机器学习—大语言模型:推动AI新时代的引擎
云边有个稻草人-CSDN博客
目录
引言
一、大语言模型的基本原理
1. 什么是大语言模型?
2. Transformer 架构
3. 模型训练
二、大语言模型的应用场景
1. 文本生成
2. 问答系统
3. 编码助手
4. 多语言翻译
三、大语言模型的最新进展
1. GPT-4
2. 开源模型
四、构建和部署一个简单的大语言模型
1. 数据准备
2. 模型训练
3. 部署模型
五、大语言模型的未来发展
结语
引言
大语言模型(Large Language Models, LLMs)是近年来人工智能(AI)领域中最具影响力的技术之一。这些模型凭借大规模的数据训练和先进的深度学习技术,在自然语言理解与生成方面表现出了卓越的能力。它们不仅能够生成高质量的文本,还在代码生成、问题解答、语言翻译等领域展现出巨大的潜力。
本文将详细介绍大语言模型的基本原理、应用场景、最新进展以及如何使用开源工具构建和部署一个简单的语言模型。
一、大语言模型的基本原理
1. 什么是大语言模型?
大语言模型是一种通过深度学习技术训练的神经网络模型,旨在理解、生成和操作自然语言。这些模型通常基于 Transformer 架构,通过大规模数据训练生成高维语义表示。
2. Transformer 架构
Transformer 是大语言模型的核心架构,其关键机制包括:
- 自注意力机制(Self-Attention):捕捉词汇间的依赖关系,理解上下文语义。
- 多头注意力(Multi-Head Attention):增强模型对不同语义特征的关注能力。
- 位置编码(Positional Encoding):保留输入序列的位置信息。
以下是一个简单的自注意力机制实现代码:
import torch
import torch.nn as nnclass SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsassert self.head_dim * heads == embed_size, "Embed size must be divisible by heads"self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(embed_size, embed_size)def forward(self, values, keys, query, mask):N = query.shape[0]value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# Split embedding into self.heads piecesvalues = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])if mask is not None:energy = energy.masked_fill(mask == 0, float("-1e20"))attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads * self.head_dim)return self.fc_out(out)
3. 模型训练
训练大语言模型需要:
- 大规模语料库:如 Common Crawl、Wikipedia。
- 优化算法:如 AdamW。
- 计算资源:通常使用数百张 GPU 或 TPU。
二、大语言模型的应用场景
1. 文本生成
LLMs 能够生成高质量的自然语言文本,应用于内容创作、新闻生成等领域。
2. 问答系统
通过微调(Fine-Tuning),LLMs 能够构建高效的问答系统,应用于智能客服和信息检索。
3. 编码助手
LLMs 能够辅助程序员完成代码补全、错误修复和优化。例如,OpenAI 的 Codex 模型。
以下是一个使用 OpenAI GPT-4 API 的代码示例:
import openai# 设置 API 密钥
openai.api_key = "your-api-key"# 调用 GPT-4 生成代码
response = openai.Completion.create(engine="gpt-4",prompt="Write a Python function to calculate factorial.",max_tokens=100
)print(response.choices[0].text.strip())
4. 多语言翻译
借助 LLMs,可以快速实现多语言翻译,应用于跨文化交流和国际化场景。
三、大语言模型的最新进展
1. GPT-4
OpenAI 的 GPT-4 是当前最先进的大语言模型之一,具备更强的推理能力和多模态支持。
2. 开源模型
- LLaMA 3:Meta 发布的开源语言模型,支持分布式训练和高效推理。
- Bloom:专注多语言处理的开源模型。
以下是使用 Hugging Face 加载开源模型的代码示例:
from transformers import AutoTokenizer, AutoModelForCausalLM# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b")# 输入文本
input_text = "What are the applications of Large Language Models?"
inputs = tokenizer(input_text, return_tensors="pt")# 生成输出
outputs = model.generate(inputs["input_ids"], max_length=50, num_return_sequences=1)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
四、构建和部署一个简单的大语言模型
1. 数据准备
准备一个包含大量文本的语料库,例如维基百科。
2. 模型训练
使用开源框架(如 PyTorch 和 Hugging Face Transformers)进行模型训练。
以下是一个简单的训练代码示例:
from transformers import GPT2Tokenizer, GPT2LMHeadModel, Trainer, TrainingArguments
from datasets import load_dataset# 加载数据集和模型
dataset = load_dataset("wikitext", "wikitext-2-raw-v1")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")# 数据预处理
def tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True)tokenized_datasets = dataset.map(tokenize_function, batched=True)# 训练参数
training_args = TrainingArguments(output_dir="./results",per_device_train_batch_size=2,num_train_epochs=3,save_steps=10_000,save_total_limit=2,prediction_loss_only=True,
)trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_datasets["train"],
)# 开始训练
trainer.train()
3. 部署模型
通过 RESTful API 或云平台(如 AWS、Azure)部署训练好的模型,以便在线推理。
五、大语言模型的未来发展
- 高效化:研究更小、更高效的模型,如 Small Language Models (SLMs),以减少计算资源需求。
- 跨模态扩展:整合视觉、音频等多模态数据。
- 更强的可解释性:开发透明的模型,便于理解和调试。
结语
大语言模型的出现标志着人工智能研究的一个重要里程碑。通过不断创新和优化,LLMs 将在更多领域释放潜力,为社会带来更多价值。
以上内容不仅展示了大语言模型的技术原理,还通过代码示例帮助读者更深入地理解其实际应用和实现过程。如果你对 LLMs 感兴趣,赶紧动手实践吧!
我是云边有个稻草人
期待与你的下一次相遇!
相关文章:

机器学习—大语言模型:推动AI新时代的引擎
云边有个稻草人-CSDN博客 目录 引言 一、大语言模型的基本原理 1. 什么是大语言模型? 2. Transformer 架构 3. 模型训练 二、大语言模型的应用场景 1. 文本生成 2. 问答系统 3. 编码助手 4. 多语言翻译 三、大语言模型的最新进展 1. GPT-4 2. 开源模型 …...

C++:探索哈希表秘密之哈希桶实现哈希
文章目录 前言一、链地址法概念二、哈希表扩容三、哈希桶插入逻辑四、析构函数五、删除逻辑六、查找七、链地址法代码实现总结 前言 前面我们用开放定址法代码实现了哈希表: C:揭秘哈希:提升查找效率的终极技巧_1 对于开放定址法来说&#…...

具身智能高校实训解决方案——从AI大模型+机器人到通用具身智能
一、 行业背景 在具身智能的发展历程中,AI 大模型的出现成为了关键的推动力量。这些大模型具有海量的参数和强大的语言理解、知识表示能力,能够为机器人的行为决策提供更丰富的信息和更智能的指导。然而,单纯的大模型在面对复杂多变的现实…...

【消息序列】详解(8):探秘物联网中设备广播服务
目录 一、概述 1.1. 定义与特点 1.2. 工作原理 1.3. 应用场景 1.4. 技术优势 二、截断寻呼(Truncated Page)流程 2.1. 截断寻呼的流程 2.2. 示例代码 2.3. 注意事项 三、无连接外围广播过程 3.1. 设备 A 启动无连接外围设备广播 3.2. 示例代…...
【RL Base】强化学习核心算法:深度Q网络(DQN)算法
📢本篇文章是博主强化学习(RL)领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对相关等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅…...

深入浅出 Python 网络爬虫:从零开始构建你的数据采集工具
在大数据时代,网络爬虫作为一种数据采集技术,已经成为开发者和数据分析师不可或缺的工具。Python 凭借其强大的生态和简单易用的语言特点,在爬虫领域大放异彩。本文将带你从零开始,逐步构建一个 Python 网络爬虫,解决实…...

美国发布《联邦风险和授权管理计划 (FedRAMP) 路线图 (2024-2025)》
文章目录 前言一、战略目标实施背景2010年12月,《改革联邦信息技术管理的25点实施计划》2011年2月,《联邦云计算战略》2011年12月,《关于“云计算环境中的信息系统安全授权”的首席信息官备忘录》2022年12月,《FedRAMP 授权法案》…...

Python语法基础(三)
🌈个人主页:羽晨同学 💫个人格言:“成为自己未来的主人~” 我们这篇文章来说一下函数的返回值和匿名函数 函数的返回值 我们先来看下面的这一段函数的定义代码 # 1、返回值的意义 def func1():print(111111111------start)num166print…...

云计算之elastaicsearch logstach kibana面试题
1.ELK是什么? ELK 其实并不是一款软件,而是一整套解决方案,是三个软件产品的首字母缩写 Elasticsearch:负责日志检索和储存 Logstash:负责日志的收集和分析、处理 Kibana:负责日志的可视化 这三款软件都是开源软件,通常是配合使用,而且又先后归于 Elastic.co 公司名下,…...

【已解决】git push需要输入用户名和密码问题
解决方法: 1)查看使用的clone方式: git remote -v 2)若为HTTPS,删除原clone方式: git remote rm origin 3)添加新的clone方式: git remote add origin gitgithub.com:zludon/git_test.git …...

python的字符串处理
需求: 编写一个程序,输入一段英文句子,统计每个单词的长度,并将单词按照长度从短到长排序。 程序逻辑框图 1、用户输入一句英文句子。 2、对输入的句子进行预处理(去空格并分割为单词列表)。 3、统计每个单…...

【线程】Java多线程代码案例(2)
【线程】Java多线程代码案例(2) 一、定时器的实现1.1Java标准库定时器1.2 定时器的实现 二、线程池的实现2.1 线程池2.2 Java标准库中的线程池2.3 线程池的实现 一、定时器的实现 1.1Java标准库定时器 import java.util.Timer; import java.util.Timer…...

虚拟机之间复制文件
在防火墙关闭的前提下,您可以通过几种不同的方法将文件从一个虚拟机复制到另一个虚拟机。这里,我们假设您想要从 IP 地址为 192.168.4.5 的虚拟机上的 /tmp 文件夹复制文件到当前虚拟机(192.168.4.6)的 /tmp 文件夹下。以下是几种…...

如何为 XFS 文件系统的 /dev/centos/root 增加 800G 空间
如何为 XFS 文件系统的 /dev/centos/root 增加 800G 空间 一、前言二、准备工作三、扩展逻辑卷1. 检查现有 LVM 配置2. 扩展物理卷3. 扩展卷组4. 扩展逻辑卷四、调整文件系统大小1. 检查文件系统状态2. 扩展文件系统五、处理可能出现的问题1. 文件系统无法扩展2. 磁盘空间不足3…...

Java算法OJ(11)双指针练习
目录 1.前言 2.正文 2.1存在重复数字 2.1.1题目 2.1.2解法一代码 解析: 2.1.3解法二代码 解析: 2.2存在重复数字plus 2.2.1题目 2.2.2代码 2.2.3解析 3.小结 1.前言 哈喽大家好吖,今天来给大家分享双指针算法的相关练习&…...

44.扫雷第二部分、放置随机的雷,扫雷,炸死或成功 C语言
按照教程打完了。好几个bug都是自己打出来的。比如统计周围8个格子时,有一个各自加号填成了减号。我还以为平移了,一会显示是0一会显示是2。结果单纯的打错了。debug的时候断点放在scanf后面会顺畅一些。中间多放一些变量名方便监视。以及mine要多显示&a…...
大语言模型LLM的微调代码详解
代码的摘要说明 一、整体功能概述 这段 Python 代码主要实现了基于 Hugging Face Transformers 库对预训练语言模型(具体为 TAIDE-LX-7B-Chat 模型)进行微调(Fine-tuning)的功能,使其能更好地应用于生成唐诗相关内容的…...

钉钉与企业微信机器人:助力网站定时任务高效实现
钉钉、企业微信机器人在网站定时任务中的应用,主要体现在自动化通知、提醒以及数据处理等方面。 以下是一些具体的应用场景: 1. 自动化通知 项目进度提醒:在蒙特网站所负责的软件开发或网站建设项目中,可以利用机器人设置定时任…...

自然语言处理工具-广告配音工具用于语音合成助手/自媒体配音/广告配音/文本朗读-已经解锁了 全功能的 apk包
Android -「安卓端」 广告配音工具用于语音合成助手/自媒体配音/广告配音/文本朗读。 广告配音工具:让您的文字“说话”,在这个快速发展的数字时代,广告配音工具为各种语音合成需求提供了一站式解决方案。无论是自媒体配音、商业广告配音、…...

深入解析注意力机制
引言随着深度学习的快速发展,注意力机制(Attention Mechanism)逐渐成为许多领域的关键技术,尤其是在自然语言处理(NLP)和计算机视觉(CV)中。其核心思想是赋予模型“关注重点”的能力…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

redis和redission的区别
Redis 和 Redisson 是两个密切相关但又本质不同的技术,它们扮演着完全不同的角色: Redis: 内存数据库/数据结构存储 本质: 它是一个开源的、高性能的、基于内存的 键值存储数据库。它也可以将数据持久化到磁盘。 核心功能: 提供丰…...
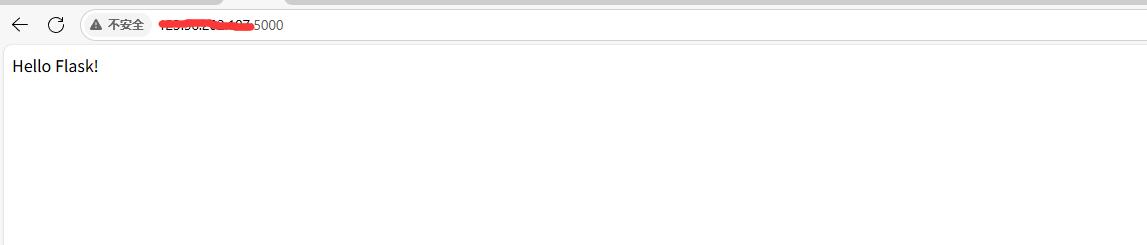
阿里云Ubuntu 22.04 64位搭建Flask流程(亲测)
cd /home 进入home盘 安装虚拟环境: 1、安装virtualenv pip install virtualenv 2.创建新的虚拟环境: virtualenv myenv 3、激活虚拟环境(激活环境可以在当前环境下安装包) source myenv/bin/activate 此时,终端…...