【AI学习】苹果技术报告《Apple Intelligence Foundation Language Models》
文章地址:https://machinelearning.apple.com/papers/apple_intelligence_foundation_language_models.pdf
这篇文章介绍了苹果公司开发的基础语言模型(Apple Foundation Language Models,简称AFM),这些模型旨在为苹果智能(Apple Intelligence)功能提供支持。文章详细描述了这些模型的架构、训练过程、优化方法以及评估结果,并强调了负责任的人工智能(Responsible AI)原则在模型开发过程中的应用。
以下是文章的主要内容概述:
-
引言:介绍了苹果智能在2024年全球开发者大会上的发布,以及它在iOS 18、iPadOS 18和macOS Sequoia中的集成情况。苹果智能包括多个高效的生成模型,能够快速、准确地适应用户的日常工作。
-
苹果基础模型:介绍了AFM-on-device(约3亿参数的设备端模型)和AFM-server(更大的服务器端模型),以及它们如何被构建和优化以高效、准确、负责任地执行专业任务。
-
模型架构:AFM基础模型是基于Transformer架构的密集型解码器模型,包括多个设计选择,例如共享输入/输出嵌入矩阵、预归一化、查询/键归一化、分组查询注意力等。
-
预训练:详细描述了AFM预训练过程,包括数据的选择和处理、训练策略和使用的优化器。
-
后训练:讨论了后训练方法,包括监督式微调(SFT)和基于人类反馈的强化学习(RLHF),以及两种新的后训练算法:迭代拒绝采样微调算法(iTeC)和带有镜像下降策略优化和留一法优势估计器(MDLOO)的RLHF算法。
-
苹果智能功能:介绍了如何使用适配器架构来为特定的任务微调基础模型,以及如何通过运行时可交换的适配器动态专业化模型。
-
负责任的人工智能:强调了苹果在开发AI工具和模型时所遵循的负责任AI原则,包括赋予用户智能工具、代表用户、谨慎设计、保护隐私等。
-
评估:对AFM模型进行了预训练、后训练和特定功能评估,包括人类评估和自动化基准测试。
-
结论:总结了AFM模型在苹果智能中的作用,以及它们如何帮助用户在苹果产品上完成日常活动。
文章还包括了一些技术细节,如模型的具体参数、训练和优化的具体方法、使用的特定算法和评估工具等。此外,还讨论了负责任AI的实践,包括数据政策、安全过滤、红队测试和安全评估。
1、介绍

图1:Apple基础模型的建模概览
在2024年全球开发者大会上,我们介绍了Apple Intelligence,这是一个深度集成到iOS 18、iPadOS 18和macOS Sequoia中的个人智能系统。Apple Intelligence由多个高效的生成型模型组成,这些模型快速、高效,专门针对用户的日常工作任务,并且能够根据当前活动即时适应。内置于Apple Intelligence的基础模型经过微调,以提升用户体验,例如撰写和润色文本、优先排序和总结通知、为与家人和朋友的对话创建有趣的图像,以及在应用内执行操作以简化跨应用的交互。
在这篇报告中,我们将详细说明这两个模型——AFM-on-device(AFM代表Apple基础模型),一个约30亿参数的语言模型,以及AFM-server,一个更大的服务器基础语言模型——是如何构建和适应的,以高效、准确、负责任地执行专业任务(见图1)。这两个基础模型是Apple创建的更大一系列生成型模型的一部分,以支持用户和开发者;这包括一个基于AFM语言模型的编程模型,以在Xcode中构建智能,以及一个扩散模型,帮助用户在例如信息应用中视觉上表达自己。Apple Intelligence的每一步设计都体现了Apple的核心价值,并建立在行业领先的隐私保护基础之上。此外,我们还创建了负责任的AI原则,以指导我们如何开发AI工具以及支撑它们的模型:
-
用智能工具赋予用户力量:我们确定可以负责任地使用AI的领域,以创建满足特定用户需求的工具。我们尊重用户选择如何使用这些工具来实现他们的目标。
-
代表我们的用户:我们构建深度个性化的产品,目标是真实地代表全球用户。我们持续努力避免在我们的AI工具和模型中传播刻板印象和系统性偏见。
-
谨慎设计:我们在流程的每个阶段,包括设计、模型训练、功能开发和质量评估中采取预防措施,以识别我们的AI工具可能被滥用或导致潜在伤害的方式。我们将不断主动地改进我们的AI工具,并借助用户反馈。
-
保护隐私:我们通过强大的设备处理能力和像Private Cloud Compute这样的开创性基础设施来保护用户的隐私。我们不会在训练我们的基础模型时使用用户的私人个人数据或用户交互数据。
这些原则体现在使能Apple Intelligence的架构的每个阶段,并将功能和工具与专业模型连接起来。在本报告的剩余部分中,我们将提供有关我们如何开发高度能干、快速和节能的模型的决策细节;我们如何训练这些模型;我们的适配器如何针对特定用户需求进行微调;以及我们如何评估模型性能,以帮助性和意外伤害为考量。
2 Architecture
AFM基础模型是密集的仅解码器模型,构建在Transformer架构之上[Vaswani等人,2017],具有以下设计选择:
• 共享输入/输出嵌入矩阵[Press和Wolf,2016]以减少参数的内存使用。
• 预规范化[Nguyen和Salazar,2019],使用RMSNorm[Zhang和Sennrich,2019]以提高训练稳定性。
• 查询/键规范化[Wortsman等人,2023]以提高训练稳定性。
• 分组查询注意力(GQA)[Ainslie等人,2023],具有8个键-值头,以减少KV缓存内存占用。
• SwiGLU激活[Shazeer,2020]以提高效率。
• RoPE[Su等人,2024]位置嵌入,基础频率设置为500k以支持长上下文。
表1提供了有关AFM-on-device尺寸的一些细节。

表1:AFM-on-device尺寸
3 Pre-training
这部分主要介绍了Apple基础模型(AFM)预训练的过程,包括数据的选择、处理和预训练的具体阶段。
AFM-server核心训练是从头开始进行的,而AFM-on-device是从较大的模型中提取和修剪。
以下是该部分的主要内容分析:
-
数据(Data):
- AFM预训练数据集包含多样化和高质量的数据混合,包括从出版商处获得的授权数据、公开可用或开源数据集,以及通过Apple的网络爬虫Applebot抓取的公开信息。
- Apple尊重网页出版商的选择退出Applebot的抓取,使用标准的robots.txt指令。
- 为了保护用户隐私,没有包含任何私人Apple用户数据,并且努力从公开数据中排除亵渎内容、不安全材料和个人身份识别信息(PII)。
- 数据质量而非数量是决定下游模型性能的关键因素。
-
数据混合的关键组成部分(Key Components of the Data Mixture):
- 网页(Web pages):使用Applebot抓取公开信息,并尊重出版商的选择退出。对网页进行处理,包括正文提取、安全和亵渎过滤、去重和质量过滤。
- 授权数据集(Licensed datasets):从出版商处获取的高质量数据,用于预训练的继续和上下文延长阶段。
- 代码(Code):从GitHub上的开源仓库中获取代码数据,涵盖多种编程语言,进行去重、过滤PII和质量过滤。
- Math:整合了来自网站的两个高质量数据类别,包括数学问答数据集和数学相关网页内容。
- 公共数据集(Public datasets):评估和选择高质量的公共数据集,并在预训练混合中排除个人身份识别信息。
- 分词器(Tokenizer):使用基于SentencePiece的字节对编码(BPE)分词器,总词汇量分别为AFM-server的100k和AFM-on-device的49k。
-
预训练配方(Recipe):
- AFM预训练分为三个阶段:核心(core)、继续(continued)和上下文延长(context-lengthening)。
- 核心预训练(Core pre-training):AFM-server从头开始训练,而AFM-on-device则通过知识蒸馏和结构修剪从更大的模型中获得。
- 继续预训练(Continued pre-training):在更长的序列长度下进行,强调代码和数学数据,减少网络爬取数据的比例。
- 上下文延长(Context lengthening):在更长的序列长度下进行,包括合成的长上下文问答数据。
-
优化器(Optimizer):
- 使用带有动量的RMSProp变体进行AFM预训练,包括梯度裁剪和全局梯度范数裁剪以提高稳定性。
-
训练基础设施(Training infrastructure):
- AFM模型在Cloud TPU集群上使用AXLearn框架进行预训练,该框架支持张量、完全分片数据并行和序列并行,以高效、可扩展地训练大型模型。
这部分内容强调了Apple在构建其基础语言模型时对数据质量、隐私保护和预训练过程的重视,以及如何通过不同的预训练阶段来提升模型的性能和适用性。
4 Post-Training
这主要讨论了Apple基础模型(AFM)在预训练之后的进一步训练和优化过程,以提升模型在特定任务上的表现,并确保模型的输出符合Apple的负责任AI原则。以下是该部分的重要内容分析:
-
后训练的重要性(Importance of Post-Training):
- 后训练(Post-Training)旨在提升模型在指令遵循、推理和写作等通用任务上的性能。
- 通过后训练,模型能够更好地适应特定的用户需求,并且与Apple的核心价值和负责任AI原则保持一致。
-
数据策略(Data Strategy):
- Apple采用了混合数据策略,包括人工标注数据和合成数据。
- 人工标注数据包括系统级和任务级指令及其响应,而合成数据则通过模型生成,以增加数据的多样性和质量。
-
人工标注(Human Annotations):
- 为了提升AFM的指令微调能力,Apple收集了高质量的人工标注示范数据集。
- 人工偏好反馈用于迭代改进AFM的能力,通过比较和排名两个模型响应来收集偏好标签。
-
合成数据(Synthetic Data):
- Apple通过合成数据生成来提升数据质量和多样性,特别是在数学、工具使用和编码领域。
- 数学领域的合成数据包括生成数学问题及其解决方案,工具使用和编码领域的合成数据则通过模型自指导方法生成。
-
监督式微调(Supervised Fine-Tuning, SFT):
- 在SFT阶段,模型在给定提示的示范数据上进行训练,以形成覆盖各种自然语言用例的高质量数据混合。
- 数据选择包括内部人工标注者评级、自动模型过滤技术和文本嵌入去重。
-
强化学习从人类反馈(Reinforcement Learning from Human Feedback, RLHF):
- 使用人类偏好数据通过强化学习提升模型性能和质量。
- 介绍了两种新的后训练算法:iTeC(迭代教学委员会)和MDLOO(镜像下降策略优化和留一优势估计器)。
-
iTeC和MDLOO算法:
- iTeC结合了多种偏好优化算法,包括拒绝采样、DPO(直接偏好优化)及其变体IPO(在线策略优化)和在线强化学习(RL)。
- MDLOO是一种在线强化学习算法,它在模型训练期间解码响应并应用强化学习算法以最大化奖励。
-
Apple Intelligence功能(Powering Apple Intelligence features):
- 基础模型为Apple Intelligence设计,这是集成在iPhone、iPad和Mac中的个人智能系统。
- 通过任务特定的微调和运行时可互换的适配器架构,基础模型能够针对日常活动进行动态专业化。
-
适配器架构(Adapter Architecture):
- 使用LoRA适配器对模型进行特定任务的微调,这些适配器是小型神经网络模块,可以插入基础模型的各个层中。
- 适配器参数使用16位表示,允许动态加载、缓存和交换,以实现任务专业化,同时有效管理内存并保证操作系统的响应性。
-
优化(Optimizations):
- 为了在设备和Private Cloud Compute上高效部署AFM,应用了多种优化技术,以减少内存、延迟和功耗,同时保持模型质量。
这部分内容强调了Apple在后训练阶段如何通过数据策略、微调和强化学习技术来提升模型性能,并确保模型输出符合公司的价值观和负责任AI原则。通过这些方法,Apple旨在为用户提供高效、安全且个性化的智能体验。
5 Powering Apple Intelligence features
我们的基础模型旨在为Apple Intelligence提供支持,这是集成在iPhone、iPad和Mac中支持的模型中的个人智能系统。我们构建了这些模型,使它们快速且高效。虽然我们在基础模型中取得了令人印象深刻的广泛能力,但衡量其质量的真正相关标准是它在操作系统中的特定任务上的表现。
在这里,我们发现我们可以通过任务特定的微调,将即使是小型模型的性能提升到同类最佳的水平。我们已经开发了一种基于运行时可互换适配器的架构,使单一基础模型能够针对数十个这样的任务进行专业化适配。图2提供了高层次的概览。

5.1 适配器架构
我们的基础模型针对用户的日常工作活动进行了微调,并且可以动态地针对手头的任务进行专业化。我们使用LoRA适配器,这些小型神经网络模块可以插入基础模型的各个层中,以针对特定任务微调我们的模型。对于每个任务,我们调整AFM自注意力层和逐点前馈网络中的所有线性投影矩阵。通过仅微调适配器,基础预训练模型的原始参数保持不变,保留了模型的一般知识,同时使适配器支持特定任务。我们用16位表示适配器参数的值,对于约30亿参数的设备模型,一个16级的适配器参数通常需要几十兆字节。适配器模型可以动态加载,临时缓存在内存中,并进行交换——使我们的基础模型能够针对手头的任务即时专业化,同时有效管理内存并保证操作系统的响应性。为了促进适配器的训练,我们创建了一个高效的基础设施,允许我们快速添加、重新训练、测试和部署适配器,当基础模型或训练数据更新或需要新功能时。
5.2 优化
AFM模型旨在支持用户的日常活动,因此推理延迟和功耗效率对整体用户体验都很重要。我们应用了各种优化技术,以使AFM能够高效地部署在设备和Private Cloud Compute上。这些技术显著减少了内存、延迟和功耗,同时保持了整体模型质量。
为了适应边缘设备的有限内存预算并降低推理成本,关键是应用模型量化技术来降低每个权重的有效位数,同时保持模型质量。以前的研究发现,与原始的32/16位浮点版本相比,4位量化模型的质量损失很小(通常在预训练指标中测量)。由于AFM预计要支持多种产品功能,因此量化模型在这些用例的关键特定领域保持能力至关重要。为了在模型容量和推理性能之间取得最佳平衡,我们开发了最先进的量化方法和框架,利用准确性恢复适配器。这使我们能够实现平均每权重不到4位的近无损量化,并提供灵活的量化方案选择。
方法
模型在训练后阶段被压缩和量化,平均每权重低于4位,量化后的模型通常会显示出适度的质量损失。因此,我们不是直接将量化模型传递给应用团队进行功能开发,而是附加一组参数效率高的LoRA适配器以恢复质量。我们确保这些LoRA适配器的训练配方与预训练和后训练过程一致。然后,产品将通过从准确性恢复适配器初始化适配器权重来微调自己的特定功能LoRA适配器,同时保持量化的基础模型冻结。值得注意的是,训练准确性恢复适配器是样本高效的,可以被认为是基础模型训练的迷你版本。在适配器的预训练阶段,我们只需要大约100亿个token(约基础模型训练的0.15%)就可以完全恢复量化模型的能力。由于应用适配器将从这些准确性恢复适配器进行微调,因此它们不会增加任何额外的内存使用或推理成本。关于适配器大小,我们发现16级的适配器在模型容量和推理性能之间提供了最佳权衡。然而,为了提供灵活性以适应各种用例,我们为应用团队提供了不同等级的准确性恢复适配器{8, 16, 32}供选择。在附录F中,我们提供了未量化、量化和准确性恢复模型的详细评估结果,并表明恢复模型的性能更接近于未量化版本。
量化方案
准确性恢复适配器带来的另一个好处是,它们允许更灵活地选择量化方案。以前在量化LLMs时,人们通常将权重分组为小块,通过相应的最大绝对值对每个块进行归一化以过滤异常值,然后以块为单位应用量化算法。较大的块大小可以降低每个权重的有效位数并提高吞吐量,但量化损失会增加。为了平衡这种权衡,通常将块大小设置为小值,如64或32。在我们的实验中,我们发现准确性恢复适配器可以极大地改善这种权衡中的帕累托前沿。对于更激进的量化方案,恢复的误差会更多。因此,我们能够使用高效量化方案而不必担心失去模型容量。具体来说,我们的AFM设备模型在Apple神经引擎(ANE)上运行时使用调色板量化:对于投影权重,每16列/行共享相同的量化常数(即查找表),并使用K均值和16个唯一值(4位)进行量化。量化块大小可以高达100k。此外,由于AFM的嵌入层在输入和输出之间共享,它与ANE上的投影层实现不同。因此,我们使用8位整数进行每通道量化,以提高效率。
混合精度量化
AFM中的每个Transformer块和每层都存在残差连接,因此并非所有层都具有相同的重要性。基于这种直觉,我们进一步通过使某些层使用2位量化(默认为4位)来减少内存使用。平均而言,AFM设备模型可以压缩到仅约3.5位每权重,而不会有显著的质量损失。我们选择在生产中使用3.7位每权重,因为它已经满足了内存要求。
交互式模型分析
我们使用交互式模型延迟和功耗分析工具Talaria[Hohman等人,2024],以更好地指导每个操作的比特率选择。
更多讨论
使用量化模型和LoRA适配器在概念上与QLoRA[Dettmers等人,2024]相似。虽然QLoRA旨在节省微调期间的计算资源,但我们的重点是能够切换不同的LoRA适配器,以高效支持各种特定用例的高性能。在特定功能微调之前,我们首先在相同的预训练和后训练数据上训练准确性恢复适配器,这对于保持模型质量至关重要。准确性恢复框架可以与不同的量化技术结合使用,如GPTQ[Frantar等人,2022]和AWQ[Lin等人,2024],因为它不直接依赖于量化方法本身。第5节中描述的功能适配器是从这些准确性恢复适配器初始化的。
5.3 Case study: summarization
我们使用AFM-on-device模型来驱动摘要功能。我们与设计团队合作,为电子邮件、消息和通知的摘要创建了规格说明。
虽然AFM-on-device在一般摘要方面表现良好,但我们发现很难引导它生成严格符合规格的摘要。因此,我们在量化的AFM-on-device之上微调了一个LoRA适配器,用于摘要。适配器是从第5.2节中描述的准确性恢复适配器初始化的。我们使用的数据混合包括涵盖电子邮件、消息和通知的输入有效载荷。这些有效载荷包括公共数据集、供应商数据和内部生成和提交的示例。所有数据都已批准用于生产使用。供应商数据和内部生成的数据都已匿名处理,以去除用户信息。鉴于这些有效载荷,我们使用AFM-server根据产品要求生成合成摘要。这些有效载荷和摘要用于训练。
合成摘要
我们使用AFM-server生成合成摘要。我们应用了一系列基于规则的过滤器,然后是模型基于的过滤器。基于规则的过滤器基于启发式方法,如长度限制、格式限制、观点、声音等。模型基于的过滤器用于筛选更具有挑战性的问题,如蕴含。我们的合成数据管道使我们能够高效地生成大量训练数据,并通过一个数量级来过滤,以保留用于微调的高质量示例。
提示注入
我们发现AFM-on-device倾向于遵循输入内容中的指令或回答问题,而不是摘要。为了缓解这个问题,我们使用启发式方法识别了大量具有这种行为的示例,使用AFM-server生成摘要,因为它没有表现出类似的倾向,并将这个合成数据集添加到微调数据混合中。
从“5.3 案例研究:摘要”这一节中,我们可以看出AFM-server和AFM-on-device之间的分工关系。以下是具体的分工描述:
-
AFM-on-device的角色:
- 一般摘要能力:AFM-on-device在一般摘要方面表现良好,这意味着它能够在设备上执行基本的摘要任务,提供快速响应。
- 遵循指令:AFM-on-device倾向于遵循输入内容中的指令或回答问题,而不是进行摘要,这表明它在理解和执行用户指令方面有优势。
-
AFM-server的角色:
- 合成摘要生成:AFM-server用于生成合成摘要,这涉及到更复杂的处理,如根据产品要求从输入有效载荷生成摘要。
- 处理复杂任务:AFM-server处理更复杂的摘要任务,如在摘要中包含多个文档或处理更复杂的语言结构。
- 辅助AFM-on-device:AFM-server通过生成合成数据来辅助AFM-on-device的训练,特别是在AFM-on-device难以处理的摘要任务上。
-
分工合作:
- 微调适配器:AFM-on-device通过微调LoRA适配器来专门化摘要任务,这个适配器是从准确性恢复适配器初始化的,而准确性恢复适配器的训练可能涉及到AFM-server生成的数据。
- 数据生成与过滤:AFM-server在生成合成摘要的同时,也负责应用规则和模型基于的过滤器来筛选和提高数据质量,这些数据随后用于训练AFM-on-device。
总结来说,AFM-on-device主要负责在设备上执行快速、高效的摘要任务,而AFM-server则处理更复杂的摘要任务,并为AFM-on-device提供训练数据和辅助。这种分工使得两者能够协同工作,提高摘要功能的整体性能和用户体验。
另有相关解读文章《揭秘!47页文档拆解苹果智能,从架构、数据到训练和优化》(链接:https://mp.weixin.qq.com/s/qniklWb57DU0zsyJ-nqSkg)
相关文章:
【AI学习】苹果技术报告《Apple Intelligence Foundation Language Models》
文章地址:https://machinelearning.apple.com/papers/apple_intelligence_foundation_language_models.pdf 这篇文章介绍了苹果公司开发的基础语言模型(Apple Foundation Language Models,简称AFM),这些模型旨在为苹果…...

深度相机获取实时图像总结
问题详情:之前一直把曝光调整到50000,画面一直很流畅,知道领导要求将曝光改成500000时整个程序卡死了 问题解决: 首先怀疑是帧率太低的原因,控制变量后发现不是帧率的问题,看着代码很迷茫,领导…...

Nginx限流实践-limit_req和limit_conn的使用说明
注意: 本文内容于 2024-12-07 19:38:40 创建,可能不会在此平台上进行更新。如果您希望查看最新版本或更多相关内容,请访问原文地址:Nginx限流实践。感谢您的关注与支持! 一、限流 之前我有记录通过CentOS7定时任务实…...

Unity在运行状态下,当物体Mesh网格发生变化时,如何让MeshCollider碰撞体也随之实时同步变化?
旧版源代码地址:https://download.csdn.net/download/qq_41603955/90087225?spm1001.2014.3001.5501 旧版效果展示: 新版加上MeshCollider后的效果: 注意:在Unity中,当你动态地更改物体的Mesh时,通常期望…...

记一次由docker容器使得服务器cpu占满密码和密钥无法访问bug
Bug场景: 前几天在服务器上部署了一个免费影视网站,这个应用需要四个容器,同时之前的建站软件workpress也是使用docker部署的,也使用了三个容器。在使用workpress之前,我将影视软件的容器全部停止。 再使用workpress…...

前端TS基础
文章目录 一、类型1、定义类型2、any、unknown、never3、基础类型4、联合类型5、交叉类型6、type、typeof7、作用域 二、数据结构1、数组2、元组3、函数类型4、对象类型 三、接口四、泛型五、enum六、断言七、工具1、模块2、namespace3、装饰器4、declare5、运算符6、映射类型7…...

前端面经每日一题day06
Cookie有什么字段 Name:cookie的唯一标识符 Value:与Name对应,存储Cookie的信息 Domain:可以访问cookie的域名 Path:可以访问cookie的路径 Expires/Max-Age:超时时间 Size:cookie大小 Ht…...

SOC,SOH含义区别及计算公式
SOC,SOH含义区别及计算公式 两者结合使用,有助于实现更精确的电池管理,延长电池的使用寿命,并确保电池的高效、安全运行。 1. SOC(State of Charge,荷电状态)2. SOH(State of Health…...

阿里云轻量应用服务器开放端口,图文教程分享
阿里云轻量应用服务器如何开放端口?在轻量服务器管理控制台的防火墙中添加规则即可开通端口,开通80端口就填80,开通443就填443端口,开通3306端口就填3306。阿里云百科网aliyunbaike.com整理阿里云轻量应用服务器端口号开通图文教程…...

嵌入式里的“移植”概念
这里因为最近一年看到公司某项目很多代码上有直接硬件的操作,这里有感而发,介绍移植的概念。 一、硬件 先上一个图: 举个例子,大学里应该都买过开发板,例如st的,这里三个层次, 内核ÿ…...

深入探讨 AF_PACKET 套接字
AF_PACKET 套接字是一种用于直接访问网络接口(即网卡)的套接字类型,通常用于网络数据包捕获和分析。它允许应用程序直接与网络接口卡(NIC)交互,而不需要通过网络协议栈。从而可以发送和接收以太网帧。它提供了比普通TCP/UDP套接字…...

Redis的哨兵机制
目录 1. 文章前言2. 基本概念2.1 主从复制的问题2.2 人工恢复主节点故障2.3 哨兵机制自动恢复主节点故障 3. 安装部署哨兵(基于docker)3.1 安装docker3.2 编排redis主从节点3.3 编排redis-sentinel节点 4. 重新选举5. 选举原理6. 总结 1. 文章前言 &…...
-- 选择器体系详解)
CSS系列(1)-- 选择器体系详解
前端技术探索系列:CSS 选择器体系详解 🎯 致读者:探索 CSS 选择器的奥秘 👋 前端开发者们, 今天我们将深入探讨 CSS 选择器体系,这是构建优雅样式表的基础。让我们一起学习如何精确地选中并控制网页中的…...

用Python开发打字速度测试小游戏
本文将带你一步步开发一个简单的打字速度测试小游戏,通过随机生成词组并计算用户输入速度,帮助提升打字技能。 一、功能描述 随机生成一段句子,用户需要尽快输入。计时功能,统计用户输入的总时长。对比正确率和速度,给出评分反馈。二、开发环境 语言:Python依赖库:pygam…...

基于gitlab API刷新MR的commit的指定status
场景介绍 自己部署的gitlab Jenkins,并已经设置好联动(如何设置可以在网上很容易搜到)每个MergeRequest都可以触发多个Jenkins pipeline,pipeline结束后会将状态更新到gitlab这个MR上希望可以跳过pipeline运行,直接将指定的MR的指定pipeline状态刷新为…...

服务器数据恢复—LINUX下各文件系统删除/格式化的数据恢复可行性分析
Linux操作系统是世界上流行的操作系统之一,被广泛用于服务器、个人电脑、移动设备和嵌入式系统。Linux系统下数据被误删除或者误格式化的问题非常普遍。下面北亚企安数据恢复工程师简单聊一下基于linux的文件系统(EXT2/EXT3/EXT4/Reiserfs/Xfs࿰…...

Spark on Yarn安装配置,大数据技能竞赛(容器环境)
Spark on Yarn模式,即把Spark作为一个客户端,将作业提交给Yarn服务,由于在生产环境中,很多时候都要与Hadoop使用同一个集群,因此采用Yarn来管理资源调度,可以有效提高资源利用率。 环境说明: 服…...
遣其欲,而心自静 -- 33DAI
显然,死做枚举只能的50分。 错了4次总算对了。 大体思路: 因题目说只有两个因数,那么有两种情况: 1:两个质数相乘,如:3*515 5*745 等(不包括5*525 或5*315 重复计算\ 因为3*5算了…...

No.25 笔记 | 信息收集与Google语法的实践应用
什么是信息收集? 信息收集(Information Gathering)是渗透测试的第一步,其目的是通过各种手段收集目标的漏洞和弱点,为后续的攻击策略提供依据。 正所谓“知己知彼,百战百胜”,信息收集的重要性…...

GitLab基础环境部署:Ubuntu 22.04.5系统在线安装GitLab 17.5.2实操手册
文章目录 GitLab基础环境部署:Ubuntu 22.04.5系统在线安装GitLab 17.5.2实操手册一、环境准备1.1 机器规划1.2 环境配置1.2.1 设置主机名1.2.2 停止和禁用防火墙1.2.3 更新系统 二、GitLab安装配置2.1 安装GitLab所需的依赖包2.2 添加GitLab存储库2.2.1 将GitLab存储…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...
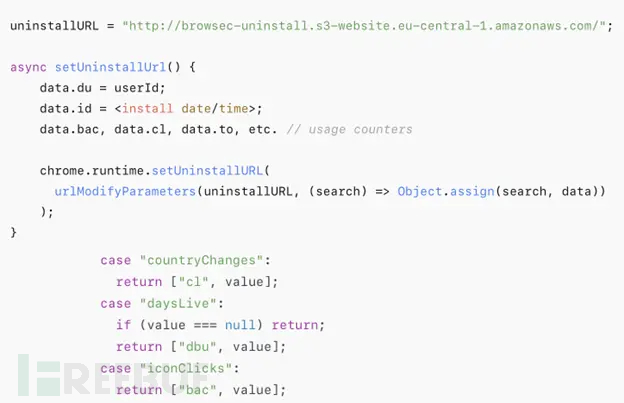
热门Chrome扩展程序存在明文传输风险,用户隐私安全受威胁
赛门铁克威胁猎手团队最新报告披露,数款拥有数百万活跃用户的Chrome扩展程序正在通过未加密的HTTP连接静默泄露用户敏感数据,严重威胁用户隐私安全。 知名扩展程序存在明文传输风险 尽管宣称提供安全浏览、数据分析或便捷界面等功能,但SEMR…...

从零开始了解数据采集(二十八)——制造业数字孪生
近年来,我国的工业领域正经历一场前所未有的数字化变革,从“双碳目标”到工业互联网平台的推广,国家政策和市场需求共同推动了制造业的升级。在这场变革中,数字孪生技术成为备受关注的关键工具,它不仅让企业“看见”设…...
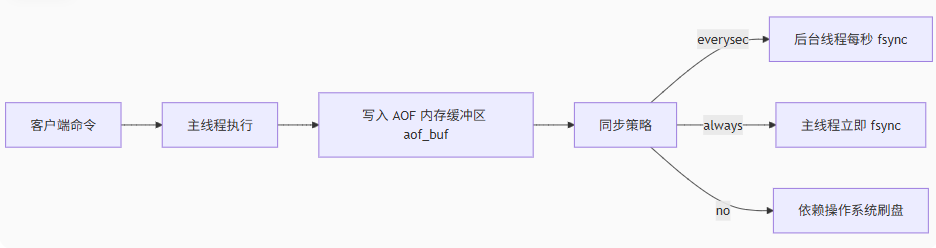
Redis上篇--知识点总结
Redis上篇–解析 本文大部分知识整理自网上,在正文结束后都会附上参考地址。如果想要深入或者详细学习可以通过文末链接跳转学习。 1. 基本介绍 Redis 是一个开源的、高性能的 内存键值数据库,Redis 的键值对中的 key 就是字符串对象,而 val…...

简单介绍C++中 string与wstring
在C中,string和wstring是两种用于处理不同字符编码的字符串类型,分别基于char和wchar_t字符类型。以下是它们的详细说明和对比: 1. 基础定义 string 类型:std::string 字符类型:char(通常为8位)…...