【机器学习】CatBoost 模型实践:回归与分类的全流程解析
一. 引言
本篇博客首发于掘金 https://juejin.cn/post/7441027173430018067。
PS:转载自己的文章也算原创吧。
在机器学习领域,CatBoost 是一款强大的梯度提升框架,特别适合处理带有类别特征的数据。本篇博客以脱敏后的保险数据集为例,展示如何利用 CatBoost 完成分类和回归任务,并以可视化的方式解析特征重要性与结果。
我们将完成以下任务:
- 回归任务:预测保险索赔金额。
- 分类任务:判断保险案件是否需要调查。
- 可视化分析:利用散点图与分割线展示结果。
二. CatBoost 模型简介
CatBoost 是由俄罗斯搜索巨头 Yandex 于 2017 年开源的机器学习库,其名称来源于 “Category” 和 “Boosting” 的组合,旨在高效处理类别特征的梯度提升算法。与其他模型(如 XGBoost 和 LightGBM)相比,CatBoost 具有以下优势:
- 支持类别特征:无需对类别特征进行独热编码,直接处理类别数据,避免数据膨胀。
- 对缺失值的鲁棒性:无需特殊预处理即可直接处理缺失值。
- 防止过拟合:内置多种正则化手段,减少梯度偏差和预测偏移,提高模型的准确性和泛化能力。
- 对称树结构:采用对称决策树(Oblivious Trees),在每个层级使用相同的特征和分割点,提升训练和预测效率。
三. 实战项目环境与数据准备
本项目使用了脱敏后的保险数据集,包含以下特征:
- 类别特征:险种代码、出险原因、医疗责任类别等。
- 数值特征:基本保额、索赔金额等。
- 标签:是否需要调查(分类任务)。
所有数据均已脱敏,支持迁移至其他表格数据集。
因为不好分享,所以后续第七节补充了一个基于sklearn "California Housing"数据集的流程代码与说明。
四. 回归任务:预测保险索赔金额
数据预处理
在回归任务中,我们根据特征预测索赔金额。以下是数据清洗与预处理的关键步骤:
- 过滤无效数据:移除缺失或非法值的记录。
- 特征转换:将类别特征转为字符串类型。
- 分割数据集:按 80% 和 20% 的比例划分训练集与测试集。
4.1 模型训练与评估
我们使用 CatBoost 进行回归建模,模型参数包括:
- 学习率:0.02
- 深度:8
- 迭代次数:10,000(支持提前停止)
以下是模型的关键代码:
from catboost import CatBoostRegressor# 初始化 CatBoost 回归模型
cat_regressor = CatBoostRegressor(iterations=10000,learning_rate=0.02,depth=8,eval_metric='RMSE',early_stopping_rounds=1500,random_seed=42
)# 训练模型
cat_regressor.fit(X_train, y_train,cat_features=categorical_features_indices,eval_set=(X_test, y_test),verbose=100
)
4.2 特征重要性分析
特征重要性是衡量特征对模型预测贡献程度的指标,可以帮助我们更好地理解模型。
# 获取特征重要性
feature_importances = cat_regressor.get_feature_importance()
feature_names = X_train.columns# 可视化特征重要性
import matplotlib.pyplot as plt
importance_df = pd.DataFrame({'Feature': feature_names,'Importance': feature_importances
}).sort_values(by='Importance', ascending=True)plt.figure(figsize=(10, 6))
plt.barh(importance_df['Feature'], importance_df['Importance'], color='salmon')
plt.xlabel('特征重要性')
plt.ylabel('特征名称')
plt.title('CatBoost 特征重要性分析')
plt.show()
结果展示:

4.3 模型评估
我们可以均方误差 (MSE) 以及 平均绝对误差 (MAE) 来评估模型在测试集上的回归性能,同时展示模型的学习曲线:
# 获取训练和测试集的 RMSE
evals_result = cat_regressor.get_evals_result()
train_rmse = evals_result['learn']['RMSE']
test_rmse = evals_result['validation']['RMSE']# 绘制 RMSE 曲线
plt.figure(figsize=(10, 6))
plt.plot(train_rmse, label='训练集 RMSE')
plt.plot(test_rmse, label='测试集 RMSE')
plt.title('训练与测试集的 RMSE 学习曲线')
plt.xlabel('迭代次数')
plt.ylabel('RMSE')
plt.legend()
plt.show()
五. 分类任务:判别是否调查
5.1 数据标注与模型选择
分类任务以 是否调查 作为标签(1 表示需要调查,0 表示无需调查),特征包括所有数值和类别字段。
为了完成分类任务,我们选用 CatBoostClassifier。模型参数类似于回归模型,分类评估指标包括准确率、混淆矩阵和分类报告。
5.2 训练结果与模型评估
训练结果显示,分类准确率达 94.0%。以下是模型的分类报告:
分类报告 (训练集):precision recall f1-score support0 0.96 0.98 0.97 130871 0.74 0.57 0.64 1354accuracy 0.94 14441macro avg 0.85 0.77 0.80 14441
weighted avg 0.94 0.94 0.94 14441
5.3 代码示例
from catboost import CatBoostClassifier# 初始化分类器
cat_classifier = CatBoostClassifier(iterations=1000,learning_rate=0.02,depth=8,eval_metric='Accuracy',early_stopping_rounds=150,random_seed=42
)# 模型训练
cat_classifier.fit(X_train, y_train,cat_features=categorical_features_indices,eval_set=(X_test, y_test),verbose=100
)
六. 可视化分析
为更直观地理解模型,我们利用散点图和分割线对预测结果进行展示:
- 散点图:展示实际金额与预测金额的分布。
- 分割线:通过 KMeans 聚类划分四个金额档次。
以下代码生成散点图与分割线:
# 使用 KMeans 聚类生成分割线
from sklearn.cluster import KMeanskmeans = KMeans(n_clusters=4, random_state=42)
df['cluster'] = kmeans.fit_predict(df[['预测金额']])# 绘制散点图
plt.figure(figsize=(12, 8))
plt.scatter(df['预测金额'], df['是否调查'], c=df['cluster'], cmap='tab10')
plt.title("预测金额与是否调查的散点图")
plt.xlabel("预测金额")
plt.ylabel("是否调查")
plt.colorbar(label='Cluster')
plt.show()
散点图展示:

七. 补充学习
7.1 基础数据集
California Housing 数据集包含加利福尼亚州 20,640 个街区的人口、住房和收入信息。目标是预测每个街区的房价中位数 MedHouseVal。
数据特征
MedInc:街区的收入中位数。HouseAge:街区住房的平均年龄。AveRooms:每个街区的平均房间数。AveBedrms:每个街区的平均卧室数。Population:街区的总人口。AveOccup:每户的平均人数。Latitude:街区的纬度。Longitude:街区的经度。
7.2 实践步骤
7.2.1 导入数据与预处理
我们使用 Scikit-learn 加载数据并进行预处理。
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd# 加载 California Housing 数据集
data = fetch_california_housing(as_frame=True)
df = data.frame# 特征和目标变量
X = df.drop(columns="MedHouseVal")
y = df["MedHouseVal"]# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)print(f"训练集大小: {X_train.shape}, 测试集大小: {X_test.shape}")
训练集大小: (16512, 8), 测试集大小: (4128, 8)
7.2.2 训练 CatBoost 回归模型
使用 CatBoost 对房价进行预测。
from catboost import CatBoostRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error# 初始化 CatBoost 回归模型
cat_regressor = CatBoostRegressor(iterations=1000,learning_rate=0.1,depth=6,eval_metric="RMSE",random_seed=42,verbose=100
)# 模型训练
cat_regressor.fit(X_train, y_train, eval_set=(X_test, y_test), verbose=100, early_stopping_rounds=50)# 模型预测
y_pred_train = cat_regressor.predict(X_train)
y_pred_test = cat_regressor.predict(X_test)# 模型评估
mse_train = mean_squared_error(y_train, y_pred_train)
mse_test = mean_squared_error(y_test, y_pred_test)
mae_test = mean_absolute_error(y_test, y_pred_test)print(f"训练集均方误差 (MSE): {mse_train}")
print(f"测试集均方误差 (MSE): {mse_test}")
print(f"测试集平均绝对误差 (MAE): {mae_test}")
输出如下:
0: learn: 1.0934740 test: 1.0841841 best: 1.0841841 (0) total: 1.24s remaining: 20m 38s
100: learn: 0.4867395 test: 0.5154868 best: 0.5154868 (100) total: 1.54s remaining: 13.7s
200: learn: 0.4320149 test: 0.4798269 best: 0.4798269 (200) total: 1.8s remaining: 7.18s
300: learn: 0.4020581 test: 0.4657293 best: 0.4657293 (300) total: 2.07s remaining: 4.8s
400: learn: 0.3803801 test: 0.4582868 best: 0.4582868 (400) total: 2.35s remaining: 3.5s
500: learn: 0.3633580 test: 0.4534430 best: 0.4534430 (500) total: 2.61s remaining: 2.6s
600: learn: 0.3488402 test: 0.4491723 best: 0.4491723 (600) total: 2.89s remaining: 1.92s
700: learn: 0.3358611 test: 0.4461323 best: 0.4461323 (700) total: 3.17s remaining: 1.35s
800: learn: 0.3234759 test: 0.4431320 best: 0.4431320 (800) total: 3.44s remaining: 854ms
900: learn: 0.3126821 test: 0.4403978 best: 0.4403978 (900) total: 3.71s remaining: 407ms
999: learn: 0.3025414 test: 0.4386906 best: 0.4386902 (998) total: 3.97s remaining: 0usbestTest = 0.438690174
bestIteration = 998Shrink model to first 999 iterations.
训练集均方误差 (MSE): 0.09158491090576551
测试集均方误差 (MSE): 0.19244906768098075
测试集平均绝对误差 (MAE): 0.28701415230111493
7.2.3 可视化预测结果
展示预测值与实际值的对比,以及模型的特征重要性。
实际值与预测值对比
import matplotlib.pyplot as plt# 对比测试集的预测值和实际值
plt.figure(figsize=(10, 6))
plt.scatter(range(len(y_test)), y_test, color="blue", label="真实值", alpha=0.6)
plt.scatter(range(len(y_pred_test)), y_pred_test, color="red", label="预测值", alpha=0.6)
plt.title("真实房价与预测房价对比")
plt.xlabel("样本索引")
plt.ylabel("房价中位数")
plt.legend()
plt.show()
特征重要性分析
# 特征重要性可视化
feature_importances = cat_regressor.get_feature_importance()
feature_names = data.feature_namesplt.figure(figsize=(10, 6))
plt.barh(feature_names, feature_importances, color="skyblue")
plt.title("CatBoost 特征重要性")
plt.xlabel("重要性得分")
plt.ylabel("特征名称")
plt.show()

7.3 数据结果
- 模型评估结果:
- 训练集均方误差 (MSE): 0.09158491090576551
- 测试集均方误差 (MSE): 0.19244906768098075
- 测试集平均绝对误差 (MAE): 0.28701415230111493
- 特征重要性解读:
根据特征重要性分析,MedInc(收入中位数)对预测房价的影响最大,而经纬度特征(Latitude 和 Longitude)也提供了显著的信息。
八. 总结
通过本项目,我们完成了基于 CatBoost 的回归与分类建模,并展示了预测结果的可视化。CatBoost 的强大功能和易用性使其在处理类别特征和缺失值的数据中表现优异。
希望本篇博客能为大家带来启发,助力实际项目的落地实现。如果对您有所帮助,也欢迎点赞与分享😊。
源码已上传到:https://github.com/YYForReal/ML-DL-RL-Learning/blob/main/ML-Learning/Catboost/
相关文章:
【机器学习】CatBoost 模型实践:回归与分类的全流程解析
一. 引言 本篇博客首发于掘金 https://juejin.cn/post/7441027173430018067。 PS:转载自己的文章也算原创吧。 在机器学习领域,CatBoost 是一款强大的梯度提升框架,特别适合处理带有类别特征的数据。本篇博客以脱敏后的保险数据集为例&#x…...

PyTorch 实现动态输入
使用 PyTorch 实现动态输入:支持训练和推理输入维度不一致的 CNN 和 LSTM/GRU 模型 在深度学习中,处理不同大小的输入数据是一个常见的挑战。许多实际应用需要模型能够灵活地处理可变长度的输入。本文将介绍如何使用 PyTorch 实现支持动态输入的 CNN 和…...

【Linux相关】查看conda路径和conda和cudnn版本、安装cudnn、cuDNN无需登录官方下载链接
【Linux相关】 查看conda路径和conda和cudnn版本 安装cudnn cuDNN无需登录官方下载链接 文章目录 1. 查看信息1.1 查看 Conda 路径1.2 查看 Conda 版本1.3 查看 cuDNN 版本1.4 总结 2. 安装cudnn2.1 安装cudnn步骤2.2 cuDNN无需登录官方下载链接 1. 查看信息 查看Conda 路径、C…...
基于Java Springboot环境保护生活App且微信小程序
一、作品包含 源码数据库设计文档万字PPT全套环境和工具资源部署教程 二、项目技术 前端技术:Html、Css、Js、Vue、Element-ui 数据库:MySQL 后端技术:Java、Spring Boot、MyBatis 三、运行环境 开发工具:IDEA/eclipse 微信…...

简单的springboot使用sse功能
什么是sse? 1、SSE 是Server-Sent Events(服务器发送事件) 2、SSE是一种允许服务器主动向客户端推送实时更新的技术。 3、它基于HTTP协议,并使用了其长连接特性,在客户端与服务器之间建立一条持久化的连接。 通过这条连接&am…...

【服务器问题】xshell 登录远程服务器卡住( 而 vscode 直接登录不上)
打开 xshell ssh 登录远程服务器:卡在下面这里,迟迟不继续 当 SSH 连接卡在 Connection established. 之后,但没有显示远程终端提示符时,这通常意味着连接已经成功建立,说明不是网络连接和服务器连接问题,…...

AI×5G 市场前瞻及应用现状
本文为《5GAI时代:生活方式和市场的裂变》一书读后总结及研究。 本书的上架建议是“经营”,内容也更偏向于市场分析。书出版于2021年,现在是2024年,可以收集整理一些例子,看看书里的前瞻性5GAI应用预测,到…...

利用 Redis 与 Lua 脚本解决秒杀系统中的高并发与库存超卖问题
1. 前言 1.1 秒杀系统中的库存超卖问题 在电商平台上,秒杀活动是吸引用户参与并提升销量的一种常见方式。秒杀通常会以极低的价格限量出售某些商品,目的是制造紧迫感,吸引大量用户参与。然而,这种活动的特殊性也带来了许多技术挑…...

【MySQL】创建数据库、用户和密码
创建数据库、用户和密码参考sql语句 drop database if exists demoshop; drop user if exists demoshop%; -- 支持emoji:需要mysql数据库参数: character_set_serverutf8mb4 create database demoshop default character set utf8mb4 collate utf8mb4_un…...

leetcode hot100【Leetcode 72.编辑距离】java实现
Leetcode 72.编辑距离 题目描述 给定两个单词 word1 和 word2,返回将 word1 转换为 word2 所使用的最少操作数。 你可以对一个单词执行以下三种操作之一: 插入一个字符删除一个字符替换一个字符 示例 1: 输入: word1 "horse", word2 &…...

腾讯阅文集团Java后端开发面试题及参考答案
Java 的基本数据类型有哪些?Byte 的数值范围是多少? Java 的基本数据类型共有 8 种,可分为 4 类: 整数类型:包括 byte、short、int 和 long。byte 占 1 个字节,其数值范围是 - 128 到 127,用于表示较小范围的整数,节省内存空间,在处理一些底层的字节流数据或对内存要求…...

protobuf实现Hbase数据压缩
目录 前置HBase数据压缩效果获取数据(反序列化) 前置 安装说明 使用说明 HBaseDDL和DML操作 HBase数据压缩 问题 在上文的datain中原文 每次写入数据会写入4个单元格的内容,现在希望能对其进行筛减,合并成1格,减少存储空间(序列…...

论文阅读之方法: Single-cell transcriptomics of 20 mouse organs creates a Tabula Muris
The Tabula Muris Consortium., Overall coordination., Logistical coordination. et al. Single-cell transcriptomics of 20 mouse organs creates a Tabula Muris. Nature 562, 367–372 (2018). 论文地址:https://doi.org/10.1038/s41586-018-0590-4 代码地址…...

PHP语法学习(第三天)
老规矩,先回顾一下昨天学习的内容 PHP语法学习(第二天) 主要学习了PHP变量、变量的作用域、以及参数作用域。 今天由Tom来打开新的篇章 文章目录 echo 和 print 区别PHP echo 语句实例 PHP print 语句实例 PHP 数组创建数组利用array() 函数 数组的类型索引数组关联…...

PostgreSQL添加PostGIS扩展和存储坐标
一、安装 1、PostGIS安装:Getting Started | PostGIS 2、安装好后,执行下面sql CREATE EXTENSION postgis;SELECT PostGIS_Full_Version(); 二、使用 PostGIS文档:PostGIS 简介 — Introduction to PostGIS 建表: CREATE TAB…...

Flink四大基石之State(状态) 的使用详解
目录 一、有状态计算与无状态计算 (一)概念差异 (二)应用场景 二、有状态计算中的状态分类 (一)托管状态(Managed State)与原生状态(Raw State) 两者的…...

Linux中dos2unix详解
dos2unix 是一个用于将文本文件从DOS/Windows格式转换为Unix/Linux格式的工具。在不同的操作系统中,文本文件中的换行符表示方式是不一样的。具体来说: 在DOS和Windows系统中,换行由两个字符组成:回车(Carriage Retur…...

MySQL MVCC 介绍
MVCC(Multi-Version Concurrency Control)是一种并发控制机制,用于在多个并发事务同时读写数据库时保持数据的一致性和隔离性。MVCC通过在每个数据行上维护多个版本的数据来实现。当一个事务要对数据库中的数据进行修改时,MVCC不会…...

Linux篇之日志管理工具Logrotate介绍并结合crontab使用
1. Logrotate介绍 logrotate 是一个用于管理和轮换日志文件的工具,通常用于 Unix 和 Linux 系统。它可以自动化日志文件的轮换、压缩、删除和邮寄等操作,确保日志文件不会无限制地增长,占用过多的磁盘空间。 2. 主要功能 轮换:定期将日志文件移动到备份目录,并生成新的…...

Vulnhub靶场 Matrix-Breakout: 2 Morpheus 练习
目录 0x00 准备0x01 主机信息收集0x02 站点信息收集0x03 漏洞查找与利用1. 文件上传2. 提权 0x04 总结 0x00 准备 下载连接:https://download.vulnhub.com/matrix-breakout/matrix-breakout-2-morpheus.ova 介绍: This is the second in the Matrix-Br…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

怎么让Comfyui导出的图像不包含工作流信息,
为了数据安全,让Comfyui导出的图像不包含工作流信息,导出的图像就不会拖到comfyui中加载出来工作流。 ComfyUI的目录下node.py 直接移除 pnginfo(推荐) 在 save_images 方法中,删除或注释掉所有与 metadata …...

【Elasticsearch】Elasticsearch 在大数据生态圈的地位 实践经验
Elasticsearch 在大数据生态圈的地位 & 实践经验 1.Elasticsearch 的优势1.1 Elasticsearch 解决的核心问题1.1.1 传统方案的短板1.1.2 Elasticsearch 的解决方案 1.2 与大数据组件的对比优势1.3 关键优势技术支撑1.4 Elasticsearch 的竞品1.4.1 全文搜索领域1.4.2 日志分析…...

云原生周刊:k0s 成为 CNCF 沙箱项目
开源项目推荐 HAMi HAMi(原名 k8s‑vGPU‑scheduler)是一款 CNCF Sandbox 级别的开源 K8s 中间件,通过虚拟化 GPU/NPU 等异构设备并支持内存、计算核心时间片隔离及共享调度,为容器提供统一接口,实现细粒度资源配额…...

comfyui 工作流中 图生视频 如何增加视频的长度到5秒
comfyUI 工作流怎么可以生成更长的视频。除了硬件显存要求之外还有别的方法吗? 在ComfyUI中实现图生视频并延长到5秒,需要结合多个扩展和技巧。以下是完整解决方案: 核心工作流配置(24fps下5秒120帧) #mermaid-svg-yP…...
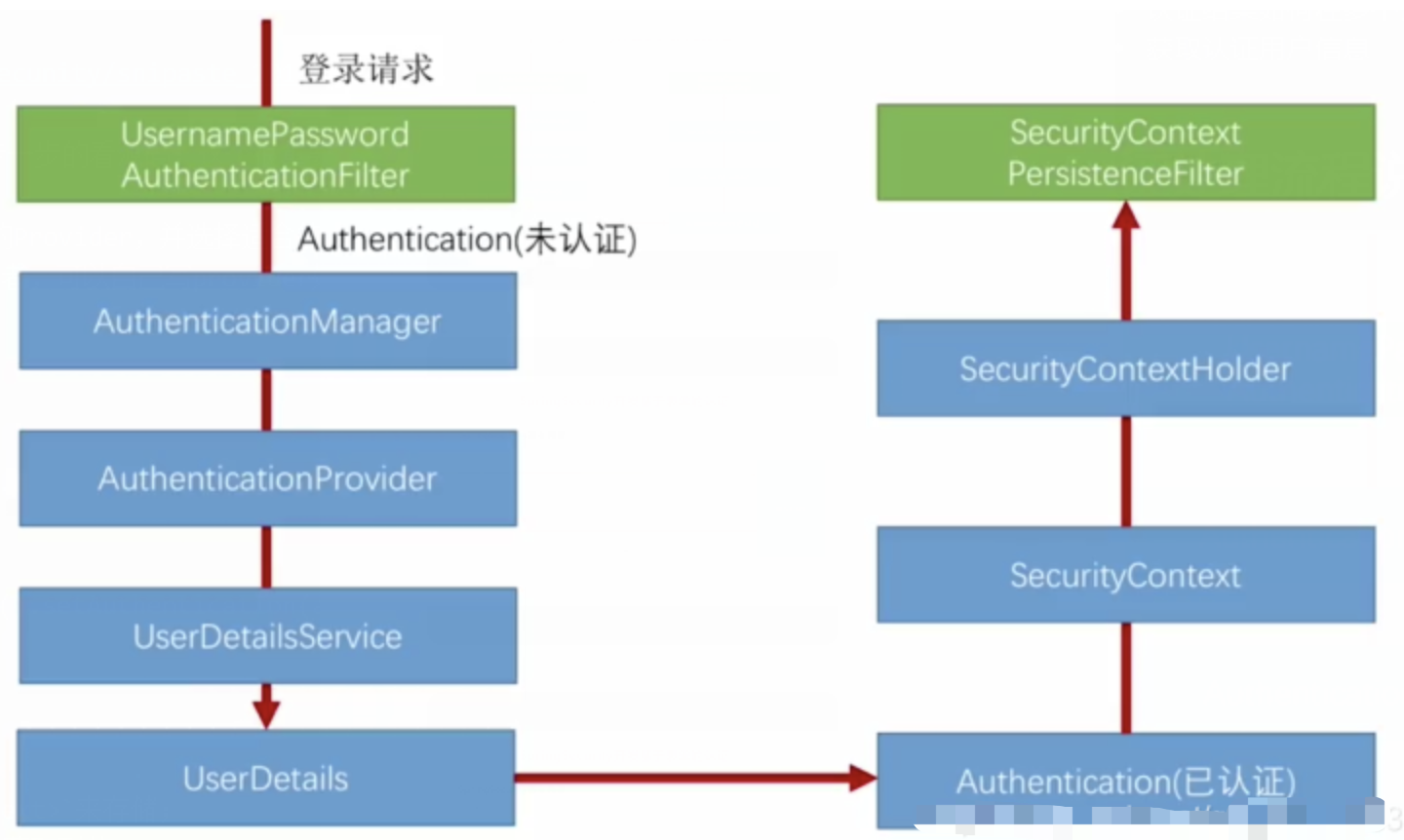
spring Security对RBAC及其ABAC的支持使用
RBAC (基于角色的访问控制) RBAC (Role-Based Access Control) 是 Spring Security 中最常用的权限模型,它将权限分配给角色,再将角色分配给用户。 RBAC 核心实现 1. 数据库设计 users roles permissions ------- ------…...