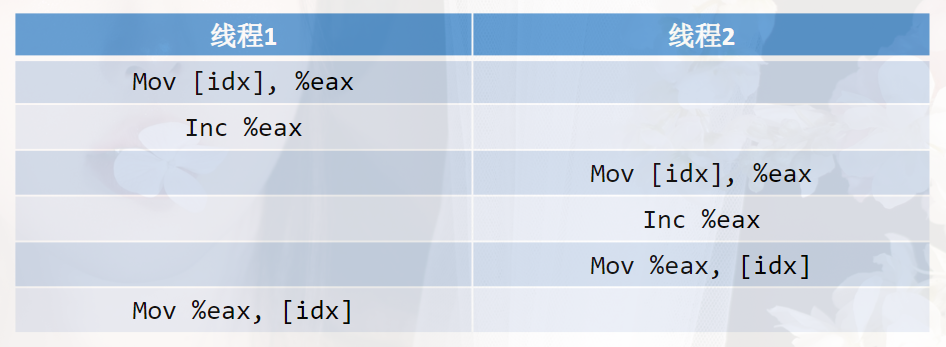
锁与原子操作
锁与原子操作 锁 以自增操作为例子: void *func(void *arg) {int *pcount (int *)arg;int i 0;//while (i < 100000) {(*pcount) ; // 并不会到达100000usleep(1);} }int main(){int i 0;for (i 0;i < THREAD_COUNT;i ) {pthread_create(&thid…...

Prometheus Pushgetway讲解与实战操作
目录 一、概述 1、Pushgateway优点: 2、Pushgateway缺点: 二、Pushgateway 架构 三、实战操作演示...
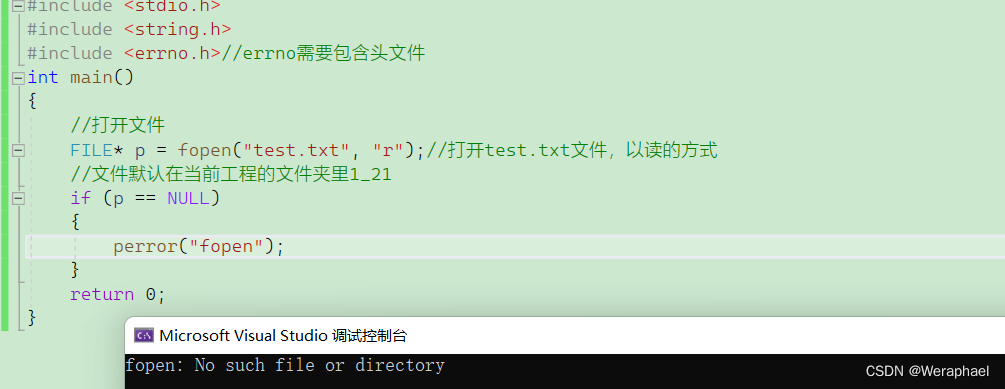
常见字符串函数的使用,你确定不进来看看吗?
👦个人主页:Weraphael ✍🏻作者简介:目前是C语言学习者 ✈️专栏:C语言航路 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬 点赞&a…...
Elasticsearch:在搜索中使用衰减函数(Gauss)
在我之前的文章 “Elasticsearch:使用 function_score 及 script_score 定制搜索结果的分数” 我有讲到 Decay 函数在搜索中的使用。在那里,我有一个例子讲述在规定的时间里,分数不进行衰减。同一的函数也可以适用于地理位置的搜索。位置搜索…...
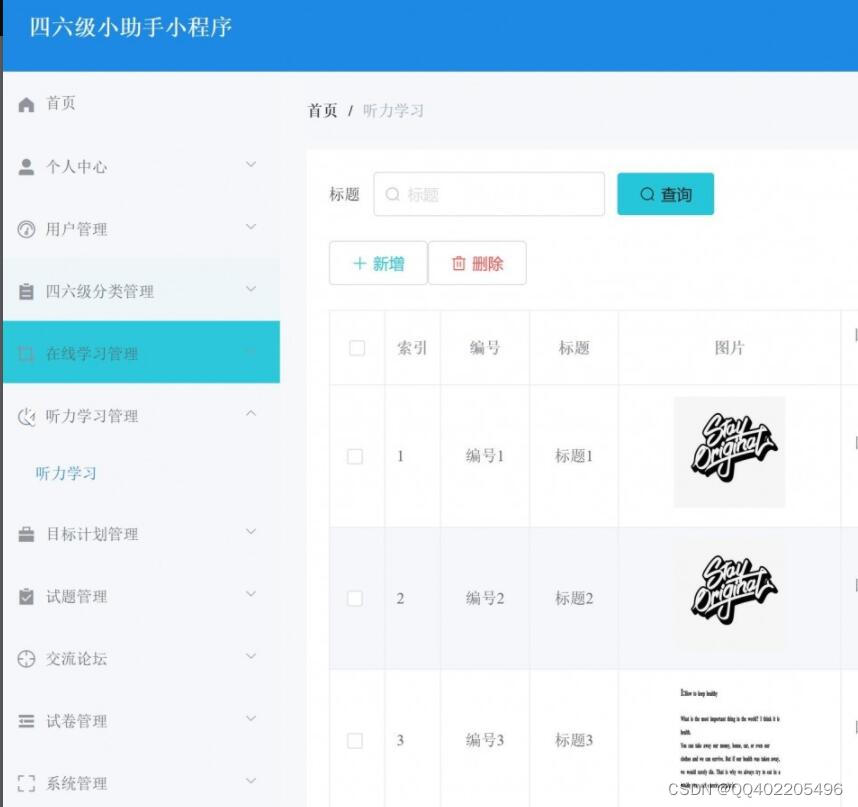
微信小程序 Springboot英语在线学习助手系统 uniapp
四六级助手系统用户端是基于微信小程序端,管理员端是基于web端,本系统是基于java编程语言,mysql数据库,idea开发工具, 系统分为用户和管理员两个角色,其中用户可以注册登陆小程序,查看英语四六级…...

LeetCode算法题解——双指针2
LeetCode算法题解——双指针2第五题思路代码第六题思路代码第七题思路代码这里介绍双指针在数组中的第二类题型:两端夹击。 第五题 977. 有序数组的平方 题目描述: 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的…...

线性杂双功能peg化试剂——HS-PEG-COOH,Thiol-PEG-Acid
英文名称:HS-PEG-COOH,Thiol-PEG-Acid 中文名称:巯基-聚乙二醇-羧基 HS-PEG-COOH是一种含有硫醇和羧酸的线性杂双功能聚乙二醇化试剂。它是一种有用的带有PEG间隔基的交联或生物结合试剂。巯基或SH、巯基或巯基选择性地与马来酰亚胺、OPSS、…...
Linux第三讲
目录 三、 磁盘和文件管理和使用检测和维护 3.1 磁盘目录 3.2 安装软件 3.2.1 rpm命令 3.2.2 克隆虚拟机 3.2.3 yum或压缩包方式安装jdk 3.2.4 使用虚拟机运行SpringBoot项目 3.2.5 安装mysql80(57) 3.2.6 运行web项目 3.2.7 安装tomcat 三、 …...
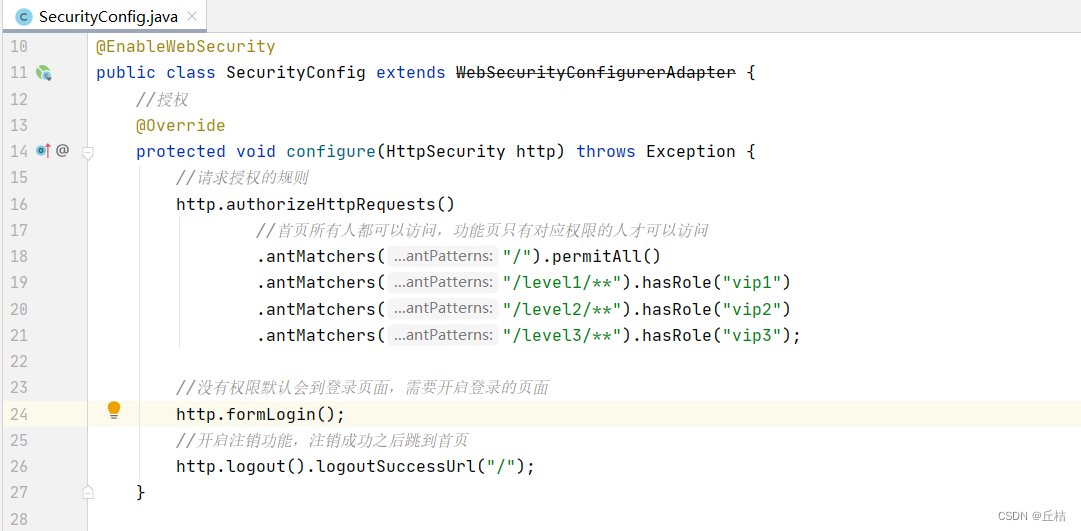
SpringBoot07:SpringSecurity
Security是什么? 是一个安全框架。可以用来做认证和授权 官网:Spring Security SpringSecurity环境搭建 1、创建一个新的project 2、导入thymeleaf依赖 <dependency><groupId>org.thymeleaf</groupId><artifactId>thymeleaf…...

C++ 浅谈之 STL Vector
C 浅谈之 STL Vector HELLO,各位博友好,我是阿呆 🙈🙈🙈 这里是 C 浅谈系列,收录在专栏 C 语言中 😜😜😜 本系列阿呆将记录一些 C 语言重要的语法特性 🏃&…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...