DBA面试题-1
面临失业,整理一下面试题,找下家继续搬砖
主要参考:https://www.csdn.net/?spm=1001.2101.3001.4476
略有修改
一、mysql有哪些数据类型
1, 整形
tinyint,smallint,medumint,int,bigint;分别占用1字节、2字节、3字节、4字节、8字节
都可以带unsigned无符号
都可以带(x)来限制显示宽度
还有float,double,decimal的小数类型
2, 字符串
varchar,char,text blob
1, char和varchar()指的是字符,不是字节;即char(10)可以存10个英文字母或者1汉字
2, char()和varchar() utf8存一个汉字占3个字节,英文字母占1个字节;Length()查看字节长度,char_length()查看字符长度;
3, char定长,尾部空格填充,性能好;varchar()变长,开头用1-2字节填充,结尾1个字节表结束
4, char对英文字符占1个字节,汉语占2个字节;varchar每个字符2个字节
5, char 0-255,varchar 65535字节长度, 存汉字要除以3
6, text又分text,mediumtext,longtext-4G
7, blob存储二进制文件
8, 推荐varchar()
9, char和varchar支持默认值,text不支持
3, 时间
datetime, date,timestamp
推荐timestamp
二, 三范式
概念
是设计关系型数据库的规范,旨在减少冗余、提高一致性和简化维护
1NF:要求每一列都是原子的,例如联系方式中如果同时包含电话、邮箱、微信等久不符合
2NF:要求每个非主属性完全依赖于主键,而不能仅仅依赖主键一部分;例如客户表的数据要依赖于客户ID,不能依赖于客户姓名;
3NF:每个非主属性都是直接依赖主键,而不是间接依赖。 例如订单明细表中,产品名称和价格依赖于产品ID,产品ID依赖于订单ID;这样构成了传递依赖,这样可以将产品信息单独放入产品表中;
三范式优缺点
范式:
优点:减少冗余、表更新快,存储空间少;
缺点:查询的时候要关联多个表,难以优化;
反范式
优点:通过冗余数据提高查询性能,减少关联,可以更好优化索引。
缺点:存在大量冗余数据,维护成本更高。
实际工作中将范式和反范式结合用,对于请求量特别高的数据可以适当反范式;
三、索引
定义
索引(Index)是一种用于提高数据库查询效率的数据结构。它类似于书籍的目录,能够帮助快速定位并检索表中的数据行。
通过索引,数据库系统可以不必扫描整个表来查找所需的数据,而是直接访问索引结构,从而显著提高查询速度。
分类
物理分类:
聚簇索引:表中索引的键值顺序和数据行的存储顺序一致;
非聚簇索引:逻辑顺序和数据行的物理顺序不一致;
应用分类:主键索引、唯一索引、普通索引、组合索引
唯一索引可以为空,且可以多个空值;
主键索引不为空;
索引优点
唯一索引可以保证唯一性
索引恶意极大加快检索效率
加速排序和分组操作
可以加速表之间的连接效率
索引缺点:
创建和维护索引需要花费时间,而且随着数据量的增加而增加;
索引会占用物理机空间
增加写操作开销,插入、更新、删除都需要对索引进行维护,这会增加操作开销,特别是大量写入时
可能降低查询性能:如果索引选择不当,会导致查询性能下降
索引设计原则
优先选择唯一性索引,速度快;
经常作为查询条件的字段选择索引;
限制索引数量
尽量使用少的做索引
清理不用的索引
索引的数据结构
B+树和HASH索引
Innodb使用的是B+树索引;
Innodb内部实现了一个自适应hash功能:当用户执行大量查询操作,且很多查询都是访问相同的页面或者寻路模式,
那么Innodb可能会在内存缓冲器中创建一个自适应hash索引,加速这些频繁的查询操作。
四、B+树结构
MySQL使用B+树作为其索引的数据结构,B+数是平衡多路搜索树,有如下特点
1, 数据存储位置: 存储在叶子节点,非叶子节点只存储索引;
2, 叶子节点连接方式:所有叶子节点通过指针相连,形成有序链表,便于顺序访问和范围查询;
3, 树高度:B+树的内部节点可以存储更多键值,因此比B-树具备更少的高度,所以在B+树中查找、删除、插入需要更少的IO
4, 查询效率:由于叶子节点间形成有序链表, 顺序访问和范围查询效率高; 效率:O(log n)
5, 插入和删除:由于数据只存储在叶子节点,所以操作只影响叶子节点和父节点,插入和删除快;
为什么MySQL用B+树不用B树
1,IO优化:B+树的非叶子节点只存储键值信息,不存储数据,所以每个节点能够存储更多的键值信息,从而查询同一层时,能够一次性读取更多数据块。减少磁盘IO操作;
B树每个节点同时存储键值和数据,增加了节点大小,进而增加IO
2, 查询效率:B+树叶子节点间形成有序链表,范围和顺序查询快;
由于B+树非叶子节点只存储键值信息,每个节点可以容纳更多键,从而降低树高度,树的高度减少意味着查找路径变短,查找效率提高
3, 动态维护:
自平衡性:B+树能够在数据发生变化时自动调整,保持树平衡。确保了查询的效率和稳定性。
插入和删除:B+树在某些情况下对插入和删除更高效,B+树可能只需要修改少量指针,而不用分裂合并
五、最左匹配原则
定义:使用联合索引时,查询条件必须从最左侧开始匹配,并且连续地使用索引。
注意: 如果查询条件中包含范围查询(>,<,between,like前缀),MySQL会停止匹配。
最左匹配原理:因为组合索引是一个B+树,例如(a,b),它会按照最左字段构建。当a相等的时候,b是有序的,但是这个有序是相对的; 所以遇上范围查询的时候就会停止继续匹配;
例如a=1 and b=2都可以命中,而a>1 and b=2无法命中
六、覆盖索引
覆盖索引(Covering Index)是一种特殊类型的索引,它不仅包含查询条件中的列,还包含要返回的列。换句话说,覆盖索引是一个包含查询所需所有列的索引,因此数据库只需查找索引,而不需要访问数据行(表),从而提高查询性能
七、什么是索引下推?
介绍
索引下推(Index condition pushdown) 简称 ICP,主要用于提升使用索引的查询效率。
在MySQL中,查询优化器会决定使用哪些索引来加速查询。当使用索引进行范围扫描时,传统的做法是先通过索引找到所有满足条件的索引项,然后回表(即访问实际的表数据)来获取完整的行数据,再在服务器层对这些行进行过滤,以确保它们满足WHERE子句中的其他条件。
索引下推技术则改变了这一流程:它将一部分过滤条件“下推”到存储引擎层,让存储引擎在扫描索引时就进行部分条件的过滤。这意味着存储引擎只返回那些真正满足所有条件的行数据给服务器层,从而减少服务器层需要处理的数据量。
索引下推的优势
1,减少数据访问,由于存储引擎在扫描时就进行了部分过滤,因此它只返回满足所有条件的行数据,减少了服务器层需要处理的数据量。
2,提高查询效率,通过减少不必要的数据访问和传输,索引下推可以显著提升性能。
3,降低IO开销:由于减少了存储引擎到服务器层的传输,从而降低了IO开销;
使用场景
索引下推通常用于带有范围扫描和复合条件的查询。例如,假设有一个表users,包含字段age和status,并且在这两个字段上建立了一个复合索引(age, status)。如果执行以下查询:
SELECT * FROM users WHERE age BETWEEN 20 AND 30 AND status = 'active';
在没有索引下推的情况下,MySQL会先通过索引找到age在20到30之间的所有行,然后回表获取这些行的完整数据,并在服务器层过滤出status = 'active'的行。
而在使用索引下推的情况下,MySQL会将status = 'active'这一条件“下推”到存储引擎层,让存储引擎在扫描索引时就进行过滤,只返回满足age BETWEEN 20 AND 30且status = 'active'的行数据给服务器层。
验证ICP是否生效?
可以使用EXPLAIN语句。在EXPLAIN的输出中,如果Extra列包含Using index condition,则表示该查询使用了索引下推优化。
八、存储
InnoDB 的四大特性?
支持事务
行级锁
外检约束
崩溃恢复
InnoDB 为何推荐使用自增主键?
1, 提高插入性能:自增主键可以保证每次插入时B+索引是从右边扩展的,可以避免B+树频繁合并和分裂。如果使用字符串主键和随机主键,会使得数据随机插入,效率比较差。
2, 减少页分裂和碎片:Innodb中,数据以页为单位进行存储。如果主键非自增,新数据插入可能导致页分裂,即原有的页无法容纳新数据需要将数据拆分到2个页中。这会增加额外的IO开销和CPU资源;
而使用自增主键的时候,数据通常都可以顺序追加到页中,减少了分页频率,提高存储效率,减少了数据碎片。由于数据按顺序追加,所以空间利用率高,减少了空间浪费。
3, 预测和缓存:使用自增主键,由于主键值是顺序递增,系统可以很容易预测下一个主键值,这种可预测性使得数据库可以更有效地利用缓存和预测机制,提前加载和缓存即将访问的数据,提高查询性能。
4, 二次索引优势:当使用自增主键时,由于聚簇索引是有序的,非聚簇索引的查询效率也会得到提升
如何选择引擎:
建议统一用Innodb
什么是Innodb的页区段?
介绍
页(page):是存储的最小单位,每一页默认 16k,是数据实际存储的页;
区(extent):逻辑概念,因为页非常多,不利于回收和管理,引入区(extent)的概念来便于资源的分配和回收,是innodb分配和回收资源的单位,每个区是连续地64 pages,即1MB;
段(segment):逻辑概念,段由一个或多个区组成,可以不连续。段是数据库的分配单位,不同类型的数据对象以不同的段形式存在。有数据段(叶子节点),索引段(非叶子节点),回滚段。
页有哪些信息组成

File Header: 文件头,描述数据页的外部信息,属于哪个表空间,前后页的页号。
Page Header: 页头,描述页的信息,有多少条记录,第一条记录的位置
infimum和superemum:系统生成的记录,分别是最小记录值和最大记录值。
User Records: 表中对应的数据,一般用Compact格式
除了表中插入的数据外还有一些隐藏列,另外还有transaction_id(事务ID), roll_pointer(回滚指针)
roll_id :有主键则指定主键,没有则用唯一索引,也没有则系统自动生成row_id;为隐藏列
Free Page:页中的空闲存储,可以插入记录。
Page Directory:类似字典的目录结构,根据主键大小每隔4-8个记录设置一个槽,用来记录其位置,当根据主键查找位置时,首先找到数据所在的槽,然后在槽中线性搜索。这种方法比遍历页要快。
Page Tailer:File Header存储刷盘前内存的校验和,Page Tailer储存刷盘后的校验和。当刷盘的时候,出现异常,Page Tailer和File Header中的校验和不一致,则说明出现刷盘错误。
页中插入记录的过程
1,如果Free Space空间足够的话,则直接分配空间来添加记录,并将插入前最后一条记录的next-record指向当前的插入记录,将当前记录的next-record指向supremum记录
2, 如果Free Space空间不够的话,将之前删除造成的碎片重新整理后,按照上述步骤重新插入
3, 如果当前页碎片整理后还不够的话,则重新申请页,将页初始化后按照上述步骤重新插入
什么是Buffer Pool
Buffer Pool是Innodb引擎层的缓冲池,不属于MySQL的Server层
内存中以页(page)为单位缓存磁盘数据,减少磁盘IO,提升访问速度。缓冲池大小默认 128M,独立的 MySQL 服务器推荐设置缓冲池大小为总内存的 80%。主要存储数据页、索引页更新缓冲(change buffer)等。
预读机制
Buffer Pool有一项技能交预读机制,存储引擎在被Server层调用时,会在响应的同时进行预判,将下次可能用到的数据和索引加载到Buffer Pool中。
预读策略分为线性预读(innodb_read_ahead_threshold)和随机预读,Innodb用线性,随机已基本废弃
线性预读:如果前面的请求顺序地访问当前区(extend)的页,那么接下来的请求也会顺序地访问下一个区的页,并将下一个区加载到BufferPool中
换页算法
Innodb的淘汰策略(换页算法)和传统的LRU(最少使用算法)不同,面临如下2个问题
1,预读失败:由于提前将数据放入BufferPool,但是MySQL最终没有从页中读取
要解决预读失败问题,则让预读失败的数据停留缓冲池时间尽可能短,预读成功的页停留尽可能长。具体将LRU链分代实现,即新生代和老年代。预读页假如缓冲池时只假如老年代的头部,只有真正预读成功了再转到新生代。如果预读失败则最先被清理。
2,缓冲池污染:如果批量扫描大量数据的时候,可能导致缓冲池所有页都被替换,导致大量热数据被换出,MySQL性能急剧下降
InnoDB Buffer Pool加入了一个老生带停留时间窗口机制,只有预读成功,并且在老年代提留时间超过该窗口时间的数据才会被放入新生代头部。
什么是Change Buffer?
如果每次写操作都更新磁盘数据,会占满IO,导致性能慢。为了减少IO,InnoDB在BufferPool中开辟了一块内存,用来存储变更记录,为了防止异常宕机丢失数据,当事务提交时会将变更记录持久化到磁盘(redo log)。等待时机更新磁盘的数据文件(刷脏),用来缓存写操作的内存就是Change Buffer。
Change Buffer默认占Buffer Pool的25%,最大50%
相关文章:
DBA面试题-1
面临失业,整理一下面试题,找下家继续搬砖 主要参考:https://www.csdn.net/?spm1001.2101.3001.4476 略有修改 一、mysql有哪些数据类型 1, 整形 tinyint,smallint,medumint,int,bigint;分别占用1字节、2字节、3字节…...

用go语言写一个小服务
文章目录 简介重新想到go 小服务main.go部署测试 结束语 简介 golang的优势 响应速度: Go > Java > Python 内存占用: Go < Java < Python 从java转go,然后go又转java,感觉就是go虽然在编译、内存占用都强于java&am…...

亚马逊开发视频人工智能模型,The Information 报道
根据《The Information》周三的报道,电子商务巨头亚马逊(AMZN)已开发出一种新的生成式人工智能(AI),不仅能处理文本,还能处理图片和视频,从而减少对人工智能初创公司Anthropic的依赖…...

WordCloud参数的用法:
-------------词云图集合------------- 用WordcloudPyQt5写个词云图生成器1.0 WordCloud去掉停用词(fit_wordsgenerate)的2种用法 通过词频来绘制词云图(jiebaWordCloud) Python教程95:去掉停用词词频统计jieba.toke…...

qml调用c++类内函数的三种方法
一.方法一:使用 Q_INVOKABLE 宏声明成员函数 1.第一步:依然需要新建一个类NetworkHandler: #include <QObject> class NetworkHandler : public QObject { Q_OBJECT public: explicit NetworkHandler(QObject *parent nullptr); Q_INVOKAB…...

NLP任务四大范式的进阶历程:从传统TF-IDF到Prompt-Tuning(提示词微调)
引言:从TF-IDF到Prompt-Tuning(提示词微调),NLP的四次变革 自然语言处理(NLP)技术从最早的手工特征设计到如今的Prompt-Tuning,经历了四个重要阶段。随着技术的不断发展,我们的目标…...

GAMES101:现代计算机图形学入门-笔记-09
久违的101图形学回归咯 今天的话题应该是比较轻松的:聊一聊在渲染中比较先进的topics Advanced Light Transport 首先是介绍一系列比较先进的光线传播方法,有无偏的如BDPT(双向路径追踪),MLT(梅特罗波利斯…...

【Db First】.NET开源 ORM 框架 SqlSugar 系列
.NET开源 ORM 框架 SqlSugar 系列 【开篇】.NET开源 ORM 框架 SqlSugar 系列【入门必看】.NET开源 ORM 框架 SqlSugar 系列【实体配置】.NET开源 ORM 框架 SqlSugar 系列【Db First】.NET开源 ORM 框架 SqlSugar 系列【Code First】.NET开源 ORM 框架 SqlSugar 系列 …...

MySQL聚合查询分组查询联合查询
#对应代码练习 -- 创建考试成绩表 DROP TABLE IF EXISTS exam; CREATE TABLE exam ( id bigint, name VARCHAR(20), chinese DECIMAL(3,1), math DECIMAL(3,1), english DECIMAL(3,1) ); -- 插入测试数据 INSERT INTO exam (id,name, chinese, math, engli…...
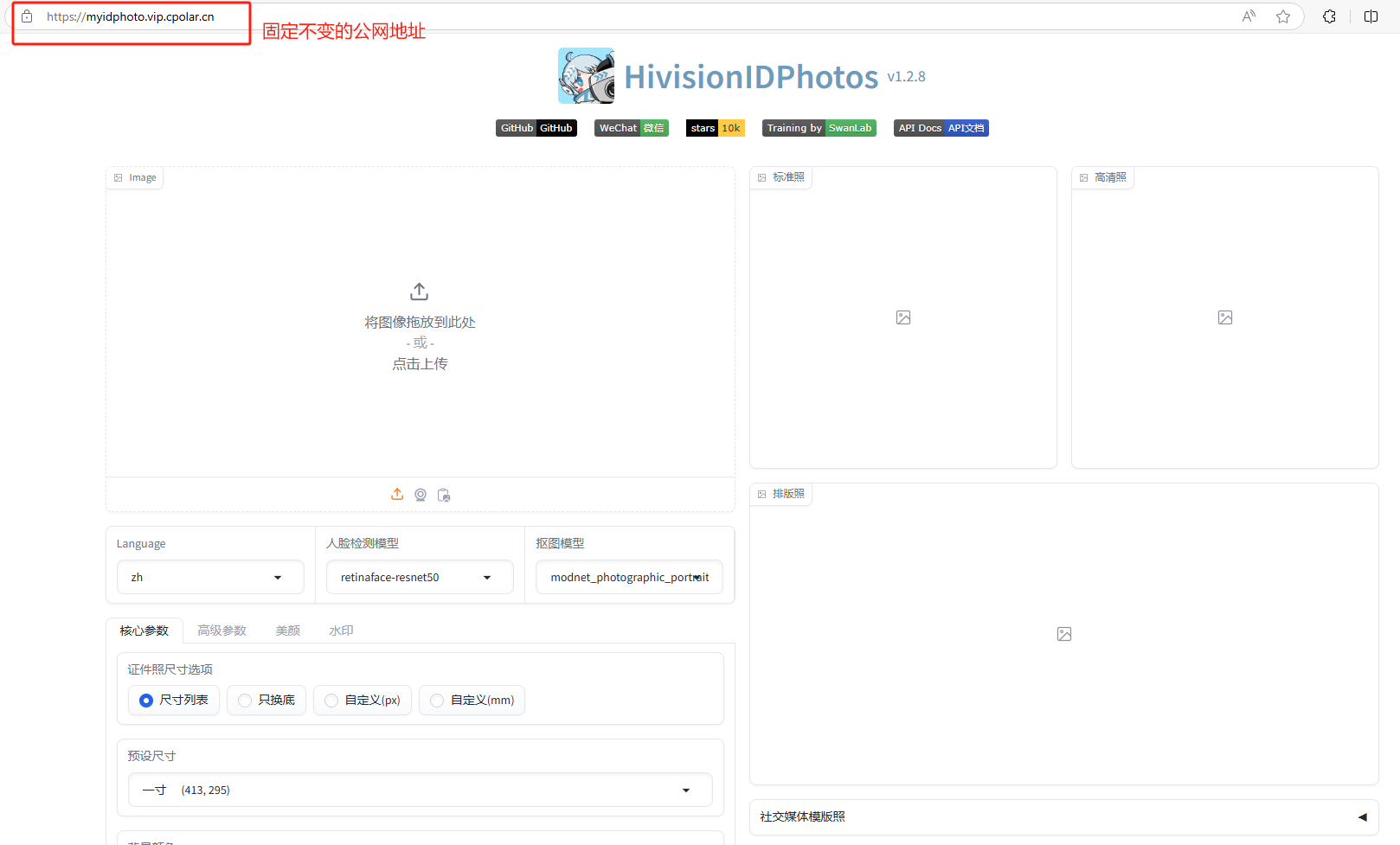
告别照相馆!使用AI证件照工具HivisionIDPhotos打造在线证件照制作软件
文章目录 前言1. 安装Docker2. 本地部署HivisionIDPhotos3. 简单使用介绍4. 公网远程访问制作照片4.1 内网穿透工具安装4.2 创建远程连接公网地址 5. 配置固定公网地址 前言 本文主要介绍如何在Linux系统使用Docker快速部署一个AI证件照工具HivisionIDPhotos,并结合…...

通信原理第三次实验
实验目的与内容 实验操作与结果 5.1 刚开始先不加入白噪声,系统设计如下: 正弦波参数设置如下: FM设计如下: 延迟设计如下: 两个滤波器设计参数如下: 输出信号频谱为(未加入噪声)&a…...

【halcon】Metrology工具系列之 get_metrology_object_result_contour
get_metrology_object_result_contour (操作员) 名称 get_metrology_object_result_contour — 查询测量对象的结果轮廓。 签名 get_metrology_object_result_contour( : Contour : MetrologyHandle, Index, Instance, Resolution : ) 描述 get_metrology_object_result_…...

A052-基于SpringBoot的酒店管理系统
🙊作者简介:在校研究生,拥有计算机专业的研究生开发团队,分享技术代码帮助学生学习,独立完成自己的网站项目。 代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 赠送计算机毕业设计600…...

NLP信息抽取大总结:三大任务(带Prompt模板)
信息抽取大总结 1.NLP的信息抽取的本质?2.信息抽取三大任务?3.开放域VS限定域4.信息抽取三大范式?范式一:基于自定义规则抽取(2018年前)范式二:基于Bert下游任务建模抽取(2018年后&a…...
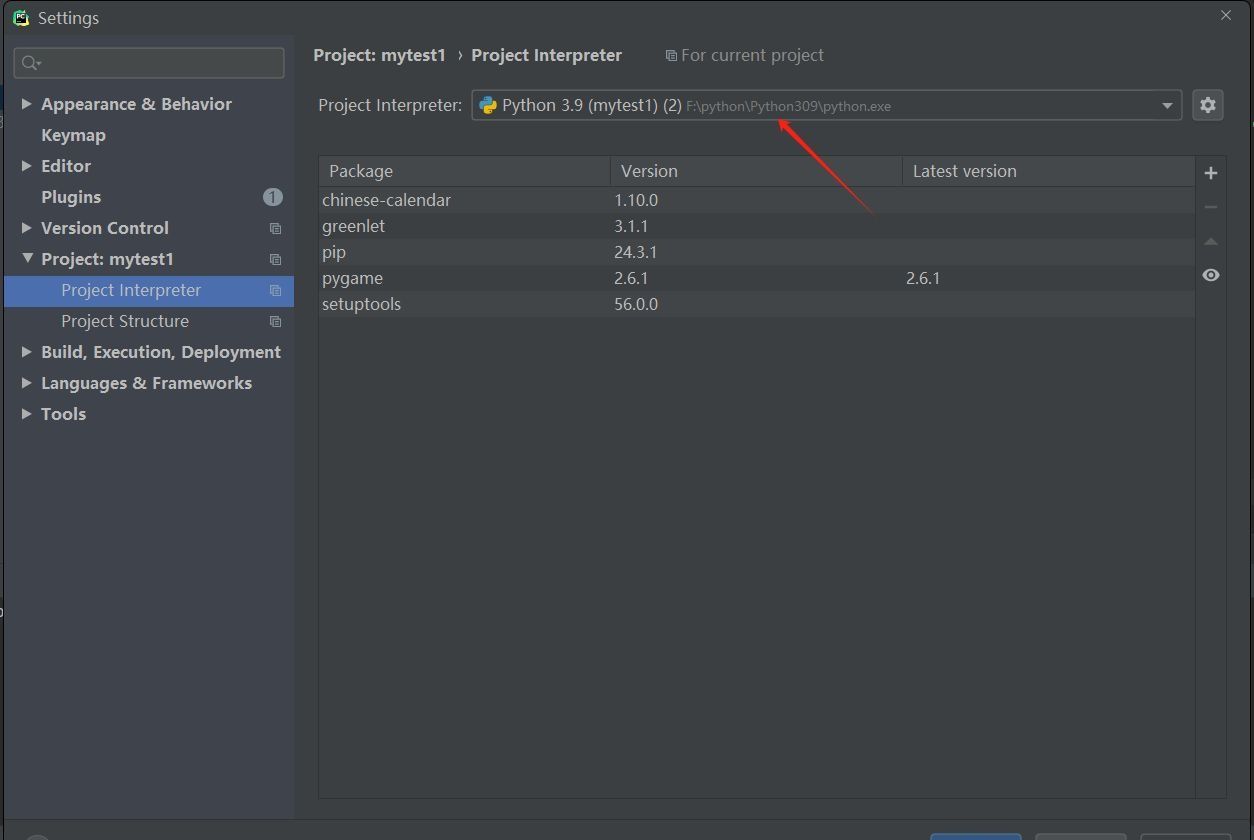
python常见问题-pycharm无法导入三方库
1.运行环境 python版本:Python 3.9.6 需导入的greenlet版本:greenlet 3.1.1 2.当前的问题 由于需要使用到greenlet三方库,所以进行了导入,以下是我个人导入时的全过程 ①首先尝试了第1种导入方式:使用pycharm进行…...

迅为RK3588开发板Android系统开发笔记-使用ADB工具
1 使用 ADB 工具 ADB 英文名叫 Android debug bridge ,是 Android SDK 里面的一个工具,用这个工具可以操作管理 Android 模拟器或者真实的 Android 设备,主要的功能如下所示: 在 Android 设备上运行 shell 终端,用命…...

什么是分布式数据库?
随着现代互联网应用和大数据时代的到来,分布式数据库成为了解决大规模数据存储和高并发处理的核心技术之一。本文将通过深入浅出的方式,带你全面理解分布式数据库的概念、工作原理以及底层实现技术。无论你是刚刚接触分布式数据库的开发者,还…...

Leetcode 3363. Find the Maximum Number of Fruits Collected
Leetcode 3363. Find the Maximum Number of Fruits Collected 1. 解题思路2. 代码实现 题目链接:3363. Find the Maximum Number of Fruits Collected 1. 解题思路 这一题是一道陷阱题…… 乍一眼看过去,由于三人的路线完全可能重叠,因此…...

【数据仓库 | Data Warehouse】数据仓库的四大特性
1. 前言 数据仓库是用于支持管理和决策的数据集合,它汇集了来自不同数据源的历史数据,以便进行多维度的分析和报告。数据仓库的四大特点是:主题性,集成性,稳定性,时变性。 2. 主题性(Subject-Oriented) …...

springboot配置多数据源mysql+TDengine保姆级教程
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pom文件二、yamlDataSourceConfigServiceMapper.xml测试总结 前言 Mybatis-plus管理多数据源,数据库为mysql和TDengine。 一、pom文件 <de…...

2025版等级保护测评报告模板:风险导向与合规深化的实践指南
1. 2025版等级保护测评报告模板的核心变革 如果你最近接触过等级保护测评工作,一定会注意到2025版报告模板带来的显著变化。这个版本最大的特点就是从过去的"得分导向"彻底转向了"风险导向"。在实际工作中,我发现很多企业安全负责人…...
ClearerVoice-Studio语音分离实用技巧:分离后各声道说话人身份标注方法
ClearerVoice-Studio语音分离实用技巧:分离后各声道说话人身份标注方法 你是不是也遇到过这种情况?用语音分离工具把一段多人对话音频分成了几个独立的声道,结果看着一堆命名为“output_1.wav”、“output_2.wav”的文件,完全搞不…...

5步打造高效工作流:Super Productivity开源工具新手实战指南
5步打造高效工作流:Super Productivity开源工具新手实战指南 【免费下载链接】super-productivity Super Productivity is an advanced todo list app with integrated Timeboxing and time tracking capabilities. It also comes with integrations for Jira, GitL…...
部署到ROS或Simulink?)
从仿真到实战:如何将你的MATLAB机械臂轨迹规划代码(3-5-3插值)部署到ROS或Simulink?
从仿真到实战:MATLAB机械臂轨迹规划代码的ROS与Simulink部署指南 当你完成了MATLAB中机械臂轨迹规划的算法开发,看着屏幕上平滑的位置、速度和加速度曲线,接下来面临的核心问题是如何将这些数据转化为真实机械臂的动作。本文将深入探讨两种主…...

TFT Overlay:云顶之弈玩家的终极装备合成与羁绊指南
TFT Overlay:云顶之弈玩家的终极装备合成与羁绊指南 【免费下载链接】TFT-Overlay Overlay for Teamfight Tactics 项目地址: https://gitcode.com/gh_mirrors/tf/TFT-Overlay 在云顶之弈的激烈对局中,你是否经常为记不住复杂的装备合成公式而烦恼…...

5大突破让暗黑2单机体验翻倍:PlugY插件全方位应用指南
5大突破让暗黑2单机体验翻倍:PlugY插件全方位应用指南 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 当你第10次因储物箱满被迫丢弃装备时,当…...
:knowledge_graph - 把任意文本转成知识图谱)
一天一个开源项目(第61篇):knowledge_graph - 把任意文本转成知识图谱
引言 “Convert any text to a graph of knowledge. Graph Retrieval Augmented Generation (GRAG) — a new and improved version of RAG.” 这是「一天一个开源项目」系列的第 61 篇文章。今天介绍的项目是 knowledge_graph(GitHub)。 想把文档、PDF…...

百度网盘提取码智能方案:从繁琐搜索到效率革命的技术跃迁
百度网盘提取码智能方案:从繁琐搜索到效率革命的技术跃迁 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 问题诊断:资源获取的现代困境 时间成本的指数级浪费 传统提取码查找流程涉及多平台切换、关键…...

Phi-3-mini-4k-instruct-gguf实战案例:用q4-GGUF模型实现10秒内短文本生成
Phi-3-mini-4k-instruct-gguf实战案例:用q4-GGUF模型实现10秒内短文本生成 1. 模型简介 Phi-3-mini-4k-instruct-gguf是微软Phi-3系列中的轻量级文本生成模型GGUF版本。这个经过优化的模型特别适合处理问答、文本改写、摘要整理和简短创作等任务。 与完整版Phi-3…...
)
别再傻傻分不清了!手把手教你选对安规电容(X1/X2/Y1/Y2等级详解)
电子工程师必读:安规电容X/Y等级实战选型指南 当你在设计一款家用空气净化器的开关电源时,突然发现EMC测试总是不达标;当你维修一台工业变频器时,发现安规电容爆裂导致设备瘫痪——这些场景背后,往往隐藏着对X1/X2/Y1/…...