4.5-Channel 和 Flow:SharedFlow 和 StateFlow
文章目录
- SharedFlow
- 数据流的收集和事件订阅的区别
- launchIn() 和 shareIn() 的区别
- SharedFlow 与 Flow、Channel 的区别
- shareIn() 适用场景
- shareIn() 的具体参数说明
- shareIn() 的 replay 参数
- shareIn() 的 started 参数
- WhileSubscribed() 的参数及适用场景
- MutableSharedFlow、asSharedFlow()
- MutableSharedFlow
- asSharedFlow()
- StateFlow、MutableStateFlow、asStateFlow()
- 总结
SharedFlow 和 StateFlow 都是一种特殊的 Flow 的变种,SharedFlow 是把 Flow 的功能从数据流的收集改成了事件流;StateFlow 是 SharedFlow 的细化细分,StateFlow 将事件流改成了状态订阅,经过这两个 Flow 的变种一下就把 Flow 的适用场景切换到了一个非常实用的范围。
但是需要了解 SharedFlow 和 StateFlow 就必须得掌握 Flow,所以在开始这篇文章前建议回看 Flow 的功能定位、工作原理及应用场景 和 Flow 的创建、收集和操作符,在掌握 Flow 的基础上学习 SharedFlow 和 StateFlow 才能更好的了解透彻。
SharedFlow
数据流的收集和事件订阅的区别
在前面的章节我们有讲过一个用 Flow 持续获取实时天气信息的例子:
var count = 0// 只负责数据的生产获取
val weatherFlow = flow {while (count < 10) {emit(getWeather())count++delay(1000)}
}suspend fun getWeather() = withContext(Dispatchers.IO) {"Sunny"
}fun main() = runBlocking {val scope = CoroutineScope(EmptyCoroutineContext)scope.launch {weatherFlow.collect {println("count = ${count}, Weather: $it")}println("done")}delay(15000)
}
通过调用 collect() [订阅] 接收数据。说是 [订阅] 更确切的说其实是 [收集],Flow 虽然是个数据流但是它只是设定好了数据流的规则,而并不是直接开始启动数据流开始生产,生产过程是在调用 collect() 时才启动的,并且是每次调用 collect() 都分别启动一个新的数据流。这也是为什么 Flow 提供数据收集的函数名为 collect() 而不是 subscribe()。
按上面这么说你或许会有疑惑:既然数据收集这个视角它这么没用,为什么不一开始就把 Flow 设计成事件订阅的视角?
因为 数据收集并不是没用,而是更加通用而已。事件订阅的场景比普通的数据收集要多得多,但并不能简单的说它更有用,而是它更专、更垂直。
实际上事件订阅就是一种特殊类型的数据收集,用数据收集的功能是能实现事件订阅的功能,这种事件订阅的 API 在 Flow 也有提供就是 SharedFlow。
launchIn() 和 shareIn() 的区别
在讲解 Flow 操作符时有提到一个函数 launchIn(),它会立即用你指定的 CoroutineScope 启动一个协程,然后调用 collect() 在这个协程启动收集流程:
Collect.ktpublic fun <T> Flow<T>.launchIn(scope: CoroutineScope): Job = scope.launch {collect() // tail-call
}
还有一个函数 shareIn(),shareIn() 可以将一个已存在的 Flow 转换成 SharedFlow,同样的也是调用 collect() 收集:
fun main() = runBlocking {val scope = CoroutineScope(EmptyCoroutineContext)val flow = flow {emit(1)delay(1000)emit(2)delay(1000)emit(3)}// 通过 shareIn() 将 Flow 转换成 SharedFlowval sharedFlow = flow.shareIn(scope)scope.launch {sharedFlow.collect { println("SharedFlow in Coroutine: $it")}}delay(10000)
}输出结果:
SharedFlow in Coroutine: 1
SharedFlow in Coroutine: 2
SharedFlow in Coroutine: 3
shareIn() 还可以定制指定数据收集的时间,比如修改为 SharingStarted.Eagerly 立即启动:
fun main() = runBlocking {val scope = CoroutineScope(EmptyCoroutineContext)val flow = flow {emit(1)delay(1000)emit(2)delay(1000)emit(3)}// 指定启动收集时间为 Eagerly,创建 SharedFlow 的同时立即启动生产val sharedFlow = flow.shareIn(scope, SharingStarted.Eagerly)scope.launch {sharedFlow.collect { println("SharedFlow in Coroutine: $it")}}delay(10000)
}
shareIn() 其实是会创建一个新的 Flow,把上游 Flow 发送的每条数据转发到下游每个调用 collect() 的 FlowCollector:
Share.ktpublic fun <T> Flow<T>.shareIn(scope: CoroutineScope,started: SharingStarted,replay: Int = 0
): SharedFlow<T> {val config = configureSharing(replay)// 创建了一个 SharedFlow,转发上游发送的数据val shared = MutableSharedFlow<T>(replay = replay,extraBufferCapacity = config.extraBufferCapacity,onBufferOverflow = config.onBufferOverflow)@Suppress("UNCHECKED_CAST")val job = scope.launchSharing(config.context, config.upstream, shared, started, NO_VALUE as T)return ReadonlySharedFlow(shared, job)
}
launchIn() 和 shareIn() 都是启动一个协程并在协程里调用 Flow 的 collect(),但它们有两点区别:
-
shareIn() 并不是第一时间就启动 Flow 的收集,可以通过参数定制启动收集的时间
-
shareIn() 会创建一个新的 Flow 并返回,返回的 Flow 类型就是 SharedFlow;SharedFlow 实际上只是把上游 Flow 发送的每条数据做转发
SharedFlow 与 Flow、Channel 的区别
fun main() = runBlocking {val scope = CoroutineScope(EmptyCoroutineContext)// 上游 Flow 数据val flow = flow {emit(1)delay(1000)emit(2)delay(1000)emit(3)}// shareIn() 创建了一个新的 Flow 为 SharedFlowval sharedFlow = flow.shareIn(scope, SharingStarted.Eagerly)scope.launch {// 上游 Flow 已经准备了数据,所以这里的 SharedFlow 其实是转发上游的数据下来收集sharedFlow.collect { println("SharedFlow in Coroutine: $it")}}delay(10000)
}
从这个角度分析,shareIn() 创建了 SharedFlow 把 [数据生产和数据收集流程分拆开],这个特点让 SharedFlow 相比传统的 Flow,倒不如说 SharedFlow 更像是 Channel。
但 SharedFlow 和 Channel 不一样的是,SharedFlow 不是瓜分式的,而是每条数据都会发送到每一个进行中的 collect()。
比如下面我们调用多个 collect(),正常是会完整打印所有数据,和 Flow 一样:
fun main() = runBlocking {val scope = CoroutineScope(EmptyCoroutineContext)val flow = flow {emit(1)delay(1000)emit(2)delay(1000)emit(3)}val sharedFlow = flow.shareIn(scope, SharingStarted.Eagerly)scope.launch {sharedFlow.collect { println("SharedFlow in Coroutine 1: $it")}}scope.launch {sharedFlow.collect { println("SharedFlow in Coroutine 2: $it")}} delay(10000)
}输出结果:
SharedFlow in Coroutine 1: 1
SharedFlow in Coroutine 2: 1
SharedFlow in Coroutine 2: 2
SharedFlow in Coroutine 1: 2
SharedFlow in Coroutine 1: 3
SharedFlow in Coroutine 2: 3
普通的 Flow 多次调用 collect() 都独立完整跑一次流程,SharedFlow 是多次调用 collect() 只跑一次流程,即用 SharedFlow 事件订阅调用 collect() 发生在数据发送之后,调用 collect() 前发送的数据将丢失。
为了验证上面的说法,我们给调用 collect() 前分别加延迟:
fun main() = runBlocking {val scope = CoroutineScope(EmptyCoroutineContext)val flow = flow {emit(1)delay(1000)emit(2)delay(1000)emit(3)}val sharedFlow = flow.shareIn(scope, SharingStarted.Eagerly)scope.launch {delay(500)// SharedFlow 设置了调用 sharedIn() 就立即启动// 这里延迟 500ms 后才调用的 collect(),错过了第一条数据sharedFlow.collect { println("SharedFlow in Coroutine 1: $it")}}scope.launch {delay(1500)// 这里延迟 1500ms 后才调用的 collect(),错过了两条数据sharedFlow.collect { println("SharedFlow in Coroutine 2: $it")}} delay(10000)
}Flow 的输出结果:
SharedFlow in Coroutine 1: 1
SharedFlow in Coroutine 2: 1
SharedFlow in Coroutine 2: 2
SharedFlow in Coroutine 1: 2
SharedFlow in Coroutine 1: 3
SharedFlow in Coroutine 2: 3SharedFlow 的输出结果:
SharedFlow in Coroutine 1: 2
SharedFlow in Coroutine 2: 3
SharedFlow in Coroutine 1: 3
Flow 还是会正常打印完整,这里 SharedFlow 分别加了延迟后都错过了数据接收没有打印出来。这就是 SharedFlow。
接下来我们再聊聊 [冷] 和 [热] 的话题。
在官方说法,Channel 是 [热] 的,Flow 是 [冷] 的,Channel 的 [热] 其实就是不读取数据它也可以发送,Flow 的 [冷] 是只在每次 collect() 被调用的时候才会启动数据发送流程。
SharedFlow 虽然是 Flow,但它是 [热] 的,因为 SharedFlow 的活跃状态跟它是否正在被调用 collect() 函数来收集数据是无关的,所以它的活跃状态是独立的,这就跟 Channel 一样了,所以它是 [热] 的。
SharedFlow 的 [热] 和 Channel 的 [热] 不太一样:Channel 的 [热] 是真的数据的发送和读取两个流程完全独立的;SharedFlow 的 [热] 其实并不是技术角度的描述,而是业务逻辑角度的,它的本质依然是在 collect() 被调用时才开始生产,本质上 SharedFlow 依然是 [冷] 的,但是由于它背靠着一个独立运作的 Flow,所以它生产出来的数据跟 collect() 的调用并没有绑定,而是独立生产的。
所以我们说 SharedFlow 是 [冷] 的那就是从技术角度分析,说它是 [热] 的那就是从业务逻辑角度分析,两个说法都对。
对 SharedFlow 调用多次 collect() 虽然它被收集了多次,但它们的数据源是同一套而不是各自一套,这就是共享。
shareIn() 适用场景
shareIn() 适用场景:
-
数据来源共享:如果想要一个 Flow 它被收集多次的时候都可以共享相同的数据生产流程,就可以用 shareIn() 将 Flow 转成 SharedFlow,再让下游去收集 SharedFlow,多次的收集之间是依赖的同一个数据流
-
生产提前启动:SharedFlow 能做到数据生产的提前启动,如果有一个 Flow 有耗时的初始化的操作,但不希望在调用 collect() 的时候等待这个初始化,也可以将 Flow 转成 SharedFlow,因为在这里的目的并不是共享,而是为了提前启动生产
-
事件订阅:因为 SharedFlow 是 [热] 的,生产流程是独立的,那么在开始生产之后才开始收集,那就会漏掉之前生产的数据,所以 SharedFlow 也适合对从头开始收集数据没有需求的场景
SharedFlow 的效果是把 [数据生产和数据收集流程分拆开],这个效果让 SharedFlow 可以满足各种需求场景,比如事件订阅、提前启动生产、数据来源共享等,通常来讲我们也会把它用在事件流订阅的场景。
shareIn() 的适用场景本质上就是 [数据生产和数据收集流程分拆开] 的需求,都可以将 Flow 转成 SharedFlow 来解决。SharedFlow 的 [热] 就是我们使用 SharedFlow 的根本原因。
SharedFlow 并不会因为生产流程的结束而结束订阅,即数据生产都发送完了,SharedFlow 的 collect() 会一直运行,直到外部协程的取消而抛异常结束。
shareIn() 的具体参数说明
Share.ktpublic fun <T> Flow<T>.shareIn(scope: CoroutineScope,started: SharingStarted,replay: Int = 0
): SharedFlow<T> {val config = configureSharing(replay)val shared = MutableSharedFlow<T>(replay = replay,extraBufferCapacity = config.extraBufferCapacity,onBufferOverflow = config.onBufferOverflow)@Suppress("UNCHECKED_CAST")val job = scope.launchSharing(config.context, config.upstream, shared, started, NO_VALUE as T)return ReadonlySharedFlow(shared, job)
}
shareIn() 有三个参数,第一个参数在前面小节也有讲到是指定启动事件订阅时所在的协程,主要是讲后面的两个参数。
shareIn() 的 replay 参数
replay 参数第一个功能是缓冲,可以做到根据设置的数值暂存数据。
比如在前面小节用 SharedFlow 收集数据,延迟一段时间在调用 collect(),最终结果就是会丢失数据,因为 SharedFlow 创建的同时也已经启动了生产流程。
现在我们设置 replay 参数暂存一条数据:
fun main() = runBlocking {val scope = CoroutineScope(EmptyCoroutineContext)val flow = flow {emit(1)delay(1000)emit(2)delay(1000)emit(3)}// 设置 replay 参数为 1,表示暂存缓冲一条数据val sharedFlow = flow.shareIn(scope, SharingStarted.Eagerly, 1)scope.launch {delay(500)sharedFlow.collect { println("SharedFlow in Coroutine 1: $it")}}scope.launch {delay(1500)sharedFlow.collect {println("SharedFlow in Coroutine 2: $it")}}delay(10000)
}输出结果:
// SharedFlow in Coroutine 1: 1,这个来不及消费的数据打印了出来
// SharedFlow in Coroutine 2: 1,没有打印,因为缓冲暂存 1 条数据,所以第一条数据被丢弃,但打印了第二条数据 SharedFlow in Coroutine 2: 2
SharedFlow in Coroutine 1: 1
SharedFlow in Coroutine 1: 2
SharedFlow in Coroutine 2: 2
SharedFlow in Coroutine 2: 3
SharedFlow in Coroutine 1: 3
将 replay 参数设置为 1 暂存一条数据,第一个 collect() 来不及消费的第一条数据也正常打印了出来,第二个 collect() 因为错过了两条数据,但暂存数据只有一条,所以第一条数据被丢弃了,第二条数据正常打印。
replay 参数第二个功能是缓存,对于已经消费过的数据,也依然缓冲下来,用来给后面新订阅的 collect() 使用。简单说就是除了缓冲来不及消费的数据,还会把已经消费过的数据也缓冲下来。
用个例子说明下 replay 缓存的功能:
fun main() = runBlocking {val scope = CoroutineScope(EmptyCoroutineContext)val flow = flow {emit(1)delay(1000)emit(2)delay(1000)emit(3)}// replay 设置缓存两条数据val sharedFlow = flow.shareIn(scope, SharingStarted.Eagerly, 2)scope.launch {delay(500)sharedFlow.collect { println("SharedFlow in Coroutine 1: $it")}}scope.launch {delay(5000) // 都错过了数据,订阅时会立即被发送出来sharedFlow.collect {println("SharedFlow in Coroutine 2: $it")}}delay(10000)
}输出结果:
SharedFlow in Coroutine 1: 1
SharedFlow in Coroutine 1: 2
SharedFlow in Coroutine 1: 3
SharedFlow in Coroutine 2: 2 // 立即收到缓存发送的数据
SharedFlow in Coroutine 2: 3 // 立即收到缓存发送的数据
上面的例子可以看到,第二个 collect() 已经都错过了数据的发送,但在调用 collect() 时还是能立即接收到数据,接收到的数据数量是 replay 设置的大小。
总结下 replay 参数的功能:
-
replay 参数是即有缓冲功能又有缓存功能的缓冲,提前生产数据但收集靠后时要缓冲暂存多少漏接收的数据
-
在来不及消费的时候可以先把数据缓冲下来,缓冲的尺寸就是 replay 的大小
-
对于已经使用完的数据它也会继续缓存下来,等到有新订阅的时候直接发送出来,缓存的大小也是 replay 的大小
shareIn() 的 started 参数
started 是用于设置数据生产的启动时间。它有三个数值:
-
SharingStarted.Eagerly:调用 shareIn() 创建 SharedFlow 的同时立即启动数据的生产
-
SharingStarted.Lazily:调用第一次 collect() 时才会启动数据的生产
-
SharingStarted.WhileSubscribed():可以把上游的数据流给结束和重启的规则,它是一种复杂化的 Lazily,不仅是在第一次订阅的时候启动上游的数据流,而且在下游所有订阅全都结束之后,它会把上游 Flow 的生产流程也结束掉,这时候如果再有订阅,它就会重新启动上游的数据流
在讲解 WhileSubscribed() 前插入一个话题,SharedFlow 的 collect() 订阅并不会因为上游 Flow 数据发送完成而结束。SharedFlow 的 collect() 返回值是 Nothing:
SharedFlow.ktoverride suspend fun collect(collector: FlowCollector<T>): Nothing
一个返回值为 Nothing,说明它永远不会返回一直运行下去,除非抛出异常。比如 SharedFlow 这里就可以通过外部协程的取消或抛出其他异常取消 SharedFlow 的订阅。
继续回到 WhileSubscribed(),模拟调用第一个 collect() 后结束了 Flow 的生产流程,调用第二个 collect() 时会重新启动生产流程,但这时候使用的是上一个 collect() 生产过的数据缓存:
fun main() = runBlocking {val scope = CoroutineScope(EmptyCoroutineContext)val flow = flow {emit(1)delay(1000)emit(2)delay(1000)emit(3)}val sharedFlow = flow.shareIn(scope, SharingStarted.WhileSubscribed(), 2)scope.launch {val parent = thislaunch {// 第二个 collect() 订阅前取消了第一个 SharedFlow 的订阅,触发上游重启生产delay(4000) // 通过取消协程的方式结束 SharedFlow 的订阅// 模拟 SharedFlow 所有 collect() 结束了,才让第二个 collect() 能触发上游的 Flow 的重启parent.cancel()}delay(1500)sharedFlow.collect { println("SharedFlow in Coroutine 1: $it")}}scope.launch {delay(5000)sharedFlow.collect {println("SharedFlow in Coroutine 2: $it")}}delay(10000)
}输出结果:
SharedFlow in Coroutine 1: 1
SharedFlow in Coroutine 1: 2
SharedFlow in Coroutine 1: 3
SharedFlow in Coroutine 2: 2 // 立即打印出来,使用了上一个 collect() 的数据缓存
SharedFlow in Coroutine 2: 3 // 立即打印出来,使用了上一个 collect() 的数据缓存
SharedFlow in Coroutine 2: 1 // 重启上游 Flow 生产发送的数据
SharedFlow in Coroutine 2: 2 // 重启上游 Flow 生产发送的数据
SharedFlow in Coroutine 2: 3 // 重启上游 Flow 生产发送的数据
上面的例子通过第一个 collect() 手动取消外部协程的方式,模拟第二个 collect() 触发重启上游 Flow 生产发送。从打印可以看到第二个 collect() 在重启前会先收到上一个 collect() 的缓存数据,然后重新接收到了上游 Flow 重启发送的数据。
WhileSubscribed() 的参数及适用场景
SharingStarted.ktpublic fun WhileSubscribed(stopTimeoutMillis: Long = 0,replayExpirationMillis: Long = Long.MAX_VALUE
): SharingStarted = StartedWhileSubscribed(stopTimeoutMillis, replayExpirationMillis)
WhileSubscribed() 还可以定制参数:
-
stopTimeoutMillis:所有 collect() 结束之后依然不判定为 [所有 collect() 都结束],等待该参数设置的时间后还没有新的 collect(),才认为是都结束将上游 Flow 的生产流程结束
-
replayExpirationMillis:设置订阅流程结束之后、清空缓存的让缓存失效的时间,最后一个 collect() 结束且 stopTimeoutMillis 也超时之后,再过 replayExpirationMillis 时间后还是没有新的 collect() 被调用,缓存下来的数据就会被丢弃
WhileSubscribed() 的适用场景:假设软件里有一个可以被订阅的事件流,这个事件流会在多个地方被订阅,而同时这个事件流还非常的重即生产流程非常消耗资源,所以想要在所有订阅都结束的时候及时的结束生产;这种场景就很适合用 WhileSubscribed() 配置自动结束、自动重启的 SharedFlow。
MutableSharedFlow、asSharedFlow()
MutableSharedFlow
一直以来我们讲解 Flow 都是在内部调用 emit() 生产数据,然后在一个地方调用 collect() 收集发送过来的数据;但我们的业务需求可能需要能支持在外部调用 emit() 发送数据,比如 UI 交互点击事件,在用户点击按钮的时候,可以从它的点击监听回调能调用一下 emit(),而不是只能从上游的 Flow 把事件发送出来,这是一种很正常的需求。
需要能在外部调用 emit() 发送数据要用 MutableSharedFlow:
fun main() = runBlocking {val scope = CoroutineScope(EmptyCoroutineContext)val mutableSharedFlow = MutableSharedFlow<String>()scope.launch {mutableSharedFlow.emit("Hello") // 可以外部发送数据mutableSharedFlow.collect {println("mutableSharedFlow: $it")}}delay(10000)
}
或许你会有疑问:为什么 Flow 不直接提供可以外部发送数据的 Flow?
Flow 不提供外部发送数据的原因也很简单,Flow 数据流本就是一个需要指定规则然后按规则一条条把数据发送出来,本来就不需要从外部发送数据,如果还提供外部发送数据,内部和外部的数据混乱数据源不统一,反而更容易让开发者不小心写出错误代码。
SharedFlow 是事件流,它天然就是需要从各个地方发送数据的,Flow 数据流的限制就不需要了,允许让我们在任何协程发送数据。
MutableSharedFlow 相比 shareIn() 并不是从内部发送数据变成了外部发送数据,而是从只能从上游 Flow 发送数据变成可以从任何协程发送数据。
MutableSharedFlow 和 shareIn() 的选择:
-
如果要创建一个事件流,在外部生产数据发送数据源,就用 MutableSharedFlow
-
如果已经有了一个生产事件流的 Flow,不需要自己写生产数据的代码,直接将 Flow 用 shareIn() 转成 SharedFlow 即可
asSharedFlow()
在 Android 经常会在 ViewModel 定义 MutableSharedFlow,在数据请求后通过 MutableSharedFlow 调用 emit() 将结果通知到页面 Activity 或 Fragment,也就是页面需要订阅事件,希望把 MutableSharedFlow 暴露出来给外部去订阅,但又不希望让外部也来发送数据的时候,可以通过 asSharedFlow() 将 MutableSharedFlow 转换成 SharedFlow:
class MyViewModel : ViewModel() {private val repository = Repository()private val flow = MutableSharedFlow<String>()val sharedFlow = flow.asSharedFlow() // 提供给外部订阅fun request() {viewModelScope.launch {repository.request {flow.emit(it)}} }
}class MyActivity : ComponentActivity() {private val viewModel by viewModels<MyViewModel>()override fun onCreate(savedInstanceState: Bundle?) {super.onCreate(savedInstanceState)lifecycleScope.launch {viewModel.sharedFlow.collect {// ...}}}
}
StateFlow、MutableStateFlow、asStateFlow()
StateFlow 是一种特殊的 SharedFlow,SharedFlow 是把数据流的收集收窄到了事件流的订阅,StateFlow 则是进一步的收窄,从事件流的订阅收窄到了状态的订阅。
StateFlow.ktpublic interface StateFlow<out T> : SharedFlow<T> {// 最新的一条数据public val value: T
}
可以看到 StateFlow 其实就是 SharedFlow 的子接口,并且增加了一个 value 属性。value 就是 SharedFlow 里最新的一条数据,所以 StateFlow 实际上就是一个仅仅保存最新的一个事件的 SharedFlow 事件流。
我们用 StateFlow 实现状态订阅:
fun main() = runBlocking {val scope = CoroutineScope(EmptyCoroutineContext)val name = MutableStateFlow("test") // 提供初始值scope.launch { name.collect {println("State: $it")}}scope.launch {delay(2000)name.emit("Hello world")}delay(10000)
}输出结果:
State: test
State: Hello world
如果想 将 Flow 转换成 StateFlow 也可以使用 stateIn():
fun main() = runBlocking {val scope = CoroutineScope(EmptyCoroutineContext)val flow = flow {emit(1)delay(1000)emit(2)delay(1000)emit(3)}// 通过 stateIn() 将 Flow 转换成 StateFlowval stateFlow = flow.stateIn(scope)scope.launch { stateFlow.collect {println("State: $it")}}delay(10000)
}
asStateFlow() 可以把可读写的 MutableStateFlow 转换为只读的 StateFlow,用来对外暴露的时候把写数据的功能给隐藏。
总结
1、数据流的收集和事件订阅的区别
Flow 数据流的数据收集相比事件订阅场景更加通用,事件订阅的场景比普通的数据收集要多得多,但并不能简单的说它更有用,而是它更专、更垂直。
实际上事件订阅就是一种特殊类型的数据收集,用数据收集的功能是能实现事件订阅的功能,这种事件订阅的 API 在 Flow 也有提供就是 SharedFlow。
2、launchIn() 和 shareIn() 的区别
launchIn() 和 shareIn() 都是启动一个协程并在协程里调用 Flow 的 collect(),但它们有两点区别:
-
shareIn() 并不是第一时间就启动 Flow 的收集,可以通过参数定制启动收集的时间
-
shareIn() 会创建一个新的 Flow 并返回,返回的 Flow 类型就是 SharedFlow;SharedFlow 实际上只是把上游 Flow 发送的每条数据做转发
3、SharedFlow 与 Flow、Channel 的区别
(1)SharedFlow 和 Flow 的区别
普通的 Flow 多次调用 collect() 都独立完整跑一次流程,SharedFlow 是多次调用 collect() 只跑一次流程,即用 SharedFlow 事件订阅调用 collect() 发生在数据发送之后,调用 collect() 前发送的数据将丢失。
(2)SharedFlow 和 Channel 的区别
在官方说法,Channel 是 [热] 的,Flow 是 [冷] 的,Channel 的 [热] 其实就是不读取数据它也可以发送,Flow 的 [冷] 是只在每次 collect() 被调用的时候才会启动数据发送流程。
SharedFlow 虽然是 Flow,但它是 [热] 的,因为 SharedFlow 的活跃状态跟它是否正在被调用 collect() 函数来收集数据是无关的,所以它的活跃状态是独立的,这就跟 Channel 一样了,所以它是 [热] 的。
SharedFlow 的 [热] 和 Channel 的 [热] 不太一样:Channel 的 [热] 是真的数据的发送和读取两个流程完全独立的;SharedFlow 的 [热] 其实并不是技术角度的描述,而是业务逻辑角度的,它的本质依然是在 collect() 被调用时才开始生产,本质上 SharedFlow 依然是 [冷] 的,但是由于它背靠着一个独立运作的 Flow,所以它生产出来的数据跟 collect() 的调用并没有绑定,而是独立生产的。
所以我们说 SharedFlow 是 [冷] 的那就是从技术角度分析,说它是 [热] 的那就是从业务逻辑角度分析,两个说法都对。
对 SharedFlow 调用多次 collect() 虽然它被收集了多次,但它们的数据源是同一套而不是各自一套,这就是共享。
4、shareIn() 的适用场景
-
数据来源共享:如果想要一个 Flow 它被收集多次的时候都可以共享相同的数据生产流程,就可以用 shareIn() 将 Flow 转成 SharedFlow,再让下游去收集 SharedFlow,多次的收集之间是依赖的同一个数据流
-
生产提前启动:SharedFlow 能做到数据生产的提前启动,如果有一个 Flow 有耗时的初始化的操作,但不希望在调用 collect() 的时候等待这个初始化,也可以将 Flow 转成 SharedFlow,因为在这里的目的并不是共享,而是为了提前启动生产
-
事件订阅:因为 SharedFlow 是 [热] 的,生产流程是独立的,那么在开始生产之后才开始收集,那就会漏掉之前生产的数据,所以 SharedFlow 也适合对从头开始收集数据没有需求的场景
SharedFlow 的效果是把 [数据生产和数据收集流程分拆开],这个效果让 SharedFlow 可以满足各种需求场景,比如事件订阅、提前启动生产、数据来源共享等,通常来讲我们也会把它用在事件流订阅的场景。
shareIn() 的适用场景本质上就是 [数据生产和数据收集流程分拆开] 的需求,都可以将 Flow 转成 SharedFlow 来解决。SharedFlow 的 [热] 就是我们使用 SharedFlow 的根本原因。
SharedFlow 并不会因为生产流程的结束而结束订阅,即数据生产都发送完了,SharedFlow 的 collect() 会一直运行,直到外部协程的取消而抛异常结束。
5、shareIn() 的具体参数
(1)shareIn() 的 replay 参数
replay 参数是即有缓冲功能又有缓存功能的缓冲,提前生产数据但收集靠后时要缓冲暂存多少漏接收的数据
-
在来不及消费的时候可以先把数据缓冲下来,缓冲的尺寸就是 replay 的大小
-
对于已经使用完的数据它也会继续缓存下来,等到有新订阅的时候直接发送出来,缓存的大小也是 replay 的大小
(2)shareIn() 的 started 参数
started 是用于设置数据生产的启动时间。它有三个数值:
-
SharingStarted.Eagerly:调用 shareIn() 创建 SharedFlow 的同时立即启动数据的生产
-
SharingStarted.Lazily:调用第一次 collect() 时才会启动数据的生产
-
SharingStarted.WhileSubscribed():可以把上游的数据流给结束和重启的规则,它是一种复杂化的 Lazily,不仅是在第一次订阅的时候启动上游的数据流,而且在下游所有订阅全都结束之后,它会把上游 Flow 的生产流程也结束掉,这时候如果再有订阅,它就会重新启动上游的数据流
除此之外还插入说明了 SharedFlow 的 collect() 订阅并不会因为上游 Flow 数据发送完成而结束。
SharedFlow 的 collect() 返回值为 Nothing,说明它永远不会返回一直运行下去,除非抛出异常。比如可以通过外部协程的取消间接取消 SharedFlow 的订阅。
(3)WhileSubscribed() 的适用场景
假设软件里有一个可以被订阅的事件流,这个事件流会在多个地方被订阅,而同时这个事件流还非常的重即生产流程非常消耗资源,所以想要在所有订阅都结束的时候及时的结束生产;这种场景就很适合用 WhileSubscribed() 配置自动结束、自动重启的 SharedFlow。
6、MutableSharedFlow、asSharedFlow()
(1)MutableSharedFlow
需要能在外部调用 emit() 发送数据要用 MutableSharedFlow。
Flow 不提供外部发送数据的原因也很简单,Flow 数据流本就是一个需要指定规则然后按规则一条条把数据发送出来,本来就不需要从外部发送数据,如果还提供外部发送数据,内部和外部的数据混乱数据源不统一,反而更容易让开发者不小心写出错误代码。
SharedFlow 是事件流,它天然就是需要从各个地方发送数据的,Flow 数据流的限制就不需要了,允许让我们在任何协程发送数据。
MutableSharedFlow 和 shareIn() 的选择:
-
如果要创建一个事件流,在外部生产数据发送数据源,就用 MutableSharedFlow
-
如果已经有了一个生产事件流的 Flow,不需要自己写生产数据的代码,直接将 Flow 用 shareIn() 转成 SharedFlow 即可
(2)asSharedFlow()
希望把 MutableSharedFlow 暴露出来给外部去订阅,但又不希望让外部也来发送数据的时候,可以通过 asSharedFlow() 将 MutableSharedFlow 转换成 SharedFlow。
7、StateFlow、MutableStateFlow、asStateFlow()
StateFlow 其实就是 SharedFlow 的子接口,StateFlow 实际上就是一个仅仅保存最新的一个事件的 SharedFlow 事件流。
将 Flow 转换成 StateFlow 也可以使用 stateIn()。
asStateFlow() 可以把可读写的 MutableStateFlow 转换为只读的 StateFlow,用来对外暴露的时候把写数据的功能给隐藏。
相关文章:

4.5-Channel 和 Flow:SharedFlow 和 StateFlow
文章目录 SharedFlow数据流的收集和事件订阅的区别launchIn() 和 shareIn() 的区别SharedFlow 与 Flow、Channel 的区别shareIn() 适用场景 shareIn() 的具体参数说明shareIn() 的 replay 参数shareIn() 的 started 参数WhileSubscribed() 的参数及适用场景 MutableSharedFlow、…...

Qt | TCP服务器实现QTcpServer,使用线程管理客户端套接字
点击上方"蓝字"关注我们 01、QTcpServer >>> QTcpServer 是 Qt 网络模块中的一个类,用于实现TCP服务器。它允许创建一个服务器,可以接受来自客户端的连接。QTcpServer 是事件驱动的,这意味着它将通过信号和槽机制处理网络事件。 常用函数 构造函数: QT…...

【提高篇】3.6 GPIO(六,寄存器介绍,下)
目录 2.3 输出速度寄存器OSPEEDR(GPIOx_OSPEEDR) (x = A..I) 2.4 上拉/下拉寄存器 (GPIOx_PUPDR) (x = A..I) 2.5 输入数据寄存器(IDR) 2.6 输出数据寄存器(ODR) 2.7 置位/复位寄存器(BSRR) 2.8 BSRR与ODR寄存器的区别 2.3 输出速度寄存器OSPEEDR(GPIOx_OSPEEDR) (…...

【AI】数据,算力,算法和应用(3)
三、算法 算法这个词,我们都不陌生。 从接触计算机,就知道有“算法”这样一个神秘的名词存在。象征着专业、权威、神秘、高难等等。 算法是一组有序的解决问题的规则和指令,用于解决特定问题的一系列步骤。算法可以被看作是解决问题的方法…...

深度学习笔记——生成对抗网络GAN
本文详细介绍早期生成式AI的代表性模型:生成对抗网络GAN。 文章目录 一、基本结构生成器判别器 二、损失函数判别器生成器交替优化目标函数 三、GAN 的训练过程训练流程概述训练流程步骤1. 初始化参数和超参数2. 定义损失函数3. 训练过程的迭代判别器训练步骤生成器…...

网络安全开源组件
本文只是针对开源项目进行收集,如果后期在工作中碰到其他开源项目将进行更新。欢迎大家在评论区留言,您在工作碰到的开源项目。 祝您工作顺利,鹏程万里! 一、FW(防火墙) 1.1 pfSense pfSense项目是一个免费…...

Python毕业设计选题:基于django+vue的智慧社区可视化平台的设计与实现+spider
开发语言:Python框架:djangoPython版本:python3.7.7数据库:mysql 5.7数据库工具:Navicat11开发软件:PyCharm 系统展示 管理员登录 管理员功能界面 养老机构管理 业主管理 社区安防管理 社区设施管理 车位…...

Oracle LinuxR7安装Oracle 12.2 RAC集群实施(DNS解析)
oracleLinuxR7-U6系统Oracle 12.2 RAC集群实施(DNS服务器) 环境 RAC1RAC2DNS服务器操作系统Oracle LinuxR7Oracle LinuxR7windows server 2008R2IP地址172.30.21.101172.30.21.102172.30.21.112主机名称hefei1hefei2hefei数据库名hefeidbhefeidb实例名…...
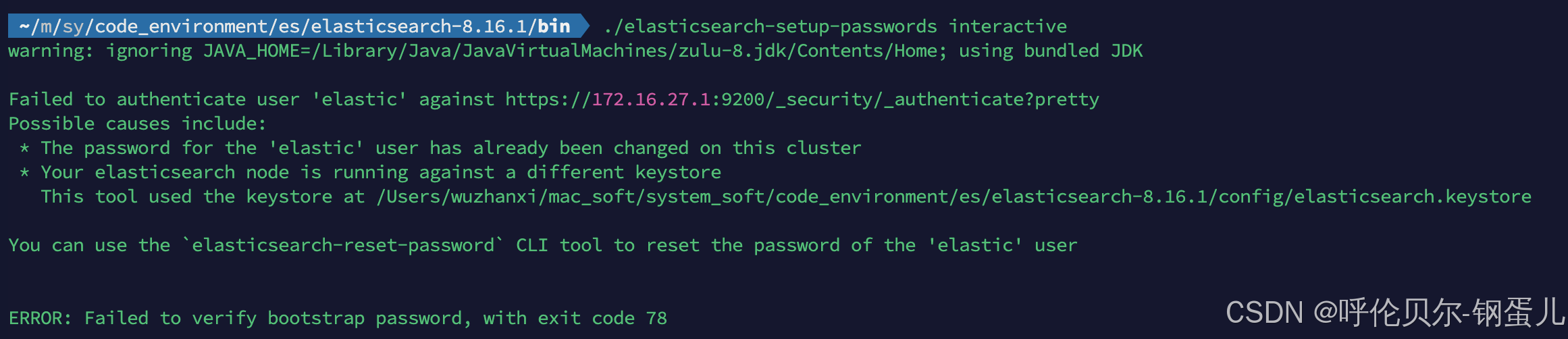
M2芯片安装es的步骤
背景:因为最近经常用到es,但是测试环境没有es,自己本地也没安装,为了方便测试,然后安装一下,但是刚开始安装就报错,记录一下,安装的版本为8.16.1 第一步:去官网下载maco…...

macos下brew安装redis
首先确保已安装brew,接下来搜索资源,在终端输入如下命令: brew search redis 演示如下: 如上看到有redis资源,下面进行安装,执行下面的命令: brew install redis 演示效果如下: …...
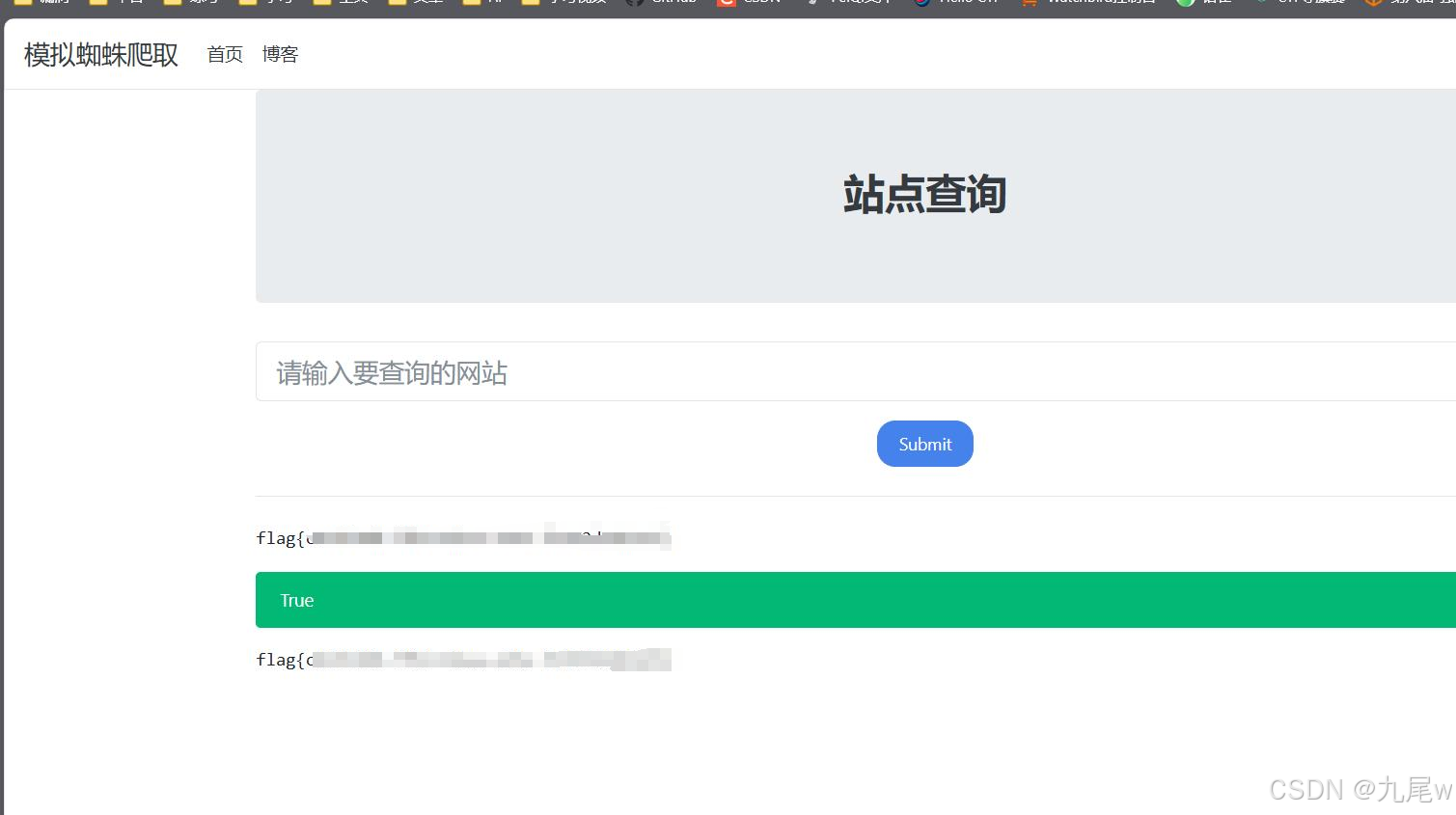
第六届金盾信安杯-SSRF
操作内容: 进入环境 可以查询网站信息 查询环境url https://114.55.67.167:52263/flag.php 返回 flag 就在这 https://114.55.67.167:52263/flag.php 把这个转换成短连接,然后再提交 得出 flag...

【论文投稿】国产游戏技术:迈向全球引领者的征途
【IEEE出版南方科技大学】第十一届电气工程与自动化国际会议(IFEEA 2024)_艾思科蓝_学术一站式服务平台 更多学术会议论文投稿请看:https://ais.cn/u/nuyAF3 目录 国产游戏技术能否引领全球? 一、国产游戏技术的崛起之路 1.1 初期探索与积…...
面试题及参考答案)
腾讯微众银行大数据面试题(包含数据分析/挖掘方向)面试题及参考答案
为什么喜欢使用 XGBoost,XGBoost 的主要优势有哪些? XGBoost 是一个优化的分布式梯度增强库,在数据科学和机器学习领域应用广泛,深受喜爱,原因主要在于其众多突出优势。 首先,它的精度高,在许多机器学习竞赛和实际应用中,XGBoost 都展现出卓越的预测准确性。其基于决策…...

【Linux】死锁、读写锁、自旋锁
文章目录 1. 死锁1.1 概念1.2 死锁形成的四个必要条件1.3 避免死锁 2. 读者写者问题与读写锁2.1 读者写者问题2.2 读写锁的使用2.3 读写策略 3. 自旋锁3.1 概念3.2 原理3.3 自旋锁的使用3.4 优点与缺点 1. 死锁 1.1 概念 死锁是指在⼀组进程中的各个进程均占有不会释放的资源…...
Spring Web开发(请求)获取JOSN对象| 获取数据(Header)
大家好,我叫小帅今天我们来继续Spring Boot的内容。 文章目录 1. 获取JSON对象2. 获取URL中参数PathVariable3.上传⽂件RequestPart3. 获取Cookie/Session3.1 获取和设置Cookie3.1.1传统获取Cookie3.1.2简洁获取Cookie 3. 2 获取和存储Session3.2.1获取Session&…...

用c语言完成俄罗斯方块小游戏
用c语言完成俄罗斯方块小游戏 这估计是你在编程学习过程中的第一个小游戏开发,怎么说呢,在这里只针对刚学程序设计的学生,就是说刚接触C语言没多久,有一点功底的学生看看,简陋的代码,简陋的实现࿰…...
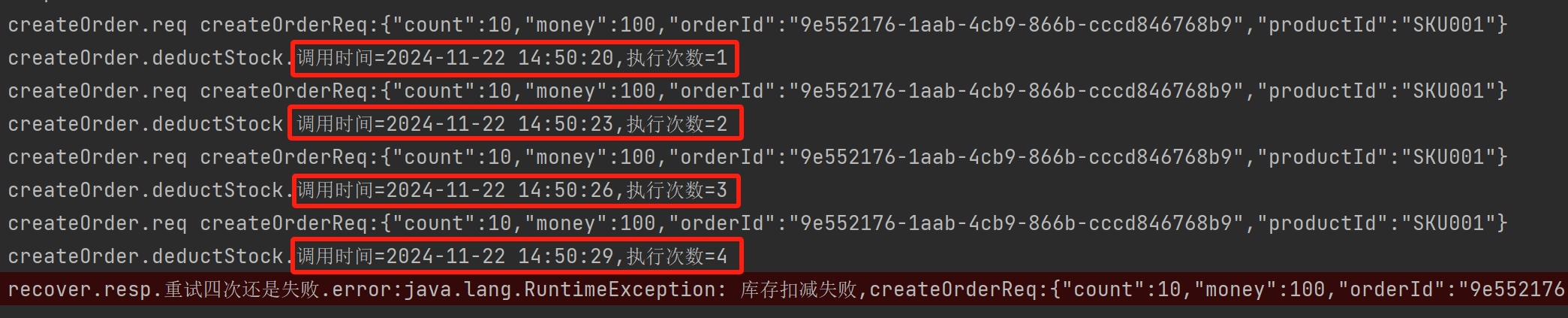
SpringBoot整合Retry详细教程
问题背景 在现代的分布式系统中,服务间的调用往往需要处理各种网络异常、超时等问题。重试机制是一种常见的解决策略,它允许应用程序在网络故障或临时性错误后自动重新尝试失败的操作。Spring Boot 提供了灵活的方式来集成重试机制,这可以通过…...
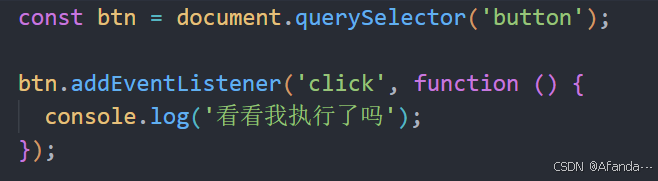
JS API事件监听(绑定)
事件监听 语法 元素对象.addEventListener(事件监听,要执行的函数) 事件监听三要素 事件源:那个dom元素被事件触发了,要获取dom元素 事件类型:用说明方式触发,比如鼠标单击click、鼠标经过mouseover等 事件调用的函数&#x…...

ceph手动部署
ceph手动部署 一、 节点规划 主机名IP地址角色ceph01.example.com172.18.0.10/24mon、mgr、osd、mds、rgwceph02.example.com172.18.0.20/24mon、mgr、osd、mds、rgwceph03.example.com172.18.0.30/24mon、mgr、osd、mds、rgw 操作系统版本: Rocky Linux release …...
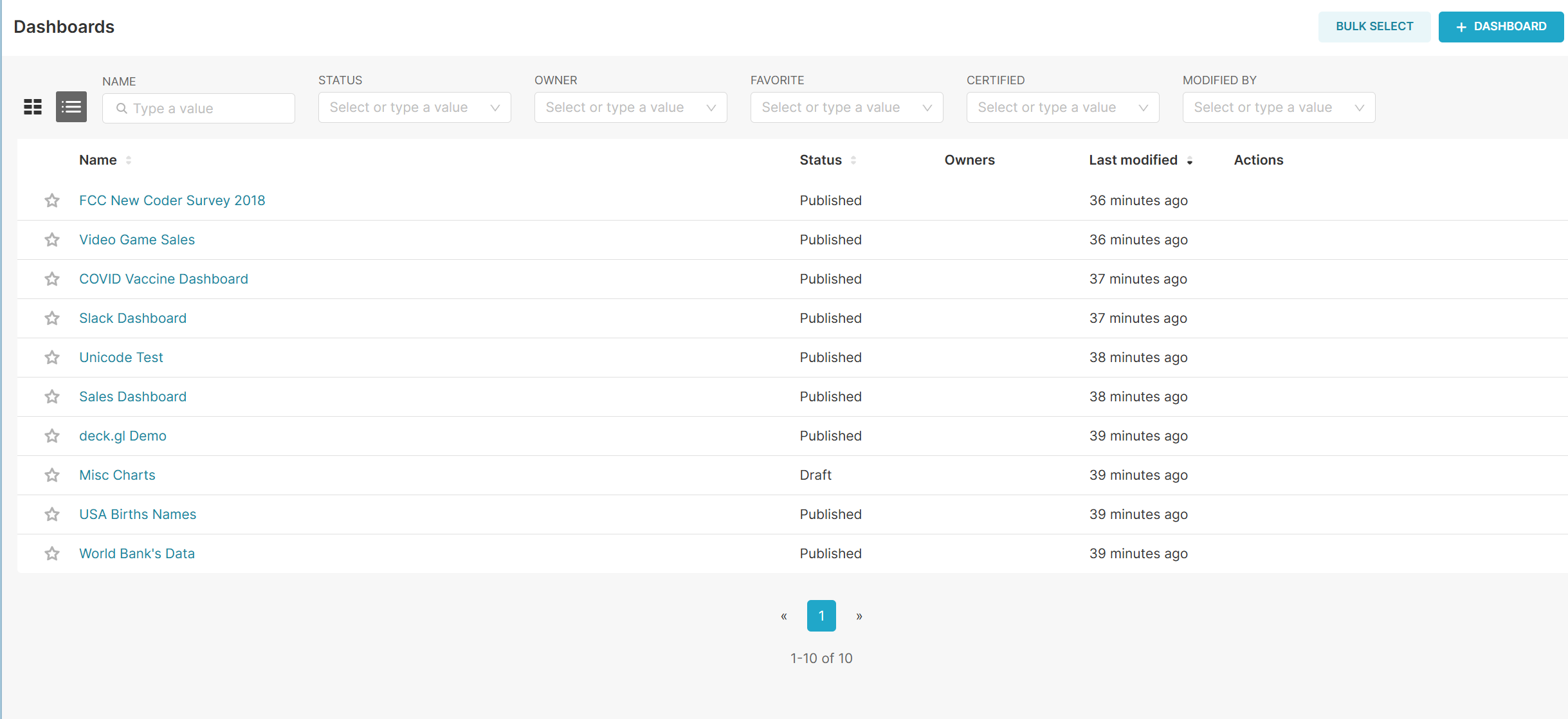
superset load_examples加载失败解决方法
如果在执行load_examples命令后,出现上方图片情况,或是相似报错(url error\connection error),大概率原因是python程序请求github数据,无法访问. 因此我们可以将数据下载在本地来解决. 1.下载zip压缩文件,存放到本地 官方示例地址:GitHub - apache-superset/examples-data …...

Arduino CLI 终极指南:5分钟掌握命令行开发环境
Arduino CLI 终极指南:5分钟掌握命令行开发环境 【免费下载链接】arduino-cli Arduino command line tool 项目地址: https://gitcode.com/gh_mirrors/ar/arduino-cli Arduino CLI 是 Arduino 官方推出的命令行工具,它为开发者提供了一个无需图形…...
)
GD32 Embedded Builder实战:从零开始配置GD32VW553的GPIO(含FreeRTOS适配指南)
GD32VW553 GPIO深度开发实战:FreeRTOS环境下的高效外设控制 引言 在嵌入式开发领域,GD32系列微控制器凭借其出色的性价比和丰富的生态资源,正逐渐成为工程师们的新宠。作为GD32家族中的无线连接明星产品,GD32VW553集成了蓝牙和Wi-…...
)
CTF新手必看:用Stegsolve破解Misc图片隐写的完整流程(附盲水印解决方案)
CTF新手入门:Stegsolve图片隐写分析与盲水印实战指南 引言 第一次参加CTF比赛时,面对Misc类题目中的图片隐写,我完全摸不着头脑。直到一位资深选手向我推荐了Stegsolve这个神器,才真正打开了新世界的大门。如果你也正在为如何从一…...

GLM-OCR在AIGC内容创作流水线中的应用:从图片素材到文案生成
GLM-OCR在AIGC内容创作流水线中的应用:从图片素材到文案生成 1. 引言 你有没有遇到过这样的情况:看到一张设计精美的海报,或者一份产品介绍图,觉得里面的文案写得特别好,想借鉴一下,但只能一个字一个字地…...

OpenClaw批量操作:Qwen3-32B处理千张图片的分类与重命名实战
OpenClaw批量操作:Qwen3-32B处理千张图片的分类与重命名实战 1. 为什么需要自动化图片管理? 作为一名业余摄影师,我每个月都会积累上千张RAW格式照片。过去我的工作流程是这样的:先手动筛选废片,再按"日期主题&…...

当信号遇见MATLAB:手把手玩转采样与重建的魔法
MATLAB滤波器 信号与系统 sa函数信号采样与重建 基于MATLAB的设计抽样信号采样与重建。 (供学习交流)带源码,带注释。 6500字信号采样:从连续到离散的魔术 实验室的示波器屏幕上跳动着优美的正弦曲线,窗外的蝉鸣声忽…...

Datashader 大规模数据可视化流水线:从海量数据到高清图像的完整指南
Datashader 大规模数据可视化流水线:从海量数据到高清图像的完整指南 【免费下载链接】datashader Quickly and accurately render even the largest data. 项目地址: https://gitcode.com/gh_mirrors/da/datashader 在数据科学和可视化领域,处理…...

OpenCASCADE法向获取避坑指南:为什么你的法线方向总是反的?
OpenCASCADE法向获取避坑指南:为什么你的法线方向总是反的? 在三维建模和CAD开发中,法线方向是一个看似简单却经常让开发者头疼的问题。特别是对于OpenCASCADE这样的开源几何建模内核,初学者经常会遇到明明按照文档操作࿰…...

Qwen2-VL-2B-Instruct效果对比:与传统计算机视觉方法在目标描述上的差异
Qwen2-VL-2B-Instruct效果对比:与传统计算机视觉方法在目标描述上的差异 最近在折腾一些图像理解的项目,发现一个挺有意思的现象:同样是让机器“看懂”图片,不同的技术路线给出的答案,差别能有多大。比如,…...
Pixel Dimension Fissioner开发者案例:技术文档可读性提升的像素化改写方案
Pixel Dimension Fissioner开发者案例:技术文档可读性提升的像素化改写方案 1. 工具概览 Pixel Dimension Fissioner是一款创新的文本改写工具,基于MT5-Zero-Shot-Augment核心引擎开发。与传统AI工具不同,它将文本处理过程转化为充满游戏感…...