Canal 深入解析:从原理到实践的全面解读
Canal 深入解析:从原理到实践的全面解读
官网:https://github.com/alibaba/canal
Canal 是阿里巴巴开源的一款分布式增量数据同步工具,广泛应用于数据同步、实时数据处理和数据库的增量备份等场景。它可以通过监听 MySQL 数据库的 binlog(二进制日志)来捕获数据变动,并将这些变动实时地同步到下游系统,如 Kafka、Elasticsearch、HBase、Redis 等。本文将从 Canal 的原理、架构、使用场景到部署和配置等方面进行全面解读,帮助你深入了解和掌握 Canal 的使用。
文章目录
- Canal 深入解析:从原理到实践的全面解读
- Canal 的工作原理
- 数据流转过程
- Canal 的核心特性
- 1. 高效的增量数据同步
- 2. 实时性强
- 3. 灵活的下游系统支持
- 4. 支持分布式部署
- 5. 数据一致性保障
- Canal 的架构设计
- 1. Canal Server
- 2. Canal Client
- 3. 下游系统(Kafka、Elasticsearch、Hadoop 等)
- 4. Canal Admin
- Canal 的使用场景
- 1. 数据库同步
- 2. 实时数据分析
- 3. 实时缓存更新
- 4. 搜索引擎同步
- Canal 的安装与配置
- 1. 安装 Canal
- 2. 配置 Canal
- 3. 启动 Canal
- 4. 查看 Canal 状态
- Canal 客户端的使用
- 解释:
- 代码运行结果:
- Canal 的优缺点
- 优点:
- 缺点:
- 总结

Canal 的工作原理
Canal 的核心思想是通过 MySQL 的 binlog 机制来捕获数据库的变更事件,获取增量数据并进行实时同步。binlog 是 MySQL 的二进制日志,它记录了所有对数据库的数据变动(如新增、修改、删除)。Canal 作为 binlog 的监听者,能够实时捕捉到这些数据变动,然后推送到下游系统。
数据流转过程
-
数据库变动:当用户在数据库中进行增、删、改等操作时,这些操作会被记录到
binlog中。 -
Canal 监听
binlog:Canal 作为 MySQL 的客户端,连接到 MySQL 实例,监听并解析binlog日志文件。Canal 会读取binlog中的变更信息,并将其转化为特定格式的增量数据。 -
数据推送到下游:Canal 将解析后的增量数据通过特定协议推送到下游系统,比如 Kafka、Elasticsearch、Hadoop 等进行存储和处理。
通过这一流程,Canal 实现了数据从一个 MySQL 数据库到另一个系统的实时同步,而无需全量同步,从而降低了数据传输量和延迟。
Canal 的核心特性
Canal 具有以下几个重要特性:
1. 高效的增量数据同步
Canal 通过 MySQL 的 binlog 来捕获数据变动,这样只同步数据的增量部分(即新增、修改、删除操作),从而避免了全量同步的性能开销,且保证了同步的实时性。
2. 实时性强
Canal 实现了数据的实时同步,通常延迟非常低,适用于需要高实时性的场景,例如实时数据分析、实时缓存更新等。
3. 灵活的下游系统支持
Canal 支持将数据同步到多种不同的下游系统,包括但不限于:
- 消息队列:如 Kafka、RocketMQ 等
- 搜索引擎:如 Elasticsearch、Solr 等
- 缓存系统:如 Redis、Memcached 等
- 大数据平台:如 Hadoop、HBase、Flink 等
4. 支持分布式部署
Canal 支持分布式架构,可以横向扩展,适应大规模、高并发的实时数据同步需求。通过分布式部署,Canal 可以轻松应对大规模的数据同步任务,保证高效的数据传输。
5. 数据一致性保障
Canal 能够保证数据的一致性。由于它是通过 binlog 读取数据库变动,并通过日志同步,能够确保下游系统的数据始终与源数据库保持一致。
Canal 的架构设计
Canal 的架构设计遵循“监听 - 解析 - 推送”的基本模式,其核心组成部分包括以下几个:
1. Canal Server
Canal Server 是 Canal 的核心组件,负责:
- 连接 MySQL 数据库,读取
binlog数据。 - 解析
binlog数据并将其转化为业务需要的格式。 - 将解析后的数据推送到下游系统(如 Kafka、Elasticsearch、HBase 等)。
2. Canal Client
Canal Client 是用于接收 Canal Server 推送的数据的组件,通常应用于下游系统的数据接收与处理。客户端可以使用 Canal 提供的 API 实现数据的消费和处理。
3. 下游系统(Kafka、Elasticsearch、Hadoop 等)
下游系统用于接收 Canal 推送的数据并存储或处理。具体的下游系统根据业务需求而定。
4. Canal Admin
Canal Admin 是用于管理 Canal 实例、监控和调度 Canal 的管理平台。通过 Canal Admin,用户可以查看 Canal 实例的状态、查看同步进度、进行故障诊断等。
Canal 的使用场景
Canal 被广泛应用于以下几种场景:
1. 数据库同步
Canal 的一个典型应用场景是数据库间的数据同步。假设企业有多个数据库实例,例如主数据库和备数据库,或者跨地域的数据库部署,Canal 可以实现它们之间的数据同步。
- MySQL 主从同步:利用 Canal 作为增量同步工具,实时地将主数据库的数据同步到从数据库中,保证数据一致性。
- 异构数据库间的数据同步:将 MySQL 数据同步到其他类型的数据库(如 Oracle、SQL Server、Elasticsearch)中,帮助企业实现跨数据库的数据整合。
2. 实时数据分析
Canal 可以将数据库中的增量数据实时同步到 Kafka、Hadoop 等大数据平台,为实时数据分析提供数据支持。例如,实时同步用户交易数据到 Kafka,再通过 Flink 等流式计算引擎进行实时分析和处理。
3. 实时缓存更新
在高并发环境下,直接从数据库读取数据可能造成较大的性能压力。使用 Canal 将数据库的增量数据同步到缓存系统(如 Redis、Memcached),可以提高系统的响应速度,减少数据库负载。
4. 搜索引擎同步
企业的搜索引擎通常需要实时同步数据库中的数据,以保证搜索结果的准确性和及时性。通过 Canal,可以将 MySQL 数据库中的数据同步到 Elasticsearch 中,从而实时更新搜索索引。
Canal 的安装与配置
1. 安装 Canal
Canal 提供了多种安装方式,包括源码安装和 Docker 安装。
- 源码安装:可以从 Canal 的 GitHub 仓库下载源码并进行编译。
- Docker 安装:Canal 提供了 Docker 镜像,使用 Docker 可以非常方便地部署 Canal。
例如,通过 Docker 安装 Canal:
docker run -d --name canal-server -p 11111:11111 canal/canal-server
2. 配置 Canal
Canal 的配置文件通常存放在 conf/ 目录下,主要的配置文件包括:
canal.properties:全局配置文件,包含 Canal 的运行模式、监听的数据库信息等。instance.properties:每个实例的配置信息,指定需要同步的数据库、表等信息。
配置项通常包括以下几个:
- MySQL 连接信息:配置 MySQL 的主机、端口、用户名、密码等信息。
- Binlog 配置:指定需要监听的
binlog文件和位置。 - 下游系统配置:配置数据同步的目标系统,如 Kafka、Elasticsearch、HBase 等。
3. 启动 Canal
配置完成后,通过启动脚本启动 Canal:
./bin/startup.sh
4. 查看 Canal 状态
启动成功后,可以通过访问 Canal Admin 来查看 Canal 实例的运行状态。
Canal 客户端的使用
Canal 提供了 Java 客户端 API,开发者可以通过它接收 Canal Server 推送的数据。以下是一个基本的 Java 客户端示例:
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.Message;public class CanalClient {public static void main(String[] args) {CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("localhost", 11111), "example", "", "");connector.connect();connector.subscribe(".*\\..*"); // 订阅所有表的变更while (true) {// 获取增量数据Message message = connector.getWithoutAck(100); // 100 表示获取 100 条数据List<Entry> entries = message.getEntries();for (Entry entry : entries) {// 处理每一条变更记录if (entry.getEntryType() == EntryType.ROWDATA) {RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());EventType eventType = rowChange.getEventType();// 遍历记录中的每一行数据for (RowData rowData : rowChange.getRowDatasList()) {if (eventType == EventType.INSERT) {// 处理插入操作System.out.println("Insert data: " + rowData);} else if (eventType == EventType.UPDATE) {// 处理更新操作System.out.println("Update data: " + rowData);} else if (eventType == EventType.DELETE) {// 处理删除操作System.out.println("Delete data: " + rowData);}}}}// 提交已处理的消息connector.ack(message.getId());}}
}
解释:
CanalConnector:建立与 Canal Server 的连接。connector.getWithoutAck(100):从 Canal Server 获取数据,最多获取 100 条数据。EntryType.ROWDATA:通过binlog解析出来的数据行。RowChange.parseFrom(entry.getStoreValue()):将binlog数据转换为RowChange对象,从而获取详细的增、删、改操作。EventType:包括 INSERT、UPDATE、DELETE 等事件类型,表示数据的操作类型。connector.ack(message.getId()):处理完一条消息后,提交确认,避免重复消费。
代码运行结果:
运行该代码后,可以看到程序会实时打印出从 MySQL 数据库中捕获到的增、删、改操作的具体数据。这些数据可以进一步处理,比如同步到 Kafka、存储到 HBase 等。
Canal 的优缺点
优点:
- 实时性强:Canal 利用
binlog机制,能够实现高效、实时的数据同步。 - 低延迟:由于 Canal 只同步增量数据,相比传统的全量同步方式,它的延迟较低。
- 高吞吐量:Canal 支持大规模的分布式部署,能够处理高吞吐量的增量数据同步任务。
- 支持多种下游系统:Canal 可以将数据同步到多种下游系统,包括 Kafka、Elasticsearch、Redis、Hadoop 等,具有较高的灵活性。
- 稳定性:Canal 在生产环境中被广泛使用,稳定性较高,能够处理大规模的实时数据同步任务。
缺点:
- 只能支持 MySQL 和 MariaDB:Canal 目前主要支持 MySQL 和 MariaDB 等基于
binlog的数据库,无法直接支持其他类型的数据库(如 Oracle、SQL Server 等),除非通过定制开发。 - 配置和部署较为复杂:对于初学者来说,Canal 的配置和部署可能会显得比较复杂,尤其是在分布式部署和集群模式下。
- 性能瓶颈:虽然 Canal 支持高吞吐量,但在极高并发的场景下,仍然可能会遇到性能瓶颈,需要优化 Canal 配置或硬件资源。
总结
Canal 作为一个分布式增量数据同步工具,基于 MySQL binlog 实现了高效、实时的数据同步功能,广泛应用于数据库同步、实时数据分析、实时缓存更新、搜索引擎同步等场景。其高效性、实时性和灵活性使其成为很多企业在进行实时数据处理时的首选工具。
通过深入了解 Canal 的工作原理、架构设计、核心特性、使用场景和部署配置等内容,你可以更好地利用它来实现各种数据同步和实时处理需求。虽然 Canal 具有很多优势,但在实际使用中,仍然需要根据具体的业务场景来调整配置和优化性能。
相关文章:
Canal 深入解析:从原理到实践的全面解读
Canal 深入解析:从原理到实践的全面解读 官网:https://github.com/alibaba/canal Canal 是阿里巴巴开源的一款分布式增量数据同步工具,广泛应用于数据同步、实时数据处理和数据库的增量备份等场景。它可以通过监听 MySQL 数据库的 binlog&am…...

SQL SERVER 2016 AlwaysOn 无域集群+负载均衡搭建与简测
之前和很多群友聊天发现对2016的无域和负载均衡满心期待,毕竟可以简单搭建而且可以不适用第三方负载均衡器,SQL自己可以负载了。windows2016已经可以下载使用了,那么这回终于可以揭开令人憧憬向往的AlwaysOn2016 负载均衡集群的神秘面纱了。 …...

解决 Maven 部署中的 Artifact 覆盖问题:实战经验分享20241204
🛠️ 解决 Maven 部署中的 Artifact 覆盖问题:实战经验分享 📌 引言 在软件开发过程中,持续集成和持续部署(CI/CD)是提高开发效率和代码质量的关键手段。Hudson 和 Maven 是两种广泛使用的工具࿰…...

【开源免费】基于SpringBoot+Vue.JS中小型医院网站(JAVA毕业设计)
博主说明:本文项目编号 T 078 ,文末自助获取源码 \color{red}{T078,文末自助获取源码} T078,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析…...

Linux CentOS
阿里云开源镜像下载链接 https://mirrors.aliyun.com/centos/7/isos/x86_64/ VMware 安装 CentOS7 自定义 下一步 选择稍后安装操作系统 选择 输入 查看物理机CPU内核数量 CtrlShiftEsc 总数不超过物理机内核数量 推荐内存 自选 推荐 推荐 默认 拆分成多个 默认 自定义硬件…...

Android SurfaceFlinger layer层级
壁纸作为显示的最底层窗口它是怎么显示的 1. SurfaceFlinger layer层级 锁屏状态dump SurfaceFlinger ,adb shell dumpsys SurfaceFlinger Display 0 (active) HWC layers: -----------------------------------------------------------------------------------…...

spark-sql配置教程
1.前期准备 (1)首先要把hadoop集群,hive和spark等配置好 hadoop集群,hive的配置可以看看这个博主写的博客 大数据_蓝净云的博客-CSDN博客 或者看看黑马程序员的视频 黑马程序员大数据入门到实战教程,大数据开发必…...

生成表格pdf格式
1. 添加依赖 <dependency><groupId>com.itextpdf</groupId><artifactId>kernel</artifactId><version>7.2.5</version></dependency><dependency><groupId>com.itextpdf</groupId><artifactId>layout…...

C++ 游戏开发的前沿趋势:从光线追踪到人工智能的全新挑战
随着游戏行业的快速发展,技术的不断进步为游戏开发带来了前所未有的机遇和挑战。从逼真的光影效果到复杂的物理模拟,再到智能化的非玩家角色(NPC)行为和玩家交互,现代游戏的技术需求已经超越了传统的图形渲染与场景搭建…...

微信小程序3-显标记信息和弹框
感谢阅读,初学小白,有错指正。 一、实现功能: 在地图上添加标记点后,标记点是可以携带以下基础信息的,如标题、id、经纬度等。但是对于开发来说,这些信息还不足够,而且还要做到点击标记点时&a…...

EasyNVR中HTTP-FLV协议无法播放怎么解决?
在科技日新月异的今天,摄像头作为公共安全领域的重要一环,其技术的不断提升正显著地改变着社会的安全格局。从最初的简单监控到如今的高清智能分析,我们可以对特定区域进行实时监控和记录,为社会的安全稳定提供了强有力的保障。 问…...

spring cloud之ribbon复习回顾
其实在项目中直接使用ribbon时不多,大多是使用feign的,其实feign底层也是通过ribbon构建的,主要记忆一下计算规则,ribbon的源码还是很不错的,还是值得学习的。 1、添加pom <dependency><groupId>org.spr…...

RFT 强化微调
OpenAI在今天发布的新技术,RFT结合了SFT和RL的优化算法,与传统的监督微调不同,强化微调旨在通过任务训练让模型掌握复杂推理能力,而不仅仅是“记住答案”。 什么是强化微调 强化微调是通过高质量任务数据和参考答案优化大语言模型…...

SpringBoot教程(三十二) SpringBoot集成Skywalking链路跟踪
SpringBoot教程(三十二) | SpringBoot集成Skywalking链路跟踪 一、Skywalking是什么?二、Skywalking与JDK版本的对应关系三、Skywalking下载四、Skywalking 数据存储五、Skywalking 的启动六、部署探针 前提: Agents 8.9.0 放入 …...

分布式搜索引擎Elasticsearch
Elasticsearch是一个基于Lucene库的开源分布式搜索引擎,它被设计用于云计算中,能够实现快速、near-real-time的搜索,并且可以进行大规模的分布式索引。 以下是一个简单的Python代码示例,展示如何使用Elasticsearch的Python客户端…...
)
在Vue.js中生成二维码(将指定的url+参数 生成二维码)
在Vue.js中生成二维码,你可以使用JavaScript库如qrcode或qr.js。以下是一个简单的例子,展示如何在Vue组件中使用qrcode库将指定的URL加上参数生成二维码。 首先,你需要安装qrcode库。如果你使用的是npm或yarn,可以通过命令行安装…...

统信桌面专业版部署postgresql-14.2+postgis-3.2方法介绍
文章来源:统信桌面专业版部署postgresql-14.2postgis-3.2方法介绍 | 统信软件-知识分享平台 应用场景 CPU架构:X86(海光C86-3G 3350) OS版本信息:1070桌面专业版 软件信息:postgresql-14.2postgis-3.2 …...

数字图像处理(16):RGB与HSV互转
(1)HSV颜色模型:HSV颜色模型,又称为六角锥体模型,以色调(H)、饱和度(S)、亮度(V)为基础,能够更加自然地表现和处理颜色,因…...

web组态可视化编辑器
随着工业智能制造的发展,工业企业对设备可视化、远程运维的需求日趋强烈,传统的单机版组态软件已经不能满足越来越复杂的控制需求,那么实现web组态可视化界面成为了主要的技术路径。 行业痛点 对于软件服务商来说,将单机版软件转…...

数组 - 八皇后 - 困难
************* C topic: 面试题 08.12. 八皇后 - 力扣(LeetCode) ************* Good morning, gays, Fridary angin and try the hard to celebrate. Inspect the topic: This topic I can understand it in a second. And I do rethink a movie, …...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...
)
【LeetCode】3309. 连接二进制表示可形成的最大数值(递归|回溯|位运算)
LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 题目描述解题思路Java代码 题目描述 题目链接:LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 给你一个长度为 3 的整数数组 nums。 现以某种顺序 连接…...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...
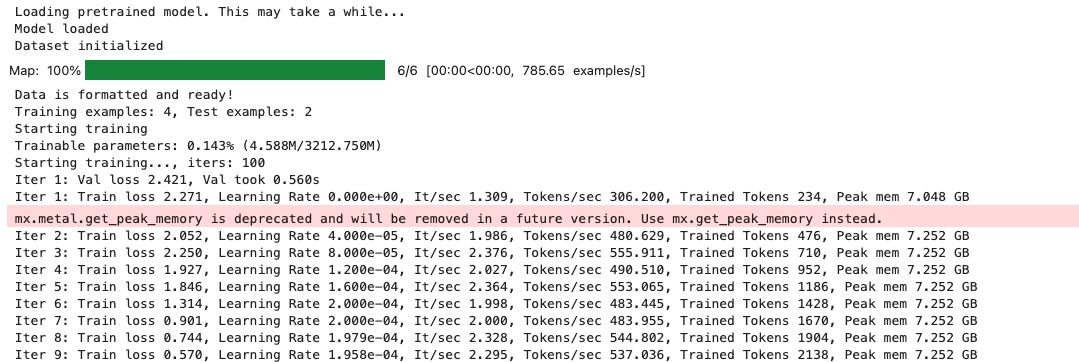
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...

Java 与 MySQL 性能优化:MySQL 慢 SQL 诊断与分析方法详解
文章目录 一、开启慢查询日志,定位耗时SQL1.1 查看慢查询日志是否开启1.2 临时开启慢查询日志1.3 永久开启慢查询日志1.4 分析慢查询日志 二、使用EXPLAIN分析SQL执行计划2.1 EXPLAIN的基本使用2.2 EXPLAIN分析案例2.3 根据EXPLAIN结果优化SQL 三、使用SHOW PROFILE…...