部署 DeepSpeed以推理 defog/sqlcoder-70b-alpha 模型
部署 DeepSpeed 以推理 defog/sqlcoder-70b-alpha 这样的 70B 模型是一个复杂的过程,涉及多个关键步骤。下面是详细的步骤,涵盖了从模型加载、内存优化到加速推理的全过程。
1. 准备环境
确保你的环境配置正确,以便能够顺利部署 defog/sqlcoder-70b-alpha 模型。
系统要求:
- CUDA 版本:确保安装的 CUDA 版本支持你正在使用的 GPU(例如 A100 或 H100,通常需要 CUDA 11.x 或更高版本)。
- NVIDIA GPU 驱动:确保你的 GPU 驱动版本兼容 CUDA。
- Python 环境:建议使用虚拟环境或 Conda 环境来管理 Python 依赖。
# 创建并激活一个虚拟环境
python3 -m venv deepspeed_env
source deepspeed_env/bin/activate
安装 DeepSpeed 和所需依赖:
pip install deepspeed
pip install torch
pip install transformers
安装 NVIDIA 工具包:
如果你打算使用 TensorRT 和量化推理,你需要安装 NVIDIA TensorRT。
# 安装 TensorRT 和相关库
pip install nvidia-pyindex
pip install nvidia-tensorrt
2. 下载 defog/sqlcoder-70b-alpha 模型
你需要从模型存储库或相关网站下载 defog/sqlcoder-70b-alpha 模型权重文件。如果模型在 Hugging Face 或其他平台提供下载,使用以下命令:
git lfs install
git clone https://huggingface.co/defog/sqlcoder-70b-alpha
3. 配置 DeepSpeed
DeepSpeed 提供了多种优化模式,如 ZeRO 优化(ZeRO Stage 1, 2, 3)和 混合精度推理(FP16)。在部署大模型时,我们将结合这些技术进行优化。
配置文件:deepspeed_config.json
创建一个 DeepSpeed 配置文件,用于指定优化和并行化策略。以下是一个针对大模型推理的典型配置:
{"train_batch_size": 1,"steps_per_print": 1,"gradient_accumulation_steps": 1,"zero_optimization": {"stage": 2,"offload_param": true,"offload_optimizer": false,"offload_activations": true,"overlap_comm": true},"fp16": {"enabled": true,"loss_scale": 0,"initial_scale_power": 16,"fp16_opt_level": "O2"},"activation_checkpointing": {"checkpoint_interval": 1,"offload_activations": true},"wall_clock_breakdown": true,"optimizer": {"type": "Adam","params": {"lr": 1e-5}},"multi_gpu": true
}
- Zero Optimization:选择 Stage 2 优化,允许将模型参数卸载到 CPU 内存,以减少 GPU 显存占用。
- FP16:启用混合精度推理来加速计算,减少显存使用。
- 激活检查点:减少 GPU 显存消耗,通过将中间激活值卸载到 CPU 来节省内存。
- 多卡支持:确保多 GPU 模式开启以支持模型并行。
4. 加载模型和 DeepSpeed 配置
你需要在代码中加载 defog/sqlcoder-70b-alpha 模型,并将 DeepSpeed 配置应用到模型上。
以下是一个 Python 示例,展示如何加载模型并使用 DeepSpeed 启动推理:
import deepspeed
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer# 1. 加载模型和分词器
model_name = "defog/sqlcoder-70b-alpha" # 模型路径或 HuggingFace 仓库
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)# 2. 配置 DeepSpeed
deepspeed_config = "deepspeed_config.json" # 你的 DeepSpeed 配置文件# 3. 使用 DeepSpeed 初始化模型
model = deepspeed.init_inference(model, config_params=deepspeed_config)# 4. 推理示例
inputs = tokenizer("SELECT * FROM users WHERE id = 1;", return_tensors="pt")
inputs = {key: value.cuda() for key, value in inputs.items()} # 将输入迁移到 GPUwith torch.no_grad():outputs = model.generate(inputs["input_ids"], max_length=100)# 解码输出
output_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(output_text)
5. 优化推理性能
-
Tensor Parallelism:对于 70B 这种超大模型,通常会选择 模型并行(Tensor Parallelism)。如果你在多个 GPU 上运行模型,可以通过
deepspeed配置实现模型的并行化。在 DeepSpeed 中,启用 Tensor Parallelism 让每个 GPU 只运行模型的某个部分,减少显存占用并提高计算速度。
示例配置:
{"tensor_parallel_degree": 8 } -
激活卸载:启用激活卸载(
offload_activations)将中间激活卸载到 CPU 内存,进一步减少 GPU 显存的使用。
6. 量化推理(Optional)
为了进一步减少显存使用并加速推理,你可以将模型量化为 INT8。这可以通过 TensorRT 或 DeepSpeed 配合 INT8 实现。
-
使用 DeepSpeed 进行 INT8 量化:
"fp16": {"enabled": true }, "int8": {"enabled": true } -
使用 TensorRT 加速推理。对于 NVIDIA GPU,转换为 TensorRT 引擎并进行推理,能显著提升性能。
7. 推理结果监控与优化
推理时,记得监控 GPU 显存使用量、计算吞吐量 和 延迟,以确保推理过程高效无瓶颈。你可以通过 nvidia-smi、nvidia-smi dmon 等工具监控 GPU 状态。
8. 优化建议
- 批处理大小(Batch Size):根据 GPU 显存和推理需求调整批处理大小。虽然 70B 模型需要在多 GPU 环境下运行,但批量处理可以加速推理。
- 流式推理(Streaming Inference):在推理过程中,可以采用流式推理方法,以便实现更低的延迟,特别是在实时应用中。
总结:
部署 DeepSpeed 来推理 defog/sqlcoder-70b-alpha 模型的核心步骤包括:
- 环境准备:安装 DeepSpeed 和相关依赖。
- DeepSpeed 配置:设置
deepspeed_config.json文件,启用 ZeRO 优化、混合精度(FP16)、激活卸载等。 - 加载模型并应用 DeepSpeed:加载模型并使用 DeepSpeed 进行推理初始化。
- 优化推理性能:使用模型并行、Tensor Parallelism 和激活卸载来优化显存和计算效率。
- 量化推理:使用 INT8 量化推理进一步提高性能(可选)。
- 监控推理过程:实时监控 GPU 状态并调整参数以优化性能。
通过这些步骤,你可以成功部署和优化 defog/sqlcoder-70b-alpha 模型,确保推理过程高效且低延迟。
相关文章:

部署 DeepSpeed以推理 defog/sqlcoder-70b-alpha 模型
部署 DeepSpeed 以推理 defog/sqlcoder-70b-alpha 这样的 70B 模型是一个复杂的过程,涉及多个关键步骤。下面是详细的步骤,涵盖了从模型加载、内存优化到加速推理的全过程。 1. 准备环境 确保你的环境配置正确,以便能够顺利部署 defog/sqlc…...

Python网络爬虫基础
Python网络爬虫是一种自动化工具,用于从互联网上抓取信息。它通过模拟人类浏览网页的行为,自动地访问网站并提取所需的数据。网络爬虫在数据挖掘、搜索引擎优化、市场研究等多个领域都有广泛的应用。以下是Python网络爬虫的一些基本概念: 1.…...

每天五分钟机器学习:支持向量机数学基础之超平面分离定理
本文重点 超平面分离定理(Separating Hyperplane Theorem)是数学和机器学习领域中的一个重要概念,特别是在凸集理论和最优化理论中有着广泛的应用。该定理表明,在特定的条件下,两个不相交的凸集总可以用一个超平面进行分离。 定义与表述 超平面分离定理(Separating Hy…...

TCP/IP网络协议栈
TCP/IP网络协议栈是一个分层的网络模型,用于在互联网和其他网络中传输数据。它由几个关键的协议层组成,每一层负责特定的功能。以下是对TCP/IP协议栈的简要介绍: TCP/IP协议模型的分层 1. 应用层(Application Layer)…...

利用编程思维做题之最小堆选出最大的前10个整数
1. 理解问题 我们需要设计一个程序,读取 80,000 个无序的整数,并将它们存储在顺序表(数组)中。然后从这些整数中选出最大的前 10 个整数,并打印它们。要求我们使用时间复杂度最低的算法。 由于数据量很大,直…...

详解MVC架构与三层架构以及DO、VO、DTO、BO、PO | SpringBoot基础概念
🙋大家好!我是毛毛张! 🌈个人首页: 神马都会亿点点的毛毛张 今天毛毛张分享的是SpeingBoot框架学习中的一些基础概念性的东西:MVC结构、三层架构、POJO、Entity、PO、VO、DO、BO、DTO、DAO 文章目录 1.架构1.1 基本…...

Unity C# 影响性能的坑点
c用的时间长了怕unity的坑忘了,记录一下。 GetComponent最好使用GetComponent<T>()的形式, 继承自Monobehaviour的函数要避免空的Awake()、Start()、Update()、FixedUpdate().这些空回调会造成性能浪费 GetComponent方法最好避免在Update当中使用…...

工作学习:切换git账号
概括 最近工作用的git账号下发下来了,需要切换一下使用的账号。因为是第一次弄,不熟悉,现在记录一下。 打开设置 路径–git—git remotes,我这里选择项是Manage Remotes,点进去就可以了。 之后会出现一个输入框&am…...
)
量化交易系统开发-实时行情自动化交易-8.量化交易服务平台(一)
19年创业做过一年的量化交易但没有成功,作为交易系统的开发人员积累了一些经验,最近想重新研究交易系统,一边整理一边写出来一些思考供大家参考,也希望跟做量化的朋友有更多的交流和合作。 接下来会对于收集整理的33个量化交易服…...

Scala习题
姓名,语文,数学,英语 张伟,87,92,88 李娜,90,85,95 王强,78,90,82 赵敏,92,88,91 孙涛,…...

结构方程模型(SEM)入门到精通:lavaan VS piecewiseSEM、全局估计/局域估计;潜变量分析、复合变量分析、贝叶斯SEM在生态学领域应用
目录 第一章 夯实基础 R/Rstudio简介及入门 第二章 结构方程模型(SEM)介绍 第三章 R语言SEM分析入门:lavaan VS piecewiseSEM 第四章 SEM全局估计(lavaan)在生态学领域高阶应用 第五章 SEM潜变量分析在生态学领域…...

OpenCV图像基础处理:通道分离与灰度转换
在计算机视觉处理中,理解图像的颜色通道和灰度表示是非常重要的基础知识。今天我们通过Python和OpenCV来探索图像的基本组成。 ## 1. 图像的基本组成 在数字图像处理中,彩色图像通常由三个基本颜色通道组成: - 蓝色(Blue&#x…...

C++ 类和对象(类型转换、static成员)
目录 一、前言 二、正文 1.隐式类型转换 1.1隐式类型转换的使用 2.static成员 2.1 static 成员的使用 2.1.1static修辞成员变量 2.1.2 static修辞成员函数 三、结语 一、前言 大家好,我们又见面了。昨天我们已经分享了初始化列表:https://blog.c…...
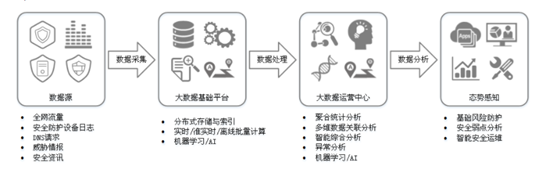
【网络安全设备系列】12、态势感知
0x00 定义: 态势感知(Situation Awareness,SA)能够检测出超过20大类的云上安全风险,包括DDoS攻击、暴力破解、Web攻击、后门木马、僵尸主机、异常行为、漏洞攻击、命令与控制等。利用大数据分析技术,态势感…...

Linux介绍与安装指南:从入门到精通
1. Linux简介 1.1 什么是Linux? Linux是一种基于Unix的操作系统,由Linus Torvalds于1991年首次发布。Linux的核心(Kernel)是开源的,允许任何人自由使用、修改和分发。Linux操作系统通常包括Linux内核、GNU工具集、图…...

BGE-M3模型结合Milvus向量数据库强强联合实现混合检索
在基于生成式人工智能的应用开发中,通过关键词或语义匹配的方式对用户提问意图进行识别是一个很重要的步骤,因为识别的精准与否会影响后续大语言模型能否检索出合适的内容作为推理的上下文信息(或选择合适的工具)以给出用户最符合…...
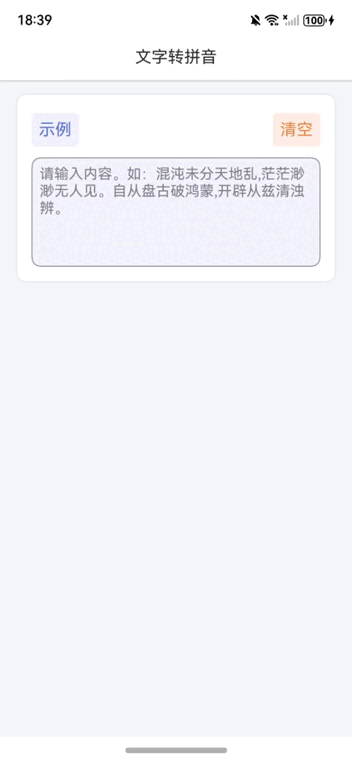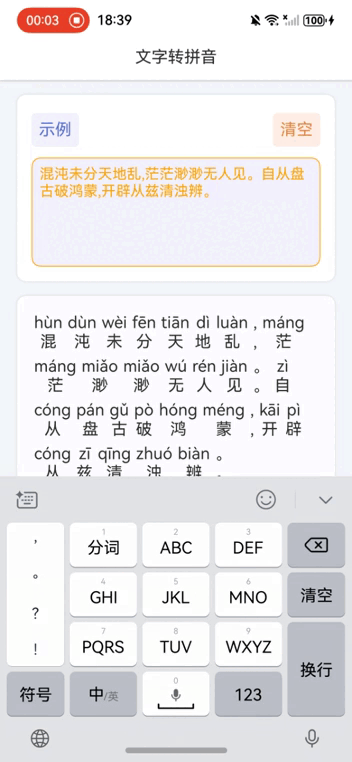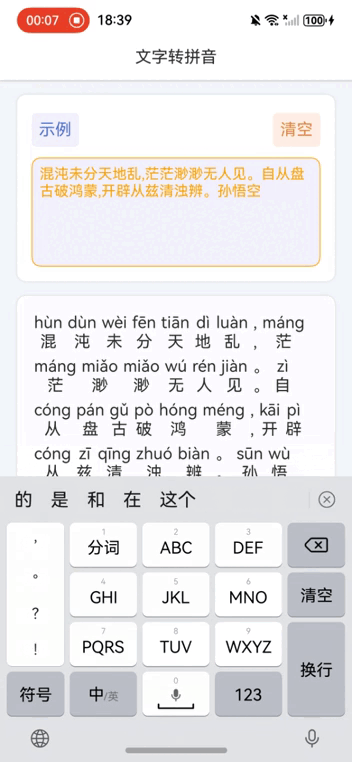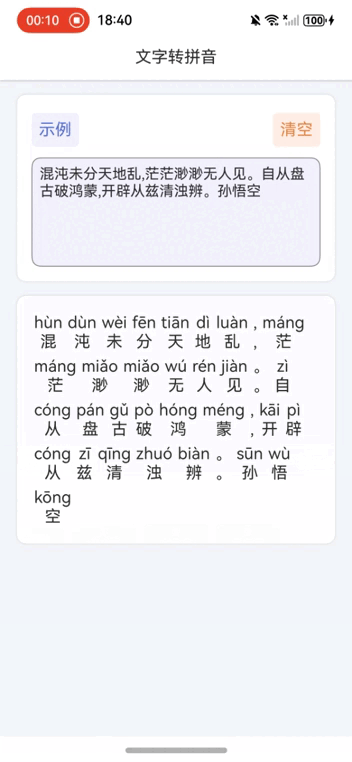
鸿蒙NEXT开发案例:文字转拼音
【引言】 在鸿蒙NEXT开发中,文字转拼音是一个常见的需求,本文将介绍如何利用鸿蒙系统和pinyin-pro库实现文字转拼音的功能。 【环境准备】 • 操作系统:Windows 10 • 开发工具:DevEco Studio NEXT Beta1 Build Version: 5.0.…...
)
CTF之密码学(栅栏加密)
栅栏密码是古典密码的一种,其原理是将一组要加密的明文划分为n个一组(n通常根据加密需求确定,且一般不会太大,以保证密码的复杂性和安全性),然后取每个组的第一个字符(有时也涉及取其他位置的字…...

修改插槽样式,el-input 插槽 append 的样式
需缩少插槽 append 的 宽度 方法1、使用内联样式直接修改,指定 width 为 30px <el-input v-model"props.applyBasicInfo.outerApplyId" :disabled"props.operateCommandType input-modify"><template #append><el-button click…...

UPLOAD LABS | PASS 01 - 绕过前端 JS 限制
关注这个靶场的其它相关笔记:UPLOAD LABS —— 靶场笔记合集-CSDN博客 0x01:过关流程 本关的目标是上传一个 WebShell 到目标服务器上,并成功访问: 我们直接尝试上传后缀为 .php 的一句话木马: 如上,靶场弹…...

大数据毕业设计容易的题目答疑
1 引言 毕业设计是大家学习生涯的最重要的里程碑,它不仅是对四年所学知识的综合运用,更是展示个人技术能力和创新思维的重要过程。选择一个合适的毕业设计题目至关重要,它应该既能体现你的专业能力,又能满足实际应用需求ÿ…...

SpringBoot 3.2.0 项目里整合 Flowable 7.1.0,我踩过的那些坑和最佳实践
SpringBoot 3.2.0 项目里整合 Flowable 7.1.0,我踩过的那些坑和最佳实践 最近在重构公司内部的工作流系统时,我决定采用 SpringBoot 3.2.0 和 Flowable 7.1.0 的组合。本以为只是简单的依赖引入和配置,没想到从 POM 文件开始就踩了不少坑。这…...

macOS高效录屏工具实战指南:从入门到专业的QuickRecorder应用技巧
macOS高效录屏工具实战指南:从入门到专业的QuickRecorder应用技巧 【免费下载链接】QuickRecorder A lightweight screen recorder based on ScreenCapture Kit for macOS / 基于 ScreenCapture Kit 的轻量化多功能 macOS 录屏工具 项目地址: https://gitcode.com…...

Qwen2.5-VL-7B-Instruct应用场景:法律合同关键条款图文定位与摘要生成
Qwen2.5-VL-7B-Instruct应用场景:法律合同关键条款图文定位与摘要生成 想象一下,你是一位法务人员或商务经理,面前摆着一份几十页、图文并茂的复杂合同。你需要快速找到关于“违约责任”、“付款条件”或“知识产权归属”的关键条款。传统的…...

基于springboot的旅游景点门票信息系统设计与实现-vue
目录 技术栈选择系统模块划分数据库设计接口设计规范前端实现要点安全措施部署方案开发流程测试计划扩展功能预留 项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作 技术栈选择 后端采用Spring Boot框架,提供RESTful…...

FireRedASR Pro模型架构浅析:从卷积神经网络到端到端设计
FireRedASR Pro模型架构浅析:从卷积神经网络到端到端设计 最近在语音识别圈子里,FireRedASR Pro这个名字被提到的次数越来越多了。不少朋友都在问,这个模型到底有什么特别之处,为什么大家都在讨论它。其实,它的核心魅…...

Fun-ASR-MLT-Nano-2512快速上手:Web界面操作,无需代码基础
Fun-ASR-MLT-Nano-2512快速上手:Web界面操作,无需代码基础 1. 语音识别新选择:Fun-ASR-MLT-Nano-2512 1.1 模型简介 Fun-ASR-MLT-Nano-2512是阿里通义实验室推出的轻量级多语言语音识别模型,经过开发者by113小贝的二次开发优化…...

C++ 智能指针的底层实现逻辑
C智能指针的底层实现逻辑揭秘 在C开发中,内存管理一直是程序员需要谨慎处理的难题。传统裸指针容易导致内存泄漏、悬垂指针等问题,而智能指针通过自动化资源管理,显著提升了代码的安全性和可维护性。那么,智能指针是如何在底层实…...

Phi-3-mini-128k-instruct辅助Dev-C++初学者:C/C++编译错误智能解读
Phi-3-mini-128k-instruct:你的Dev-C编程“陪练” 刚学C/C那会儿,你是不是也经常被Dev-C弹出的那一大串编译错误信息搞得一头雾水?什么“undefined reference”,什么“expected ‘;’ before ‘}’ token”,每个单词都…...

Wan2.2-T2V-A5B提示词怎么写?新手快速出效果的实用指南
Wan2.2-T2V-A5B提示词怎么写?新手快速出效果的实用指南 1. 认识Wan2.2-T2V-A5B视频生成模型 Wan2.2-T2V-A5B是一款由通义万相开源的轻量级文本到视频生成模型,拥有50亿参数规模。虽然它生成的视频分辨率是480P,但在时序连贯性和运动推理能力…...