基于开源云原生数据仓库 ByConity 体验多种数据分析场景
基于开源云原生数据仓库 ByConity 体验多种数据分析场景
- 业务背景
- 什么是 ByConity
- 上手实测
- 环境要求
- 测试操作
- 远程登录 ECS 服务器
- windows10 自带连接工具
- 执行查询
- ByConity 相对于 ELT 能力的优化
- 提升并行度
- 任务级重试
- 并行写入
- 简化数据链路
业务背景
大家都知道,在现在这个数据量飞速增长的数据为王时代,任何一家企业只有对自身的企业数据有精准的分析和研判,那么才能掌握数据密码,从而掌握这个时代盈利的秘诀。因此,高效的数据处理和分析能力已经成为企业竞争力的关键。
在实际业务中,用户会基于不同的产品分别构建实时数仓和离线数仓。其中,实时数仓强调数据能够快速入库,且在入库的第一时间就可以进行分析,低时延的返回分析结果。而离线数仓强调复杂任务能够稳定的执行完,需要更好的内存管理。
什么是 ByConity
我们今天的主角是 ByConity,那么什么是 ByConity?
ByConity 是字节跳动开源的云原生数据仓库,可以满足用户的多种数据分析场景。并且,ByConity 增加了 bsp 模式:可以进行 task 级别的容错;更细粒度的调度;基于资源感知的调度。希望通过 bsp 能力,把数据加工(T)的过程转移到 ByConity 内部,能够一站式完成数据接入、加工和分析。

上手实测
在对当前数字驱动时代下的企业处境有了一个基础的了解后,我们又了解了开源的云原生数据仓库 ByConity。下面就正式开始今天的上手实测吧。
为了实际上手感受 bsp 模式带来的效果,官方为我们提供了使用 TPC-DS 1TB 的数据测试活动,让我们可以亲自验证 ByConity 在 ELT 方面的实际感受。
环境要求
由于要测试的是大数据量的数据加工和分析,因此对于环境的要求也相对比较高,官方为我们提供了一个测试集群,下面是集群规格

测试操作
远程登录 ECS 服务器
开始操作之前首先需要登录 ECS 服务器,我们可以通过本地 SSH 工具连接到 ECS 服务器,打开本地远程连接工具 Xshell,点击【新建会话】,输入 ECS 服务器 IP 地址,选择端口 23

继续点击【用户身份验证】选择密码登录方式,输入用户名、密码,点击【确定】

这里需要说明一下,我用我本地自带的 Xshell 5 远程连接服务器工具没有成功,提示如下【找不到匹配的 host key 算法。】,我理解应该是我本地的连接远程工具太老了,很久没更新导致的。那么下面我采用第二种链接方法,采用 windows10 自带的远程连接工具。
windows10 自带连接工具
这里在本地磁盘新建一个文件夹,在文件夹内点击 ctrl+shift+鼠标右键 选中【在此处打开 Powershell 窗口(S)】打开自带的命令行工具

在命令行工具输入以下命令,并回车确认
ssh -p 23 <提供的用户名>@<ECS服务器IP地址>
# ssh -p 23 root@14.103.145.182
这时会出现一句提示,我们输入 yes 点击回车
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
随后会提示让我们输入密码,我们输入密码后点击回车即可登录 ECS 服务器。这里需要注意的是密码一定要手输入,粘贴的密码这里不能识别

为了避免连接超时导致断开连接,频繁输入密码耽误时间,我们可以执行命令
tmux new -s $user_id
# tmux new -s $user_2024
创建一个新的 tmux 会话,其中$user_id是可以自定义的会话名称。(后续重新登录时,使用 tmux a -t $user_id)。
继续输入命令执行,进入客户端
clickhouse client --port 9010

执行查询
首先切换到测试用数据库 test_elt
use test_elt
TPC-DS 定义的查询语法为标准 SQL,因此设置数据库会话的方言类型为 ANSI
set dialect_type = 'ANSI'
执行后结果如图

选择 TPC-DS 的 99 个查询中你希望的执行,因为 q78 查询会因为内存限制而执行失败,所以我们优先执行 q78 查询语句,打开 q78 sql 文件,复制 sql 执行
with ws as(select d_year AS ws_sold_year, ws_item_sk,ws_bill_customer_sk ws_customer_sk,sum(ws_quantity) ws_qty,sum(ws_wholesale_cost) ws_wc,sum(ws_sales_price) ws_spfrom web_salesleft join web_returns on wr_order_number=ws_order_number and ws_item_sk=wr_item_skjoin date_dim on ws_sold_date_sk = d_date_skwhere wr_order_number is nullgroup by d_year, ws_item_sk, ws_bill_customer_sk),cs as(select d_year AS cs_sold_year, cs_item_sk,cs_bill_customer_sk cs_customer_sk,sum(cs_quantity) cs_qty,sum(cs_wholesale_cost) cs_wc,sum(cs_sales_price) cs_spfrom catalog_salesleft join catalog_returns on cr_order_number=cs_order_number and cs_item_sk=cr_item_skjoin date_dim on cs_sold_date_sk = d_date_skwhere cr_order_number is nullgroup by d_year, cs_item_sk, cs_bill_customer_sk),ss as(select d_year AS ss_sold_year, ss_item_sk,ss_customer_sk,sum(ss_quantity) ss_qty,sum(ss_wholesale_cost) ss_wc,sum(ss_sales_price) ss_spfrom store_salesleft join store_returns on sr_ticket_number=ss_ticket_number and ss_item_sk=sr_item_skjoin date_dim on ss_sold_date_sk = d_date_skwhere sr_ticket_number is nullgroup by d_year, ss_item_sk, ss_customer_sk)selectss_sold_year, ss_item_sk, ss_customer_sk,round(ss_qty/(coalesce(ws_qty,0)+coalesce(cs_qty,0)),2) ratio,ss_qty store_qty, ss_wc store_wholesale_cost, ss_sp store_sales_price,coalesce(ws_qty,0)+coalesce(cs_qty,0) other_chan_qty,coalesce(ws_wc,0)+coalesce(cs_wc,0) other_chan_wholesale_cost,coalesce(ws_sp,0)+coalesce(cs_sp,0) other_chan_sales_pricefrom ssleft join ws on (ws_sold_year=ss_sold_year and ws_item_sk=ss_item_sk and ws_customer_sk=ss_customer_sk)left join cs on (cs_sold_year=ss_sold_year and cs_item_sk=ss_item_sk and cs_customer_sk=ss_customer_sk)where (coalesce(ws_qty,0)>0 or coalesce(cs_qty, 0)>0) and ss_sold_year=2000order byss_sold_year, ss_item_sk, ss_customer_sk,ss_qty desc, ss_wc desc, ss_sp desc,other_chan_qty,other_chan_wholesale_cost,other_chan_sales_price,ratioLIMIT 100;
复制 sql 到命令框后,点击回车确定,这里可以看到执行失败

这时在失败的 sql 后加上一下语句再执行尝试,其中参数distributed_max_parallel_size可以设置为 4 的其他整数倍(因为 Worker 的数量为 4)
SETTINGS bsp_mode = 1,distributed_max_parallel_size = 12;
更改后的 q78 sql 文件内容如下
with ws as(select d_year AS ws_sold_year, ws_item_sk,ws_bill_customer_sk ws_customer_sk,sum(ws_quantity) ws_qty,sum(ws_wholesale_cost) ws_wc,sum(ws_sales_price) ws_spfrom web_salesleft join web_returns on wr_order_number=ws_order_number and ws_item_sk=wr_item_skjoin date_dim on ws_sold_date_sk = d_date_skwhere wr_order_number is nullgroup by d_year, ws_item_sk, ws_bill_customer_sk),cs as(select d_year AS cs_sold_year, cs_item_sk,cs_bill_customer_sk cs_customer_sk,sum(cs_quantity) cs_qty,sum(cs_wholesale_cost) cs_wc,sum(cs_sales_price) cs_spfrom catalog_salesleft join catalog_returns on cr_order_number=cs_order_number and cs_item_sk=cr_item_skjoin date_dim on cs_sold_date_sk = d_date_skwhere cr_order_number is nullgroup by d_year, cs_item_sk, cs_bill_customer_sk),ss as(select d_year AS ss_sold_year, ss_item_sk,ss_customer_sk,sum(ss_quantity) ss_qty,sum(ss_wholesale_cost) ss_wc,sum(ss_sales_price) ss_spfrom store_salesleft join store_returns on sr_ticket_number=ss_ticket_number and ss_item_sk=sr_item_skjoin date_dim on ss_sold_date_sk = d_date_skwhere sr_ticket_number is nullgroup by d_year, ss_item_sk, ss_customer_sk)selectss_sold_year, ss_item_sk, ss_customer_sk,round(ss_qty/(coalesce(ws_qty,0)+coalesce(cs_qty,0)),2) ratio,ss_qty store_qty, ss_wc store_wholesale_cost, ss_sp store_sales_price,coalesce(ws_qty,0)+coalesce(cs_qty,0) other_chan_qty,coalesce(ws_wc,0)+coalesce(cs_wc,0) other_chan_wholesale_cost,coalesce(ws_sp,0)+coalesce(cs_sp,0) other_chan_sales_pricefrom ssleft join ws on (ws_sold_year=ss_sold_year and ws_item_sk=ss_item_sk and ws_customer_sk=ss_customer_sk)left join cs on (cs_sold_year=ss_sold_year and cs_item_sk=ss_item_sk and cs_customer_sk=ss_customer_sk)where (coalesce(ws_qty,0)>0 or coalesce(cs_qty, 0)>0) and ss_sold_year=2000order byss_sold_year, ss_item_sk, ss_customer_sk,ss_qty desc, ss_wc desc, ss_sp desc,other_chan_qty,other_chan_wholesale_cost,other_chan_sales_price,ratioLIMIT 100SETTINGS bsp_mode = 1,distributed_max_parallel_size = 12;
本次执行成功了,返回 100 条数据,耗时 60.510 秒。处理了 5.0421 亿行,6.05 GB(833 万行/秒,99.96 MB/秒)
100 rows in set. Elapsed: 60.510 sec. Processed 504.21 million rows, 6.05 GB (8.33 million rows/s., 99.96 MB/s.)

我再换一条 sql 执行操作,选择 q99 sql 命令复制并执行
select substr(w_warehouse_name,1,20),sm_type,cc_name,sum(case when (cs_ship_date_sk - cs_sold_date_sk <= 30 ) then 1 else 0 end) as "30 days" ,sum(case when (cs_ship_date_sk - cs_sold_date_sk > 30) and (cs_ship_date_sk - cs_sold_date_sk <= 60) then 1 else 0 end ) as "31-60 days" ,sum(case when (cs_ship_date_sk - cs_sold_date_sk > 60) and (cs_ship_date_sk - cs_sold_date_sk <= 90) then 1 else 0 end) as "61-90 days" ,sum(case when (cs_ship_date_sk - cs_sold_date_sk > 90) and(cs_ship_date_sk - cs_sold_date_sk <= 120) then 1 else 0 end) as "91-120 days" ,sum(case when (cs_ship_date_sk - cs_sold_date_sk > 120) then 1 else 0 end) as ">120 days"
fromcatalog_sales,warehouse,ship_mode,call_center,date_dim
whered_month_seq between 1200 and 1200 + 11
and cs_ship_date_sk = d_date_sk
and cs_warehouse_sk = w_warehouse_sk
and cs_ship_mode_sk = sm_ship_mode_sk
and cs_call_center_sk = cc_call_center_sk
group bysubstr(w_warehouse_name,1,20),sm_type,cc_name
order by substr(w_warehouse_name,1,20),sm_type,cc_name
limit 100;
执行结果返回 100 条数据,耗时 9.086 秒。处理了 7313 千行,197.11 KB(8.05 千行/秒,21.69 KB/秒)
100 rows in set. Elapsed: 9.086 sec. Processed 73.13 thousand rows, 197.11 KB (8.05 thousand rows/s., 21.69 KB/s.)

添加参数限制查询的最大内存使用量引发 oom,在 q99 sql 命令后增加如下命令
-- (单位为 B,当前约合 37.25 GB)
SETTINGS max_memory_usage=40000000000;
更改后的 sql 命令依然执行成功,这个时候我不断调整,按照每次下调资源总数 70%的方式,不断缩小 max_memory_usage 的大小进行尝试,
SETTINGS max_memory_usage=93052205;
经过多次的尝试,设置为 SETTINGS max_memory_usage=93052205; 后出现了内存错误信息

此时我们再为 q99 sql 增加参数 distributed_max_parallel_size 来进行尝试,在上述 sql 后继续增加以下命令信息
SETTINGS bsp_mode = 1,distributed_max_parallel_size = 12;
增加参数 分布式最大并行大小 参数 distributed_max_parallel_size 后的 sql 从最大并行大小 4 调整到了 76,进行尝试,但是还是没有成功
select substr(w_warehouse_name,1,20),sm_type,cc_name,sum(case when (cs_ship_date_sk - cs_sold_date_sk <= 30 ) then 1 else 0 end) as "30 days" ,sum(case when (cs_ship_date_sk - cs_sold_date_sk > 30) and (cs_ship_date_sk - cs_sold_date_sk <= 60) then 1 else 0 end ) as "31-60 days" ,sum(case when (cs_ship_date_sk - cs_sold_date_sk > 60) and (cs_ship_date_sk - cs_sold_date_sk <= 90) then 1 else 0 end) as "61-90 days" ,sum(case when (cs_ship_date_sk - cs_sold_date_sk > 90) and(cs_ship_date_sk - cs_sold_date_sk <= 120) then 1 else 0 end) as "91-120 days" ,sum(case when (cs_ship_date_sk - cs_sold_date_sk > 120) then 1 else 0 end) as ">120 days"
fromcatalog_sales,warehouse,ship_mode,call_center,date_dim
whered_month_seq between 1200 and 1200 + 11
and cs_ship_date_sk = d_date_sk
and cs_warehouse_sk = w_warehouse_sk
and cs_ship_mode_sk = sm_ship_mode_sk
and cs_call_center_sk = cc_call_center_sk
group bysubstr(w_warehouse_name,1,20),sm_type,cc_name
order by substr(w_warehouse_name,1,20),sm_type,cc_name
limit 100
SETTINGS max_memory_usage=93052205,bsp_mode = 1,distributed_max_parallel_size = 76;
并且我发现随着分布式最大并行大小 参数 distributed_max_parallel_size 的 不断升高,执行 sql 等待的时间也越来越长,我这边调整参数 distributed_max_parallel_size 从 4 一直按照 4 的倍数尝试到 76 ,执行时间从最初的 10s 以内到现在的近 180s 还是没成功,

下面我准备再体验其他 sql 语句的查询效果。复制 q01 的 sql 到命令框,这时可以看到 sql 文件内容本身有问题并不能执行,而是被截成了两断,

其实上面的 sql 直接从 sql 文件复制出来执行也是会报错的,我这边都是经过根据错误提示修改后执行成功的,对于 q01 按照错误提示修改后 sql 如下
with customer_total_return as
(selectsr_customer_sk as ctr_customer_sk,sr_store_sk as ctr_store_sk,sum(sr_return_amt) as ctr_total_returnfrom store_returns, date_dimwhere sr_returned_date_sk = d_date_sk and d_year = 2000 group by sr_customer_sk,sr_store_sk)
select c_customer_id
from customer_total_return ctr1, store, customer
where ctr1.ctr_total_return > (select avg(ctr_total_return) *1.2from customer_total_return ctr2where ctr1.ctr_store_sk = ctr2.ctr_store_sk
)
and s_store_sk = ctr1.ctr_store_sk
and s_state = 'TN'
and ctr1.ctr_customer_sk = c_customer_sk
order by c_customer_id
limit 100;
执行后可以看到返回信息,返回 100 条数据,执行耗时 6.275 秒。处理了 147.1 万行,394.73 KB(234.4 万行/秒,62.90 KB/秒)
100 rows in set. Elapsed: 6.275 sec. Processed 147.10 thousand rows, 394.73 KB (23.44 thousand rows/s., 62.90 KB/s.)
执行结果过如图所示

当然,TPC-DS 测试集均为模拟实际场景的查询,如果你希望了解具体查询的含义,可以将 SQL 复制到大模型产品(如豆包)中让其进行解释,能帮助您更好的理解查询对应的实际场景。豆包大模型地址https://www.doubao.com/chat/365034912382466,这里我输入 q01 sql 文件内容进行解释,得到如下内容
以下是对这段 SQL 代码的分析:
代码整体功能概述
这段 SQL 代码的目的是从数据库中查询出满足特定条件的客户 ID(c_customer_id)。它首先通过一个公共表达式(CTE,即 customer_total_return)计算出每个客户在特定商店(基于 sr_customer_sk 和 sr_store_sk 分组)在 2000 年的总退货金额(ctr_total_return)。然后,在主查询中筛选出那些在所在商店的总退货金额大于该商店平均总退货金额 1.2 倍,并且对应的商店位于 'TN'(田纳西州,推测这里 s_state 代表商店所在州)的客户,最后按照客户 ID 排序并限制返回结果为 100 条记录。
具体各部分分析
公共表达式(CTE)部分:customer_total_return
逻辑说明:
通过关联 store_returns 表(可能存储商店退货相关信息)和 date_dim 表(可能存储日期维度相关数据),以 sr_returned_date_sk 和 d_date_sk 作为关联条件,筛选出退货日期在 2000 年(通过 d_year = 2000 条件)的数据。
然后按照客户编号(sr_customer_sk)和商店编号(sr_store_sk)进行分组,并对每个分组内的退货金额(sr_return_amt)求和,得到每个客户在每个商店在 2000 年的总退货金额,将其命名为 ctr_total_return,同时将 sr_customer_sk 重命名为 ctr_customer_sk,sr_store_sk 重命名为 ctr_store_sk。
代码示例:
selectsr_customer_sk as ctr_customer_sk,sr_store_sk as ctr_store_sk,sum(sr_return_amt) as ctr_total_return
from store_returns, date_dim
where sr_returned_date_sk = d_date_sk and d_year = 2000
group by sr_customer_sk,sr_store_sk
主查询部分
筛选条件分析:
首先在 FROM 子句中关联了 customer_total_return(通过别名 ctr1 使用)、store 表和 customer 表。关联条件分别是 s_store_sk = ctr1.ctr_store_sk(将商店表和前面计算总退货的 CTE 按商店编号关联)以及 ctr1.ctr_customer_sk = c_customer_sk(将客户表和 CTE 按客户编号关联)。
在 WHERE 子句中,有多个筛选条件:
ctr1.ctr_total_return > (select avg(ctr_total_return) * 1.2 from customer_total_return ctr2 where ctr1.ctr_store_sk = ctr2.ctr_store_sk):这是一个比较关键的筛选条件,它使用了子查询。对于每一个 ctr1 中的记录(即每个客户在每个商店的情况),会在子查询中计算出与当前记录所在商店相同(通过 ctr1.ctr_store_sk = ctr2.ctr_store_sk 关联条件)的所有客户的平均总退货金额,然后要求当前客户在该商店的总退货金额大于这个平均总退货金额的 1.2 倍。
s_state = 'TN':筛选出所在商店位于田纳西州的情况,这里是基于 store 表中的 s_state 字段进行筛选。
排序和限制结果:
最后使用 ORDER BY c_customer_id 按照客户 ID 进行排序,并通过 LIMIT 100 限制只返回前 100 条记录。
代码示例:
select c_customer_id
from customer_total_return ctr1, store, customer
where ctr1.ctr_total_return > (select avg(ctr_total_return) *1.2from customer_total_return ctr2where ctr1.ctr_store_sk = ctr2.ctr_store_sk
)
and s_store_sk = ctr1.ctr_store_sk
and s_state = 'TN'
and ctr1.ctr_customer_sk = c_customer_sk
order by c_customer_id
limit 100;
潜在优化点或注意事项
关联方式:
当前代码中在 CTE 和主查询里使用的表连接方式是隐式连接(使用逗号分隔表,在 WHERE 子句中写关联条件),建议可以改为显式的 JOIN 语法,这样代码的可读性会更好。例如在 CTE 中可以写成:
selectsr_customer_sk as ctr_customer_sk,sr_store_sk as ctr_store_sk,sum(sr_return_amt) as ctr_total_return
from store_returns
JOIN date_dim ON sr_returned_date_sk = d_date_sk
where d_year = 2000
group by sr_customer_sk,sr_store_sk
在主查询中类似地可以将连接改为显式的 JOIN 语句来提升可读性。
性能方面:
如果数据量较大,涉及到的子查询(计算同商店平均退货金额的子查询)可能会影响性能,因为对于每一条外部查询的记录都要执行一次子查询。可以考虑使用窗口函数等方式来预先计算平均退货金额并关联到原始数据上,以优化性能,不过这需要根据具体数据库的支持情况来调整代码实现。
索引使用:
考虑在关联字段(如 sr_customer_sk、sr_store_sk、d_date_sk、s_store_sk、c_customer_sk 等)以及用于筛选和排序的字段(如 d_year、s_state、c_customer_id)上根据数据库的查询特点创建合适的索引,有助于提升查询性能。
总的来说,这段代码实现了特定业务需求下筛选客户的功能,但在代码风格和性能方面有一定的优化空间,可以根据实际使用的数据库环境做进一步调整。豆包界面如图所示,简洁明了,唯一亮点是竟然不用登录就可以使用,这个就省去了每次登录的麻烦,很好

后面可以测试的 sql 还有很多,这里受限于文章篇幅,不再依依在这里描述了,大家可以在官方提供的测试服务器进行操作,不过根据我操作了这么多 sql 的经验,很少有粘贴出来 sql 就可以执行的,经常会遇到 sql 换行引起的 sql 查询断行的情况,就像这样

到这里关于实验操作操作的部分就已经告一段落,后续对于不同场景的业务 sql 的执行,这里也就不再一一列举截图了。那么相对于传统 ELT,ByConity 有哪些优化的地方。 下面再来聊一下 ByConity 相比于 ELT 优化的地方,这里需要声明一点哈,对于 ByConity 相比于 ELT 优化的地方 的内容摘自于其他文章内容,也是本次活动页地址:https://xie.infoq.cn/article/dd49679fc505dc3249692cf74
以下内容基本来自活动页内容搬过来的,为了方便大家在实验操作之后,回想实验中的操作体验,可以结合传统 ELT 能力做个对比,对比的内容我搬来放在下面,不用大家再去别的地方搜索增加学习负担了。
ByConity 相对于 ELT 能力的优化
提升并行度
在传统结构中,为什么要分别建设离线数仓和实时数仓。是因为常见的 OLAP 产品不擅长处理大量的复杂查询,很容易把内容打满任务中断,甚至造成宕机。
ByteHouse 具备 BSP 模式,支持将查询切分为不同的 stage,每个 stage 独立运行。在此基础上,stage 内的数据也可以进行切分,并行化不再受节点数量限制,理论上可以无限扩展,从而大幅度降低峰值内存。正如我们在测试 q78 时,当遇到内存不足情况时,可以通过 bsp 模式来设置并行参数 distributed_max_parallel_size 来提升并行度,保障系统稳定性。
任务级重试
对于离线加工任务来说,离线加工任务的另外一个特点就是链路比较长,并且任务间有依赖关系。当某一个任务失败会导致整个链路失败,

比如,task4 依赖 task1、task2 的完成。如果 task1 失败发起重试,会显示为整个链路执行失败。ByteHouse 增加了任务级重试能力,在 ByteHouse 中只有运行失败的 task 需要重试。
并行写入
实时数仓存在频繁更新的特点,使用重叠窗口进行批量 ETL 操作时,会带来大量的数据更新。在这种场景下,ByteHouse 做了大量的优化。

经过持续优化,将最耗时的数据写入部分单独并行化,并且在写入 part 文件时标记是否需要进行后续的 dedup 作业。在所有数据写入完毕后,由 server 指定一个 worker 进行 dedup 和最后的事务提交(如上图最右)。
简化数据链路
ByteHouse 在传统的 MPP 链路基础上增加了对复杂查询的支持,这使得 join 等操作可以有效地得到执行。
BSP 模式使用 barrier 将各个 stage 进行隔离,每个 stage 独立运行,stage 之内的 task 也相互独立。即便机器环境发生变化,对查询的影响被限定在 task 级别。且每个 task 运行完毕后会及时释放计算资源,对资源的使用更加充分。
在这个基础上,BSP 的这种设计更利于重试的设计。任务失败后,只需要重新拉起时读取它所依赖的任务的 shuffle 数据即可,而无需考虑任务状态。
相关文章:
基于开源云原生数据仓库 ByConity 体验多种数据分析场景
基于开源云原生数据仓库 ByConity 体验多种数据分析场景 业务背景什么是 ByConity上手实测环境要求测试操作远程登录 ECS 服务器windows10 自带连接工具 执行查询 ByConity 相对于 ELT 能力的优化提升并行度任务级重试并行写入简化数据链路 业务背景 大家都知道,在…...

RabbitMQ 消息确认机制
RabbitMQ 消息确认机制 本文总结了RabbitMQ消息发送过程中的一些代码片段,详细分析了回调函数和发布确认机制的实现,以提高消息传递的可靠性。 返回回调机制的代码分析 主要用途 这个代码主要用于设置RabbitMQ消息发送过程中的回调函数,即…...

Node.js:开发和生产之间的区别
Node.js 中的开发和生产没有区别,即,你无需应用任何特定设置即可使 Node.js 在生产配置中工作。但是,npm 注册表中的一些库会识别使用 NODE_ENV 变量并将其默认为 development 设置。始终在设置了 NODE_ENVproduction 的情况下运行 Node.js。…...

【QT】背景,安装和介绍
TOC 目录 背景 GUI技术 QT的安装 使用流程 QT程序介绍 main.cpp编辑 Wiget.h Widget.cpp form file .pro文件 临时文件 C作为一门比较古老的语言,在人们的认知里始终是以底层,复杂和高性能著称,所以在很多高性能需求的场景之下…...

从0到1搭建webpack
好,上一篇文章我们说了一下在react中怎么弄这个webpack,那么现在在说一下不用react我们又该怎么配置,这些呢也都是我自己通弄过看视频自己总结的,拿来给大家分享一下。 前期准备条件 1、nvm(可以快速切换node版本&am…...

针对解决conda环境BUG的个人笔记
1-conda学习&安装 安装视频: 零基础教程:基于Anaconda和PyCharm配置Pytorch环境_哔哩哔哩_bilibili 安装过程: MX250笔记本安装Pytorch、CUDA和cuDNN-CSDN博客 Win10MX250CUDA10.1cuDNNPytorch1.4安装测试全过程(吐血)_nvidia geforc…...

读《Effective Java》笔记 - 条目13
条目13:谨慎重写clone方法 浅拷贝和深拷贝 浅拷贝(Shallow Copy) 浅拷贝 只复制对象本身,而不复制对象引用的成员。 对于引用类型的字段,浅拷贝会将原对象的引用复制到新对象中,而不会创建新对象实例。因…...

SQL 之连接查询
SQL 连接查询:深入理解 JOIN 操作 在数据库管理中,连接查询(JOIN)是一种基本而强大的操作,它允许我们从两个或多个表中检索数据。SQL 中的 JOIN 操作使得数据整合变得简单,这对于数据分析和报告至关重要。…...

vscode切换anaconda虚拟环境解释器不成功
问题: 切换解释器之后运行代码还是使用的原来的解释器 可以看到,我已经切换了“nlp”解释器,我的nltk包只在“nlp”环境下安装了,但是运行代码依然是"torch"解释器,所以找不到“nltk”包。 在网上找了各种…...

一个实用的 Maven localRepository 工具
目录 1 现状2 当前解决3 更好的解决3.1 下载 Maven localRepository 工具包3.2 上传本地 localRepository 包3.3 清理 localRepository 中指定后缀的文件 1 现状 在使用 Maven 时,我们可能会经常与本地仓库和私服仓库打交道。 例如对于本地仓库,因为某…...

目标检测,图像分割,超分辨率重建
目标检测和图像分割 目标检测和图像分割是计算机视觉中的两个不同任务,它们的输出形式也有所不同。下面我将分别介绍这两个任务的输出。图像分割又可以分为:语义分割、实例分割、全景分割。 语义分割(Semantic Segmentation)&…...

微信小程序 城市点击后跳转 并首页显示被点击城市
在微信小程序中,渲染出城市列表后,如何点击城市,就跳转回到首页,并在首页显示所点击的城市呢? 目录 一、定义点击城市的事件 二、首页的处理 首页:点击成都市会跳转到城市列表 城市列表:点击…...

Linux - nfs服务器
五、nfs服务器 1、基础 NFS服务器可以让PC将网络中的NFS服务器共享的目录挂载到本地端的文件系统中,而在本地端的系统 中看来,那个远程主机的目录就好像是自己的一个磁盘分区一样。 由于NFS支持的功能比较多,而不同的功能都会使用不同的程…...

uniapp图片上传预览uni.chooseImage、uni.previewImage
文章目录 1.上传图片2.预览图片 1.上传图片 uni.chooseImage(OBJECT) 从本地相册选择图片或使用相机拍照。 App端如需要更丰富的相机拍照API(如直接调用前置摄像头),参考plus.camera 微信小程序从基础库 2.21.0 开始, wx.choos…...

C++ 字符串中数字识别
【问题描述】 输入一个字符串,含有数字和非数字字符,如“sumabc234;while(abc700)tab{ass346;bssabc267;}”,将其中连续的数字作为一个整数,依次存放到一个数组nums中。例如,234放在nums[0],700放在nums[1…...

学术中常见理论归纳总结-不定期更新
1.信息传播类 1.1 扩散创新理论 创新扩散理论是传播效果研究的经典理论之一,是由美国学者埃弗雷特罗杰斯(E.M.Rogers)于20世纪60年代提出的一个关于通过媒介劝服人们接受新观念、新事物、新产品的理论,侧重大众传播对社会和文化的影响。 1927-1941年进行的“艾奥瓦杂交玉…...

ModelSim怎么修改字体及大小
点击TOOLS 选择PERFERENCES选择下一级菜单的TEXTFONT/CHOOSE/选择字体和大小最后不要忘记点apply再退出...

图片预处理技术介绍4——降噪
图片预处理 大家好,我是阿赵。 这一篇将两种基础的降噪算法。 之前介绍过均值模糊和高斯模糊。如果从降噪的角度来说,模糊算法也算是降噪的一类,所以之前介绍的两种模糊可以称呼为均值降噪和高斯降噪。不过模糊算法对原来的图像特征的…...

Scrapy管道设置和数据保存
1.1 介绍部分: 文字提到常用的Web框架有Django和Flask,接下来将学习一个全球范围内流行的爬虫框架Scrapy。 1.2 内容部分: Scrapy的概念、作用和工作流程 Scrapy的入门使用 Scrapy构造并发送请求 Scrapy模拟登陆 Scrapy管道的使用 Scrapy中…...

D84【python 接口自动化学习】- pytest基础用法
day84 pytest常用断言类型 学习日期:20241130 学习目标:pytest基础用法 -- pytest常用断言类型 学习笔记: 常用断言类型 代码实践 def test_assert():assert 11assert 1!2assert 1<2assert 2>1assert 1>1assert 1<1assert a…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

RSS 2025|从说明书学习复杂机器人操作任务:NUS邵林团队提出全新机器人装配技能学习框架Manual2Skill
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。 尽管 VLMs 取得了显著进展,机器人仍难以胜任复杂的长时程任务(如家具装配),主要受限于人…...

【Elasticsearch】Elasticsearch 在大数据生态圈的地位 实践经验
Elasticsearch 在大数据生态圈的地位 & 实践经验 1.Elasticsearch 的优势1.1 Elasticsearch 解决的核心问题1.1.1 传统方案的短板1.1.2 Elasticsearch 的解决方案 1.2 与大数据组件的对比优势1.3 关键优势技术支撑1.4 Elasticsearch 的竞品1.4.1 全文搜索领域1.4.2 日志分析…...
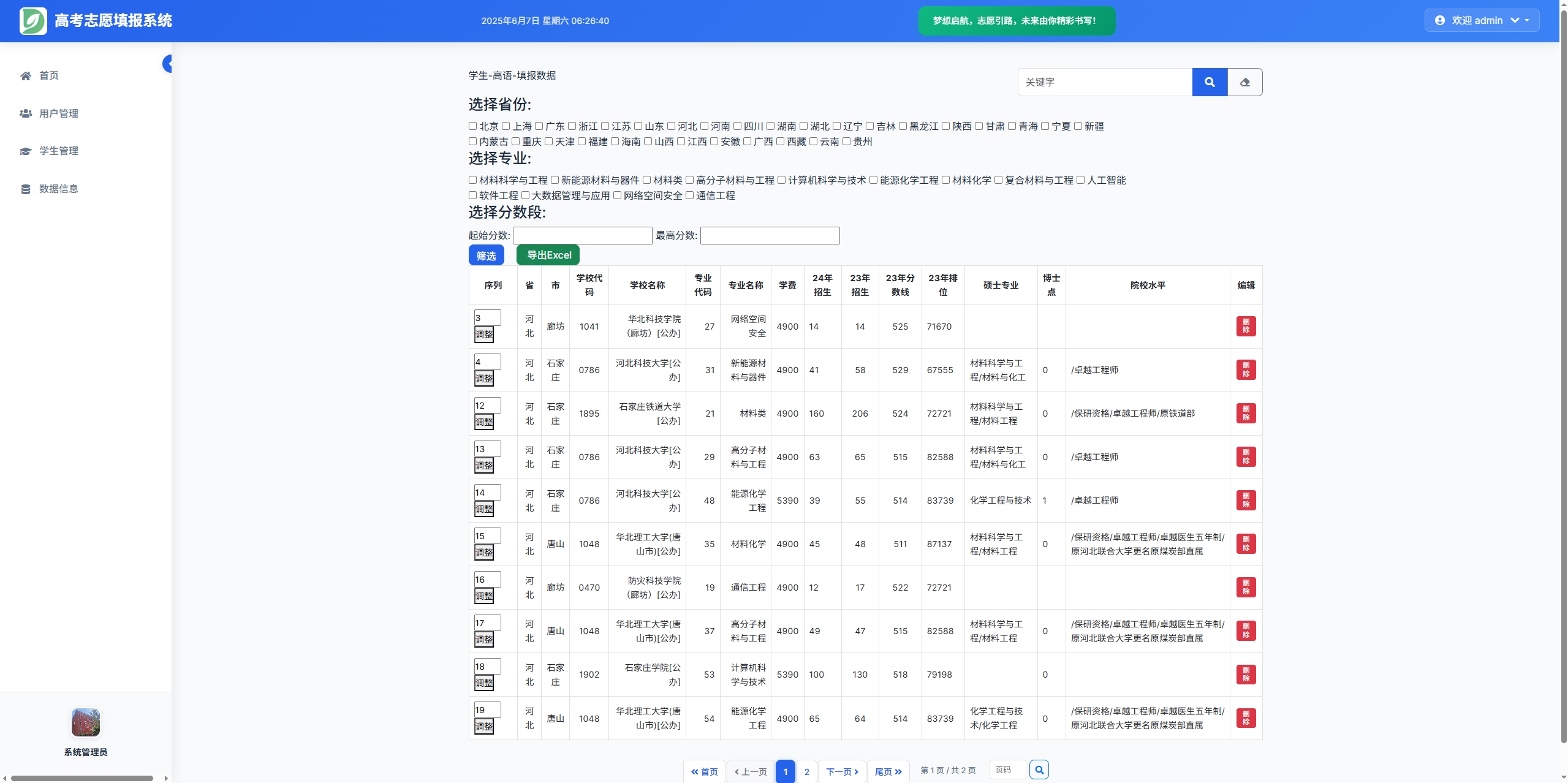
高考志愿填报管理系统---开发介绍
高考志愿填报管理系统是一款专为教育机构、学校和教师设计的学生信息管理和志愿填报辅助平台。系统基于Django框架开发,采用现代化的Web技术,为教育工作者提供高效、安全、便捷的学生管理解决方案。 ## 📋 系统概述 ### 🎯 系统定…...
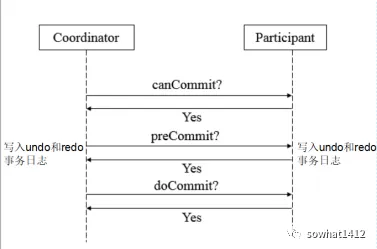
解析两阶段提交与三阶段提交的核心差异及MySQL实现方案
引言 在分布式系统的事务处理中,如何保障跨节点数据操作的一致性始终是核心挑战。经典的两阶段提交协议(2PC)通过准备阶段与提交阶段的协调机制,以同步决策模式确保事务原子性。其改进版本三阶段提交协议(3PC…...