学习日记_20241126_聚类方法(自组织映射Self-Organizing Maps, SOM)
前言
提醒:
文章内容为方便作者自己后日复习与查阅而进行的书写与发布,其中引用内容都会使用链接表明出处(如有侵权问题,请及时联系)。
其中内容多为一次书写,缺少检查与订正,如有问题或其他拓展及意见建议,欢迎评论区讨论交流。
文章目录
- 前言
- 聚类算法
- 经典应用场景
- 自组织映射(Self-Organizing Maps, SOM)
- 优点:
- 缺点:
- 简单实例(函数库实现)
- 数学表达
- 。。。。。。。
聚类算法
聚类算法在各种领域中有广泛的应用,主要用于发现数据中的自然分组和模式。以下是一些常见的应用场景以及每种算法的优缺点:
经典应用场景
-
市场细分:根据消费者的行为和特征,将他们分成不同的群体,以便进行有针对性的营销。
-
图像分割: 将图像划分为多个区域或对象,以便进行进一步的分析或处理。
-
社交网络分析:识别社交网络中的社区结构。
-
文档分类:自动将文档分组到不同的主题或类别中。
-
异常检测识别数据中的异常点或异常行为。
-
基因表达分析:在生物信息学中,根据基因表达模式对基因进行聚类。
自组织映射(Self-Organizing Maps, SOM)
Self-Organizing Maps (SOM),也称为自组织映射或Kohonen网络,是一种无监督的机器学习方法,主要用于降维和聚类。以下是SOM聚类方法的优缺点:
优点:
- 降维:SOM能够将高维数据映射到低维空间(通常是二维),同时保持数据的拓扑结构,这使得数据可视化变得更加容易。
- 拓扑保持:SOM在映射过程中努力保持原始数据中相似性关系的拓扑结构,即相似的输入向量在映射后仍然接近。
- 无监督学习:SOM不需要预先标记的数据,可以自动发现数据中的结构和模式。
- 可解释性:SOM的输出是一个网格,每个网格节点代表一个聚类中心,这种结构使得聚类结果具有一定的可解释性。
- 灵活性:SOM可以适应不同形状和密度的聚类。
- 噪声鲁棒性:SOM对噪声数据有一定的鲁棒性,能够在一定程度上忽略小的数据扰动。
缺点:
- 参数敏感:SOM的性能对初始参数(如网格大小、学习率、邻域函数等)非常敏感,需要仔细选择和调整。
- 计算复杂度:SOM的训练过程可能比较耗时,特别是对于大型数据集和复杂的网格结构。
- 缺乏全局优化:SOM的训练过程是局部的,可能导致无法达到全局最优解。
- 边界效应:SOM的边界节点可能没有足够的邻居,这可能导致边界区域的映射不够准确。
- 难以确定最佳网格大小:选择合适的网格大小是一个挑战,过小可能无法捕捉数据的复杂性,过大则可能导致过度拟合。
- 对初始化敏感:SOM的最终结果可能受到初始权重随机化的影响,不同的初始化可能导致不同的聚类结果。
- 不适合非凸聚类:SOM在处理非凸形状的聚类时可能表现不佳,因为其本质上是基于距离的聚类方法。
总的来说,SOM是一种强大的工具,适用于多种数据分析和聚类任务,但也需要仔细考虑其参数设置和适用场景。在实际应用中,可能需要结合其他方法或技术来克服其局限性。
简单实例(函数库实现)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from minisom import MiniSom# 生成示例数据
n_samples = 500
n_centers = 3
X, _ = make_blobs(n_samples=n_samples, centers=n_centers, cluster_std=0.7, random_state=42)# 自组织映射的参数
som_size = 7 # SOM的网格大小
som = MiniSom(som_size, som_size, X.shape[1], sigma=1.0, learning_rate=0.9)# 初始化并训练SOM
som.random_weights_init(X)
som.train_random(X, num_iteration=100)# 获取SOM的输出
win_map = som.win_map(X)
labels = np.zeros(X.shape[0])# 将每个数据点分配给最近的SOM节点
for i in range(som_size):for j in range(som_size):if (i, j) in win_map:for x in win_map[(i, j)]:# 使用SOM的网格位置来标记index = np.argmin(np.linalg.norm(X - x, axis=1))labels[index] = (i * som_size + j)
# 可视化结果
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', marker='o', edgecolor='k', s=50)
plt.title('Self-Organizing Map Clustering Result')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.grid(True)
plt.show()
代码运行结果:
学习效果不是很好,是很不好,原因以后再说吧
数学表达
自组织映射(Self-Organizing Maps, SOM)是一种基于神经网络的无监督学习算法,旨在通过无监督的方式对高维数据进行降维和聚类。其核心思想是通过竞争学习使得相似的数据点在低维空间中尽可能靠近。下面我们将结合数学公式详细讲解SOM的工作原理。
- 网络结构
SOM通常由一个二维的神经元网格组成,每个神经元都有一个权重向量 w j ∈ R n \mathbf{w}_j \in \mathbb{R}^n wj∈Rn,与输入数据的维度相同。设网络中有 m × n m \times n m×n 个神经元,权重向量表示为:
W = { w 1 , w 2 , … , w m × n } \mathbf{W} = \{ \mathbf{w}_1, \mathbf{w}_2, \ldots, \mathbf{w}_{m \times n} \} W={w1,w2,…,wm×n}- 输入信号
给定一个输入样本 x ∈ R n \mathbf{x} \in \mathbb{R}^n x∈Rn,SOM的目标是找到一个最接近的神经元,即最佳匹配单元(Best Matching Unit, BMU),其位置为 b \mathbf{b} b:
b = arg min j ∥ x − w j ∥ 2 \mathbf{b} = \arg\min_{j} \|\mathbf{x} - \mathbf{w}_j\|^2 b=argjmin∥x−wj∥2
这里, ∥ ⋅ ∥ \|\cdot\| ∥⋅∥ 表示欧几里得距离。- 更新权重
一旦确定了BMU,下一步是更新BMU及其邻域神经元的权重,以使它们更接近输入向量 x \mathbf{x} x。权重更新规则如下:
w j ( t + 1 ) = w j ( t ) + α ( t ) ⋅ h b , j ( t ) ⋅ ( x − w j ( t ) ) \mathbf{w}_j(t + 1) = \mathbf{w}_j(t) + \alpha(t) \cdot h_{b,j}(t) \cdot (\mathbf{x} - \mathbf{w}_j(t)) wj(t+1)=wj(t)+α(t)⋅hb,j(t)⋅(x−wj(t))
其中:
- t t t 表示当前的训练迭代次数。
- α ( t ) \alpha(t) α(t) 是学习率,随着时间的推移通常会逐步降低。
- h b , j ( t ) h_{b,j}(t) hb,j(t) 是邻域函数,表示与BMU相邻的神经元的影响程度,一般定义为:
h b , j ( t ) = { exp ( − d b , j 2 2 σ ( t ) 2 ) if j is a neighbor of b 0 otherwise h_{b,j}(t) = \begin{cases} \exp\left(-\frac{d_{b,j}^2}{2\sigma(t)^2}\right) & \text{if } j \text{ is a neighbor of } b \\ 0 & \text{otherwise} \end{cases} hb,j(t)={exp(−2σ(t)2db,j2)0if j is a neighbor of botherwise
这里 d b , j d_{b,j} db,j 是BMU和神经元 j j j 之间的距离, σ ( t ) \sigma(t) σ(t) 是邻域范围,通常也随着时间衰减。- 学习率和邻域函数
- 学习率 α ( t ) \alpha(t) α(t):通常定义为:
α ( t ) = α 0 ⋅ ( 1 − t T ) \alpha(t) = \alpha_0 \cdot \left(1 - \frac{t}{T}\right) α(t)=α0⋅(1−Tt)
其中 α 0 \alpha_0 α0 是初始学习率, T T T 是总训练迭代次数。- 邻域范围 σ ( t ) \sigma(t) σ(t):通常定义为:
σ ( t ) = σ 0 ⋅ ( 1 − t T ) \sigma(t) = \sigma_0 \cdot \left(1 - \frac{t}{T}\right) σ(t)=σ0⋅(1−Tt)
其中 σ 0 \sigma_0 σ0 是初始邻域范围。- 算法步骤
SOM算法的主要步骤如下:
- 初始化权重向量 W \mathbf{W} W。
- 对于每个输入样本 x \mathbf{x} x:
- 找到BMU b \mathbf{b} b。
- 更新BMU及其邻域的权重。
- 重复步骤2,直到达到设定的训练次数或收敛条件。
- 结果与聚类
训练完成后,SOM将高维数据映射到低维网格上,具有相似特征的数据点会被映射到相邻的神经元。通过分析每个神经元的权重向量,可以识别出数据的聚类结构。
总结
自组织映射(SOM)是一种强大且直观的聚类和可视化方法。通过竞争学习和权重更新机制,SOM能够有效地将高维数据映射到低维空间,同时保持数据的拓扑结构。其数学基础包括欧几里得距离计算、权重更新规则以及邻域函数的设计,是理解SOM算法的关键。
。。。。。。。
学习日记_20241110_聚类方法(K-Means)
学习日记_20241115_聚类方法(层次聚类)
学习日记_20241115_聚类方法(DBSCAN)
学习日记_20241117_聚类方法(高斯混合模型)
学习日记_20241123_聚类方法(高斯混合模型)续
学习日记_20241123_聚类方法(MeanShift)
学习日记_20241126_聚类方法(谱聚类Spectral Clustering)
学习日记_20241126_聚类方法(聚合聚类Agglomerative Clustering)
学习日记_20241126_聚类方法(Affinity Propagation)
九个聚类算法终于搞完了,终于。
我要刷视频放松去了。
相关文章:

学习日记_20241126_聚类方法(自组织映射Self-Organizing Maps, SOM)
前言 提醒: 文章内容为方便作者自己后日复习与查阅而进行的书写与发布,其中引用内容都会使用链接表明出处(如有侵权问题,请及时联系)。 其中内容多为一次书写,缺少检查与订正,如有问题或其他拓展…...

【接口自动化测试】一文从0到1详解接口测试协议!
接口自动化测试是软件开发过程中重要的环节之一。通过对接口进行测试,可以验证接口的功能和性能,确保系统正常运行。本文将从零开始详细介绍接口测试的协议和规范。 定义接口测试协议 接口测试协议是指用于描述接口测试的规范和约定。它包含了接口的请求…...

安全设备-日志审计-系统安装部署配置
3.1 系统安装部署概述 通过系统初始化安装部署,可实现对系统的基础管理工作。系统安装基本部署涉及功能有时间配置、 资产组、资产、用户组、用户、时间配置等) 3.2 系统安装部署配置举例 3.2.1 用户场景 本阶段进行系统安装,进行相关设…...
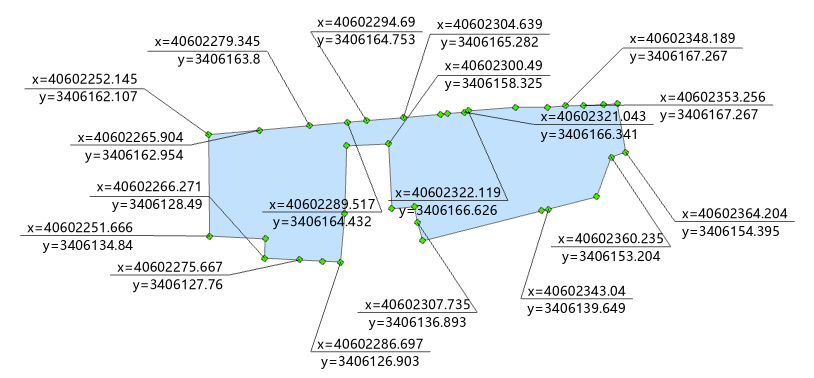
【ArcGIS Pro】实现一下完美的坐标点标注
在CAD里利用湘源可以很快点出一个完美的坐标点标注。 但是在ArcGIS Pro中要实现这个效果却并不容易。 虽然有点标题党,这里就尽量在ArcGIS Pro中实现一下。 01 标注实现方法 首先是准备工作,准备一个点要素图层,包含xy坐标字段。 在地图框…...

Unity项目性能优化列表
1、对象池 2、检查内存是否泄露。内存持续上升(闭包、委托造成泄露) 3、检查DrawCall数量,尽量减少SetPassCall 4、尽量多的利用四种合批 动态合批(Dynamic Batching)静态合批(Static Batching)GPUInstancingSRP Batcher 动态合批消耗内存把多个网格组合在一起合并…...

【系统架构设计师】高分论文:论软件架构的生命周期
更多内容请见: 备考系统架构设计师-专栏介绍和目录 文章目录 摘要正文摘要 2022 年5月,本人所在的某集团公司承接了财务共享服务平台综合管理系统的项目开发,该项目主要实现财务系统主流业务的集成共享。本人担任项目组成员中的系统架构设计师一职,全面负责项目的全生命周…...

流量控制和拥塞控制的区别
流量控制和拥塞控制是TCP协议中两个重要的机制,它们分别用于解决不同的问题。 流量控制 流量控制的目的是防止发送方发送数据过快,导致接收方来不及接收,从而避免分组丢失。流量控制是通过滑动窗口机制实现的,接收方在返回的ACK…...

CSS 背景、阴影和混合模式
网站的好坏在于细节,在实现页面里某个组件的布局并写完样式之后,不要急着继续,有意识地训练自己,以挑剔的眼光审视刚刚完成的代码。 1 背景与渐变 background-image 指定文件或者生成的颜色渐变为背景图片。 background-origin…...

第49届ICPC亚洲区域赛,非凸科技再次支持上海赛站
11月16日-17日,第49届ICPC国际大学生程序设计竞赛亚洲区域赛上海站在上海大学宝山校区成功举办,来自全国各地222所高校、中学、企业的352支参赛队伍同台竞技。非凸科技高度重视ICPC竞赛,再次荣膺上海赛站合作伙伴,共同推动全球信息…...
)
良好的并发编程习惯之封闭(Confinement)
创作内容丰富的干货文章很费心力,感谢点过此文章的读者,点一个关注鼓励一下作者,激励他分享更多的精彩好文,谢谢大家! “共享可变状态”有两个要点:“共享”和“可变”。封闭的策略是:不共享就完…...
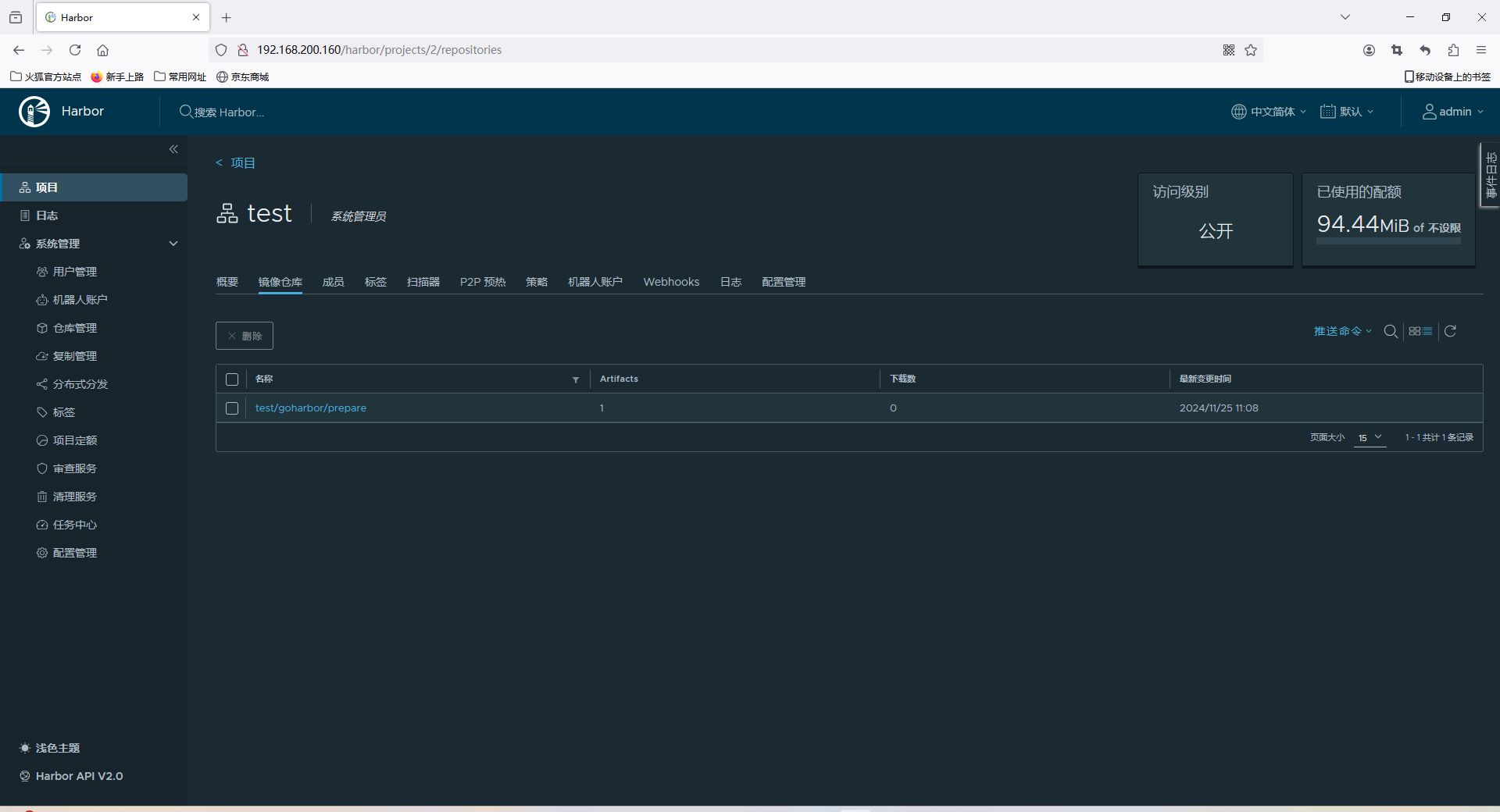
docker镜像、容器、仓库介绍
docker docker介绍docker镜像命令docker容器命令docker仓库 docker介绍 官网 Docker 是一种开源的容器化平台,用于开发、部署和运行应用。它通过将应用程序及其依赖项打包到称为“容器”的单一包中,使得应用能够在任何环境下运行,不受底层系…...
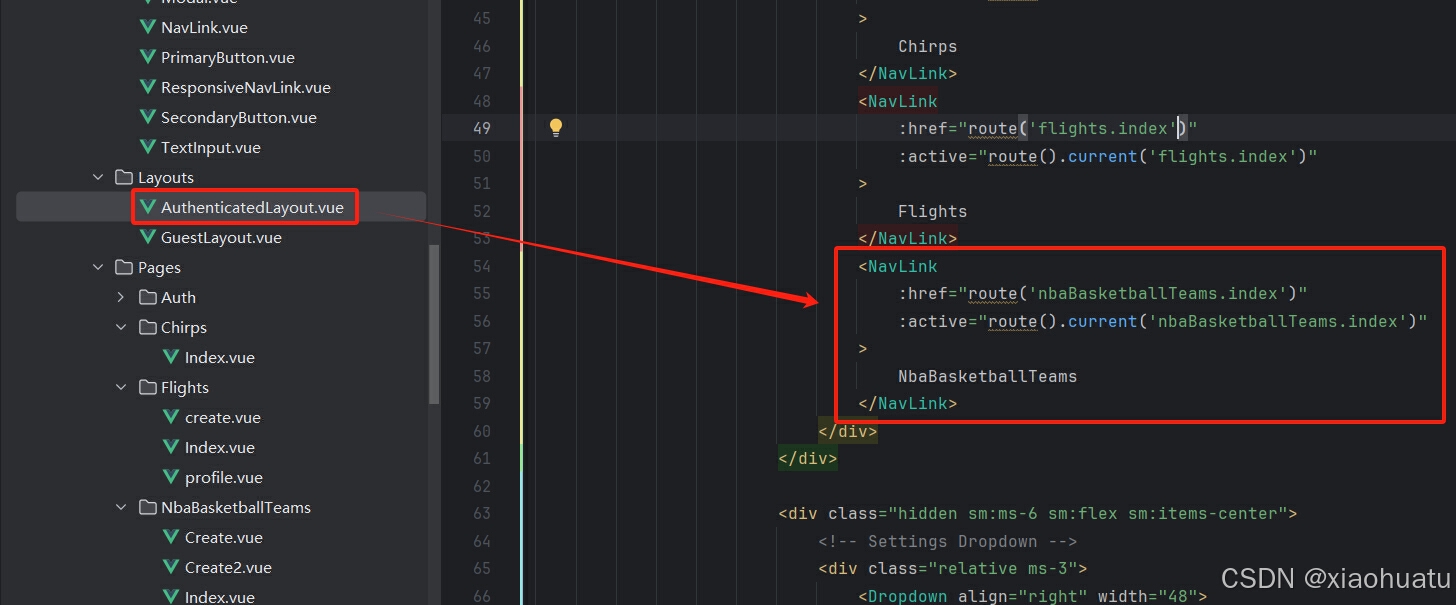
写个添加球队和展示球队的功能--laravel与inertia
先展示下最终效果,如下是展示球队的界面 如下是添加球队的界面 界面样式没怎么调整,不要在意这些细节。先说说操作流程 首先需要登录,没注册就注册一个账号。登录界面就不展示了。然后选中”NbaBasketballTeams“这个选项,就进入了展示球队的界面。然后点击…...
自制Windows系统(十)
上图 (真的不是Windows破解版) 开源地址:仿Windows...
World of Warcraft /script SetRaidTarget(“target“, n, ““) n=8,7,6,5,4,3,2,1,0
魔兽世界执行当前目标标记方法 /script SetRaidTarget("target", n, "") n8,7,6,5,4,3,2,1,0 解析这个lua脚本 D:\Battle.net\World of Warcraft\_classic_\Interface\AddOns\wMarker wMarker.lua /script SetRaidTarget("target", 8, &quo…...

Rust中Tracing 应用指南
欢迎来到这篇全面的Rust跟踪入门指南。Rust 的tracing是一个用于应用程序级别的诊断和调试的库。它提供了一种结构化的、异步感知的方式来记录日志和跟踪事件。与传统的日志记录相比,tracing能够更好地处理复杂的异步系统和分布式系统中的事件跟踪,帮助开…...

海外媒体发稿:根据您的要求编写二十个文案标题方法-华媒舍
本文旨在科普解读并描述标题中所包含的二十个爆款文案,为读者提供更深入的了解和知识。通过对每个标题进行拆解描述,我们将深入探讨各个文案标题的背后含义和吸引人之处。 1、"10个你不可忽视的秘密技巧,提升你的生活品质!&q…...

gitlab:使用脚本批量下载项目,实现全项目检索
目的 当需要知道gitlab中所有项目是否存在某段代码时,gitlab免费版只提供了当个项目内的检索,当项目过多时一个个查太过繁琐。下面通过 GitLab API 将指定 Group 下的所有项目克隆到本地。此脚本会自动获取项目列表并逐一克隆它们,再在本地进…...

macos 使用 nvm 管理 node 并自定义安装目录
系统环境:MacOS Version 参考文章: Github 地址:https://github.com/nvm-sh/nvm 安装的方式是很简单的,直接执行下面的命令即可: curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.0/install.sh | bas…...

网络编程第一课
0voice第一课 https://github.com/0voice 今日学习:网络通信IO 网络通信的核心是通过系统提供的socket套接字实现的。socket和c语言中文件操作的本质类似,在c语言中,通过fopen、fclose、fread、fwrite实现了对文件的操作,socket…...
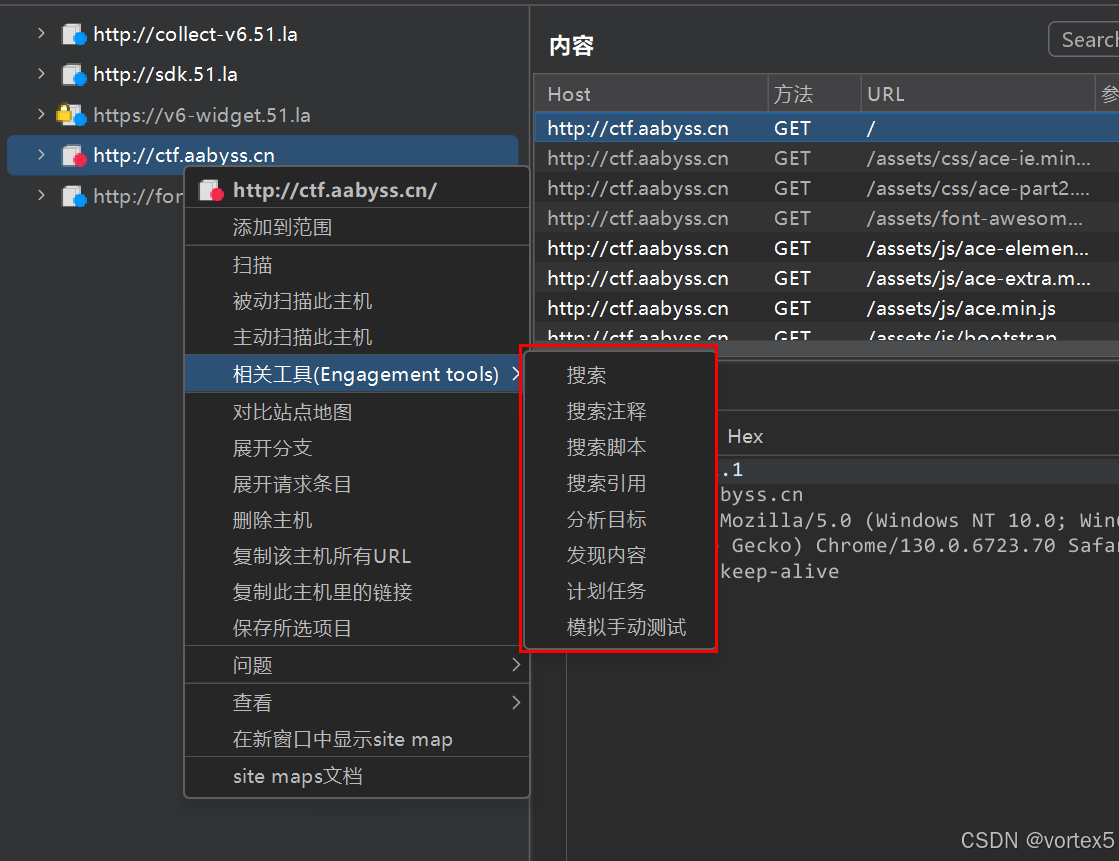
玩转 Burp Suite (1)
内容预览 ≧∀≦ゞ 玩转 Burp Suite (1)声明Burp Suite 简介Dashboard(仪表盘)1. 默认任务管理2. 暂停任务3. 新建扫描任务4. 使用总结 Target(目标)1. SIte Map (站点地图)2. Scope(范围&#…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

BLE四大广播模式详解:可连接/不可连接/定向/周期广播
一、前言在低功耗蓝牙(BLE)开发中,广播(Advertising)是设备发现、连接建立、数据广播、设备重连的核心基石,所有BLE交互流程均始于广播报文的收发。不同于传统经典蓝牙,BLE所有广播行为标准化、…...

为什么软件开发偏爱 Linux?深度剖析 Linux 相较于 Windows 的核心优势
引言 在软件开发的世界里,一个有趣的现象是:无论是大型互联网公司的服务器集群,还是资深程序员的个人开发机,Linux 操作系统的身影无处不在。与之形成鲜明对比的是,尽管 Windows 在个人消费市场占据绝对主导地位&…...
)
GIS工程应用记录(AI辅助编程)
问题的问题:语境坍缩“从各个角度提出问题,AI做出对应积极答复和修改,结果没有什么变化。”这,就是元问题最核心的症状。你尝试了所有你已知的“高级”协作手段,但就像重拳打在棉花上,AI永远在积极回应&…...

3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行
3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or KernelSU (root so…...
【php语法学习,iscc校赛wp】)
学习日志(三)【php语法学习,iscc校赛wp】
1. 任务 1.1.1.1.1.1. 知识部分 rce看【之前的笔记?】php的知识点学习继续jwt token好像是比赛的题目考察内容,我看看php伪协议 1.1.1.1.1.2. 题目 参加iscc比赛【五一】rce题目 1.1.1.1.1.3. 环境配置 把vscode搞好,上学期没有把Php配…...