万字长文解读深度学习——dVAE(DALL·E的核心部件)
🌺历史文章列表🌺
深度学习——优化算法、激活函数、归一化、正则化
深度学习——权重初始化、评估指标、梯度消失和梯度爆炸
深度学习——前向传播与反向传播、神经网络(前馈神经网络与反馈神经网络)、常见算法概要汇总
万字长文解读深度学习——卷积神经网络CNN
万字长文解读深度学习——循环神经网络RNN、LSTM、GRU、Bi-RNN
万字长文解读深度学习——Transformer
深度学习——3种常见的Transformer位置编码【sin/cos、基于频率的二维位置编码(2D Frequency Embeddings)、RoPE】
万字长文解读深度学习——GPT、BERT、T5
万字长文解读深度学习——ViT、ViLT、DiT
DiT(Diffusion Transformer)详解——AIGC时代的新宠儿
万字长文解读深度学习——CLIP、BLIP
万字长文解读深度学习——AE、VAE
万字长文解读深度学习——GAN
万字长文解读深度学习——训练、优化、部署细节
万字长文解读深度学习——多模态模型BLIP2
万字长文解读深度学习——VQ-VAE和VQ-VAE-2
文章目录
- 前情提要
- VAE
- VQ-VAE
- VAE vs. VQ-VAE
- 区别
- 不可导问题及解决方法
- dVAE
- VQ-VAE 和 dVAE 的对比
- 背景:VQ-VAE 的停止梯度策略
- 局限性
- dVAE的结构
- dVAE 引入 Gumbel-Softmax 替代停止梯度策略
- Gumbel 分布
- Gumbel和高斯分布对比
- Gumbel-Softmax 采样过程
- Gumbel-Max Trick与Gumbel-Softmax区别
- 采样过程详细介绍
- 端到端优化的实现
- 替代的好处
前情提要
VAE
深度学习——AE、VAE
AE 和 VAE 在结构、目的和优化方式上存在多个重要区别:
| 特性 | AE | VAE |
|---|---|---|
| 编码器输出 | 固定的低维向量(确定性的表示) | 隐藏变量的均值 μ \mu μ 和方差 σ 2 \sigma^2 σ2(表示潜在空间的分布) |
| 潜在空间 | 没有明确的分布假设 | 假设潜在空间遵循某种概率分布(通常为正态分布) |
| 解码器 | 从固定低维向量生成输入数据的近似 | 使用 重参数化技巧 从潜在变量的分布中采样,再通过解码器生成输入数据的近似 |
| 损失函数 | 仅有重构损失,最小化输入数据与重构数据的差异 | 重构损失 + KL 散度,既保证数据重构效果,又保证潜在空间的分布合理 |
| 目的 | 数据降维、特征提取或数据去噪 | 生成新数据(如图像生成、文本生成等),同时保留对输入数据的重构能力 |
| 生成新数据的能力 | 无法直接生成新数据 | 可以通过在潜在空间中采样生成与训练数据相似的全新数据 |
VQ-VAE
万字长文解读深度学习——VQ-VAE和VQ-VAE-2
VAE vs. VQ-VAE
区别
需要明白的是,VAE的主要作用是生成数据;而VQ-VAE的主要作用是压缩、重建数据(与AE一样),如果需要生成新数据,则需要结合 PixelCNN 等生成模型。
- VAE 的核心思想是通过编码器学习潜在变量的
连续分布(通常是高斯分布,非离散),并从该分布中采样潜在变量 z,然后由解码器生成数据。- VQ-VAE模型的目标是学习如何将输入数据编码为
离散潜在表示,并通过解码器重建输入数据,量化过程通过最近邻搜索确定嵌入向量,是一个确定性操作,这一过程并不涉及离散采样。- 如果需要生成新数据,则需要在离散潜在空间中随机采样嵌入向量。VQ-VAE 本身没有内置采样机制,通常需要结合 PixelCNN 或PixelSNAIL 等模型来完成离散采样。
不可导问题及解决方法
- VAE 通过
连续潜在空间和重参数化技巧避免了采样操作的不可导问题。 - VQ-VAE 的
潜在空间是离散的,量化过程是不可导的,通过在最近邻搜索中使用停止梯度传播来解决不可导问题(dVAE中引入Gumbel-Softmax 替代停止梯度)。原本的VQ-VAE不涉及生成数据,所以不需要采样,如果需要生成数据,则需要结合 PixelCNN 等生成模型。
VAE 和 VQ-VAE 的不可导问题及解决方法:
| 特性 | VAE | VQ-VAE |
|---|---|---|
| 潜在空间 | 连续空间 | 离散空间 |
| 不可导问题来源 | 采样操作不可导 | 最近邻搜索不可导 |
| 解决方法 | 重参数化技巧 | 停止梯度传播 |
| 实现方式 | 分离随机性,直接优化 μ , σ \mu, \sigma μ,σ | 解码器损失绕过量化过程优化编码器 |
| 适用场景 | 平滑采样和连续潜在变量建模 | 离散特征学习和高分辨率生成 |
重新参数化梯度是一种常用于训练变分自编码器(VAE)等生成模型的技术。它依赖于连续分布的可分解性,而 VQ-VAE 的离散分布(通过 one-hot 编码或 Codebook 表示)无法通过这种方式重新参数化。
VAE 的不可导问题及解决方法
不可导问题
- 在训练VAE时,我们希望从一个分布中采样出一些隐变量,以生成模型的输出。然而,由于采样操作是不可导的,因此通常不能直接对采样操作求梯度。为了解决这个问题,我们可以使用重新参数化技术。
- 在 VAE 中,潜在变量 z z z 是通过从编码器输出的分布 q ( z ∣ x ) q(z|x) q(z∣x) 中采样得到的: z ∼ N ( μ , σ 2 ) z \sim \mathcal{N}(\mu, \sigma^2) z∼N(μ,σ2)
- μ \mu μ 和 σ \sigma σ 是编码器生成的分布参数。
- 采样操作引入随机性,而随机采样本身不可导,因此无法通过梯度反向传播来优化编码器参数。
解决方法:重参数化技巧
- 重新参数化技术的基本思想是,将采样过程拆分为两步:首先从一个固定的分布中采样一些固定的随机变量,然后通过一个确定的函数将这些随机变量转换为我们所需的随机变量。这样,我们就可以对这个确定的函数求导,从而能够计算出采样操作对于损失函数的梯度。
VAE 通过 重参数化技巧(Reparameterization Trick) 将采样过程分解为可导部分和不可导部分:
- 分离随机性:
- 采样公式改写为:
z = μ + σ ⋅ ϵ , ϵ ∼ N ( 0 , 1 ) z = \mu + \sigma \cdot \epsilon, \quad \epsilon \sim \mathcal{N}(0, 1) z=μ+σ⋅ϵ,ϵ∼N(0,1)- ϵ \epsilon ϵ 是标准正态分布的随机噪声,采样只发生在 ϵ \epsilon ϵ 中。
- μ \mu μ 和 σ \sigma σ 是由编码器网络直接输出的,可导。
- 作用:
- 随机性仅由不可导的 ϵ \epsilon ϵ 控制,而 μ \mu μ 和 σ \sigma σ 的梯度可以正常计算,从而实现端到端训练。
VQ-VAE 的不可导问题及解决方法
不可导问题
- 在 VQ-VAE 中,潜在变量是通过将编码器输出 z e ( x ) z_e(x) ze(x) 映射到最近的嵌入向量(codebook 中的向量)得到的: z q ( x ) = arg min e k ∥ z e ( x ) − e k ∥ 2 z_q(x) = \arg\min_{e_k} \|z_e(x) - e_k\|_2 zq(x)=argekmin∥ze(x)−ek∥2
- 最近邻搜索是一个不可导操作,因为argmin或argmax 是一个离散操作,涉及离散索引 k k k,因此不可导。
解决方法:停止梯度传播(Stop Gradient)
VQ-VAE 使用 停止梯度传播(Stop Gradient) 技巧来解决不可导问题:
- 停止梯度:
- 在计算量化操作时,不允许梯度传播到最近邻搜索的部分。
- 假设 z q ( x ) z_q(x) zq(x) 是量化后的嵌入向量,VQ-VAE 中的梯度计算会直接将解码器损失作用到编码器输出 z e ( x ) z_e(x) ze(x),而不会涉及量化过程。
- 公式:
- z q ( x ) z_q(x) zq(x) 的生成:
z q ( x ) = e k , k = arg min i ∥ z e ( x ) − e i ∥ 2 z_q(x) = e_k, \quad k = \arg\min_{i} \|z_e(x) - e_i\|_2 zq(x)=ek,k=argimin∥ze(x)−ei∥2- 在优化过程中,损失的梯度会通过以下方式传播:
z q ( x ) = z e ( x ) + ( e k − z e ( x ) ) . d e t a c h ( ) z_q(x) = z_e(x) + (e_k - z_e(x)).detach() zq(x)=ze(x)+(ek−ze(x)).detach()
- ( e k − z e ( x ) ) . d e t a c h ( ) (e_k - z_e(x)).detach() (ek−ze(x)).detach() 表示停止梯度传播,仅用 z e ( x ) z_e(x) ze(x) 来优化编码器。
dVAE
dVAE第一次出现是在 Open AI 的 DALL·E 模型论文(Zero-Shot Text-to-Image Generation)中,DALL·E模型是我最近开始研究VAE系列模型的根源,论文中并没有详细给出dVAE的模型架构,更多详细的dVAE结构,强烈推荐下面三篇外文博客:
Understanding VQ-VAE (DALL-E Explained Pt. 1)
How is it so good ? (DALL-E Explained Pt. 2)
How OpenAI’s DALL-E works?
Discrete VAE(dVAE),整体来说与 VQ-VAE 类似,主要的区别是:
- 在 VQ-VAE 中使用停止梯度传播来解决最近邻搜索的离散化方法造成的不可导问题。
- 在 dVAE 中使用Gumbel-Softmax为离散变量提供了一种连续化的近似来解决的离散化方法造成的不可导问题。
具体来说,Gumbel-Softmax 为离散变量提供了一种连续化的近似,使得离散潜变量的采样过程可以进行梯度反向传播,而不需要依赖停止梯度策略。dVAE 本身可以独立生成图像,不一定需要与生成模型(如 PixelCNN 或 Transformer)结合使用。
VQ-VAE 和 dVAE 的对比
| 特性 | VQ-VAE | dVAE |
|---|---|---|
| 离散化方法 | 最近邻搜索 | Gumbel-Softmax |
| 不可导问题解决策略 | 停止梯度传播 | 连续化近似 |
| 端到端可微性 | 部分可微 | 完全可微 |
| 训练效率 | 间接优化,编码器通过解码器接收反馈 | 高效优化,编码器直接接收梯度信号 |
| 潜变量表示 | 离散嵌入向量 | 平滑 one-hot 表示 |
| 灵活性 | 完全离散,固定 Codebook | 可调节连续与离散之间的平衡 |
| 生成能力 | 通常需要结合生成模型(如 PixelCNN) | 独立生成能力强 |
| 适用场景 | 离散建模,适合高分辨率图像生成或压缩任务 | 灵活生成,适合快速原型开发或连续采样任务 |
背景:VQ-VAE 的停止梯度策略
在 VQ-VAE 中,量化操作(如最近邻搜索)会将连续编码器输出 z e ( x ) z_e(x) ze(x) 映射到离散 Codebook 中的某个嵌入向量 e k e_k ek:
z q ( x ) = e k , k = argmin i ∥ z e ( x ) − e i ∥ 2 z_q(x) = e_k, \quad k = \text{argmin}_i \| z_e(x) - e_i \|_2 zq(x)=ek,k=argmini∥ze(x)−ei∥2
由于最近邻搜索的离散性,梯度无法直接通过离散化操作反向传播到编码器,因此 VQ-VAE 使用 停止梯度策略(Stop Gradient) 来解决不可导问题:
- 解码器的梯度绕过量化操作,直接作用于编码器输出 z e ( x ) z_e(x) ze(x)。
- 停止梯度的关键公式:
z q ( x ) = z e ( x ) + ( e k − z e ( x ) ) . d e t a c h ( ) z_q(x) = z_e(x) + (e_k - z_e(x)).detach() zq(x)=ze(x)+(ek−ze(x)).detach()- ( e k − z e ( x ) ) . d e t a c h ( ) (e_k - z_e(x)).detach() (ek−ze(x)).detach() 表示量化部分的梯度被截断,编码器无法接收到量化过程的直接信号。
局限性
- 停止梯度策略只是一种间接优化,编码器无法完全利用量化的反馈信号。
- 这种间接的训练方法可能导致训练效率较低或模型收敛较慢。
dVAE的结构

图片来源
dVAE 引入 Gumbel-Softmax 替代停止梯度策略
论文:CATEGORICAL REPARAMETERIZATION WITH GUMBEL-SOFTMAX
Gumbel-Softmax 为离散变量提供了一种连续化的近似,使得离散潜变量的采样过程可以进行梯度反向传播,而不需要依赖停止梯度策略,同时保持端到端可微性。
Gumbel 分布
Gumbel 分布是一种概率分布,用于建模极值(最大值或最小值)的分布情况。它经常在极值理论(Extreme Value Theory)中使用,描述数据集中最大值或最小值的分布特性。具体来说,Gumbel(0, 1) 是一种标准化的 Gumbel 分布,其位置参数为 0,尺度参数为 1。
- 定义域:Gumbel 分布定义在整个实数范围 ( − ∞ , + ∞ ) (-\infty, +\infty) (−∞,+∞)。
- 极值理论:Gumbel 分布常用于建模一组数据的极值(最大值或最小值)。
- 标准化形式(Gumbel(0, 1)):
- 位置参数 μ = 0 \mu = 0 μ=0:分布的中心在 0。
- 尺度参数 β = 1 \beta = 1 β=1:控制分布的离散程度。
Gumbel和高斯分布对比
| 特点 | Gumbel 分布 | 高斯分布 |
|---|---|---|
| 数据类型 | 离散(类别),离散分布的采样 | 连续(实数值),连续分布的采样 |
| 应用场景 | 离散变量采样(如 dVAE, Gumbel-Softmax) | 连续变量采样(如 VAE, 正态分布噪声) |
| 目标 | 极值建模、离散采样 | 数据建模、噪声建模 |
| 可微性 | 结合 Softmax 可实现连续化,支持梯度反传 | 本身是连续分布,天然可微 |
| 尾部行为 | 长尾分布,适合极值建模 | 轻尾分布,适合一般建模 |
| 数学特性 | 极值分布理论,适合最大值或最小值问题 | 中心极限定理,适合数据聚类和分布建模 |
Gumbel-Softmax 采样过程
- 使用 Gumbel 分布生成一组噪声样本:
- 对每个类别 i i i 从 Gumbel 分布 Gumbel ( 0 , 1 ) \text{Gumbel}(0, 1) Gumbel(0,1) 中采样噪声 g i g_i gi,模拟离散采样中的随机性。
- 通过 Softmax 函数将这些噪声样本映射到一个类别分布:
- 将 logits(类别概率的对数)加上 Gumbel 噪声后通过 Softmax 转化为一个概率分布:
y i = exp ( ( log ( π i ) + g i ) / τ ) ∑ j = 1 k exp ( ( log ( π j ) + g j ) / τ ) y_i = \frac{\exp((\log(\pi_i) + g_i)/\tau)}{\sum_{j=1}^k \exp((\log(\pi_j) + g_j)/\tau)} yi=∑j=1kexp((log(πj)+gj)/τ)exp((log(πi)+gi)/τ) - 输出的 y y y 是一个平滑的概率分布,近似 one-hot 编码。
- 将 logits(类别概率的对数)加上 Gumbel 噪声后通过 Softmax 转化为一个概率分布:
- 温度控制:
- 温度系数 τ \tau τ 控制分布的平滑程度:
- 当 τ → 0 \tau \to 0 τ→0:Softmax 逼近 ArgMax,输出接近离散 one-hot。
- 当 τ → ∞ \tau \to \infty τ→∞:分布接近均匀,类别无显著差异。
- 温度系数 τ \tau τ 控制分布的平滑程度:
Gumbel-Max Trick与Gumbel-Softmax区别
| 特性 | Gumbel-Max Trick | Gumbel-Softmax |
|---|---|---|
| 采样目标 | 精确离散采样 | 连续化近似采样 |
| 输出形式 | 单一类别(离散值) | 连续概率分布 |
| 是否可微 | 不可微 | 可微 |
| 适用场景 | 需要离散采样的任务 | 深度学习中的端到端训练任务 |
| 温度参数 τ \tau τ | 不涉及 | 控制分布的平滑程度 |
| 推理阶段 | 直接使用 | 通常替换为 argmax \text{argmax} argmax |
采样过程详细介绍
这个过程是可微分的,因此可以在反向传播中进行梯度计算。
如下图所示:
-
一个图像经 Encoder 编码会生成 32x32 个 embedding;
-
embedding 和 codebook (8192 个)进行内积;
-
内积再经 Softmax 即可得到在每个 codebook 向量的概率。

dVAE获取图像,并输出每个潜在特征的码本向量集上的分类分布 -
应用 Gumbel Softmax 采样即可获得新的概率分布;
-
然后将概率分布作为权重,对相应的 codebook 向量进行累积;就可以获得 latent vector。
-
然后 Decoder 可以基于此 latent vector 重构输出图像。

从Gumbel softmax分布中采样码本向量,然后将它们传递到解码器以重建原始的编码图像
在上述的过程中,通过添加 Gumbel 噪声的方式进行离散采样,可以近似为选择 logits 中概率最大的类别,从而提供一种可微分的方式来处理离散采样问题。具体来说,其关键为 Gumbel-Max Trick,其中 g i g_i gi 是从 Gumbel(0, 1) 分布中采样得到的噪声,τ 是温度系数。需要说明的是,t 越小,此处的 Softmax 就会越逼近于 ArgMax。τ 越大,就越接近于均匀分布。这也就引入了训练的一个 Trick:训练起始的温度系数 τ 很高,在训练的过程中,逐渐降低 τ,以便其逐渐逼近 ArgMax。在推理阶段就不再需要 Gumbel Softmax,直接使用 ArgMax 即可。

图片来源
通过 Gumbel-Softmax,编码器输出的 logits 可以生成一个连续近似的 one-hot 表示 y y y,公式如下:
y i = exp ( ( log ( π i ) + g i ) / τ ) ∑ j = 1 k exp ( ( log ( π j ) + g j ) / τ ) , g i ∼ Gumbel ( 0 , 1 ) y_i = \frac{\exp((\log(\pi_i) + g_i)/\tau)}{\sum_{j=1}^k \exp((\log(\pi_j) + g_j)/\tau)}, \quad g_i \sim \text{Gumbel}(0, 1) yi=∑j=1kexp((log(πj)+gj)/τ)exp((log(πi)+gi)/τ),gi∼Gumbel(0,1)
- π i \pi_i πi: 类别 i i i 的概率,表示离散分布中类别 i i i 被选择的概率,满足 π i > 0 \pi_i > 0 πi>0 且 ∑ i = 1 k π i = 1 \sum_{i=1}^k \pi_i = 1 ∑i=1kπi=1。
- log ( π i ) \log(\pi_i) log(πi): 类别 i i i 的对数概率,也称为 logits(表示每个类别的概率得分)。它是为了将概率值映射到对数空间,便于数值稳定性和与 Gumbel 噪声结合。
- g i g_i gi: 从 Gumbel 分布 Gumbel ( 0 , 1 ) \text{Gumbel}(0, 1) Gumbel(0,1) 中采样的噪声,用于引入随机性,模拟离散采样过程。
- τ \tau τ: 温度参数,控制生成分布的平滑程度:
- 当 τ → 0 \tau \to 0 τ→0, y i y_i yi 趋于 one-hot 表示(接近离散分布)。
- 当 τ → ∞ \tau \to \infty τ→∞, y i y_i yi 趋于均匀分布(所有类别的概率接近相等)。
端到端优化的实现
- Gumbel-Softmax 的输出是一个连续变量,可以近似离散的 one-hot 表示。
- 由于其公式中仅包含可导操作,梯度可以通过 Gumbel-Softmax 直接传递到编码器的 logits,实现端到端的可微优化。
- 不需要像 VQ-VAE 一样依赖停止梯度策略来绕过不可导的离散化操作。
替代的好处
- 完全可微:
- Gumbel-Softmax 的连续近似使得整个模型可以端到端训练,而不需要手动截断梯度。
- 更直接的优化:
- 编码器可以接收到更完整的梯度信号,而不是依赖解码器的间接反馈。
- 灵活的离散化:
- 通过调节温度参数 τ \tau τ,可以在连续和离散之间找到平衡,进一步增强模型的优化能力。
总体而言,dVAE与VQ-VAE的目标相同:它们都试图学习复杂数据分布的离散潜在表示,例如自然图像的分布。每种方法都以自己独特的方式解决问题。VQ-VAE使用矢量量化,而dVAE将离散采样问题放宽为连续近似。虽然每种技术都有自己的一套权衡,但最终它们似乎都是解决这个问题的同样有效和同样成功的方法。
参考:
文生图模型演进:AE、VAE、VQ-VAE、VQ-GAN、DALL-E 等 8 模型
【论文精读】DALLE: Zero-Shot Text-to-Image Generation零样本文本到图像生成
【论文精读】DALLE2: Hierarchical Text-Conditional Image Generation with CLIP Latents
【论文精读】DALLE3:Improving Image Generation with Better Captions 通过更好的文本标注改进图像生成
AI绘画原理解析:从CLIP、BLIP到DALLE、DALLE 2、DALLE 3、Stable Diffusion(含ControlNet详解)
参考博文(DALL·E和dVAE的很多国内文章图片都来自下面的博文):
Understanding VQ-VAE (DALL-E Explained Pt. 1)
How is it so good ? (DALL-E Explained Pt. 2)
How OpenAI’s DALL-E works?
相关文章:
万字长文解读深度学习——dVAE(DALL·E的核心部件)
🌺历史文章列表🌺 深度学习——优化算法、激活函数、归一化、正则化 深度学习——权重初始化、评估指标、梯度消失和梯度爆炸 深度学习——前向传播与反向传播、神经网络(前馈神经网络与反馈神经网络)、常见算法概要汇总 万字长…...

RL仿真库pybullet
1. 介绍 PyBullet是一个基于Bullet Physics引擎的物理仿真Python接口,主要用于机器人仿真模拟。 1.1 主要特点 提供大量预设的机器人模型,例如URDF(统一机器人描述格式)、SDF、MJCF 格式。适用于训练和评估强化学习算法,提供了大量的强化学…...

file_get_contents函数导致网站卡死响应超时
宝塔控制面板系统下运行包含file_get_contents函数的php文件时候,发生以下报错: PHP Warning: file_get_contents():php_network_getaddresses: getaddrinfo failed: 解决方法: 一:需要检查请求的远程主机是否在本机的/etc/host…...

如何使用C#与SQL Server数据库进行交互
一.创建数据库 用VS 创建数据库的步骤: 1.打开vs,创建一个新项目,分别在搜素框中选择C#、Windows、桌面,然后选择Windows窗体应用(.NET Framework) 2.打开“视图-服务器资源管理器”,右键单击“数据连接”࿰…...

#渗透测试#红蓝对抗#SRC漏洞挖掘# Yakit(5)进阶模式-MITM中间人代理与劫持(上)
免责声明 本教程仅为合法的教学目的而准备,严禁用于任何形式的违法犯罪活动及其他商业行为,在使用本教程前,您应确保该行为符合当地的法律法规,继续阅读即表示您需自行承担所有操作的后果,如有异议,请立即停…...

vue3 项目搭建-9-通过 router 在跳转页面时传参
第一步,在跳转链接处挂载方法,将要传输的数据传入: <a href"#" click.prevent"goToArticle(obj.id)" class"click"><h1>{{obj.title}}</h1><p>作者:{{obj.author}}</p&…...

Java、python标识符命名规范
Java 包名所有字母一律小写。例如cn.com.test类名和接口名每个单词的首字母都要大写。例如ArrayList、Iterator常量名所有字母都大写,单词之间用下划线连接,例如:DAY_OF_MONTH变量名和方法名的第一个单词首字母小写,从第二个单词…...

高效职场人
文章目录 1.时间效能 ABCD2.高效员工的习惯之 自我掌控的秘诀3.学会做主4.学会互赢5.学会沟通、学会聆听6.学会可持续发展:四个方面更新自我(1)更新身体(2)更新精神(3)更新智力(4)更新人际情感 1.时间效能 ABCD 时间四象限: A类任务:重要且紧…...

深入探索现代 IT 技术:从云计算到人工智能的全面解析
目录 1. 云计算:重塑 IT 基础设施 2. 大数据:挖掘信息的价值 3. 物联网(IoT):连接物理世界 4. 区块链:重塑信任机制 5. 人工智能(AI):智能未来的驱动力 结语 在当今…...

【AI学习】苹果技术报告《Apple Intelligence Foundation Language Models》
文章地址:https://machinelearning.apple.com/papers/apple_intelligence_foundation_language_models.pdf 这篇文章介绍了苹果公司开发的基础语言模型(Apple Foundation Language Models,简称AFM),这些模型旨在为苹果…...

深度相机获取实时图像总结
问题详情:之前一直把曝光调整到50000,画面一直很流畅,知道领导要求将曝光改成500000时整个程序卡死了 问题解决: 首先怀疑是帧率太低的原因,控制变量后发现不是帧率的问题,看着代码很迷茫,领导…...

Nginx限流实践-limit_req和limit_conn的使用说明
注意: 本文内容于 2024-12-07 19:38:40 创建,可能不会在此平台上进行更新。如果您希望查看最新版本或更多相关内容,请访问原文地址:Nginx限流实践。感谢您的关注与支持! 一、限流 之前我有记录通过CentOS7定时任务实…...

Unity在运行状态下,当物体Mesh网格发生变化时,如何让MeshCollider碰撞体也随之实时同步变化?
旧版源代码地址:https://download.csdn.net/download/qq_41603955/90087225?spm1001.2014.3001.5501 旧版效果展示: 新版加上MeshCollider后的效果: 注意:在Unity中,当你动态地更改物体的Mesh时,通常期望…...

记一次由docker容器使得服务器cpu占满密码和密钥无法访问bug
Bug场景: 前几天在服务器上部署了一个免费影视网站,这个应用需要四个容器,同时之前的建站软件workpress也是使用docker部署的,也使用了三个容器。在使用workpress之前,我将影视软件的容器全部停止。 再使用workpress…...

前端TS基础
文章目录 一、类型1、定义类型2、any、unknown、never3、基础类型4、联合类型5、交叉类型6、type、typeof7、作用域 二、数据结构1、数组2、元组3、函数类型4、对象类型 三、接口四、泛型五、enum六、断言七、工具1、模块2、namespace3、装饰器4、declare5、运算符6、映射类型7…...

前端面经每日一题day06
Cookie有什么字段 Name:cookie的唯一标识符 Value:与Name对应,存储Cookie的信息 Domain:可以访问cookie的域名 Path:可以访问cookie的路径 Expires/Max-Age:超时时间 Size:cookie大小 Ht…...

SOC,SOH含义区别及计算公式
SOC,SOH含义区别及计算公式 两者结合使用,有助于实现更精确的电池管理,延长电池的使用寿命,并确保电池的高效、安全运行。 1. SOC(State of Charge,荷电状态)2. SOH(State of Health…...

阿里云轻量应用服务器开放端口,图文教程分享
阿里云轻量应用服务器如何开放端口?在轻量服务器管理控制台的防火墙中添加规则即可开通端口,开通80端口就填80,开通443就填443端口,开通3306端口就填3306。阿里云百科网aliyunbaike.com整理阿里云轻量应用服务器端口号开通图文教程…...

嵌入式里的“移植”概念
这里因为最近一年看到公司某项目很多代码上有直接硬件的操作,这里有感而发,介绍移植的概念。 一、硬件 先上一个图: 举个例子,大学里应该都买过开发板,例如st的,这里三个层次, 内核ÿ…...

深入探讨 AF_PACKET 套接字
AF_PACKET 套接字是一种用于直接访问网络接口(即网卡)的套接字类型,通常用于网络数据包捕获和分析。它允许应用程序直接与网络接口卡(NIC)交互,而不需要通过网络协议栈。从而可以发送和接收以太网帧。它提供了比普通TCP/UDP套接字…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...
关于easyexcel动态下拉选问题处理
前些日子突然碰到一个问题,说是客户的导入文件模版想支持部分导入内容的下拉选,于是我就找了easyexcel官网寻找解决方案,并没有找到合适的方案,没办法只能自己动手并分享出来,针对Java生成Excel下拉菜单时因选项过多导…...
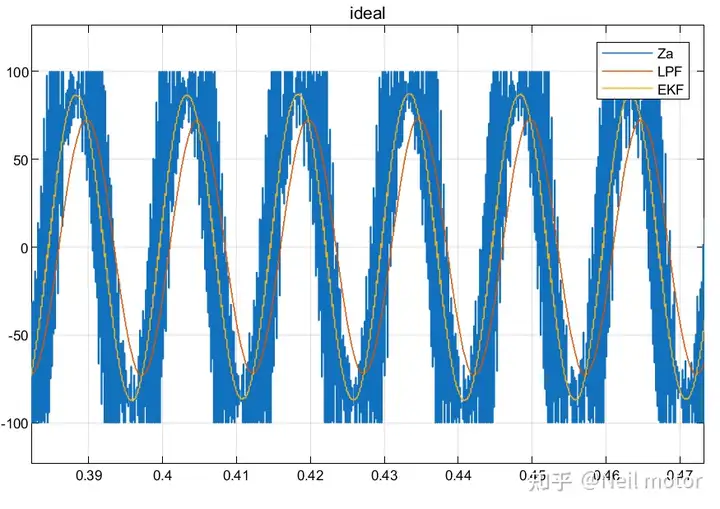
永磁同步电机无速度算法--基于卡尔曼滤波器的滑模观测器
一、原理介绍 传统滑模观测器采用如下结构: 传统SMO中LPF会带来相位延迟和幅值衰减,并且需要额外的相位补偿。 采用扩展卡尔曼滤波器代替常用低通滤波器(LPF),可以去除高次谐波,并且不用相位补偿就可以获得一个误差较小的转子位…...

深入浅出WebGL:在浏览器中解锁3D世界的魔法钥匙
WebGL:在浏览器中解锁3D世界的魔法钥匙 引言:网页的边界正在消失 在数字化浪潮的推动下,网页早已不再是静态信息的展示窗口。如今,我们可以在浏览器中体验逼真的3D游戏、交互式数据可视化、虚拟实验室,甚至沉浸式的V…...

LangChain【6】之输出解析器:结构化LLM响应的关键工具
文章目录 一 LangChain输出解析器概述1.1 什么是输出解析器?1.2 主要功能与工作原理1.3 常用解析器类型 二 主要输出解析器类型2.1 Pydantic/Json输出解析器2.2 结构化输出解析器2.3 列表解析器2.4 日期解析器2.5 Json输出解析器2.6 xml输出解析器 三 高级使用技巧3…...

深入浅出JavaScript中的ArrayBuffer:二进制数据的“瑞士军刀”
深入浅出JavaScript中的ArrayBuffer:二进制数据的“瑞士军刀” 在JavaScript中,我们经常需要处理文本、数组、对象等数据类型。但当我们需要处理文件上传、图像处理、网络通信等场景时,单纯依赖字符串或数组就显得力不从心了。这时ÿ…...
)
GitHub 常见高频问题与解决方案(实用手册)
1.Push 提示权限错误(Permission denied) 问题: Bash Permission denied (publickey) fatal: Could not read from remote repository. 原因: 没有配置 SSH key 或使用了 HTTPS 而没有权限…...