基于 LlamaFactory 的 LoRA 微调模型支持 vllm 批量推理的实现
背景
LlamaFactory 的 LoRA 微调功能非常便捷,微调后的模型,没有直接支持 vllm 推理,故导致推理速度不够快。
LlamaFactory 目前支持通过 VLLM API 进行部署,调用 API 时的响应速度,仍然没有vllm批量推理的速度快。
如果模型是通过 LlamaFactory 微调的,为了确保数据集的一致性,建议在推理时也使用 LlamaFactory 提供的封装数据集。
简介
在上述的背景下,我们使用 LlamaFactory 原生数据集,支持 lora的 vllm 批量推理。
完整代码如下:
import json
import os
from typing import Listfrom vllm import LLM, SamplingParams
from vllm.lora.request import LoRARequestfrom llamafactory.data import get_dataset, get_template_and_fix_tokenizer
from llamafactory.extras.constants import IGNORE_INDEX
from llamafactory.hparams import get_train_args
from llamafactory.model import load_tokenizerdef vllm_infer():model_args, data_args, training_args, finetuning_args, generating_args = (get_train_args())tokenizer = load_tokenizer(model_args)["tokenizer"]template = get_template_and_fix_tokenizer(tokenizer, data_args)eval_dataset = get_dataset(template, model_args, data_args, training_args, finetuning_args.stage, tokenizer)["eval_dataset"]prompts = [item["input_ids"] for item in eval_dataset]prompts = tokenizer.batch_decode(prompts, skip_special_tokens=False)labels = [list(filter(lambda x: x != IGNORE_INDEX, item["labels"]))for item in eval_dataset]labels = tokenizer.batch_decode(labels, skip_special_tokens=True)sampling_params = SamplingParams(temperature=generating_args.temperature,top_k=generating_args.top_k,top_p=generating_args.top_p,max_tokens=2048,)if model_args.adapter_name_or_path:if isinstance(model_args.adapter_name_or_path, list):lora_requests = []for i, _lora_path in enumerate(model_args.adapter_name_or_path):lora_requests.append(LoRARequest(f"lora_adapter_{i}", i, lora_path=_lora_path))else:lora_requests = LoRARequest("lora_adapter_0", 0, lora_path=model_args.adapter_name_or_path)enable_lora = Trueelse:lora_requests = Noneenable_lora = Falsellm = LLM(model=model_args.model_name_or_path,trust_remote_code=True,tokenizer=model_args.model_name_or_path,enable_lora=enable_lora,)outputs = llm.generate(prompts, sampling_params, lora_request=lora_requests)if not os.path.exists(training_args.output_dir):os.makedirs(training_args.output_dir, exist_ok=True)output_prediction_file = os.path.join(training_args.output_dir, "generated_predictions.jsonl")with open(output_prediction_file, "w", encoding="utf-8") as writer:res: List[str] = []for text, pred, label in zip(prompts, outputs, labels):res.append(json.dumps({"prompt": text, "predict": pred.outputs[0].text, "label": label},ensure_ascii=False,))writer.write("\n".join(res))
vllm.yaml 示例:
## model
model_name_or_path: qwen/Qwen2.5-7B-Instruct
# adapter_name_or_path: lora模型### method
stage: sft
do_predict: true
finetuning_type: lora### dataset
dataset_dir: 数据集路径
eval_dataset: 数据集
template: qwen
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16### output
output_dir: output/
overwrite_output_dir: true### eval
predict_with_generate: true
程序调用:
python vllm_infer.py vllm.yaml
程序运行速度:
Processed prompts: 100%|█| 1000/1000 [01:56<00:00, 8.60it/s, est. speed input: 5169.35 toks/s, output: 811.57
总结
本方案在原生 LlamaFactory 数据集的基础上,支持 LoRA 的 vllm 批量推理,能提升了推理效率。
进一步阅读
如果微调模型后,发现使用vllm模型批量效果不太好,可以参考下述文章:
- 基于 LLamafactory 的异步API高效调用实现与速度对比.https://blog.csdn.net/sjxgghg/article/details/144176645
亲测,LLamafactory 部署 模型,然后使用 Async API 调用后评估效果会好一些。
相关文章:

基于 LlamaFactory 的 LoRA 微调模型支持 vllm 批量推理的实现
背景 LlamaFactory 的 LoRA 微调功能非常便捷,微调后的模型,没有直接支持 vllm 推理,故导致推理速度不够快。 LlamaFactory 目前支持通过 VLLM API 进行部署,调用 API 时的响应速度,仍然没有vllm批量推理的速度快。 …...

【赵渝强老师】PostgreSQL的物理存储结构
PostgreSQL在执行initdb的数据库集群初始化时会指定一个目录。该目录通过环境变量$PGDATA来表示。当数据库集群初始化完成后,会在这个目录生成相关的子目录以及一些文件。这些生成的文件就是PostgreSQL的物理存储结构中的文件。如下图所示。 如上图所示,…...

智能探针技术:实现可视、可知、可诊的主动网络运维策略
网络维护的重要性 网络运维是确保网络系统稳定、高效、安全运行的关键活动。在当今这个高度依赖信息技术的时代,网络运维的重要性不仅体现在技术层面,更关乎到企业运营的方方面面。网络运维具有保障网络的稳定性、提升网络运维性能、降低企业运营成本等…...
)
CTF-PWN: 全保护下格式化字符串利用 [第一届“吾杯”网络安全技能大赛 如果能重来] 赛后学习(不会)
通过网盘分享的文件:如果能重来.zip 链接: https://pan.baidu.com/s/1XKIJx32nWVcSpKiWFQGpYA?pwd1111 提取码: 1111 --来自百度网盘超级会员v2的分享漏洞分析 格式化字符串漏洞,在printf(format); __int64 sub_13D7() {char format[56]; // [rsp10h] [rbp-40h]…...

debian 11 虚拟机环境搭建过坑记录
目录 安装过程系统配置修改 sudoers 文件网络配置换源安装桌面mount nfs 挂载安装复制功能tab 无法补全其他安装 软件配置eclipse 配置git 配置老虚拟机硬盘挂载 参考 原来去 debian 官网下载了一个最新的 debian 12,安装后出现包依赖问题,搞了半天&…...

MYSQL 什么是内连接 外连接 左连接 右连接?及适用场景
在 SQL 中,连接(JOIN)是用于组合来自两个或更多表的行的一种方法。根据连接的方式不同,可以分为几种类型的连接:内连接(INNER JOIN)、外连接(OUTER JOIN)、左连接&#x…...

利用Ubuntu批量下载modis图像(New)
由于最近modis原来批量下载的代码不再直接给出,因此,再次梳理如何利用Ubuntu下载modis数据。 之前的下载代码为十分长,现在只给出一部分,需要自己再补充另一部分。之前的为: 感谢郭师兄的指导(https://blo…...

【Springboot】@Autowired和@Resource的区别
【Springboot】Autowired和Resource的区别 【一】定义【1】Autowired【2】Resource 【二】区别【1】包含的属性不同【2】Autowired默认按byType自动装配,而Resource默认byName自动装配【3】注解应用的地方不同【4】出处不同【5】装配顺序不用(1ÿ…...

UIE与ERNIE-Layout:智能视频问答任务初探
内容来自百度飞桨ai社区UIE与ERNIE-Layout:智能视频问答任务初探: 如有侵权,请联系删除 1 环境准备 In [2] # 安装依赖库 !pip install paddlenlp --upgrade !pip install paddleocr --upgrade !pip install paddlespeech --upgrade In …...

数据结构:树
树的基本定义: 树是一种数据结构,它是由n(n>1)个有限节点组成一个具有层次关系的集合。把它叫做 “树” 是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点: …...

docker 怎么启动nginx
在Docker中启动Nginx容器是一个简单的过程。以下是启动Nginx容器的步骤: 拉取Nginx镜像: 首先,你需要从Docker Hub拉取Nginx的官方镜像。使用以下命令: docker pull nginx运行Nginx容器: 使用docker run命令来启动一个…...

【智商检测——DP】
题目 代码 #include <bits/stdc.h> using namespace std; const int N 1e510, M 110; int f[N][M]; int main() {int n, k;cin >> n >> k;for(int i 1; i < n; i){int x;cin >> x;f[i][0] __gcd(f[i-1][0], x);for(int j 1; j < min(i, k)…...

YOLOv11改进,YOLOv11添加SAConv可切换空洞卷积,二次创新C3k2结构
摘要 作者提出的技术结合了递归特征金字塔和可切换空洞卷积,通过强化多尺度特征学习和自适应的空洞卷积,显著提升了目标检测的效果。 理论介绍 空洞卷积(Atrous Convolution)是一种可以在卷积操作中插入“空洞”来扩大感受野的技术,更有效地捕捉到图像中的大范围上下文…...

使用R语言优雅的获取任意区域的POI,道路,河流等数据
POI是“Polnt of Information”的缩写,中文可以翻译为“信息点”。是地图上任何非地理意义的有意义的点,如商店,酒吧,加油站,医院,车站等。POI,道路网,河流等是我们日常研究中经常需…...

【设计模式】工厂方法模式 在java中的应用
文章目录 1. 引言工厂方法模式的定义 2. 工厂方法模式的核心概念工厂方法模式的目的和原理与其他创建型模式的比较(如简单工厂和抽象工厂) 3. Java中工厂方法模式的实现基本的工厂方法模式结构示例代码:创建不同类型的日志记录器 4. 工厂方法…...

Pytest框架学习20--conftest.py
conftest.py作用 正常情况下,如果多个py文件之间需要共享数据,如一个变量,或者调用一个方法 需要先在一个新文件中编写函数等,然后在使用的文件中导入,然后使用 pytest中定义个conftest.py来实现数据,参…...

【面试开放题】挫折、问题、擅长、应用技能
1. 项目中遇到的最大挫折是什么?你是如何应对的? 解答思路: 这个问题通常考察你的问题解决能力、抗压能力和团队协作精神。回答时,可以从以下几个角度展开: 问题背景: 描述项目中遇到的具体挑战。是技术难…...
)
CTF-PWN: 全保护下格式化字符串利用 [第一届“吾杯”网络安全技能大赛 如果能重来] 赛后学习(没思路了)
通过网盘分享的文件:如果能重来.zip 链接: https://pan.baidu.com/s/1XKIJx32nWVcSpKiWFQGpYA?pwd1111 提取码: 1111 --来自百度网盘超级会员v2的分享漏洞分析 格式化字符串漏洞,在printf(format); __int64 sub_13D7() {char format[56]; // [rsp10h] [rbp-40h]…...

C++学习日记---第16天
笔记复习 1.C对象模型 在C中,类内的成员变量和成员函数分开存储 我们知道,C中的成员变量和成员函数均可分为两种,一种是普通的,一种是静态的,对于静态成员变量和静态成员函数,我们知道他们不属于类的对象…...

SOA、分布式、微服务之间的关系和区别?
在当今的软件开发领域,SOA(面向服务架构)、分布式系统和微服务是三个重要的概念。它们各自有着独特的特性和应用场景,同时也存在着密切的关系。以下是关于这三者之间关系和区别的详细分析: 关系 分布式架构的范畴&…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...
ubuntu22.04有线网络无法连接,图标也没了
今天突然无法有线网络无法连接任何设备,并且图标都没了 错误案例 往上一顿搜索,试了很多博客都不行,比如 Ubuntu22.04右上角网络图标消失 最后解决的办法 下载网卡驱动,重新安装 操作步骤 查看自己网卡的型号 lspci | gre…...
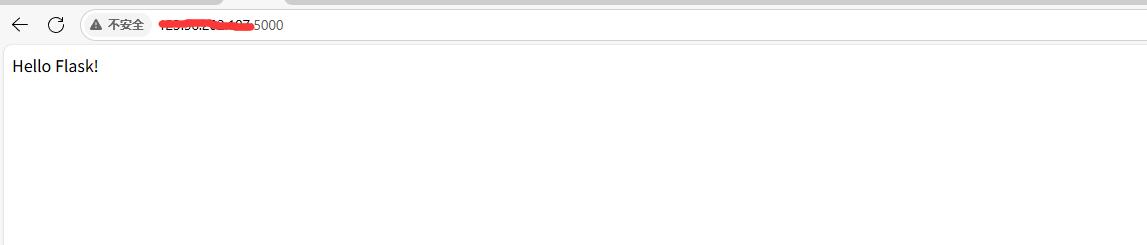
阿里云Ubuntu 22.04 64位搭建Flask流程(亲测)
cd /home 进入home盘 安装虚拟环境: 1、安装virtualenv pip install virtualenv 2.创建新的虚拟环境: virtualenv myenv 3、激活虚拟环境(激活环境可以在当前环境下安装包) source myenv/bin/activate 此时,终端…...