论文笔记 SliceGPT: Compress Large Language Models By Deleting Rows And Columns
欲买桂花同载酒,终不似,少年游。
数学知识
秩: 矩阵中最大线性无关的行/列向量数。行秩与列秩相等。
线性无关:对于N个向量而言,如果任取一个向量 v \textbf{v} v,不能被剩下的N-1个向量通过线性组合的方式表示,则称这N个向量为线性无关。
SliceGPT: Compress Large Language Models By Deleting Rows And Columns
主要剪枝的效果:
- 将权重矩阵的尺寸缩小,变成更小的矩阵。具体而言是乘以一个Deleting Matrix: D \textbf{D} D。这个矩阵实际上是通过构造一个正交矩阵,再做PCA删除一些行/列得到。
- 减少embedding dimension。与权重矩阵的缩小对应。
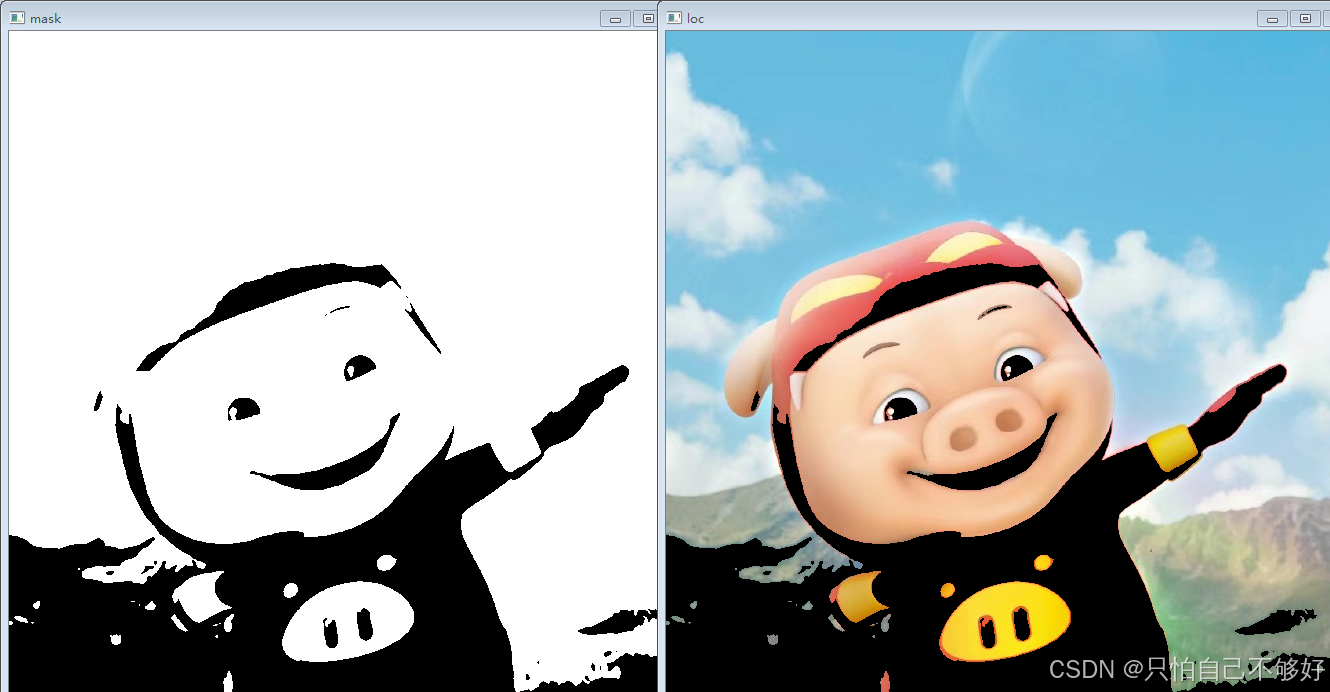
可以参考Figure 1中右图

0. Introduction
目前许多权重剪枝的方法都需要RFT(recovery fine-tuning),耗时并且可拓展性差。
- SliceGPT无需RFT也能有良好的效果。
本文的三大Contributions
- 引入了计算不变性。对于transformer中的权重矩阵做正交变换。简而言之就是乘上一个正交矩阵和正交矩阵的转置,计算结果不变。
- 使用signal matrix计算正交阵,利用PCA,在其主成分方向做投影后,与权重矩阵相乘,移去部分columns和rows以达到权重剪枝的目的。
- 在多个模型,不同任务上做实验并证明效果良好。
1. Related Work
常见的稀疏化方法:
- magnitude-based:移除绝对值较小的权重,但性能损失较大。
- OBS(optimial brain surgeon):使用Hessian矩阵来更新weight,移除对loss函数影响最小的weight。但是计算Hessian的逆过于复杂,尤其是大模型。
- 针对OBS的问题:
- 近似Hessian,如WoodFisher
- 逐层使用OBS,比如OBC(optimal brain compression)。
- GPTQ:量化权重矩阵。
- sparseGPT:半结构化/非结构化剪枝
- 仅使用Hessian的对角项(对角近似)
2. Transformer模型架构回顾。
相关信息可以参阅CSDN或知乎关于Transformer原文的详解,也可以参考我的这篇文章(内容比较简略):Transformer架构笔记
一个典型的Transformer中Encoder的结构Figure 2所示,作者把这样一个结构称为Transformer Block(不同的Transformer实现可能有所不同):

简要回顾一下Transformer的主要组件,以及约定符号表示。
一个标准的Transformer Block包含Attention Block,FFN Block,LayerNorm层。Transformer在起始阶段有embedding层将sequence转为嵌入向量,末尾有一个输出层,文中称为Language Modelling Head,将embedding转为对下一个word的预测。
-
Embeddings层:将sequence: S S S,转为embedding: X ∈ R N × D \textbf{X} \in R^{N \times D} X∈RN×D。其中 N N N为序列长度, D D D为嵌入向量的长度,同时一般也是模型当中统一的hidden dimension。 W embd ∈ R h × D W_\text{embd} \in R^{h \times D} Wembd∈Rh×D为该层的权重矩阵。 h h h为one-hot编码长度。
-
LN层(LayerNorm):标准的Transformer使用LN,而作者使用RMSNorm原因是其具有计算不变性(Computational Invariance)。RMSNorm相比于LN而言计算更简单,每个元素只除以RMS(均方根,并且这里求均方根时,统计的是 X \textbf{X} X中的所有元素: 共 N × D N \times D N×D个,这也是为什么后面要乘以一个 D \sqrt{D} D的原因。LN是对每个样本做归一化,即按行归一化)即可,LN与RMSNorm之间的关系如下:
LayerNorm ( X ) = RMSNorm ( X M ) diag ( α ) D + 1 N β ⊤ (1) \text{LayerNorm}(\mathbf{X})=\text{RMSNorm}(\mathbf{X}\mathbf{M})\text{diag}(\mathbf{\alpha})\sqrt{D}+\mathbf{1}_N\beta^\top \tag1 LayerNorm(X)=RMSNorm(XM)diag(α)D+1Nβ⊤(1)
其中:
M = I − 1 D 1 ⋅ 1 T s . t . I ∈ R D × D , 1 ∈ R D × 1 \textbf{M} = I - \frac{1}{D}1 \cdot 1^T \quad s.t. \quad I \in \mathbb{R}^{D \times D}, \ 1 \in \mathbb{R}^{D \times 1} M=I−D11⋅1Ts.t.I∈RD×D, 1∈RD×1
输入乘上 M \textbf{M} M相当于逐行减去mean。 d i a g ( α ) diag(\alpha) diag(α)为缩放系数, β \beta β为偏置项。
-
Attention Blocks:使用多头注意力, W k , W q , W v , W o , \mathbf{W}_k,\mathbf{W}_q,\mathbf{W}_v\mathrm{,}\mathbf{W}_o, Wk,Wq,Wv,Wo,分别对应K, Q, V, Output的权重矩阵。(output是一个Linear,把各个head拼接后的embedding再映射回去)。Attention Block用以下公式表示:
σ ( W i n + b i n ) W o u t + b o u t (2) \sigma(\mathbf{W}_{\mathrm{in}}+\boldsymbol{b}_{\mathrm{in}})\mathbf{W}_{\mathrm{out}}+\boldsymbol{b}_{\mathrm{out}} \tag2 σ(Win+bin)Wout+bout(2)
作者把 W k , W q , W v \mathbf{W}_k,\mathbf{W}_q,\mathbf{W}_v Wk,Wq,Wv统称为 W i n W_{in} Win,因为这几个矩阵对attention block的输入做线性变换,把 W o \mathbf{W}_o Wo称为 W o u t \mathbf{W}_{out} Wout,因为是attention中的输出层(多头注意力中把concatenated embedding映射回原维度)。 -
FFN Blocks: σ ( XW in ) W out \sigma(\textbf{XW}_\text{in})\textbf{W}_\text{out} σ(XWin)Wout。即MLP,简而言之就是先后做两次线性变换,先升维,再还原维度。
-
LM Head: XW head + b head \textbf{XW}_\text{head} + \textbf{b}_\text{head} XWhead+bhead。其中 X \textbf{X} X为最后一个FFN Block的输出。LM Head输出即为最终的预测word。
Transformer整体的前向传播流程如Algorithm1所示:

3.SliceGPT
Key Idea:Computational Invariance。即:对线性层(使用nn.Linear的层如Attention,FFN)施加正交变换,计算结果不变。
3.1 Transformer中的computational invariance的说明
- 正交矩阵的保范性:假设 Q \textbf{Q} Q为正交矩阵,则 Q Q T = I \textbf{Q}\textbf{Q}^T = \textbf{I} QQT=I,对于向量 x \textbf{x} x, ∣ ∣ Qx ∣ ∣ = x T Q T Qx = x T x = ∣ ∣ x ∣ ∣ ||\textbf{Q}\textbf{x}|| = \sqrt{\textbf{x}^T\textbf{Q}^T\textbf{Q}\textbf{x}} = \sqrt{\textbf{x}^T\textbf{x}} = || \textbf{x} || ∣∣Qx∣∣=xTQTQx=xTx=∣∣x∣∣。即向量乘以正交阵不改变其范数。这里列出的是L2范数。
作者指出RMSNorm具有计算不变性,如eq2所示,作者在Appendix A.1给出了证明:
R M S N o r m ( X ℓ Q ) Q ⊤ = R M S N o r m ( X ℓ ) . (2) \mathrm{RMSNorm}(\mathbf{X}_\ell\mathbf{Q})\mathbf{Q}^\top=\mathrm{RMSNorm}(\mathbf{X}_\ell) . \tag2 RMSNorm(XℓQ)Q⊤=RMSNorm(Xℓ).(2)
3.1(续)定理一以及证明:
定理一:作者指出,给Transformer当中的权重矩阵施加正交变换,能够保证其计算不变性:
W ~ e m b d = W e m b d Q , (3) b ~ o u t ℓ = b o u t ℓ Q , (6) W ~ i n ℓ = Q ⊤ W i n ℓ , (4) W ~ h e a d = Q ⊤ W h e a d . (7) W ~ o u t ℓ = W o u t ℓ Q , (5) \begin{array}{crcr} \tilde{\mathbf{W}}_{embd}=\mathbf{W}_{embd}\mathbf{Q}, \qquad & \text{(3)} & \qquad \tilde{\boldsymbol{b}}_{out}^{\ell}=\boldsymbol{b}_{out}^{\ell} \mathbf{Q}, \qquad & \text{(6)} \\ \tilde{\mathbf{W}}_{in}^{\ell}=\mathbf{Q}^{\top}\mathbf{W}_{in}^{\ell}, \qquad & \text{(4)} & \qquad \tilde{\mathbf{W}}_{head}=\mathbf{Q}^{\top}\mathbf{W}_{head} .\qquad & \text{(7)} \\ \tilde{\mathbf{W}}_{out}^{\ell}=\mathbf{W}_{out}^{\ell}\mathbf{Q}, \qquad & \text{(5)} & \end{array} W~embd=WembdQ,W~inℓ=Q⊤Winℓ,W~outℓ=WoutℓQ,(3)(4)(5)b~outℓ=boutℓQ,W~head=Q⊤Whead.(6)(7)
加波浪线的为变换后(microsoft实现代码中称为rotate 即旋转)
- 注:原文中eq.6为 b ~ o u t ℓ = Q ⊤ b o u t ℓ \tilde{\boldsymbol{b}}_{out}^{\ell}=\mathbf{Q}^\top\boldsymbol{b}_{out}^{\ell} b~outℓ=Q⊤boutℓ,好像有问题,正在向作者咨询。
- 注: b ~ i n ℓ = b i n ℓ , b ~ h e a d = b h e a d . \tilde{\boldsymbol{b}}_{in}^{\ell}=\boldsymbol{b}_{in}^{\ell},\tilde{\boldsymbol{b}}_{head}=\boldsymbol{b}_{head}. b~inℓ=binℓ,b~head=bhead.
在这里我们也可以简单证明一下。我们参考Algorithm 1中1-7行,对前向传播的各个步骤给出对应的公式:
1 : X ← S W e m b d 2 : X ← R M S N o r m 0 ( X ) 3 : f o r ℓ = 1 … L d o 4 : Z ← σ ℓ ( X W i n ℓ + b i n ℓ ) W o u t ℓ + b o u t ℓ 5 : X ← R M S N o r m ℓ ( X + Z ) 6 : end for 7 : return XW h e a d + b h e a d \begin{aligned} &1\colon\mathbf{X} \leftarrow S\mathbf{W}_{\mathrm{embd}}\\ &2\colon\mathbf{X} \leftarrow \mathrm{RMSNorm}_0(\mathbf{X})\\ &3\colon\mathbf{for}\ell=1\ldots L\mathbf{~do}\\ &4{:}\quad\mathbf{Z} \leftarrow \sigma_\ell(\mathbf{XW}_{\mathrm{in}}^\ell+\boldsymbol{b}_{\mathrm{in}}^\ell)\mathbf{W}_{\mathrm{out}}^\ell+\boldsymbol{b}_{\mathrm{out}}^\ell\\ &5{:}\quad\mathbf{X} \leftarrow \mathrm{RMSNorm}_\ell(\mathbf{X}+\mathbf{Z})\\ &6{:}\textbf{ end for}\\ &7{:}\textbf{ return XW}_{\mathrm{head}}+\mathbf{b}_{\mathrm{head}} \end{aligned} 1:X←SWembd2:X←RMSNorm0(X)3:forℓ=1…L do4:Z←σℓ(XWinℓ+binℓ)Woutℓ+boutℓ5:X←RMSNormℓ(X+Z)6: end for7: return XWhead+bhead
其中 S ∈ R N × h , W e m b d ∈ R h × D , W h e a d ∈ R D × h S \in R^{N \times h}, \mathbf{W}_{\mathrm{embd}} \in R^{h \times D},\mathbf{W}_{\mathrm{head}} \in R^{D \times h} S∈RN×h,Wembd∈Rh×D,Whead∈RD×h。为了简化,统一认为 W i n , W o u t ∈ R D × D \mathbf{W}_{\mathrm{in}}, \mathbf{W}_{\mathrm{out}} \in R^{D \times D} Win,Wout∈RD×D。其中 N N N为序列长度, h h h为one-hot编码的长度, D D D为hidden dimension(或者叫embedding dimension)。
施加正交矩阵 Q \mathbf{Q} Q后的各步骤公式如下,我们将 X , X ~ \mathbf{X}, \tilde{\mathbf{X}} X,X~分别表示为施加正交变换前,正交变换后block的输入/输出:
-
line1 : S W ~ e m b d = S W e m b d Q = X Q → X ~ \text{line1}: S\tilde{\mathbf{W}}_{\mathrm{embd}} = S\mathbf{W}_{\mathrm{embd}}\mathbf{Q} = \mathbf{XQ} \rightarrow \tilde{\mathbf{X}} line1:SW~embd=SWembdQ=XQ→X~
-
line2 : RMSNorm ( X ~ ) = RMSNorm ( X Q ) = RMSNorm ( X ) Q → X ~ \text{line2}: \text{RMSNorm}(\tilde{\mathbf{X}}) = \text{RMSNorm}(\mathbf{X}\mathbf{Q}) = \text{RMSNorm}(\mathbf{X})\mathbf{Q} \rightarrow \tilde{\mathbf{X}} line2:RMSNorm(X~)=RMSNorm(XQ)=RMSNorm(X)Q→X~
-
line4 : σ ℓ ( X ~ W ~ i n ℓ + b ~ i n ℓ ) W ~ o u t ℓ + b ~ o u t ℓ = σ ℓ ( X Q Q ⊤ W i n ℓ + b i n ℓ ) W o u t ℓ Q + b o u t ℓ Q = ( σ ℓ ( X W i n ℓ + b i n ℓ ) W o u t ℓ + b o u t ℓ ) Q = Z Q → Z ~ \text{line4}: \sigma_\ell(\mathbf{\tilde{X}\tilde{W}}_{\mathrm{in}}^\ell+\boldsymbol{\tilde{b}}_{\mathrm{in}}^\ell)\mathbf{\tilde{W}}_{\mathrm{out}}^\ell+\boldsymbol{\tilde{b}}_{\mathrm{out}}^\ell = \sigma_\ell(\mathbf{X Q Q^\top W}_{\mathrm{in}}^\ell+\boldsymbol{b}_{\mathrm{in}}^\ell)\mathbf{W}_{\mathrm{out}}^\ell \mathbf{Q}+\boldsymbol{b}_{\mathrm{out}}^\ell \mathbf{Q} = (\sigma_\ell(\mathbf{XW}_{\mathrm{in}}^\ell+\boldsymbol{b}_{\mathrm{in}}^\ell)\mathbf{W}_{\mathrm{out}}^\ell+\boldsymbol{b}_{\mathrm{out}}^\ell)\mathbf{Q} = \mathbf{ZQ} \rightarrow \tilde{\mathbf{Z}} line4:σℓ(X~W~inℓ+b~inℓ)W~outℓ+b~outℓ=σℓ(XQQ⊤Winℓ+binℓ)WoutℓQ+boutℓQ=(σℓ(XWinℓ+binℓ)Woutℓ+boutℓ)Q=ZQ→Z~
-
line5 : RMSNorm ( X ~ + Z ~ ) = RMSNorm ( X Q + Z Q ) = RMSNorm ( X + Z ) Q = X Q → X ~ \text{line5}: \text{RMSNorm}(\tilde{\mathbf{X}} + \tilde{\mathbf{Z}}) = \text{RMSNorm}(\mathbf{XQ} + \mathbf{ZQ}) = \text{RMSNorm}(\mathbf{X} + \mathbf{Z})\mathbf{Q} = \mathbf{XQ} \rightarrow \mathbf{\tilde{X}} line5:RMSNorm(X~+Z~)=RMSNorm(XQ+ZQ)=RMSNorm(X+Z)Q=XQ→X~
-
line7 : X ~ W ~ head + b ~ head = X Q Q ⊤ W head + b head = X W head + b head → X ~ = X \text{line7}: \mathbf{\tilde{X}}\mathbf{\tilde{W}}_\text{head} + \boldsymbol{\tilde{b}}_\text{head} = \mathbf{X Q Q^\top W_\text{head}} + \boldsymbol{b}_\text{head} = \mathbf{X W_\text{head}} + \boldsymbol{b}_\text{head} \rightarrow \mathbf{\tilde{X}} = \mathbf{X} line7:X~W~head+b~head=XQQ⊤Whead+bhead=XWhead+bhead→X~=X
发现 line7 \text{line7} line7 结果相等。综上,可以证明变换前后输出不变。
3.2 Transformer中LN向RMSNorm的转换:
根据eq.1我们可以知道LN与RMSNorm之间存在转换关系。其中最重要的两个就是mean-substraction: M \mathbf{M} M,以及系数: diag ( α ) \text{diag}(\alpha) diag(α)。作者指出,可以将LayerNorm中的这两个步骤分别放在前一个Block与后一个Block当中,如Figure 3所示。可以对比一下Figure 2与Figure 3有哪些不同。

可以发现, W in \mathbf{W}_\text{in} Win都是左乘 diag ( α ) \text{diag}(\alpha) diag(α),而 W out \mathbf{W}_\text{out} Wout均为右乘 M \mathbf{M} M。除了考虑Figure 3中所包含的Attention Block以及FFN Block当中的 W in \mathbf{W}_\text{in} Win与 W out \mathbf{W}_\text{out} Wout以外,考虑 W embd , W head \mathbf{W}_\text{embd}, \mathbf{W}_\text{head} Wembd,Whead应该分别左乘 diag ( α ) \text{diag}(\alpha) diag(α)、右乘 M \mathbf{M} M。(这里其实很好理解,因为embedding层位于第一个LN层的前面,而LM Head层恰好在最后一个LN层的后面)
用矩阵运算求均值:乘以矩阵 M M M即可。对最后一个维度求均值(对一行求均值):
M = I − 1 D 1 ⋅ 1 T s . t . I ∈ R D × D , 1 ∈ R D × 1 M = I - \frac{1}{D}1 \cdot 1^T \quad s.t. \quad I \in \mathbb{R}^{D \times D}, \ 1 \in \mathbb{R}^{D \times 1} M=I−D11⋅1Ts.t.I∈RD×D, 1∈RD×1
因此严格来说,将LayerNorm中的均值相减操作融合至前一个block后,似乎与原始的模型不太一致,因为矩阵乘法不遵循交换律。但代码实现中直接对权重矩阵做了mean-substraction操作。本人理解可能是作者为了简便,以及希望可以pre-compute W in \mathbf{W}_\text{in} Win 的一种权宜之计。(这里加粗处存疑,如有问题请大佬指正)
3.3 Transformation Per Block
作者指出,对不同的Block,应该根据当前输入的signal matrix的不同,计算得到不同的正交阵 Q \mathbf{Q} Q。但是Algorithm 1中 line 5 \text{line 5} line 5会存在等式不相等的情况:
( X ~ + Z ~ ) = ( X Q ℓ − 1 + Z Q ℓ ) ≠ ( X + Z ) Q ℓ . 因为不同Block正交阵不相等 (\tilde{\mathbf{X}} + \tilde{\mathbf{Z}}) = (\mathbf{X}\mathbf{Q}_{\ell - 1} + \mathbf{Z}\mathbf{Q}_\ell) \neq (\mathbf{X} + \mathbf{Z})\mathbf{Q}_\ell. \quad \text{因为不同Block正交阵不相等} (X~+Z~)=(XQℓ−1+ZQℓ)=(X+Z)Qℓ.因为不同Block正交阵不相等
本质原因是存在Residual Connection。故每一个残差连接对应的 X \textbf{X} X应当右乘 Q ℓ − 1 Q ℓ \mathbf{Q}_{\ell - 1}\mathbf{Q}_\ell Qℓ−1Qℓ,以保证 line 5 \text{line 5} line 5等式成立。
最终的经过变换后的Transformer Block示意图如Figure 4所示:

3.3(续)如何构造正交阵Q
作者提出根据每一层不同的signal matrix,分别构造不同的正交阵。公式如下:
C ℓ = ∑ i X ℓ , i ⊤ X ℓ , i (8) \mathbf{C}_{\ell}=\sum_{i}\mathbf{X}_{\ell,i}^{\top}\mathbf{X}_{\ell,i} \tag8 Cℓ=i∑Xℓ,i⊤Xℓ,i(8)
其中 X ℓ , i \mathbf{X}_{\ell,i} Xℓ,i表示第 ℓ \ell ℓ个 RMSNorm \text{RMSNorm} RMSNorm层对于第 i i i个sequence的输出。 Q ℓ \mathbf{Q}_\ell Qℓ即为 C ℓ \mathbf{C}_{\ell} Cℓ经过特征分解后,按特征值从大到小排列的所有特征向量所构成的矩阵。
注: C ℓ \mathbf{C}_{\ell} Cℓ为对称矩阵,有什么意义?首先实对称矩阵的特征值肯定为实数。
3.4 Slicing
类似PCA当中的操作,选取 Q \mathbf{Q} Q的特征值最大的 D small D_\text{small} Dsmall个特征向量,构造删除矩阵 D ∈ R D × D small \mathbf{D} \in R^{D \times D_\text{small}} D∈RD×Dsmall,将 X \mathbf{X} X映射为一个低纬度的特征 Z \mathbf{Z} Z,然后再经过正交阵的转置,又变换回 X ~ \tilde{\mathbf{X}} X~,相当于reconstruction的过程。如以下公式所示:
Z = X Q D , X ~ = Z D ⊤ Q ⊤ . (9) \mathbf{Z}=\mathbf{X}\mathbf{Q}\mathbf{D}\mathrm{~,~~~~}\tilde{\mathbf{X}}=\mathbf{Z}\mathbf{D}^{\top}\mathbf{Q}^{\top}. \tag9 Z=XQD , X~=ZD⊤Q⊤.(9)
具体的slice过程如下图所示(Figure 1的右图)

多头注意力机制实现方法:
- 第一种实现:将输入向量降维成多个低维向量,比如8个头,embedding维度为512,那么就有24个Linear(512, 64),其中8个作为 W q W_q Wq,8个作为 W k W_k Wk,8个作为 W v W_v Wv,这里Linear(512, 64)即是权重矩阵,也起到降维作用。然后8个降维后的向量各自做各自的attention,得到attention中每个head的输出(每个维度为64),再把这8个输出拼接起来,得到维度为512,然后再经过一个线性层Linear(512,512),得到multi-head attention最终的输出。
- 第二种实现:还是8个头的注意力机制,但是 W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv都只有一个,为Linear(512,512),然后将 W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv输出的embedding reshape(使用view函数),把shape变换为[N, seq, head_num, head_dim]分别对应为样本数,序列长度,head数量,每个head分得的维度数(比如8个头,则shape为[N, seq, 8, 64]),然后直接做点乘,最后再reshape将维度变换回去,再经过线性层Linear(512,512),得到多头注意力机制的最终输出。
问题
- 如何做Fusion?即如何将LN中的Linear operation融合至相邻线性层?
Embedding层只做了mean substraction。其余层直接和LN层的参数做element-wise multiplication。相当于乘以了缩放系数,这里没问题。 - 如何求解正交矩阵 Q \mathbf{Q} Q?对signal matrix(指的是input / embedding)使用PCA,QR分解(后续需补充QR分解和特征分解的关系)。
- 文中提到哪些部分不能pre-computed?指的是 Q ℓ − 1 Q ℓ \mathbf{Q}_{\ell - 1}\mathbf{Q}_\ell Qℓ−1Qℓ,可以从代码实现中看到,该算法是一边forward,一边剪枝,也就是需要等当前的Block前向传播完毕后,拿到当前Block的输出(下一个Block的输入),才能开始计算下一个Block的 Q \mathbf{Q} Q。比如当前是第 ℓ − 1 \ell - 1 ℓ−1个Block,等这一个Block前向传播完毕后,才能开始算 Q ℓ \mathbf{Q}_{\ell} Qℓ。
- Norm层的可学习参数是指的哪些?指 γ , β \gamma,\beta γ,β即缩放系数和偏移量: https://www.cnblogs.com/tian777/p/17911800.html
- Convolutional Layer是否也具有计算不变性?
- LN层为什么不具备计算不变性?
- 解释RMSNorm为什么具备计算不变性?
词语释义
cornerstone 基石
post-hoc = after this 事后的adj./事后adv.
complementary 补充的
undertaking 任务/项目
so long as 只要
whilst 与此同时
参考链接
- SliceGPT原文链接
- SliceGPT源码
- LLM大模型压缩——ICLR 2024 SliceGPT(原理详解)
- SliceGPT概述
- Phi-2 Transformer模型代码
(作者的实验代码中给出了Phi-2对应的ModelAdapter以及LayerAdapter的实现) - 机器之心: SliceGPT
相关文章:
论文笔记 SliceGPT: Compress Large Language Models By Deleting Rows And Columns
欲买桂花同载酒,终不似,少年游。 数学知识 秩: 矩阵中最大线性无关的行/列向量数。行秩与列秩相等。 线性无关:对于N个向量而言,如果任取一个向量 v \textbf{v} v,不能被剩下的N-1个向量通过线性组合的方式…...

前端工具的选择和安装
选择和安装前端工具是前端开发过程中的重要步骤。现代前端开发需要一些工具来提高效率和协作能力。以下是一些常用的前端工具及其选择和安装指南。 1. 代码编辑器 选择一个好的代码编辑器可以显著提高开发效率。以下是几款流行的代码编辑器: Visual Studio Code (…...

Fantasy中定时器得驱动原理
一、服务器框架启动 public static async FTask Start(){// 启动ProcessStartProcess().Coroutine();await FTask.CompletedTask;while (true){ThreadScheduler.Update();Thread.Sleep(1);}} 二、主线程 Fantasy.ThreadScheduler.Update internal static void Update(){MainS…...

【反转链表】力扣 445. 两数相加 II
一、题目 二、思路 加法运算是从低位开始,向高位进位,因此需要将两个链表进行反转,再进行对齐后的相加操作。力扣 2. 两数相加 三、题解 /*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode …...

SpringBoot 项目中使用 spring-boot-starter-amqp 依赖实现 RabbitMQ
文章目录 前言1、application.yml2、RabbitMqConfig3、MqMessage4、MqMessageItem5、DirectMode6、StateConsumer:消费者7、InfoConsumer:消费者 前言 本文是工作之余的随手记,记录在工作期间使用 RabbitMQ 的笔记。 1、application.yml 使…...

Uniapp 安装安卓、IOS模拟器并调试
一、安装Android模拟器并调试 1. 下载并安装 Android Studio 首先下载 Mac 环境下的 Android Studio 的安装包,为dmg 格式。 下载完将Android Studio 向右拖拽到Applications中,接下来等待安装完成就OK啦! 打开过程界面如下图所示…...

JavaScript 中的原型和原型链
JavaScript 中的原型和原型链也是一个相对较难理解透彻的知识点,下面结合详细例子来进行说明: 一、原型的概念 在 JavaScript 中,每个函数都有一个 prototype 属性,这个属性指向一个对象,这个对象就是所谓的 “原型对…...

数组变换(两倍)
数组变换 以最大元素为基准元素,判读其他元素能否通过 x 2 成为最大值! 那么怎么判断呢: max % arr[i] 0arr[i] * 2 ^n max int x 2 ^ n max / arr[i] 3.只需判断 这个 x 是不是 2 的 n 次放就可以了! 判断 是否为 2 的 n 次 …...

GBN协议、SR协议
1、回退N步(Go-Back-N,GBN)协议: 总结: GBN协议的特点: (1)累计确认机制:当发送方收到ACKn时,表明接收方已正确接收序号为n以及序号小于n的所有分组,发送窗…...

三维扫描检测仪3d扫描测量尺寸-自动蓝光测量
在现代工业及生产过程中,精确、高效的尺寸检测是保证产品质量、提升生产效率的关键因素。 红、蓝光测量,以其高精度、高效率和非接触式的特点,在工业及生产中发挥着越来越重要的作用。蓝光测量技术利用蓝色激光光源,通过扫描被测…...

大模型翻译能力评测
1. 背景介绍 随着自然语言处理技术的飞速发展,机器翻译已经成为一个重要的研究领域。近年来,基于大模型的语言模型在机器翻译任务上取得了显著的进展。这些大模型通常具有数亿甚至数千亿的参数,能够更好地理解和生成自然语言。 但是…...

MySQL隐式转换造成索引失效
一、什么是 MySQL 的隐式转换? MySQL 在执行查询语句时,有时候会自动帮我们进行数据类型的转换,这个过程就是隐式转换。比如说,我们在一个 INT 类型的字段上进行查询,但是传入的查询条件却是字符串类型的值,…...

SuperMap Objects组件式GIS开发技术浅析
引言 随着GIS应用领域的扩展,GIS开发工作日显重要。一般地,从平台和模式上划分,GIS二次开发主要有三种实现方式:独立开发、单纯二次开发和集成二次开发。上述的GIS应用开发方式各有利弊,其中集成二次开发既可以充分利…...

多组数输入a+b:JAVA
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 输入描述: 输入包含多组数据,每组数据输入一行,包含两个整数 输出描述: 对于每组数据输出一行包含一个整数表示两个整数的和 代码: import java.util.Scanner; pu…...

R语言结构方程模型(SEM)在生态学领域中的应用
目录 专题一、R/Rstudio简介及入门 专题二、结构方程模型(SEM)介绍 专题三:R语言SEM分析入门:lavaan VS piecewiseSEM 专题四:SEM全局估计(lavaan)在生态学领域高阶应用 专题五࿱…...

架构-微服务-服务调用Dubbo
文章目录 前言一、Dubbo介绍1. 什么是Dubbo 二、实现1. 提供统一业务api2. 提供服务提供者3. 提供服务消费者 前言 服务调用方案--Dubbo 基于 Java 的高性能 RPC分布式服务框架,致力于提供高性能和透明化的 RPC远程服务调用方案,以及SOA服务治理方案。…...

【SpringBoot问题】IDEA中用Service窗口展示所有服务及端口的办法
1、调出Service窗口 打开View→Tool Windows→Service,即可显示。 2、正常情况应该已经出现SpringBoot,如下图请继续第三步 3、配置Service窗口的项目启动类型。微服务一般是Springboot类型。所以这里需要选择一下。 点击最后一个号,点击Ru…...
OpenCV 图像轮廓查找与绘制全攻略:从函数使用到实战应用详解
摘要:本文详细介绍了 OpenCV 中用于查找图像轮廓的 cv2.findContours() 函数以及绘制轮廓的 cv2.drawContours() 函数的使用方法。涵盖 cv2.findContours() 各参数(如 mode 不同取值对应不同轮廓检索模式)及返回值的详细解析,搭配…...

电机驱动MCU介绍
电机驱动MCU是一种专为电机控制设计的微控制器单元,它集成了先进的控制算法和高性能的功率输出能力。 电机驱动MCU采用高性能的处理器核心,具有快速的运算速度和丰富的外设接口。它内置了专业的电机控制算法,包括PID控制、FOC(Fi…...

人工智能学习框架详解及代码使用案例
人工智能学习框架详解及代码使用案例 人工智能(AI)学习框架是构建和训练AI模型的基础工具,它们提供了一组预定义的算法、函数和工具,使得开发者能够更快速、更高效地构建AI应用。本文将深入探讨人工智能学习框架的基本概念、分类、优缺点、选择要素以及实际应用,并通过代…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...

解决:Android studio 编译后报错\app\src\main\cpp\CMakeLists.txt‘ to exist
现象: android studio报错: [CXX1409] D:\GitLab\xxxxx\app.cxx\Debug\3f3w4y1i\arm64-v8a\android_gradle_build.json : expected buildFiles file ‘D:\GitLab\xxxxx\app\src\main\cpp\CMakeLists.txt’ to exist 解决: 不要动CMakeLists.…...