运维面试整理总结
面试题可以参考:面试题总结
查看系统相关信息
查看系统登陆成功与失败记录
- 成功:last
- 失败:lastb
查看二进制文件
hexdump
查看进程端口或连接
netstat -nltp
ss -nltp
补充:pidof与lsof命令
pidof [进程名] #根据 进程名 查询进程id
lsof -i:[端口号] #根据 端口号 查询有哪些连接
lsof -p [进程id] #根据 进程id 查询有哪些连接
lsof -c [进程名称] #根据 进程名称 查询有哪些连接
查看CPU相关信息
- top 查看每个进程占用CPU的时间,平均负载,按
1键查看每个cpu的具体使用情况,按t将进程按照CPU的占用使用从大到小排序 - uptime 查看CPU的平均负载
- iostat 主要用来查看磁盘读写状态的,也可以查看到cpu的平均负载情况
[root@k8s-master ~]# iostat
Linux 3.10.0-1160.92.1.el7.x86_64 (k8s-master) 11/26/2024 _x86_64_ (8 CPU)avg-cpu: %user %nice %system %iowait %steal %idle2.46 0.00 2.06 1.50 0.04 93.93Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 284.84 0.64 645.34 1007304 1017702772
sdb 201.55 2.49 711.40 3928223 1121874803查看内存相关信息
- free -h 最常用的系统命令
- vmstat 查看具体的使用情况
[root@k8s-master ~]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st2 0 0 1281692 4252 12091736 0 0 3 172 2 2 2 2 94 2 0
查看磁盘相关信息
- lsblk
- df -Th
- iostat
查看网卡流量
iftop
我愿称这个命令为最强命令
可以非常清晰的看到每个流量的具体情况,谁用谁知道
查看路由相关信息
- 查看路由
ip route show
- 查看路由表
# 下面两个结果相同
route -n
netstat -nr
watch
[root@3 ~]# watch ifconfig eth0Every 2.0s: ifconfig eth0 Sun May 1 21:53:10 2022eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500inet 10.2.3.101 netmask 255.255.255.0 broadcast 10.2.3.255inet6 fe80::546f:77ff:fe6f:78 prefixlen 64 scopeid 0x20<link>ether 56:6f:77:6f:00:78 txqueuelen 1000 (Ethernet)RX packets 980997 bytes 63958819 (60.9 MiB)RX errors 0 dropped 140820 overruns 0 frame 0TX packets 109994 bytes 6171909 (5.8 MiB)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
dstat
[root@3 ~]# dstat
You did not select any stats, using -cdngy by default.
----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai hiq siq| read writ| recv send| in out | int csw 0 0 100 0 0 0|1277B 1515B| 0 0 | 0 0 | 54 56 0 0 100 0 0 0| 0 0 | 485B 130B| 0 0 | 95 103 0 0 100 0 0 0| 0 0 | 348B 898B| 0 0 | 84 109 0 0 100 0 0 0| 0 0 | 449B 370B| 0 0 | 93 110 0 0 100 0 0 0| 0 0 | 450B 370B| 0 0 | 84 91 0 0 100 0 0 0| 0 0 | 467B 370B| 0 0 | 90 101 0 0 100 0 0 0| 0 0 | 306B 370B| 0 0 | 72 95 q0 0 100 0 0 0| 0 0 | 501B 740B| 0 0 | 69 92 0 0 100 0 0 0| 0 345k| 186B 130B| 0 0 | 78 101 0 0 100 0 0 0| 0 0 | 485B 370B| 0 0 | 70 90
sysstat
此命令根据参数的不同,可以查看系统不同的信息,详情请见:https://linux.cn/article-4028-1.html
也可以参考百度文库:https://wenku.baidu.com/view/e89049fdcd2f0066f5335a8102d276a2002960e6.html
[root@3 ~]# yum -y install sysstat
[root@3 ~]# sar -n DEV 1 2 // -n DEV表示查看网络信息,1表示一秒一次,2表示一共两次
Linux 3.10.0-957.el7.x86_64 (3.101-CentOS7.6) 05/01/2022 _x86_64_ (8 CPU)09:59:51 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
09:59:52 PM eth0 6.00 0.00 0.42 0.00 0.00 0.00 0.00
09:59:52 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.0009:59:52 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
09:59:53 PM eth0 6.00 1.00 0.36 0.19 0.00 0.00 0.00
09:59:53 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
Average: eth0 6.00 0.50 0.39 0.09 0.00 0.00 0.00
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
cat直接查看
[root@3 ~]# cat /proc/net/dev
Inter-| Receive | Transmitface |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressedeth0: 95970470 988296 0 141200 0 0 0 0 6464566 114062 0 0 0 0 0 0lo: 336200 6724 0 0 0 0 0 0 336200 6724 0 0 0 0 0 0
proc/net/dev中每一项的含义是:
-
bytes: The total number of bytes of data transmitted or received by the interface.(接口发送或接收的数据的总字节数)
-
packets: The total number of packets of data transmitted or received by the interface.(接口发送或接收的数据包总数)
-
errs: The total number of transmit or receive errors detected by the device driver.(由设备驱动程序检测到的发送或接收错误的总数)
-
drop: The total number of packets dropped by the device driver.(设备驱动程序丢弃的数据包总数)
-
fifo: The number of FIFO buffer errors.(FIFO缓冲区错误的数量)
-
frame: The number of packet framing errors.(分组帧错误的数量)
-
colls: The number of collisions detected on the interface.(接口上检测到的冲突数)
-
compressed: The number of compressed packets transmitted or received by the device driver. (This - - appears to be unused in the 2.2.15 kernel.)(设备驱动程序发送或接收的压缩数据包数)
-
carrier: The number of carrier losses detected by the device driver.(由设备驱动程序检测到的载波损耗的数量)
-
multicast: The number of multicast frames transmitted or received by the device driver.(设备驱动程序发送或接收的多播帧数)
查看进程
查看进程已运行时间
[root@3 ~]# ps -eo pid,lstart,etime,command PID STARTED ELAPSED COMMAND1 Fri Apr 29 14:00:04 2022 2-08:53:16 /usr/lib/systemd/systemd --switched-root --system --deserialize 222 Fri Apr 29 14:00:04 2022 2-08:53:16 [kthreadd]3 Fri Apr 29 14:00:04 2022 2-08:53:16 [ksoftirqd/0]5 Fri Apr 29 14:00:04 2022 2-08:53:16 [kworker/0:0H]6 Fri Apr 29 14:00:04 2022 2-08:53:16 [kworker/u32:0]7 Fri Apr 29 14:00:04 2022 2-08:53:16 [migration/0]8 Fri Apr 29 14:00:04 2022 2-08:53:16 [rcu_bh]
进程相关
## processes 进程管理##ps查看当前系统执行的线程列表,进行瞬间状态,不是连续状态,连续状态需要使用top名称查看 更多常用参数请使用 man ps查看
ps##显示所有进程详细信息
ps aux##-u 显示某个用户的进程列表
ps -f -u www-data ## -C 通过名字或者命令搜索进程
ps -C apache2## --sort 根据进程cpu使用率降序排列,查看前5个进程 -pcpu表示降序 pcpu升序
ps aux --sort=-pcpu | head -5 ##-f 用树结构显示进程的层次关系,父子进程情况下
ps -f --forest -C apache2 ##显示一个父进程的所有子进程
ps -o pid,uname,comm -C apache2
ps --ppid 2359 ##显示一个进程的所有线程 -L 参数
ps -p 3150 -L ##显示进程的执行时间 -o参数
ps -e -o pid,comm,etime ##watch命令可以用来实时捕捉ps显示进程
watch -n 1 'ps -e -o pid,uname,cmd,pmem,pcpu --sort=-pmem,-pcpu | head -15' ##jobs 查看后台运行的进程 jobs命令执行的结果,+表示是一个当前的作业,减号表是是一个当前作业之后的一个作业,jobs -l选项可显示所有任务的PID,jobs的状态可以是running, stopped, Terminated,但是如果任务被终止了(kill),shell 从当前的shell环境已知的列表中删除任务的进程标识;也就是说,jobs命令显示的是当前shell环境中所起的后台正在运行或者被挂起的任务信息
jobs##查看后台运营的进程号
jobs -p##查看现在被终止或者退出的进程号
jobs -n##kill命令 终止一个前台进程可以使用Ctrl+C键 kill 通过top或者ps获取进程id号 kill [-s 信号 | -p ] [ -a ] 进程号 ...
##发送指定的信号到相应进程。不指定型号将发送SIGTERM(15)终止指定进程。关闭进程号12的进程
kill 12##等同于在前台运行PID为123的进程时按下Ctrl+C键
kill -2 123##如果任无法终止该程序可用“-KILL” 参数,其发送的信号为SIGKILL(9) ,将强制结束进程
kill -9 123##列出所有信号名称
##HUP 1 终端断线
##INT 2 中断(同 Ctrl + C)
##QUIT 3 退出(同 Ctrl + \)
##TERM 15 终止
##KILL 9 强制终止
##CONT 18 继续(与STOP相反, fg/bg命令)
##STOP 19 暂停(同 Ctrl + Z)
kill -l##得到指定信号的数值
kill -l KILL##杀死指定用户所有进程
kill -u peidalinux
kill -9 $(ps -ef | grep peidalinux) ##将后台中的命令调至前台继续运行 将进程123调至前台执行
fg 123##将一个在后台暂停的命令,变成继续执行
bg 123##该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup就是不挂起的意思 下面输出被重定向到myout.file文件中
nohup command > myout.file 2>&1 &##at:计划任务,在特定的时间执行某项工作,在特定的时间执行一次。
## 格式:at HH:MM YYYY-MM-DD //HH(小时):MM(分钟) YYYY(年)-MM(月份)-DD(日)
##HH[am pm]+D(天) days //HH(小时)[am(上午)pm(下午)]+days(天)
at 12:00(时间) //at命令设定12:00执行一项操作
#at>useradd aaa //在at命令里设定添加用户aaa
#ctrl+d //退出at命令
#tail -f /etc/passwd //查看/etc/passwd文件后十行是否增加了一个用户aaa##计划任务设定后,在没有执行之前我们可以用atq命令来查看系统没有执行工作任务。
atq##启动计划任务后,如果不想启动设定好的计划任务可以使用atrm命令删除。
atrm 1 //删除计划任务1##pstree命令:列出当前的进程,以及它们的树状结构 格式:pstree [选项] [pid|user]
pstree##nice命令:改变程序执行的优先权等级 应用程序优先权值的范围从-20~19,数字越小,优先权就越高。一般情况下,普通应用程序的优先权值(CPU使用权值)都是0,如果让常用程序拥有较高的优先权等级,自然启动和运行速度都会快些。需要注意的是普通用户只能在0~19之间调整应用程序的优先权值,只有超级用户有权调整更高的优先权值(从-20~19)。
nice [-n <优先等级>][--help][--version][命令]
nice -n 5 ls##sleep命令:使进程暂停执行一段时间
date;sleep 1m;date##renice命令 renice命令允许用户修改一个正在运行进程的优先权。利用renice命令可以在命令执行时调整其优先权。
##其中,参数number与nice命令的number意义相同。(1) 用户只能对自己所有的进程使用renice命令。(2) root用户可以在任何进程上使用renice命令。(3) 只有root用户才能提高进程的优先权
renice -5 -p 5200 #PID为5200的进程nice设为-5 ##pmap命令用于显示一个或多个进程的内存状态。其报告进程的地址空间和内存状态信息 #pmap PID
pmap 20367
什么是进程间通信?列举几种常见的IPC方法
进程间通信(Inter-Process Communication, IPC)是指操作系统中两个或多个进程之间交换数据和信息的过程。在许多应用程序中,不同的进程需要相互通信以实现协作功能,例如多进程并发服务器、分布式系统、图形用户界面 (GUI) 应用程序等。
在操作系统中,有许多的进程间通信技术,包括管道、套接字、共享内存、信号量、消息队列、远程过程调用 (RPC) 等。每种技术都有其优点和缺点,具体选择哪种方式要根据实际需求进行选择。
什么是进程调度算法?列举几种常见的调度算法
调度算法是指:根据系统的资源分配策略所规定的资源分配算法
先来先服务调度算法
时间片轮转调度法
短作业(SJF)优先调度算法
最短剩余时间优先
高响应比优先调度算法
优先级调度算法
多级反馈队列调度算法
如何查看一个进程的打开文件和网络连接
ps -elf #查看进程对应的PID
lsof -p 进程PID
netstat -nltp | grep 进程PID
如何设置一个进程的CPU亲和性
taskset 用于设置或查看进程的CPU亲和性,即限制程序运行的CPU核心。通过 taskset 命令,您可以将一个正在运行的进程或启动一个新进程绑定到指定的CPU核心上。
- 将进程绑定到指定的CPU核心上:
taskset -c <CPU列表> <命令>- cpu列表 是一个逗号分隔的CPU核心列表,例如:0、0,1、0-3。这个列表指定了要绑定到的CPU核心。
- 命令 是要执行的命令或程序。该命令将在指定的CPU核心上运行。
- 查看进程的CPU亲和性设置:
taskset -p <进程ID> - 将一个已经运行的进程重新绑定到不同的CPU核心上:
taskset -cp <CPU列表> <进程ID>
taskset 命令需要在具有足够权限的情况下运行(通常需要使用sudo或作为超级用户运行)。使用 taskset 可以帮助优化多核处理器上的任务分配,但需要小心使用,以避免过度绑定或影响系统性能。
以下是一个简单的例子,假设我们想要将进程ID为1234的进程绑定到CPU 0上:
taskset -pc 0 1234
如果你想要将进程绑定到多个CPU上,可以指定CPU的列表,例如CPU 0和CPU 2:
taskset -pc 0,2 1234
如果你想要在运行一个新的程序时设置亲和性,可以使用taskset来启动程序:
taskset -c 0 ./my_program
这里的-c选项后面跟着的是CPU的编号。如果你想要将程序绑定到多个CPU,可以提供一个逗号分隔的列表。
如何限制一个进程的线程数
1. 进程最大数
定义:进程最大数是指系统可以同时运行的进程的最大数量。这个限制通常由内核参数 kernel.pid_max 控制。
调整方法:
- 使用
sysctl命令临时修改:
sudo sysctl -w kernel.pid_max=65536
- 永久修改:
- 编辑
/etc/sysctl.conf文件,添加或修改:
- 编辑
kernel.pid_max = 65536
- 应用更改:
sudo sysctl -p
2. 最大线程数
定义:最大线程数是指一个进程可以创建的最大线程数。线程数的限制通常与系统的可用资源(如内存)有关,而不是直接由一个特定的参数控制。
调整方法:
- 使用
ulimit命令查看和设置线程数限制。线程数的限制通常是由max user processes控制。
# 查看当前用户的最大进程数(包括线程)
ulimit -u# 设置最大进程数(包括线程)
ulimit -u 4096
- 要使更改永久生效,可以在用户的 shell 配置文件(如
~/.bashrc或/etc/security/limits.conf)中添加:
* hard nproc 4096
* soft nproc 4096
3. 进程打开的文件数
定义:每个进程可以打开的文件数是指单个进程能够同时打开的文件描述符的最大数量。这个限制由 fs.file-max 和每个用户或进程的 nofile 限制控制。
调整方法:
- 查看当前的最大文件数限制:
cat /proc/sys/fs/file-max
- 临时修改:
sudo sysctl -w fs.file-max=100000
- 永久修改:
- 编辑
/etc/sysctl.conf文件,添加或修改:
- 编辑
fs.file-max = 100000
- 应用更改:
sudo sysctl -p
- 对于每个用户的文件描述符限制,使用
ulimit命令:
# 查看当前用户的文件数限制
ulimit -n# 设置文件数限制
ulimit -n 65536
- 在
/etc/security/limits.conf中设置:
* hard nofile 65536
* soft nofile 65536
总结
通过调整进程最大数、最大线程数和每个进程可以打开的文件数,可以有效地提高系统的并发处理能力和资源利用率。在进行这些调整时,建议逐步进行并监控系统性能,以确保不会引起资源争用或系统不稳定的问题。
查看Linux系统每个IP的连接数
netstat -n | awk '/^tcp/{print $5}' | awk -F: '{print $1}' | sort | uniq -c | sort -nr
awk数量统计
统计Apache/Nginx日志中某一天不同IP的访问量 <统计日志>
例如: awk ‘{a[$1]++}END{for(i in a){printf(“%d\t%s\n”,a[i],i)}}’ access.log | sort -nr | head -5
[root@test nginx_log]# grep '07/Aug/2012' access.log |awk '{a[$1]++} END{for(i in a){print i,a[i]} }' |sort -k2 -rn |head
222.130.129.42 5761
123.126.51.94 988
123.126.68.22 588
123.114.46.141 418
61.135.249.218 368
110.75.173.162 330
110.75.173.163 327
110.75.173.161 321
110.75.173.160 319
110.75.173.164 314
- 相关解释
- {a[$1]++} 对每行内容,以第一个字段(估计就是IP地址吧)为数组下标进行计数。若遇第一个字段相同的情况,计数累加。用于统计各个IP地址出现的次数。
- END{for(i in a){printf(“%d\t%s\n”,a[i],i)}} 对数组中的每个下标,打印最终统计次数及IP地址,中间以TAB分隔。
- sort -nr 由于之前的打印是次数在前,所以这里可以用sort按数字由大到小排序
- head -5 取前5个,即出现次数最多的(访问频率最高的)
查看inode信息
除了文件本身的文件名称之外,文件所有的信息都在inode中保存.
# 查看文件的inode信息
[root@3 ~]# stat /etc/passwdFile: ‘/etc/passwd’Size: 1047 Blocks: 8 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 67498799 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Context: system_u:object_r:passwd_file_t:s0
Access: 2022-05-02 14:01:01.743000000 +0800
Modify: 2021-05-25 18:03:10.665000000 +0800
Change: 2021-05-25 18:03:10.669000000 +0800# 查看文件的inode号码
[root@3 ~]# ls -i /etc/passwd
67498799 /etc/passwd
性能相关
#查看当前系统load
uptime#查看系统状态和每个进程的系统资源使用状况
top#可视化显示CPU的使用状况
htop#查看每个CPU的负载信息
mpstat -P ALL 1#每隔1秒查看磁盘IO的统计信息
iostat -xkdz 1#每隔一秒查看虚拟内存的使用信息
vmstat 1#查看内存使用统计信息
free#查看网络使用信息
nicstat -z 1#类似vmstat的显示优化的工具
dstat 1#查看系统活动状态,比如系统分页统计,块设备IO统计等
sar#网络连接状态查看
netstat -s#进程资源使用信息查看
pidstat 1
pidstat -d 1#查看某个进程的系统调用信息 -p后面是进程id,-tttT 进程系统后的系统调用时间
strace -tttT -p 12670
#统计IO设备输入输出的系统调用信息
strace -c dd if=/dev/zero of=/dev/null bs=512 count=1024k#tcpdump 查看网络数据包
tcpdump -nr /tmp/out.tcpdump#块设备的读写事件信息统计
btrace /dev/sdb #iotop查看某个进程的IO操作统计信息
iotop -bod5#slabtop 查看内核 slab内存分配器的使用信息
slabtop -sc#系统参数设置
sysctl -a#系统性能指标统计信息
perf stat gzip file1
#系统cpu活动状态查看
perf record -a -g -F 997 sleep 10
磁盘IO检查
##iostat是查看磁盘活动统计情况##显示所有设备负载情况 r/s: 每秒完成的读 I/O 设备次数。即 rio/s;w/s: 每秒完成的写 I/O 设备次数。即 wio/s等
iostat ##每隔2秒刷新磁盘IO信息,并且每次显示3次
iostat 2 3#显示某个磁盘的IO信息
iostat -d sda1##显示tty和cpu信息
iostat -t##以M为单位显示磁盘IO信息
iostat -m##查看TPS和吞吐量信息 kB_read/s:每秒从设备(drive expressed)读取的数据量;kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;kB_read:读取的总数据量;kB_wrtn:写入的总数量数据量;
iostat -d -k 1 1#查看设备使用率(%util)、响应时间(await)
iostat -d -x -k 1 1#查看CPU状态
iostat -c 1 3#统计进程(pid)的stat,进程的stat自然包括进程的IO状况
pidstat#只显示IO
pidstat -d 1 #-d IO 信息,-r 缺页及内存信息-u CPU使用率-t 以线程为统计单位1 1秒统计一次
pidstat -u -r -d -t 1#文件级IO分析,查看当前文件由哪些进程打开
lsof
ls /proc/pid/fd#利用 sar 报告磁盘 I/O 信息DEV 正在监视的块设备 tps 每秒钟物理设备的 I/O 传输总量 rd_sec/s 每秒从设备读取的扇区数量 wr_sec/s 每秒向设备写入的扇区数量 avgrq-sz I/O 请求的平均扇区数
#avgqu-sz I/O 请求的平均队列长度 await I/O 请求的平均等待时间,单位为毫秒 svctm I/O 请求的平均服务时间,单位为毫秒 %util I/O 请求所占用的时间的百分比,即设备利用率
sar -pd 10 3 #iotop top的io版
iotop#查看页面缓存信息 其中的Cached 指用于pagecache的内存大小(diskcache-SwapCache)。随着写入缓存页,Dirty 的值会增加 一旦开始把缓存页写入硬盘,Writeback的值会增加直到写入结束。
cat /proc/meminfo #查看有多少个pdflush进程 Linux 用pdflush进程把数据从缓存页写入硬盘
#pdflush的行为受/proc/sys/vm中的参数的控制/proc/sys/vm/dirty_writeback_centisecs (default 500): 1/100秒, 多长时间唤醒pdflush将缓存页数据写入硬盘。默认5秒唤醒2个(更多个)线程。如果wrteback的时间长于dirty_writeback_centisecs的时间,可能会出问题
cat /proc/sys/vm/nr_pdflush_threads#查看I/O 调度器
#调度算法
#noop anticipatory deadline [cfq]
#deadline : deadline 算法保证对既定的IO请求以最小的延迟时间。
#anticipatory:有个IO发生后,如果又有进程请求IO,则产生一个默认6ms猜测时间,猜测下一个进程请求IO是干什么。这对于随机读取会造成较大的延时。对数据库应用很糟糕,而对于Web Server等则会表现不错。
#cfq: 对每个进程维护一个IO队列,各个进程发来的IO请求会被cfq以轮循方式处理,对每一个IO请求都是公平。适合离散读的应用。
#noop: 对所有IO请求都用FIFO队列形式处理。默认IO不会存在性能问题。
cat /sys/block/[disk]/queue/scheduler#改变IO调度器
$ echo deadline > /sys/block/sdX/queue/scheduler
#提高调度器请求队列的
$ echo 4096 > /sys/block/sdX/queue/nr_requests
概念
进程与线程
概念
- 进程:
- 是系统进行资源分配和调度的一个独立单位.
- 是程序的一次执行,每个进程都有自己的地址空间、内存、数据栈及其他辅助记录运行轨迹的数据
- 线程:
- 是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位
- 所有的线程运行在同一个进程中,共享相同的运行资源和环境
- 线程一般是并发执行的,使得实现了多任务的并行和数据共享。
区别
(1)通常在一个进程中可以包含若干个线程,它们可以利用进程所拥有的资源。在引入线程的操作系统中,通常都是把进程作为分配资源的基本单位,而把线程作为独立运行和独立调度的基本单位。
(2)线程和进程的区别在于,子进程和父进程有不同的代码和数据空间,而多个线程则共享数据空间,每个线程有自己的执行堆栈和程序计数器为其执行上下文。多线程主要是为了节约CPU时间,发挥利用,根据具体情况而定。线程的运行中需要使用计算机的内存资源和CPU。
(3)进程间相互独立,同一进程的各线程间共享。某进程内的线程在其它进程不可见。
(4)线程的上下文切换远大于进程间上下文切换的速度。
(5)进程是不可执行的实体,程序是一个没有生命的实体,只有当处理器赋予程序生命时,它才能成为一个活动的实体,我们称其为进程。
进程和线程的关系
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3)处理机分给线程,即真正在处理机上运行的是线程。
(4)线程在执行过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步。线程是指进程内的一个执行单元,也是进程内的可调度实体.
进程与线程的区别
(1)调度:线程作为调度和分配的基本单位,进程作为拥有资源的基本单位
(2)并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行
(3)拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源.
(4)系统开销:在创建或撤消进程时,由于系统都要为之分配和回收资源,导致系统的开销明显大于创建或撤消线程时的开销。
软链接与硬链接的区别
- 路径
- 软链接: 必须是绝对路径
- 硬链接: 可以是相对路径,也可以是绝对路径
- 权限
- 软链接: 链接文件权限永远是 777
- 硬链接: 跟源文件权限一致
- 变更源文件
- 软链接: 不可以删除与移动源文件
- 硬链接: 可以删除与移动源文件
- inode数量
- 软链接: inode数量与源文件不通
- 硬链接: inode数量与源文件相同
- 文件与目录
- 软链接: 对目录与文件都生效
- 硬链接: 只对文件生效
- 跨文件系统
- 软链接: 可以跨文件系统
- 硬链接: 不可以跨文件系统
cookie与session的区别:
cookie数据保存在客户端,session数据保存在服务器端。
session和cookie的作用有点类似,都是为了存储用户相关的信息。不同的是,cookie是存储在本地浏览器,而session存储在服务器。存储在服务器的数据会更加的安全,不容易被窃取。但存储在服务器也有一定的弊端,就是会占用服务器的资源,但现在服务器已经发展至今,一些session信息还是绰绰有余的。
CDN访问流程
①当用户点击网站页面上的内容URL,经过本地DNS系统解析,DNS系统会最终将域名的解析权交给CNAME指向的CDN专用DNS服务器。
②CDN的DNS服务器将CDN的全局负载均衡设备IP地址返回用户。
③用户向CDN的全局负载均衡设备发起内容URL访问请求。
④CDN全局负载均衡设备根据用户IP地址,以及用户请求的内容URL,选择一台用户所属区域的区域负载均衡设备,告诉用户向这台设备发起请求。
⑤区域负载均衡设备会为用户选择一台合适的缓存服务器提供服务,选择的依据包括:根据用户IP地址,判断哪一台服务器距用户最近;根据用户所请求的URL中携带的内容名称,判断哪一台服务器上有用户所需内容;查询各个服务器当前的负载情况,判断哪一台服务器尚有服务能力。基于以上这些条件的综合分析之后,区域负载均衡设备会向全局负载均衡设备返回一台缓存服务器的IP地址。
⑥全局负载均衡设备把服务器的IP地址返回给用户。
⑦用户向缓存服务器发起请求,缓存服务器响应用户请求,将用户所需内容传送到用户终端。如果这台缓存服务器上并没有用户想要的内容,而区域均衡设备依然将它分配给了用户,那么这台服务器就要向它的上一级缓存服务器请求内容,直至追溯到网站的源服务器将内容拉到本地。
DNS服务器根据用户IP地址,将域名解析成相应节点的缓存服务器IP地址,实现用户就近访问。使用CDN服务的网站,只需将其域名解析权交给CDN的GSLB设备,将需要分发的内容注入CDN,就可以实现内容加速了。
进程间如何通信
| 通信方法 | 无法介于内核态与用户态的原因 |
|---|---|
| 管道(不包括命名管道) | 局限于父子进程间的通信。 |
| 消息队列 | 在硬、软中断中无法无阻塞地接收数据。 |
| 信号量 | 无法介于内核态和用户态使用。 |
| 共享内存 | 需要信号量辅助,而信号量又无法使用。 |
什么是rootkit
入侵者入侵后往往会进行清理脚印和留后门等工作,最常使用的后门创建工具就是rootkit。
不要被名字所迷惑,这个所谓的“rootkit”可不是给超级用户root用的,它是入侵者在入侵了一台主机后,用来做创建后门并加以伪装用的程序包。这个程序包里通常包括了日志清理器,后门等程序。同时,程序包里通常还带有一些伪造的ps、ls、who、w、netstat等原本属于系统本身的程序。这样的话,程序员在试图通过这些命令查询系统状况的时候,就无法通过这些假的系统程序发觉入侵者的行踪。
在一些黑客组织中,rootkit (或者backdoor) 是一个非常感兴趣的话题。
各种不同的rootkit被开发并发布在internet上。在这些rootkit之中, LKM尤其被人关注, 因为它是利用现代操作系统的模块技术。作为内核的一部分运行,这种rootkit将会越来越比传统技术更加强大更加不易被发觉。一旦被安装运行到目标机器上, 系统就会完全被控制在hacker手中了。甚至系统管理员根本找不到安全隐患的痕迹, 因为他们不能再信任它们的操作系统了。
后门程序的目的就是甚至系统管理员企图弥补系统漏洞的时候也可以给hacker系统的访问权限。
什么是蜜罐
蜜罐技术本质上是一种对攻击方进行欺骗的技术,通过布置一些作为诱饵的主机、网络服务或者信息,诱使攻击方对它们实施攻击,从而可以对攻击行为进行捕获和分析,了解攻击方所使用的工具与方法,推测攻击意图和动机,能够让防御方清晰地了解他们所面对的安全威胁,并通过技术和管理手段来增强实际系统的安全防护能力。
蜜罐好比是情报收集系统。蜜罐好像是故意让人攻击的目标,引诱黑客前来攻击。所以攻击者入侵后,你就可以知道他是如何得逞的,随时了解针对服务器发动的最新的攻击和漏洞。还可以通过窃听黑客之间的联系,收集黑客所用的种种工具,并且掌握他们的社交网络。
Linux中什么是Watchdog
Watchdog在实现上可以是硬件电路也可以是软件定时器,能够在系统出现故障时自动重新启动系统。在Linux 内核下, watchdog的基本工作原理是:当watchdog启动后(即/dev/watchdog 设备被打开后),如果在某一设定的时间间隔内/dev/watchdog没有被执行写操作, 硬件watchdog电路或软件定时器就会重新启动系统
访问一个网站的流程
用户输入网站按回车, 查找本地缓存,如果有就打开页面,如果没有,利用DNS做域名解析,递归查询,一级一级的向上提交查询请求,知道查询到为止
HOSTS表 --> 本地DNS -->上层DNS(包括根DNS)
经过了DNS解析,知道了网站的IP地址,然后建立tcp三次握手; 建立请求后,发送请求报文,默认请求的是index.html
传送完毕,断开连接
三次握手,四次挥手
三次握手
- 由客户端(用户)发送建立TCP连接的请求报文,其中报文中包含
seq序列号,是由发送端随机生成的。并且还将报文中SYN字段置为 1,表示需要建立TCP连接请求。 - 服务端(就是百度服务器)会回复客户端(用户)发送的TCP连接请求报文,其中包含
seq序列号,也是由回复端随机生成的, 并且将回复报文的SYN字段置1,而且会产生ACK验证字段,ACK 验证字段数值是在客户端发过来的seq序列号基础上加 1 进行回复: 并且还会回复ack确认控制字段,以便客户端收到信息时,知晓自己的TCP建立请求已得到了确认。 - 客户端收到服务端发送的TCP建立请求后,会使自己的原有序列号加 1 进行再次发送序列号, 并且再次回复
ACK验证请求,在B端发送过来的seq基础上加1,进行回复; 同时也会回复 ack 确认控制字段, 以便B收到信息时,知晓自己的TCP建立请求已经得到了确认。
四次挥手*
*第一次挥手:
Client 发送一个 FIN,用来关闭 Client 到 Server 的数据传送,Client 进入 FIN_WAIT_1 状态。
第二次挥手:
Server 收到 FIN 后,发送一个 ACK 给 Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server 进入 CLOSE_WAIT 状态。
第三次挥手:
Server 发送一个FIN,用来关闭 Server 到 Client 的数据传送,Server 进入 LAST_ACK 状态。
第四次挥手:
Client 收到 FIN 后,Client 进入 TIME_WAIT 状态,接着发送一个 ACK 给Server,确认序号为收到序号+1,
Server进入CLOSED状态,完成四次挥手.

LVS相关
LVS 负载均衡有哪些策略
LVS一共有三种工作模式:
- DR
- Tunnel
- NAT
谈谈你对LVS的理解
LVS是一个虚拟的服务器集群系统,在unix系统下实现负载均衡的功能;采用IP负载均衡技术和机遇内容请求分发技术来实现。
LVS采用三层结构,分别是:
-
第一层: 负载调度器
-
第二层: 服务池
-
第三层:共享存储
负载调度器(load balancer/ Director),是整个集群的总代理,它有两个网卡,一个网卡面对访问网站的客户端,一个网卡面对整个集群的内部。负责将客户端的请求发送到一组服务器上执行,而客户也认为服务是来自这台主的。举个生动的例子,集群是个公司,负载调度器就是在外接揽生意,将接揽到的生意分发给后台的真正干活的真正的主机们。当然需要将活按照一定的算法分发下去,让大家都公平的干活。
服务器池(server pool/ Realserver),是一组真正执行客户请求的服务器,可以当做WEB服务器。就 是上面例子中的小员工。
共享存储(shared storage),它为服务器池提供一个共享的存储区,这样很容易使得服务器池拥有相 同的内容,提供相同的服务。一个公司得有一个后台账目吧,这才能协调。不然客户把钱付给了A,而 换B接待客户,因为没有相同的账目。B说客户没付钱,那这样就不是客户体验度的问题了。
负载均衡的原理是什么
当客户端发起请求时,请求直接发给Director Server(调度器),这时会根据设定的调度算法,将请求按照算法的规定智能的分发到真正的后台服务器。以达到将压力均摊。
但是我们知道,http的连接时无状态的,假设这样一个场景,我登录某宝买东西,当我看上某款商品时,我将它加入购物车,但是我刷新了一下页面,这时由于负载均衡的原因,调度器又选了新的一台服务器为我提供服务,我刚才的购物车内容全都不见了,这样就会有十分差的用户体验。
所以就还需要一个存储共享,这样就保证了用户请求的数据是一样的
LVS由哪两部分组成的
LVS由ipvs和ipvsadm组成
-
ipvs(ip virtual server): 一段代码工作在内核空间,叫ipvs,是真正生效实现调度的代码。
-
ipvsadm: 另外一段是工作在用户空间,叫ipvsadm,负责为ipvs内核框架编写规则,定义谁是集群服务,而谁是后端真实的服务器(Real Server)
LVS相关的术语
-
DS: Director Server。指的是前端负载均衡器节点。
-
RS: Real Server。后端真实的工作服务器。
-
VIP: Virtual IP 向外部直接面向用户请求,作为用户请求的目标的IP地址。
-
DIP: Director Server IP,主要用于和内部主机通讯的IP地址。
-
RIP: Real Server IP,后端服务器的IP地址。
-
CIP: Client IP,访问客户端的IP地址。
LVS-NAT模式的原理
(1). 当用户请求到达 Director Server,此时请求的数据报文会先到内核空间的 PREROUTING 链。 此时报文的源IP为CIP,目标IP为VIP
(2). PREROUTING检查发现数据包的目标 IP 是本机,将数据包送至 INPUT 链
(3). IPVS比对数据包请求的服务是否为集群服务,若是,修改数据包的目标IP地址为后端服务器 IP, 然后将数据包发至POSTROUTING链。 此时报文的源IP为CIP,目标IP为RIP
(4). POSTROUTING链通过选路,将数据包发送给Real Server
(5). Real Server比对发现目标为自己的IP,开始构建响应报文发回给Director Server。 此时报文的源IP为RIP,目标IP为CIP
(6). Director Server在响应客户端前,此时会将源IP地址修改为自己的VIP地址,然后响应给客户端。 此时报文的源IP为VIP,目标IP为CIP
LVS-NAT模型的特性
-
RS 应该使用私有地址,RS 的网关必须指向 DIP
-
DIP 和 RIP 必须在同一个网段内
-
请求和响应报文都需要经过 Director Server,高负载场景中,Director Server 易成为性能瓶颈
-
支持端口映射
-
RS 可以使用任意操作系统
-
缺陷: 对 Director Server 压力会比较大,请求和响应都需经过 Director server
LVS-DR模式原理
(1) 当用户请求到达 Director Server,此时请求的数据报文会先到内核空间的 PREROUTING 链。 此时报文的源IP为 CIP,目标 IP 为 VIP
(2) PREROUTING 检查发现数据包的目标IP是本机,将数据包送至 INPUT 链
(3) IPVS比对数据包请求的服务是否为集群服务,若是,将请求报文中的源 MAC 地址修改为 DIP 的 MAC 地址,将目标 MAC 地址修改 RIP 的 MAC 地址,然后将数据包发至 POSTROUTING 链。 此时的源 IP 和目的 IP 均未修改,仅修改了源 MAC 地址为 DIP 的 MAC 地址,目标 MAC 地址为 RIP 的 MAC 地址
(4) 由于 DS 和 RS 在同一个网络中,所以是通过二层来传输。POSTROUTING 链检查目标 MAC 地址为 RIP 的 MAC 地址,那么此时数据包将会发至Real Server。
(5) RS 发现请求报文的 MAC 地址是自己的 MAC 地址,就接收此报文。处理完成之后,将响应报文通过 lo 接口传送给 eth0 网卡然后向外发出。 此时的源 IP 地址为 VIP,目标 IP 为 CIP
(6) 响应报文最终送达至客户端
LVS-DR模型的特性
特点:
-
保证前端路由将目标地址为 VIP 报文统统发给 Director Server,而不是 RS
-
RS 可以使用私有地址; 也可以是公网地址,如果使用公网地址,此时可以通过互联网对RIP进行直接访问
-
RS 跟 Director Server 必须在同一个物理网络中
-
所有的请求报文经由 Director Server,但响应报文不能经过 Director Server
-
不支持地址转换,也不支持端口映射
-
RS 可以是大多数常见的操作系统
-
RS 的网关绝不允许指向DIP(因为我们不允许他经过director)
-
RS 上的 lo 接口配置 VIP 的 IP 地址
缺陷:
- RS 和 DS 必须在同一机房中
LVS三种负载均衡模式的比较
三种负载均衡: nat,tunneling,dr
| 类目 | NAT | TUN | DR |
|---|---|---|---|
| 操作系统 | 任意 | 支持隧道 | 多数(支持non-arp) |
| 服务器网络 | 私有网络 | 局域网/广域网 | 局域网 |
| 服务器数目 | 10-20 | 100 | 大于100 |
| 服务器网关 | 负载均衡器 | 自己的路由 | 自己的路由 |
| 效率 | 一般 | 高 | 最高 |
LVS的负载调度算法
- 轮叫调度
- 加权轮叫调度
- 最小连接调度
- 加权最小连接调度
- 基于局部性能的最少连接
- 带复制的基于局部性能最小连接
- 目标地址散列调度
- 源地址散列调度
LVS与nginx的区别
lvs的优势(互联网老辛):
- 抗负载能力强,因为 lvs 工作方式的逻辑是非常简单的,而且工作在网络的第 4 层,仅作请求分发用,没有流量,所以在效率上基本不需要太过考虑。lvs 一般很少出现故障,即使出现故障一般也是其他地方(如内存、CPU等)出现问题导致 lvs 出现问题。
- 配置性低,这通常是一大劣势同时也是一大优势,因为没有太多的可配置的选项,所以除了增减服务器,并不需要经常去触碰它,大大减少了人为出错的几率。
- 工作稳定,因为其本身抗负载能力很强,所以稳定性高也是顺理成章的事,另外各种 lvs 都有完整的双机热备方案,所以一点不用担心均衡器本身会出什么问题,节点出现故障的话,lvs 会自动判别,所以系统整体是非常稳定的。
- 无流量,lvs 仅仅分发请求,而流量并不从它本身出去,所以可以利用它这点来做一些线路分流之用。没有流量同时也保住了均衡器的 IO 性能不会受到大流量的影响。
- lvs 基本上能支持所有应用,因为 lvs 工作在第4层,所以它可以对几乎所有应用做负载均衡,包括 http、数据库、聊天室等。
nginx与LVS的对比:
- nginx工作在网络的第7层,所以它可以针对 http 应用本身来做分流策略,比如针对域名、目录结构等,相比之下 lvs 并不具备这样的功能,所以 nginx 单凭这点可以利用的场合就远多于 lvs 了;但 nginx 有用的这些功能使其可调整度要高于lvs,所以经常要去触碰,由 lvs 的第2条优点来看,触碰多了,人为出现问题的几率也就会大。
- nginx对网络的依赖较小,理论上只要 ping 得通,网页访问正常,nginx就能连得通,nginx 同时还能区分内外网,如果是同时拥有内外网的节点,就相当于单机拥有了备份线路; lvs 就比较依赖于网络环境,目前来看服务器在同一网段内并且 lvs 使用 direct 方式分流,效果较能得到保证。另外注意,lvs 需要向托管商至少申请多于一个 ip 来做visual ip。
- nginx 安装和配置比较简单,测试起来也很方便,因为它基本能把错误用日志打印出来。lvs 的安装和配置、测试就要花比较长的时间,因为同上所述,lvs 对网络依赖性比较大,很多时候不能配置成功都是因为网络问题而不是配置问题,出了问题要解决也相应的会麻烦的多。
- nginx也同样能承受很高负载且稳定,但负载度和稳定度差 lvs 还有几个等级:nginx处理所有流量所以受限于机器 IO 和配置;本身的bug也还是难以避免的;nginx没有现成的双机热备方案,所以跑在单机上还是风险比较大,单机上的事情全都很难说。
- nginx 可以检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点。目前 lvs 中 ldirectd 也能支持针对服务器内部的情况来监控,但 lvs 的原理使其不能重发请求。比如用户正在上传一个文件,而处理该上传的节点刚好在上传过程中出现故障,nginx 会把上传切到另一台服务器重新处理,而 lvs 就直接断掉了。
两者配合使用:
nginx 用来做 http 的反向代理,能够 upsteam 实现 http 请求的多种方式的均衡转发。由于采用的是异步转发可以做到如果一个服务器请求失败,立即切换到其他服务器,直到请求成功或者最后一台服务器失败为止。这可以最大程度的提高系统的请求成功率。
lvs采用的是同步请求转发的策略。这里说一下同步转发和异步转发的区别。同步转发是在 lvs 服务器接收到请求之后,立即 redirect 到一个后端服务器,由客户端直接和后端服务器建立连接。异步转发是 nginx 在保持客户端连接的同时,发起一个相同内容的新请求到后端,等后端返回结果后,由 nginx 返回给客户端。
进一步来说:当做为负载均衡服务器的 nginx 和 lvs 处理相同的请求时,所有的请求和响应流量都会经过 nginx; 但是使用 lvs 时,仅请求流量经过 lvs 的网络,响应流量由后端服务器的网络返回。
也就是,当作为后端的服务器规模庞大时,nginx的网络带宽就成了一个巨大的瓶颈。
但是仅仅使用 lvs 作为负载均衡的话,一旦后端接受到请求的服务器出了问题,那么这次请求就失败了。 但是如果在lvs的后端在添加一层nginx(多个),每个nginx后端再有几台应用服务器,那么结合两者的优势,既能避免单nginx的流量集中瓶颈,又能避免单lvs时一锤子买卖的问题。
负载均衡的作用有哪些
1、转发功能
按照一定的算法【权重、轮询】,将客户端请求转发到不同应用服务器上,减轻单个服务器压力,提高系统并发量。
2、故障移除
通过心跳检测的方式,判断应用服务器当前是否可以正常工作,如果服务器期宕掉,自动将请求发送到其他应用服务器。
3、恢复添加
如检测到发生故障的应用服务器恢复工作,自动将其添加到处理用户请求队伍中。
Nginx与Apache相关
常见问题
nginx负载均衡实现的策略
-
轮询(默认)
-
权重
-
ip_hash
-
fair(第三方插件)
-
url_hash(第三方插件)
nginx做负载均衡用到的模块
- upstream 定义负载节点池。
- location 模块进行URL匹配。
- proxy模块发送请求给upstream定义的节点池。
负载均衡有哪些实现方式
-
硬件负载
-
HTTP重定向负载均衡
-
DNS负载均衡
-
反向代理负载均衡
-
IP层负载均衡
-
数据链路层负载均衡
web服务有哪些
- apache
- nginx
- IIS
- tomcat
- lighttpd
- weblogic
为什么要用nginx
- 跨平台、配置简单,非阻塞、高并发连接: 处理2-3万并发连接数,官方监测能支持5万并发
- 内存消耗小: 开启10个nginx才占150M内存,nginx处理静态文件好,耗费内存少
- 内置的健康检查功能: 如果有一个服务器宕机,会做一个健康检查,再发送的请求就不会发送到宕机的服务器了。重新将请求提交到其他的节点上。
- 节省宽带: 支持GZIP压缩,可以添加浏览器本地缓存
- 稳定性高: 宕机的概率非常小
- 接收用户请求是异步的
nginx的性能为什么比apache高
nginx采用的是epoll模型和kqueue网络模型,而apache采用的是select模型
举一个例子来解释两种模型的区别:
菜鸟驿站放着很多快件,以前去拿快件都是短信通知你有快件,然后你去了之后,负责菜鸟驿站的人在一堆快递里帮你找,直到找到为止。
但现在菜鸟驿站的方式变了,他会发你一个地址,比如 3-3-5009. 这个就是第三个货架的第三排,从做往右第九个。
如果有几百个人同时去找快递,这两种方式哪个更有效率,不言而喻。
之前还看到这个例子也比较形象:
> 假设你在大学读书,住的宿舍楼有很多间房间,你的朋友要来找你。
select版宿管大妈就会带着你的朋友挨个房间去找,直到找到你为止。
而epoll版宿管大妈会先记下每位同学的房间号,
你的朋友来时,只需告诉你的朋友你住在哪个房间即可,不用亲自带着你的朋友满大楼找人。
如果来了10000个人,都要找自己住这栋楼的同学时,select版和epoll版宿管大妈,谁的效率更高,不言自明。
同理,在高并发服务器中,轮询I/O是最耗时间的操作之一,select和epoll的性能谁的性能更高,同样十分明了
select 采用的是轮询的方式来处理请求,轮询的次数越多,耗时也就越多。
nginx和apache的区别
Nginx
-
轻量级,采用 C 进行编写,同样的 web 服务,会占用更少的内存及资源
-
抗并发,nginx 以 epoll and kqueue 作为开发模型,处理请求是异步非阻塞的,负载能力比 apache 高很多,而 apache 则是阻塞型的。在高并发下 nginx 能保持低资源低消耗高性能 ,而 apache 在 PHP 处理慢或者前端压力很大的情况下,很容易出现进程数飙升,从而拒绝服务的现象。
-
nginx 处理静态文件好,静态处理性能比 apache 高三倍以上
-
nginx 的设计高度模块化,编写模块相对简单
-
nginx 配置简洁,正则配置让很多事情变得简单,而且改完配置能使用 -t 测试配置有没有问题, apache 配置复杂 ,重启的时候发现配置出错了,会很崩溃
-
nginx 作为负载均衡服务器,支持 7 层负载均衡
七层负载可以有效的防止ddos攻击 -
nginx本身就是一个反向代理服务器,也可以左右邮件代理服务器来使用
Apache
- apache 的 rewrite 比 nginx 强大,在 rewrite 频繁的情况下,用 apache
- apache 发展到现在,模块超多,基本想到的都可以找到
- apache 更为成熟,少 bug ,nginx 的 bug 相对较多
- apache 对 PHP 支持比较简单,nginx 需要配合其他后端用
- apache 在处理动态请求有优势,nginx 在这方面是鸡肋,一般动态请求要 apache 去做,nginx 适合静态和反向。
- apache 仍然是目前的主流,拥有丰富的特性,成熟的技术和开发社区
- 两者最核心的区别在于 apache 是同步多进程模型,一个连接对应一个进程,而 nginx 是异步的,多个连接(万级别)可以对应一个进程。
- 需要稳定用 apache,需要高性能用 nginx
反向代理与正向代理以及区别
正向代理:
所谓的正向代理就是: 需要在用户端去配置的。配置完再去访问具体的服务,这叫正向代理
正向代理,其实是"代理服务器"代理了"客户端",去和"目标服务器"进行交互。
正向代理的用途:
-
提高访问速度
-
隐藏客户真实IP
反向代理:
反向代理是在服务端的,不需要访问用户关心。用户访问服务器A, A服务器是代理服务器,将用户服务
再转发到服务器B.这就是反向代理
反向代理的作用:
-
缓存,将服务器的响应缓存在自己的内存中,减少服务器的压力。
-
负载均衡,将用户请求分配给多个服务器。
-
访问控制
nginx如何处理http请求
四个步骤:
- 读取解析请求行;
- 读取解析请求头;
- 开始最重要的部分,即多阶段处理;
nginx 把请求处理划分成了11个阶段,也就是说当 nginx 读取了请求行和请求头之后,将请求封装了结构体ngx_http_request_t,然后每个阶段的 handler 都会根据这个 ngx_http_request_t,对请求进行处理,例如重写uri,权限控制,路径查找,生成内容以及记录日志等等;
最后将结果返回给客户端。
也可以这么回答:
- 首先,Nginx 在启动时,会解析配置文件,得到需要监听的端口与 IP 地址,然后在 Nginx 的 Master 进程里面先初始化好这个监控的Socket(创建 Socket,设置 addr、reuse 等选项,绑定到指定的 ip 地址端口,再 listen 监听)。
- 然后,再 fork(一个现有进程可以调用 fork 函数创建一个新进程。由 fork 创建的新进程被称为子进程 )出多个子进程出来。
- 之后,子进程会竞争 accept 新的连接。此时,客户端就可以向 nginx 发起连接了。当客户端与 nginx进行三次握手,与 nginx 建立好一个连接后。此时,某一个子进程会 accept 成功,得到这个建立好的连接的 Socket ,
- 然后创建 nginx 对连接的封装,即 ngx_connection_t 结构体。
- 接着,设置读写事件处理函数,并添加读写事件来与客户端进行数据的交换。
- 最后,Nginx 或客户端来主动关掉连接,到此,一个连接就寿终正寝了。
nginx虚拟主机有哪些
- 基于域名的虚拟主机
- 基于端口的虚拟主机
- 基于 IP 的虚拟主机
apache中的Worker和Prefork的区别
它们都是MPM, Worker 和 prefork 有它们各自在Apache上的运行机制. 它们完全依赖于你想要以哪一
种模式启动你的Apache.
- Worker 和 MPM 基本的区别在于它们产生子进程的处理过程, 在 Prefork MPM 中, 一个主 httpd 进行被启动,这个主进程会管理所有其它子进程为客户端请求提供服务. 而在worker MPM中一个httpd进程被激活,则会使用不同的线程来为客户端请求提供服务.
- Prefork MPM 使用多个子进程,每一个进程带有一个线程; 而 worker MPM 使用多个子进程,每一个进程带有多个线程.
- Prefork MPM中的连接处理, 每一个进程一次处理一个连接而在Worker mpm中每一个线程一次处理一个连接.
- 内存占用 Prefork MPM 占用庞大的内存, 而Worker占用更小的内存
nginx的优化
- gzip压缩优化
- expires缓存
- 网络IO事件模型优化
- 隐藏软件名称和版本号
- 防盗链优化
- 禁止恶意域名解析
- 禁止通过IP地址访问网站
- HTTP请求方法优化
- 防DOS攻击单IP并发连接的控制,与连接速率控制
- 严格设置web站点目录的权限
- 将nginx进程以及站点运行于监牢模式
- 通过robot协议以及HTTP_USER_AGENT防爬虫优化
- 配置错误页面根据错误码指定网页反馈给用户
- nginx日志相关优化访问日志切割轮询,不记录指定元素日志、最小化日志目录权限
- 限制上传到资源目录的程序被访问,防止木马入侵系统破坏文件
- FastCGI参数buffer和cache配置文件的优化
- php.ini和php-fpm.conf配置文件的优化
- 有关web服务的Linux内核方面深度优化(网络连接、IO、内存等)
- nginx加密传输优化(SSL)
- web服务器磁盘挂载及网络文件系统的优化
- 使用nginx cache
nginx的session不同步怎么办
我们可以采用 ip_hash 指令解决这个问题,如果客户已经访问了某个服务器,当用户再次访问时,会将该请求通过哈希算法,自动定位到该服务器。即每个访客固定访问一个后端服务器,可以解决 session 的问题。
其他办法: 那就是用 spring_session+redis,把session放到缓存中实现 session 共享。
Tomcat相关
Tomcat作为web的优缺点
缺点:
tomcat 只能用做 java 服务器,处理静态请求的能力不如 nginx 和 apache,高并发能力有限
优点:
动态解析容器,处理动态请求,是编译 JSP/Servlet 的容器,轻量级
tomcat的三个端口及作用
- 8005: 关闭Tomcat通信接口
- 8009: 与其他httpd服务器通信接口,用于http服务器的集合
- 8080: 建立httpd连接用,如浏览器访问
Tomcat缺省端口是多少,怎么修改
-
找到Tomcat目录下的conf文件夹
-
进入conf文件夹里面找到server.xml文件
-
打开server.xml文件
-
在server.xml文件里面找到下列信息
-
把Connector标签的8080端口改成你想要的端口
Tomcat的工作模式是什么
Tomcat作为servlet容器,有三种工作模式:
- 独立的servlet容器,servlet容器是web服务器的一部分;
- 进程内的servlet容器,servlet容器是作为web服务器的插件和java容器的实现,web服务器插件在内部地址空间打开一个jvm使得java容器在内部得以运行。反应速度快但伸缩性不足;
- 进程外的servlet容器,servlet容器运行于web服务器之外的地址空间,并作为web服务器的插件和 java 容器实现的结合。反应时间不如进程内但伸缩性和稳定性比进程内优;
进入Tomcat的请求可以根据Tomcat的工作模式分为如下两类:
-
Tomcat作为应用程序服务器:请求来自于前端的web服务器,这可能是Apache, IIS, Nginx等;
-
Tomcat作为独立服务器:请求来自于web浏览器;
Web请求在Tomcat请求中的请求流程
- 浏览器输入URL地址;
- 查询本机hosts文件寻找IP;
- 查询DNS服务器寻找IP;
- 向该IP发送Http请求;
- Tomcat容器解析主机名;
- Tomcat容器解析Web应用;
- Tomcat容器解析资源名称;
- Tomcat容器获取资源;
- Tomcat响应浏览器。
Tomcat优化
- Tomcat的运行模式 : bio,nio, apr
一般使用nio模式,bio效率低,apr对系统配置有一些更高的要求 - 关键配置
maxThreads: 最大线程数,默认是200,
minspareThread: 最小活跃线程数,默认是25
maxqueuesize: 最大等待队列个数 - 影响性能的配置:
compression 设置成on,开启压缩
禁用AJP连接器: 用nginx+Tomcat的架构,用不到AJP
enableLookups=false 关闭反查域名,直接返回ip,提高效率
disableUploadTimeou=false 上传是否使用超时机制
acceptCount=300 , 当前所有可以使用的处理请求都被使用时,传入请求连接最大队列长队,超过个数不予处理,默认是100
keepalive timeout=120000 场链接保持时间 - 优化jvm
/bin/catalina.sh
-server: jvm的server工作模式,对应的有client工作模式。使用“java -version”可以查看当前工作 模式
-Xms1024m: 初始Heap大小,使用的最小内存
-Xmx1024m: Java heap 最大值,使用的最大内存。经验: 设置 Xms 大小等于 Xmx 大小
-XX:NewSize=512m:表示新生代初始内存的大小,应该小于 -Xms 的值
-XX:MaxNewSize=1024M:表示新生代可被分配的内存的最大上限,应该小于 -Xmx 的值
-XX:PermSize=1024m:设定内存的永久保存区域,内存的永久保存区域,VM 存放 Class 和 Meta 信息,JVM在运行期间不会清除该区域
-XX:MaxPermSize=1024m:设定最大内存的永久保存区域。经验: 设置PermSize大小等于 MaxPermSize大小
-XX:+DisableExplicitGC:自动将System.gc() 调用转换成一个空操作,即应用中调用System.gc() 会变成一个空操作,避免程序员在代码里进行System.gc()这种危险操作。System.gc() 除非是到了万不得也的情况下使用,都应该交给 JVM。
fastcgi 和cgi的区别
cgi:
web 服务器会根据请求的内容,然后会 fork 一个新进程来运行外部 c 程序(或 perl 脚本…), 这个进程会把处理完的数据返回给 web 服务器,最后 web 服务器把内容发送给用户,刚才 fork 的进程也随之退出。
如果下次用户还请求该动态脚本,那么 web 服务器又再次 fork 一个新进程,周而复始的进行
fastcgi:
web 服务器收到一个请求时,他不会重新 fork 一个进程(因为这个进程在 web 服务器启动时就开启了,而且不会退出),web 服务器直接把内容传递给这个进程(进程间通信,但 fastcgi 使用了别的方式,tcp 方式通信),这个进程收到请求后进行处理,把结果返回给 web 服务器,最后自己接着等待下一个请求的到来,而不是退出。
Keepalived相关
keepalived 是什么
广义上讲是高可用,狭义上讲是主机的冗余和管理
Keepalived起初是为 LVS 设计的,专门用来监控集群系统中各个服务节点的状态,它根据 TCP/IP 参考模型的第三、第四层、第五层交换机制检测每个服务节点的状态,如果某个服务器节点出现异常,或者工作出现故障,Keepalived 将检测到,并将出现的故障的服务器节点从集群系统中剔除,这些工作全部是自动完成的,不需要人工干涉,需要人工完成的只是修复出现故障的服务节点。
后来 Keepalived 又加入了 VRRP 的功能,VRRP(VritrualRouterRedundancyProtocol,虚拟路由冗余协议)出现的目的是解决静态路由出现的单点故障问题,通过 VRRP 可以实现网络不间断稳定运行,因此 Keepalvied 一方面具有服务器状态检测和故障隔离功能,另外一方面也有 HAcluster 功能。
所以 keepalived 的核心功能就是健康检查和失败切换。 所谓的健康检查,就是采用 tcp 三次握手,icmp 请求,http 请求,udp echo 请求等方式对负载均衡器后面的实际的服务器(通常是承载真实业务的服务器)进行保活;
而失败切换主要是应用于配置了主备模式的负载均衡器,利用 VRRP 维持主备负载均衡器的心跳,当主负载均衡器出现问题时,由备负载均衡器承载对应的业务,从而在最大限度上减少流量损失,并提供服务的稳定性
如何理解VRRP协议
为什么使用 VRRP ? 主机之间的通信都是通过配置静态路由或者(默认网关)来完成的,而主机之间的路由器一旦发生故障,通信就会失效,因此这种通信模式当中,路由器就成了一个单点瓶颈,为了解决这个问题,就引入了 VRRP 协议。
VRRP 协议是一种容错的主备模式的协议,保证当主机的下一跳路由出现故障时,由另一台路由器来代替出现故障的路由器进行工作,通过 VRRP 可以在网络发生故障时透明的进行设备切换而不影响主机之间的数据通信。
VRRP 的三种状态:
VRRP路由器在运行过程中有三种状态:
- Initialize状态: 系统启动后就进入Initialize,此状态下路由器不对 VRRP 报文做任何处理;
- Master状态;
- Backup状态;
- 一般主路由器处于Master状态,备份路由器处于Backup状态。
keepalived的工作原理
keepalived 采用是模块化设计,不同模块实现不同的功能。
keepalived 主要有三个模块,分别是 core、check 和 vrrp。
core: 是 keepalived 的核心,负责主进程的启动和维护,全局配置文件的加载解析等
check: 负责 healthchecker(健康检查),包括了各种健康检查方式,以及对应的配置的解析包括LVS的配置解析;可基于脚本检查对IPVS后端服务器健康状况进行检查
vrrp: VRRPD子进程,VRRPD 子进程就是来实现 VRRP 协议的
Keepalived 高可用对之间是通过 VRRP 进行通信的, VRRP是通过竞选机制来确定主备的,主的优先级高于备,因此,工作时主会优先获得所有的资源,备节点处于等待状态,当主宕机的时候,备节点就会接管主节点的资源,然后顶替主节点对外提供服务
在 Keepalived 服务对之间,只有作为主的服务器会一直发送 VRRP 广播包,告诉备它还活着,此时备不会抢占主,当主不可用时,即备监听不到主发送的广播包时,就会启动相关服务接管资源,保证业务的连续性.接管速度最快
出现脑裂的原因
什么是脑裂?
-
在高可用(HA)系统中,当联系2个节点的“心跳线”断开时,本来为一整体、动作协调的HA系统, 就分裂成为2个独立的个体。
-
由于相互失去了联系,都以为是对方出了故障。两个节点上的HA软件像“裂脑人”一样,争抢“共享 资源”、争起“应用服务”,就会发生严重后果。共享资源被瓜分、两边“服务”都起不来了;或者两边 “服务”都起来了,但同时读写“共享存储”,导致数据损坏
都有哪些原因导致脑裂?
-
高可用服务器对之间心跳线链路发生故障,导致无法正常通信。
-
因心跳线坏了(包括断了,老化)。
-
因网卡及相关驱动坏了,ip配置及冲突问题(网卡直连)
-
因心跳线间连接的设备故障(网卡及交换机)
-
因仲裁的机器出问题(采用仲裁的方案)
-
高可用服务器上开启了 iptables 防火墙阻挡了心跳消息传输。
-
高可用服务器上心跳网卡地址等信息配置不正确,导致发送心跳失败
-
其他服务配置不当等原因,如心跳方式不同,心跳广插冲突、软件Bug等。
如何解决keepalived脑裂问题
在实际生产环境中,我们从以下方面防止脑裂:
- 同时使用串行电缆和以太网电缆连接、同时使用两条心跳线路,这样一条线路断了,另外一条还是好的,依然能传送心跳消息
- 当检查脑裂时强行关闭一个心跳节点(这个功能需要特殊设备支持,如stonith、fence)相当于备节点接收不到心跳消息,通过单独的线路发送关机命令关闭主节点的电源
- 做好对脑裂的监控报警
解决常见方案:
- 如果开启防火墙,一定要让心跳消息通过,一般通过允许IP段的形式解决
- 可以拉一条以太网网线或者串口线作为主被节点心跳线路的冗余
- 开发检测程序通过监控软件检测脑裂
Linux系统
常见日志文件与各自的用途
| 路径 | 用途 |
|---|---|
| /var/log/messages | 内核及公共消息日志 |
| /var/log/cron | 计划任务日志 |
| /var/log/dmesg | 系统引导日志 |
| /var/log/maillog | 邮件系统日志 |
| /var/log/secure | 记录与访问限制相关日志 |
| /etc/logrotate.d | 此目录下是各个服务的日志轮询配置文件 |
Linux系统的运行级别
- 0=>关机
- 1=>单用户
- 2=>多用户有网络服务
- 3=>多用户无网络服务
- 4=>保留
- 5=>图形界面
- 6=>重启
Linux开机过程
1.开机BIOS自检
2.MBR引导
3.grub引导菜单
4.加载内核kernel
5.启动init进程
6.读取inittab文件,执行rc.sysinit,rc等脚本
7.启动mingetty,进入系统登陆界面
详情请参考链接:Linux开机过程
网络协议
STP协议
主要用途:
-
STP通过阻塞冗余链路,来消除桥接网络中可能存在的路径回环;
-
当前活动路径发生故障时,STP激活冗余链路恢复网络连通性。
为什么要用STP:
- 原因:交换网络存在环路时引起:广播环路(广播风暴);桥表损坏。
介绍一下ACL和NAT?
ACL:
-
访问控制列表(ACL)是应用在路由器接口的指令列表(规则),用来告诉路由器哪些数据包可以接收转发,哪些数据包需要拒绝;
-
ACL的工作原理 :读取第三层及第四层包头中的信息,根据预先定义好的规则对包进行过滤;
-
使用ACL实现网络控制:实现访问控制列表的核心技术是包过滤;
-
ACL的两种基本类型(标准访问控制列表;扩展访问控制列表)
NAT:
- 改变IP包头使目的地址,源地址或两个地址在包头中被不同地址替换。
NAT有几种方式?
-
静态NAT
-
动态NAT
-
PAT
RIP协议
RIP是Routing Information Protocol(路由信息协议)的简称,它是一种较为简单的内部网关协议(Interior Gateway Protocol)。RIP是一种基于距离矢量(Distance-Vector)算法的协议,它使用跳数(Hop Count)作为度量来衡量到达目的网络的距离。RIP通过UDP报文进行路由信息的交换,使用的端口号为520。
RIP包括RIP-1和RIP-2两个版本,RIP-2对RIP-1进行了扩充,使其更具有优势。
RIP是一种基于距离矢量(Distance-Vector)算法的协议,它使用跳数(Hop Count)作为度量值来衡量到达目的地址的距离。在RIP网络中,缺省情况下,设备到与它直接相连网络的跳数为0,通过一个设备可达的网络的跳数为1,其余依此类推。也就是说,度量值等于从本网络到达目的网络间的设备数量。为限制收敛时间,RIP规定度量值取0~15之间的整数,大于或等于16的跳数被定义为无穷大,即目的网络或主机不可达。由于这个限制,使得RIP不可能在大型网络中得到应用。
静态路由的缺陷
- 配置量大
- 只能适用于小型网络中
- 维护麻烦,无法自动适应网络的拓扑变化
动态路由协议:可以根据网络拓扑的变化根据协议来选择路径
动态路由协议分为:
- 内部网关协议:运行在同一个AS号内的路由协议。如:RIP、OSPF、EIGRP(思科设备专用)
- 外部网关协议:运行在不同AS号之间的路由协议。如:BGP
内部网关协议分为:
- 距离矢量协议(RIP、EIGRP)
- 链路状态协议(OSPF)
RIP协议:属于内部网关协议,是一个距离矢量协议,工作在UDP的520端口
有类路由协议:在发送路由更新的时候是不会携带子网掩码的(已经被淘汰)
无类路由协议:在发送路由更新的时候携带子网掩码。
RIP的两个版本
RIPv1:是一个有类路由协议,是通过广播(255.255.255.255)的形式来发送路由更新的。
RIPv2:是一个无类路由协议,是通过组播(224.0.0.9)的形式来发送路由更新的。
RIP的选路标准:通过跳数来衡量路径,RIP认为跳数越少,路径越优先。同时这也是它的缺陷,因为RIP有可能选择了一条次优路径。
RIPv1的特点:
- 有类别路由协议。
- 广播更新。
- 基于UDP,端口号520
RIP是一个基于UDP的路由协议,并且RIPv1的数据包不能超过512字节(RIP报文头部占用4个字节,而每个路由条目占用20个八位组字节。因此,RIP消息最大为4+(25*20)=504个字节,再加上8个字节的UDP头部,所以RIP数据报的大小(不含IP包的头部)最大可达512个字节。)。RIPv1的协议报文中没有携带掩码信息,所以RIPv1在发送和接收路由更新时会根据主类网段掩码和接口地址掩码来处理路由条目。因此RIPv1无法支持路由聚合,也不支持不连续子网。RIPv1的协议报文中没有验证字段,所以RIPv1也不支持验证。
RIPv2特点:
- 无类别路由协议。
- 组播更新,组播地址224.0.0.9
- 基于UDP,端口号520.
- 支持外部Tag。
- 支持路由聚合和CIDR
- 支持指定下一跳。
- 支持认证。
OSPF协议
路由协议OSPF全称为Open Shortest Path First,也就开放的最短路径优先协议,因为OSPF是由IETF开发的,它的使用不受任何厂商限制,所有人都可以使用,所以称为开放的,而最短路径优先(SPF)只是OSPF的核心思想,其使用的算法是Dijkstra算法,最短路径优先并没有太多特殊的含义,并没有任何一个路由协议是最长路径优先的,所有协议,都会选最短的。
- OSPF的流量使用IP协议号89。
- OSPF工作在单个AS,是个绝对的内部网关路由协议(Interior Gateway Protocol,即IGP)。
- OSPF对网络没有跳数限制,支持 Classless Interdomain Routing (CIDR)和Variable-Length Subnet Masks (VLSMs),没有自动汇总功能,但可以手工在任意比特位汇总,并且手工汇总没有任何条件限制,可以汇总到任意掩码长度。
- OSPF支持认证,并且支持明文和MD5认证;OSPF不可以通过Offset list来改变路由的metric。
- OSPF并不会周期性更新路由表,而采用增量更新,即只在路由有变化时,才会发送更新,并且只发送有变化的路由信息;事实上,OSPF是间接设置了周期性更新路由的规则,因为所有路由都是有刷新时间的,当达到刷新时间阀值时,该路由就会产生一次更新,默认时间为1800秒,即30分钟,所以OSPF路由的定期更新周期默认为30分钟。
- OSPF所有路由的管理距离(Ddministrative Distance)为110,OSPF只支持等价负载均衡。
- 距离矢量路由协议的根本特征就是自己的路由表是完全从其它路由器学来的,并且将收到的路由条目一丝不变地放进自己的路由表,运行距离矢量路由协议的路由器之间交换的是路由表,距离矢量路由协议是没有大脑的,路由表从来不会自己计算,总是把别人的路由表拿来就用;而OSPF完全抛弃了这种不可靠的算法,OSPF是典型的链路状态路由协议,路由器之间交换的并不是路由表,而是链路状态,OSPF通过获得网络中所有的链路状态信息,从而计算出到达每个目标精确的网络路径。
Kubernetes
常见面试题
参考链接: https://www.zhihu.com/question/379143600
1、简述etcd及其特点
etcd是CoreOS团队发起的开源项目,是一个管理配置信息和服务发现(service discovery)的项目,它的目标是构建一个高可用的分布式键值(key-value)数据库,基于Go语言实现。
特点:
- 简单:支持REST风格的HTTP+JSON API
- 安全:支持HTTPS方式的访问
- 快速:支持并发1k/s的写操作
- 可靠:支持分布式结构,基于Raft的一致性算法,Raft是一套通过选举主节点来实现分布式系统一致性的算法。
2、简述etcd适应的场景
etcd基于其优秀的特点,可广泛的应用于以下场景:
- 服务发现(Service Discovery):服务发现主要解决在同一个分布式集群中的进程或服务,要如何才能找到对方并建立连接。本质上来说,服务发现就是想要了解集群中是否有进程在监听UDP或TCP端口,并且通过名字就可以查找和连接。
- 消息发布与订阅:在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅。即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者。通过这种方式可以做到分布式系统配置的集中式管理与动态更新。应用中用到的一些配置信息放到etcd上进行集中管理。
- 负载均衡:在分布式系统中,为了保证服务的高可用以及数据的一致性,通常都会把数据和服务部署多份,以此达到对等服务,即使其中的某一个服务失效了,也不影响使用。etcd本身分布式架构存储的信息访问支持负载均衡。etcd集群化以后,每个etcd的核心节点都可以处理用户的请求。所以,把数据量小但是访问频繁的消息数据直接存储到etcd中也可以实现负载均衡的效果。
- 分布式通知与协调:与消息发布和订阅类似,都用到了etcd中的Watcher机制,通过注册与异步通知机制,实现分布式环境下不同系统之间的通知与协调,从而对数据变更做到实时处理。
- 分布式锁:因为etcd使用Raft算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致的,所以很容易实现分布式锁。锁服务有两种使用方式,一是保持独占,二是控制时序。
- 集群监控与Leader竞选:通过etcd来进行监控实现起来非常简单并且实时性强。
3、简述什么是Kubernetes
Kubernetes是一个全新的基于容器技术的分布式系统支撑平台。是Google开源的容器集群管理系统(谷歌内部:Borg)。在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模容器集群管理的便捷性。并且具有完备的集群管理能力,多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和发现机制、內建智能负载均衡器、强大的故障发现和自我修复能力、服务滚动升级和在线扩容能力、可扩展的资源自动调度机制以及多粒度的资源配额管理能力。
4、简述Kubernetes和Docker的关系
Docker提供容器的生命周期管理和Docker镜像构建运行时容器。它的主要优点是将将软件/应用程序运行所需的设置和依赖项打包到一个容器中,从而实现了可移植性等优点。
Kubernetes用于关联和编排在多个主机上运行的容器。
5、简述Minikube、Kubectl、Kubelet分别是什么
Minikube是一种可以在本地轻松运行一个单节点Kubernetes群集的工具。
Kubectl是一个命令行工具,可以使用该工具控制Kubernetes集群管理器,如检查群集资源,创建、删除和更新组件,查看应用程序。
Kubelet是一个代理服务,它在每个节点上运行,并使从服务器与主服务器通信。
6、简述Kubernetes常见的部署方式
常见的Kubernetes部署方式有:
- kubeadm,也是推荐的一种部署方式;
- 二进制;
- minikube,在本地轻松运行一个单节点Kubernetes群集的工具。
7、简述Kubernetes如何实现集群管理
在集群管理方面,Kubernetes将集群中的机器划分为一个Master节点和一群工作节点Node。其中,在Master节点运行着集群管理相关的一组进程kube-apiserver、kube-controller-manager和kube-scheduler,这些进程实现了整个集群的资源管理、Pod调度、弹性伸缩、安全控制、系统监控和纠错等管理能力,并且都是全自动完成的。
8、简述Kubernetes的优势、适应场景及其特点
Kubernetes作为一个完备的分布式系统支撑平台,其主要优势:
- 容器编排
- 轻量级
- 开源
- 弹性伸缩
- 负载均衡
Kubernetes常见场景:
- 快速部署应用
- 快速扩展应用
- 无缝对接新的应用功能
- 节省资源,优化硬件资源的使用
Kubernetes相关特点:
- 可移植:支持公有云、私有云、混合云、多重云(multi-cloud)。
- 可扩展: 模块化,、插件化、可挂载、可组合。
- 自动化: 自动部署、自动重启、自动复制、自动伸缩/扩展。
9、简述Kubernetes的缺点或当前的不足之处
Kubernetes当前存在的缺点(不足)如下:
- 安装过程和配置相对困难复杂。
- 管理服务相对繁琐。
- 运行和编译需要很多时间。
- 它比其他替代品更昂贵。
- 对于简单的应用程序来说,可能不需要涉及Kubernetes即可满足。
10、简述Kubernetes相关基础概念
- Master:Kubernetes集群的管理节点,负责管理集群,提供集群的资源数据访问入口。拥有etcd存储服务(可选),运行Api Server进程,Controller Manager服务进程及Scheduler服务进程。
- Node(worker):Node(worker)是Kubernetes集群架构中运行Pod的服务节点,是Kubernetes集群操作的单元,用来承载被分配Pod的运行,是Pod运行的宿主机。运行Docker Eninge服务,守护进程kunelet及负载均衡器kube-proxy。
- Pod:运行于Node节点上,若干相关容器的组合。Pod内包含的容器运行在同一宿主机上,使用相同的网络命名空间、IP地址和端口,能够通过localhost进行通信。Pod是Kubernetes进行创建、调度和管理的最小单位,它提供了比容器更高层次的抽象,使得部署和管理更加灵活。一个Pod可以包含一个容器或者多个相关容器。
- Label:Kubernetes中的Label实质是一系列的Key/Value键值对,其中key与value可自定义。Label可以附加到各种资源对象上,如Node、Pod、Service、RC等。一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源对象上去。Kubernetes通过Label Selector(标签选择器)查询和筛选资源对象。
- Replication Controller:Replication Controller用来管理Pod的副本,保证集群中存在指定数量的Pod副本。集群中副本的数量大于指定数量,则会停止指定数量之外的多余容器数量。反之,则会启动少于指定数量个数的容器,保证数量不变。Replication Controller是实现弹性伸缩、动态扩容和滚动升级的核心。
- Deployment:Deployment在内部使用了RS来实现目的,Deployment相当于RC的一次升级,其最大的特色为可以随时获知当前Pod的部署进度。
- HPA(Horizontal Pod Autoscaler):Pod的横向自动扩容,也是Kubernetes的一种资源,通过追踪分析RC控制的所有Pod目标的负载变化情况,来确定是否需要针对性的调整Pod副本数量。
- Service:Service定义了Pod的逻辑集合和访问该集合的策略,是真实服务的抽象。Service提供了一个统一的服务访问入口以及服务代理和发现机制,关联多个相同Label的Pod,用户不需要了解后台Pod是如何运行。
- Volume:Volume是Pod中能够被多个容器访问的共享目录,Kubernetes中的Volume是定义在Pod上,可以被一个或多个Pod中的容器挂载到某个目录下。
- Namespace:Namespace用于实现多租户的资源隔离,可将集群内部的资源对象分配到不同的Namespace中,形成逻辑上的不同项目、小组或用户组,便于不同的Namespace在共享使用整个集群的资源的同时还能被分别管理。
11、简述Kubernetes集群相关组件
Kubernetes Master控制组件,调度管理整个系统(集群),包含如下组件:
- Kubernetes API Server:作为Kubernetes系统的入口,其封装了核心对象的增删改查操作,以RESTful API接口方式提供给外部客户和内部组件调用,集群内各个功能模块之间数据交互和通信的中心枢纽。
- Kubernetes Scheduler:为新建立的Pod进行节点(Node)选择(即分配机器),负责集群的资源调度。
- Kubernetes Controller:负责执行各种控制器,目前已经提供了很多控制器来保证Kubernetes的正常运行。
- Replication Controller:管理维护Replication Controller,关联Replication Controller和Pod,保证Replication Controller定义的副本数量与实际运行Pod数量一致。
- Node Controller:管理维护Node,定期检查Node的健康状态,标识出(失效|未失效)的Node节点。
- Namespace Controller:管理维护Namespace,定期清理无效的Namespace,包括Namesapce下的API对象,比如Pod、Service等。
- Service Controller:管理维护Service,提供负载以及服务代理。
- EndPoints Controller:管理维护Endpoints,关联Service和Pod,创建Endpoints为Service的后端,当Pod发生变化时,实时更新Endpoints。
- Service Account Controller:管理维护Service Account,为每个Namespace创建默认的Service Account,同时为Service Account创建Service Account Secret。
- Persistent Volume Controller:管理维护Persistent Volume和Persistent Volume Claim,为新的Persistent Volume Claim分配Persistent Volume进行绑定,为释放的Persistent Volume执行清理回收。
- Daemon Set Controller:管理维护Daemon Set,负责创建Daemon Pod,保证指定的Node上正常的运行Daemon Pod。
- Deployment Controller:管理维护Deployment,关联Deployment和Replication Controller,保证运行指定数量的Pod。当Deployment更新时,控制实现Replication Controller和Pod的更新。
- Job Controller:管理维护Job,为Jod创建一次性任务Pod,保证完成Job指定完成的任务数目
- Pod Autoscaler Controller:实现Pod的自动伸缩,定时获取监控数据,进行策略匹配,当满足条件时执行Pod的伸缩动作。
12、简述Kubernetes RC的机制
Replication Controller用来管理Pod的副本,保证集群中存在指定数量的Pod副本。当定义了RC并提交至Kubernetes集群中之后,Master节点上的Controller Manager组件获悉,并同时巡检系统中当前存活的目标Pod,并确保目标Pod实例的数量刚好等于此RC的期望值,若存在过多的Pod副本在运行,系统会停止一些Pod,反之则自动创建一些Pod。
13、简述Kubernetes Replica Set和Replication Controller之间有什么区别
Replica Set和Replication Controller类似,都是确保在任何给定时间运行指定数量的Pod副本。不同之处在于RS使用基于集合的选择器,而Replication Controller使用基于权限的选择器。
14、简述kube-proxy的作用
kube-proxy运行在所有节点上,它监听apiserver中service和endpoint的变化情况,创建路由规则以提供服务IP和负载均衡功能。简单理解此进程是Service的透明代理兼负载均衡器,其核心功能是将到某个Service的访问请求转发到后端的多个Pod实例上。
15、简述kube-proxy iptables的原理
Kubernetes从1.2版本开始,将iptables作为kube-proxy的默认模式。iptables模式下的kube-proxy不再起到Proxy的作用,其核心功能:通过API Server的Watch接口实时跟踪Service与Endpoint的变更信息,并更新对应的iptables规则,Client的请求流量则通过iptables的NAT机制“直接路由”到目标Pod。
16、简述kube-proxy ipvs的原理
IPVS在Kubernetes1.11中升级为GA稳定版。IPVS则专门用于高性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的规模扩张,因此被kube-proxy采纳为最新模式。
在IPVS模式下,使用iptables的扩展ipset,而不是直接调用iptables来生成规则链。iptables规则链是一个线性的数据结构,ipset则引入了带索引的数据结构,因此当规则很多时,也可以很高效地查找和匹配。
可以将ipset简单理解为一个IP(段)的集合,这个集合的内容可以是IP地址、IP网段、端口等,iptables可以直接添加规则对这个“可变的集合”进行操作,这样做的好处在于可以大大减少iptables规则的数量,从而减少性能损耗。
17、简述kube-proxy ipvs和iptables的异同
iptables与IPVS都是基于Netfilter实现的,但因为定位不同,二者有着本质的差别:iptables是为防火墙而设计的;IPVS则专门用于高性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的规模扩张。
与iptables相比,IPVS拥有以下明显优势:
- 为大型集群提供了更好的可扩展性和性能;
- 支持比iptables更复杂的复制均衡算法(最小负载、最少连接、加权等);
- 支持服务器健康检查和连接重试等功能;
- 可以动态修改ipset的集合,即使iptables的规则正在使用这个集合。
18、简述Kubernetes中什么是静态Pod
静态Pod是由kubelet进行管理的仅存在于特定Node的Pod上,他们不能通过API Server进行管理,无法与ReplicationController、Deployment或者DaemonSet进行关联,并且kubelet无法对他们进行健康检查。静态Pod总是由kubelet进行创建,并且总是在kubelet所在的Node上运行。
19、简述Kubernetes中Pod可能位于的状态
- Pending:API Server已经创建该Pod,且Pod内还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程。
- Running:Pod内所有容器均已创建,且至少有一个容器处于运行状态、正在启动状态或正在重启状态。
- Succeeded:Pod内所有容器均成功执行退出,且不会重启。
- Failed:Pod内所有容器均已退出,但至少有一个容器退出为失败状态。
- Unknown:由于某种原因无法获取该Pod状态,可能由于网络通信不畅导致。
20、简述Kubernetes创建一个Pod的主要流程?
Kubernetes中创建一个Pod涉及多个组件之间联动,主要流程如下:
- 客户端提交Pod的配置信息(可以是yaml文件定义的信息)到kube-apiserver。
- Apiserver收到指令后,通知给controller-manager创建一个资源对象。
- Controller-manager通过api-server将Pod的配置信息存储到etcd数据中心中。
- Kube-scheduler检测到Pod信息会开始调度预选,会先过滤掉不符合Pod资源配置要求的节点,然后开始调度调优,主要是挑选出更适合运行Pod的节点,然后将Pod的资源配置单发送到Node节点上的kubelet组件上。
- Kubelet根据scheduler发来的资源配置单运行Pod,运行成功后,将Pod的运行信息返回给scheduler,scheduler将返回的Pod运行状况的信息存储到etcd数据中心。
21、简述Kubernetes中Pod的重启策略
Pod重启策略(RestartPolicy)应用于Pod内的所有容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet将根据RestartPolicy的设置来进行相应操作。
Pod的重启策略包括Always、OnFailure和Never,默认值为Always。
- Always:当容器失效时,由kubelet自动重启该容器;
- OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器;
- Never:不论容器运行状态如何,kubelet都不会重启该容器。
同时Pod的重启策略与控制方式关联,当前可用于管理Pod的控制器包括ReplicationController、Job、DaemonSet及直接管理kubelet管理(静态Pod)。
不同控制器的重启策略限制如下:
- RC和DaemonSet:必须设置为Always,需要保证该容器持续运行;
- Job:OnFailure或Never,确保容器执行完成后不再重启;
- kubelet:在Pod失效时重启,不论将RestartPolicy设置为何值,也不会对Pod进行健康检查。
22、简述Kubernetes中Pod的健康检查方式
对Pod的健康检查可以通过两类探针来检查:LivenessProbe和ReadinessProbe。
- LivenessProbe探针:用于判断容器是否存活(running状态),如果LivenessProbe探针探测到容器不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应处理。若一个容器不包含LivenessProbe探针,kubelet认为该容器的LivenessProbe探针返回值用于是“Success”。
- ReadineeProbe探针:用于判断容器是否启动完成(ready状态)。如果ReadinessProbe探针探测到失败,则Pod的状态将被修改。Endpoint Controller将从Service的Endpoint中删除包含该容器所在Pod的Eenpoint。
- startupProbe探针:启动检查机制,应用一些启动缓慢的业务,避免业务长时间启动而被上面两类探针kill掉。
23、简述Kubernetes Pod的LivenessProbe探针的常见方式
kubelet定期执行LivenessProbe探针来诊断容器的健康状态,通常有以下三种方式:
- ExecAction:在容器内执行一个命令,若返回码为0,则表明容器健康。
- TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,若能建立TCP连接,则表明容器健康。
- HTTPGetAction:通过容器的IP地址、端口号及路径调用HTTP Get方法,若响应的状态码大于等于200且小于400,则表明容器健康。
24、简述Kubernetes Pod的常见调度方式
Kubernetes中,Pod通常是容器的载体,主要有如下常见调度方式:
-
Deployment或RC:该调度策略主要功能就是自动部署一个容器应用的多份副本,以及持续监控副本的数量,在集群内始终维持用户指定的副本数量。
-
NodeSelector:定向调度,当需要手动指定将Pod调度到特定Node上,可以通过Node的标签(Label)和Pod的nodeSelector属性相匹配。
-
NodeAffinity亲和性调度:亲和性调度机制极大的扩展了Pod的调度能力,目前有两种节点亲和力表达:
-
- requiredDuringSchedulingIgnoredDuringExecution:硬规则,必须满足指定的规则,调度器才可以调度Pod至Node上(类似nodeSelector,语法不同)。
- preferredDuringSchedulingIgnoredDuringExecution:软规则,优先调度至满足的Node的节点,但不强求,多个优先级规则还可以设置权重值。
-
Taints和Tolerations(污点和容忍):
-
- Taint:使Node拒绝特定Pod运行;
- Toleration:为Pod的属性,表示Pod能容忍(运行)标注了Taint的Node。
25、简述Kubernetes初始化容器(init container)
init container的运行方式与应用容器不同,它们必须先于应用容器执行完成,当设置了多个init container时,将按顺序逐个运行,并且只有前一个init container运行成功后才能运行后一个init container。当所有init container都成功运行后,Kubernetes才会初始化Pod的各种信息,并开始创建和运行应用容器。
26、简述Kubernetes deployment升级过程
- 初始创建Deployment时,系统创建了一个ReplicaSet,并按用户的需求创建了对应数量的Pod副本。
- 当更新Deployment时,系统创建了一个新的ReplicaSet,并将其副本数量扩展到1,然后将旧ReplicaSet缩减为2。
- 之后,系统继续按照相同的更新策略对新旧两个ReplicaSet进行逐个调整。
- 最后,新的ReplicaSet运行了对应个新版本Pod副本,旧的ReplicaSet副本数量则缩减为0。
27、简述Kubernetes deployment升级策略
在Deployment的定义中,可以通过spec.strategy指定Pod更新的策略,目前支持两种策略:Recreate(重建)和RollingUpdate(滚动更新),默认值为RollingUpdate。
- Recreate:设置spec.strategy.type=Recreate,表示Deployment在更新Pod时,会先杀掉所有正在运行的Pod,然后创建新的Pod。
- RollingUpdate:设置spec.strategy.type=RollingUpdate,表示Deployment会以滚动更新的方式来逐个更新Pod。同时,可以通过设置spec.strategy.rollingUpdate下的两个参数(maxUnavailable和maxSurge)来控制滚动更新的过程。
28、简述Kubernetes DaemonSet类型的资源特性
DaemonSet资源对象会在每个Kubernetes集群中的节点上运行,并且每个节点只能运行一个Pod,这是它和Deployment资源对象的最大也是唯一的区别。因此,在定义yaml文件中,不支持定义replicas。
它的一般使用场景如下:
- 在去做每个节点的日志收集工作。
- 监控每个节点的的运行状态。
29、简述Kubernetes自动扩容机制
Kubernetes使用Horizontal Pod Autoscaler(HPA)的控制器实现基于CPU使用率进行自动Pod扩缩容的功能。HPA控制器周期性地监测目标Pod的资源性能指标,并与HPA资源对象中的扩缩容条件进行对比,在满足条件时对Pod副本数量进行调整。
Kubernetes中的某个Metrics Server(Heapster或自定义Metrics Server)持续采集所有Pod副本的指标数据。HPA控制器通过Metrics Server的API(Heapster的API或聚合API)获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标Pod副本数量。
当目标Pod副本数量与当前副本数量不同时,HPA控制器就向Pod的副本控制器(Deployment、RC或ReplicaSet)发起scale操作,调整Pod的副本数量,完成扩缩容操作。
30、简述Kubernetes Service类型
通过创建Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求负载分发到后端的各个容器应用上。其主要类型有:
- ClusterIP:虚拟的服务IP地址,该地址用于Kubernetes集群内部的Pod访问,在Node上kube-proxy通过设置的iptables规则进行转发;
- NodePort:使用宿主机的端口,使能够访问各Node的外部客户端通过Node的IP地址和端口号就能访问服务;
- LoadBalancer:使用外接负载均衡器完成到服务的负载分发,需要在spec.status.loadBalancer字段指定外部负载均衡器的IP地址,通常用于公有云。
31、简述Kubernetes Service分发后端的策略
Service负载分发的策略有:RoundRobin和SessionAffinity
- RoundRobin:默认为轮询模式,即轮询将请求转发到后端的各个Pod上。
- SessionAffinity:基于客户端IP地址进行会话保持的模式,即第1次将某个客户端发起的请求转发到后端的某个Pod上,之后从相同的客户端发起的请求都将被转发到后端相同的Pod上。
32、简述Kubernetes Headless Service
在某些应用场景中,若需要人为指定负载均衡器,不使用Service提供的默认负载均衡的功能,或者应用程序希望知道属于同组服务的其他实例。Kubernetes提供了Headless Service来实现这种功能,即不为Service设置ClusterIP(入口IP地址),仅通过Label Selector将后端的Pod列表返回给调用的客户端。
33、简述Kubernetes外部如何访问集群内的服务
对于Kubernetes,集群外的客户端默认情况,无法通过Pod的IP地址或者Service的虚拟IP地址:虚拟端口号进行访问。通常可以通过以下方式进行访问Kubernetes集群内的服务:
- 映射Pod到物理机:将Pod端口号映射到宿主机,即在Pod中采用hostPort方式,以使客户端应用能够通过物理机访问容器应用。
- 映射Service到物理机:将Service端口号映射到宿主机,即在Service中采用nodePort方式,以使客户端应用能够通过物理机访问容器应用。
- 映射Sercie到LoadBalancer:通过设置LoadBalancer映射到云服务商提供的LoadBalancer地址。这种用法仅用于在公有云服务提供商的云平台上设置Service的场景。
34、简述Kubernetes ingress
Kubernetes的Ingress资源对象,用于将不同URL的访问请求转发到后端不同的Service,以实现HTTP层的业务路由机制。
Kubernetes使用了Ingress策略和Ingress Controller,两者结合并实现了一个完整的Ingress负载均衡器。使用Ingress进行负载分发时,Ingress Controller基于Ingress规则将客户端请求直接转发到Service对应的后端Endpoint(Pod)上,从而跳过kube-proxy的转发功能,kube-proxy不再起作用,全过程为:ingress controller + ingress 规则 ----> services。
同时当Ingress Controller提供的是对外服务,则实际上实现的是边缘路由器的功能。
35、简述Kubernetes镜像的下载策略
Kubernetes的镜像下载策略有三种:Always、Never、IFNotPresent。
- Always:镜像标签为latest时,总是从指定的仓库中获取镜像。
- Never:禁止从仓库中下载镜像,也就是说只能使用本地镜像。
- IfNotPresent:仅当本地没有对应镜像时,才从目标仓库中下载。默认的镜像下载策略是:当镜像标签是latest时,默认策略是Always;当镜像标签是自定义时(也就是标签不是latest),那么默认策略是IfNotPresent。
36、简述Kubernetes的负载均衡器
负载均衡器是暴露服务的最常见和标准方式之一。
根据工作环境使用两种类型的负载均衡器,即内部负载均衡器或外部负载均衡器。内部负载均衡器自动平衡负载并使用所需配置分配容器,而外部负载均衡器将流量从外部负载引导至后端容器。
37、简述Kubernetes各模块如何与API Server通信
Kubernetes API Server作为集群的核心,负责集群各功能模块之间的通信。集群内的各个功能模块通过API Server将信息存入etcd,当需要获取和操作这些数据时,则通过API Server提供的REST接口(用GET、LIST或WATCH方法)来实现,从而实现各模块之间的信息交互。
如kubelet进程与API Server的交互:每个Node上的kubelet每隔一个时间周期,就会调用一次API Server的REST接口报告自身状态,API Server在接收到这些信息后,会将节点状态信息更新到etcd中。
如kube-controller-manager进程与API Server的交互:kube-controller-manager中的Node Controller模块通过API Server提供的Watch接口实时监控Node的信息,并做相应处理。
如kube-scheduler进程与API Server的交互:Scheduler通过API Server的Watch接口监听到新建Pod副本的信息后,会检索所有符合该Pod要求的Node列表,开始执行Pod调度逻辑,在调度成功后将Pod绑定到目标节点上。
38、简述Kubernetes Scheduler作用及实现原理
Kubernetes Scheduler是负责Pod调度的重要功能模块,Kubernetes Scheduler在整个系统中承担了“承上启下”的重要功能,“承上”是指它负责接收Controller Manager创建的新Pod,为其调度至目标Node;“启下”是指调度完成后,目标Node上的kubelet服务进程接管后继工作,负责Pod接下来生命周期。
Kubernetes Scheduler的作用是将待调度的Pod(API新创建的Pod、Controller Manager为补足副本而创建的Pod等)按照特定的调度算法和调度策略绑定(Binding)到集群中某个合适的Node上,并将绑定信息写入etcd中。
在整个调度过程中涉及三个对象,分别是待调度Pod列表、可用Node列表,以及调度算法和策略。
Kubernetes Scheduler通过调度算法调度为待调度Pod列表中的每个Pod从Node列表中选择一个最适合的Node来实现Pod的调度。随后,目标节点上的kubelet通过API Server监听到Kubernetes Scheduler产生的Pod绑定事件,然后获取对应的Pod清单,下载Image镜像并启动容器。
39、简述Kubernetes Scheduler使用哪两种算法将Pod绑定到worker节点
Kubernetes Scheduler根据如下两种调度算法将 Pod 绑定到最合适的工作节点:
- 预选(Predicates):输入是所有节点,输出是满足预选条件的节点。kube-scheduler根据预选策略过滤掉不满足策略的Nodes。如果某节点的资源不足或者不满足预选策略的条件则无法通过预选。如“Node的label必须与Pod的Selector一致”。
- 优选(Priorities):输入是预选阶段筛选出的节点,优选会根据优先策略为通过预选的Nodes进行打分排名,选择得分最高的Node。例如,资源越富裕、负载越小的Node可能具有越高的排名。
40、简述Kubernetes kubelet的作用
在Kubernetes集群中,在每个Node(又称Worker)上都会启动一个kubelet服务进程。该进程用于处理Master下发到本节点的任务,管理Pod及Pod中的容器。每个kubelet进程都会在API Server上注册节点自身的信息,定期向Master汇报节点资源的使用情况,并通过cAdvisor监控容器和节点资源。
41、简述Kubernetes kubelet监控Worker节点资源是使用什么组件来实现的
kubelet使用cAdvisor对worker节点资源进行监控。在Kubernetes系统中,cAdvisor已被默认集成到kubelet组件内,当kubelet服务启动时,它会自动启动cAdvisor服务,然后cAdvisor会实时采集所在节点的性能指标及在节点上运行的容器的性能指标。
42、简述Kubernetes如何保证集群的安全性
Kubernetes通过一系列机制来实现集群的安全控制,主要有如下不同的维度:
-
基础设施方面:保证容器与其所在宿主机的隔离;
-
权限方面:
-
- 最小权限原则:合理限制所有组件的权限,确保组件只执行它被授权的行为,通过限制单个组件的能力来限制它的权限范围。
- 用户权限:划分普通用户和管理员的角色。
-
集群方面:
-
- API Server的认证授权:Kubernetes集群中所有资源的访问和变更都是通过Kubernetes API Server来实现的,因此需要建议采用更安全的HTTPS或Token来识别和认证客户端身份(Authentication),以及随后访问权限的授权(Authorization)环节。
- API Server的授权管理:通过授权策略来决定一个API调用是否合法。对合法用户进行授权并且随后在用户访问时进行鉴权,建议采用更安全的RBAC方式来提升集群安全授权。
-
敏感数据引入Secret机制:对于集群敏感数据建议使用Secret方式进行保护。
-
AdmissionControl(准入机制):对kubernetes api的请求过程中,顺序为:先经过认证 & 授权,然后执行准入操作,最后对目标对象进行操作。
43、简述Kubernetes准入机制
在对集群进行请求时,每个准入控制代码都按照一定顺序执行。如果有一个准入控制拒绝了此次请求,那么整个请求的结果将会立即返回,并提示用户相应的error信息。
准入控制(AdmissionControl)准入控制本质上为一段准入代码,在对kubernetes api的请求过程中,顺序为:先经过认证 & 授权,然后执行准入操作,最后对目标对象进行操作。常用组件(控制代码)如下:
- AlwaysAdmit:允许所有请求
- AlwaysDeny:禁止所有请求,多用于测试环境。
- ServiceAccount:它将serviceAccounts实现了自动化,它会辅助serviceAccount做一些事情,比如如果pod没有serviceAccount属性,它会自动添加一个default,并确保pod的serviceAccount始终存在。
- LimitRanger:观察所有的请求,确保没有违反已经定义好的约束条件,这些条件定义在namespace中LimitRange对象中。
- NamespaceExists:观察所有的请求,如果请求尝试创建一个不存在的namespace,则这个请求被拒绝。
44、简述Kubernetes RBAC及其特点(优势)
RBAC是基于角色的访问控制,是一种基于个人用户的角色来管理对计算机或网络资源的访问的方法。
相对于其他授权模式,RBAC具有如下优势:
- 对集群中的资源和非资源权限均有完整的覆盖。
- 整个RBAC完全由几个API对象完成, 同其他API对象一样, 可以用kubectl或API进行操作。
- 可以在运行时进行调整,无须重新启动API Server。
45、简述Kubernetes Secret作用
Secret对象,主要作用是保管私密数据,比如密码、OAuth Tokens、SSH Keys等信息。将这些私密信息放在Secret对象中比直接放在Pod或Docker Image中更安全,也更便于使用和分发。
46、简述Kubernetes Secret有哪些使用方式
创建完secret之后,可通过如下三种方式使用:
- 在创建Pod时,通过为Pod指定Service Account来自动使用该Secret。
- 通过挂载该Secret到Pod来使用它。
- 在Docker镜像下载时使用,通过指定Pod的spc.ImagePullSecrets来引用它。
47、简述Kubernetes PodSecurityPolicy机制
Kubernetes PodSecurityPolicy是为了更精细地控制Pod对资源的使用方式以及提升安全策略。在开启PodSecurityPolicy准入控制器后,Kubernetes默认不允许创建任何Pod,需要创建PodSecurityPolicy策略和相应的RBAC授权策略(Authorizing Policies),Pod才能创建成功。
48、简述Kubernetes PodSecurityPolicy机制能实现哪些安全策略
在PodSecurityPolicy对象中可以设置不同字段来控制Pod运行时的各种安全策略,常见的有:
- 特权模式:privileged是否允许Pod以特权模式运行。
- 宿主机资源:控制Pod对宿主机资源的控制,如hostPID:是否允许Pod共享宿主机的进程空间。
- 用户和组:设置运行容器的用户ID(范围)或组(范围)。
- 提升权限:AllowPrivilegeEscalation:设置容器内的子进程是否可以提升权限,通常在设置非root用户(MustRunAsNonRoot)时进行设置。
- SELinux:进行SELinux的相关配置。
49、简述Kubernetes网络模型
Kubernetes网络模型中每个Pod都拥有一个独立的IP地址,并假定所有Pod都在一个可以直接连通的、扁平的网络空间中。所以不管它们是否运行在同一个Node(宿主机)中,都要求它们可以直接通过对方的IP进行访问。设计这个原则的原因是,用户不需要额外考虑如何建立Pod之间的连接,也不需要考虑如何将容器端口映射到主机端口等问题。
同时为每个Pod都设置一个IP地址的模型使得同一个Pod内的不同容器会共享同一个网络命名空间,也就是同一个Linux网络协议栈。这就意味着同一个Pod内的容器可以通过localhost来连接对方的端口。
在Kubernetes的集群里,IP是以Pod为单位进行分配的。一个Pod内部的所有容器共享一个网络堆栈(相当于一个网络命名空间,它们的IP地址、网络设备、配置等都是共享的)。
50、简述Kubernetes CNI模型
CNI提供了一种应用容器的插件化网络解决方案,定义对容器网络进行操作和配置的规范,通过插件的形式对CNI接口进行实现。CNI仅关注在创建容器时分配网络资源,和在销毁容器时删除网络资源。在CNI模型中只涉及两个概念:容器和网络。
- 容器(Container):是拥有独立Linux网络命名空间的环境,例如使用Docker或rkt创建的容器。容器需要拥有自己的Linux网络命名空间,这是加入网络的必要条件。
- 网络(Network):表示可以互连的一组实体,这些实体拥有各自独立、唯一的IP地址,可以是容器、物理机或者其他网络设备(比如路由器)等。
对容器网络的设置和操作都通过插件(Plugin)进行具体实现,CNI插件包括两种类型:CNI Plugin和IPAM(IP Address Management)Plugin。CNI Plugin负责为容器配置网络资源,IPAM Plugin负责对容器的IP地址进行分配和管理。IPAM Plugin作为CNI Plugin的一部分,与CNI Plugin协同工作。
51、简述Kubernetes网络策略
为实现细粒度的容器间网络访问隔离策略,Kubernetes引入Network Policy。
Network Policy的主要功能是对Pod间的网络通信进行限制和准入控制,设置允许访问或禁止访问的客户端Pod列表。Network Policy定义网络策略,配合策略控制器(Policy Controller)进行策略的实现。
52、简述Kubernetes网络策略原理
Network Policy的工作原理主要为:policy controller需要实现一个API Listener,监听用户设置的Network Policy定义,并将网络访问规则通过各Node的Agent进行实际设置(Agent则需要通过CNI网络插件实现)。
53、简述Kubernetes中flannel的作用
Flannel可以用于Kubernetes底层网络的实现,主要作用有:
- 它能协助Kubernetes,给每一个Node上的Docker容器都分配互相不冲突的IP地址。
- 它能在这些IP地址之间建立一个覆盖网络(Overlay Network),通过这个覆盖网络,将数据包原封不动地传递到目标容器内。
54、简述Kubernetes Calico网络组件实现原理
Calico是一个基于BGP的纯三层的网络方案,与OpenStack、Kubernetes、AWS、GCE等云平台都能够良好地集成。
Calico在每个计算节点都利用Linux Kernel实现了一个高效的vRouter来负责数据转发。每个vRouter都通过BGP协议把在本节点上运行的容器的路由信息向整个Calico网络广播,并自动设置到达其他节点的路由转发规则。
Calico保证所有容器之间的数据流量都是通过IP路由的方式完成互联互通的。Calico节点组网时可以直接利用数据中心的网络结构(L2或者L3),不需要额外的NAT、隧道或者Overlay Network,没有额外的封包解包,能够节约CPU运算,提高网络效率。
55、简述Kubernetes共享存储的作用
Kubernetes对于有状态的容器应用或者对数据需要持久化的应用,因此需要更加可靠的存储来保存应用产生的重要数据,以便容器应用在重建之后仍然可以使用之前的数据。因此需要使用共享存储。
56、简述Kubernetes数据持久化的方式有哪些
Kubernetes通过数据持久化来持久化保存重要数据,常见的方式有:
-
EmptyDir(空目录):没有指定要挂载宿主机上的某个目录,直接由Pod内保部映射到宿主机上。类似于docker中的manager volume。
-
场景:
-
- 只需要临时将数据保存在磁盘上,比如在合并/排序算法中;
- 作为两个容器的共享存储。
-
特性:
-
- 同个pod里面的不同容器,共享同一个持久化目录,当pod节点删除时,volume的数据也会被删除。
- emptyDir的数据持久化的生命周期和使用的pod一致,一般是作为临时存储使用。
-
Hostpath:将宿主机上已存在的目录或文件挂载到容器内部。类似于docker中的bind mount挂载方式。
-
特性:增加了Pod与节点之间的耦合。
PersistentVolume(简称PV):如基于NFS服务的PV,也可以基于GFS的PV。它的作用是统一数据持久化目录,方便管理。
57、简述Kubernetes PV和PVC
PV是对底层网络共享存储的抽象,将共享存储定义为一种“资源”。
PVC则是用户对存储资源的一个“申请”。
58、简述Kubernetes PV生命周期内的阶段
某个PV在生命周期中可能处于以下4个阶段(Phaes)之一。
- Available:可用状态,还未与某个PVC绑定。
- Bound:已与某个PVC绑定。
- Released:绑定的PVC已经删除,资源已释放,但没有被集群回收。
- Failed:自动资源回收失败。
59、简述Kubernetes所支持的存储供应模式
Kubernetes支持两种资源的存储供应模式:静态模式(Static)和动态模式(Dynamic)。
- 静态模式:集群管理员手工创建许多PV,在定义PV时需要将后端存储的特性进行设置。
- 动态模式:集群管理员无须手工创建PV,而是通过StorageClass的设置对后端存储进行描述,标记为某种类型。此时要求PVC对存储的类型进行声明,系统将自动完成PV的创建及与PVC的绑定。
60、简述Kubernetes CSI模型
Kubernetes CSI是Kubernetes推出与容器对接的存储接口标准,存储提供方只需要基于标准接口进行存储插件的实现,就能使用Kubernetes的原生存储机制为容器提供存储服务。CSI使得存储提供方的代码能和Kubernetes代码彻底解耦,部署也与Kubernetes核心组件分离,显然,存储插件的开发由提供方自行维护,就能为Kubernetes用户提供更多的存储功能,也更加安全可靠。
CSI包括CSI Controller和CSI Node:
- CSI Controller的主要功能是提供存储服务视角对存储资源和存储卷进行管理和操作。
- CSI Node的主要功能是对主机(Node)上的Volume进行管理和操作。
61、简述Kubernetes Worker节点加入集群的过程
通常需要对Worker节点进行扩容,从而将应用系统进行水平扩展。主要过程如下:
- 在该Node上安装Docker、kubelet和kube-proxy服务;
- 然后配置kubelet和kubeproxy的启动参数,将Master URL指定为当前Kubernetes集群Master的地址,最后启动这些服务;
- 通过kubelet默认的自动注册机制,新的Worker将会自动加入现有的Kubernetes集群中;
- Kubernetes Master在接受了新Worker的注册之后,会自动将其纳入当前集群的调度范围。
62、简述Kubernetes Pod如何实现对节点的资源控制
Kubernetes集群里的节点提供的资源主要是计算资源,计算资源是可计量的能被申请、分配和使用的基础资源。当前Kubernetes集群中的计算资源主要包括CPU、GPU及Memory。CPU与Memory是被Pod使用的,因此在配置Pod时可以通过参数CPU Request及Memory Request为其中的每个容器指定所需使用的CPU与Memory量,Kubernetes会根据Request的值去查找有足够资源的Node来调度此Pod。
通常,一个程序所使用的CPU与Memory是一个动态的量,确切地说,是一个范围,跟它的负载密切相关:负载增加时,CPU和Memory的使用量也会增加。
63、简述Kubernetes Requests和Limits如何影响Pod的调度
当一个Pod创建成功时,Kubernetes调度器(Scheduler)会为该Pod选择一个节点来执行。对于每种计算资源(CPU和Memory)而言,每个节点都有一个能用于运行Pod的最大容量值。调度器在调度时,首先要确保调度后该节点上所有Pod的CPU和内存的Requests总和,不超过该节点能提供给Pod使用的CPU和Memory的最大容量值。
64、简述Kubernetes Metric Service
在Kubernetes从1.10版本后采用Metrics Server作为默认的性能数据采集和监控,主要用于提供核心指标(Core Metrics),包括Node、Pod的CPU和内存使用指标。
对其他自定义指标(Custom Metrics)的监控则由Prometheus等组件来完成。
65、简述Kubernetes中,如何使用EFK实现日志的统一管理
在Kubernetes集群环境中,通常一个完整的应用或服务涉及组件过多,建议对日志系统进行集中化管理,通常采用EFK实现。
EFK是 Elasticsearch、Fluentd 和 Kibana 的组合,其各组件功能如下:
- Elasticsearch:是一个搜索引擎,负责存储日志并提供查询接口;
- Fluentd:负责从 Kubernetes 搜集日志,每个Node节点上面的Fluentd监控并收集该节点上面的系统日志,并将处理过后的日志信息发送给Elasticsearch;
- Kibana:提供了一个 Web GUI,用户可以浏览和搜索存储在 Elasticsearch 中的日志。
通过在每台Node上部署一个以DaemonSet方式运行的Fluentd来收集每台Node上的日志。Fluentd将Docker日志目录/var/lib/docker/containers和/var/log目录挂载到Pod中,然后Pod会在Node节点的/var/log/pods目录中创建新的目录,可以区别不同的容器日志输出,该目录下有一个日志文件链接到/var/lib/docker/contianers目录下的容器日志输出。
66、简述Kubernetes如何进行优雅的节点关机维护
由于Kubernetes节点运行大量Pod,因此在进行关机维护之前,建议先使用kubectl drain将该节点的Pod进行驱逐,然后进行关机维护。
67、简述Kubernetes集群联邦
Kubernetes集群联邦可以将多个Kubernetes集群作为一个集群进行管理。因此,可以在一个数据中心/云中创建多个Kubernetes集群,并使用集群联邦在一个地方控制/管理所有集群。
68、简述Helm及其优势
Helm是Kubernetes的软件包管理工具。类似Ubuntu中使用的APT、CentOS中使用的yum 或者Python中的 pip 一样。
Helm能够将一组Kubernetes资源打包统一管理, 是查找、共享和使用为Kubernetes构建的软件的最佳方式。
Helm中通常每个包称为一个Chart,一个Chart是一个目录(一般情况下会将目录进行打包压缩,形成name-version.tgz格式的单一文件,方便传输和存储)。
在Kubernetes中部署一个可以使用的应用,需要涉及到很多的 Kubernetes 资源的共同协作。使用Helm则具有如下优势:
- 统一管理、配置和更新这些分散的Kubernetes的应用资源文件;
- 分发和复用一套应用模板;
- 将应用的一系列资源当做一个软件包管理。
- 对于应用发布者而言,可以通过 Helm 打包应用、管理应用依赖关系、管理应用版本并发布应用到软件仓库。
对于使用者而言,使用Helm后不用需要编写复杂的应用部署文件,可以以简单的方式在Kubernetes上查找、安装、升级、回滚、卸载应用程序。
69、k8s是什么?请说出你的了解?
答:Kubenetes是一个针对容器应用,进行自动部署,弹性伸缩和管理的开源系统。主要功能是生产环境中的容器编排。
K8S是Google公司推出的,它来源于由Google公司内部使用了15年的Borg系统,集结了Borg的精华。
70、K8s架构的组成是什么?
答:和大多数分布式系统一样,K8S集群至少需要一个主节点(Master)和多个计算节点(Node)。
- 主节点主要用于暴露API,调度部署和节点的管理;
- 计算节点运行一个容器运行环境,一般是docker环境(类似docker环境的还有rkt),同时运行一个K8s的代理(kubelet)用于和master通信。计算节点也会运行一些额外的组件,像记录日志,节点监控,服务发现等等。计算节点是k8s集群中真正工作的节点。
K8S架构细分:
1、Master节点(默认不参加实际工作):
- Kubectl:客户端命令行工具,作为整个K8s集群的操作入口;
- Api Server:在K8s架构中承担的是“桥梁”的角色,作为资源操作的唯一入口,它提供了认证、授权、访问控制、API注册和发现等机制。客户端与k8s群集及K8s内部组件的通信,都要通过Api Server这个组件;
- Controller-manager:负责维护群集的状态,比如故障检测、自动扩展、滚动更新等;
- Scheduler:负责资源的调度,按照预定的调度策略将pod调度到相应的node节点上;
- Etcd:担任数据中心的角色,保存了整个群集的状态;
2、Node节点:
- Kubelet:负责维护容器的生命周期,同时也负责Volume和网络的管理,一般运行在所有的节点,是Node节点的代理,当Scheduler确定某个node上运行pod之后,会将pod的具体信息(image,volume)等发送给该节点的kubelet,kubelet根据这些信息创建和运行容器,并向master返回运行状态。(自动修复功能:如果某个节点中的容器宕机,它会尝试重启该容器,若重启无效,则会将该pod杀死,然后重新创建一个容器);
- Kube-proxy:Service在逻辑上代表了后端的多个pod。负责为Service提供cluster内部的服务发现和负载均衡(外界通过Service访问pod提供的服务时,Service接收到的请求后就是通过kube-proxy来转发到pod上的);
- container-runtime:是负责管理运行容器的软件,比如docker
- Pod:是k8s集群里面最小的单位。每个pod里边可以运行一个或多个container(容器),如果一个pod中有两个container,那么container的USR(用户)、MNT(挂载点)、PID(进程号)是相互隔离的,UTS(主机名和域名)、IPC(消息队列)、NET(网络栈)是相互共享的。我比较喜欢把pod来当做豌豆夹,而豌豆就是pod中的container;
71、容器和主机部署应用的区别是什么?
答:容器的中心思想就是秒级启动;一次封装、到处运行;这是主机部署应用无法达到的效果,但同时也更应该注重容器的数据持久化问题。
另外,容器部署可以将各个服务进行隔离,互不影响,这也是容器的另一个核心概念。
72、请你说一下kubenetes针对pod资源对象的健康监测机制?
答:K8s中对于pod资源对象的健康状态检测,提供了三类probe(探针)来执行对pod的健康监测:
1) livenessProbe探针
可以根据用户自定义规则来判定pod是否健康,如果livenessProbe探针探测到容器不健康,则kubelet会根据其重启策略来决定是否重启,如果一个容器不包含livenessProbe探针,则kubelet会认为容器的livenessProbe探针的返回值永远成功。
2) ReadinessProbe探针
同样是可以根据用户自定义规则来判断pod是否健康,如果探测失败,控制器会将此pod从对应service的endpoint列表中移除,从此不再将任何请求调度到此Pod上,直到下次探测成功。
3) startupProbe探针
启动检查机制,应用一些启动缓慢的业务,避免业务长时间启动而被上面两类探针kill掉,这个问题也可以换另一种方式解决,就是定义上面两类探针机制时,初始化时间定义的长一些即可。
每种探测方法能支持以下几个相同的检查参数,用于设置控制检查时间:
initialDelaySeconds:初始第一次探测间隔,用于应用启动的时间,防止应用还没启动而健康检查失败periodSeconds:检查间隔,多久执行probe检查,默认为10s;timeoutSeconds:检查超时时长,探测应用timeout后为失败;successThreshold:成功探测阈值,表示探测多少次为健康正常,默认探测1次。
上面两种探针都支持以下三种探测方法:
1)Exec:通过执行命令的方式来检查服务是否正常,比如使用cat命令查看pod中的某个重要配置文件是否存在,若存在,则表示pod健康。反之异常。
Exec探测方式的yaml文件语法如下:
spec:containers:- name: livenessimage: k8s.gcr.io/busyboxargs:- /bin/sh- -c- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600livenessProbe: #选择livenessProbe的探测机制exec: #执行以下命令command:- cat- /tmp/healthyinitialDelaySeconds: 5 #在容器运行五秒后开始探测periodSeconds: 5 #每次探测的时间间隔为5秒
在上面的配置文件中,探测机制为在容器运行5秒后,每隔五秒探测一次,如果cat命令返回的值为“0”,则表示健康,如果为非0,则表示异常。
2)Httpget:通过发送http/htps请求检查服务是否正常,返回的状态码为200-399则表示容器健康(注http get类似于命令curl -I)。
Httpget探测方式的yaml文件语法如下:
spec:containers:- name: livenessimage: k8s.gcr.io/livenesslivenessProbe: #采用livenessProbe机制探测httpGet: #采用httpget的方式scheme:HTTP #指定协议,也支持httpspath: /healthz #检测是否可以访问到网页根目录下的healthz网页文件port: 8080 #监听端口是8080initialDelaySeconds: 3 #容器运行3秒后开始探测periodSeconds: 3 #探测频率为3秒
上述配置文件中,探测方式为项容器发送HTTP GET请求,请求的是8080端口下的healthz文件,返回任何大于或等于200且小于400的状态码表示成功。任何其他代码表示异常。
3)tcpSocket:通过容器的IP和Port执行TCP检查,如果能够建立TCP连接,则表明容器健康,这种方式与HTTPget的探测机制有些类似,tcpsocket健康检查适用于TCP业务。
tcpSocket探测方式的yaml文件语法如下:
spec:containers:- name: goproxyimage: k8s.gcr.io/goproxy:0.1ports:
- containerPort: 8080
#这里两种探测机制都用上了,都是为了和容器的8080端口建立TCP连接readinessProbe:tcpSocket:port: 8080initialDelaySeconds: 5periodSeconds: 10livenessProbe:tcpSocket:port: 8080initialDelaySeconds: 15periodSeconds: 20
在上述的yaml配置文件中,两类探针都使用了,在容器启动5秒后,kubelet将发送第一个readinessProbe探针,这将连接容器的8080端口,如果探测成功,则该pod为健康,十秒后,kubelet将进行第二次连接。
除了readinessProbe探针外,在容器启动15秒后,kubelet将发送第一个livenessProbe探针,仍然尝试连接容器的8080端口,如果连接失败,则重启容器。
探针探测的结果无外乎以下三者之一:
- Success:Container通过了检查;
- Failure:Container没有通过检查;
- Unknown:没有执行检查,因此不采取任何措施(通常是我们没有定义探针检测,默认为成功)。
若觉得上面还不够透彻,可以移步其官网文档:
https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
73、如何控制滚动更新过程?
答:可以通过下面的命令查看到更新时可以控制的参数:
[root@master yaml]# kubectl explain deploy.spec.strategy.rollingUpdate
maxSurge: 此参数控制滚动更新过程,副本总数超过预期pod数量的上限。可以是百分比,也可以是具体的值。默认为1。
(上述参数的作用就是在更新过程中,值若为3,那么不管三七二一,先运行三个pod,用于替换旧的pod,以此类推)
maxUnavailable:此参数控制滚动更新过程中,不可用的Pod的数量。
(这个值和上面的值没有任何关系,举个例子:我有十个pod,但是在更新的过程中,我允许这十个pod中最多有三个不可用,那么就将这个参数的值设置为3,在更新的过程中,只要不可用的pod数量小于或等于3,那么更新过程就不会停止)。
74、K8s中镜像的下载策略是什么?
答:可通过命令“kubectl explain pod.spec.containers”来查看imagePullPolicy这行的解释。
K8s的镜像下载策略有三种:Always、Never、IFNotPresent;
- Always:镜像标签为latest时,总是从指定的仓库中获取镜像;
- Never:禁止从仓库中下载镜像,也就是说只能使用本地镜像;
- IfNotPresent:仅当本地没有对应镜像时,才从目标仓库中下载。
- 默认的镜像下载策略是:当镜像标签是latest时,默认策略是Always;当镜像标签是自定义时(也就是标签不是latest),那么默认策略是IfNotPresent。
75、image的状态有哪些?
- Running:Pod所需的容器已经被成功调度到某个节点,且已经成功运行,
- Pending:APIserver创建了pod资源对象,并且已经存入etcd中,但它尚未被调度完成或者仍然处于仓库中下载镜像的过程
- Unknown:APIserver无法正常获取到pod对象的状态,通常是其无法与所在工作节点的kubelet通信所致。
76、pod的重启策略是什么?
答:可以通过命令“kubectl explain pod.spec”查看pod的重启策略。(restartPolicy字段)
- Always:但凡pod对象终止就重启,此为默认策略。
- OnFailure:仅在pod对象出现错误时才重启
77、Service这种资源对象的作用是什么?
答:用来给相同的多个pod对象提供一个固定的统一访问接口,常用于服务发现和服务访问。
78、版本回滚相关的命令?
[root@master httpd-web]# kubectl apply -f httpd2-deploy1.yaml --record
#运行yaml文件,并记录版本信息;
[root@master httpd-web]# kubectl rollout history deployment httpd-devploy1
#查看该deployment的历史版本
[root@master httpd-web]# kubectl rollout undo deployment httpd-devploy1 --to-revision=1
#执行回滚操作,指定回滚到版本1
#在yaml文件的spec字段中,可以写以下选项(用于限制最多记录多少个历史版本):
spec:revisionHistoryLimit: 5
#这个字段通过 kubectl explain deploy.spec 命令找到revisionHistoryLimit <integer>行获得
79、标签与标签选择器的作用是什么?
标签:是当相同类型的资源对象越来越多的时候,为了更好的管理,可以按照标签将其分为一个组,为的是提升资源对象的管理效率。
标签选择器:就是标签的查询过滤条件。目前API支持两种标签选择器:
- 基于等值关系的,如:“=”、“”“”、“!=”(注:“”也是等于的意思,yaml文件中的matchLabels字段);
- 基于集合的,如:in、notin、exists(yaml文件中的matchExpressions字段);
注:in:在这个集合中;notin:不在这个集合中;exists:要么全在(exists)这个集合中,要么都不在(notexists);
使用标签选择器的操作逻辑:
- 在使用基于集合的标签选择器同时指定多个选择器之间的逻辑关系为“与”操作(比如:- {key: name,operator: In,values: [zhangsan,lisi]} ,那么只要拥有这两个值的资源,都会被选中);
- 使用空值的标签选择器,意味着每个资源对象都被选中(如:标签选择器的键是“A”,两个资源对象同时拥有A这个键,但是值不一样,这种情况下,如果使用空值的标签选择器,那么将同时选中这两个资源对象)
- 空的标签选择器(注意不是上面说的空值,而是空的,都没有定义键的名称),将无法选择出任何资源;
在基于集合的选择器中,使用“In”或者“Notin”操作时,其values可以为空,但是如果为空,这个标签选择器,就没有任何意义了。
两种标签选择器类型(基于等值、基于集合的书写方法):
selector:matchLabels: #基于等值app: nginxmatchExpressions: #基于集合- {key: name,operator: In,values: [zhangsan,lisi]} #key、operator、values这三个字段是固定的- {key: age,operator: Exists,values:} #如果指定为exists,那么values的值一定要为空
80、常用的标签分类有哪些?
标签分类是可以自定义的,但是为了能使他人可以达到一目了然的效果,一般会使用以下一些分类:
- 版本类标签(release):stable(稳定版)、canary(金丝雀版本,可以将其称之为测试版中的测试版)、beta(测试版);
- 环境类标签(environment):dev(开发)、qa(测试)、production(生产)、op(运维);
- 应用类(app):ui、as、pc、sc;
- 架构类(tier):frontend(前端)、backend(后端)、cache(缓存);
- 分区标签(partition):customerA(客户A)、customerB(客户B);
- 品控级别(Track):daily(每天)、weekly(每周)。
81、有几种查看标签的方式?
答:常用的有以下三种查看方式:
[root@master ~]# kubectl get pod --show-labels #查看pod,并且显示标签内容
[root@master ~]# kubectl get pod -L env,tier #显示资源对象标签的值
[root@master ~]# kubectl get pod -l env,tier #只显示符合键值资源对象的pod,而“-L”是显示所有的pod
82、添加、修改、删除标签的命令?
#对pod标签的操作
[root@master ~]# kubectl label pod label-pod abc=123 #给名为label-pod的pod添加标签
[root@master ~]# kubectl label pod label-pod abc=456 --overwrite #修改名为label-pod的标签
[root@master ~]# kubectl label pod label-pod abc- #删除名为label-pod的标签
[root@master ~]# kubectl get pod --show-labels#对node节点的标签操作
[root@master ~]# kubectl label nodes node01 disk=ssd #给节点node01添加disk标签
[root@master ~]# kubectl label nodes node01 disk=sss –overwrite #修改节点node01的标签
[root@master ~]# kubectl label nodes node01 disk- #删除节点node01的disk标签
83、DaemonSet资源对象的特性?
DaemonSet这种资源对象会在每个k8s集群中的节点上运行,并且每个节点只能运行一个pod,这是它和deployment资源对象的最大也是唯一的区别。所以,在其yaml文件中,不支持定义replicas,除此之外,与Deployment、RS等资源对象的写法相同。
它的一般使用场景如下:
- 在去做每个节点的日志收集工作;
- 监控每个节点的的运行状态;
84、说说你对Job这种资源对象的了解?
答:Job与其他服务类容器不同,Job是一种工作类容器(一般用于做一次性任务)。使用常见不多,可以忽略这个问题。
#提高Job执行效率的方法:
spec:parallelism: 2 #一次运行2个completions: 8 #最多运行8个template:
metadata:
85、描述一下pod的生命周期有哪些状态?
- Pending:表示pod已经被同意创建,正在等待kube-scheduler选择合适的节点创建,一般是在准备镜像;
- Running:表示pod中所有的容器已经被创建,并且至少有一个容器正在运行或者是正在启动或者是正在重启;
- Succeeded:表示所有容器已经成功终止,并且不会再启动;
- Failed:表示pod中所有容器都是非0(不正常)状态退出;
- Unknown:表示无法读取Pod状态,通常是kube-controller-manager无法与Pod通信。
86、创建一个pod的流程是什么?
- 客户端提交Pod的配置信息(可以是yaml文件定义好的信息)到kube-apiserver;
- Apiserver收到指令后,通知给controller-manager创建一个资源对象;
- Controller-manager通过api-server将pod的配置信息存储到ETCD数据中心中;
- Kube-scheduler检测到pod信息会开始调度预选,会先过滤掉不符合Pod资源配置要求的节点,然后开始调度调优,主要是挑选出更适合运行pod的节点,然后将pod的资源配置单发送到node节点上的kubelet组件上。
- Kubelet根据scheduler发来的资源配置单运行pod,运行成功后,将pod的运行信息返回给scheduler,scheduler将返回的pod运行状况的信息存储到etcd数据中心。
87、删除一个Pod会发生什么事情?
答:Kube-apiserver会接受到用户的删除指令,默认有30秒时间等待优雅退出,超过30秒会被标记为死亡状态,此时Pod的状态Terminating,kubelet看到pod标记为Terminating就开始了关闭Pod的工作;
关闭流程如下:
- pod从service的endpoint列表中被移除;
- 如果该pod定义了一个停止前的钩子,其会在pod内部被调用,停止钩子一般定义了如何优雅的结束进程;
- 进程被发送TERM信号(kill -14)
- 当超过优雅退出的时间后,Pod中的所有进程都会被发送SIGKILL信号(kill -9)。
88、K8s的Service是什么?
答:Pod每次重启或者重新部署,其IP地址都会产生变化,这使得pod间通信和pod与外部通信变得困难,这时候,就需要Service为pod提供一个固定的入口。
Service的Endpoint列表通常绑定了一组相同配置的pod,通过负载均衡的方式把外界请求分配到多个pod上
89、k8s是怎么进行服务注册的?
答:Pod启动后会加载当前环境所有Service信息,以便不同Pod根据Service名进行通信。
90、k8s集群外流量怎么访问Pod?
答:可以通过Service的NodePort方式访问,会在所有节点监听同一个端口,比如:30000,访问节点的流量会被重定向到对应的Service上面。
91、k8s数据持久化的方式有哪些?
答:
1)EmptyDir(空目录):
没有指定要挂载宿主机上的某个目录,直接由Pod内保部映射到宿主机上。类似于docker中的manager volume。
主要使用场景:
- 只需要临时将数据保存在磁盘上,比如在合并/排序算法中;
- 作为两个容器的共享存储,使得第一个内容管理的容器可以将生成的数据存入其中,同时由同一个webserver容器对外提供这些页面。
emptyDir的特性:
同个pod里面的不同容器,共享同一个持久化目录,当pod节点删除时,volume的数据也会被删除。如果仅仅是容器被销毁,pod还在,则不会影响volume中的数据。
总结来说:emptyDir的数据持久化的生命周期和使用的pod一致。一般是作为临时存储使用。
2)Hostpath:
将宿主机上已存在的目录或文件挂载到容器内部。类似于docker中的bind mount挂载方式。
这种数据持久化方式,运用场景不多,因为它增加了pod与节点之间的耦合。
一般对于k8s集群本身的数据持久化和docker本身的数据持久化会使用这种方式,可以自行参考apiService的yaml文件,位于:/etc/kubernetes/main…目录下。
3)PersistentVolume(简称PV):
基于NFS服务的PV,也可以基于GFS的PV。它的作用是统一数据持久化目录,方便管理。
在一个PV的yaml文件中,可以对其配置PV的大小,指定PV的访问模式:
ReadWriteOnce:只能以读写的方式挂载到单个节点;ReadOnlyMany:能以只读的方式挂载到多个节点;ReadWriteMany:能以读写的方式挂载到多个节点。以及指定pv的回收策略:recycle:清除PV的数据,然后自动回收;Retain:需要手动回收;delete:删除云存储资源,云存储专用;
PS:这里的回收策略指的是在PV被删除后,在这个PV下所存储的源文件是否删除)。
若需使用PV,那么还有一个重要的概念:PVC,PVC是向PV申请应用所需的容量大小,K8s集群中可能会有多个PV,PVC和PV若要关联,其定义的访问模式必须一致。定义的storageClassName也必须一致,若群集中存在相同的(名字、访问模式都一致)两个PV,那么PVC会选择向它所需容量接近的PV去申请,或者随机申请。
Mysql
Mysql性能优化
优化思路:
- 开启慢查询日志,查看哪些sql耗时长
- 查看执行慢的sql的执行计划(为优化提供方向)
- 优化查询sql(怎么优化)
- 使用【show profils】查看问题sql的使用情况(使用方法是啥)
- 调整操作系统参数优化(怎么调整)
- 升级服务硬件(什么条件下升级)
慢查询日志
1、MySQL的慢查询日志功能默认是关闭的,需要手动开启
show variables like '%slow_query%'
- 【slow_query_log】 :是否开启慢查询日志,1为开启,0为关闭。
- 【slow-query-log-file】:新版(5.6及以上版本)MySQL数据库慢查询日志存储路径。可以不设置
该参数,系统则会默认给一个缺省的文件host_name-slow.log
show variables like 'long_query_time%'
- 【long_query_time】 :慢查询阈值,当查询时间多于设定的阈值时,记录日志,【单位为秒】。
2、临时开启慢查询功能
set global slow_query_log = ON;
set global long_query_time = 1;
3、永久开启慢查询功能
#修改/etc/my.cnf配置文件,重启 MySQL, 这种永久生效.
[mysqld]
slow_query_log=ON
long_query_time=1
- 第一行:SQL查询执行的具体时间
- 第二行:执行SQL查询的连接信息,用户和连接IP
- 第三行:记录了一些我们比较有用的信息
- Query_time:这条SQL执行的时间,越长则越慢
- Lock_time:在MySQL服务器阶段(不是在存储引擎阶段)等待表锁时间
- Rows_sent:查询返回的行数
- Rows_examined:查询检查的行数,越长就当然越费时间
分析慢查询日志的工具
mysqldumpslow工具:是MySQL自带的慢查询日志工具
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/localhost-slow.log
常用参数说明:
-s:是表示按照何种方式排序
- al 平均锁定时间
- ar 平均返回记录时间
- at 平均查询时间(默认)
- c 计数
- l 锁定时间
- r 返回记录
- t 查询时间
-t:是top n的意思,即为返回前面多少条的数据
-g:后边可以写一个正则匹配模式,大小写不敏感的
查看执行计划
create table tuser(id int primary key auto_increment,name varchar(100),age int,sex char(1),address varchar(100)
);
alter table tuser add index idx_name_age(name(100),age);
alter table tuser add index idx_sex(sex(1));
insert into tuser(id,name,age,sex,address) values (1,'张三',20,'1','北京');
insert into tuser(id,name,age,sex,address) values (2,'李四',16,'1','上海');
insert into tuser(id,name,age,sex,address) values (3,'王五',34,'1','杭州');
insert into tuser(id,name,age,sex,address) values (4,'方六',26,'2','广州');
insert into tuser(id,name,age,sex,address) values (5,'季七',18,'2','上海');explain select * from tuser where id = 2
- id: SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符.
- select_type: SELECT 查询的类型。(普通查询、联合查询(union、union all)、子查询等复杂查询)
- table: 查询的是哪个表
- partitions: 匹配的分区
- type: join 类型
- possible_keys: 此次查询中可能选用的索引
- key: 此次查询中确切使用到的索引.
- ref: 哪个字段或常数与 key 一起被使用
- rows: 显示此查询一共扫描了多少行. 这个是一个估计值.
- filtered: 表示此查询条件所过滤的数据的百分比
- extra: 额外的信息
select_type(重要)
1、simple
- 不需要union操作或者不包含子查询的简单select查询
2、primary
- 个需要union操作或者含有子查询的select
3、union
- union连接的两个select查询,第一个查询是dervied派生表,除了第一个表外,第二个以后的表select_type都是union
4、dependent union
- 出现在union 或union all语句中,但是这个查询要受到外部查询的影响
5、union result
- 包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null
6、subquery
- 除了from字句中包含的子查询外,其他地方出现的子查询都可能是subquery
7、dependent subquery
- 表示这个subquery的查询要受到外部表查询的影响
8、derived
- from字句中出现的子查询,也叫做派生表,其他数据库中可能叫做内联视图或嵌套select
type(重要)
- system:表中只有一行数据或者是空表
- const:使用唯一索引或者主键
- eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。
- ref:非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体。
- fulltext:全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引
- ref_or_null:与ref方法类似,只是增加了null值的比较。
- unique_subquery:用于where中的in形式子查询,子查询返回不重复值唯一值
- index_subquery:用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重。
- range:索引范围扫描,常见于使用>,<,is null,between ,in ,like等运算符的查询中。
- index_merge:表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引
- index:select结果列中使用到了索引,type会显示为index。
- ALL:这个就是全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录。
extra(重要)
- Using filesort:说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。
- Using temporary:MySQL在对查询结果排序时使用临时表。
- using index:查询时不需要回表查询,直接通过索引就可以获取查询的结果数据。(使用到了覆盖索引)
- using where:Mysql将对storage engine提取的结果进行过滤,过滤条件字段无索引;
- Using join buffer:使用了连接缓存,比如说在查询的时候,多表join的次数非常多,那么将配置文件中的缓冲区的joinbuffer调大一些。
- impossible where:where子句的值总是false ,不能用来获取任何元组(SELECT * FROM t_user WHERE id = ‘1’ and id = ‘2’)
SQL语句优化
- 为搜索字段(where中的条件)、排序字段、select查询列,创建合适的索引,不过要考虑数据业务场景:查询多还是增删多?
- 尽量建立组合索引并注意组合索引的创建顺序,按照顺序组织查询条件、尽量将筛选粒度大的查询条件放到最左边。
- 尽量使用覆盖索引,SELECT语句中尽量不要使用*。
- 索引长度尽量短,短索引可以节省索引空间,使查找的速度得到提升,同时内存中也可以装载更多的索引键值。太长的列,可以选择建立前缀索引。
- 索引更新不能频繁,更新非常频繁的数据不适宜建索引,因为维护索引的成本。
order by、group by语句要尽量使用到索引 - order by的索引生效,order by排序应该遵循最左前缀查询,如果是使用多个索引字段进行排序,那么排序的规则必须相同(同是升序或者降序),否则索引同样会失效。
LIMIT优化
- 如果预计SELECT语句的查询结果是一条,最好使用 LIMIT 1,可以停止全表扫描。
- 处理分页会使用到LIMIT ,当翻页到非常靠后的页面的时候,偏移量会非常大,这时LIMIT的效率会非常差。(单表分页时,使用自增主键排序之后,先使用where条件 id > offset值,limit后面只写rows) (select * from (select * from tuser2 where id > 1000000 and id < 1000500 ORDER BY id) t limit 0, 20)
- 小表驱动大表,建议使用left join时,以小表关联大表(使用join的话,第一张表是必须全扫描的,以少关联多就可以减少这个扫描次数。)
- 避免全表扫描
- 避免mysql放弃索引查询
- 尽量不使用count(*)、尽量使用count(主键)
- JOIN两张表的关联字段最好都建立索引
- WHERE条件中尽量不要使用not in语句
- 合理利用慢查询日志、explain执行计划查询、show profile查看SQL执行时的资源使用情况
profile分析语句
- Query Profiler是MySQL自带的一种query诊断分析工具
- 通过它可以分析出一条SQL语句的硬件性能瓶颈在什么地方
show variables like '%profil%';
profiling : ON 表示开启
#开启profile功能
set profiling=1; --1是开启、0是关闭
-
show profile: 展示最近一条语句执行的详细资源占用信息,默认显示 Status和Duration两列
-
show profile 还可根据 show profiles 列表中的 Query_ID ,选择显示某条记录的性能分析信息
服务器层面优化
1、缓冲区优化
- 设置足够大的innodb_buffer_pool_size ,将数据读取到内存中
- 建议innodb_buffer_pool_size设置为总内存大小的3/4或者4/5
2、降低磁盘写入次数
- 生产环境,很多日志是不需要开启的,比如:通用查询日志、慢查询日志、错误日志
- 使用足够大的写入缓存 innodb_log_file_size(0.25 * innodb_buffer_pool_size)
3、MySQL数据库配置优化
innodb_buffer_pool_size #总内存大小的3/4或者4/5
innodb_flush_log_at_trx_commit=1 #控制redo log刷新到磁盘的策略
sync_binlog=1 #每提交1次事务同步写到磁盘中
innodb_max_dirty_pages_pct=30 #脏页占innodb_buffer_pool_size的比例时,触发刷脏页到磁盘。 推荐值为25%~50%。
innodb_io_capacity=200 #后台进程最大IO性能指标。默认200,如果SSD,调整为5000~20000
innodb_data_file_path #指定innodb共享表空间文件的大小
ong_qurey_time=0.3 #慢查询日志的阈值设置,单位秒
binlog_format=row #mysql复制的形式,row为MySQL8.0的默认形式。
max_connections=200 #调高该参数则应降低interactive_timeout、wait_timeout的值
innodb_log_file_size #过大,实例恢复时间长;过小,造成日志切换频繁。
general_log=0 #全量日志建议关闭,默认关闭
操作系统优化
内核参数优化
CentOS系统针对mysql的参数优化,内核相关参数(/etc/sysctl.conf),以下参数可以直接放到sysctl.conf文件的末尾。
- 增加监听队列上限:
net.core.somaxconn = 65535
net.core.netdev_max_backlog = 65535
net.ipv4.tcp_max_syn_backlog = 65535
- 加快TCP连接的回收:
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
- TCP连接接收和发送缓冲区大小的默认值和最大值:
net.core.wmem_default = 87380
net.core.wmem_max = 16777216
net.core.rmem_default = 87380
net.core.rmem_max = 16777216
- 减少失效连接所占用的TCP资源的数量,加快资源回收的效率:
net.ipv4.tcp_keepalive_time = 120
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 3
- 单个共享内存段的最大值:
kernel.shmmax = 4294967295
#这个参数应该设置的足够大,以便能在一个共享内存段下容纳整个的Innodb缓冲池的大小。
#这个值的大小对于64位linux系统,可取的最大值为(物理内存值-1)byte,建议值为大于物理
内存的一半,一般取值大于Innodb缓冲池的大小即可。
- 控制换出运行时内存的相对权重
vm.swappiness = 0
#这个参数当内存不足时会对性能产生比较明显的影响
#设置为0,表示Linux内核虚拟内存完全被占用,才会要使用交换区
增加资源限制
- 打开文件数的限制(/etc/security/limit.conf)
* soft nofile 65535
* hard nofile 65535*:表示对所有用户有效
soft:表示当前系统生效的设置(soft不能大于hard )
hard:表明系统中所能设定的最大值
nofile:表示所限制的资源是打开文件的最大数目
65535:限制的数量
- 磁盘调度策略(选用deadline)
查看调度策略的方法:
cat /sys/block/devname/queue/scheduler
修改调度策略的方法:
echo > /sys/block/devname/queue/scheduler#该模式按进程创建多个队列,各个进程发来的IO请求会被cfq以轮循方式处理,对每个IO请求都是公平
#的。该策略适合离散读的应用。
cfq (完全公平队列策略,Linux2.6.18之后内核的系统默认策略)#deadline,包含读和写两个队列,确保在一个截止时间内服务请求(截止时间是可调整的),而默认读
#期限短于写期限。这样就防止了写操作因为不能被读取而饿死的现象,deadline对数据库类应用是最好的选择。
deadline (截止时间调度策略)#noop只实现一个简单的FIFO队列,倾向饿死读而利于写,因此noop对于闪存设备、RAM及嵌入式系统是最好的选择。
noop (电梯式调度策略)#本质上与deadline策略一样,但在最后一次读操作之后,要等待6ms,才能继续进行对其它I/O请求进
#行调度。它会在每个6ms中插入新的I/O操作,合并写入流,用写入延时换取最大的写入吞吐量。
#anticipatory适合于写入较多的环境,比如文件服务器。该策略对数据库环境表现很差。
anticipatory (预料I/O调度策略)
服务器硬件优化
- 尽量选择高频率的内存
- 提升网络带宽
- 使用SSD高速磁盘
- 提升CPU性能(对于数据库并发比较高的场景,CPU的数量比频率重要;对于CPU密集型场景和频繁执行复杂SQL的场景,CPU的频率越高越好)
Prometheus
知识点总结
HTTP状态码
HTTP 状态码分类
HTTP 状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型。响应分为五类:信息响应(100–199),成功响应(200–299),重定向(300–399),客户端错误(400–499)和服务器错误 (500–599):
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
HTTP状态码列表
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
相关文章:
运维面试整理总结
面试题可以参考:面试题总结 查看系统相关信息 查看系统登陆成功与失败记录 成功:last失败:lastb 查看二进制文件 hexdump查看进程端口或连接 netstat -nltp ss -nltp补充:pidof与lsof命令 pidof [进程名] #根据 进程名 查询进程id ls…...

图数据库 Cypher语言
图数据库 属性图 属性图(Property Graph)概述 属性图是一种广泛用于建模关系数据的图数据结构,它将**顶点(节点)和边(关系)**进行结构化存储,并为它们附加属性以提供丰富的语义信…...

阿里云oss转发上线-实现不出网钓鱼
本地实现阿里云oss转发上线,全部代码在文末,代码存在冗余 实战环境 被钓鱼机器不出网只可访问内部网络包含集团oss 实战思路 若将我们的shellcode文件上传到集团oss上仍无法上线,那么就利用oss做中转使用本地转发进行上线,先发送…...

Spring Boot 3.4.0 发行:革新与突破的里程碑
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...

【网络安全】
黑客入侵 什么是黑客入侵? “黑客”是一个外来词,是英语单词hacker的中文音译。最初,“黑客”只是一个褒义词,指的是那些尽力挖掘计算机程序最大潜力的点脑精英,他们讨论软件黑客的技巧和态度,以及共享文化…...

在SQLyog中导入和导出数据库
导入 假如我要导入一个xxx.sql,我就先创建一个叫做xxx的数据库。 然后右键点击导入、执行SQL脚本 选择要导入的数据库文件的位置,点击执行即可 注意: 导入之后记得刷新一下导出 选择你要导出的数据库 右键选择:备份/导出、…...
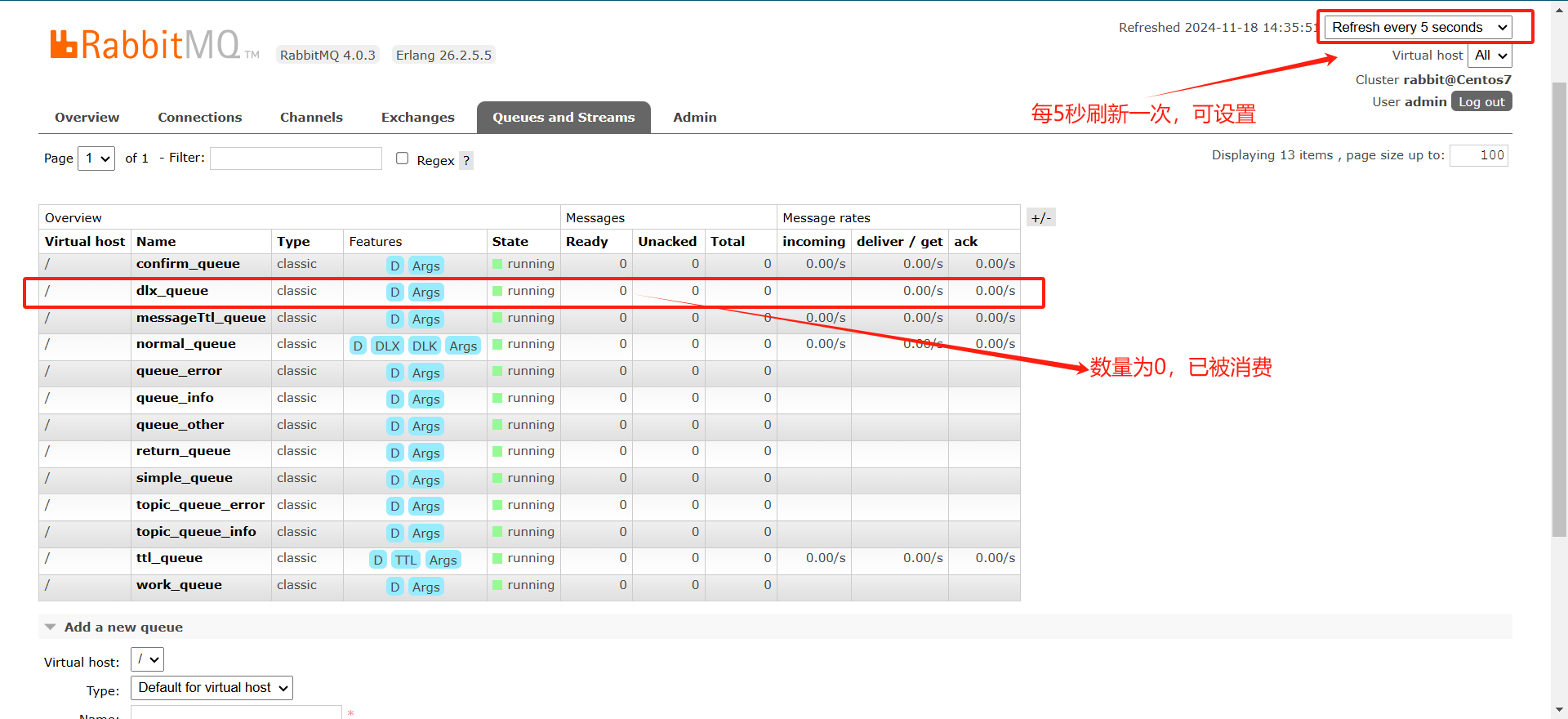
RabbitMQ简单应用
概念 RabbitMQ 是一种流行的开源消息代理(Message Broker)软件,它实现了高级消息队列协议(AMQP - Advanced Message Queuing Protocol)。RabbitMQ 通过高效的消息传递机制,主要应用于分布式系统中解耦应用…...

使用LUKS对Linux磁盘进行加密
前言 本实验用于日常学习用,如需对存有重要数据的磁盘进行操作,请做好数据备份工作。 此实验只是使用LUKS工具的冰山一角,后续还会有更多功能等待探索。 LUKS(Linux Unified Key Setup)是Linux系统中用于磁盘加密的一…...

戴尔电脑安装centos7系统遇到的问题
1,找不到启动盘(Operation System Loader signature found in SecureBoot exclusion database(‘dbx’).All bootable devices failed secure Boot Verification) 关闭 Secure Boot(推荐): 进入 BIOS/UEFI…...

3.4.SynchronousMethodHandler组件之ResponseHandler
前言 feign发送完请求后, 拿到返回结果, 那么这个返回结果肯定是需要经过框架进一步处理然后再返回到调用者的, 其中ResponseHandler就是用来处理这个返回结果的, 这也是符合正常思维的处理方式, 例如springmvc部分在调用在controller端点前后都会增加扩展点。 从图中可以看得…...

Linux 下进程的状态
操作系统中常见进程状态 在操作系统中有六种常见进程状态: 新建状态: 进程正在被创建. 此时操作系统会为进程分配资源, 如: 内存空间等, 进行初始化就绪状态: 进程已经准备好运行了, 只需要等待被调度, 获取 CPU 资源就可以执行了, 操作系统中可能同时存在多个进程处于就绪状…...

【计算机网络】核心部分复习
目录 交换机 v.s. 路由器OSI七层更实用的TCP/IP四层TCPUDP 交换机 v.s. 路由器 交换机-MAC地址 链接设备和设备 路由器- IP地址 链接局域网和局域网 OSI七层 物理层:传输设备。原始电信号比特流。数据链路层:代表是交换机。物理地址寻址,交…...
Spring Boot开发实战:从入门到构建高效应用
Spring Boot 是 Java 开发者构建微服务、Web 应用和后端服务的首选框架之一。其凭借开箱即用的特性、大量的自动化配置和灵活的扩展性,极大简化了开发流程。本文将以实战为核心,从基础到高级,全面探讨 Spring Boot 的应用开发。 一、Spring B…...

pyshark安装使用,ubuntu:20.04
1.容器创建 命令 docker run -d --name pyshark -v D:\src:/root/share ubuntu:2004 /bin/bash -c "while true;do sleep 1000;done" 用于创建并启动一个新的 Docker 容器。 docker run -d --name pyshark -v D:\src:/root/share ubuntu:2004 /bin/bash -c "w…...

基本功能实现
目录 1、环境搭建 2、按键控制灯&电机 LED 电机 垂直按键(机械按键) 3、串口调试功能 4、定时器延时和定时器中断 5、振动强弱调节 6、万年历 7、五方向按键 1、原理及分析 2、程序设计 1、环境搭建 需求: 搭建一个STM32F411CEU6工程 分析: C / C 宏定义栏…...
《那个让服务器“跳舞”的bug》
在程序的世界里,bug 就像隐藏在暗处的小怪兽,时不时跳出来捣乱。而在我的职业生涯中,有一个bug让我至今难忘,它不仅让项目差点夭折,还让我熬了无数个通宵。这个故事发生在一个风和日丽的下午,我们正在开发一…...
Python 网络爬虫进阶:动态网页爬取与反爬机制应对
在上一篇文章中,我们学习了如何使用 Python 构建一个基本的网络爬虫。然而,在实际应用中,许多网站使用动态内容加载或实现反爬机制来阻止未经授权的抓取。因此,本篇文章将深入探讨以下进阶主题: 如何处理动态加载的网…...
创建可直接用 root 用户 ssh 登陆的 Docker 镜像
有时候我们在 Mac OS X 或 Windows 平台下需要开发以 Linux 为运行时的应用,IDE 或可直接使用 Docker 容器,或 SSH 远程连接。本地命令行下操作虽然可以用 docker exec 连接正在运行的容器,但 IDE 远程连接的话 SSH 总是一种较为通用的连接方…...
wordpress 中添加图片放大功能
功能描述 使用 Fancybox 实现图片放大和灯箱效果。自动为文章内容中的图片添加链接,使其支持 Fancybox。修改了 header.php 和 footer.php 以引入必要的 CSS 和 JS 文件。在 functions.php 中通过过滤器自动为图片添加 data-fancybox 属性。 最终代码 1. 修改 hea…...

数据结构 (7)线性表的链式存储
前言 线性表是一种基本的数据结构,用于存储线性序列的元素。线性表的存储方式主要有两种:顺序存储和链式存储。链式存储,即链表,是一种非常灵活和高效的存储方式,特别适用于需要频繁插入和删除操作的场景。 链表的基本…...

库的操作.
创建、删除数据库 创建语法: CREATE DATABASE [IF NOT EXISTS] db_name[ ]是可选项,IF NOT EXISTS 是表明如果不存在才能创建数据库 //查看数据库,假设7行 show databases; //创建数据库 --- 本质在Linux创建一个目录 create database databa…...
Vue进阶之Vue CLI服务—@vue/cli-service Vuex
Vue CLI服务—vue/cli-service & Vuex vue/cli-service初识bin/vue-cli-service.js代码执行解读 Vuexgenerator/index.jsstore/index.js插件化的能力怎么引入呢? vue/cli-service 初识 第一块是上一个讲述的cli是把我们代码的配置项,各种各样的插件…...

导入100道注会cpa题的方法,导入试题,自己刷题
一、问题描述 复习备考的小伙伴们,往往希望能够利用零碎的时间和手上的试题,来复习和备考 用一个能够导入自己试题的刷题工具,既能加强练习又能利用好零碎时间,是一个不错的解决方案 目前市面上刷题工具存下这些问题 1、要收费…...

数据库操作、锁特性
1. DML、DDL和DQL是数据库操作语言的三种主要类型 1.1 DML(Data Manipulation Language)数据操纵语言 DML是用于检索、插入、更新和删除数据库中数据的SQL语句。 主要的DML语句包括: SELECT:用于查询数据库中的数据。 INSERT&a…...
学习笔记039——SpringBoot整合Redis
文章目录 1、Redis 基本操作Redis 默认有 16 个数据库,使用的是第 0 个,切换数据库添加数据/修改数据查询数据批量添加批量查询删除数据查询所有的 key清除当前数据库清除所有数据库查看 key 是否存在设置有效期查看有效期 2、Redis 数据类型String追加字…...

(笔记)简单了解ZYNQ
1、zynq首先是一个片上操作系统(Soc),结合了arm(PS)和fpga(PL)两部分组成 Zynq系统主要由两部分组成:PS(Processing System)和PL(Programmable L…...

大众点评小程序mtgsig1.2算法
测试效果: var e function _typeof(o) {return "function" typeof Symbol && "symbol" typeof Symbol.iterator? function (o) {return typeof o;}: function (o) {return o && "function" typeof Symbol &…...

七牛云AIGC内容安全方案助力企业合规创新
随着人工智能生成内容(AIGC)技术的飞速发展,内容审核的难度也随之急剧上升。在传统审核场景中,涉及色情、政治、恐怖主义等内容的标准相对清晰明确,但在AIGC的应用场景中,这些界限变得模糊且难以界定。用户可能通过交互性引导AI生成违规内容,为审核工作带来了前所未有的不可预测…...

.net的winfrom程序 窗体透明打开窗体时出现在屏幕右上角
窗体透明, 将Form的属性Opacity,由默认的100% 调整到 80%,这个数字越小越透明(尽量别低于50%,不信你试试看)! 打开窗体时出现在屏幕右上角 //构造函数 public frmCalendarList() {InitializeComponent();//打开窗体&…...
基于YOLOv8深度学习的智慧课堂教师上课行为检测系统研究与实现(PyQt5界面+数据集+训练代码)
随着人工智能技术的迅猛发展,智能课堂行为分析逐渐成为提高教学质量和提升教学效率的关键工具之一。在现代教学环境中,能够实时了解教师的课堂表现和行为,对于促进互动式教学和个性化辅导具有重要意义。传统的课堂行为分析依赖于人工观测&…...

山东网站排行/个人网站推广
package com.tiger;import java.nio.ByteBuffer;/*** 缓冲区分片案例* 在现有缓冲区对象中创建一个子缓冲区,即在现有缓冲区上切出一片作为一个新的缓冲区,* 但现有缓冲区与创建的子缓冲区在底层数组层面上是数据共享;* 也就是说,…...
佛山做网站建设公司/职业技能培训学校
昨晚与闺中密友聚餐,话题自然少不了女人世界的种种。不知怎么,话题就扯到了女人的头发上。从头发谈到染发又谈到染发剂,又从染发剂谈到经常染发有致癌的可能。一位朋友刚换了一种染发剂的颜色,浅棕色里掺杂着丝丝灰白,…...
查二级建造师个人信息查询/seo是如何优化
SqlHelper详解2008-05-24 10:40SqlHelper 类实现详细信息SqlHelper 类用于通过一组静态方法来封装数据访问功能。该类不能被继承或实例化,因此将其声明为包含专用构造函数的不可继承类。在 SqlHelper 类中实现的每种方法都提供了一组一致的重载。这提供了一种很好的…...
启动wordpress mu功能/百度网盘app下载安装官方免费下载
单例模式: 单例模式,它是指在设计一个类时,需要保证在整个运行期间针对该类只存在一个实例对象。 class BBC{private static BBC bbcnew BBC(); private BBC(){} //私有化构造方法public static BBC getBBC(){return bbc;} }类的构造…...

低价企业网站搭建/9 1短视频安装
1 修改配置文件 /etc/my.conf (为了命令 mysqldump能省略输入密码执行,mysql5.5 之后已经不建议控制台直接输入密码的方式)增加如下配置[client]hostlocalhostuserrootpassword‘password‘2 创建任务 shell# !/bin/shdd"$(date "%Y%m%d%H%M%S")&qu…...
哪家网站建设公司靠谱/手机百度正式版
今天在看王爽的《汇编语言》,看到地址总线的时候,由于那个图画的是并行传输,于是我就去搜了下地址总线是不是并行总线,结果看到一篇文章说现在串行总线的传输速度比并行总线要快,我就奇怪了。 在我的印象中,…...