基于 AutoFlow 快速搭建基于 TiDB 向量搜索的本地知识库问答机器人
导读
本文将详细介绍如何通过 PingCAP 开源项目 AutoFlow 实现快速搭建基于 TiDB 的本地知识库问答机器人。如果提前准备好 Docker、TiDB 环境,整个搭建过程估计在 10 分钟左右即可完成,无须开发任何代码。
文中使用一篇 TiDB 文档作为本地数据源作为示例,在实际情况中,您可以基于自己的企业环境用同样的方法快速构造企业内部知识库问答机器人。
背景知识
AutoFlow 是 PingCAP 开源的一个基于 Graph RAG、使用 TiDB 向量存储和 LlamaIndex 构建的对话式知识库聊天助手。https://tidb.ai 也是 PingCAP 基于 AutoFlow 实现的一个 TiDB AI 智能问答系统,我们可以向 tidb.ai 咨询任何有关 TiDB 的问题,比如 “TiDB 对比 MySQL 有什么优势?”

以下是 tidb.ai 的回答,从结果来说,tidb.ai 非常准确的理解了用户的问题并给出了相应的回答。它首先给出 TiDB 优势及 MySQL 限制的详细说明,然后给出一个结论性的总结,最后给出更多的参考链接。

基于 TiDB 实现问答系统的基本流程
相信通过前面的一些介绍,大家对 tidb.ai 的能力已经有了一个清楚的认识。TiDB 的使用人员很幸运,因为有了 tidb.ai,几乎任何有关 TiDB 的问题都可以在这个统一的平台得到相应的解答,一方面节省了自己人工去查找 TiDB 官方文档或 AskTUG 论坛的时间,另一方面 tidb.ai 拥有比普通大模型更专业的 TiDB 知识问答。
在技术实现上,tidb.ai 背后主要使用到 TiDB 的 Graph RAG 技术、TiDB 向量检索功能以及 LLM 大模型的使用。实际上,在 AutoFlow 出来之前,我们也可以通过 python 编程开发的方式基于 LLM+RAG+TiDB 实现一套问答系统。主要的开发流程如下:
- 准备私域文本数据
- 对文本进行切分
- 通过 Embedding 将文本转为向量数据
- 把向量数据保存到 TiDB
- 获得用户输入问题并进行向量化,然后从 TiDB 中进行相似度搜索
- 将上述片段和历史问答作为上下文,与用户问题一起传入大模型,最后输出结果

基于 AutoFlow 搭建本地知识库问答系统
基于 python 开发这样一套问答系统,一般要结合大模型常用开发框架如 Langchain,Langchain 集成了多种文件格式或 URL 网址的导入功能。如果希望给这个系统增加 Web 界面的能力,还需要引入前端可视化工具,如 Gradio 或 Steamlit。但是如果使用开源的 AutoFlow,即使对于没有任何开发背景的同学来说,搭建一套这样的问答系统也是一件轻而易举的事情,以下我们具体演示整个搭建的过程。
环境准备
在环境准备阶段,我们主要需要准备以下几项内容:
- Docker 环境
需要确保 AutoFlow 运行的机器上具备 Docker 运行环境,因为 AutoFlow 项目中的应用是基于 docker 容器环境运行的。有关 Docker 运行环境的准备工作本文不作说明,安装完成后可使用 docker run hello-world 命令验证安装成功。
- AutoFlow 项目
AutoFlow 是一个开源的 github 项目,地址为 https://github.com/pingcap/autoflow。下载之后需要在 AutoFlow 根目录下配置相关信息,包括 TiDB 数据库连接信息、EMBEDDING 维度等。
cat > .env <<'EOF'
ENVIRONMENT=production# 可使用 python3 -c "import secrets; print(secrets.token_urlsafe(32))" 生成密钥
SECRET_KEY="some_secret_key_that_is_at_least_32_characters_long"TIDB_HOST=<ip>
TIDB_PORT=<port>
TIDB_USER=<username>
TIDB_PASSWORD=<password>
TIDB_DATABASE=tidbai_test
# 非 TiDB serverless 环境需要将 TIDB_SSL 设置为 false
TIDB_SSL=falseEMBEDDING_DIMS=1024
EMBEDDING_MAX_TOKENS=4096
EOF
- 带向量功能的 TiDB 环境
TiDB 最新发布的 v8.4 版本,支持向量搜索功能(实验特性)。向量搜索是一种基于数据语义的搜索方法,可以提供更相关的搜索结果。有关 TiDB 向量搜索功能,参考 https://docs.pingcap.com/zh/tidb/v8.4/vector-search-overview
需要确保 TiDB 8.4 集群正常运行,且已经创建有 AutoFlow 配置中指定的 TIDB_DATABASE 数据库(必须为空库)。
mysql> select version();
+--------------------+
| version() |
+--------------------+
| 8.0.11-TiDB-v8.4.0 |
+--------------------+
1 row in set (0.00 sec)mysql> create database tidbai_test;
Query OK, 0 rows affected (0.52 sec)
- 智谱 AI API Key
注册并登录智谱 AI 平台 https://bigmodel.cn/, 在个人中心->API kys 添加新的 API Key 并复制保存。注意,如果免费创建的用户已经超过一定的时效期限,API Key 将是无效的。

数据初始化
运行数据迁移以创建所需的表并创建初始管理员用户
cd autoflow
docker compose -f docker-compose-cn.yml run backend /bin/sh -c "alembic upgrade head"
docker compose -f docker-compose-cn.yml run backend /bin/sh -c "python bootstrap.py"

当看到如上输出结果时,说明初始化这一步已经成功(注意保存好红色字体中的密码以备后面使用)。这时我们去 TiDB 数据库中查看,发现 tidbai_test 这个库中已经自动创建出了相应的表并有一些初始化数据,符合预期。

启动知识库应用
运行以下 docker compose 命令启动知识库应用程序
cd autoflow
docker compose -f docker-compose-cn.yml up -d --force-recreate

网页访问和配置知识库应用
应用启动成功后,我们可以直接通过默认的 3000 端口访问相应的界面进行下一步操作了。使用默认管理员用户 admin@example.com 以及上述应用启动打印的密码进行登录。

登录成功后,会弹出如下图所示的提示框,后面我们只要按照提示框一步步进行相应配置即可。
注意:3000 这个端口是 TiDB 数据库默认的 Grafana 端口号,如果把 AutoFlow 部署在和 Grafana 相同的节点,需要考虑端口冲突问题。

此步骤需要配置的内容包括:
- 模型名称
- 模型提供商(选择 OpenAI Like)
- 模型型号(如 glm-4-0520)
- 智谱AI API KEY(见环境准备阶段)
- 高级选项-> api_base 路径(需与 LLM 对应)
- 是否默认 LLM(是或否)

配置完成后,点击 Create LLM 创建 LLM 关联。需要注意的是,这里提供的 API Key 必须是一个有效的 Key,如果创建 API Key 的账户本身就过时,创建 LLM 时可能就会遇到以下报错。如果只是为了测试用途,可以重新注册一个账号并取得一个新的 API Key 试用。
Failed to create LLM
Error code: 429 - {'error': {'code': '1113', 'message': '您的账户已欠费,请充值后重试。'}}
此步骤需要配置的内容包括:
- embedding名称
- 模型提供商(选择 OpenAI Like)
- 模型型号(如 embedding-2)
- 智谱AI API KEY(与上述相同)

配置完成后,点击 Create Embedding Model 创建 Embedding 模型。需要注意的是,这里的 Model 必须要与环境变量中的 EMBEDDING_DIMS 对应,否则可能会出现以下类似报错。
Failed to create Embedding Model
Currently we only support 1536 dims embedding, got 1024 dims.
这里的数据来源可以是本地文件,也可以是具体的网址。这里我们配置具体有关 TiDB 和 MySQL 兼容性的网页 https://docs.pingcap.com/zh/tidb/stable/mysql-compatibility 为数据来源。具体配置内容包括:
- 数据源名称
- 数据源描述
- 网页 URL(可以配置一个或多个)
- 是否 build 知识图谱 Index(是或否)

配置完成后,点击 Create Datasource 创建数据来源。当然,如果有本地文件,也可以直接导入本地文件并创建数据源。另外如果不是在初始化时配置数据源,我们也可以在后续的过程中手动添加更多的数据源,下图显示将一个本地的文档导入为数据源。

上述步骤配置完成后,应用将基于配置的数据源进行向量化并创建索引,这需要一定的时间,具体耗时跟数据源的多少以及机器的配置都有关。通过页面左侧菜单栏-> Index Progress 查看索引创建进度,绿色代表索引创建成功,蓝色代表正在创建,红色代表创建失败。下图表示 Vector Index 已经创建成功,Knowlege Graph Index 正在创建中。当两个图表都变成绿色时,代表全部创建成功。

体验智能问答
至此,我们已经完成了配置数据源并完成了向量化存储及向量索引的创建。在网页的左侧菜单栏中,我们可以点击 Datasources 查看当前数据源, LLMs 查看当前 LLM,Embedding Model 查看 Embedding 模型。

我们现在也可以开始向自己搭建的 tidb.ai 咨询有关 TiDB 的问题了,比如提问 “TiFlash 高性能列式分析引擎”。从结果可以看出,本地知识库问答机器人引用导入的文档并作出了相似回答,而假如我们删除数据源之后再提出相同的问题,它的回答是 Empty Response。下图对比充分说明了 TiDB 向量搜索在基础 LLM 大模型的增强能力。

相关文章:
基于 AutoFlow 快速搭建基于 TiDB 向量搜索的本地知识库问答机器人
导读 本文将详细介绍如何通过 PingCAP 开源项目 AutoFlow 实现快速搭建基于 TiDB 的本地知识库问答机器人。如果提前准备好 Docker、TiDB 环境,整个搭建过程估计在 10 分钟左右即可完成,无须开发任何代码。 文中使用一篇 TiDB 文档作为本地数据源作为示…...
C语言学习:速通指针(2)
这里要学习的有以下内容 1. const修饰指针 2. 野指针 3. assert断⾔ 4. 指针的使⽤和传址调⽤ 那么从这里开始 1. const 修饰指针 const修饰变量 首先我们知道变量是可以修改的,如果把变量的地址交给⼀个指针变量,通过指针变量的也可以修改这个变…...

windows 上ffmpeg编译好的版本选择
1. Gyan.dev Gyan.dev 是一个广受信赖的 FFmpeg 预编译库提供者,提供多种版本的 FFmpeg,包括静态和动态链接版本。 下载链接: https://www.gyan.dev/ffmpeg/builds/ 特点: 提供最新稳定版和开发版。 支持静态和共享(动态&…...

Java设计模式笔记(二)
十四、模版方法模式 1、介绍 1)模板方法模式(Template Method Pattern),又叫模板模式(Template Patern),在一个抽象类公开定义了执行它的方法的模板。它的子类可以按需重写方法实现,但调用将以抽象类中定义的方式进行。 2&…...

Vue CLI的作用
Vue CLI(Command Line Interface)是一个基于Vue.js的官方脚手架工具,其主要作用是帮助开发者快速搭建Vue项目的基础结构和开发环境。以下是Vue CLI的具体作用: 1、项目模板与快速生成 Vue CLI提供了一系列预设的项目模板&#x…...

短视频矩阵系统开发|技术源代码部署
短视频矩阵系统通过多账号运营管理、多平台视频智能分发等功能,助力企业实现视频引流、粉丝沉淀和转化。 短视频矩阵系统是一种创新的营销工具,它整合了多账号管理、视频智能分发、数据可视化等多种功能,为企业在短视频领域的发展提供了强大…...
)
Erlang socket编程(二)
模拟服务器和客户端通信 %%%------------------------------------------------------------------- %%% author Administrator %%% copyright (C) 2024, <COMPANY> %%% doc %%% %%% end %%% Created : 03. 12月 2024 22:28 %%%---------------------------------------…...

工业检测基础-线扫相机和面阵相机参数及应用
以下是工业面阵相机和线扫相机的重要参数、应用场景以及调节方法的科普: 重要参数 分辨率: 面阵相机:由相机所采用的芯片分辨率决定,常用的有500万、1200万、6500万等像素,一般用长宽表示。如19201080等,…...

【无标题】建议用坚果云直接同步zotero,其他方法已经过时,容易出现bug
created: 2024-12-06T16:07:45 (UTC 08:00) tags: [] source: https://zotero-chinese.com/user-guide/sync author: 数据与文件的同步 | Zotero 中文社区 Excerpt Zotero 中文社区,Zotero 中文维护小组,Zotero 插件,Zotero 中文 CSL 样式 数…...
_273)
基于STM32设计的智能宠物喂养系统(华为云IOT)_273
文章目录 一、前言1.1 项目介绍【1】项目开发背景【2】设计实现的功能【3】项目硬件模块组成【4】设计意义【5】国内外研究现状【6】摘要1.2 设计思路1.3 系统功能总结1.4 开发工具的选择【1】设备端开发【2】上位机开发1.5 参考文献1.6 系统框架图1.7 系统原理图1.8 实物图1.9…...

cesium truf 利用缓冲如何将一个点缓冲成一个方形
: 在Cesium中如果你想要一个更简单的方法将一个点缓冲成一个方形区域,你可以考虑以下步骤: 确定中心点:首先,你需要有一个中心点的经纬度坐标。计算边长:确定你想要缓冲的方形的边长,这里以10…...

HarmonyOS 5.0应用开发——Ability与Page数据传递
【高心星出品】 文章目录 Ability与Page数据传递Page向Ability传递数据Ability向Page传递数据 Ability与Page数据传递 基于当前的应用模型,可以通过以下几种方式来实现UIAbility组件与UI之间的数据同步。 使用EventHub进行数据通信:在基类Context中提供…...

【推荐算法】推荐系统的评估
这篇文章是笔者阅读《深度学习推荐系统》第五章推荐系统的评估的学习笔记,在原文的基础上增加了自己的理解以及内容的补充,在未来的日子里会不断完善这篇文章的相关工作。 文章目录 离线评估划分数据集方法客观评价指标P-R曲线ROC/AUCmAPNDCG A/B 测试分…...
鸿蒙:实现类似Android.9图的图片资源呈现
问题: 在鸿蒙中,是识别不了.9格式的图片资源的,那么如何实现.9图效果呢。? 解决方案: 首先需要将图片资源转为普通的png格式。如果是背景图的,需要换一种方式来处理,目前我所实现的方案是通过St…...

ros2人脸检测
第一步: 首先在工作空间/src下创建数据结构目录service_interfaces ros2 pkg create service_interfaces --build-type ament_cmake 然后再创建一个srv目录 在里面创建FaceDetect.srv(注意,首字母要大写) sensor_msgs/Image …...

Pillow:强大的Python图像处理库
目录 一、引言 二、Pillow 库的安装 三、Pillow 库的基本概念 四、图像的读取和保存 五、图像的基本属性 六、图像的裁剪、缩放和旋转 七、图像的颜色调整 八、图像的滤镜效果 九、图像的合成和叠加 十、图像的绘制 十一、示例程序:制作图片水印 十二、…...

微信小程序uni-app+vue3实现局部上下拉刷新和scroll-view动态高度计算
微信小程序uni-appvue3实现局部上下拉刷新和scroll-view动态高度计算 前言 在uni-appvue3项目开发中,经常需要实现列表的局部上下拉刷新功能。由于网上相关教程较少且比较零散,本文将详细介绍如何使用scroll-view组件实现这一功能,包括动态高度计算、下拉刷新、上拉加载等完整…...

为什么类 UNIX 操作系统通常内置编译器?为什么 Windows 更倾向于直接使用二进制文件?
操作系统是否内置编译器,取决于该系统的设计目标、用户群体以及常见的使用场景。以下是内置编译器和直接使用二进制的设计理念和原因的分析: 为什么类 UNIX 操作系统通常内置编译器? 面向开发者的需求: 类 UNIX 系统(如…...

吉林大学23级数据结构上机实验(第7周)
A 去火车站 寒假到了,小明准备坐火车回老家,现在他从学校出发去火车站,CC市去火车站有两种方式:轻轨和公交车。小明为了省钱,准备主要以乘坐公交为主。CC市还有一项优惠政策,持学生证可以免费乘坐一站轻轨&…...

实验13 使用预训练resnet18实现CIFAR-10分类
1.数据预处理 首先利用函数transforms.Compose定义了一个预处理函数transform,里面定义了两种操作,一个是将图像转换为Tensor,一个是对图像进行标准化。然后利用函数torchvision.datasets.CIFAR10下载数据集,这个函数有四个常见的…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的----NTFS源代码分析--重要
根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的 第一部分: 0: kd> g Breakpoint 9 hit Ntfs!ReadIndexBuffer: f7173886 55 push ebp 0: kd> kc # 00 Ntfs!ReadIndexBuffer 01 Ntfs!FindFirstIndexEntry 02 Ntfs!NtfsUpda…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...
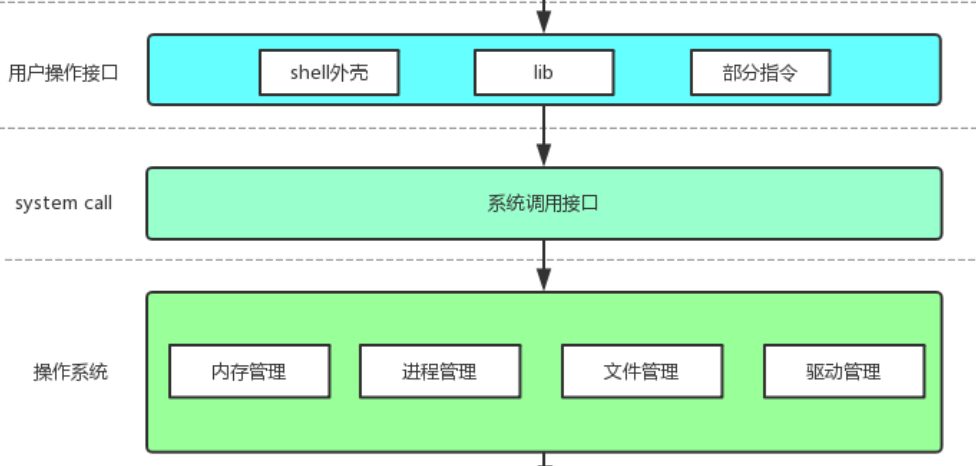
【Linux手册】探秘系统世界:从用户交互到硬件底层的全链路工作之旅
目录 前言 操作系统与驱动程序 是什么,为什么 怎么做 system call 用户操作接口 总结 前言 日常生活中,我们在使用电子设备时,我们所输入执行的每一条指令最终大多都会作用到硬件上,比如下载一款软件最终会下载到硬盘上&am…...