如何构建一个可扩展、全球可访问的 GenAI 架构?
你有没有尝试过使用人工智能生成图像?
如果你尝试过,你就会知道,一张好的图像的关键在于一个详细具体的提示。
我不擅长这种详细的视觉提示,所以我依赖大型语言模型来生成详细的提示,然后使用这些提示来生成出色的图像。以下是我能够生成的一些提示和图像的例子:
Prompt: Create a stunning aerial view of Bengaluru, India with the city name written in bold, golden font across the top of the image, with the city skyline and Nandi Hills visible in the background.

Prompt: Design an image of the iconic Vidhana Soudha building in Bengaluru, India, with the city name written in a modern, sans-serif font at the bottom of the image, in a sleek and minimalist style.

为了实现这些结果,我们使用了Flux.1-schnell模型进行图像生成,以及Llamma 3.1 - 8B - Instruct模型来生成提示。这两个模型都托管在一台配备了MIG(多实例 GPU)的单卡 H100 机器上。
这篇博客不是图像生成教程,我们以前已经分享过 Flux 的教程了。这次,我们的目标是创建一个可扩展、安全、全球可访问(且价格合理)的 GenAI 架构。同时,你还将在本文中了解,如何在同一块 H100 GPU 上同时运行 Flux 和 Llamma3 两个模型。
现在中国很多企业都在做大语言模型,就我们接触过的一些公司来讲,哪怕是一些小公司都在利用开源的模型定制自己内部使用的文生图和视频 AI 工具。
想象一下,一个全球化的平台需要为用户快速定制生成图像,或者一个内容平台需要跨地区提供用 AI 生成的文本。
对于开发者来说,想实现这样的架构存在许多挑战。例如:
- GPU 昂贵的价格
- GenAI 工具是尖端技术,每个工具都有特定的配置要求
- 安全地将后端服务器与GenAI服务器连接
- 将全球分布的用户路由到最近的服务器等
这次分享应该能给你提供一个参考和启发,逐一解决这些问题。
架构设计
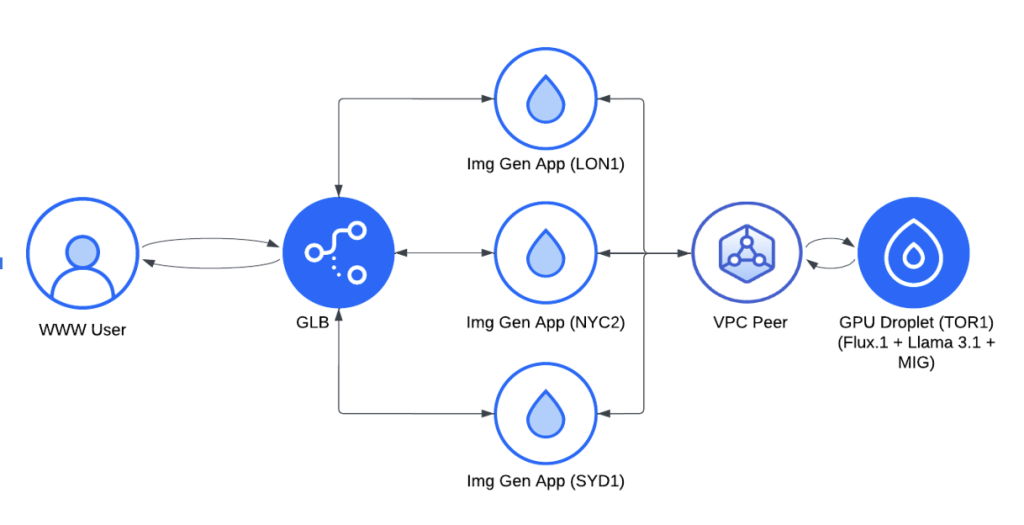
实现方案
为了实现这一目标,我们设计了一个基于 DigitalOcean 云基础设施的分布式架构。后面我们会解释为什么会选择 DigitalOcean 服务器。以下是这个架构的具体工作原理:
- 我们首先使用全球负载均衡器(GLB)来管理来自不同地区的请求,确保所有用户都能体验到最小的延迟。
- 我们在关键地区(伦敦、纽约和悉尼)部署了轻量级的图像生成应用,每个应用都有自己的缓存,并且可以根据需要连接到 GPU 资源。这些应用通过 VPC 对等连接(有免费的1200 GiB的数据传输流量)安全地通信,将复杂的任务回传到多伦多的 H100 GPU Droplet 服务器上,这些服务器负责处理提Prompt和图像生成的核心任务。
组件详解
在这个架构中,有两个重要的组件 ,一个是轻量级图像生成应用,另一个是 MIG GPU 组件,我们需要解释一下这两个组件。
轻量级图像生成应用
图像生成应用是一个简单的 Python Flask 应用,主要包含三个部分:
1、位置检测模块:这个模块通过浏览器向服务器发送一个虚拟请求,以确定用户的地理位置(城市和国家),并识别哪个服务器区域正在处理该请求。这些信息会显示给用户,并帮助优化提示和图像生成的过程。
2、提示下拉模块:确定用户位置后,应用首先检查缓存中是否有与该位置相关的预存提示。如果找到合适的提示,它们会立即显示在下拉菜单中,供用户选择用于图像生成。如果没有缓存的提示,应用会向大型语言模型(LLM)发送请求生成新的提示,这些提示会被缓存起来以供将来使用,并填充到下拉菜单中供用户选择。
3、生成图像模块:当用户选择一个提示后,应用首先检查是否有从该特定提示生成的图像已缓存。如果有缓存的图像,会直接从磁盘加载,确保更快的响应时间。如果没有缓存的图像,应用会调用 API 生成新的图像,并将其缓存以供未来的请求使用,最后展示给用户。
MIG GPU 组件
MIG(多实例 GPU)是 NVIDIA GPU(如 H100)官方提供的一项功能,它允许将单个物理 GPU 划分为多个独立的实例。每个实例称为一个 MIG 片段,具有独立的计算、内存和带宽资源。
例如,我们可以为每个 H100 GPU 获得两个 H100 MIG 模型,每个模型的计算能力约为完整 GPU 的一半。在一项基准测试中,每个实例通常能在仅需 A100 GPU 80%成本的情况下提供相同甚至超过 A100 GPU 的性能。
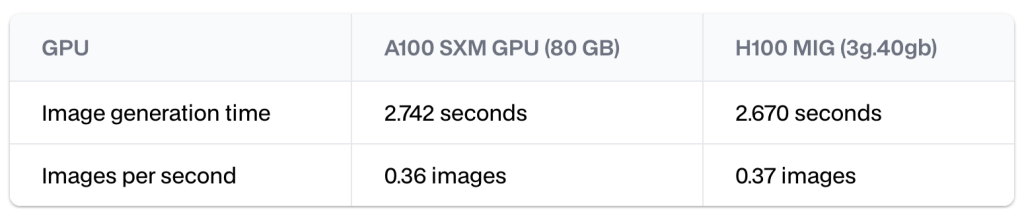
这种设计不仅优化了 GPU 的利用率,还使我们能够在同一个 GPU 上并行部署图像生成和提示生成模型。
多实例 GPU (MIG) 如何工作
MIG 是 NVIDIA 在 Ampere 架构中引入的一项技术,同时也支持 Hopper 和 Blackwell 架构。MIG 可以将单个 GPU 划分为多个小的 GPU 实例,每个实例都可以独立运行一个模型服务器。
MIG 的组成
MIG 实例是由 GPU 的物理计算和内存切片组装而成的:
- 7 个计算切片:这些切片均匀划分了芯片上的流式多处理器(SMs)。H100 GPU 拥有 140 个 SMs,这些 SMs 被均匀分配到 7 个切片中,每个切片包含 20 个 SMs。此外,H100 GPU 还有 7 个 NVDEC 和 JPEG 图像解码器,每个切片分配一个。
- 8 个内存切片:这些切片均匀划分了芯片上的显存(VRAM)。每个内存切片有 10 GB 的 VRAM 和 GPU 总内存带宽的八分之一。
7 个计算切片看起来可能有些奇怪,但这并不是因为预留了一部分计算资源用于开销,而是因为 H100 GPU 恰好有 140 个 SMs,这些 SMs 被均匀分成 7 个切片,每个切片包含 20 个 SMs。
实现该架构
在这里我们要开始做一个演示,基于 DigitalOcean 的 GPU Droplet 服务器。DigitalOcean的 H100 GPU 在2024 年底之前仅需 2.5 美元/月/GPU,从成本上来讲非常合算。而且 DigitalOcean 也已经推出了裸金属 GPU 服务器,以供对性能要求更苛刻的 AI 工作任务,比如大型模型的训练和 GenAI 应用。
在进行 Demo 之前,你需要做以下准备:
- DigitalOcean 账户:你需要有一个DigitalOcean 账户,新用户可以获得 200 美元的免费额度,如果你正在做服务器选型,可以用这些额度来做充分的测试。(具体服务器价格可参考官方文档)
- 基本知识:你需要了解 GPU、云网络、VPC(虚拟私有云)和负载均衡的基本概念。
- 基本技能:熟悉 Bash、Docker 和 Python。
- HuggingFace 访问权限:
- 已获得对 Image Generation with Flux.1 模型的访问权限。
- 已获得对 Llama 3.1-8b-Instruct 模型的访问权限。
- vLLM 库:vLLM 是一个快速且易于使用的大型语言模型(LLM)推理和服务库。
Step-by-Step Setup
1. 创建 GPU Droplet
首先,在 DigitalOcean 上创建一个带有单个 H100 GPU 的 GPU Droplet,并选择预装了机器学习开发所需的操作系统镜像。
2. 启用 MIG 模式
GPU Droplet 启动并运行后,启用 MIG(多实例 GPU)模式。MIG 可以将 GPU 划分为多个独立的 GPU 实例,每个实例都是相互隔离的,这对于并行运行不同模型非常重要。
sudo nvidia-smi -i 0 -mig 13. 选择 MIG 配置文件并创建实例
启用 MIG 后,选择一个符合你模型需求的配置文件。
nvidia-smi mig -lgip # 列出所有配置文件例如,创建两个 MIG 实例,每个实例提供 40GB 内存,这应该足够运行两个模型。
sudo nvidia-smi mig -cgi 9,9 -C查看所有 MIG 实例 ID:
nvidia-smi -L4. 在每个 MIG 实例上设置 Docker 容器
对于每个 MIG 实例,运行一个单独的 Docker 容器,分别用于图像生成和提示生成模型。
部署 Flux.1-schnell 用于图像生成
我们使用 metatonic 的图像和代码来部署 Flux.1 的 Docker 镜像。
# 克隆仓库
git clone https://github.com/matatonic/openedai-images-flux
cd openedai-images-flux# 复制配置文件
cp config.default.json config/config.json# 运行 Docker 镜像
sudo docker run -d \-e HUGGING_FACE_HUB_TOKEN="<HF_READ_TOKEN>" \--runtime=nvidia -e NVIDIA_VISIBLE_DEVICES=<MIG_INSTANCE_ID> \-v ./config:/app/config \-v ./models:/app/models \-v ./lora:/app/lora \-v ./models/hf_home:/root/.cache/huggingface \-p 5005:5005 \
ghcr.io/matatonic/openedai-images-flux使用 vLLM 部署 Llama 3.1 用于提示生成
下载并运行用于提示生成模型的 Docker 容器。
sudo docker run -d --runtime=nvidia \
-e NVIDIA_VISIBLE_DEVICES=<MIG_INSTANCE_ID> \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HUGGING_FACE_HUB_TOKEN="<HF_READ_TOKEN>" \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model meta-llama/Meta-Llama-3.1-8B-Instruct5. 模型访问和通信
每个容器通过指定的端口访问,允许图像生成应用实例连接并发送请求到图像生成模型(Flux.1-schnell)或提示生成模型(Llama 3.1)。MIG 分区确保两个模型高效并发运行,互不干扰。
6. 设置区域应用实例
在伦敦、纽约和悉尼等区域位置设置轻量级应用实例,以本地处理用户请求,缓存频繁访问的提示和图像,加快响应速度。
- 通过 DigitalOcean 控制台的 Droplets 部分在某个区域创建 Droplet。
- SSH 登录并设置代码。为了加快速度,我已经创建了一个容器,只需要确保有 DigitalOcean 容器注册表的访问权限并拉取镜像。
# 登录到 Docker 注册表
sudo docker login registry.digitalocean.com# 拉取容器
sudo docker pull registry.digitalocean.com/<cr_name>/city-image-generator:v2- 创建快照并将 Droplet 部署到其他区域。
# 运行容器
sudo docker run -d -p 80:80 registry.digitalocean.com/<cr_name>/city-image-generator:v2- 在其他区域创建其他 Droplet 并运行容器。
7. 设置 VPC Peering
VPC Peering 确保区域应用实例与多伦多的 GPU 服务器之间通过私有网络进行安全、低延迟的通信。
- 进入 DigitalOcean 控制台的 Networking 部分。
- 查看每个区域的默认 VPC(例如伦敦、纽约、悉尼和多伦多)。
- 使用 VPC Peering 功能建立多伦多 VPC 与其他区域 VPC 的连接。
- 使用简单的网络工具(如
ping或curl)验证连接。
8. 设置全局负载均衡器 (GLB)
全局负载均衡器 (GLB) 将用户请求分发到最近的区域应用实例,优化延迟并提升用户体验。
- 进入 DigitalOcean 控制台的 Networking 部分的 Load Balancers 部分。
- 创建一个新的全局负载均衡器。
- 将区域应用实例添加为后端目标。
- 配置健康检查、超时和其他高级设置。
- 创建负载均衡器。
写在最后
这个示例适用于探索分布式 GenAI 解决方案的企业和开发者,例如生成个性化内容的广告平台、社交平台、电商平台,或服务于全球受众的 AI 内容平台。通过利用 DigitalOcean 的产品,我们展示了如何在部署前沿 AI 服务时平衡可扩展性、安全性和成本效益。
如果你需要了解 DigitalOcean 的 GPU Droplet或裸金属 GPU 服务器,可与 DigitalOcean 中国区独家战略合作伙伴卓普云联系。
如果需要了解更多关于 AI、云架构的开发,可关注我们的博客。
相关文章:
如何构建一个可扩展、全球可访问的 GenAI 架构?
你有没有尝试过使用人工智能生成图像? 如果你尝试过,你就会知道,一张好的图像的关键在于一个详细具体的提示。 我不擅长这种详细的视觉提示,所以我依赖大型语言模型来生成详细的提示,然后使用这些提示来生成出色的图像…...

QT实战--qt各种按钮实现
本篇介绍qt一些按钮的实现,包括正常按钮;带有下拉箭头的按钮的各种实现;按钮和箭头两部分分别响应;图片和按钮大小一致;图片和按钮大小不一致的处理;文字和图片位置的按钮 效果图如下: 详细实现…...

RNN And CNN通识
CNN And RNN RNN And CNN通识一、卷积神经网络(Convolutional Neural Networks,CNN)1. 诞生背景2. 核心思想和原理(1)基本结构:(2)核心公式:(3)关…...

生产环境中:Flume 与 Prometheus 集成
在生产环境中,将 Apache Flume 与 Prometheus 集成的过程,需要借助 JMX Exporter 或 HTTP Exporter 来将 Flume 的监控数据转换为 Prometheus 格式。以下是详细的实现方法,连同原理和原因进行逐步解释,让刚接触的初学者也能完成集…...

求平均年龄
求平均年龄 C语言代码C 代码Java代码Python代码 💐The Begin💐点点关注,收藏不迷路💐 班上有学生若干名,给出每名学生的年龄(整数),求班上所有学生的平均年龄,保留到小数…...
——AP_Arming_Sub)
Ardusub源码剖析(1)——AP_Arming_Sub
代码 AP_Arming_Sub.h #pragma once#include <AP_Arming/AP_Arming.h>class AP_Arming_Sub : public AP_Arming { public:AP_Arming_Sub() : AP_Arming() { }/* Do not allow copies */CLASS_NO_COPY(AP_Arming_Sub);bool rc_calibration_checks(bool display_failure)…...

【NLP 2、机器学习简介】
人生的苦难不过伏尔加河上的纤夫 —— 24.11.27 一、机器学习起源 机器学习的本质 —— 找规律 通过一定量的训练样本找到这些数据样本中所蕴含的规律 规律愈发复杂,机器学习就是在其中找到这些的规律,挖掘规律建立一个公式,导致对陌生的数…...

数据结构与算法——N叉树(自学笔记)
本文参考 N 叉树 - LeetBook - 力扣(LeetCode)全球极客挚爱的技术成长平台 遍历 前序遍历:A->B->C->E->F->D->G后序遍历:B->E->F->C->G->D->A层序遍历:A->B->C->D->…...

【趣味升级版】斗破苍穹修炼文字游戏HTML,CSS,JS
目录 图片展示 开始游戏 手动升级(满100%即可升级) 升级完成,即可解锁打怪模式 新增功能说明: 如何操作: 完整代码 实现一个简单的斗破苍穹修炼文字游戏,你可以使用HTML、CSS和JavaScript结合来构建…...

【Oracle】个人收集整理的Oracle常用SQL及命令
【建表】 create table emp( id number(12), name nvarchar2(20), primary key(id) ); 【充值一】 insert into emp select rownum,dbms_random.string(*,dbms_random.value(6,20)) from dual connect by level<101; 【充值二】 begin for i in 1..100 loop inser…...
——通用API)
Linux内核4.14版本——ccf时钟子系统(5)——通用API
1. clk_get 1.1 __of_clk_get_by_name 1.2 clk_get_sys 2. clk_prepare_enable 2.1 clk_prepare 2.2 clk_enable 3. clk_set_rate 1. clk_get clock get是通过clock名称获取struct clk指针的过程,由clk_get、devm_clk_get、clk_get_sys、of_clk_get、of_clk_g…...
安装MySQL 5.7 亲测有效
前言:本文是笔者在安装MySQL5.7时根据另一位博主大大的安装教程基础上做了一些修改而成 首先在这里表示对博主大大的感谢 下面附博主大大地址 下面的步骤言简意赅 跟着做就不会出错 希望各位读者耐下心来 慢慢解决安装中出现的问题~MySQL 5.7 安装教程(全…...

《Django 5 By Example》阅读笔记:p455-p492
《Django 5 By Example》学习第 16 天,p455-p492 总结,总计 38 页。 一、技术总结 1.myshop (1)打折功能 使用折扣码实现,但是折扣码是手动生成的,感觉实际业务中应该不是这样的。 (2)推荐功能 使用 Redis 做缓存࿰…...

Element-UI 官网的主题切换动画
文章目录 实现圆形扩散过渡动画 实现一下 Element-UI 官网的主题切换动画加粗样式 实现 首先我们起一个 html 文件,写一个按钮,以及简单的背景颜色切换,来模拟主题的切换 想要实现过渡效果,需要先用到一个 JavaScript 的原生方…...

Golang 构建学习
Golang 构建学习 如何搭建Golang开发环境 1. 下载GOlang包 https://golang.google.cn/dl/ 在地址上下载Golang 2. 配置包环境 修改全局环境变量,GOPROXY,GOPATH,GOROOT GOPROXYhttps://goproxy.cn,direct GOROOT"" // go二进…...

VM Virutal Box的Ubuntu虚拟机与windows宿主机之间设置共享文件夹(自动挂载,永久有效)
本文参考如下链接 How to access a shared folder in VirtualBox? - Ask Ubuntu (1)安装增强功能(Guest Additions) 首先,在网上下载VBoxGuestAdditions光盘映像文件 下载地址:Index of http://…...

分析 系统滴答时钟(tickClock),设置72MHz系统周期,如何实现1毫秒的系统时间?
一、CubeMX相关配置 1.1 相关引脚配置 1.2 相关时钟数配置 1.3 打开程序源码 二、相关函数分析...

C++优选算法十七 多源BFS
1.单源最短路问题 一个起点一个终点。 定义:在给定加权图中,选择一个顶点作为源点,计算该源点到图中所有其他顶点的最短路径长度。 2.多源最短路问题 定义:多源最短路问题指的是在图中存在多个起点,需要求出从这些…...

Mongodb入门到放弃
Mongodb分片概括 分片在多台服务器上分布数据的方法, Mongodb使用分片来支持具有非常大的数据集和高吞吐量的操作的部署 具有大数据集和高吞吐量应用程序的数据库系统,可以挑战单台服务器的容量。 例如,高查询率可以耗尽服务器的cpu容量&…...

青藤云安全携手财信证券,入选金融科技创新应用优秀案例
11月29日,由中国信息通信研究院主办的第四届“金信通”金融科技创新应用案例评选结果正式发布。财信证券与青藤云安全联合提交的“基于RASP技术的API及数据链路安全治理项目”以其卓越的创新性和先进性,成功入选金融科技创新应用优秀案例。 据悉&#x…...

在超大数据集下 DuckDB 与 MySQL 查询速度对比卤
一、什么是urllib3? urllib3 是一个用于处理 HTTP 请求和连接池的强大、用户友好的 Python 库。 它可以帮助你: 发送各种 HTTP 请求(GET, POST, PUT, DELETE等)。 管理连接池,提高网络请求效率。 处理重试和重定向。 支…...

2026就业新风口:AI、新能源、半导体领跑高薪时代,掌握这些技能让你年薪百万!
2026年中国就业市场呈现新质产业领跑、高薪向技术岗集中、城市梯度分化明显的核心特征,AI、新能源、半导体等赛道爆发式增长,一线城市依旧是高薪高地,新一线城市则凭借产业优势快速追赶。与此同时,AI已成为职场核心竞争力…...

保姆级教程:在Win10的WSL2里,用Dify 1.9和Ollama 0.12.9搭一个本地的通义千问AI助手
零基础在Windows 10上打造专属AI助手:WSL2DifyOllama实战指南 你是否想过在自己的电脑上运行一个完全本地的AI助手?不需要昂贵的云端算力,不依赖网络连接,所有数据都在本地处理。今天我们就用Windows 10自带的WSL2功能,…...
)
从删库到跑路?Oracle DBA必备的5种安全删除操作手册(附实战命令)
Oracle DBA安全删除操作全指南:从原理到实战 引言:为什么安全删除如此重要? 在数据库管理领域,删除操作可能是最令人胆战心惊的任务之一。想象一下这样的场景:凌晨三点,你接到紧急电话,因为一个…...
萍)
归并排序力扣题(leetcode)萍
1.概述在人工智能快速发展的今天,AI不再仅仅是回答问题的聊天机器人,而是正在演变为能够主动完成复杂任务的智能代理。OpenAI的Codex CLI就是这一趋势的典型代表——一个跨平台的本地软件代理,能够在用户的机器上安全高效地生成高质量的软件变…...
)
告别模拟器!手把手教你将Flutter App部署到树莓派4B(ARM64 Linux实战)
告别模拟器!手把手教你将Flutter App部署到树莓派4B(ARM64 Linux实战) 在物联网和边缘计算蓬勃发展的今天,开发者越来越需要将现代UI框架的能力延伸到资源受限的嵌入式设备。树莓派4B作为一款性价比极高的ARM64开发板,…...

告别“伪快充”:实测2026年五款最快移动电源,消费者需警惕哪些坑?
面对“告别充电焦虑”的营销话术,消费者最该关注的是“实测”与“兼容”。2026年这五款移动电源虽标榜高功率,但实际体验取决于三点:第一,协议匹配。若你的手机不支持该电源的私有快充协议(如某品牌200W仅适配自家旗舰…...
云服务器部署)
前后端分离项目(Vue + Java)云服务器部署
前后端分离项目(Vue Java)云服务器部署完整版文档 文档说明 本文档适用于: 前端:Vue2 / Vue3 项目后端:SpringBoot 项目服务器:Linux 云服务器(CentOS7 / CentOS8 / Ubuntu)部署方式…...
FastAPI 2.0流式AI响应落地全链路(从uvicorn配置到SSE/Chunked Transfer终极适配)
第一章:FastAPI 2.0流式AI响应落地全链路概览FastAPI 2.0 引入了对原生异步流式响应(StreamingResponse)的深度增强支持,结合 ASGI 3.0 规范与现代 LLM 推理服务特性,为构建低延迟、高吞吐的 AI 对话接口提供了坚实基础…...

ESP32-S3播放网络音频避坑指南:PlatformIO库依赖、I2S引脚冲突与内存优化
ESP32-S3音频开发实战:从库依赖管理到高稳定流媒体方案 引言:当智能硬件遇上音频流媒体 在物联网设备上实现音频播放功能,听起来像是把手机上的功能搬到了一个小开发板上——直到你真正开始动手。ESP32-S3凭借其双核处理能力和丰富的外设接口…...